Linux系统运维排故思路参考手册
一、前言

Linux运维过程中,我们会遇到一些进程突然出现挂死的状态(即进程处于运行状态,但无法处理请求,比如会报404,但这时服务端口是通的,日志也没显示明显异常,有的会简单给出无法连接某个组件,比如数据库等),那这时我们如何定位排查问题呢,偶然间看到网上一位同学的文章,这里分享一下。
二、故障分析思路
遇到系统问题,有一个清晰的分析思路其实比直接解决问题本身更重要,结合相关经验,大体可从6个方面来分析:


注 : 常见指标含义说明
buffer(写缓冲):是用于存放(缓冲)要输出到disk(块设备)的数据的;
cache(读缓存):是缓存从disk上读出的数据。buffer和cache都是为了提高IO性能,并由OS来管理;
swap:linux内核读写虚拟内存是以 “页” 为单位操作的,把内存转移到硬盘交换空间(SWAP)和从交换空间读取到内存 的时候都是按页来读写的;
Paging:内存和SWAP的这种交换过程称为页面交换(Paging)

1)系统负载和cpu:
这个是最直观的,数据也是最容易获取的,监控软件基本都满足,云平台也可一般都支持显示,通过查看历史数据,或查看当前linux OS的负载和CPU使用率,可首先看系统整体是否超载或当前cpu超载;
load average(平均负载:CPU性能指标):在特定时间间隔内运行队列中(在CPU上运行或者等待运行多少进程)的平均进程数。如果一个进程满足以下条件则其就会位于运行队列中:
- 它没有在等待I/O操作的结果;
- 它没有主动进入等待状态(也就是没有调用’wait’);
- 没有被停止(例如:等待终止);
在Linux中,进程分为三种状态,一种是阻塞的进程blocked process,一种是可运行的进程runnable process,另外就是正在运行的进程running process。当进程阻塞时,进程会等待I/O设备的数据或者系统调用。
进程可运行状态时,它处在一个运行队列run queue中,与其他可运行进程争夺CPU时间。 系统的load是指正在运行running one和准备好运行runnable one的进程的总数。比如现在系统有2个正在运行的进程,3个可运行进程,那么系统的load就是5。load average就是一定时间内的load数量。如果是单核CPU,1是理论的临界值,我们希望负载平均值小于 1.00,对于多核CPU,满负荷状态的数字为 “1.00 * CPU核数”,n核就小于n;单线程任务只会使用一个CPU,不管CPU核数有多少。
2)内存分析
同上,内存指标获取也相对容易,而且内存过载造成的卡死,系统也会假死掉,比如:系统登录执行命令卡慢,远程无法登录,云平台console登录界面卡死没有反应,内核崩溃出现告警等;
3)网络IO与流量:
同上,网络IO及带宽流量数据也获取相对容易,且通过流量趋势图,可判断是否存在网络IO问题,导致网络本身请求无法处理,如果出现网络IO,这时我们的ip一般也会ping不通,端口无法telnet,无法远程登录,网页404,趋势图流量异常增高,不在正常业务激增区间;甚至出现安全问题;
4)磁盘IO与空间使用
如果文件系统使用率占满,也会导致程序阻塞,无法接受响应处理请求,或磁盘直接与OS断联,通信故障,挂载故障,或大量小文件耗尽inode,或进程占用导致删除的文件空间无法释放,类似OOM一样,磁盘空间被累积堆满,导致其上程序阻塞;另外如果是磁盘IO问题,导致读写数据无法满足要求,或写入阻塞,或读延迟,导致系统超时报错等;另外也有可能是文件篡改,中毒等导致磁盘异常;
5)文件描述符fd占用
如4中所述,可能存在很多未被进程释放的文件,显示deleted状态,但占用fd不会释放已经分配到的空间,文件实际被未有效删除,释放空间,导致累积性磁盘使用耗尽问题
6)线程占用与运行
部分线程可能由于以上几种原因阻塞,导致争抢cpu无法释放,CPU显示%之3-400,进程虽然存活,端口也能telnet,但是线程处理某任务,处于阻塞状态,无法自行恢复,因当前可能就是正常的业务处理逻辑,所以并不会触发抛错机制;可分析进程背后线程阻塞的深层次原因定位,看是具体哪些任务/接口调用导致了相关问题;


