如何处理百亿级别的数据信息
导读:本次分享将从以下几个方面进行分享,首先讲一下我们目前所做的工作,目前平台架构是怎么样的,第二个是大量日志情况下如何收集,第三个涉及百亿数据后如何快速存储以及快速查询,第四个讲一下数据存储后如何对数据进行聚合分析,挖掘出更有价值的信息。
--
01 平台简介
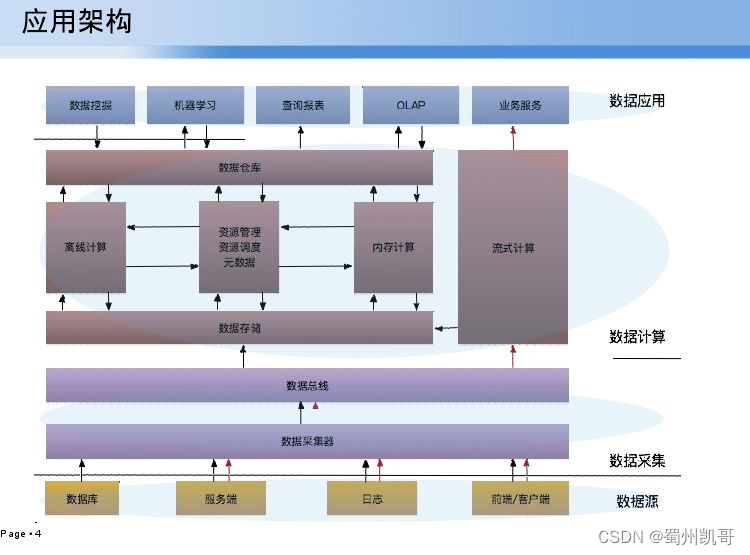
我们的平台架构是基于Hadoop的办公生态插件,比如Ambari、spark、Flume等。基本上分为四个层次,第一个数据源,主要是收集数据库mysql、mongodb、redis等数据,再一个就是服务端日志(基于log4j)、前端/客户端数据;这些数据通过不同的数据采集器进行收集,最后通过一个数据总线中转到数据存储中,这是第二层数据采集;第三层就是数据计算,落地于Hbase、HDFS存储,基于hive的离线计算分析、内存计算会用spark,流式计算会用storm,主要用来实时统计和监控;最顶层就是数据应用,目前业务服务比较多,查询报表、数据挖掘我们会把数据中转dm组、风控组、安全组进行数据应用。

02 日志收集
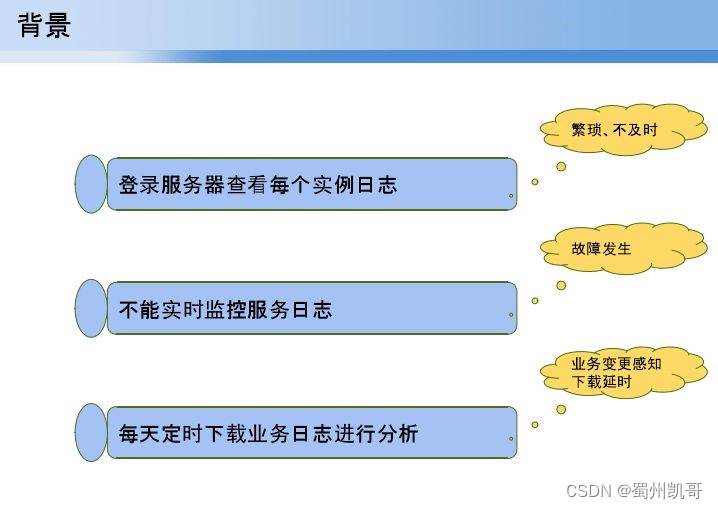
接下来讲解日志收集是如何收集的,当我们服务量比较大的时候,会面临过一亿到百亿阶段,会面临登录服务器如何查看日志的问题,第二个就是这样的日志如何实现实时监控,对一个业务状态有个基本的了解,第三个就是定时下载一个业务日志进行分析。基于这三个点带来的一些问题如繁琐、不及时,故障发生后才知道什么导致,还有业务感知。
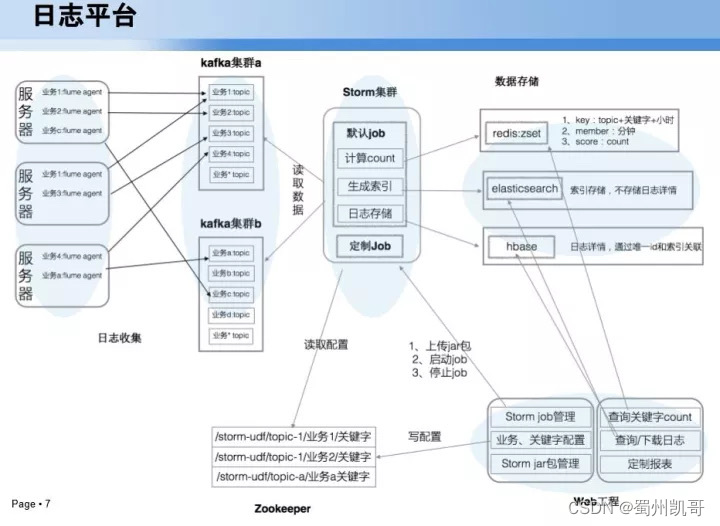
基于上面三个问题,构建了一个日志平台,一个就是收集器,目前在每台服务器上部署flume agent,基于flume自己实现的数据收集器,收集后以kafka集群作为数据中转。第一部分数据基于storm,生成一些索引方式,计算count等流式处理,接下来就会存到redis、Hbase,最后会基于一个web工程进行相关管理。这就是目前日志平台处理。
