BlockingQueue
网上看了好多文章将线程池的但是似乎都没的多少人会详细讲解里面的任务队列,所以只有自己动手学习其中的任务队列
BlockingQueue

要学习其中的任务队列就需要先学习BlockingQueue,Blocking是一个接口,其中主要的方法为
// 尝试往队尾添加元素,添加成功返回true,添加失败返回false
boolean add(E e);
// 尝试往队尾添加元素,添加成功返回true,添加失败返回false
boolean offer(E e);
// 尝试往队尾添加元素,如果队列满了,则阻塞当前线程,直到其能够添加成功为止
void put(E e) throws InterruptedException;
// 尝试往队尾添加元素,如果队列满了,则阻塞当前线程,直到超时
boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException;
// 从队头取出元素,如果队列为空则一直等待
E take() throws InterruptedException;
// 从队头取出元素,如果队列为空则等待一段时间
E poll(long timeout, TimeUnit unit) throws InterruptedException;
int remainingCapacity();
//从队列中移除指定对象
boolean remove(Object o);
//判断队列是否存在指定对象
public boolean contains(Object o);
//将队列中元素转移到指定集合
int drainTo(Collection<? super E> c);
//将最多MAX个元素转移到指定集合
int drainTo(Collection<? super E> c, int maxElements);
ArrayBlockingQueue
ArrayBlockingQueue的底层是基于数组实现,当指定容量后数组就确定了不会发生扩容
参数
// 元素
final Object[] items;
//可以被取到的元素下标
int takeIndex;
//可以放入元素的下标
int putIndex;
//元素个数
int count;
//锁
final ReentrantLock lock;
//等待条件,用于队列为空的时候阻塞当前线程获取
private final Condition notEmpty;
//等待条件,用于队列满的时候阻塞当前线程加入元素
private final Condition notFull;
transient Itrs itrs = null;
通过上述数据结构可以看出,ArrayBlockingQueue是通过一个循环数组的方式来实现存储元素的,这里takeIndex记录当前可以取元素的索引位置,而putIndex则记录了下一个元素可以放入的位置,如果队列满了则是takeIndex == putIndex,这里可以通过判断count字段来判断当前是处于满状态还是空置状态,通过一个全局锁lock来实现控制
对于其中的方法比较重要的是出队与入队方法,enqueue与dequeue
重要方法
enqueue与dequeue
其中入队与出队就是将对应位置的putIndex与takeIndex放入其中位置即可,然后加一,但是加一要判断是否超过了当前数组最大位置,如果是则设置为0,同时需要唤醒对应条件的等待队列
private void enqueue(E x) {
final Object[] items = this.items;
items[putIndex] = x;
if (++putIndex == items.length)
putIndex = 0;
count++;