三、分析工具


1)CPU查看命令
cat /proc/cpuinfo
grep ‘model name’ /proc/cpuinfo | wc -l //查看cpu总核心数命令或
grep -c ‘model name’ /proc/cpuinfo
CPU负载:
#对于单核CPU来说,可参考如下经验判定:
1分钟Load>1,5分钟Load<1,15分钟Load<1:短期内繁忙,中长期空闲,初步判断是一个“抖动”,或者是“拥塞前兆”
1分钟Load>1,5分钟Load>1,15分钟Load<1:短期内繁忙,中期内紧张,很可能是一个“拥塞的开始”
1分钟Load>1,5分钟Load>1,15分钟Load>1:短、中、长期都繁忙,系统“正在拥塞”
1分钟Load<1,5分钟Load>1,15分钟Load>1:短期内空闲,中、长期繁忙,不用紧张,系统“拥塞正在好转
1、top命令
shift + h 按线程查看cpu消耗情况
查看每个核消耗情况
us 过高说明应用程序消耗了大部分cpu
sy 过高表示系统线程切换频繁
wa 表示为在执行过程中等待io所占的百分比 hi 硬件中断(ex:网卡接收数据频发)
top -p pid 多列信息列表中直显示对应进程信息.


其中,状态D,表示 uninterruptible sleep,这种状态是不可中断的,无论是kill,kill -9,还是kill -15。处于D状态的进程通常是在等待IO,比如磁盘 IO,网络 IO,其他外设 IO。如果处于D状态的时间较长,意味着可能是IO设备本身出了故障,需要排查设备是否正常。
2、查看CPU占用最多的前10个进程
ps auxw | head -1;
ps auxw | sort -rn -k3 | head -10
3、uptime 查看 load average
00:13:49 up 117 days, 13:22, 2 users, load average: 0.00, 0.01, 0.05
4、htop查看: Load Average和Uptime和各个进程的耗用详情,内存
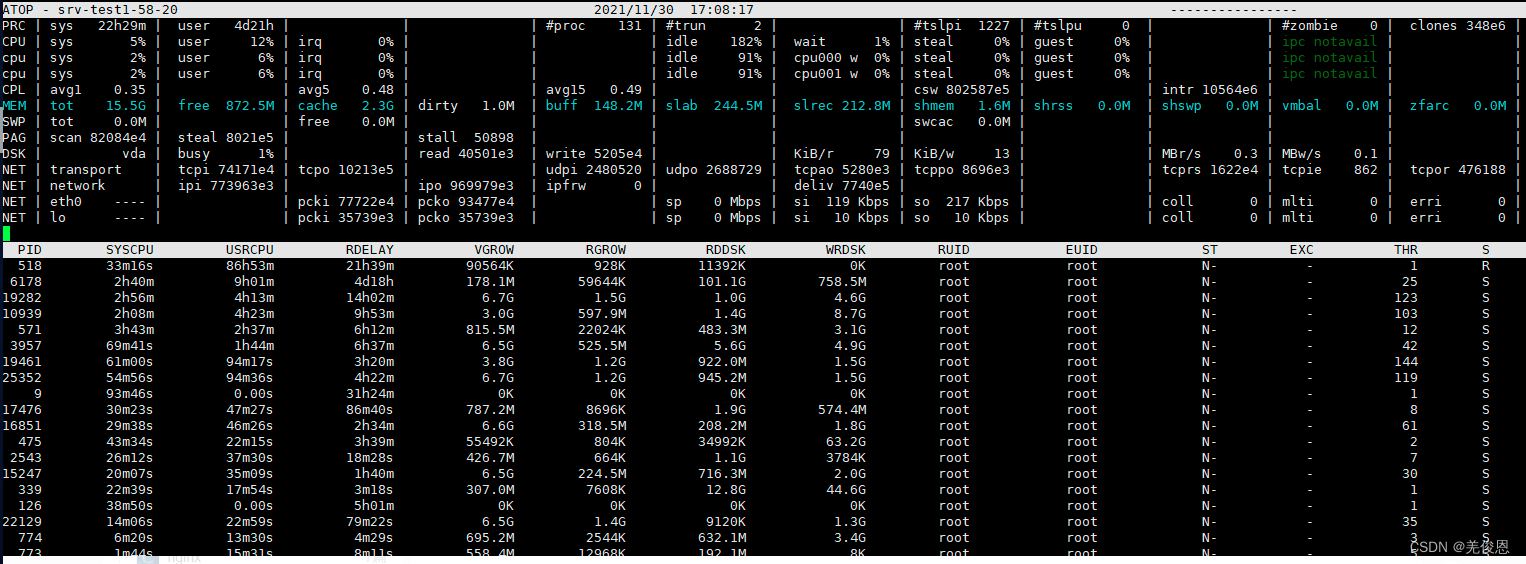
5、atop命令:
CPU列显示CPU整体(即多核CPU作为一个整体CPU资源)的使用情况,我们知道CPU可被用于执行进程、处理中断,也可处于空闲状态(空闲状态分两种,一种是活动进程等待磁盘IO导致CPU空闲,另一种是完全空闲);各个字段指示值相加结果为N00%,其中N为cpu核数。
sys、usr字段:指示CPU被用于处理进程时,进程在内核态、用户态所占CPU的时间比例
irq字段:指示CPU被用于处理中断的时间比例
idle字段:指示CPU处在完全空闲状态的时间比例
wait字段:指示CPU处在“进程等待磁盘IO导致CPU空闲”状态的时间比例
csw字段:指示上下文交换次数
intr字段:指示中断发生次数
6、dstat命令
dstat 2 10 //每2秒采集一次共采集10次,默认dstat每秒都会刷新数据,输出结果说明:
cpu列里:hiq、siq分别为硬中断和软中断次数;当CPU的状态处在"waits"时,那是因为它正在等待I/O设备(例如内存,磁盘或者网络)的响应而且还没有收到。
system列:int、csw分别为系统的中断次数(interrupt)和上下文切换次数(context switch);这项统计仅在有比较基线时才有意义。这一栏中较高的统计值通常表示大量的进程造成拥塞,需要对CPU进行关注。
dstat 是一个可以取代vmstat,iostat,netstat和ifstat这些命令的多功能产品。它增加了一些另外的功能,增加了监控项,也变得更灵活了,它还支持输出CSV格式报表,并能导入到Gnumeric和Excel以生成图形。dstat可以很方便监控系统运行状况并用于基准测试和排除故障。我们可实时地看到所有系统资源,例如:通过统计IDE控制器当前状态来比较磁盘利用率,或者直接通过网络带宽数值来比较磁盘的吞吐率(在相同的时间间隔内)。yum -y install dstat 即可安装。
常用参数:
-l :显示负载统计量
-m :显示内存使用率(包括used,buffer,cache,free值)
-r :显示I/O统计
-s :显示交换分区使用情况
-t :将当前时间显示在第一行
–fs :显示文件系统统计数据(包括文件总数量和inodes值)
–nocolor :不显示颜色(有时候有用)
–socket :显示网络统计数据
–tcp :显示常用的TCP统计
–udp :显示监听的UDP接口及其当前用量的一些动态数据
-c:表示只显示我们的CPU信息
-p:表示只显示我们的进程信息