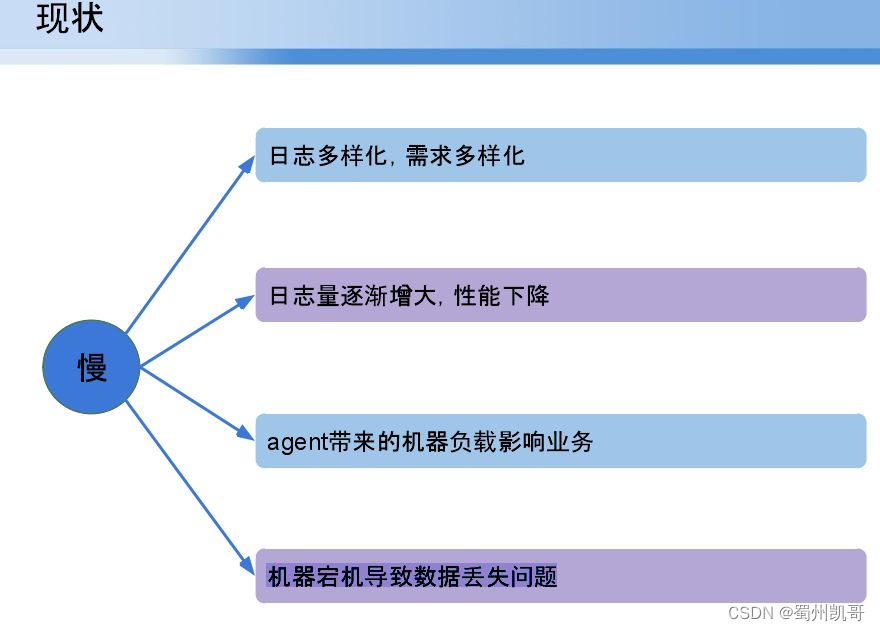
日志平台上线后,开始速度是每秒上万,随着服务逐渐增多,会上升每秒十万,会带来一个性能慢的问题:日志多样化,需求多样化;日志量逐渐增大,性能下降;agent带来的机器负载影响业务(每个目录服务端日志非常多,成千文件会实时变化,导致机器负载较高);机器宕机导致数据丢失问题。
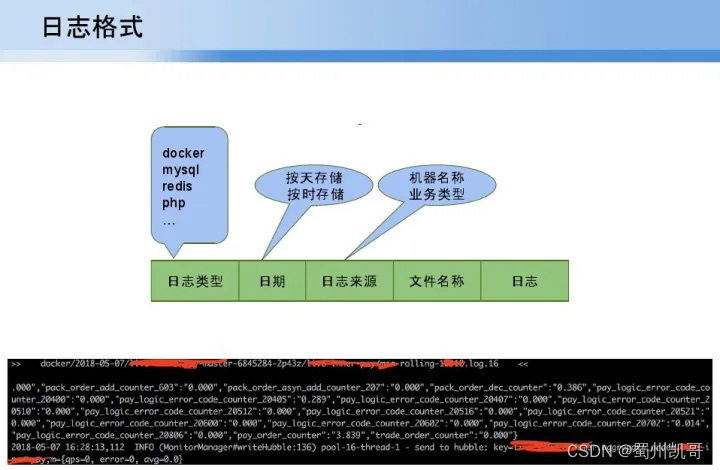
基于上面的问题,第一个在日志需求多样化情况下,对日志进行一个规范化的定义。首先会基于第一层做一个大的分类,每一个大类按照实时的要求,比如按天计算还是小时计算,进行一个日期划分;接下来根据不同日志来源,我们会以业务类型划分日志的来源;接下来文件的名称,文件在服务器的位置就用全量标识文件的唯一地址;最后一个就是文件中每一行日志中实际标识的原始日志位置。下图是我们收集后通过客户端查阅的日志,第一层代表一个docker,第二个是按天存储的日期类型,接下来docker标识唯一id,后面是实际业务的日志,下面就是原始日志类型。
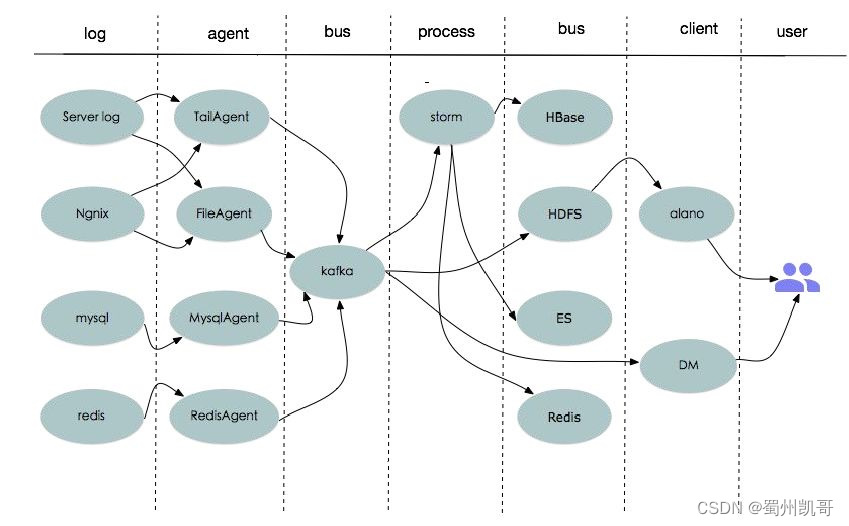
经过上面处理后,分析到底性能慢在哪,每一层数据流流向。
第一层日志通过(比如服务端日志)tailagent、fileagent、mysqlagent、redisagent,最后收集到kafka,在数据量大情况下tailagent会非常慢,比如一个目录有上百个文件,收集的时候每个文件每秒一千的话,这个量在单线程下完全来不及文件消费;
再一个像目前开源flume agent中对tailagent收集是不保证数据丢失的,不保证每一个文件读取游标保存;
