使用聚类(K-means)分析方法对骑手进行分类标签定义
什么是聚类分析
聚类分析的目标就是在相似的基础上收集数据来分类,属于无监督学习。就是通过行为数据,通过算法将相似的人群聚集在一起,形成不带标签的人群簇。再人为的对人群簇进行分析,寻找特征标签。
一、数据构建
根据骑手的行为数据,可以从 日均活跃时长、工作日/非工作日、高峰期/平峰期、白天/夜间、骑手年龄等 可能存在喜好偏差的行为数据,进行数据构建。
#基础包导入(有很多无关的,懒的删除了,哈哈哈
from sklearn.datasets import load_iris
import xgboost as xgb
from xgboost import plot_importance
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
import pandas as pd
import numpy as np
from sklearn.metrics import accuracy_score
import seaborn as sns
import matplotlib
#指定默认字体
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['font.family']='sans-serif'
#解决负号'-'显示为方块的问题
matplotlib.rcParams['axes.unicode_minus'] = False
from pyhive import hive
import os
def presto_read_sql_df(sql):
conn=prestodb.dbapi.connect(
host=os.environ['PRESTO_HOST'],
port=os.environ['PRESTO_PORT'],
user=os.environ['JUPYTER_HADOOP_USER'],
password=os.environ['HADOOP_USER_PASSWORD'],
catalog='hive')
cur = conn.cursor()
cur.execute(sql)
query_result = cur.fetchall()
colnames = [part[0] for part in cur.description]
