(Spark3.2.0)Spark SQL 初探: 使用大数据分析2000万KF数据
(Spark3.2.0)Spark SQL 初探: 使用大数据分析2000万KF数据
一、测试环境:
本地单机版本Spark3.2.0
处理器:2.3 GHz 四核Intel Core i5
内存:8 GB 2133 MHz LPDDR3。
二、数据来源:
你可以写个随机程序生成2000W的kaifang测试数据, 以CSV格式
使用数据纯属编造。
三、本次实验目的:
使用Spark SQL按照星座对2000WKF数据进行分组统计,
看看哪个星座的人最喜欢KaiFang(实验数据结论是摩羯座)
其中男女比例大概为2:1。
使用纯Spark也可以完成相关的分析,
因为实际Spark SQL最终是利用Spark来完成的。
实际测试中发现这些数据并不是完全遵守一个schema,
有些数据的格式是不对的,
有些数据的数据项也是错误的。
在代码中要剔除那么干扰数据。
用这个数据测试并没有严格的要求去整理哪些错误数据。
四、实验过程
4.1使用SparkSession代替SaprkContext
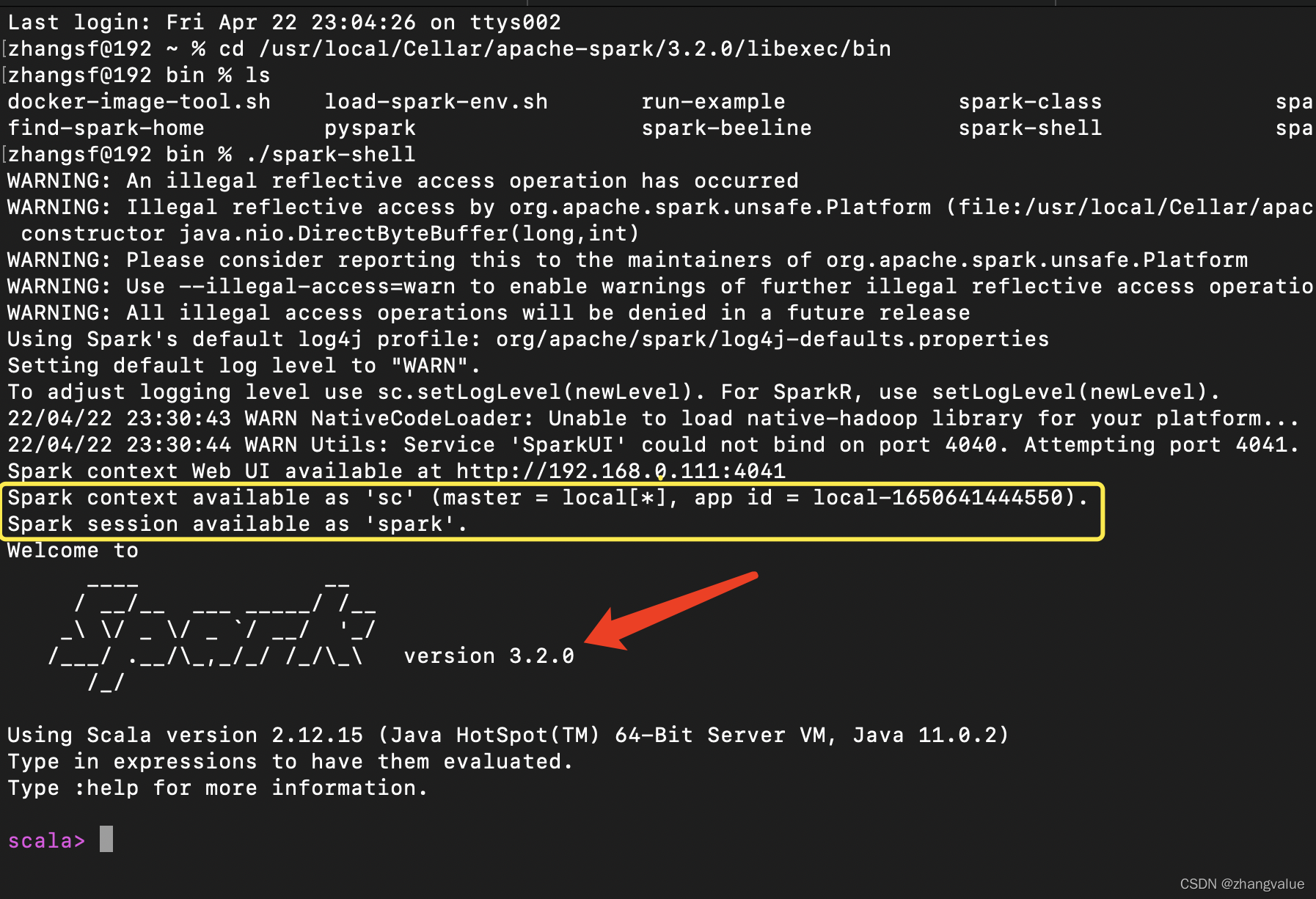
4.2导入SparkSession依赖包
import org.apache.spark.sql.SparkSession
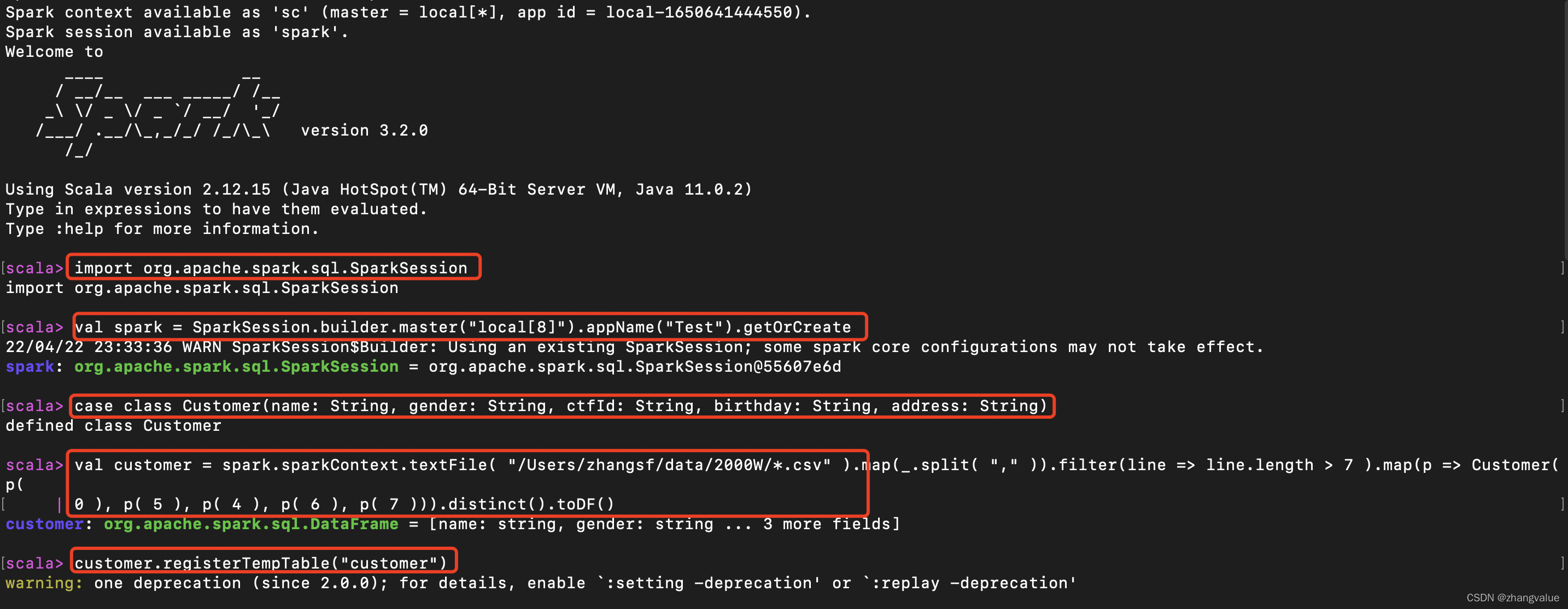
4.3创建 SparkSession 实例 - 入口
val spark = SparkSession.builder.master("local[8]").appName("Test").getOrCreate
4.4定义用户类
case class Customer(name: String, gender: String, ctfId: String, birthday: String, address: String)
4.5读取文件,构造 RDD
