数据导入与预处理-第4章-pandas数据获取
数据导入与预处理-第4章-pandas数据获取
- 1 数据获取
- 1.1 概述
- 1.2 从CSV和TXT文件获取数据
- 1.2.1 读取csv案例-指定sep,encoding,engine
- 1.2.2 读取csv案例-names和header
- 1.2.3 读取csv案例-指定index_col和usecols
- 1.2.4 读取csv案例-指定nrows和skiprows
- 1.2.5 读取csv案例-指定dtype
- 1.2.6读取csv案例-分块读取chunk
- 1.2.7 读取txt案例
- 1.3读取Excel文件
- 1.3.1 读取Excel案例
1 数据获取
1.1 概述
数据经过采集后通常会被存储到Word、Excel、JSON等文件或数据库中,从而为后期的预处理工作做好数据储备。数据获取是数据预处理的第一步操作,主要是从不同的渠道中读取数据。Pandas支持CSV、TXT、Excel、JSON这几种格式文件、HTML表格的读取操作,另外Python可借助第三方库实现Word与PDF文件的读取操作。本章主要为大家介绍如何从多个渠道中获取数据,为预处理做好数据准备。
1.2 从CSV和TXT文件获取数据
参考连接:https://zhuanlan.zhihu.com/p/340441922
掌握read_csv()函数的用法,可以熟练地使用该方法从CSV或TXT文件中获取数据
CSV(Comma-Separated Values,字符分隔值)和TXT是比较常见的文本格式,其文件以纯文本形式存储数据,其中CSV文件通常是以逗号或制表符为分隔符来分隔值的文本文档,扩展名为“.csv”,可通过Excel等文本编辑器查看与编辑;TXT是微软公司在操作系统上附带的一种文本格式,其文件扩展名为“.txt”,可通过记事本等软件查看。
Pandas中使用read_csv()函数读取CSV或TXT文件的数据,并将读取的数据转换成一个DataFrame类对象。
read_csv(filepath_or_buffer,sep=',', delimiter=None,
header='infer', names=None, index_col=None, usecols=None,
squeeze=False, prefix=None, mangle_dupe_cols=True, encoding=None...)
filepath_or_buffe:表示文件的路径,可以取值为有效的路径字符串、路径对象或类似文件的对象。
sep:表示指定的分隔符,默认为“,”。
header:表示指定文件中的哪一行数据作为DataFrame类对象的列索引,默认为0,即第一行数据作为列索引。
