消息队列笔记
消息队列笔记
本文部分图片摘自极客课程:消息队列高手课;部分概念摘自维基百科。
消息队列的概念
任何技术的出现都是为了解决某个问题,消息队列是为了解决应用之间通信的需求,但是又不仅仅是这个需求。
那么消息队列是什么,有什么作用呢?
举个例子来说,就比如现在网购这么发达,最开始的快递行业是送货上门,你有个快递,快递小哥就会送到你家门口。但是问题来了,家里不一定有人啊。快递小哥就会直接把快递放在家门口,然后给你发个短信——xxx单号的快递放你家门口了,记得签收一下。如果没什么意外你下班回到家拿到快递,诶你很高兴。但是如果出现意外,比如说被偷走了,你就很生气,就会去投诉快递小哥。快递小哥也很委屈啊,我也不能蹲你家门口一直等你回来把快递给你我再走啊,那我剩下那一大堆快递可怎么整啊!那有什么地方可以存放快递,解放快递小哥的同时又保证快递不会丢呢——快递柜出现了。快递小哥把快递放到你楼下的快递柜,那么快递柜做了什么呢?一般去快递柜寄过快递的都知道啊:首先快递小哥会登陆,然后输入要存放的快递订单号,收件人电话,然后快递小哥就把快递放进去,在他关上快递柜门的同时,快递柜就会给你发个短信通知你:你的快递已经放到了快递柜,你下班记得来取一下!这样你什么时候有空就什么时候去取,快递小哥可以继续送他剩下的快递,你也可以安心的上你的班逛你的街,两边都很开心。那如果正好是双十一啊,你买了N多快递,这也没问题啊,快递小哥会按照快递送达的顺序,给你放到快递柜,你到时候按照去取就好啦。
快递柜就好比消息队列,你的快递就好比是消息,你就好比是消费者。一个快递柜就实现了快递小哥跟你的解耦。
消息队列也是一样,它可以实现两个应用之间的解耦——从名字上看,是用来发送消息的,存放消息的数据结构是队队列,也就是先放进去的会先被取出来。那么我们从名字上可以看出消息队列第一个功能:存放消息,并且保证消息严格有序。第二个功能:异步。
消息队列模型
好的架构不是设计出来的,而是演进出来的。 现代的消息队列呈现出的模式,一样是经过之前的十几年逐步演进而来的。
队列模型
早期的消息队列,确实是按照队列这种数据结构设计的。在维基百科中,队列是这样定义的:
队列是先进先出(FIFO, First-In-First-Out)的线性表(Linear List)。在具体应用中通常用链表或者数组来实现。队列只允许在后端(称为 rear)进行插入操作,在前端(称为 front)进行删除操作。
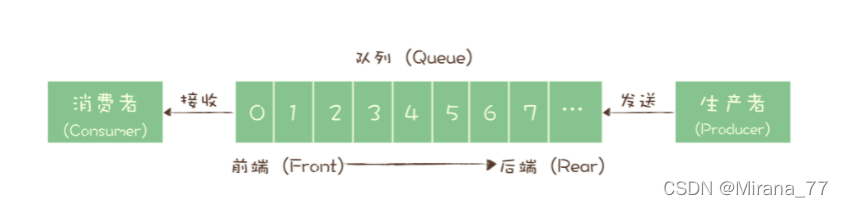
这有个显著的缺点:
如果有多个消费者消费队列中的数据,这些消费者其实是竞争的关系。我把消息消费掉了,你就不能再消费了。除非生产者事先知道有N个消费者要消费,然后同样的数据往队列中放N份。
那显然生产者跟消费者并没有解耦啊。为了解决这个问题,演化出了另一种消息模型:
发布订阅模型
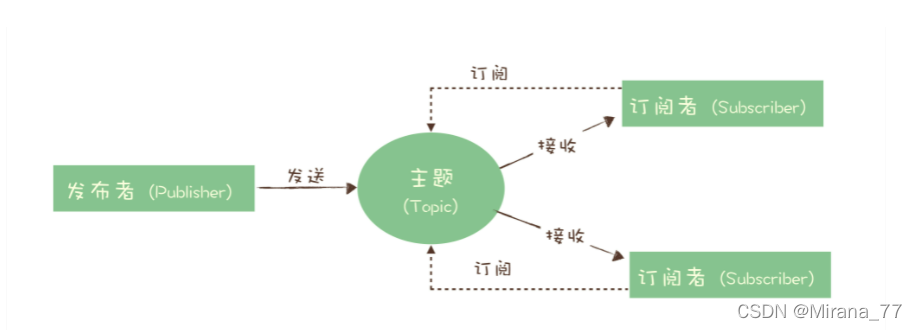
在发布 - 订阅模型中,消息的发送方称为发布者(Publisher),消息的接收方称为订阅者(Subscriber),服务端存放消息的容器称为主题(Topic)。发布者将消息发送到主题中,订阅者在接收消息之前需要先“订阅主题”。“订阅”在这里既是一个动作,同时还可以认为是主题在消费时的一个逻辑副本,每份订阅中,订阅者都可以接收到主题的所有消息。
