@select 怎么写存储过程_你知道select语句和update语句分别是怎么执行的吗?
最近有粉丝面试互联网公司被问到:你知道select语句和update语句分别是怎么执行的吗?,要我写一篇这两者执行SQL语句的区别,这不就来了。
总的来说,select和update执行的逻辑大体一样,但是具体的实现还是有区别的。
当然深入了解select和update的具体区别并不是只为了面试,当希望Mysql能够高效的执行的时候,最好的办法就是清楚的了解Mysql是如何执行查询的,只有更加全面的了解SQL执行的每一个过程,才能更好的进行SQl的优化。
select语句
当执行一条查询的SQl的时候大概发生了一下的步骤:
- 客户端发送查询语句给服务器。
- 服务器首先进行用户名和密码的验证以及权限的校验。
- 然后会检查缓存中是否存在该查询,若存在,返回缓存中存在的结果。若是不存在就进行下一步。
- 接着进行语法和词法的分析,对SQl的解析、语法检测和预处理,再由优化器生成对应的执行计划。
- Mysql的执行器根据优化器生成的执行计划执行,调用存储引擎的接口进行查询。
- 服务器将查询的结果返回客户端。
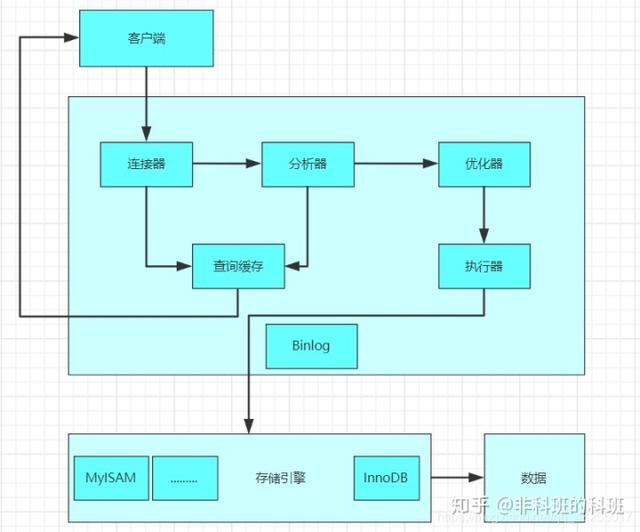
Mysql的执行的流程
Mysql中语句的执行都是都是分层执行,每一层执行的任务都不同,直到最后拿到结果返回,主要分为Service层和引擎层,在Service层中包含:连接器、分析器、优化器、执行器。引擎层以插件的形式可以兼容各种不同的存储引擎。
Mysql的执行的流程图如下图所示:
这里以一个实例进行说明Mysql的的执行过程,新建一个User表,如下:
// 新建一个表DROP TABLE IF EXISTS User;CREATE TABLE `User` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(10) DEFAULT NULL, `age` int DEFAULT 0, `address` varchar(255) DEFAULT NULL, `phone` varchar(255) DEFAULT NULL, `dept` int, PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=40 DEFAULT CHARSET=utf8;// 并初始化数据,如下INSERT INTO User(name,age,address,phone,dept)VALUES('张三',24,'北京','13265543552',2);INSERT INTO User(name,age,address,phone,dept)VALUES('张三三',20,'北京','13265543557',2);INSERT INTO User(name,age,address,phone,dept)VALUES('李四',23,'上海','13265543553',2);INSERT INTO User(name,age,address,phone,dept)VALUES('李四四',21,'上海','13265543556',2);INSERT INTO User(name,age,address,phone,dept)VALUES('王五',27,'广州','13265543558',3);INSERT INTO User(name,age,address,phone,dept)VALUES('王五五',26,'广州','13265543559',3);INSERT INTO User(name,age,address,phone,dept)VALUES('赵六',25,'深圳','13265543550',3);INSERT INTO