names:表示DataFrame类对象的列索引列表,当names没被赋值时,header会变成0,即选取数据文件的第一行作为列名;当 names 被赋值,header 没被赋值时,那么header会变成None。如果都赋值,就会实现两个参数的组合功能。
encoding:表示指定的编码格式。
有一个csv文件,名称为phones.csv
商品名称,价格,颜色
Apple iPhone X (A1865) 64GB,6299,深空灰色
Apple iPhone XS Max (A2104) 256GB ,10999,深空灰色
Apple iPhone XR (A2108) 128GB,6199,黑色
Apple iPhone 8 (A1863) 64GB,3999,深空灰色
Apple iPhone 8 Plus (A1864) 64GB,4799,深空灰色
Apple iPhone XS (A2100) 64GB,8699,深空灰色
Apple 苹果 iPhone Xs Max 256GB,9988,金色
Apple 苹果 iPhone Xs 64GB,8058,金色
Apple 苹果 iPhone XR 128GB,5788,黑色
Apple iPhone 7 (A1660) 128G,4139,玫瑰金色
1.2.1 读取csv案例-指定sep,encoding,engine
import pandas as pd
evaluation_data = pd.read_csv(
"phones.csv", sep=',',encoding='gbk',engine = 'python')
print(evaluation_data)
engine:使用的分析引擎。可以选择C或者是python。C引擎快但是Python引擎功能更加完备。
encoding:指定字符集类型,即编码,通常指定为’utf-8’
1.2.2 读取csv案例-names和header
- names 没有被赋值,header 也没赋值
evaluation_data = pd.read_csv(
"phones.csv", sep=',',encoding='gbk',engine = 'python')
上面的案例中,names 没有被赋值,header 也没赋值:这种情况下,header为0,即选取文件的第一行作为表头

- names 没有被赋值,header 被赋值:
#不指定names,指定header为1,则选取第二行当做表头,第二行下面为数据
pd.read_csv("phones.csv", encoding='gbk',header=1)
输出为:

- names 被赋值,header 没有被赋值:
pd.read_csv("phones.csv", encoding='gbk',names=['商品名称1','价格1','颜色1'])
