[ACL2022] Text Smoothing: 一种在文本分类任务上的数据增强方法

论文链接: https://arxiv.org/abs/2202.13840
背景
不论在CV和还是NLP领域中,数据增强一直是一种广泛使用的技术,特别是在低资源环境下。可以通过增加训练数据的规模来缓解过拟合,提高深度神经网络的鲁棒性。在NLP领域,数据增强的方法通常有: (1) 对文本进行增删改。(2)通过dropout。(3) mixup技术。 本文提出的方法类似于mixup。下面我们介绍一下本文的方法:
模型
首先,大白话讲一下思想。给出一个句子,“The quality of this shirt is average.”,通过MLM任务对average这个词进行预测,就会出现一个概率分布。如下图:
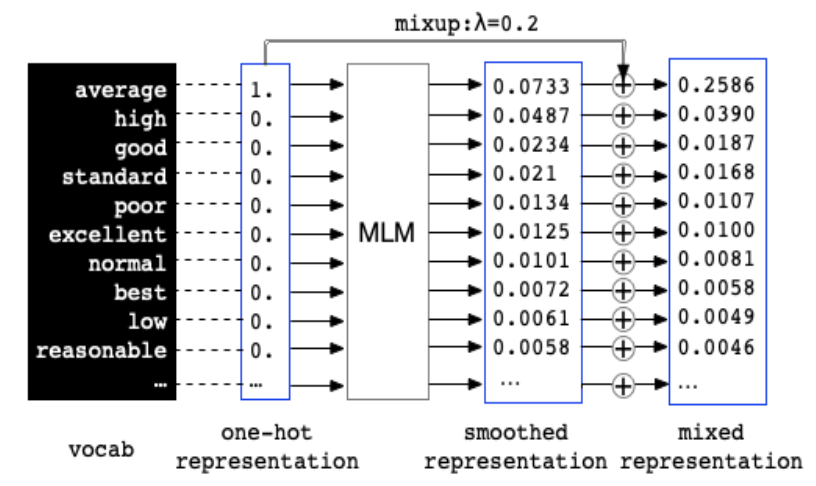
上图中最左边是词表,接下来是average的one-hot表示,通过MLM任务,得到average在词表中的概率分布,可以发现预测出average的概率最高,为0.0733,其余的high、good等概率都偏低,但可以发现,这些词和average在某种程度上有些相像。比如词性,或者是近义词等等。如果将这些词替换原句中的average,就可以对数据进行增强。但本文不是替换,本文采用mixup的方式,将概率分布和one-hot进行加权和,然后代替one-hot的作用,即: 之前one-hot是对embedding进行lookup,现在是对embedding进行了加权和。显然这样引入了其他词的信息,这样就实现了数据增强。
上面如果听着还有些迷糊的话,接下来上公式了解一下具体的流程。

上图是本文方法的架构图,首先看蓝色部分,从one-hot输入开始,经过一个MLM得到概率分布,然后和one-hot进行加权和代替原始的one-hot。接着看下面的红色部分,将加权和和one-hot结合,送到task model中,进行我们的分类任务。注: 这里的MLM模型是训练好的bert模型。
Smoothed Representation
假设下游任务是: D = { t i , p i , s i , l i } i = 1 N D=\{{t_i, p_i, s_i, l_i}\}_{i=1}^N D={ti,pi,si,li}i=1N,其中N是样本个数, t i t_i ti为one-hot表示, p i p_i pi为position embedding, s i s_i si为segment embedding, l i l_i li为当前分类任务的标签数。
首先通过MLM模型得到最后一层的输出:
t
→
=
B
E
R
T
(
t
i
,
p
i
,
s
i
)
\mathop{t}\limits ^{\rightarrow}=BERT(t_i, p_i, s_i)
t→=BERT(ti,pi,si)
此时 t → \mathop{t}\limits ^{\rightarrow} t→的维度为(seq_len, hidden_size),然后对每个token进行概率预测。即:
M
L
M
(
t
i
)
=
s
o
f
t
m
a
x
(
t
→
W
T
)
MLM(t_i) = softmax(\mathop{t}\limits ^{\rightarrow} W^T)
MLM(ti)=softmax(t→WT)
其中
W
T
W^T
WT的维度为(vocab_size, hidden_size),因为bert中hidden_size和embedding_size维度一致,所以原本中使用的embedding_size,说法一样。
此时: M L M ( t i ) MLM(t_i) MLM(ti)每一行就是当前一个token的概率分布。
Mixup Strategy
首先看看最原始的mixup方法,如下:
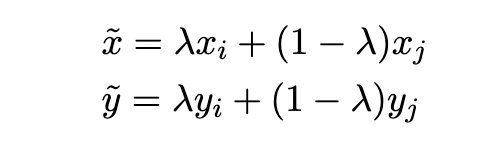
是通过两个样本再合成一个样本达到数据的增广。如上公式所示: 样本
(
x
i
,
y
i
)
,
(
x
j
,
y
j
)
(x_i, y_i), (x_j, y_j)
(xi,yi),(xj,yj),对
x
i
和
x
j
x_i和x_j
xi和xj的输入在embedding处加权和,得到新的输入embedding,标签是
y
i
和
y
j
y_i和y_j
yi和yj直接进行加权和。然后用新的embedding去学习合成的标签。这里的
λ
\lambda
λ取值范围[0,1]之间。
本文借鉴了上述方法,将MLM输出的概率分布和one-hot进行加权和,公式如下:
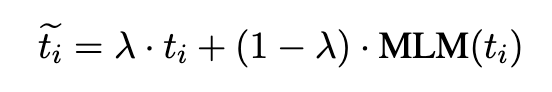
本文的方法介绍到此就结束了。另外本文给了一个简单的实现demo,如下:

最后我们看看实验结果。
实验
作者在SST-2、SNIPS、TREC数据上,对不同的数据增广方式做了对比,如下:

可以发现Text Smoothing方法提升还是比较明显的。因为Text Smoothing方法和其他增广方式可以联合使用,因为作者又做了以下实验:
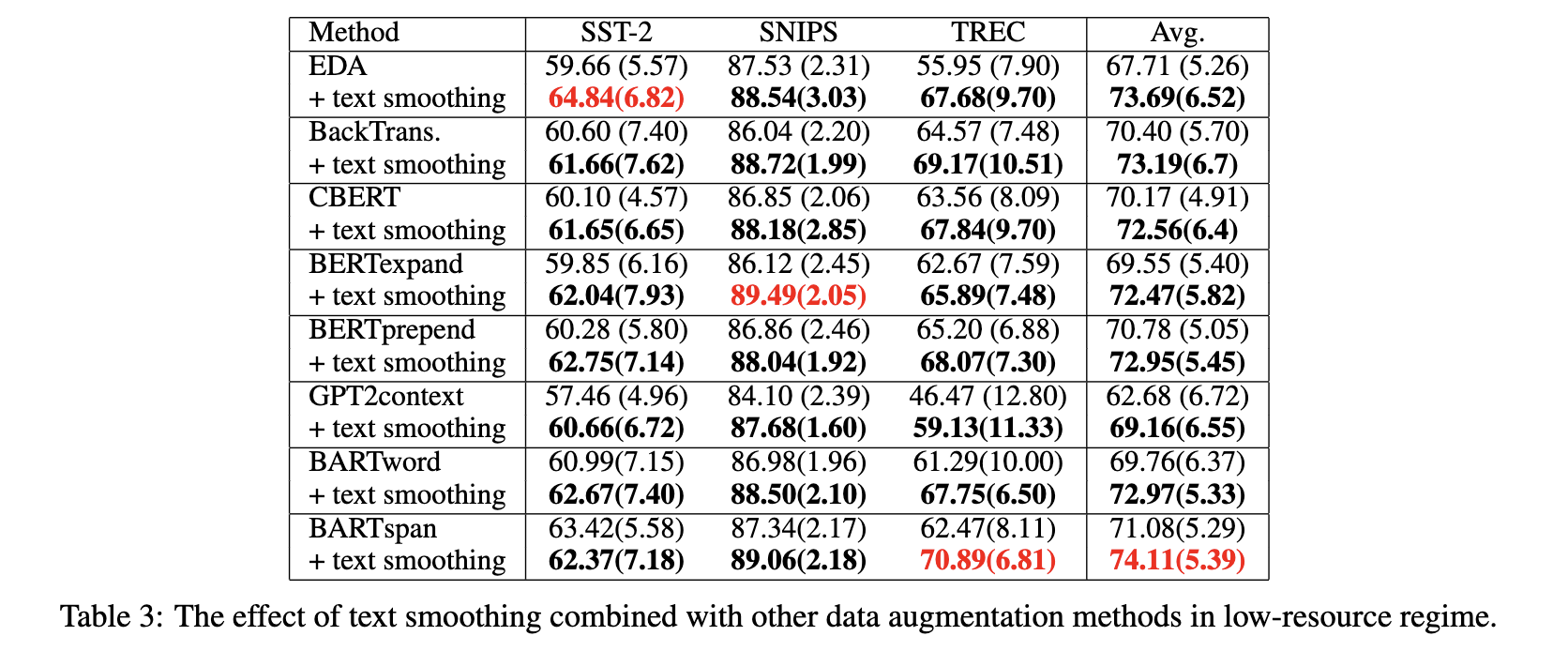
整体来看,和其他方法结合,比单纯的Text Smoothing提升更多。