2019独角兽企业重金招聘Python工程师标准>>> 
一、找3台Linux机器,或者Ubuntu虚拟机
二、修改主机名
执行命令 : sudo vim /etc/hostname
假设3台机器分别叫做,
vm-007 作为master
vm-008 作为slave
vm-009 作为slave
三、修改Hosts
执行命令:sudo vi /etc/hosts
3台机器都得修改
192.168.132.128 vm-007
192.168.132.129 vm-008
192.168.132.130 vm-009
四、重启机器
ping vm-007 ,ping vm-008,ping vm-009 能Ping通则没问题
五、配置无密码访问SSH
在3台机器上,执行命令:
sudo apt-get install ssh 安装好SSH
ssh-keygen 一直 Enter Enter... 会在当前用户的文件夹中生成一个.ssh文件夹
cd .ssh
在vm-007 执行命令:cp id_rsa.pub authorized_keys
在vm-008,vm-009 执行命令:
scp id_rsa.pub lwj@vm-007:/home/lwj/.ssh/id_rsa.pub.vm-008
scp id_rsa.pub lwj@vm-007:/home/lwj/.ssh/id_rsa.pub.vm-009
在vm-007执行命令:
cat d_rsa.pub.vm-008 >> authorized_keys
cat id_rsa.pub.vm-009 >> authorized_keys
vm-008,vm-009的公钥追加到vm-007的authorized_keys文件中,这样的话vm-007,就拥有了3台机器的公钥
执行命令:
scp authorized_keys lwj@vm-008:/home/lwj/.ssh/
scp authorized_keys lwj@vm-009:/home/lwj/.ssh/
在vm-007上执行
ssh vm-008,ssh vm-009 如果不需要输入密码,则表示成功。
这个环节也是很有必要的:在每台机器上执行,ssh localhost
五,配置环境变量
执行命令:
sudo vim .bashrc 或者 sudo vim /etc/profile
export JAVA_HOME=/opt/software/jdk1.7.0_80
export CLASSPATH=$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:.
#Hadoop 配置
export HADOOP_PREFIX="/opt/software/hadoop-2.6.5"
export HADOOP_MAPRED_HOME=$HADOOP_PREFIX
export HADOOP_COMMON_HOME=$HADOOP_PREFIX
export HADOOP_HOME=$HADOOP_PREFIX
export HADOOP_HDFS_HOME=$HADOOP_PREFIX
export HADOOP_CONF_DIR=$HADOOP_PREFIX/etc/hadoop
export YARN_CONF_DIR=$HADOOP_PREFIX/etc/hadoop
export YARN_HOME=$HADOOP_PREFIX
export PATH=$JAVA_HOME/bin:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin:$PATH
六、配置 /opt/software/hadoop-2.6.5/etc/hadoop 下的文件
6.1 修改 hadoop-env.sh
export JAVA_HOME=/opt/software/jdk1.7.0_80
export HADOOP_HOME=/opt/software/hadoop-2.6.5
6.2 修改 core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>/disk/hadoop/tempdir</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://vm-007:9000</value>
</property>
<!--Enabling Trash-->
<!--fs.trash.interval:意思是在这个1440分钟的回收周期范围之内,文件不会被马上删除,
而是暂时被移动到了trash的目录下面,等时间到了才会被真正的删除。当执行./bin/hadoop fs -rm -r /xxx 的时候,能
看见他是暂时被移动到了某个地方。可以试一试。-->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>1440</value>
</property>
<!--注意:和压缩有关系,如果没有安装Snappy,就不要启动整个参数。-->
<property>
<name>io.compression.codecs</name>
<value>
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.SnappyCodec