notEmpty.signal();
}
private E dequeue() {
final Object[] items = this.items;
@SuppressWarnings("unchecked")
E x = (E) items[takeIndex];
items[takeIndex] = null;
if (++takeIndex == items.length)
takeIndex = 0;
count--;
if (itrs != null)
itrs.elementDequeued();
notFull.signal();
return x;
}
这是其中内层调用的方法,而外部方法我们提供方法为
put与take
put与take实现了其阻塞队列满足条件的方法
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await(); //通过while循环以防止当前线程被意外唤醒,如果当前循环被打破则代表没有满了
enqueue(e); // 放入元素
} finally {
lock.unlock();
}
}
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0)
notEmpty.await(); //与上面类似
return dequeue();
} finally {
lock.unlock();
}
}
从这里可以看出ArrayBlockingQueue实现的是先进先出
LinkedBlockingQueue
LinkedBlockingQueue,其底层是通过一个单项链表实现的,由于单项链表需要有一个指向下一个节点的指针,因而其必须使用一个对象这里是Node来存储当前元素的值和下一个节点索引
Node节点
static class Node<E> {
//当前元素的值
E item;
//下一个元素
Node<E> next;
Node(E x) { item = x; }
}
参数
//容量
private final int capacity;
//当前队列已经存储个数
private final AtomicInteger count = new AtomicInteger();
//头指针
transient Node<E> head;
//尾指针
private transient Node<E> last;
//从队列取出元素的锁
private final ReentrantLock takeLock = new ReentrantLock();
//等待如果队列为空
private final Condition notEmpty = takeLock.newCondition();
//放入元素的锁
private final ReentrantLock putLock = new ReentrantLock();
private final Condition notFull = putLock.newCondition();
这里与ArrayBBlockingQueue存在着一些差异,其中head与last与takeIndex与putIndex都是类似的,但是LinkedBlockingQueue使用了两把锁,而上面只使用了一把锁
重要方法
enqueue与dequeue
private void enqueue(Node<E> node) {
//将队列尾部节点的下一个节点指向新的节点,并更新尾部节点为最新的节点
last = last.next = node;
}
//返回头节点的下一个节点并更新头节点
//因为头节点存储不是第一个元素
private E dequeue() {
Node<E> h = head;
Node<E> first = h.next;
