亲密接触Redis-第二天(Redis Sentinel)
简介
经过上次轻松搭建了一个Redis的环境并用Java代码调通后,这次我们要来看看Redis的一些坑以及Redis2.8以后带来的一个新的特性即支持高可用特性功能的Sentinel(哨兵)。
Redis的一些坑
Redis是一个很优秀的NoSql,它支持键值对,查询方便,被大量应用在Internet的应用中,它即可以用作Http Session的分离如上一次举例中的和Spring Session的结合,还可以直接配置在Tomcat中和Tomcat容器结合并可以自动使用Redis作Session盛载器,同时它也可以作为一个分布式缓存。
Redis是单线程工作的
这边的单线程不是指它就是顺序式工作的,这边的单线程主要关注的是Redis的一个很重要的功能即“持久化”工作机制。Redis一般会使用两种持久化工作机制,这种工作机制如果在单个Redis Node下工作是没有意义的,因此你必须要有两个Redis Nodes,如:
| IP | 端口 | 身份 |
| 192.168.56.101 | 7001 | 主节点 |
| 192.168.56.101 | 7002 | 备节点 |
- RDB模式
- AOF模式
RDB
RDB 是一个非常紧凑(compact)的文件,它保存了 Redis 在某个时间点上的数据集。 这种文件非常适合用于进行备份: 比如说,你可以在最近的 24 小时内,每小时备份一次 RDB 文件,并且在每个月的每一天,也备份一个 RDB 文件。 这样的话,即使遇上问题,也可以随时将数据集还原到不同的版本。RDB 非常适用于灾难恢复(disaster recovery):它只有一个文件,并且内容都非常紧凑,可以(在加密后)将它传送到别的数据中心,或者亚马逊 S3 中。RDB 可以最大化 Redis 的性能:父进程在保存 RDB 文件时唯一要做的就是 fork 出一个子进程,然后这个子进程就会处理接下来的所有保存工作,父进程无须执行任何磁盘 I/O 操作。RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
RDB 的缺点:
如果你需要尽量避免在服务器故障时丢失数据,那么 RDB 不适合你。 虽然 Redis 允许你设置不同的保存点(save point)来控制保存 RDB 文件的频率, 但是, 因为RDB 文件需要保存整个数据集的状态, 所以它并不是一个轻松的操作。 因此你可能会至少 5 分钟才保存一次 RDB 文件。 在这种情况下, 一旦发生故障停机, 你就可能会丢失好几分钟的数据。每次保存 RDB 的时候,Redis 都要 fork() 出一个子进程,并由子进程来进行实际的持久化工作。 在数据集比较庞大时, fork() 可能会非常耗时,造成服务器在某某毫秒内停止处理客户端; 如果数据集非常巨大,并且 CPU 时间非常紧张的话,那么这种停止时间甚至可能会长达整整一秒。 虽然 AOF 重写也需要进行 fork() ,但无论 AOF 重写的执行间隔有多长,数据的耐久性都不会有任何损失。
AOF
使用 AOF 持久化会让 Redis 变得非常耐久(much more durable):你可以设置不同的 fsync 策略,比如无 fsync ,每秒钟一次 fsync ,或者每次执行写入命令时 fsync 。 AOF 的默认策略为每秒钟 fsync 一次,在这种配置下,Redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据( fsync 会在后台线程执行,所以主线程可以继续努力地处理命令请求)。AOF 文件是一个只进行追加操作的日志文件(append only log), 因此对 AOF 文件的写入不需要进行 seek , 即使日志因为某些原因而包含了未写入完整的命令(比如写入时磁盘已满,写入中途停机,等等), redis-check-aof 工具也可以轻易地修复这种问题。
Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写: 重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。 整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的过程中,会继续将命令追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件也不会丢失。 而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开始对新 AOF 文件进行追加操作。AOF 文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂, 对文件进行分析(parse)也很轻松。 导出(export) AOF 文件也非常简单: 举个例子, 如果你不小心执行了 FLUSHALL 命令, 但只要 AOF 文件未被重写, 那么只要停止服务器, 移除 AOF 文件末尾的 FLUSHALL 命令, 并重启 Redis , 就可以将数据集恢复到 FLUSHALL 执行之前的状态。