-n:表示只显示我们的网络信息
-–disk-util :显示某一时间磁盘的忙碌状况
-–freespace :显示当前磁盘空间使用率
-–proc-count :显示正在运行的程序数量
-–top-bio :指出块I/O最大的进程
-–top-cpu :图形化显示CPU占用最大的进程
-–top-io :显示正常I/O最大的进程
-–top-mem :显示占用最多内存的进程
eg1: dstat 2 10
You did not select any stats, using -cdngy by default.
----total-cpu-usage---- -dsk/total- -net/total- ---paging-- ---system--
usr sys idl wai hiq siq| read writ| recv send| in out | int csw
2 0 98 0 0 0| 26k 39k| 0 0 | 0 0 |2222 3985
1 1 98 0 0 0| 0 0 |6458B 19k| 0 0 |3905 8052
2 1 97 0 0 0| 0 0 | 24k 21k| 0 0 |4397 8494
6 1 94 0 0 0| 0 116k| 22k 37k| 0 0 |5466 9090
1 1 98 0 0 0| 0 0 |7846B 19k| 0 0 |3777 7509
1 1 98 0 0 0| 0 76k|6141B 17k| 0 0 |3802 7597
1 1 99 0 0 0| 0 0 |2350B 10k| 0 0 |4071 7912
2 1 98 0 0 0| 0 0 | 23k 19k| 0 0 |4274 8029
1 1 98 0 0 0| 0 116k| 25k 40k| 0 0 |4314 8235
1 1 98 0 0 0| 0 0 | 15k 21k| 0 0 |3820 7635
1 1 98 0 0 0| 0 182k|9072B 20k| 0 0 |4550 8393
eg2:dstat -c -y -l --proc-count --top-cpu //显示CPU资源损耗
eg3:dstat -g -l -m -s --top-mem //查看全部内存占用
eg4:dstat –output /tmp/sampleoutput.csv -cdn //输出一个csv格式的文件
7、perf 工具
perf 是一个调查 Linux 中各种性能问题的有力工具。该工具包包含了:perf-stat (perf stat), perf-top (perf top), perf-record (perf record), perf-list (perf list);perf 是 Linux 2.6.31 以后内置的性能分析工具,没有的话 yum install perf -y安装。它以性能事件采样为基础,不仅可以分析系统的各种事件和内核性能,还可以用来分析指定应用程序的性能问题。使用 perf 分析 CPU 性能非常好用。常见用法是 perf top,类似于 top,它能够实时显示占用 CPU 时钟最多的函数或者指令,可以用来查找热点函数;perf top 虽然实时展示了系统的性能信息,但它的缺点是并不保存数据,也就无法用于离线或者后续的分析。这时我们可使用perf record ,它提供了保存数据的功能,保存后的数据,可以用 perf report 解析展示。实际使用中,我们还经常为 perf top 和 perf record 加上 -g 参数,开启调用关系的采样,方便我们根据调用链来分析性能问题,注意采样数据过少的话数据会不准确。另外需要对内核比较了解,才有利于正确分析相关调用。
eg1: perf top -e xxx //-e后跟perf list里列出来的事件类型,查看对应的程序事件耗用资源情况
eg2:perf top -e cpu-clock //查看CPU的使用
eg3:perf top -e faults //查看 page faults
eg4:perf top -e block:block_rq_issue //查看系统IO的请求,比如可以在发现系统IO异常时,可以使用该命令进行调查,就能指定到底是什么原因导致的IO异常。 block_rq_issue 表示 block_request_issue 就是IO请求数。
eg5:perf top -g -p 1234 //实时查看进程1234CPU耗用,-g:可以查看堆栈调用;-a:查看所有CPU
eg6:perf record -ag -- sleep 15 perf report //查看CPU事件占比,调用栈,CPU使用情况

