python笔记Ⅳ--序列(列表、切片)
一、序列:序列是python中最基本的一种数据结构。数据结构指计算机中数据存储的方式。
序列用于保存一组有序的数据,所有的数据在序列当中都有唯一的位置(索引),并且序列中的数据会按照添加的顺序来分配索引。
序列的分类:
(1)可变序列(序列中的元素可以改变):
① 列表(list)
(2)不可变序列(序列中的元素不可以改变):
① 字符串(str)
② 元组(tuple)
二、列表:列表是python中的一个对象
1.列表中可以保存多个有序的数据,列表存储的数据,我们称为元素。一个列表中可以存储多个元素,也可以在创建列表时,来指定列表中的元素。
my_list = [10] # 创建一个只包含一个元素的列表2.列表是用来存储对象的对象,列表中可以保存任意的对象。
my_list = [10,'hello',True,None,[1,2,3],print]3.列表中的对象都会按照插入的顺序存储到列表中, 第一个插入的对象保存到第一个位置,第二个保存到第二个位置。
我们可以通过索引(index)来获取列表中的元素。索引是元素在列表中的位置,列表中的每一个元素都有一个索引。索引是从0开始的整数,列表第一个位置索引为0,第二个位置索引为1,第三个位置索引为2,以此类推。
my_list = [10,20,30,40,50]通过索引获取列表中的元素:
语法:
my_list[索引] my_list[0]
# 如果使用的索引超过了最大的范围,会抛出异常
# print(my_list[5]) IndexError: list index out of range注意:列表的索引可以是负数。如果索引是负数,则从后向前获取元素,-1表示倒数第一个,-2表示倒数第二个。
4.通过len()函数可以获取列表中元素的个数,通过该函数可以获取列表的长度。
注意:获取到的长度的值,是列表的最大索引 + 1
print(len(my_list)) # 55.列表的使用:
(1)列表的创建
(2)操作列表中的数据
6.列表的方法----只适用于可变序列
stus = ['路飞','索隆','山治','索隆']
print('原列表:',stus)(1)插入的方法
① append()----向列表的最后添加一个元素
stus.append('娜美')② insert()----向列表的指定位置插入一个元素
参数: Ⅰ、要插入的位置 Ⅱ、要插入的元素
stus.insert(2,'罗宾')③ extend()----使用新的序列来扩展当前序列。需要一个序列作为参数,它会将该序列中的元素添加到当前列表中
stus.extend(['乌索普','乔巴'])
stus += ['乌索普','乔巴'](2)删除的方法
① clear()----清空序列
stus.clear()② pop()----根据索引删除并返回被删除的元素,del没有返回值
result = stus.pop(2) # 删除索引为2的元素
result = stus.pop() # 删除最后一个元素
print('result =',result)③ remove()----删除指定值的元素,如果相同值的元素有多个,只会删除第一个
stus.remove('索隆')(3)reverse()----用来反转列表
stus.reverse()(4)sort()----用来对列表中的元素进行排序,默认是升序排列
my_list = list('gxcggg')
my_list = [10,3,5,78,9,22]
print('修改后:',my_list)注意:如果需要降序排列,则需要传递一个reverse=True作为参数
my_list.sort(reverse=True)
print('修改后:',my_list)7.遍历列表:指的就是将列表中的所有元素取出来
# 创建列表
stus = ['路飞','索隆','山治','娜美','乌索普','罗宾','布鲁克'](1)遍历列表
① 通过while循环来遍历列表
创建一个循环,来打印0-3四个数字
i = 0
while i < len(stus):
print(stus[i])
i += 1② 通过for循环来遍历列表
语法:
for 变量 in 序列 :
代码块
for s in stus :
print(s) for循环的代码块会执行多次,序列中有几个元素就会执行几次。
每执行一次就会将序列中的一个元素赋值给变量。所以我们可以通过变量,来获取列表中的元素。
(2)range():range()是一个函数,可以用来生成一个自然数的序列