val customer = spark.sparkContext.textFile( "/data/2000W/*.csv" ).map(_.split( "," )).filter(line => line.length > 7 ).map(p => Customer(p(
0 ), p( 5 ), p( 4 ), p( 6 ), p( 7 ))).distinct().toDF()
4.6注册临时表
customer.registerTempTable("customer")
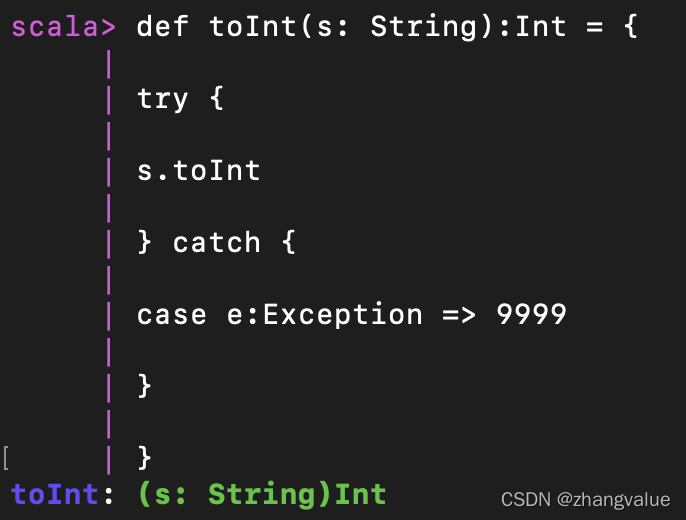
4.7创建一个函数用于将String类型转为Int类型
def toInt(s: String):Int = {
try {
s.toInt
} catch {
case e:Exception => 9999
}
}
4.8定义一个函数用于判断识别用户星座
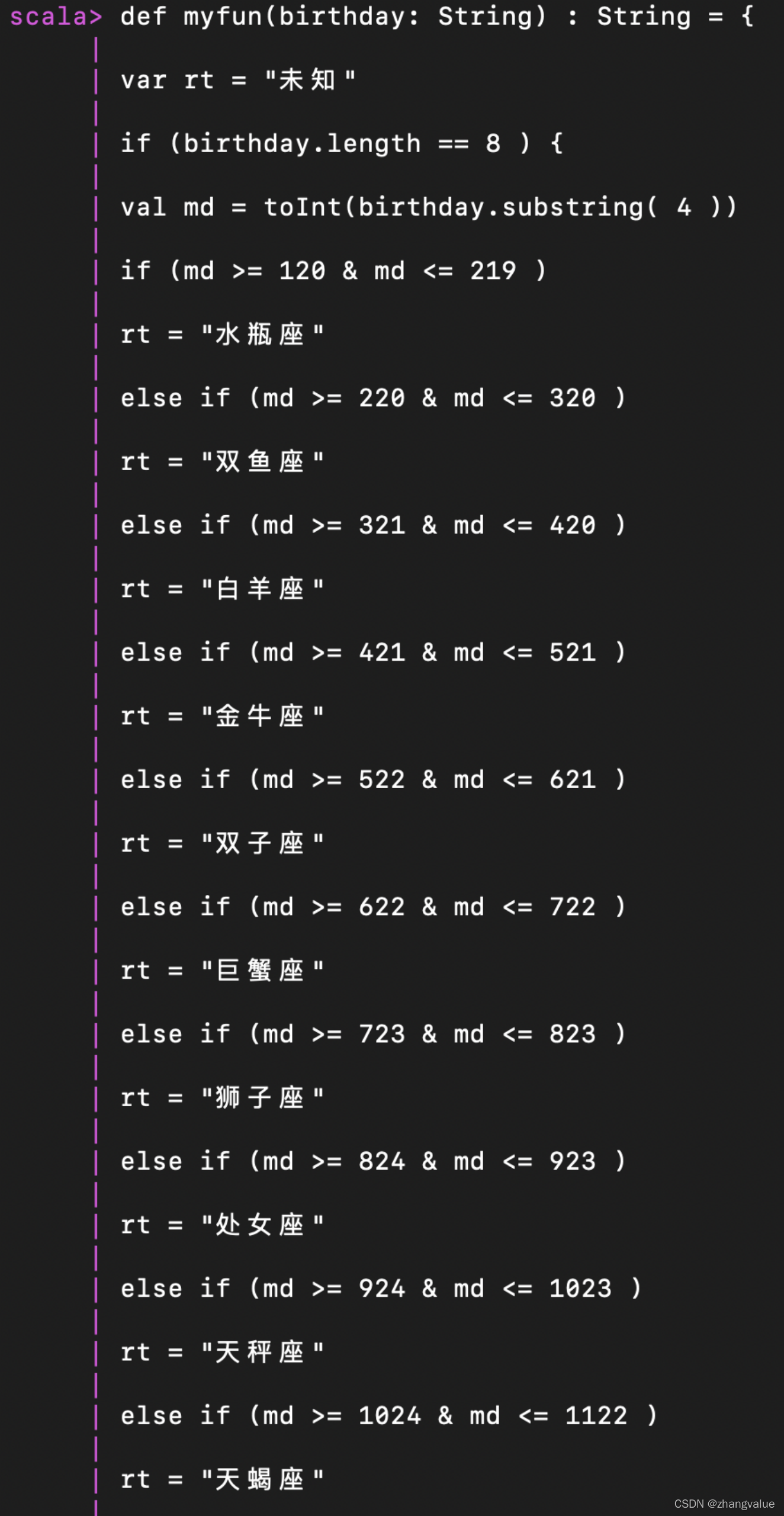
def myfun(birthday: String) : String = {
var rt = "未知"
if (birthday.length == 8 ) {
val md = toInt(birthday.substring( 4 )
if (md >= 120 & md <= 219 )
rt = "水瓶座
else if (md >= 220 & md <= 320 )
rt = "双鱼
else if (md >= 321 & md <= 420 )
rt = "白羊座"
else if (md >= 421 & md <= 521 )
rt = "金牛座"
else if (md >= 522 & md <= 621 )
rt = "双子座"
else if (md >= 622 & md <= 722 )
rt = "巨蟹座"
else if (md >= 723 & md <= 823 )
rt = "狮子座"
else if (md >= 824 & md <= 923 )
rt = "处女座"