输出为:
 可以看到,names适用于没有表头的情况,指定names没有指定header,那么header相当于None。
可以看到,names适用于没有表头的情况,指定names没有指定header,那么header相当于None。
一般来说,读取文件的时候会有一个表头,一般默认是第一行,但是有的文件中是没有表头的,那么这个时候就可以通过names手动指定、或者生成表头,而文件里面的数据则全部是内容。所以这里id、name、address、date也当成是一条记录了,本来它是表头的,但是我们指定了names,所以它就变成数据了,表头是我们在names里面指定的。
- names和header都被赋值:
pd.read_csv("phones.csv", encoding='gbk',names=['商品名称1','价格1','颜色1'],header=0)
输出为:
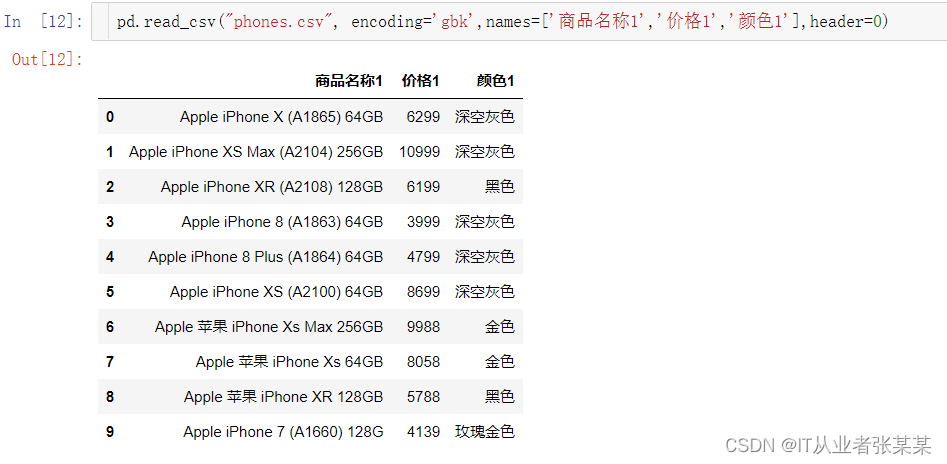
这个时候,相当于先不看names,只看header,header为0代表先把第一行当做表头,下面的当成数据;然后再把表头用names给替换掉。
所以names和header的使用场景主要如下:
- csv文件有表头并且是第一行,那么names和header都无需指定;
- csv文件有表头、但表头不是第一行,可能从下面几行开始才是真正的表头和数据,这个时候指定header即可;
- csv文件没有表头,全部是纯数据,那么我们可以通过names手动生成表头;
- csv文件有表头、但是这个表头你不想用,这个时候同时指定names和header。先用header选出表头和数据,然后再用names将表头替换掉,就等价于将数据读取进来之后再对列名进行rename;
1.2.3 读取csv案例-指定index_col和usecols
- 指定index_col
index_col:我们在读取文件之后所得到的DataFrame的索引默认是0、1、2……,我们可以通过set_index设定索引,但是也可以在读取的时候就指定某列为索引。
pd.read_csv("phones.csv", index_col="商品名称1",encoding='gbk', names=['商品名称1','价格1','颜色1'],header=0)
输出为:

这里,我们在读取的时候指定了name列作为索引;
此外,除了指定单个列,还可以指定多列作为索引,比如[“id”, “name”]。同时,我们除了可以输入列名外,还可以输入列对应的索引。比如:“id”、“name”、“address”、"date"对应的索引就分别是0、1、2、3。
- 指定usecols
usecols:如果一个数据集中有很多列,但是我们在读取的时候只想要使用到的列,我们就可以使用这个参数。