r = range(5) # 生成一个这样的序列[0,1,2,3,4]该函数需要三个参数:
① 起始位置(可以省略,默认是0)
② 结束位置
③ 步长(可以省略,默认是1)
通过range()可以创建一个执行指定次数的for循环。
for i in range(10):
print(i)
三、切片:切片指从现有列表中,获取一个子列表
通过切片来获取指定的元素:
语法1:
列表[起始:结束]
stus = ['路飞','索隆','山治','娜美','乔巴','乌索普']
print(stus[1:])
print(stus[:3])
print(stus[:])
print(stus)注意:
(1)通过切片获取元素时,会包括起始位置的元素,不会包括结束位置的元素
(2)做切片操作时,总会返回一个新的列表,不会影响原来的列表
(3)起始和结束位置的索引都可以省略不写
① 如果省略结束位置,则会一直截取到最后
![]()
② 如果省略开始位置,则会从第一个位置开始截取
![]()
③ 如果开始位置和结束位置全部省略,则相当于创建了一个列表的副本
![]()
语法2:
列表[起始:结束:步长]
① 步长表示:每次获取元素的间隔,默认值是1
print(stus[0:5:3])![]()
② 步长不能为0,但是可以是负数
# print(stus[::0]) ValueError: slice step cannot be zero
③ 如果是负数,则会从列表的后部向前边取元素
print(stus[::-2]) 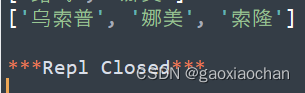
四、序列的通用操作
# 创建一个列表
stus = ['路飞','索隆','山治','娜美','乔巴','乌索普']1、+ 和 *
(1)+可以将两个列表拼接为一个列表
my_list = [1,2,3] + [4,5,6]
print(my_list)(2)*可以将列表重复指定的次数
my_list = [1,2,3] * 5
print(my_list)2、in 和 not in
(1)in用来检查指定元素是否存在于列表中。如果存在,返回True,否则返回False。
print('罗宾' not in stus)
print('罗宾' in stus)(2)not in用来检查指定元素是否不在列表中。如果不在,返回True,否则返回False
3、len()获取列表中的元素的个数
4、min() 获取列表中的最小值,max() 获取列表中的最大值
arr = [10,3,5,7,9,99]
print(min(arr),max(arr))5、两个方法(method):方法和函数基本上是一样,只不过方法必须通过 对象.方法() 的形式调用
(1)s.index()获取指定元素在列表中第一次出现时的索引
print(stus.index('路飞'))index()的第二个参数,表示查找的起始位置,第三个参数,表示查找的结束位置.
print(stus.index('山治',2,7))注意:如果要获取列表中没有的元素,会抛出异常
print(stus.index('罗宾')) # ValueError: '罗宾' is not in list(2)s.count()统计指定元素在列表中出现的次数
print(stus.count('路飞'))五、修改元素
# 创建一个列表
stus = ['路飞','索隆','山治','娜美','乔巴','乌索普']1、修改列表中的元素
(1)直接通过索引来修改元素
stus[0] = 'lufei'
stus[2] = '罗宾'(2)通过切片来修改列表
注意1:在给切片进行赋值时,只能使用序列
stus[0:2] = 123 # TypeError: can only assign an iterable
使用新的元素替换旧元素:
stus[0:2] = ['罗宾','布鲁克']
stus[0:2] = ['罗宾','布鲁克','弗兰奇']
stus[0:0] = ['罗宾'] #向索引为0的位置插入元素注意2:当设置了步长时,序列中元素的个数必须和切片中元素的个数一致
stus[::2] = ['罗宾'] # ValueError: attempt to assign sequence of size 1 to extended slice of size 3
2、 删除元素
(1)通过del来删除元素
del stus[2] #删除索引为2的元素(2)通过切片来删除元素
del stus[0:2]
del stus[::2]注意:以上操作只适用于可变序列。不可变序列无法通过索引来修改。