else if (md >= 924 & md <= 1023 )
rt = "天秤座"
else if (md >= 1024 & md <= 1122 )
rt = "天蝎座"
else if (md >= 1123 & md <= 1222 )
rt = "射手座"
else if ((md >= 1223 & md <= 1231 ) | (md >= 101 & md <= 119 ))
rt = "摩蝎座"
else
rt = "未知"
}
rt
}
4.9注册为UDF
spark.udf.register("constellation" , (x:String) => myfun(x))
4.10使用Spark sql进行查询用户的星座
var result = spark.sql( "SELECT constellation(birthday), count(constellation(birthday)) FROM customer group by constellation(birthday)" )
4.11将结果进行collect并打印
result.collect().foreach(println)
4.12使用Spark sql进行查询KF用户的性别
var GenderResult = spark.sql( "SELECT gender, count(gender) FROM customer where gender = 'F' or gender = 'M' group by gender")
4.13将结果进行collect并打印
GenderResult.collect().foreach(println)
五、具体截图如下:
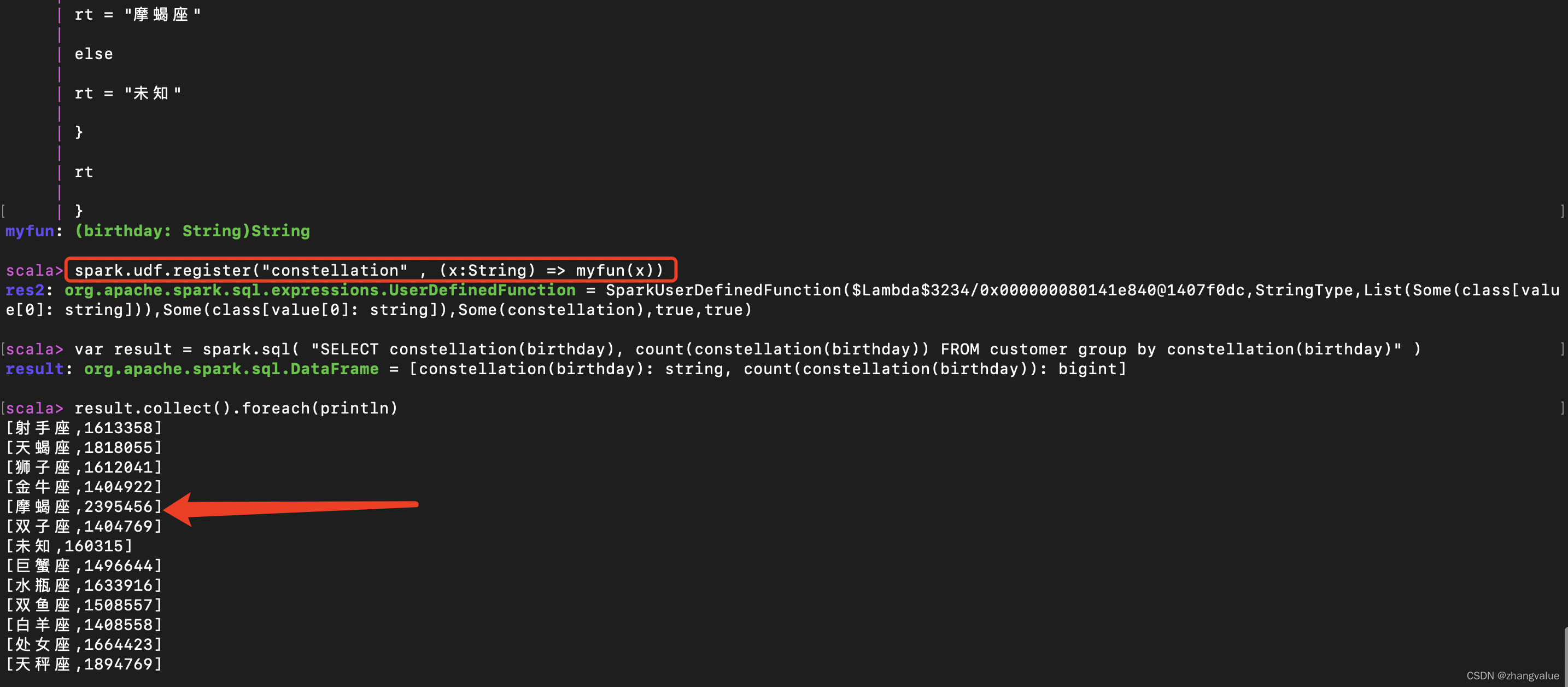

六实验结论:
魔蝎座的人最喜欢KF了, 明显比其它星座的人要多。且男女KF的人数大约是2:1。
七具体代码:
// 导入依赖包
import org.apache.spark.sql.SparkSession