</value>
</property>6.3 修改 hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!--这个参数可以避免Permission denied: user=root, access=WRITE, inode="":hduser:supergroup:rwxr-xr-x
这个错误。注意,如果想让这个参数生效,需要重启启动集群。我就是在重新启动集群的情况下尝试成功的。-->
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>6.4 修改 mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--Map Task的输出被写出到本地磁盘,
而且需要通过网络传输至Reduce Task的节点,
只要简单地使用一个快速的压缩算法(如LZO、LZ4、Snappy)就可以带来性能的提升,
因为压缩机制的使用避免了Map Tasks与Reduce Tasks之间大量中间结果数据被传输。
可以通过设置相应的Job配置属性开启:..如果说是Snappy没有安装,就不要设置整个属性。
记住Snappy需要单独安装-->
<property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
6.5 修改 yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>vm-007</value>
</property>6.6 修改 slaves
vm-007
vm-008
vm-009
6.7 把修改过的配置文件scp到vm-008,vm-009
scp hadoop-env.sh core-site.xml mapred-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml slaves vm-008:/opt/software/hadoop-2.6.5/etc/hadoop/
scp hadoop-env.sh core-site.xml mapred-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml slaves vm-009:/opt/software/hadoop-2.6.5/etc/hadoop/
6.8 启动Hadoop
到Haoop安装目录下
执行命令:
hdfs namenode –format
这叫格式化NameNode
执行命令:
./sbin/start-all.sh
6.8.1 启动的进程
vim-007启动的进程
3936 NodeManager
3648 ResourceManager
3516 SecondaryNameNode
5011 Jps
3213 NameNode
3320 DataNode
vim-008 vim-009 启动的进程
4913 DataNode
5563 Jps
5027 NodeManager
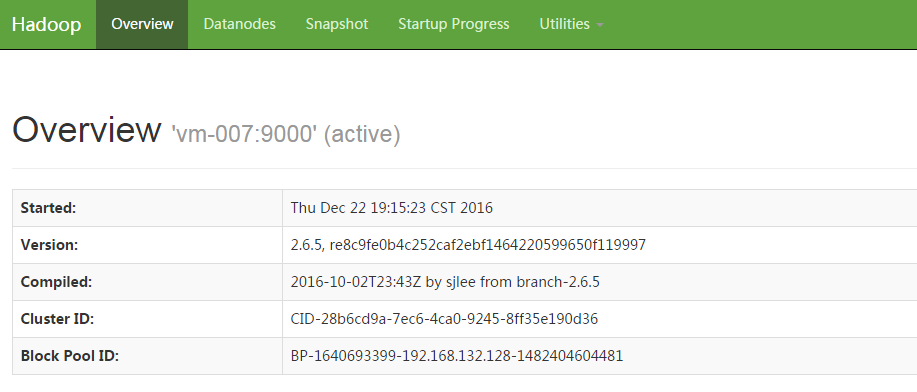
6.8.2 HDFS页面
http://vm-007:50070/dfshealth.html#tab-overview
6.8.3 HDFS上传文件
执行命令:./bin/hadoop fs -mkdir /data 新建一个data目录
执行命令:./bin/hadoop fs -put a.txt /data/ 将a.txt上传到HDFS
执行命令:lwj@vm-007:/opt/software/hadoop-2.6.5$ ./bin/hadoop fs -ls /
Found 2 items
drwxr-xr-x - lwj supergroup 0 2016-12-22 19:28 /data
drwx------ - lwj supergroup 0 2016-12-22 19:28 /tmp
执行命令:lwj@vm-007:/opt/software/hadoop-2.6.5$ ./bin/hadoop fs -cat /data/a.txt
a
a
b
b
c
c
a
a
6.8.4 任务监控页面
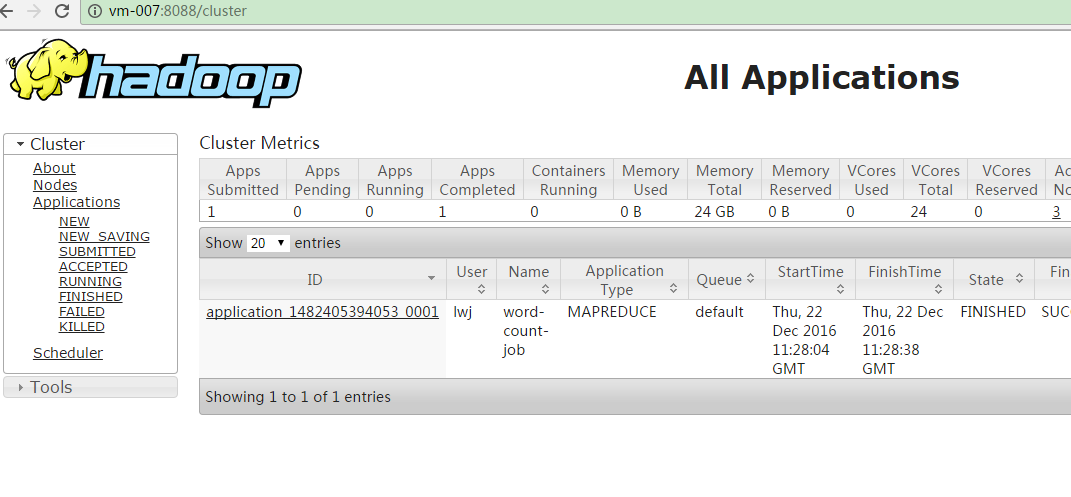
6.8.5 编写一个简单的统计单词任务在集群上执行
执行命令:lwj@vm-007:/opt/software/hadoop-2.6.5$ ./bin/yarn jar /opt/software/hadoop-2.6.5/bvc-test-0.0.0.jar com.blueview.hadoop.mr.WordCount /data/a.txt /data/word_count
inputPath: /data/a.txt
outputpath: /data/word_count
16/12/22 20:51:51 INFO client.RMProxy: Connecting to ResourceManager at vm-007/192.168.132.128:8032
16/12/22 20:51:52 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