第三个问题就是若业务方要求数据非常实时,日志延迟不能超过一百毫秒,我们引入redisagent,就是业务方将数据导入redis中,我们进行100毫秒的针对处理,这样经过对阿agent层的优化,基本可以解决性能延迟、查询延迟等问题。
所有的数据存储kafka后,当时kafka是按照数据库类型进行大类topic划分,带来的问题就是数据热点问题,比如agent日志量非常大,但是服务端日志有时因为业务问题,量不是很多会导致topic量非常大,客户端消费会产生延迟、堵塞,接下来会在kafka层对数据量大的(比如每秒十万)会进行topic划分。到了storm层,基本对kafka进行队列消费,基本能满足性能。Storm后会将数据存储hbase、redis,在客户端为了方便浏览日志,开发了alano客户端日志,相当于在Linux下TL-f或者下载一个文件,第二个就是DM客户端,主要用来把收集到日志中转给DM或风控或安全组。
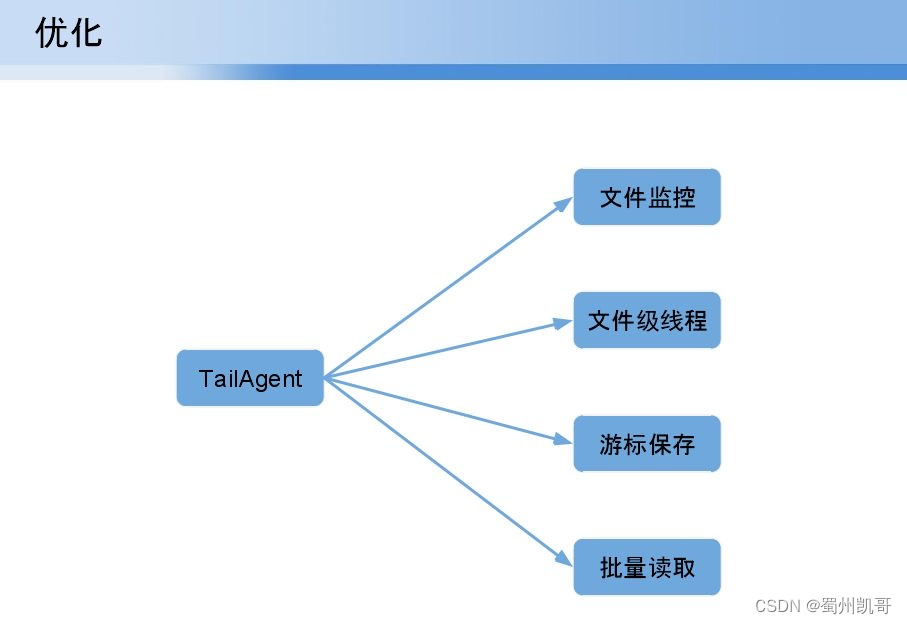
接下来讲一下对tailagent做了哪些优化,(1)文件监控。实时监控文件的变化;(2)文件级线程。针对每一个文件引入一个线程,如果一个文件比较大会单独分一个线程处理。(3)游标保存,每一个文件的读取根据日志读取实时性要求会在每个一秒进行保存在本地或zommtable。(3)批量读取。为了提升性能,单行读取很慢,超过一定时间或一定行数批量读取,将数据传到agent,通过agent传到kafka。
对于redis主要解毫秒级的延迟问题,对于客户端通过RPUSH将数据打到队列中,在每一台服务器上部署一个redisagent,通过LPOP或者TRANSACTION进行消费。对于每秒在一万数据量LPOP能够满足,当达到每秒5-10万,引入LRANGE+LTRIM组合方式实现批量读取。