你会发现,发布订阅模型跟队列模型的区别就在于订阅者将自己需要订阅哪些数据这个信息交给消息队列去管理,生产者依旧是把数据发送给消息队列,然后订阅者告诉消息队列,我需要订阅哪些数据,由消息队列去给订阅者发送这些数据;而不是订阅者告诉生产者,我需要订阅xxx数据,你把这些数据往消息队列上发送N份。实际上就是把队列模型中,负责处理订阅者订阅数据的这个功能转交给消息队列去负责,从而实现了发布者与订阅者的解耦。
而事实上,可以认为发布订阅模型在功能层面上是兼容队列模型的。而大部分消息队列都使用发布订阅模型,当然也有少数:RabbitMQ。
消息队列的消息模型实现
RabbitMQ的消息模型
RabbitMQ的消息模型是队列模型,它采用Exchange 模块去解决多个消费者的问题:
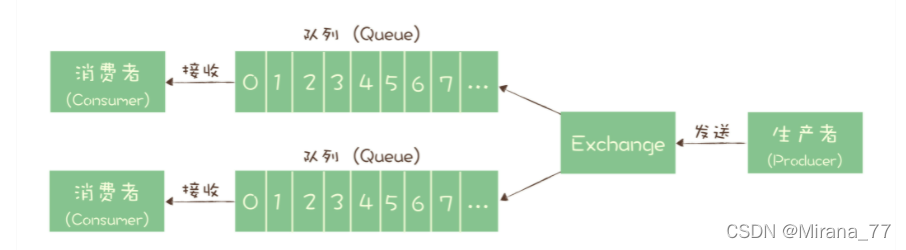
在 RabbitMQ 中,Exchange 位于生产者和队列之间,生产者并不关心将消息发送给哪个队列,而是将消息发送给 Exchange,由 Exchange 上配置的策略来决定将消息投递到哪些队列中。同一份消息如果需要被多个消费者来消费,需要配置 Exchange 将消息发送到多个队列,每个队列中都存放一份完整的消息数据,可以为一个消费者提供消费服务。这也可以变相地实现新发布 - 订阅模型中,“一份消息数据可以被多个订阅者来多次消费”这样的功能。
RocketMQ的消息模型
RocketMQ的消息模型是标准的发布-订阅模型。同时,RocketMQ中也有队列的概念。
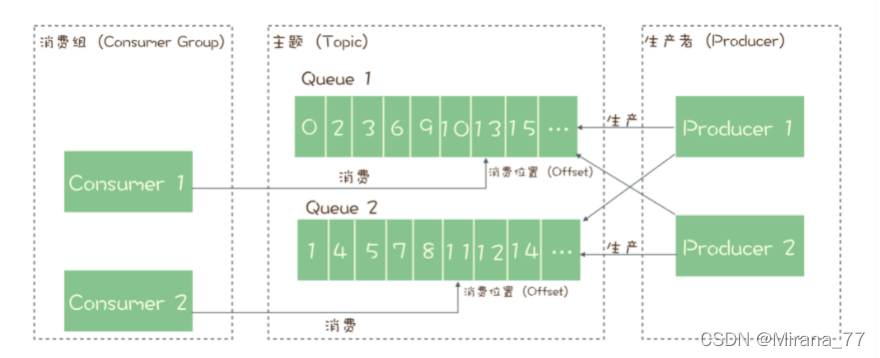
RocketMQ中,订阅者的概念是通过消费组(Consumer Group)来体现的。每个消费组都消费主题中一份完整的消息,不同消费组之间消费进度彼此不受影响,也就是说,一条消息被 Consumer Group1 消费过,也会再给 Consumer Group2 消费。
消费组中包含多个消费者,同一个组内的消费者是竞争消费的关系,每个消费者负责消费组内的一部分消息。如果一条消息被消费者 Consumer1 消费了,那同组的其他消费者就不会再收到这条消息。
在 Topic 的消费过程中,由于消息需要被不同的组进行多次消费,所以消费完的消息并不会立即被删除,这就需要 RocketMQ 为每个消费组在每个队列上维护一个消费位置(Consumer Offset),这个位置之前的消息都被消费过,之后的消息都没有被消费过,每成功消费一条消息,消费位置就加一。这个消费位置是非常重要的概念,我们在使用消息队列的时候,丢消息的原因大多是由于消费位置处理不当导致的。
消息队列的消费机制
几乎所有的消息队列产品都使用一种非常朴素的“请求 - 确认”机制,确保消息不会在传递过程中由于网络或服务器故障丢失。具体的做法也非常简单。在生产端,生产者先将消息发送给服务端,也就是 Broker,服务端在收到消息并将消息写入主题或者队列中后,会给生产者发送确认的响应。
如果生产者没有收到服务端的确认或者收到失败的响应,则会重新发送消息;在消费端,消费者在收到消息并完成自己的消费业务逻辑(比如,将数据保存到数据库中)后,也会给服务端发送消费成功的确认,服务端只有收到消费确认后,才认为一条消息被成功消费,否则它会给消费者重新发送这条消息,直到收到对应的消费成功确认。