8、ps命令
eg1:ps aux --sort=-%cpu //按CPU使用率排序,找出CPU消耗最多进程
eg2:
案例1: CPU使用率高,IO无作业,Load Average低,系统反应颠簸
这种场景,通常是计算密集型任务,即大量生成耗时短的计算任务。这种任务会占满CPU资源,造成系统响应速度颠簸,但由于每个任务能快速计算完成,不会在运行队列堆积,所以在Load Average里不会体现出来。
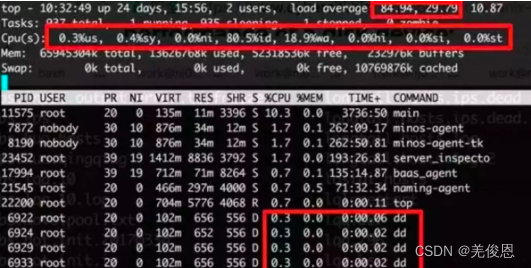
案例2: CPU使用率低,IO等待,Load Average高,系统不卡
如下图模拟场景:
dd if=/dev/zero of=testx.img bs=512count=1000000 oflag=dsync //
这种场景,通常是IO密集型任务,如果大量请求都集中于相同的IO设备,超出设备的响应能力,会造成任务在运行队列里堆积等待,也就是D状态的进程堆积,那么此时Load Average就会飙高。由于任务都处于等待状态,所以Load Average的值虽然很高,但系统响应速度不受影响。
案例3: CPU使用率低,IO繁忙,Load Average低,系统卡
这种场景,通常是低频大文件读写,由于请求数量不大,所以任务都处于R状态,Load Average数值反映了当前运行的任务数,不会飙升,IO设备处于满负荷工作状态,导致系统响应能力降低。模拟命令:
少量写大文件:dd if=/dev/zero of=testx.img bs=5120000count=10000 oflag=dsync //可看到dd程序都处于R状态
案例4: CPU使用率高,IO繁忙/等待,Load Average高,系统卡
这种场景,通常是服务混部,即IO、计算密集型任务混部在一起,相当于CPU、IO都处于高负荷状态,那么Load Average 自然很高。
2)内存查看定位
1、top
2、free
3、
4、ps
eg1:ps -eo pid,comm,rss | awk ‘{m=$3/1e6;s[“*”]+=m;s[$2]+=m} END{for (n in s) printf"%10.3f GB %s\n",s[n],n}’ | sort -nr | head -20 //统计前20内存占用;
eg2:awk ‘NF>3{s[“"]+=s[$1]=$3$4/1e6} END{for (n in s) printf”%10.1f MB %s\n",s[n],n}’ /proc/slabinfo | sort -nr | head -20 //统计内核前20slab的占用;slab是动态内存管理的一个算法机制,
3)网络负载分析
4)存储分析
5)文件系统分析
6)进程、线程分析
1、htop命令/工具
htop 是Linux系统中的一个互动的进程查看器,一个文本模式的应用程序(在控制台或者X终端中),需要ncurses。与Linux传统的top相比,htop更加人性化。它可让用户交互式操作,支持颜色主题显示,可横向或纵向滚动浏览进程列表,并支持鼠标操作。安装只需要sudo apt install htop;
htop相比较top的优势:
可以横向或纵向滚动浏览进程列表,以便看到所有的进程和完整的命令行。
在启动上比top 更快。
杀进程时不需要输入进程号。
htop 支持鼠标选中操作(反应不太快)。
top 已不再维护。
参数:
-C --no-color 使用一个单色的配色方案
-d --delay=DELAY 设置延迟更新时间,单位秒
-h --help 显示htop 命令帮助信息
-u --user=USERNAME 只显示一个给定的用户的过程