基于日志平台架构以及优化,目前线上应用有百台计算存储,一个队列服务器,实现实时监控服务状态,每天百亿日志中转量以及秒级客户端平均延迟。三者分别应用于不同业务方,实时监控实时状态是业务需求,每天百亿日志中转量对DM、风控、安全组的数据中转,秒级客户端平均延迟方便大家日志排查,如服务出问题不会登陆每台服务器,而是通过客户端查看所有日志的情况。
--
03 数据存储
数据收集后数据是如何存储的,存储后上百亿的数据如何实现秒内查询,上百亿数据如何用更少的数据节点存储,业务服务如何确保线上服务24小时无宕机服务,最重要的点就是数据不能丢。基于这四点,对于秒级查询采用HBase机制,第一通过服务高可用Hmaster,部署三个Hmaster,任何一台出状况可以实现秒级切换,保证服务可用性,秒价查询会对Blockcache要求非常高,平均读入写入请求量,最后数据落到DataNode,对数据要求可靠性高,将副本增到五个节点,能够保证数据一直存在。
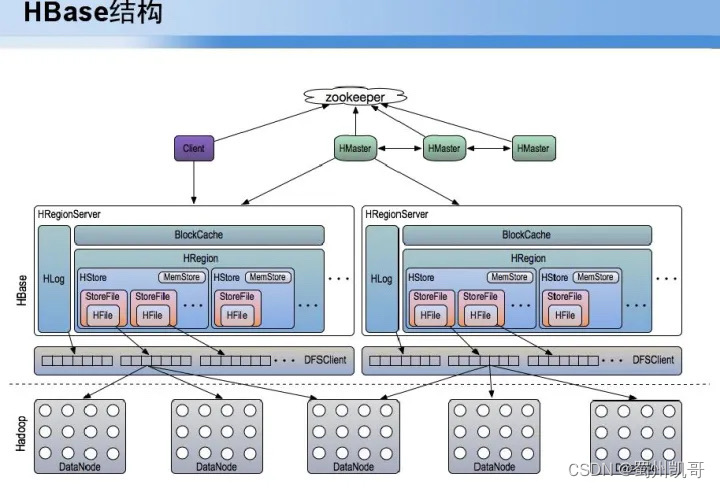
接下来介绍实现HBASE高可用实用性方面的探索,(1)Namenode进程死机(2)Hmaster进程死机(3)datanode磁盘坏掉或整个机器挂掉(4)namenode元数据丢失能否快速恢复等问题。
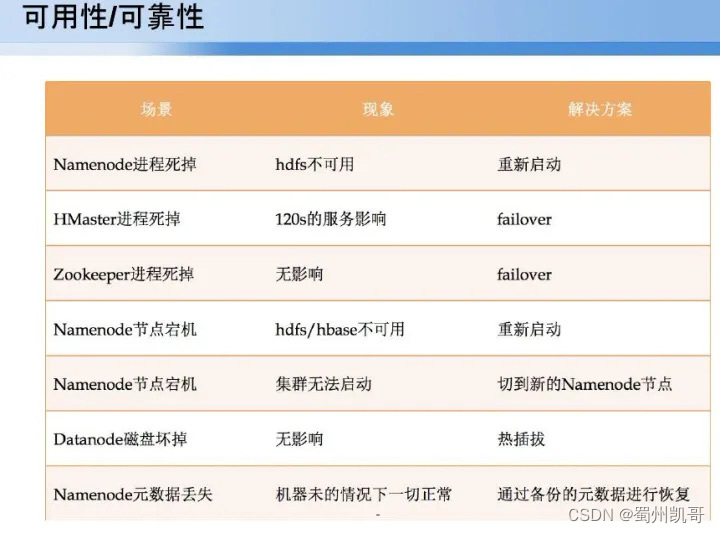
如何在数据节点比较少的情况下存储几十TB到百TB的数据,当前压缩技术有snappy、lzo、gzip,最后选型为snappy,因为它在压缩比例和性能读取方面,读取解压方面要远远好于gzip,压缩性能又优于lzo。

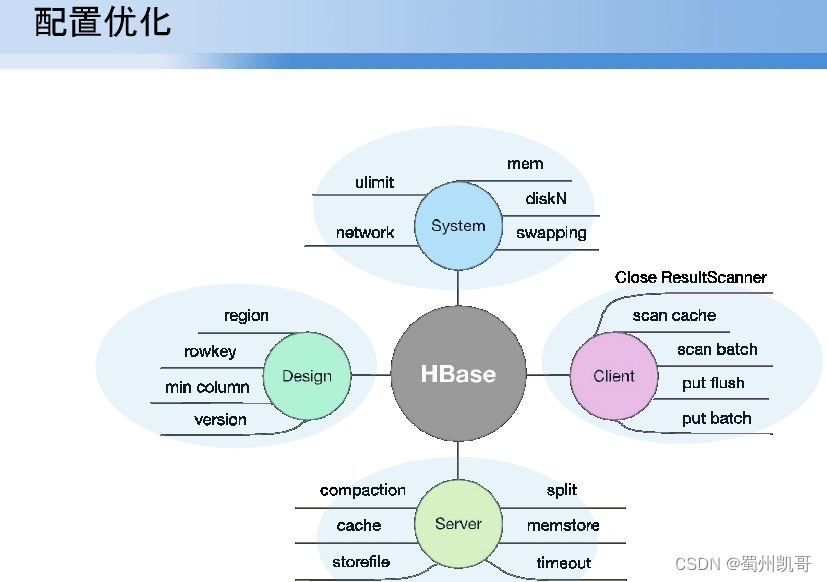
在解决完压缩后,就要解决如何实现服务的秒级查询,以及一台服务down后不应影响查询,或者服务GC导致查询延迟秒级以上。
解决方案有以下几个方面:
(1)系统级别的优化。比如磁盘选型、swapping的禁用、网络参数优化等;