这个确认机制很好地保证了消息传递过程中的可靠性,但是,引入这个机制在消费端带来了一个不小的问题。什么问题呢?为了确保消息的有序性,在某一条消息被成功消费之前,下一条消息是不能被消费的,否则就会出现消息空洞,违背了有序性这个原则。
也就是说,每个主题在任意时刻,至多只能有一个消费者实例在进行消费,那就没法通过水平扩展消费者的数量来提升消费端总体的消费性能。既然水平不行,那么就垂直——
RocketMQ 在主题下面增加了队列的概念。每个主题包含多个队列,通过多个队列来实现多实例并行生产和消费。RocketMQ 只在队列上保证消息的有序性,主题层面是无法保证消息的严格顺序的。而在Kafka中,队列的名字叫做“分区(Partition)”,只是单纯的名字不一样,功能与含义都是一样的。
消息队列的特性
事务
我们对事务对认知通常是在数据库行为上:我们对数据库中的一组数据进行操作,希望它们同时成功或者同时失败。 严格的事务实现,应该具有A(atomicity原子性)C(consistency一致性)I(isolation隔离性)D(durability持久性)四个属性。
举个例子:我们在淘宝购物时,先把商品加到购物车里,然后几件商品一起下单,最后支付,然后就可以坐等收货。购物这个简单的动作,其实划分为几个模块:订单-购物车-用户等,而下单这个动作一般会涉及到订单与购物车,我们从购物车选中商品,支付成功后生成订单的同时,购物车中这几个商品就消失了,这个步骤就可以使用消息队列来实现:
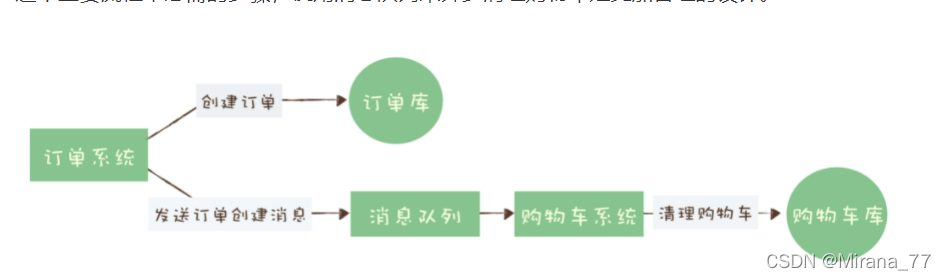
分布式事务
而在分布式系统中,想要保证ACID那代价可太大了,分布式事务常见的实现是2PC(Two-phase Commit,也叫二阶段提交)、TCC(Try-Confirm-Cancel) 和事务消息。
事务消息适用的场景主要是那些需要异步更新数据,并且对数据实时性要求不太高的场景。
2PC是二阶段提交,简单的描述就是准备和提交两个阶段。
TCC(Try-Confirm-Cancel)事务过程中会分为三步:try-confirm-cancel。
后续会专门对分布式事务做整理,所以在此不做过多介绍。
消息队列更多是两个应用之间,也就是两个系统之间的通信,事务消息需要消息队列提供相应的功能才能实现,Kafka 和 RocketMQ 都提供了事务相关功能,采用的其实是2PC二阶段提交,不过它们具体的细节实现不一样。
还是购物车与订单这个栗子:
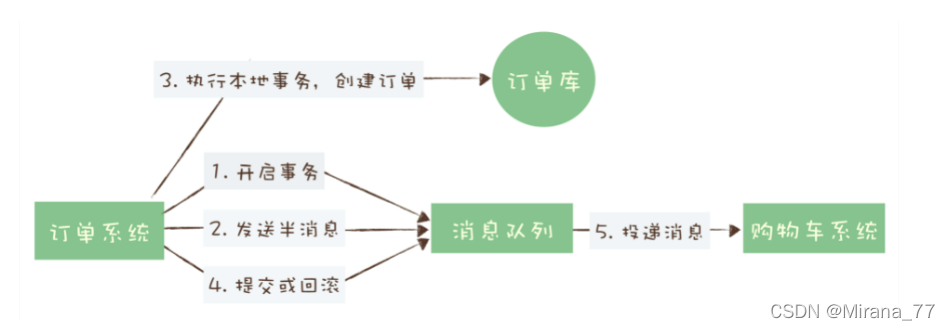
我们在购物车中选择商品提交订单——订单系统就会开启一个事务,同时也会告诉消息队列,然后订单系统继续执行本地事务,进行后续业务操作,例如支付啊,扣除库存啊。我们知道,在使用淘宝下订单的时候,下单成功并不代表购买成功,真正支付才代表购买成功。
如果你下单完支付失败了,订单系统就会回滚,同时告诉消息队列,我这边失败了你那里也要回滚。
如果下单后支付成功订单系统后续业务操作也都支付成功,那就提交事务,购物车系统就可以消费到这条消息继续后续的流程。
在订单系统没提交之前,购物车系统是看不到这条消息的。
那还有一个问题:如果在第4步提交事务消息时失败了如何处理?