-p --pid=PID,PID… 只显示给定的PIDs
-s --sort-key COLUMN 依此列来排序
-v –version 显示版本信息
使用说明:
每一个CPU的总用量情况,注意这条上面会有不同的颜色:
蓝色:显示低优先级(low priority)进程使用的CPU百分比。
绿色:显示用于普通用户(user)拥有的进程的CPU百分比。
红色:显示系统进程(kernel threads)使用的CPU百分比。
橙色:显示IRQ时间使用的CPU百分比。
洋红色(Magenta):显示Soft IRQ时间消耗的CPU百分比。
灰色:显示IO等待时间消耗的CPU百分比。
青色:显示窃取时间(Steal time)消耗的CPU百分比。
快捷键:
u – 用于显示特定用户拥有的所有进程。
P –用于基于高CPU消耗对进程进行排序。
M –用于基于高内存消耗对进程进行排序。
T –用于根据时间段对过程进行排序。
h –用于打开帮助窗口并查看此处未提及的更多快捷方式
上下键或PgUP, PgDn 选定想要的进程,左右键或Home, End 移动字段,当然也可以直接用鼠标选定进程;
Space 标记/取消标记一个进程。命令可以作用于多个进程,例如 “kill”,将应用于所有已标记的进程
U 取消标记所有进程
s 选择某一进程,按s:用strace追踪进程的系统调用
l 显示进程打开的文件: 如果安装了lsof,按此键可以显示进程所打开的文件
I 倒转排序顺序,如果排序是正序的,则反转成倒序的,反之亦然
+, - 在树视图模式下,展开或折叠子树。当子树折叠时,进程名称左侧会显示一个“+”号
a (在有多处理器的机器上) 设置 CPU affinity: 标记一个进程允许使用哪些CPU
u 显示特定用户进程
M 按Memory 使用排序
P 按CPU 使用排序
T 按time+ 使用排序
F 跟踪进程: 如果排序顺序引起选定的进程在列表上到处移动,让选定条跟随该进程。这对监视一个进程非常有用:通过这种方式,你可以让一个进程在屏幕上一直可见。使用方向键会停止该功能。
K 显示/隐藏内核线程
H 显示/隐藏用户线程
Ctrl-L 刷新
Numbers PID 查找: 输入PID,光标将移动到相应的进程上
2、atop命令
atop是一款用于监控Linux系统资源与进程的工具,它以一定的频率记录系统的运行状态,所采集的数据包含系统资源(CPU、内存、磁盘和网络)使用情况和进程运行情况,并能以日志文件的方式保存在磁盘中,服务器出现问题后,我们可获取相应的atop日志文件进行分析,其比较强大的地方是其支持我们分析数据时进行排序、视图切换、正则匹配等处理。
7)日志分析
8)内核问题
9)安全问题
10)平台关联问题
11)人为问题
附录:
1)常见架构

2)启动过程
BIOS加电自检—MBR引导—加载grub界面—加载liunx内核参数及文件系统—运行init进程—系统初始化—用户登录系统
BIOS的主要作用是检测连接硬件提供给操作系统和寻找启动(设备)硬盘并找到主引导记录MBR移交控制权。
MBR作为主引导记录负责加载grub并一起定位和加载 Linux 内核到内存中,grub转移控制权到内核。
内核启动后会向bios查询电脑的所有硬件信息,内核会试着驱动这些设备。
内核会尝试挂载根文件系统,根文件系统至少包含 /etc /bin /sbin /lib /dev 这5大目录
挂载了根文件系统后,就会启动init服务。
init 程序首先是需要读取配置文件 /etc/inittab(配置文件),根据这个文件的信息来进行初始化工作.。

相关更多可参看:附
3)文件存储