(2)服务级别优化。如读写请求的量如何配置cache、menstore,对于大文件下如何压缩保证文件不能太大或太小;
(3)客户端。如何保证如果服务端gc,某一服务down后,查询保证服务的可用性;
(4)设计时,这是最重要的阶段,如果你的索引设计不好查询肯定不好。比如对hbase的rowkey是单行多列还是多行单列,这要基于业务选型。
接下来讲一下机器选型,HMaster、Name Node、zoomkeeper等我们需要用什么样的机器,数据节点采用什么机器,加入服务要求性能比较高,数据节点对磁盘RAID比较高,可以选择600G磁盘选型,还是不够,可以选择SSID,如果对查询耗时要求比较低,但存储量又较大,可以选择3T的大盘。
接下来讲一下表设计,基于业务、场景不一样,选择表设计也不一样。什么样的业务可以选择多列,什么样的业务选择多行,假如对邮件的访问,是每个邮件做一个C1,C2、C3,还是我的邮件和别人的做一个rowkey的查询等。

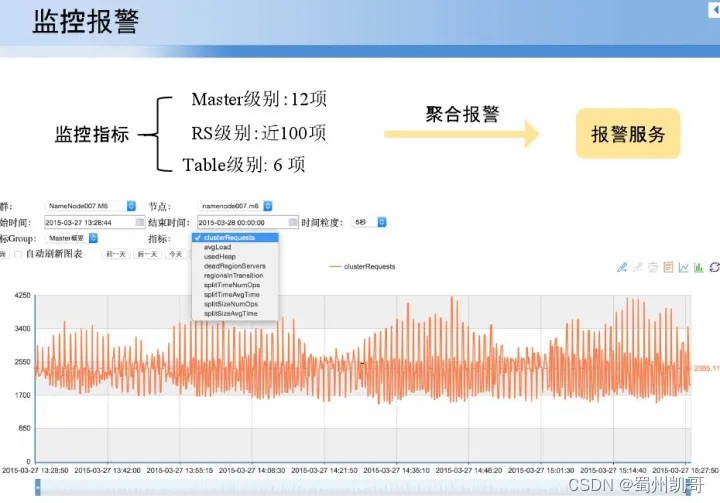
完成上面后,要做好监控报警,对master监控,RS监控,table监控,下面是对一个集群七个节点监控情况。
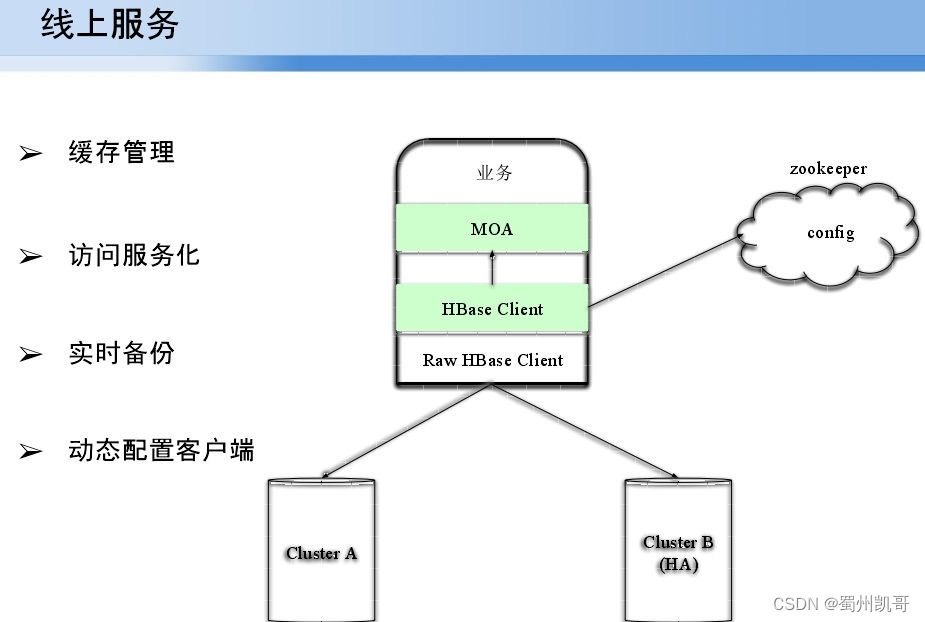
下图是线上的服务架构,主要解决了基于原生的Raw HBase Client进行缓存管理,访问的服务化,实时备份以及动态配置客户端。实时备份主要解决当HBase一个agent服务挂掉后可以无感知的切换到另一台机器进行数据读取。目前线上应用有几十个集群,上百个数据节点,在线业务量几百T左右,出来span数据外数据都需要实时查询。
数据存储有的使用hbase,但是有的需要进行离线分析吗,因此会选择存储到hive中,接下来讲一下对于大数据,hive是如何进行分析的。
--
04 聚合分析