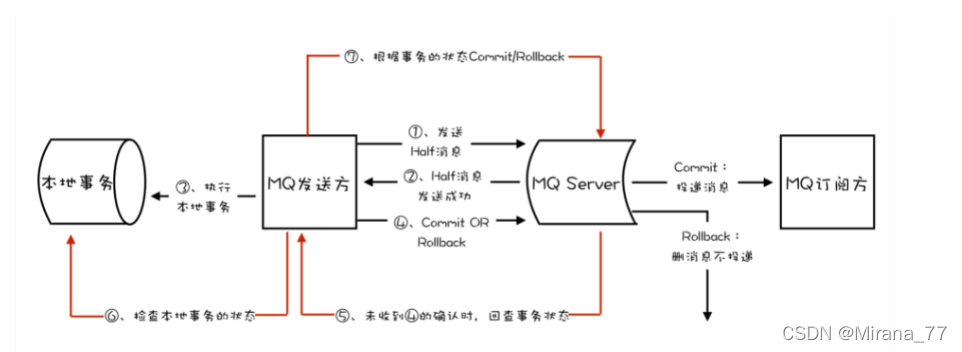
RocketMQ的处理
在 RocketMQ 中的事务实现中,增加了事务反查的机制来解决事务消息提交失败的问题。如果 Producer 也就是订单系统,在提交或者回滚事务消息时发生网络异常,RocketMQ 的 Broker 没有收到提交或者回滚的请求,Broker 会定期去 Producer 上反查这个事务对应的本地事务的状态,然后根据反查结果决定提交或者回滚这个事务。
为了支持这个事务反查机制,我们的业务代码需要实现一个事务反查状态的接口,告诉RocketMQ本地事务所成功还是失败。
这个反查本地事务的实现,并不依赖消息的发送方,也就是订单服务的某个实例节点上的任何数据。这种情况下,即使是发送事务消息的那个订单服务节点宕机了,RocketMQ 依然可以通过其他订单服务的节点来执行反查,确保事务的完整性。
使用 RocketMQ 事务消息功能实现分布式事务的流程如下图:
Kafka的处理
Kafka的处理就非常的简单粗暴了:直接给你抛个异常,您自己看着办吧嗷,小爷我不伺候了。
可靠性
我们都知道消息队列会提供可靠性保证——这个保证指的就是消息传递过程中,哪怕遇到了网络中断或者硬件故障,数据也不会丢失。
消息队列的可靠性实现
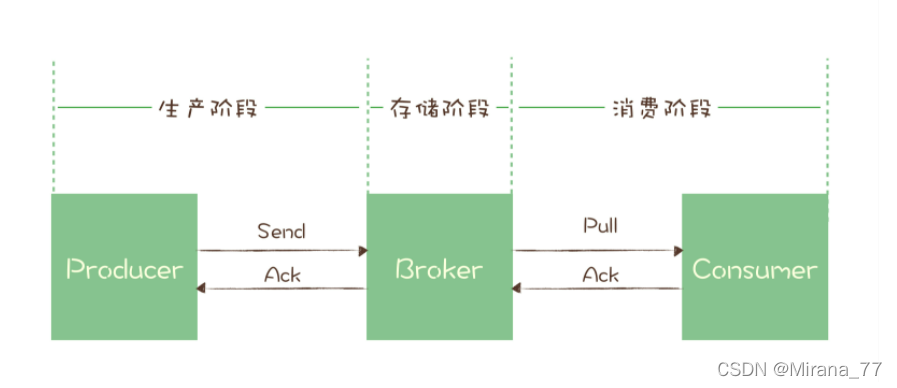
一条消息从生产者发送到消费者接收,主要经过三步:
-
生产阶段: 在这个阶段,从消息在 Producer 创建出来,经过网络传输发送到 Broker 端。
生产阶段主要通过请求确认机制ACK来保证消息的可靠传递:当你的代码调用发消息方法时,消息队列的客户端会把消息发送到 Broker,Broker 收到消息后,会给客户端返回一个确认响应,表明消息已经收到了。客户端收到响应后,完成了一次正常消息的发送。有些消息队列在长时间没收到发送确认响应后,会自动重试,如果重试再失败,就会以返回值或者异常的方式告知用户。
做法就是你需要捕获消息发送的错误,并重发消息。
-
存储阶段: 在这个阶段,消息在 Broker 端存储,如果是集群,消息会在这个阶段被复制到其他的副本上。
你可以通过配置刷盘和复制相关的参数,让消息写入到多个副本的磁盘上,来确保消息不会因为某个 Broker 宕机或者磁盘损坏而丢失。例如kafka就是通过配置参数acks来实现可靠性保证的。
-
消费阶段: 在这个阶段,Consumer 从 Broker 上拉取消息,经过网络传输发送到 Consumer 上。
同生产阶段,利用ACK保证可靠性,你需要在处理完全部消费业务逻辑之后,再发送消费确认。
检测丢失消息
我们知道消息队列中的消息是有序的,那我们就可以利用这个有序性来检测消息是否丢失。
做法很简单,在生产者端,我们搞个拦截器,每个发出的消息都加上一个连续递增的序号,在消费者端检查下就可以啦。
注意的点
- 像 Kafka 和 RocketMQ 这样的消息队列,它是不保证在 Topic 上的严格顺序的,只能保证分区上的消息是有序的,所以我们在发消息的时候必须要指定分区,并且,在每个分区单独检测消息序号的连续性。
- 如果你的系统中 Producer 是多实例的,由于并不好协调多个 Producer 之间的发送顺序,所以也需要每个 Producer 分别生成各自的消息序号,并且需要附加上 Producer 的标识,在 Consumer 端按照每个 Producer 分别来检测序号的连续性。
- Consumer 实例的数量最好和分区数量一致,做到 Consumer 和分区一一对应,这样会比较方便地在 Consumer 内检测消息序号的连续性。
消息队列的问题
如何处理重复消息
消息队列在消息生产阶段既然利用了ACK来保证消息一定发送出去,那么就可能会产生重复的消息,消费者就必须要对重复消息进行处理。解决的方式我们通常一搜一大把,关键词基本上只有一个:让我们消费消息的操作具备幂等性。
幂等性
幂等(Idempotence) 本来是一个数学上的概念,它是这样定义的:
如果一个函数 f(x) 满足:f(f(x)) = f(x),则函数 f(x) 满足幂等性。
这个概念被拓展到计算机领域,被用来描述一个操作、方法或者服务。一个幂等操作的特点是,其任意多次执行所产生的影响均与一次执行的影响相同。
实现的方式:在业务逻辑处理上,将消费的操作设计成幂等性操作。
幂等性操作设计
1. 利用数据库的唯一约束实现幂等
比如你要给你女朋友转账,那么保证只转一次呢?