User(name,age,address,phone,dept)VALUES('赵六六',28,'广州','13265543561',3);INSERT INTO User(name,age,address,phone,dept)VALUES('七七',29,'广州','13265543562',4);INSERT INTO User(name,age,address,phone,dept)VALUES('八八',23,'广州','13265543563',4);INSERT INTO User(name,age,address,phone,dept)VALUES('九九',24,'广州','13265543564',4);现在针对这个表发出一条SQl查询:查询每个部门中25岁以下的员工个数大于3的员工个数和部门编号,并按照人工个数降序排序和部门编号升序排序的前两个部门。
SELECT dept,COUNT(phone) AS num FROM User WHERE age< 25 GROUP BY dept HAVING num >= 3 ORDER BY num DESC,dept ASC LIMIT 0,2;连接器
开始执行这条sql时,首先会校验你的用户名和密码是否正确,若是不正确会返回错误信息:"Access denied for user";
若是用户名和密码校验通过,然后就会到权限表获取当前用户拥有的权限,会检查该语句是否有权限,若是没有权限就直接返回错误信息,有权限会进行下一步,校验权限的这一步是在图一的连接器进行的,对连接用户权限的校验。
注意:后续的一些列操作都是依赖于这个权限的范围内的。
检索缓存
当建立连接,履行查询语句的时候,会先行检查在缓存区域看看这个sql与否履行过,若是之前执行过,它的执行结果会以Key-Value的形式平缓适用内存中,Key是执行的sql,Value是结果集。
假如,缓存中key遭击中,便会直接将结果返回给客户端,假如没命中,便会履行后续的操作,完工之后亦会将结果缓存起来以便再次查询获取,当下一次进行查询的时候也是如此的循环操作。
注意:Mysql中的缓存比较适合于那些静态的表,更新不频繁的表,因为只要当前表有数据更新,有关于该表的缓存就会失效,若是表更新频繁缓存频繁的实效,这样维护缓存的消耗的性能远大于使用缓存带来的性能优化,这样就会得不偿失,严重影响Mysql的性能,所以在Mysql 8版本中的时候把缓存这一块给砍掉了。
在个人的观点中对于缓存这一块的看法是,没必要砍掉,可以设置成默认关闭缓存,需要的时候再设置开启,并且可以通过配置参数指定那别表使用缓存,那些表不使用缓存,这样或许使用缓存更有效。
分析器
分析器主要有两步:(1)词法分析(2)语法分析
词法分析主要执行提炼关键性字,比如select,提交检索的表,提交字段名,提交检索条件,确定该语句是select还是update或者是delete语句。
语法分析主要执行辨别你输出的sql与否准确,是否合乎mysql的语法,若是不符合sql语法就会抛出:You have an error in your SQL syntax。
优化器
查询优化器会将解析树转化成执行计划。一条查询可以有多种执行方法,最后都是返回相同结果。优化器的作用就是找到这其中最好的执行计划。
例如:在查询语句中有多个索引的时候,优化器决定使用哪一个索引,或者有多表关联的时候,决定表的连接顺序等这些操作都是在优化器决定的。
生成执行计划的过程会消耗较多的时间,特别是存在许多可选的执行计划时。如果在一条SQL语句执行的过程中将该语句对应的最终执行计划进行缓存。
当相似的语句再次被输入服务器时,就可以直接使用已缓存的执行计划,从而跳过SQL语句生成执行计划的整个过程,进而可以提高语句的执行速度。
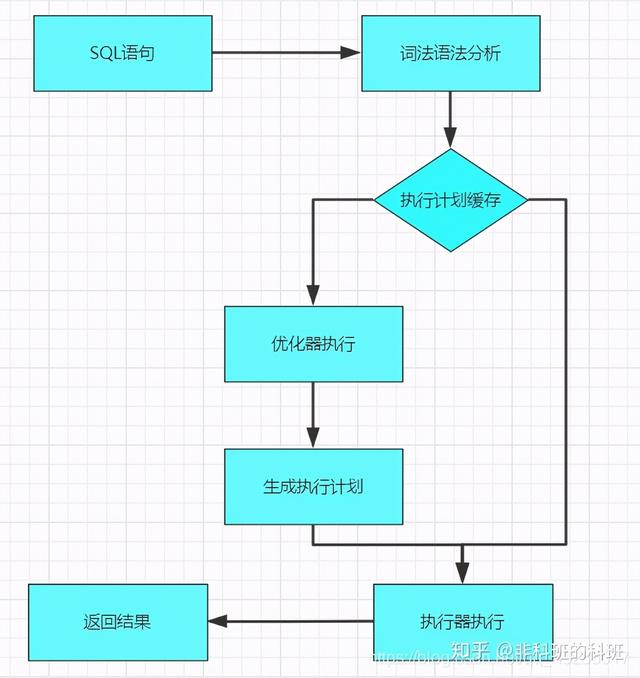