数据收集后,会得到很多表,每个表数据量都很大,最大的上百亿,因此选型用hive。架构如下,taskdrive,tasktracker最终获取结果 ,真正运行总数据量在300亿情况下,十几个小时无法跑完。
你如何解决呢?首先系统级别磁盘IO,CPU,内存,网络。
这是基本要求,内存至少要96g,cpu至少24核,网络如果说计算密集型网络io不是很密集千兆网络基本能满足高性能计算;表进行join,groupby进行外页过滤会发现生成N多个job而map数少,map少导致并行计算的量很大,输出量很大带来内存消耗过大,job的map少导致并行计算度不够影响执行的效果;job数过多,8张表最终可以优化为7个,在原始执行下可能会生成12个,job耗时严重;第四个最重要的,也是hive中常遇到的,数据倾斜,map影响不大 reduce阶段非常慢(256个前255执行完最后一个耗时很长),这是因为数据倾斜导致分区不均匀,某一个reduce分区可能会是其他分区的几十倍或几百倍。
基于上面的问题,做了几方面的优化:硬件优化,应用软件优化,比如操作系统选择,网络参数如何配置降低网络IO消耗,Hadoop软件优化基本就是DataNode层次优化,配置优化,主要是hive如何配置实现解决数据倾斜的问题、map过少的问题等。
接下来介绍下map过少、数据量较大如何解决,用join,选型是bucket,如果你用普通join进行上十亿数据的join话,耗时达七八个小时,选用bucket能缩短三分之二的时间;对sort优化;文件系统选型,数据录入hive有txtfile、enforcefile等选择哪一种数据存储;数据倾斜,要保证数据倾斜在hive能够自动处理决策,其次数据分区时保证分区均匀。
经过上面基本配置,重新对表的join进行梳理,首先如何减少job数,同时每一个job的map数增大。第一选择一个小表和一个大表进行map join,出来的结果尽可能变小,将结果集和另一个大表进行join,最后得出一个上千万聚合后的表,依据过滤条件少的进行join形成bucket join或普通的join,按照顺序join基本能解决job数过多的问题。