h.next = h; // help GC
head = first;
E x = first.item;
first.item = null;
return x;
}
可以看到对于链表的入队与出队操作是非常简单的,所以我们需要看其中的take与put方法
take与put
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
int c = -1;
Node<E> node = new Node<E>(e);
final ReentrantLock putLock = this.putLock;
final AtomicInteger count = this.count;
putLock.lockInterruptibly();
try {
while (count.get() == capacity) {
notFull.await(); // 如果满了则进入等待
}
enqueue(node); //放入元素
c = count.getAndIncrement(); //元素个数++
if (c + 1 < capacity) //如果添加元素过后还是未满那么则继续唤醒下一个
notFull.signal();
} finally {
putLock.unlock();
}
if (c == 0)
//将等待取出的线程唤醒,而唤醒的时候也必须获取take锁才能唤醒
signalNotEmpty();
}
public E take() throws InterruptedException {
E x;
int c = -1;
final AtomicInteger count = this.count;
final ReentrantLock takeLock = this.takeLock;
takeLock.lockInterruptibly();
try {
while (count.get() == 0) {
notEmpty.await(); //同理
}
x = dequeue();
c = count.getAndDecrement();
if (c > 1)
notEmpty.signal(); //继续获取
} finally {
takeLock.unlock();
}
if (c == capacity)
signalNotFull(); //同理
return x;
}
ArrayBlockingQueue与LinkedBlockingQueue区别
1、两种底层数据结构不同,一个是基于循环数组一个是基于单向链表
2、两种阻塞方式不同,ArrayBlockingQueue使用了一个全局锁来处理所有操作,也就是无论插入还是获取都只能一个线程执行,而LinkedBlockingQueue则是使用两个锁,使得获取与放入无干扰
3、两着初始化不同,ArrayBlockingQueue必须指定一个大小初始化而LinkedBlockingQueue则可以不指定,不指定则为Integer.MAX_VALUE
SynchronousQueue
这个阻塞队列就比上面两种麻烦多了,那就需要一步一步理解
SynchronousQueue也是一个队列来的,但他的特别之处在于它内部没有容器,一个生产线程,当它生产产品(即put时候),如果当前没有人想要消费产品此生产线程必须阻塞等待一个消费者调用take操作,take操作将唤醒该生产线程,同时消费线程会获取生产线程的产品(即数据传递),这样的一个过程称一次配对过程
构造器
其构造器可传入是公平还是非公平的,默认是非公平的
如果是公平的则采用TransferQueue如果是非公平的则采用TransferStack
public SynchronousQueue(boolean fair) {