AOF 的缺点:
对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB 。 在一般情况下, 每秒 fsync 的性能依然非常高, 而关闭 fsync 可以让 AOF 的速度和 RDB 一样快, 即使在高负荷之下也是如此。 不过在处理巨大的写入载入时,RDB 可以提供更有保证的最大延迟时间(latency)。AOF 在过去曾经发生过这样的 bug : 因为个别命令的原因,导致 AOF 文件在重新载入时,无法将数据集恢复成保存时的原样。 (举个例子,阻塞命令 BRPOPLPUSH 就曾经引起过这样的 bug 。) 测试套件里为这种情况添加了测试: 它们会自动生成随机的、复杂的数据集, 并通过重新载入这些数据来确保一切正常。 虽然这种 bug 在 AOF 文件中并不常见, 但是对比来说, RDB 几乎是不可能出现这种 bug 的。
RDB 和 AOF间的选择
object=queryFromCache();
if(object==null||queryFromCache throw any exception)
{
object=queryFromDB();
}如果因为缓存服务不存在而在queryFromCache时抛错一个exception以致于页面直接回一个HTTP 500 error给用户那是相当的不合理的。
2) 如果 slave-serve-stale data设置成 'no' slave会返回"SYNC with master in progress"这样的错误信息。 但 INFO 和SLAVEOF命令除外。
THP(Transparent Huge Pages)
- 开启THP的优势在于:
- 减少page fault。一次page fault可以加载更大的内存块.。
- 更小的页表。相同的内存大小,需要更少的页。
- 由于页表更小,虚拟地址到物理地址的翻译也更快。
- 劣势在于:
- 降低分配内存效率。需要大块、连续内存块,内核线程会比较激进的进行compaction,解决内存碎片,加剧锁争用。
- 降低IO吞吐。由于swapable huge page,在swap时需要切分成原有的4K的页。Oracle的测试数据显示会降低30%的IO吞吐。
- 对于redis而言,开启THP的优势:fork子进程的时间大幅减少。fork进程的主要开销是拷贝页表、fd列表等进程数据结构。由于页表大幅较小(2MB / 4KB = 512倍),fork的耗时也会大幅减少。
- 劣势在于: fork之后,父子进程间以copy-on-write方式共享地址空间。如果父进程有大量写操作,并且不具有locality,会有大量的页被写,并需要拷贝。同时,由于开启THP,每个页2MB,会大幅增加内存拷贝。
- fork时间对比 开启THP后,fork大幅减少。
- 超时次数对比 开启THP后,超时次数明显增多,但是每次超时时间较短。而关闭THP后,只有4次超时,原因是与fork在同一事件循环的请求受到fork的影响。 关闭THP影响的只是零星几个请求,而开启后,虽然超时时间短了,但是影响面扩大了进而导致了整个Linux系统的不稳定。
echo never > /sys/kernel/mm/transparent_hugepage/enabledRedis的maxmemory 0的问题
Redis配置文件中的这一行代表Redis会使用系统内存,你不该去限制Redis的内存开销如:JVM中的-xmx这个参数,而是要让Redis自动去使用系统的内存以获得最高的性能,因此我们会把这个值设成0即代表无限使用系统内存,系统内存有多少我们用多少。默认它启动后会消耗掉1个G的系统自有内存。
因此linux系统中有一个系统参数叫overcommit_memory,它代表的是内存分配策略,可选值为:0、1、2。
0, 表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程。
1, 表示内核允许分配所有的物理内存,而不管当前的内存状态如何。
2, 表示内核允许分配超过所有物理内存和交换空间总和的内存
所以我们结合我们的Redis使用以下的linux命令:
echo 1 > /proc/sys/vm/overcommit_memory上述两条命令发完后不要完了刷新系统内存策略,因此我们接着发出一条命令
sysctl -p
Redis在Linux系统中Too many open files的问题
有时位于系统访问高峰时间段突发的大量请求导致redis连接数过大,你会收到这样的错误信息:
Too many open files.
这是因为频繁访问Redis时造成了TCP连接数打开过大的主要原因, 这是因为Redis源码中在accept tcp socket时的实现里面遇到句柄数不够的处理方法为:留在下次处理,而不是断开TCP连接。
但这一行为就会导致监听套接字不断有可读消息,但却accept无法接受,从而listen的backlog被塞满;从而导致后面的连接被RST了。
这里我多啰嗦一下也就是Redis和Memcached的比较,memcached对于这种情况的处理有点特殊,或者说周到!