// 创建 SparkSession 实例 - 入口
val spark = SparkSession.builder.master("local[8]").appName("Test").getOrCreate
//定义用户类
case class Customer(name: String, gender: String, ctfId: String, birthday: String, address: String)
// 读取文件,构造 RDD
val customer = spark.sparkContext.textFile( "/Users/zhangsf/data/2000W/*.csv" ).map(_.split( "," )).filter(line => line.length > 7 ).map(p => Customer(p(
0 ), p( 5 ), p( 4 ), p( 6 ), p( 7 ))).distinct().toDF()
//注册临时表
customer.registerTempTable("customer")
//创建一个函数用于将String类型转为Int类型
def toInt(s: String):Int = {
try {
s.toInt
} catch {
case e:Exception => 9999
}
}
//定义一个函数用于判断识别用户星座
def myfun(birthday: String) : String = {
var rt = "未知"
if (birthday.length == 8 ) {
val md = toInt(birthday.substring( 4 )
if (md >= 120 & md <= 219 )
rt = "水瓶座
else if (md >= 220 & md <= 320 )
rt = "双鱼
else if (md >= 321 & md <= 420 )
rt = "白羊座"
else if (md >= 421 & md <= 521 )
rt = "金牛座"
else if (md >= 522 & md <= 621 )
rt = "双子座"
else if (md >= 622 & md <= 722 )
rt = "巨蟹座"
else if (md >= 723 & md <= 823 )
rt = "狮子座"
else if (md >= 824 & md <= 923 )
rt = "处女座"
else if (md >= 924 & md <= 1023 )
rt = "天秤座"
else if (md >= 1024 & md <= 1122 )
rt = "天蝎座"
else if (md >= 1123 & md <= 1222 )
rt = "射手座"
else if ((md >= 1223 & md <= 1231 ) | (md >= 101 & md <= 119 ))
rt = "摩蝎座"
else
rt = "未知"
}
rt
}
//注册为UDF
spark.udf.register("constellation" , (x:String) => myfun(x))
//使用Spark sql进行查询用户的星座
var result = spark.sql( "SELECT constellation(birthday), count(constellation(birthday)) FROM customer group by constellation(birthday)" )
//将结果进行collect并打印
result.collect().foreach(println)
//使用Spark sql进行查询KF用户的性别
var GenderResult = spark.sql( "SELECT gender, count(gender) FROM customer where gender = 'F' or gender = 'M' group by gender")
//将结果进行collect并打印
GenderResult.collect().foreach(println)