MySQL使用基于成本的查询优化器。它会尝试预测一个查询使用某种执行计划时的成本,并选择其中成本最少的一个。
执行器
优化器生成的执行计划,交由执行器进行执行,执行器调用存储引擎得读接口,执行器中循环地调用存储引擎的读接口,以此换取满足条件的数据行,并把它放在一个结果集中,遍历并获取了所有满足条件的数据行,最后将结果集返回,结束整个查询得过程。
update语句
上面我们说完了select语句,select语句的执行过程会经过连接器、分析器、优化器、执行器、存储引擎,同样的update语句也会同样走一遍select语句的执行过程。
但是和select最大不同的是,update语句会涉及到两个日志的操作redo log(重做日志) 和binlog (归档日志)。对于这两个日志的详细介绍,我之前写过一篇文章进行介绍,有兴趣的可以看一看[]:
那么Mysql中又是怎么使用redo log和binlog?为什么要使用redo log和binlog呢?直接执行更新然后存库不就行了吗?还要放在redo log和binlog中,这不是多此一举吗?且听我慢慢道来,这里面大有文章。
redo log
大家都是知道Mysql是关系型数据库,用来存储数据的,在访问数据库量大的时候,Mysql读写磁盘访问的效率是非常低的,加上sql中的条件对数据的筛选过滤,那么效率就更低了。
这也是为什么引入非关系型数据库作为作为数据缓存原因,例如:Redis、MongoDB等,就是为了减少sql执行期间的数据库io操作。
同样的道理,若是每次执行update语句都要进行磁盘的io操作、以及数据的过滤筛选,小量的访问和数据量数据库还可以撑住,那么访问量一大以及数据量一大,这样数据库肯定顶不住。
基于上面的问题于是出现了redo log日志,redo log日志也叫做WAL技术(Write- Ahead Logging),他是一种先写日志,并更新内存,最后再更新磁盘的技术,并且更新磁盘往往是在Mysql比较闲的时候,这样就大大减轻了Mysql的压力。
redo log的特点就是:redo log是固定大小,是物理日志,属于InnoDB引擎的,并且写redo log是环状写日志的形式:
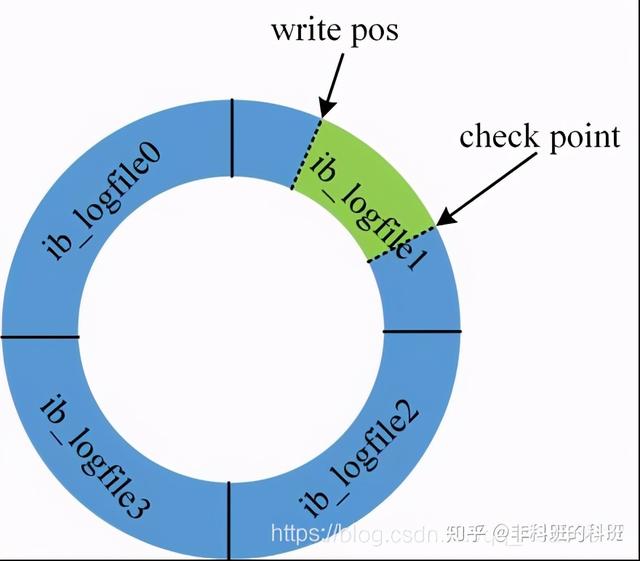
如上图所示:若是四组的redo log文件,一组为1G的大小,那么四组就是4G的大小,其中write pos是记录当前的位置,有数据写入当前位置,那么write pos就会边写入边往后移。
而check point是擦除的位置,因为redo log是固定大小,所以当redo log满的时候,也就是write pos追上check point的时候,需要清除redo log的部分数据,清除的数据会被持久化到磁盘中,然后将check point向前移动。
redo log日志实现了即使在数据库出现异常宕机的时候,重启后之前的记录也不会丢失,这就是crash-safe能力。
binlog
binlog称为归档日志,是逻辑上的日志,它属于Mysql的Server层面的日志,记录着sql的原始逻辑,主要有两种模式,一个是statement格式记录的是原始的sql,而row格式则是记录行内容。
那么这样看来redo log和binlog虽然记录的形式、内容不同,但是这两者日志都能通过自己记录的内容恢复数据,那么为什么还要这两个日志同时存在呢?只要其中一个不就行了嘛,两个同时存在不就多此一举了嘛。且听我慢慢道来,这里面也大有文章。
因为刚开Mysql自带的引擎MyISAM就没有crash-safe功能的,并且在此之前Mysql还没有InnoDB引擎,Mysql自带的binlog日志只是用来归档日志的,所以InnoDB引擎也就通过自己redo log日志来实现crash-safe功能。
update执行过程
上面说了那么久两种日志的作用和特点,那么这两种日志究竟和update执行语句有什么关系呢?