如果memcache accept 的时候返回EMFILE,那么它会立即调用listen(sfd, 0) , 也就是将监听套接字的等待accept队列的backlog设置为0,从而拒绝掉这部分请求,减轻系统负载,保全自我。
因此为了对付这个too many open files问题我们需要在Linux下做点小动作来改变ulimit的配置。
- 修改/etc/security/limits.conf
通过 vi /etc/security/limits.conf修改其内容,在文件最后加入(数值也可以自己定义):
* soft nofile = 65535
* hard nofile = 65535
- 修改/etc/profile
通过vi /etc/profile修改,在最后加入以下内容
ulimit -n 65535
通过上述一些设置,我们基本完成了Redis在做集群前的准备工作了,下面就来使用Redis的Sentinel来做我们的高可用方案吧。
使用Redis Sentinel来做HA
sentinel是一个分布式系统,在源码包的src目录下会有redis-sentinel命令,你甚至还可以在多台机器上部署sentinel进程,共同监控redis实例。
- 一个Master可以有多个Slave;
- Redis使用异步复制。从2.8开始,Slave会周期性(每秒一次)发起一个Ack确认复制流(replication stream)被处理进度;
- 不仅主服务器可以有从服务器, 从服务器也可以有自己的从服务器, 多个从服务器之间可以构成一个图状结构;
- 复制在Master端是非阻塞模式的,这意味着即便是多个Slave执行首次同步时,Master依然可以提供查询服务;
- 复制在Slave端也是非阻塞模式的:如果你在redis.conf做了设置,Slave在执行首次同步的时候仍可以使用旧数据集提供查询;你也可以配置为当Master与Slave失去联系时,让Slave返回客户端一个错误提示;
- 当Slave要删掉旧的数据集,并重新加载新版数据时,Slave会阻塞连接请求(一般发生在与Master断开重连后的恢复阶段);
- 复制功能可以单纯地用于数据冗余(data redundancy),也可以通过让多个从服务器处理只读命令请求来提升扩展性(scalability): 比如说, 繁重的 SORT 命令可以交给附属节点去运行。
- 可以通过修改Master端的redis.config来避免在Master端执行持久化操作(Save),由Slave端来执行持久化。
Redis Sentinel规划
考虑到大多数学习者环境有限,我们使用如下配置:
| IP | 端口 | 身份 |
| 192.168.56.101 | 7001 | master |
| 192.168.56.101 | 7002 | slave |
| 192.168.56.101 | 26379 | sentinel |
所以我们在一台服务器上安装3个目录:
- redis1-对应master
- redis2-对应slave
- redis-sentinel对应sentinel,它使用26379这个端口来监控master和slave
make PREFIX=/usr/local/redis1 install
make PREFIX=/usr/local/redis2 install
make PREFIX=/usr/local/redis-sentinel install
Sentinel中的配置
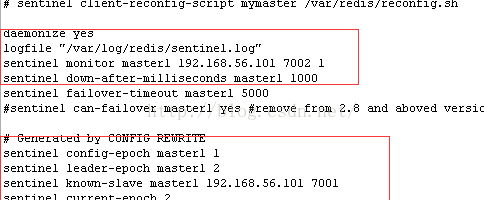
port 26379
daemonize yes
logfile "/var/log/redis/sentinel.log"
sentinel monitor master1 192.168.56.101 7001 1
sentinel down-after-milliseconds master1 1000
sentinel failover-timeout master1 5000
#sentinel can-failover master1 yes #remove from 2.8 and aboved version
- daemonize yes – 以后台进程模式运行
- port 26379 – 哨兵的端口号,该端口号默认为26379,不得与任何redis node的端口号重复
- logfile “/var/log/redis/sentinel.log“ – log文件所在地
- sentinel monitor master1 192.168.56.101 7001 1 – (第一次配置时)哨兵对哪个master进行监测,此处的master1为一“别名”可以任意如sentinel-26379,然后哨兵会通过这个别名后的IP知道整个该master内的slave关系。因此你不用在此配置slave是什么而由哨兵自己去维护这个“链表”。
- sentinel monitor master1 192.168.56.101 7001 1 – 这边有一个“1”,这个“1”代表当新master产生时,同时进行“slaveof”到新master并进行同步复制的slave个数。在salve执行salveof与同步时,将会终止客户端请求。此值较大,意味着“集群”终止客户端请求的时间总和和较大。此值较小,意味着“集群”在故障转移期间,多个salve向客户端提供服务时仍然使用旧数据。我们这边只想让一个slave来做此时的响应以取得较好的客户端体验。
- sentinel down-after-milliseconds master1 1000 – 如果master在多少秒内无反应哨兵会开始进行master-slave间的切换,使用“选举”机制
- sentinel failover-timeout master1 5000 – 如果在多少秒内没有把宕掉的那台master恢复,那哨兵认为这是一次真正的宕机,而排除该宕掉的master作为节点选取时可用的node然后等待一定的设定值的毫秒数后再来探测该节点是否恢复,如果恢复就把它作为一台slave加入哨兵监测节点群并在下一次切换时为他分配一个“选取号”。
- #sentinel can-failover master1 yes #remove from 2.8 and aboved version – 该功能已经从2.6版以后去除,因此注释掉,网上的教程不适合于redis-stable版
在配置Redis Sentinel做Redis的HA场景时,一定要注意下面几个点:
- 除非有多机房HA场景的存在,坚持使用单向链接式的master->slave的配置如:node3->node2->node1,把node1设为master
- 如果sentinel(哨兵)或者是HA群重启,一定要使用如此顺序:先启master,再启slave,再启哨兵
- 第一次配置完成“哨兵”HA群时每次启动不需要手动再去每个redis node中去更改master slave这些参数了,哨兵会在第一次启动后记录和动态修改每个节点间的关系,第一次配置好启动“哨兵”后由哨兵以后自行维护一般情况下不需要人为干涉,如果切换过一次master/slave后也因该记得永远先起master再起slave再起哨兵这个顺序,具体当前哪个是master可以直接看哨兵的sentinel.conf文件中最末尾哨兵自行的记录
Redis Master和Redis Slave的配置
这部分配置除了端口号,所在目录,pid文件与log文件不同其它配置相同,因此下面只给出一份配置:
daemonize yes
pidfile "/var/run/redis/redis1.pid"
port 7001
tcp-backlog 511
timeout 0
tcp-keepalive 0
loglevel notice
logfile "/var/log/redis/redis1.log"
databases 16
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error no
rdbcompression yes
rdbchecksum yes
dbfilename "dump.rdb"
dir "/usr/local/redis1/data"
slave-serve-stale-data yes
slave-read-only yes #slave只读,当你的应用程序试图向一个slave写数据时你会得到一个错误
repl-diskless-sync no
repl-disable-tcp-nodelay no
slave-priority 100
maxmemory 0
appendonly no
# The name of the append only file (default: "appendonly.aof")
appendfilename "appendonly.aof"
# appendfsync always
#appendfsync everysec
appendfsync no #关闭AOF
no-appendfsync-on-rewrite yes
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
lua-time-limit 5000
slowlog-log-slower-than 10000
slowlog-max-len 128
latency-monitor-threshold 0
notify-keyspace-events "gxE"
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-entries 512
list-max-ziplist-value 64
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
hll-sparse-max-bytes 3000
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10
其中:
- slave-read-only yes 我们把slave设成只读,当你的应用程序试图向一个slave写数据时你会得到一个错误
- appendfsync no 我们关闭了AOF功能
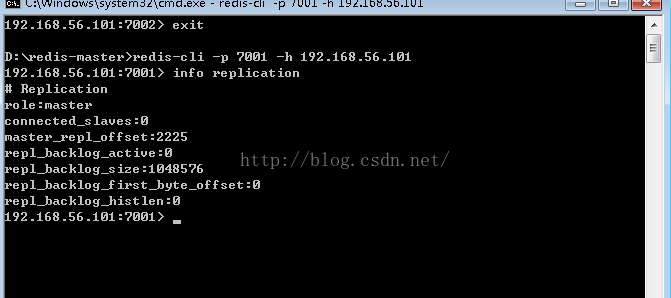
slaveof 192.168.56.101 7001配完了master, slave和sentinel后,我们按照这个顺序来启动redis HA:
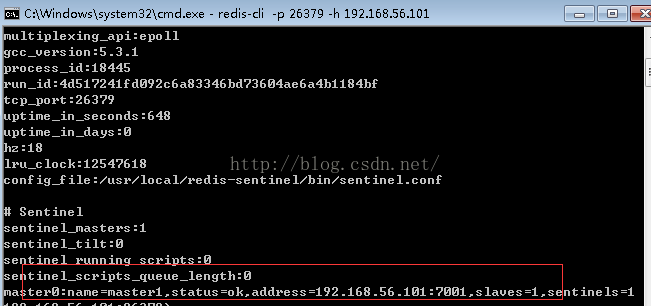
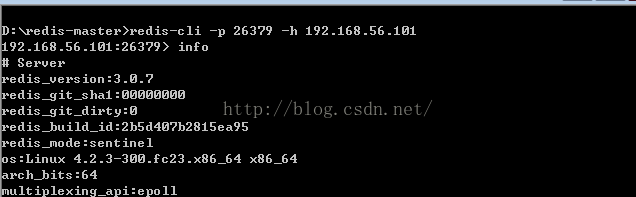
redis-cli -p 26379 -h 192.168.56.101进入我们配置好的sentinel后并使用: info命令来查看我们的redis sentinel HA配置。
可以看到目前它的master为7001,它有一个slave。
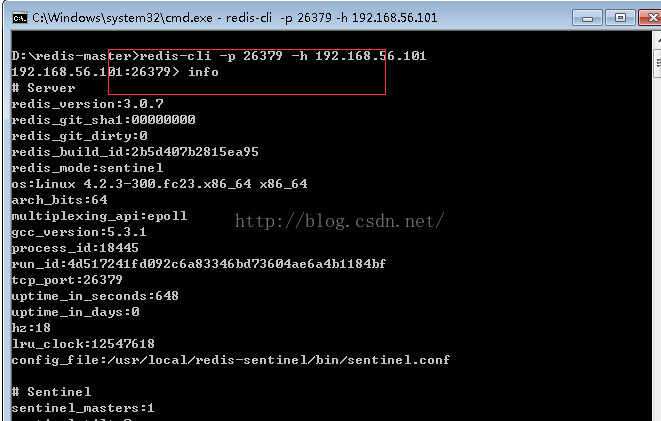
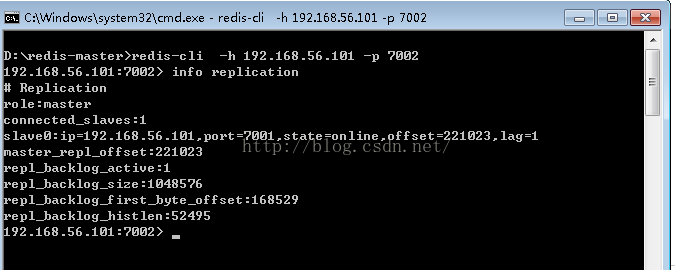
为了确认,我们另外开一个command窗口,通过:
redis-cli -p 7001 -h 192.168.56.101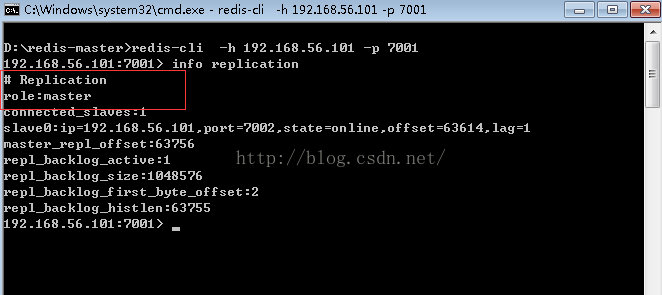
我们还可以通过命令:
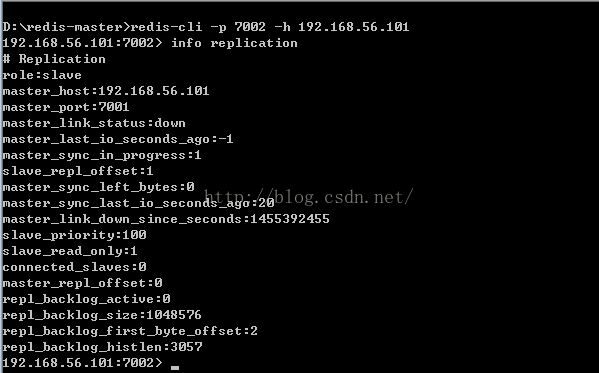
redis-cli -h 192.168.56.101 -p 7002进入到7002中并通过info replication来查看7002内的情况:
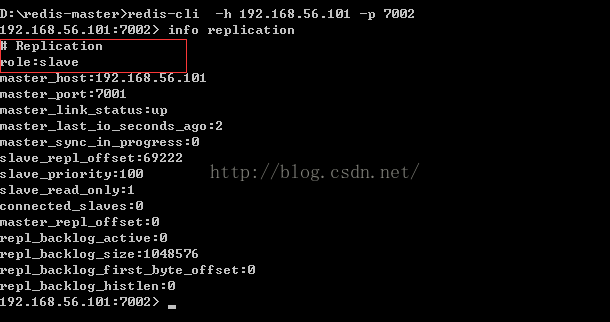
好了,环境有了,我们接下来要使用:
- 模拟代码
- 模拟并发测试工具
使用 Spring Data + Jedis来访问我们的Redis Sentinel
pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>webpoc</groupId>
<artifactId>webpoc</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>war</packaging>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.8</java.version>
<jetty.version>9.3.3.v20150827</jetty.version>
<slf4j.version>1.7.7</slf4j.version>
<spring.version>4.2.1.RELEASE</spring.version>
<spring.session.version>1.0.2.RELEASE</spring.session.version>