16/12/22 20:51:53 INFO input.FileInputFormat: Total input paths to process : 1
16/12/22 20:51:53 INFO mapreduce.JobSubmitter: number of splits:1
16/12/22 20:51:54 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1482405394053_0003
16/12/22 20:51:54 INFO impl.YarnClientImpl: Submitted application application_1482405394053_0003
16/12/22 20:51:54 INFO mapreduce.Job: The url to track the job: http://vm-007:8088/proxy/application_1482405394053_0003/
16/12/22 20:51:54 INFO mapreduce.Job: Running job: job_1482405394053_0003
16/12/22 20:52:04 INFO mapreduce.Job: Job job_1482405394053_0003 running in uber mode : false
16/12/22 20:52:04 INFO mapreduce.Job: map 0% reduce 0%
16/12/22 20:52:12 INFO mapreduce.Job: map 100% reduce 0%
16/12/22 20:52:22 INFO mapreduce.Job: map 100% reduce 100%
16/12/22 20:52:22 INFO mapreduce.Job: Job job_1482405394053_0003 completed successfully
16/12/22 20:52:23 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=70
FILE: Number of bytes written=215415
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=110
HDFS: Number of bytes written=12
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=5664
Total time spent by all reduces in occupied slots (ms)=6487
Total time spent by all map tasks (ms)=5664
Total time spent by all reduce tasks (ms)=6487
Total vcore-milliseconds taken by all map tasks=5664
Total vcore-milliseconds taken by all reduce tasks=6487
Total megabyte-milliseconds taken by all map tasks=5799936
Total megabyte-milliseconds taken by all reduce tasks=6642688
Map-Reduce Framework
Map input records=8
Map output records=8
Map output bytes=48
Map output materialized bytes=70
Input split bytes=94
Combine input records=0
Combine output records=0
Reduce input groups=3
Reduce shuffle bytes=70
Reduce input records=8
Reduce output records=3
Spilled Records=16
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=176
CPU time spent (ms)=1810
Physical memory (bytes) snapshot=315183104
Virtual memory (bytes) snapshot=1355341824
Total committed heap usage (bytes)=135860224
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=16
File Output Format Counters
Bytes Written=12
任务提交成功!
花费时间:34077ms
执行命令:lwj@vm-007:/opt/software/hadoop-2.6.5$ ./bin/hadoop fs -cat /data/word_count/part-r-00000
a 4
b 2
c 2
说明:我也是参考了推酷的这篇文章
http://www.tuicool.com/articles/BRVjiq