先来看图:
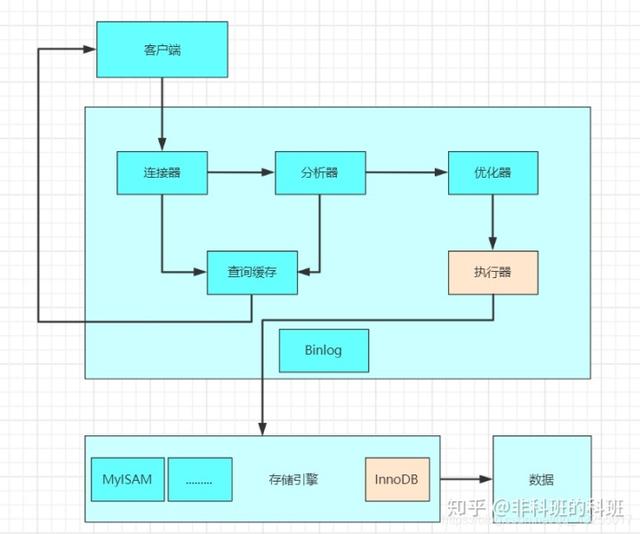
前提:当前的引擎是使用InnoDB,update语句与select语句区别主要是这两日志的使用主要是在执行器和引擎之间进行交互时体现的区别。假如执行如下一条简单的更新语句是:
update user set age=age+1 where id =2;上面说过select语句走过的流程update语句也会走一遍,当来到执行器的时候:
- 执行器会调用引擎的读接口,然后找到id=2的数据行,因为id是主键索引,索引按照树的搜索找到这一行,若是数据行已经存在于内存的数据页中就会立即将结果返回,若是不在内存中,就会从磁盘中进行加载到内存中,然后将查询的结果返回。
- 然后,执行器将返回的结果的age字段+1,并调用引擎的写接口写入更新后的数据行。
- 引擎获取到更新后的数据行更新到内存和redo log中,并告诉执行器可以随时提交事务,此时的redo log处于prepare阶段。
- 执行器收到引擎的告知后,生成binlog日志,并且调用引擎的接口提交事务,引擎将redo log的状态修改为commit状态,这样这个更新操作算是完成。
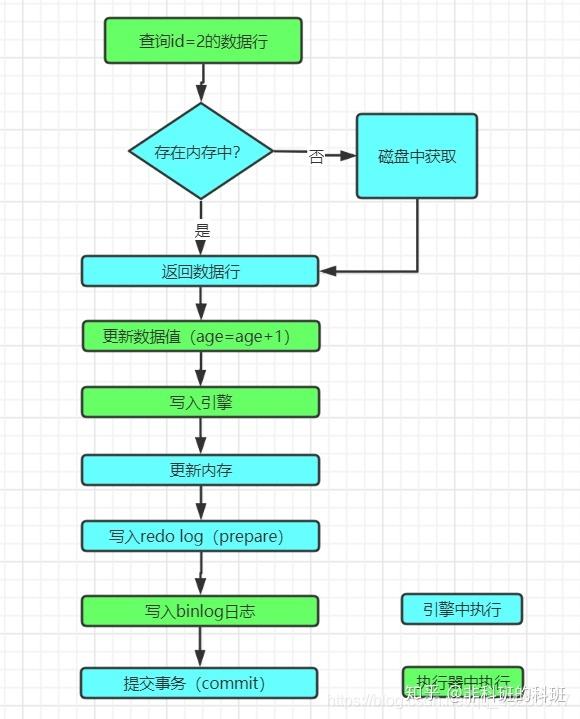
与select语句相比,因为select没有更新数据,只是将引擎查询的数据返回给执行器就算是完后,而update涉及数据的更新并且重新调用引擎接口写会存储引擎中的交互过程。
两阶段提交
上面详细的说了update语句的执行流程,提到了redo log的prepare和commit两个阶段,这就是两阶段提交,两阶段提交的目的是为了保证redo log日志与binlog日志保持数据的一致性。
若是redo log写成功binlog写失败,或者redo log写失败binlog写成功,最后使用这两者日志进行数据恢复得到的结果数据都是不一致性的,所以为了保证两个日志逻辑上的一致,使用两阶段进行提交。
redo log与binlog的总结
最后来对比一下这两种日志:redo是物理的,binlog是逻辑的,redo的大小固定,并且以环状的形式写入数据,数据满的时候需要将redo日志中擦除数据,并且将擦除的数据持久化到磁盘中。
而binlog以追加日志的形式写入,也就是当日志写到一定大小后,就会切换到下一个,并不会覆盖以前写的日志。
binlog是在Mysql的Server层中使用,因为binlog没有crash-safe功能,所以InnoDB引擎自己实现了redo log日志的crash-safe的功能,为了保证这两个日志逻辑上的一致使用两阶段提交。
在使用redo和binlog这两种日志的时候,可以将参数innodb_flush_log_at_trx_commit和sync_binlog都设置为1,它表示每次事务提交的时候,都会将日志持久化到磁盘中。
好了,这里详细的介绍了select和update执行语句的区别,这一期就到这里,我们下一期间,喜欢的欢迎转发和分享。