<javax.servlet-api.version>2.5</javax.servlet-api.version>
<activemq_version>5.8.0</activemq_version>
<poi_version>3.8</poi_version>
</properties>
<dependencies>
<!-- poi start -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>${poi_version}</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml-schemas</artifactId>
<version>${poi_version}</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-scratchpad</artifactId>
<version>${poi_version}</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>${poi_version}</version>
</dependency>
<!-- poi end -->
<!-- active mq start -->
<dependency>
<groupId>org.apache.activemq</groupId>
<artifactId>activemq-all</artifactId>
<version>5.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.activemq</groupId>
<artifactId>activemq-pool</artifactId>
<version>${activemq_version}</version>
</dependency>
<dependency>
<groupId>org.apache.xbean</groupId>
<artifactId>xbean-spring</artifactId>
<version>3.16</version>
</dependency>
<!-- active mq end -->
<!-- servlet start -->
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
<version>${javax.servlet-api.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>javax.servlet.jsp</groupId>
<artifactId>jsp-api</artifactId>
<version>2.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>jstl</artifactId>
<version>1.2</version>
</dependency>
<!-- servlet end -->
<!-- redis start -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>1.0.2</version>
</dependency>
<!-- redis end -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>jcl-over-slf4j</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<!-- spring conf start -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-redis</artifactId>
<version>1.6.2.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>${spring.version}</version>
<exclusions>
<exclusion>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-tx</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aop</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-orm</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jms</artifactId>
<version>${spring.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session</artifactId>
<version>${spring.session.version}</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>${spring.version}</version>
</dependency>
<!-- spring conf end -->
</dependencies>
<build>
<sourceDirectory>src</sourceDirectory>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.7</source>
<target>1.7</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-war-plugin</artifactId>
<version>2.4</version>
<configuration>
<warSourceDirectory>WebContent</warSourceDirectory>
<failOnMissingWebXml>false</failOnMissingWebXml>
</configuration>
</plugin>
</plugins>
</build>
