【SpringBoot】71、SpringBoot中集成多数据源+动态数据源
1、介绍
dynamic-datasource-spring-boot-starter 是一个基于 springboot 的快速集成多数据源的启动器。
- 详细文档
https://www.kancloud.cn/tracy5546/dynamic-datasource/2264611
- 特性
支持 数据源分组 ,适用于多种场景 纯粹多库 读写分离 一主多从 混合模式。
支持数据库敏感配置信息 加密(可自定义) ENC()。
支持每个数据库独立初始化表结构schema和数据库database。
支持无数据源启动,支持懒加载数据源(需要的时候再创建连接)。
支持 自定义注解 ,需继承DS(3.2.0+)。
提供并简化对Druid,HikariCp,BeeCp,Dbcp2的快速集成。
提供对Mybatis-Plus,Quartz,ShardingJdbc,P6sy,Jndi等组件的集成方案。
提供 自定义数据源来源 方案(如全从数据库加载)。
提供项目启动后 动态增加移除数据源 方案。
提供Mybatis环境下的 纯读写分离 方案。
提供使用 spel动态参数 解析数据源方案。内置spel,session,header,支持自定义。
支持 多层数据源嵌套切换 。(ServiceA >>> ServiceB >>> ServiceC)。
提供 基于seata的分布式事务方案 。
提供 本地多数据源事务方案。
- 约定
1、本框架只做 切换数据源 这件核心的事情,并不限制你的具体操作,切换了数据源可以做任何 CRUD。
2、配置文件所有以下划线 _ 分割的数据源 首部 即为组的名称,相同组名称的数据源会放在一个组下。
3、切换数据源可以是组名,也可以是具体数据源名称。组名则切换时采用负载均衡算法切换。
4、默认的数据源名称为 master ,你可以通过 spring.datasource.dynamic.primary 修改。
5、方法上的注解优先于类上注解。
6、DS 支持继承抽象类上的 DS,暂不支持继承接口上的 DS。
2、引入依赖
<!-- web支持 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- mysql -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!-- 多数据源依赖 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>dynamic-datasource-spring-boot-starter</artifactId>
<version>3.4.0</version>
</dependency>
3、建库建表
- 1、建两个数据库:test1、test2
CREATE DATABASE IF NOT EXISTS `test1` DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
CREATE DATABASE IF NOT EXISTS `test2` DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
- 2、分别建一张数据表:test
USE test1;
DROP TABLE IF EXISTS `test`;
CREATE TABLE `test` (
`id` int(11) NOT NULL,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;
USE test2;
DROP TABLE IF EXISTS `test`;
CREATE TABLE `test` (
`id` int(11) NOT NULL,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;
- 3、分别插入一条数据
USE test1;
INSERT INTO `test` VALUES (1, 'test1');
USE test2;
INSERT INTO `test` VALUES (1, 'test2');
4、配置多数据源信息
spring:
# 数据源配置
datasource:
dynamic:
# 默认数据源,默认master
primary: master
# 严格匹配数据源,默认false. true未匹配到指定数据源时抛异常,false使用默认数据源
strict: false
# 数据库连接信息配置
datasource:
# 主库
master:
url: jdbc:mysql://127.0.0.1:3306/test1?useUnicode=true&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=Asia/Shanghai&useSSL=true&characterEncoding=UTF-8
username: root
password: 123456
# 从库
slave:
url: jdbc:mysql://127.0.0.1:3306/test2?useUnicode=true&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=Asia/Shanghai&useSSL=true&characterEncoding=UTF-8
username: root
password: 123456
配置了一主一从,主库:master,从库:slave,默认使用主库
- 多种配置方法
# 多主多从 纯粹多库(记得设置primary) 混合配置
spring: spring: spring:
datasource: datasource: datasource:
dynamic: dynamic: dynamic:
datasource: datasource: datasource:
master_1: mysql: master:
master_2: oracle: slave_1:
slave_1: sqlserver: slave_2:
slave_2: postgresql: oracle_1:
slave_3: h2: oracle_2:
5、测试方法
import com.baomidou.dynamic.datasource.annotation.DS;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.stereotype.Service;
@Service
public class TestService {
@Autowired
private JdbcTemplate jdbcTemplate;