可以在数据库建一张流水记录表,付款账户、收款账户、转账记录ID,这三个字段建立唯一约束,每次消费消息时,转账前先把转账记录写入流水表,写入成功才转账,失败就丢弃。这样就算重复消费,也可以保证只转账一次。
2. 为更新的数据设置前置条件
还是那个栗子,可以在消息发送的时候把:账户A给账户B转500,改为:如果账户A的余额是1000,账户B的余额是500,那么账户A就给账户B转500。但是这样有可能出现ABA问题,更好的解决思路:版本控制MVCC,给你的数据增加版本号,每次更新比较版本号,就可以实现。
3. 记录并检查操作
也称为“Token 机制或者 GUID(全局唯一 ID)机制”,实现的思路特别简单:在执行数据更新操作之前,先检查一下是否执行过这个更新操作。
具体的实现方法是,在发送消息时,给每条消息指定一个全局唯一的 ID,消费时,先根据这个 ID 检查这条消息是否有被消费过,如果没有消费过,才更新数据,然后将消费状态置为已消费。
消息积压
消息积压的直接原因,一定是系统中的某个部分出现了性能问题,来不及处理上游发送的消息,才会导致消息积压。
对于系统发生消息积压的情况,需要先解决积压,再分析原因,毕竟保证系统的可用性是首先要解决的问题。快速解决积压的方法就是通过水平扩容增加 Consumer 的实例数量。
优化性能来避免消息积压
在使用消息队列的系统中,对于性能的优化,主要体现在生产者和消费者这一收一发两部分的业务逻辑中。对于绝大多数使用消息队列的业务来说,消息队列本身的处理能力要远大于业务系统的处理能力。主流消息队列的单个节点,消息收发的性能可以达到每秒钟处理几万至几十万条消息的水平,还可以通过水平扩展 Broker 的实例数成倍地提升处理能力。一般的业务系统需要处理的业务逻辑远比消息队列要复杂,单个节点每秒钟可以处理几百到几千次请求,已经可以算是性能非常好的了。所以,对于消息队列的性能优化,我们更关注的是,在消息的收发两端,我们的业务代码怎么和消息队列配合,达到一个最佳的性能。
1. 发送端性能优化
如果说,你的代码发送消息的性能上不去,你需要优先检查一下,是不是发消息之前的业务逻辑耗时太多导致的
对于发送消息的业务逻辑,只需要注意设置合适的并发和批量大小,就可以达到很好的发送性能。
2. 消费端性能优化
使用消息队列的时候,大部分的性能问题都出现在消费端,如果消费的速度跟不上发送端生产消息的速度,就会造成消息积压。如果这种性能倒挂的问题只是暂时的,那问题不大,只要消费端的性能恢复之后,超过发送端的性能,那积压的消息是可以逐渐被消化掉的。
在设计系统的时候,一定要保证消费端的消费性能要高于生产端的发送性能,这样的系统才能健康的持续运行。
消费端的性能优化除了优化消费业务逻辑以外,也可以通过水平扩容,增加消费端的并发数来提升总体的消费性能。特别需要注意的一点是,在扩容 Consumer 的实例数量的同时,必须同步扩容主题中的分区(也叫队列)数量,确保 Consumer 的实例数和分区数量是相等的。如果 Consumer 的实例数量超过分区数量,这样的扩容实际上是没有效果的。原因我们之前讲过,因为对于消费者来说,在每个分区上实际上只能支持单线程消费。
但是注意不要通过这种方法:
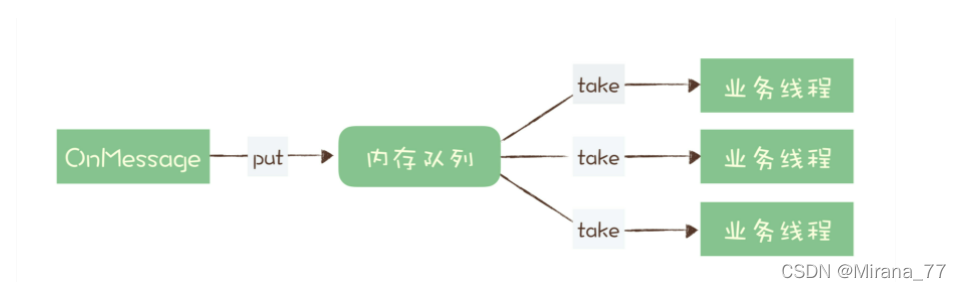
为了避免消息积压,在收到消息的 OnMessage 方法中,不处理任何业务逻辑,把这个消息放到一个内存队列里面就返回了。然后它可以启动很多的业务线程,这些业务线程里面是真正处理消息的业务逻辑,这些线程从内存队列里取消息处理,这样它就解决了单个 Consumer 不能并行消费的问题。
如果收消息的节点发生宕机,在内存队列中还没来及处理的这些消息就会丢失。
消息积压了该如何处理?