raw = pd.DataFrame(query_result, columns=colnames,dtype=np.float64)
return raw
def hive_read_sql_df(sql):
conn = hive.connect(
host=os.environ['PYHIVE_HOST'],
port=os.environ['PYHIVE_PORT'],
username=os.environ['JUPYTER_HADOOP_USER'],
password=os.environ['HADOOP_USER_PASSWORD'],
auth='LDAP',
configuration={'mapreduce.job.queuename': os.environ['JUPYTER_HADOOP_QUEUE'],
'hive.resultset.use.unique.column.names':'false'})
raw = pd.read_sql_query(sql,conn)
return raw#数据读取(可以用hive,也可以直接读取文件
df = hive_read_sql_df("""
select
*
from XXX
""")
df.to_csv('XXXXX.csv',encoding='gbk',sep=',',index = False)#从文件读取数据
# 路径调整
# print(os.getcwd())
# os.chdir('/home/')
# print(os.getcwd())
data = pd.read_csv('XXXXXX.csv',encoding='gbk')
#可能会存在部分缺失值导致后续运行报错,先将缺失值进行剔除
df = data
df.describe() #数据预览
print(df.isnull().any()) #缺失值判断
df.dropna(inplace=True) #删除缺失值
print(df.isnull().any()) #缺失值判断
df.describe() #数据预览
# df = df.query("main_city_tsh_rate > 0.15") #数据筛选
# df = df.drop('age',axis=1) #删除无关列
_id = df['_id'] #先将dri_id单独存储,在分类后再加回去