</project>applicationContext.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:p="http://www.springframework.org/schema/p"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:jee="http://www.springframework.org/schema/jee" xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd">
<context:property-placeholder location="classpath:/spring/redis.properties" />
<context:component-scan base-package="org.sky.redis">
</context:component-scan>
<bean id="jedisConnectionFactory"
class="org.springframework.data.redis.connection.jedis.JedisConnectionFactory">
<constructor-arg index="0" ref="redisSentinelConfiguration" />
<constructor-arg index="1" ref="jedisPoolConfig" />
</bean>
<bean id="jedisPoolConfig" class="redis.clients.jedis.JedisPoolConfig">
<property name="maxTotal" value="${redis.maxTotal}" />
<property name="maxIdle" value="${redis.maxIdle}" />
<property name="maxWaitMillis" value="${redis.maxWait}" />
<property name="testOnBorrow" value="${redis.testOnBorrow}" />
<property name="testOnReturn" value="${redis.testOnReturn}" />
</bean>
<bean id="redisSentinelConfiguration"
class="org.springframework.data.redis.connection.RedisSentinelConfiguration">
<property name="master">
<bean class="org.springframework.data.redis.connection.RedisNode">
<property name="name" value="master1" />
</bean>
</property>
<property name="sentinels">
<set>
<bean class="org.springframework.data.redis.connection.RedisNode">
<constructor-arg name="host" value="192.168.56.101" />
<constructor-arg name="port" value="26379" />
</bean>
</set>
</property>
</bean>
<bean id="redisTemplate" class="org.springframework.data.redis.core.StringRedisTemplate">
<property name="connectionFactory" ref="jedisConnectionFactory" />
</bean>
<!--将session放入redis -->
<bean id="redisHttpSessionConfiguration"
class="org.springframework.session.data.redis.config.annotation.web.http.RedisHttpSessionConfiguration">
<property name="maxInactiveIntervalInSeconds" value="1800" />
</bean>
<bean id="customExceptionHandler" class="sample.MyHandlerExceptionResolver" />
</beans> 其中:
<property name="master">
<bean class="org.springframework.data.redis.connection.RedisNode">
<property name="name" value="master1" />
</bean>
</property>redis.properties文件
# Redis settings
redis.host.ip=192.168.56.101
redis.host.port=7001
redis.maxTotal=1000
redis.maxIdle=100
redis.maxWait=2000
redis.testOnBorrow=false
redis.testOnReturn=true
redis.sentinel.addr=192.168.56.101:26379
SentinelController.java文件
package sample;
import java.util.HashMap;
import java.util.Map;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.data.redis.core.BoundHashOperations;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.RequestMapping;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisSentinelPool;
import util.CountCreater;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpSession;
/**
* Created by xin on 15/1/7.