pd.read_csv("phones.csv", usecols=['价格1','颜色1'],encoding='gbk', names=['商品名称1','价格1','颜色1'],header=0)
输出为:

1.2.4 读取csv案例-指定nrows和skiprows
skiprows:表示过滤行,想过滤掉哪些行,就写在一个列表里面传递给skiprows即可。注意的是:这里是先过滤,然后再确定表头
nrows:设置一次性读入的文件行数,在读入大文件时很有用,比如 16G 内存的PC无法容纳几百 G 的大文件。
pd.read_csv("phones.csv",encoding='gbk',nrows = 2,skiprows = [i for i in range(1,9)])
输出为:
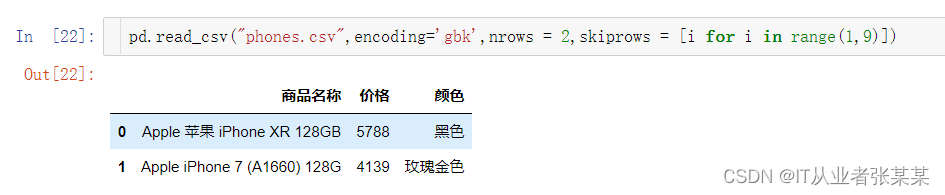 其中skiprows = [i for i in range(1,9)]跳过了前8条数据,nrows = 2输出为跳过之后的2条数据。
其中skiprows = [i for i in range(1,9)]跳过了前8条数据,nrows = 2输出为跳过之后的2条数据。
1.2.5 读取csv案例-指定dtype
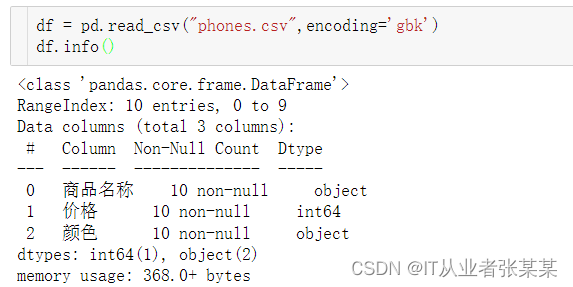
df = pd.read_csv("phones.csv",encoding='gbk')
df.info()
输出为:
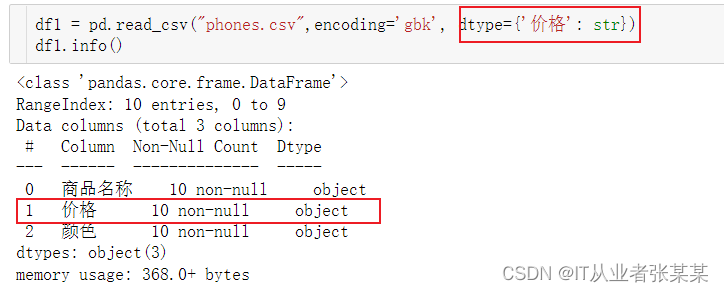
df1 = pd.read_csv("phones.csv",encoding='gbk', dtype={'价格': str})
# 也可以df1['价格'] = df1['价格'].astype("str")
df1.info()
输出为:
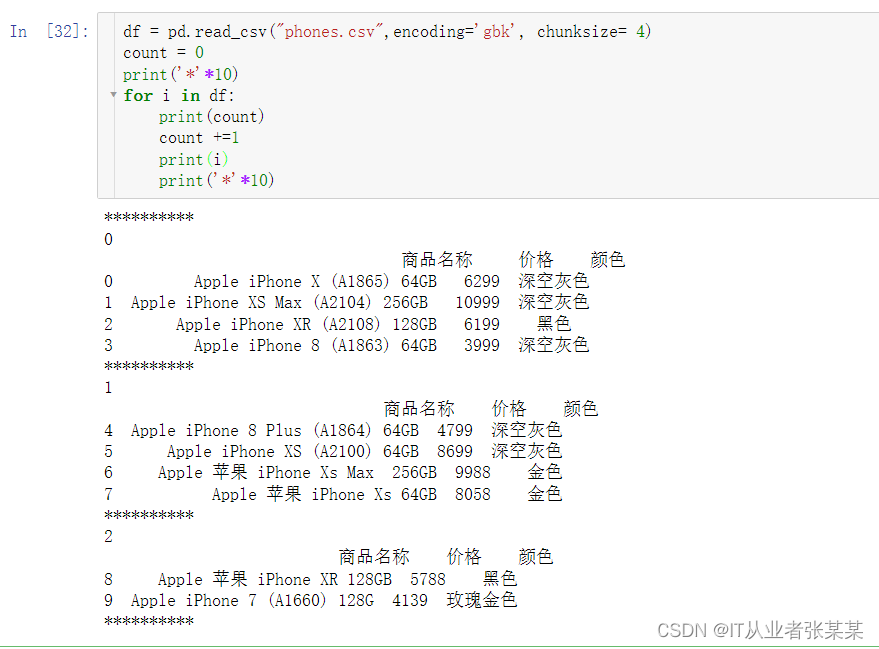
1.2.6读取csv案例-分块读取chunk
df = pd.read_csv("phones.csv",encoding='gbk', chunksize= 4)
count = 0
print('*'*10)
for i in df:
print(count)
count +=1
print(i)
print('*'*10)
输出为:
1.2.7 读取txt案例
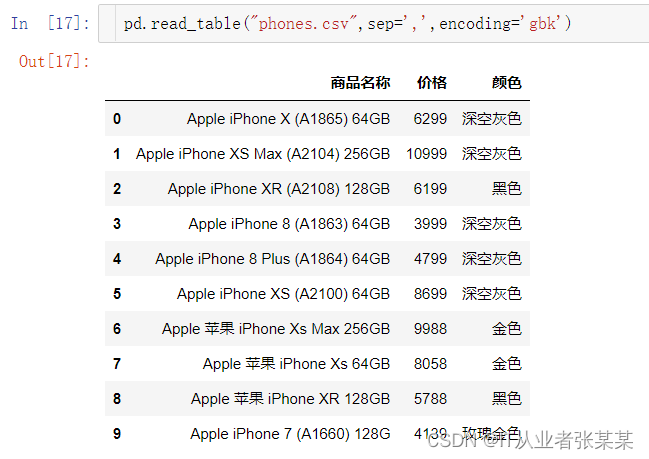
采用read_csv也可以读取txt文件,同时pandas也提供了read_table用于读取文本文件。
pd.read_table("phones.csv",sep=',',encoding='gbk')
输出为:
1.3读取Excel文件