td = df.drop('_id',axis=1) #删除_id列#数据标准化,避免数据的量纲对分类产生权重影响,对数据进行标准化
使用Z分数标准化数据:Z分数_百度百科
#数据标准化处理——z分数: x = (x - x.mean()) /x.std()
td.tsh_avg = (td.tsh_avg -td.tsh_avg.mean()) / td.tsh_avg.std() 二、超参数K值回归
K,即K-means聚类产生的结果数,k-means不会自主决定聚类的结果数,需要人为的指定。人为指定通常存在一些误判,可通过手肘法、轮廓系数法进行回归计算,从而选择最优的超参数K。
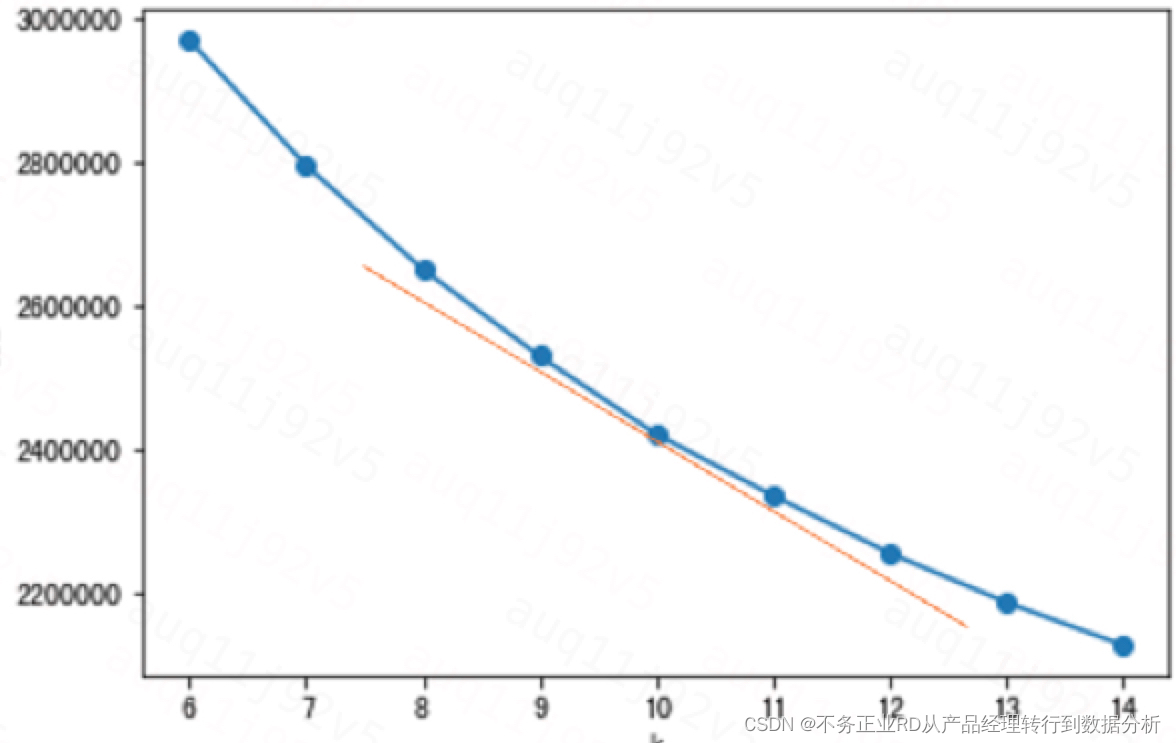
2.1手肘法
(由于我的数据量比较大,且有倾向性的希望结果在6-14之间,所以K的范围选择6-14,也可根据自己的需求定义范围)
# '利用SSE选择k' 选择斜率最小的点作为K
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
# '利用SSE选择k'
SSE = [] # 存放每次结果的误差平方和
for k in range(6, 15):
estimator = KMeans(n_clusters = k,max_iter = 10000,random_state = 10)
estimator = estimator.fit(x)
SSE.append(estimator.inertia_)
print(k)
X = range(6, 15)
plt.xlabel('k')
plt.ylabel('SSE')
plt.plot(X, SSE, 'o-')
plt.show()
K=10,拐点不是非常显著,但基于我的业务需求,倾向将K定义为10
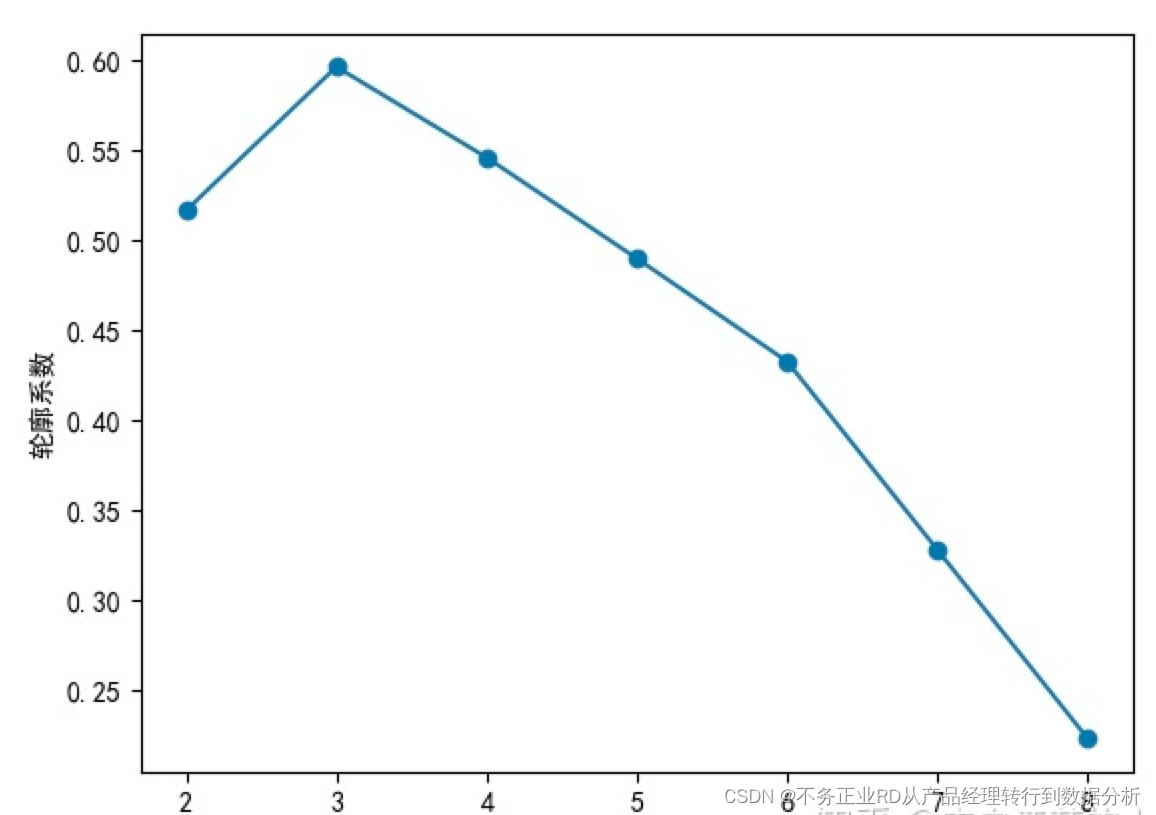
2.2轮廓系数法:
# 选择最高点作为K
Scores = [] # 存放轮廓系数
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
for k in range(6, 15):