能导致积压突然增加,最粗粒度的原因,只有两种:要么是发送变快了,要么是消费变慢了。
大部分消息队列都内置了监控的功能,只要通过监控数据,很容易确定是哪种原因。如果是单位时间发送的消息增多,比如说是赶上大促或者抢购,短时间内不太可能优化消费端的代码来提升消费性能,唯一的方法是通过扩容消费端的实例数来提升总体的消费能力
如果短时间内没有足够的服务器资源进行扩容,没办法的办法是,将系统降级,通过关闭一些不重要的业务,减少发送方发送的数据量,最低限度让系统还能正常运转,服务一些重要业务。
还有一种不太常见的情况,你通过监控发现,无论是发送消息的速度还是消费消息的速度和原来都没什么变化,这时候你需要检查一下你的消费端,是不是消费失败导致的一条消息反复消费这种情况比较多,这种情况也会拖慢整个系统的消费速度。
如果监控到消费变慢了,你需要检查你的消费实例,分析一下是什么原因导致消费变慢。优先检查一下日志是否有大量的消费错误,如果没有错误的话,可以通过打印堆栈信息,看一下你的消费线程是不是卡在什么地方不动了,比如触发了死锁或者卡在等待某些资源上了。
选择合适的消息队列
我们听过一句话:“没有银弹”。为什么这么说呢,因为在软件开发中,不存在像“银弹”这样可以解决一切问题的设计、架构或软件,每一个软件系统,它要做的事情、解决的需求都是不同的,它都是独一无二的,你不可能用一套方法去解决所有的问题。在消息队列的技术选型这个问题上,我们要结合自己实际需求,根据系统的现有情况,选择最适合自己的。
通常挑选产品有几个标准:
- 必须是开源的产品,如果你真的碰到了一个对你系统影响非常大的bug,还有机会修改源码来解决,而不是傻等开发者发版本
- 这个产品必须是近年来比较流行并且有一定社区活跃度的产品,这有只要你使用的场景不是特别冷门,遇到bug的概率会非常的低(会有人帮你踩过坑)
- 流行的产品与周边生态系统会有一个比较好的集成和兼容
作为一款及格的消息队列产品,还必须具备的几个特性包括:
- 消息的可靠传递:确保不丢消息;
- Cluster:支持集群,确保不会因为某个节点宕机导致服务不可用,当然也不能丢消息;
- 性能:具备足够好的性能,能满足绝大多数场景的性能要求。
可供选择的开源消息队列产品
RabbitMQ
RabbitMQ 是使用一种比较小众的编程语言:Erlang 语言编写的,它最早是为电信行业系统之间的可靠通信设计 的,也是少数几个支持 AMQP 协议的消息队列之一。
我们先看下官网的介绍:
Messaging that just works——RabbitMQ is the most widely deployed open source message broker.
With tens of thousands of users, RabbitMQ is one of the most popular open source message brokers. From T-Mobile to Runtastic, RabbitMQ is used worldwide at small startups and large enterprises.
RabbitMQ is lightweight and easy to deploy on premises and in the cloud. It supports multiple messaging protocols. RabbitMQ can be deployed in distributed and federated configurations to meet high-scale, high-availability requirements.
RabbitMQ runs on many operating systems and cloud environments, and provides a wide range of developer tools for most popular languages.
Messaging that just works,“开箱即用的消息队列”。也就是说,RabbitMQ 是一个相当轻量级的消息队列,非常容易部署和使用。
RabbitMQ 的几个问题
-
第一个问题是,RabbitMQ 对消息堆积的支持并不好,在它的设计理念里面,消息队列是 一个管道,大量的消息积压是一种不正常的情况,应当尽量去避免。当大量消息积压的时候,会导致 RabbitMQ 的性能急剧下降
-
第二个问题是,RabbitMQ 的性能是我们介绍的这几个消息队列中最差的,根据官方给出 的测试数据综合我们日常使用的经验,依据硬件配置的不同,它大概每秒钟可以处理几万到 十几万条消息。其实,这个性能也足够支撑绝大多数的应用场景了,不过,如果你的应用对消息队列的性能要求非常高,那不要选择 RabbitMQ
-
最后一个问题是 RabbitMQ 使用的编程语言 Erlang,这个编程语言不仅是非常小众的语言,更麻烦的是,这个语言的学习曲线非常陡峭。大多数流行的编程语言,比如 Java、 C/C++、Python 和 JavaScript,虽然语法、特性有很多的不同,但它们基本的体系结构都 是一样的,你只精通一种语言,也很容易学习其他的语言,短时间内即使做不到精通,但至 少能达到“会用”的水平
RocketMQ
RocketMQ 是阿里巴巴在 2012 年开源的消息队列产品,后来捐赠给 Apache 软件基金 会,2017 正式毕业,成为 Apache 的顶级项目。阿里内部也是使用 RocketMQ 作为支撑 其业务的消息队列,经历过多次“双十一”考验,它的性能、稳定性和可靠性都是值得信赖 的。作为优秀的国产消息队列,近年来越来越多的被国内众多大厂使用
官网介绍:
Apache RocketMQ™ is a unified messaging engine, lightweight data processing platform
Low Latency:More than 99.6% response latency within 1 millisecond under high pressure.