*/
@Controller
public class SentinelController {
private final Logger logger = LoggerFactory.getLogger(this.getClass());
@Autowired
private StringRedisTemplate redisTemplate;
@RequestMapping("/sentinelTest")
public String sentinelTest(final Model model,
final HttpServletRequest request, final String action) {
return "sentinelTest";
}
@ExceptionHandler(value = { java.lang.Exception.class })
@RequestMapping("/setValueToRedis")
public String setValueToRedis(final Model model,
final HttpServletRequest request, final String action)
throws Exception {
CountCreater.setCount();
String key = String.valueOf(CountCreater.getCount());
Map mapValue = new HashMap();
for (int i = 0; i < 1000; i++) {
mapValue.put(String.valueOf(i), String.valueOf(i));
}
try {
BoundHashOperations<String, String, String> boundHashOperations = redisTemplate
.boundHashOps(key);
boundHashOperations.putAll(mapValue);
logger.info("put key into redis");
} catch (Exception e) {
logger.error(e.getMessage(), e);
throw new Exception(e);
}
return "sentinelTest";
}
}
sentinelTest.jsp文件
<%@ page language="java" contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; UTF-8">
<title>test sentinel r/w</title>
</head>
<body>
</body>
</html>测试代码运行


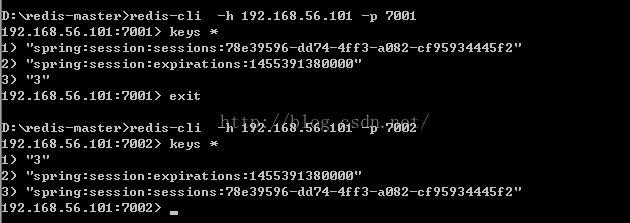
测试master不可访问时sentinel的自动切换
- master-7001
- slave-7002



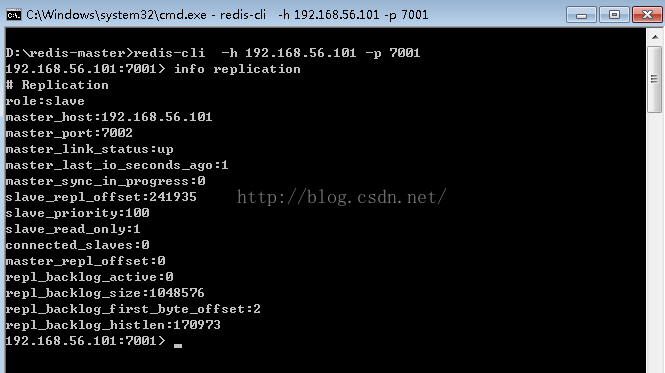
现在,我们把7001重新“恢复”起来,因此我们发出如下的命令:




使用jmter模拟大并发用户操作下的故障自动转移
压力测试计划
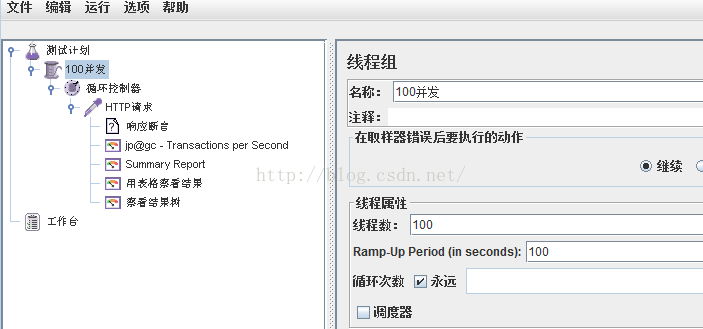
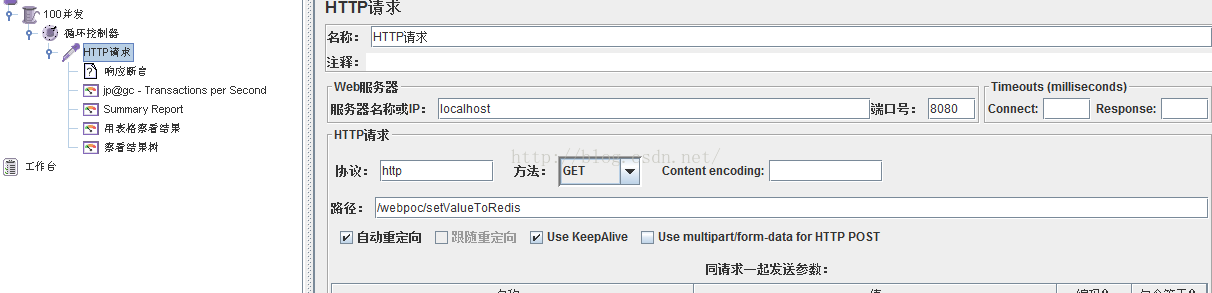
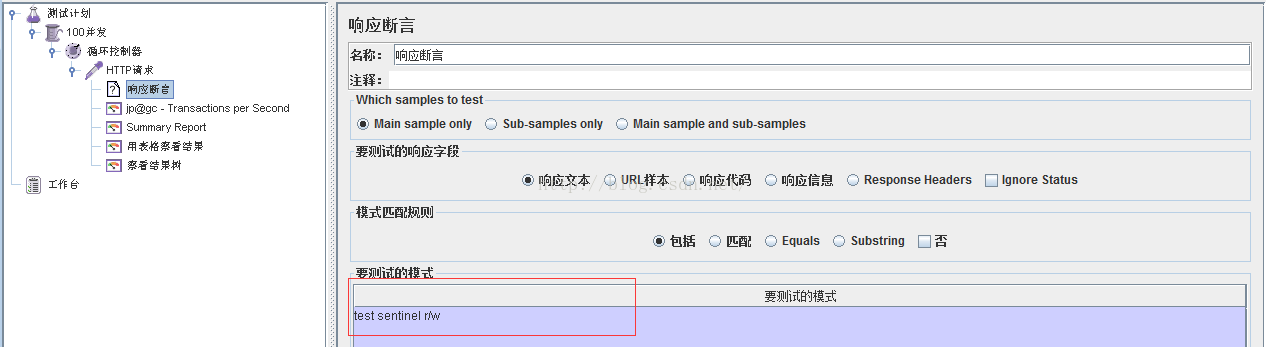
- TPS值
- summary report
- 表格查看结果
- 树形查看结果
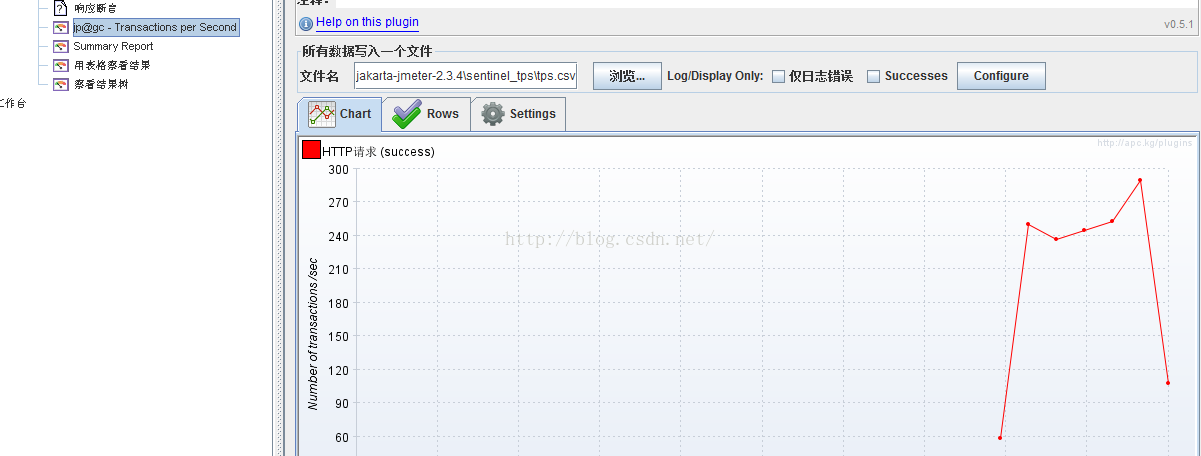
人为故意造成一次宕机

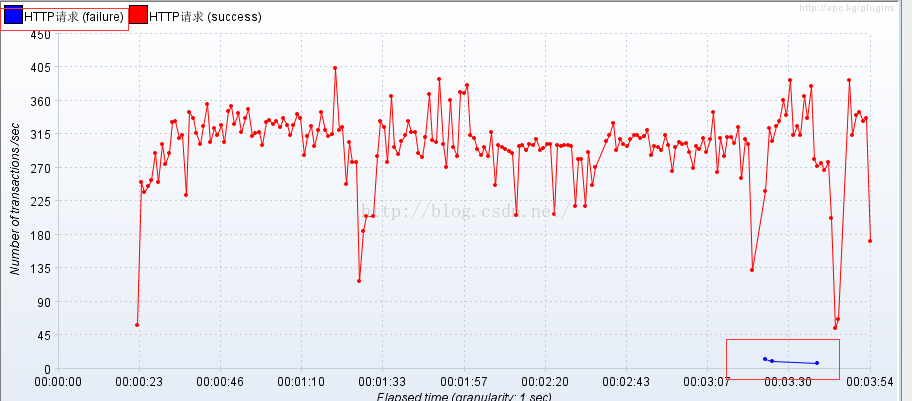

- 通过TPS我们可以发觉有蓝色的线,这代表“出错率”,这个出错率应该是7002在“崩”掉后,7001从slave升级成master时redis对客户端无法及时响应时抛出的HTTP 500即service unavailable的错。
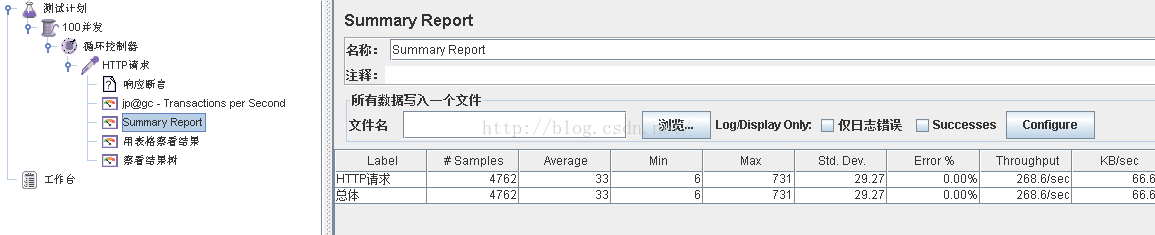
- 通过Summary Report我们可以看到在主从切换的那一刻我们的fail rate为千分之0.5,这个fail rate是完全可以在接受范围内的,一般错误率在千分之一就已经很好了。