estimator = KMeans(n_clusters = k,max_iter = 10000,random_state = 10)
estimator = estimator.fit(x)
Scores.append(silhouette_score(x, estimator.labels_, metric='euclidean'))
print(k )
X = range(6, 15)
plt.xlabel('k')
plt.ylabel('轮廓系数')
plt.plot(X, Scores, 'o-')
这个方法数据量大时巨慢,结果没跑出来(大家可以自己尝试下,选择方法可以参考下图,选择K=3,即轮廓系数最大值,理论可参考原文
2.3Gap Statistic 法:
具体可大家再深入,我内网环境没安装成功
from gap_statistic import OptimalK
def gap_statistic_K(data, range_K, pro_num):
K = np.arange(1, range_K)
optimalK = OptimalK(n_jobs=1, parallel_backend='joblib')
n_clusters = optimalK(data, cluster_array=K)
# Gap values plot
plt.plot(optimalK.gap_df.n_clusters, optimalK.gap_df.gap_value, linewidth=3)
plt.scatter(optimalK.gap_df[optimalK.gap_df.n_clusters == n_clusters].n_clusters,
optimalK.gap_df[optimalK.gap_df.n_clusters == n_clusters].gap_value, s=250, c='r')
plt.grid(True)
plt.xlabel('Cluster Count')
plt.ylabel('Gap Value')
plt.title('Gap Values by Cluster Count')
plt.savefig(f'/Users/cecilia/Desktop/K_图片/{pro_num}_gap_values_K.jpg')
plt.cla()