Finance Oriented:High availability with tracking and auditing features.
Industry Sustainable:Trillion-level message capacity guaranteed.
Vendor Neutral:A new open distributed messaging and streaming standard since latest 4.1 version.
BigData Friendly:Batch transferring with versatile integration for flooding throughput.
Massive Accumulation:Given sufficient disk space, accumulate messages without performance loss.
根据官网描述,它有几个特点:低延迟、面向金融、行业可持续性、供应商中立、量大数据(BigData ,我实在找不到合适的词描述)友好、可积压消息。事实上,RocketMQ 对在线业务的响应时延做了很多的优化,大多数情况下可以做到毫秒级的响应,如果你的应用场景很在意响应时延,那应该选择使用 RocketMQ。但是它也有一个缺点:作为国产的消息队列,相比国外的比较流行的同类产品,在国 际上还没有那么流行,与周边生态系统的集成和兼容程度要略逊一筹。
Kafka
Kafka 最早是由 LinkedIn 开发,目前也是 Apache 的顶级项目。 Kafka 最初的设计目的是用于处理海量的日志。Kafka 与周边生态系统的兼容性是最好的没有之一,尤其在大数据和流计算领域,几乎所 有的相关开源软件系统都会优先支持 Kafka。
它的官网描述:
APACHE KAFKA
More than 80% of all Fortune 100 companies trust, and use Kafka.
Apache Kafka is an open-source distributed event streaming platform used by thousands of companies for high-performance data pipelines, streaming analytics, data integration, and mission-critical applications.
可以看到kafka对自己的定位是: open-source distributed event streaming platform,开源的分布式消息引擎系统。它的格局就大了一点啊,它不仅仅是消息队列,它在大数据领域的场景更友好。
Kafka 使用 Scala 和 Java 语言开发,设计上大量使用了批量和异步的思想,这种设计使得 Kafka 能做到超高的性能。Kafka 的性能,尤其是异步收发的性能,是三者中最好的,但与 RocketMQ 并没有量级上的差异,大约每秒钟可以处理几十万条消息。
但是 Kafka 这种异步批量的设计带来的问题是,它的同步收发消息的响应时延比较高,因为当客户端发送一条消息的时候,Kafka 并不会立即发送出去,而是要等一会儿攒一批再发送,在它的Broker 中,很多地方都会使用这种“先攒一波再一起处理”的设计。当你的业务场景中,每秒钟消息数量没有那么多的时候,Kafka的时延反而会比较高。所以,Kafka 不太适合在线业务场景。
消息队列的应用
消息队列是工具,它已经告诉了我们它的特点,那什么场景下用适合用消息队列?
举个秒杀の栗子
在面试中,应该都问过或被问过一个经典却没有标准答案的问题:如何设计一个秒杀系统?这个问题可以有一百个版本的合理答案,但大多数答案中都离不开消息队列。秒杀系统需要解决的核心问题是,如何利用有限的服务器资源,尽可能多地处理短时间内的海量请求。我们知道,处理一个秒杀请求包含了很多步骤,例如:
- 风险控制;
- 库存锁定;
- 生成订单;
- 短信通知;
- 更新统计数据。
如果没有任何优化,正常的处理流程是:App 将请求发送给网关,依次调用上述 5 个流程,然后将结果返回给 APP。
流量控制
秒杀这个场景,我们就面临一个很严肃的问题:如何避免过多的请求压垮我们的秒杀系统?秒杀的时间一到,瞬间会有很多请求,作为一个用户,你肯定不希望在疯狂点下单的时候看到——程序已崩溃。很不幸,在最早2015年的双十一的时候,我就遇到过。体验真的无比的差。所以后面的双十一,就看不到程序已崩溃了,要么是说你访问太频繁让你验证,或者提交后让你等待,其实本质上都是限流。