在hive进行数据分析的过程中,需要考虑的点有:
(1)尽量早地过滤数据,减少每个阶段的数据量,分区表要加分区且只选择需要使用到的字段;
(2)尽量原子化操作,避免一个 SQL包含复杂逻辑,可以使用中间表来完成复杂逻辑。因为会形成更多job数,尽量保证每一个sql语句就是一个简单select 的where条件或group by等,生成结果用中间表与其他表进行join,而不是包含在语义中直接使用;
(3)单个SQL所起的JOB个数尽量控制在5个以下;
(4)慎重使用mapjoin,否则会引起磁盘和内存的大量消耗。Mapjoin在小表和大表中性能提升很大,因为是纯内存加载,但是使用不当容易导致机器死机,内存耗尽;
(5)SQL要先了解数据本身的特点,要注意是否有数据倾斜,数据过滤后大约过滤什么样的级别,那些表应该首先做join,获得一个比较小的结果集,再用结果集和其他表join。
基于这五个原则在写hql语句时能够避免job过多map过少的问题,以及reduce阶段某一reduce执行慢的情况。

通过上面数据收集、存储以及数据的分析,最后结果是性能提升,如何实现数据及时收集,如何实现百亿数据的实时查询,最后尽量实现在大量数据量情况下能够把一个报表结果迅速给出来。
最简单粗暴的办法就是横向扩展堆机器,主要是保证机器横向扩展时能解决在数据量不变情况下能够线性增长,再线性增长变化不是太大情况下,就要考虑优化sql语句,软件配置,hive中有没有配置bucket,join有没有配置一些数据集倾斜参数,选择的是什么样的文件系统。
考虑这些后我们系统的优化,在处理上百T数据量下,可能文件数过多导致机器文件数不够,就要考虑增加文件数和进程数优化。
今天的分享就到这里,谢谢大家。