# plt.show()
return n_clusters
三、聚类方法——K-means
n_clusters = 10 ,即结果为10类
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 10,max_iter = 10000,random_state = 10) #构建模型
y = kmeans.fit(td)
# y = kmeans.fit(x)
label_pred = y.labels_#获取聚类标签
df['_type'] = label_pred
df.to_csv('result_v4.csv',encoding='gbk',sep=',',index = False) ##先将结果保存下来
dri_type_cnt = df.groupby('_type').count()._id
# 画图,plt.bar()可以画柱状图
for i in range(len(dri_type_cnt)):
plt.bar(i, dri_type_cnt[i])
# 设置图片名称
plt.title("各簇人数")
# 设置x轴标签名
plt.xlabel("簇标签")
# 设置y轴标签名
plt.ylabel("人数")
# 显示
plt.show()
dri_type_mean = df.groupby('dri_type').mean()
dri_type_mean.to_csv('group_mean_v5.csv',encoding='gbk',sep=',',index = False) ##根据均值寻找人群簇特征 k-means会将人群分为10类,根据每个特征值,可以对人群进行标签定义 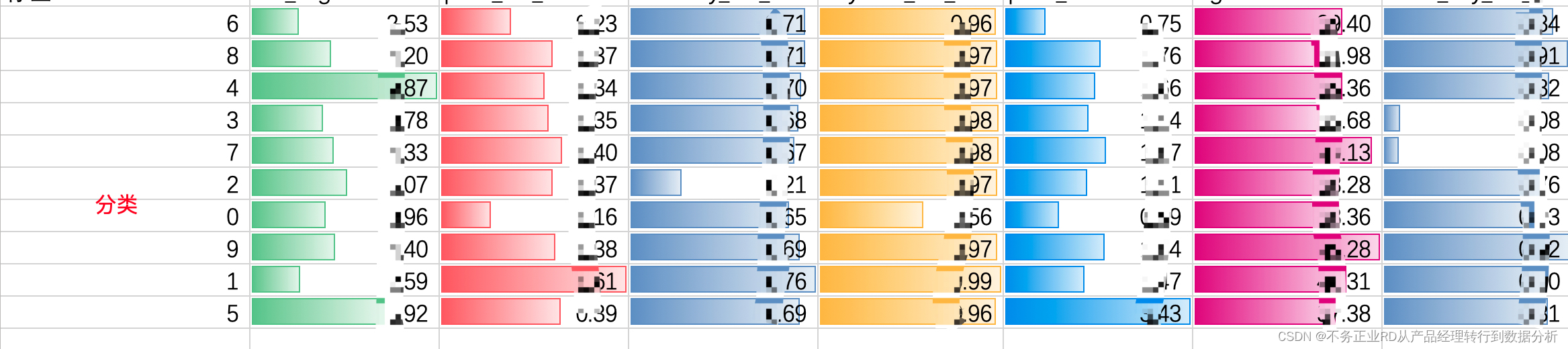
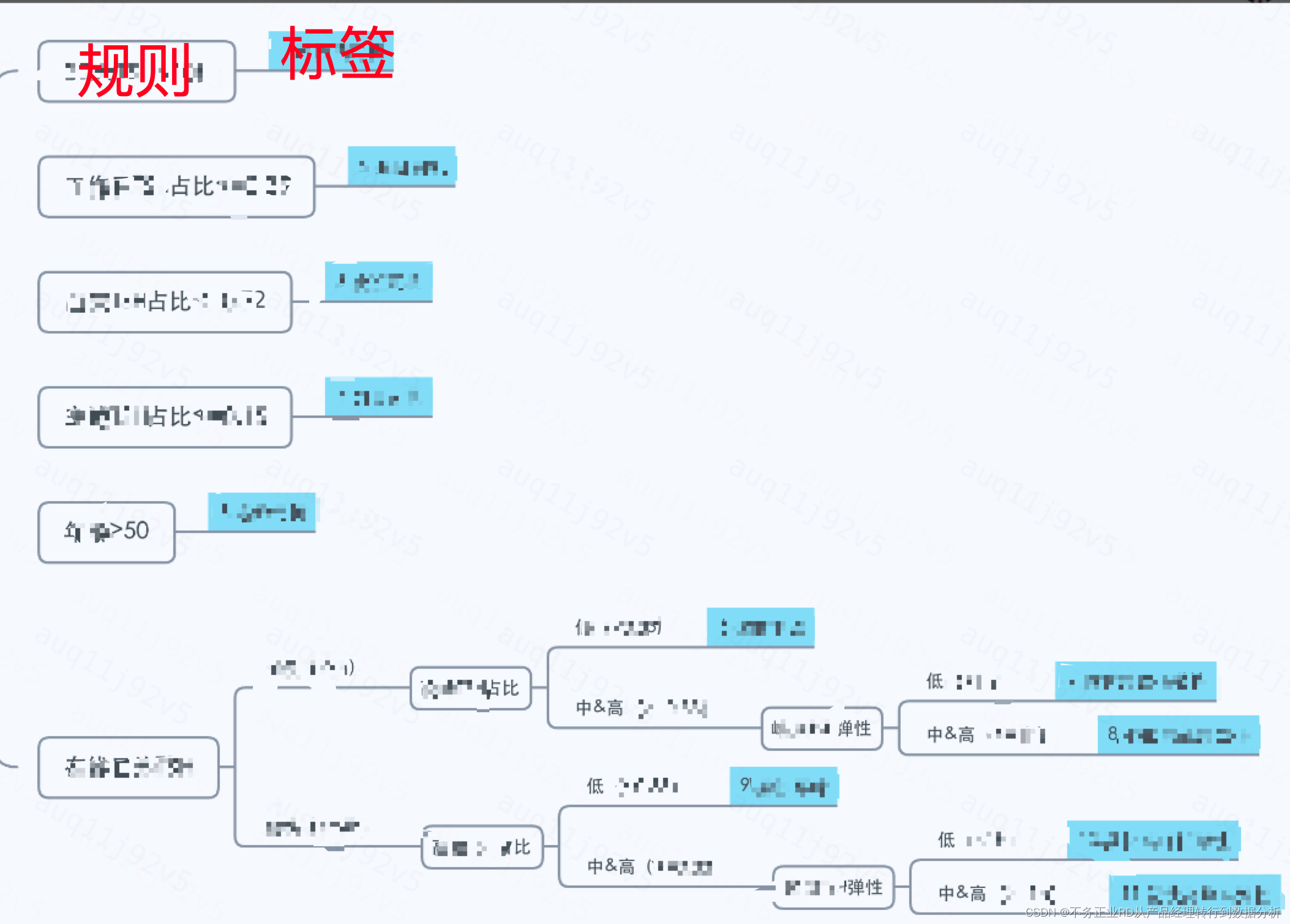
四、聚类结果白盒化
因为算法实现的可解释性较差理解成本高,且容易受特征波动有较大变化;基于用户显著性特征对类群进行白盒规则化。
即根据人群的特征,将人群标签的定义规则进行明确,根据明确的规则,对人群进行直接的标签划分,便于数据的产出和标签的稳定。(此处可根据人群簇的特征值作为参考,也可结合业务的体感进行判断,或者数据分布进行去尾、去头等,无绝对准确的规则,更多的是业务体感)