一个设计健壮的程序有自我保护的能力,也就是说,它应该可以在海量的请求下,还能在自身能力范围内尽可能多地处理请求,拒绝处理不了的请求并且保证自身运行正常。不幸的是,现实中很多程序并没有那么“健壮”,而直接拒绝请求返回错误对于用户来说也是不怎么好的体验。
因此,我们需要设计一套足够健壮的架构来将后端的服务保护起来。我们的设计思路是,使用消息队列隔离网关和后端服务,以达到流量控制和保护后端服务的目的。
加入消息队列后,整个秒杀流程变为:
- 网关在收到请求后,将请求放入请求消息队列;
- 后端服务从请求消息队列中获取 APP 请求,完成后续秒杀处理过程,然后返回结果。
秒杀开始后,当短时间内大量的秒杀请求到达网关时,不会直接冲击到后端的秒杀服务,而是先堆积在消息队列中,后端服务按照自己的最大处理能力,从消息队列中消费请求进行处理。
对于超时的请求可以直接丢弃,APP 将超时无响应的请求处理为秒杀失败即可。运维人员还可以随时增加秒杀服务的实例数量进行水平扩容,而不用对系统的其他部分做任何更改。
这种设计的优点是:能根据下游的处理能力自动调节流量,达到“削峰填谷”的作用。但这样做同样是有代价的:
- 增加了系统调用链环节,导致总体的响应时延变长。
- 上下游系统都要将同步调用改为异步消息,增加了系统的复杂度。
那还有没有更简单一点儿的流量控制方法呢?如果我们能预估出秒杀服务的处理能力,就可以用消息队列实现一个令牌桶,更简单地进行流量控制。
令牌桶控制流量的原理是:单位时间内只发放固定数量的令牌到令牌桶中,规定服务在处理请求之前必须先从令牌桶中拿出一个令牌,如果令牌桶中没有令牌,则拒绝请求。这样就保证单位时间内,能处理的请求不超过发放令牌的数量,起到了流量控制的作用。
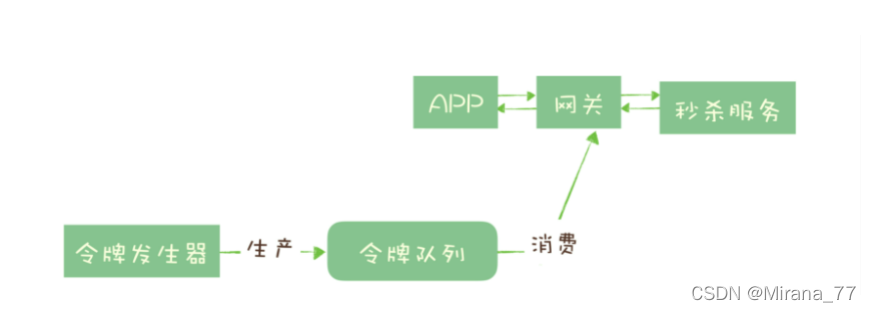
实现的方式也很简单,不需要破坏原有的调用链,只要网关在处理 APP 请求时增加一个获取令牌的逻辑。
令牌桶可以简单地用一个有固定容量的消息队列加一个“令牌发生器”来实现:令牌发生器按照预估的处理能力,匀速生产令牌并放入令牌队列(如果队列满了则丢弃令牌),网关在收到请求时去令牌队列消费一个令牌,获取到令牌则继续调用后端秒杀服务,如果获取不到令牌则直接返回秒杀失败。
后续会对限流处理做专门总结,所以这里只简单介绍下令牌桶用消息队列的实现方式。
异步处理
对于秒杀这 5 个步骤来说,能否决定秒杀成功,实际上只有风险控制和库存锁定这 2 个步骤。识别出核心步骤后,只要核心步骤成功,就可以给用户返回秒杀结果了,对于后续的生成订单、短信通知和更新统计数据等步骤,并不一定要在秒杀请求中处理完成。
所以当服务端完成前面 2 个步骤,确定本次请求的秒杀结果后,就可以马上给用户返回响应,然后把请求的数据放入消息队列中,由消息队列异步地进行后续的操作。
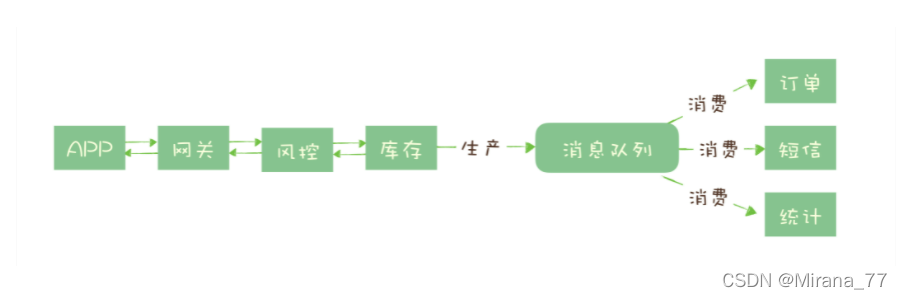
处理一个秒杀请求,从 5 个步骤减少为 2 个步骤,这样不仅响应速度更快,并且在秒杀期间,我们可以把大量的服务器资源用来处理秒杀请求。秒杀结束后再把资源用于处理后面的步骤,充分利用有限的服务器资源处理更多的秒杀请求。
可以看到,在这个场景中,消息队列被用于实现服务的异步处理。这样做的好处是:
- 可以更快地返回结果;
- 减少等待,自然实现了步骤之间的并发,提升系统总体的性能。
服务解耦
消息队列的另外一个作用,就是实现系统应用之间的解耦。就好比最开始举得栗子:快递小哥跟收件人。
其余
当然,消息队列的适用范围不仅仅局限于这些场景,还有包括:
- 作为发布 / 订阅系统实现一个微服务级系统间的观察者模式;
- 连接流计算任务和数据;
- 用于将消息广播给大量接收者。
同时我们也要认识到,消息队列也有它自身的一些问题和局限性,包括:
- 引入消息队列带来的延迟问题;
- 增加了系统的复杂度;
- 可能产生数据不一致的问题。
FAQ
1.mq和rpc的区别
Q:mq和rpc的区别
A:往大了说属于数据流模式(dataflow mode)的问题。我们常见的数据流有三种:
- 通过数据库;
- 通过服务调用(REST/RPC);
- 通过异步消息传递(消息引擎,如 Kafka)
RPC和MQ是有相似之处的,毕竟我们远程调用一个服务也可以看做是一个事件,但不同之处在 于:
-
MQ有自己的buffer,能够对抗过载(overloaded)和不可用场景
-
MQ支持重试
-
允许发布/订阅模式当然它们还有其他区别。
应该这样说RPC是介于通过数据库和通过MQ之间的数据流模式。