Excel文件(Excel 2007及以上版本的扩展名为.xlsx)是日常工作中经常使用的,该文件主要以工作表存储数据,工作表中包含排列成行和列的单元格。Excel文件中默认有3个工作表,用户可根据需要添加一定个数(因可用内存的限制)的工作表。
Pandas中使用read_excel()函数读取Excel文件中指定工作表的数据,并将数据转换成一个结构与工作表相似的DataFrame类对象。
pandas.read_excel(io, sheet_name=0, header=0, names=None, index_col=None,
usecols=None,squeeze=False, dtype=None, engine=None,converters=None,
true_values=None, false_values=None, skiprows=None, nrows=None,na_values=None,
parse_dates=False, date_parser=None,thousands=None, comment=None,
skipfooter=0,convert_float=True,**kwds)
sheet_name:表示要读取的工作表,默认值为0。
header:表示指定文件中的哪一行数据作为DataFrame类对象的列索引。
names:表示DataFrame类对象的列索引列表。
值得一提的是,当使用read_excel()函数读取Excel文件时,若出现importError异常,说明当前Python环境中缺少读取Excel文件的依赖库xlrd,需要手动安装依赖库xlrd(pip install xlrd)进行解决。或是安装
pip install openpyxl==3.0.9
1.3.1 读取Excel案例
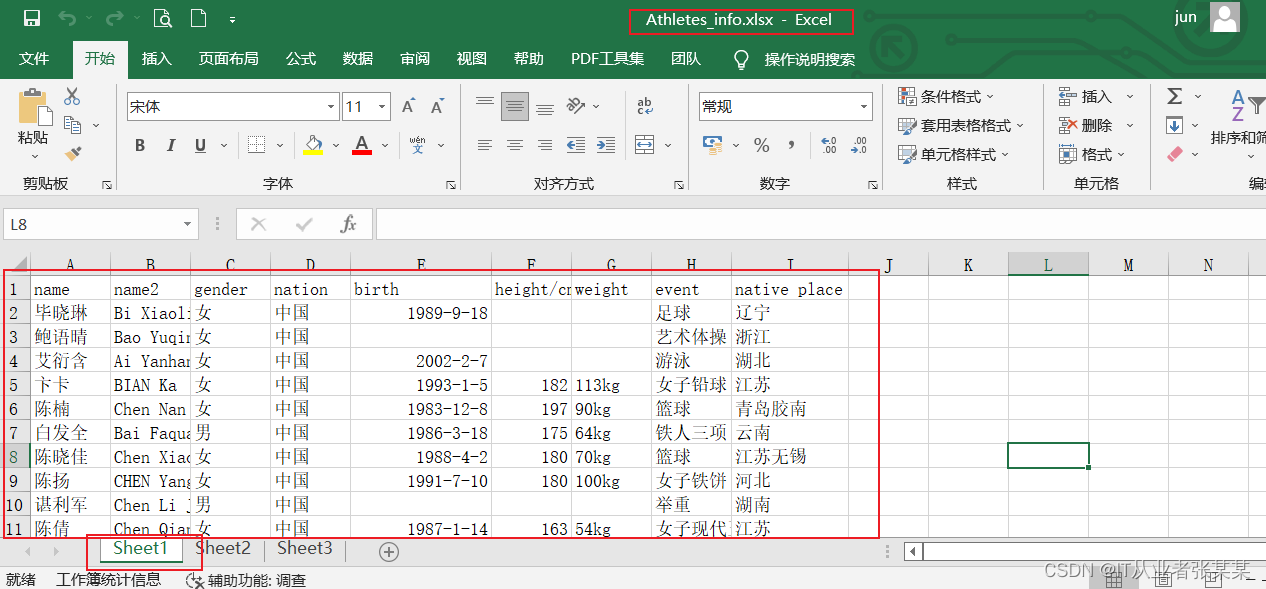
有Excel文件
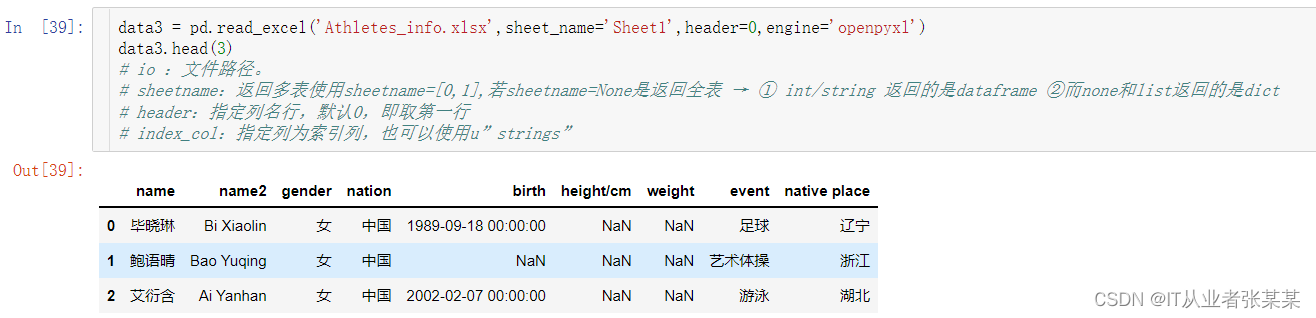
data3 = pd.read_excel('Athletes_info.xlsx',sheet_name='Sheet1',header=0,engine='openpyxl')
data3.head(3)
输出为:
io :文件路径。
sheetname:返回多表使用sheetname=[0,1],若sheetname=None是返回全表 → ① int/string 返回的是dataframe ②而none和list返回的是dict
header:指定列名行,默认0,即取第一行
index_col:指定列为索引列,也可以使用u”strings”
备注:使用 pandas 读取 CSV 与 读取 xlsx 格式的 Excel 文件方法大致相同