@DS("master")
public String test1() {
return jdbcTemplate.queryForObject("select name from test where id = 1", String.class);
}
@DS("slave")
public String test2() {
return jdbcTemplate.queryForObject("select name from test where id = 1", String.class);
}
}
使用 DS 注解动态切换数据源,如不写,则默认使用主库,该注解支持就近原则:方法上注解 优先于 类上注解
| 注解 | 结果 |
|---|---|
| 没有@DS | 默认数据源 |
| @DS(“dsName”) | dsName可以为组名也可以为具体某个库的名称 |
6、测试结果
import com.asurplus.service.TestService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class TestController {
@Autowired
private TestService testService;
@GetMapping("test1")
public String test1() {
return testService.test1();
}
@GetMapping("test2")
public String test2() {
return testService.test2();
}
}
提供两个接口,分别访问得到结果如下
http://localhost:8080/test1

http://localhost:8080/test2

证明我们的动态数据源切换成功
7、配置Druid监控
- 1、引入依赖
<!-- Alibaba的druid数据库连接池 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.6</version>
</dependency>
- 2、配置Druid信息
spring:
# 数据源配置
datasource:
dynamic:
# 默认数据源,默认master
primary: master
# 严格匹配数据源,默认false. true未匹配到指定数据源时抛异常,false使用默认数据源
strict: false
# 数据库连接信息配置
datasource:
# 主库
master:
url: jdbc:mysql://127.0.0.1:3306/test1?useUnicode=true&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=Asia/Shanghai&useSSL=true&characterEncoding=UTF-8
username: root
password: 123456
# 从库
slave:
url: jdbc:mysql://127.0.0.1:3306/test2?useUnicode=true&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=Asia/Shanghai&useSSL=true&characterEncoding=UTF-8
username: root
password: 123456
# druid相关配置
druid:
# 初始化时建立物理连接的个数
initial-size: 5
# 最大连接池数量
max-active: 20
# 最小连接池数量
min-idle: 10
# 获取连接时最大等待时间,单位毫秒
max-wait: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
time-between-eviction-runs-millis: 60000
# 连接保持空闲而不被驱逐的最小时间
min-evictable-idle-time-millis: 300000
# 用来检测连接是否有效的sql,要求是一个查询语句
validation-query: SELECT 1 FROM DUAL
# 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效
test-while-idle: true
# 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能
test-on-borrow: false
# 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能
test-on-return: false
# 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭
pool-prepared-statements: false
# 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true
max-pool-prepared-statement-per-connection-size: 50
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计
filter:
stat:
enabled: true
# 慢sql记录
log-slow-sql: true
slow-sql-millis: 1000
merge-sql: true
wall:
config:
multi-statement-allow: true
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
connect-properties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
# 合并多个DruidDataSource的监控数据
use-global-data-source-stat: true
web-stat-filter:
enabled: true
stat-view-servlet:
enabled: true
# 设置白名单,不填则允许所有访问
allow:
url-pattern: /druid/*
# 用户名密码
login-username: admin
login-password: 123456
- 3、启动项目
http://localhost:8080/druid/
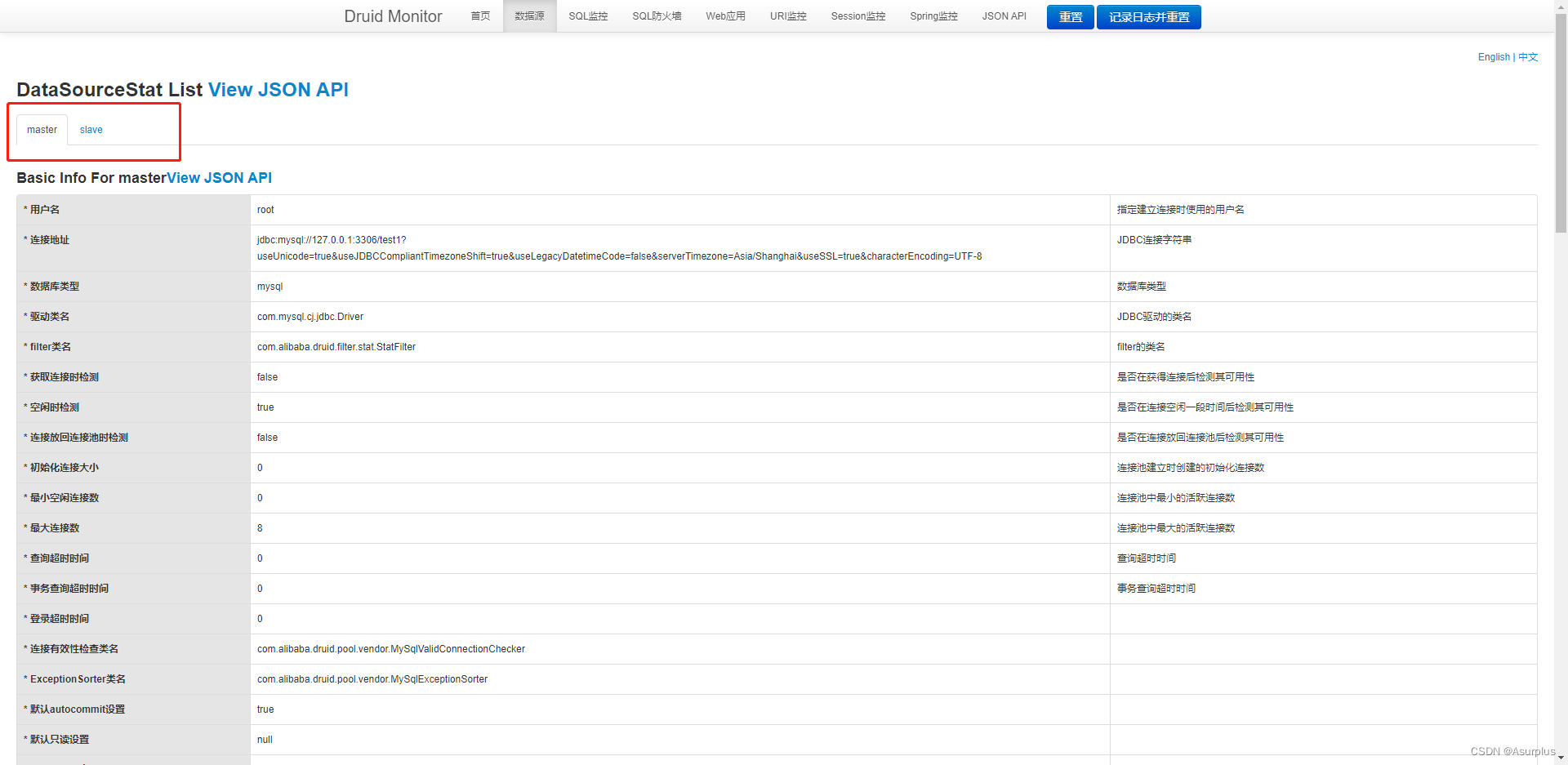
如图,就已经看到了两个数据源被 druid 所监控到了
如您在阅读中发现不足,欢迎留言!!!