transferer = fair ? new TransferQueue<E>() : new TransferStack<E>();
}
从源码上课其中的pull、take等方法都素调用transfer方法
transfer中有三个参数:
e:要存放的元素
timed:是否超时等待
nanos:超时等待时间
TransferQueue
TransferQueue内部有一个内部类:QNode,TransferQueue是由QNode节点构成的链表结构
QNode
//下一个节点
volatile QNode next;
//存入元素
volatile Object item;
//等待线程
volatile Thread waiter;
//是否是数据
final boolean isData;
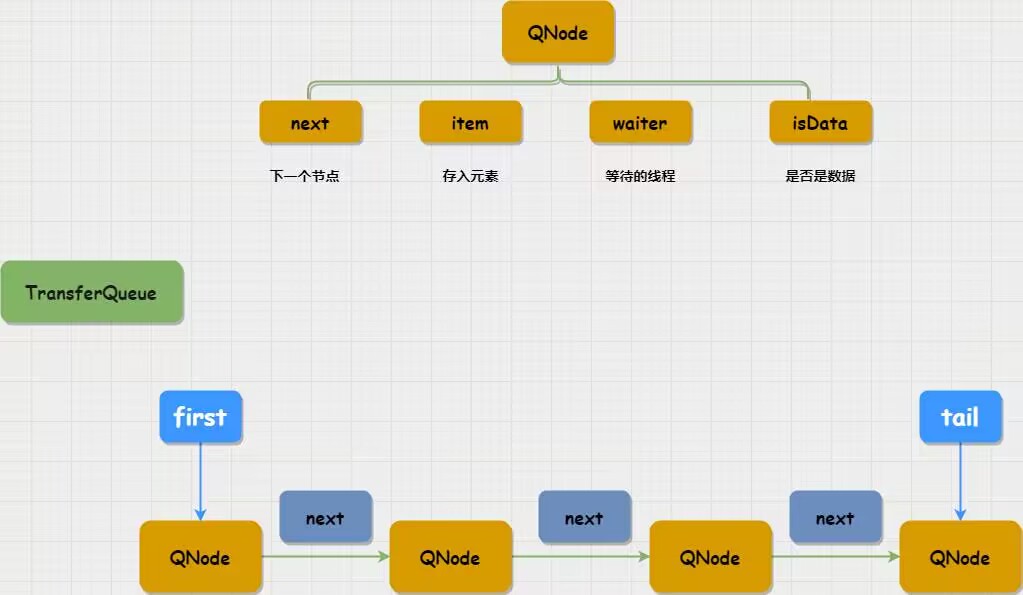
TransferQueue初始化
TransferQueue创建时会初始化一个QNode节点,head,tail都会指向这个空节点,在TransferQueue中会以根据传入的参数:e是否为null来将节点分为两类,从TransferQueue队列中获取元素的线程是同一类节点,比如:调用take,poll的线程就是同一类节点;从TransferQueue队列中添加元素的线程是一类节点
TransferQueue队列特殊的地方就在于这个队列中只会存在一种节点:要么是获取元素的线程节点,要么是添加元素的线程节点
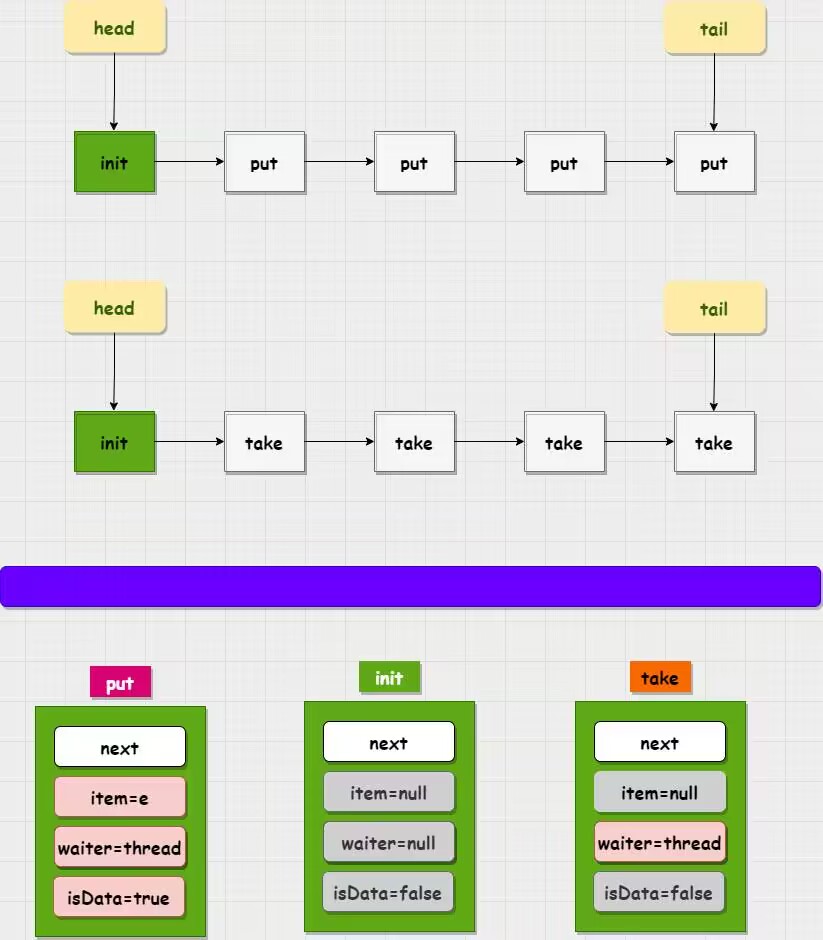
在初始化TransferQueue对象时,会初始化生产一个节点队列的头,尾:head,tail都会指向这个init节点
举个例子:假设当前队列中都是put线程,此时有一个take线程,那么这个take线程就会唤醒队列中的一个put线程
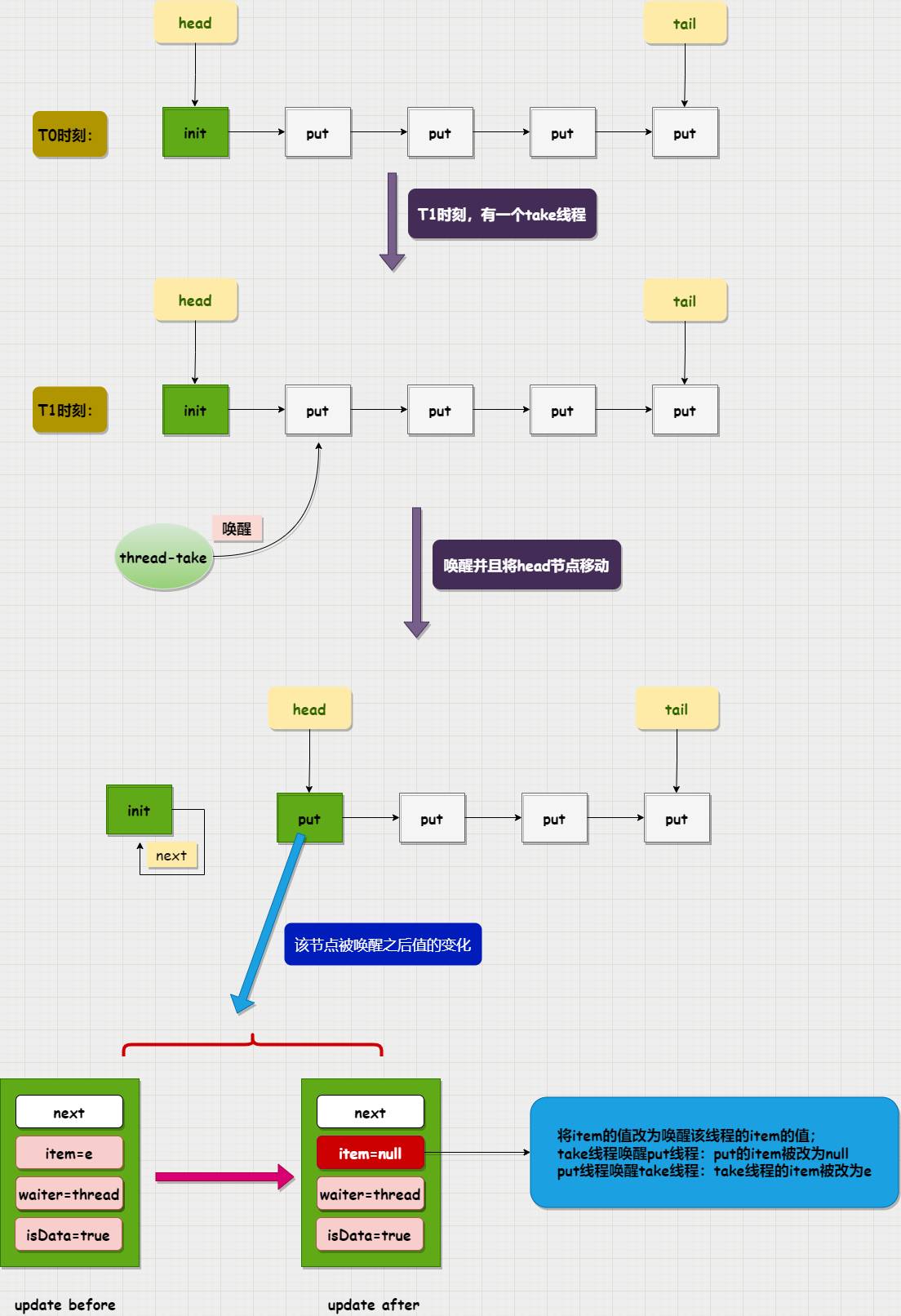
在唤醒线程时,同时会修改该线程所在节点的item值,在后面分析源码时候会看到,如果只是唤醒线程是没有用的,还需要将item的值修改才能真正唤醒该线程
Transfer
下面就来分析Transfer方法
E transfer(E e, boolean timed, long nanos) {
QNode s = null;
boolean isData = (e != null); // 判断当前是什么类型线程
for (;;) {
QNode t = tail;
QNode h = head;
if (t == null || h == null)
continue;
if (h == t || t.isData == isData) { // 如果队列为空 || 新类型线程与队列中线程类型一致
QNode tn = t.next;
if (t != tail) //队列尾节点已经被更新
continue;
if (tn != null) { //有新节点加入到队列
advanceTail(t, tn); //更新尾节点
continue;
}
if (timed && nanos <= 0)
return null;
if (s == null)
s = new QNode(e, isData); //将线程包装成QNode节点
if (!t.casNext(null, s)) //将新节点添加到队列末尾
continue;
advanceTail(t, s); //添加成功后更新tail
Object x = awaitFulfill(s, e, timed, nanos); //等待被唤醒
if (x == s) { //中断标记,带阻塞时间的线程等待了规定时间恢复运行
clean(t, s); //节点从队列中删除
return null;
}
if (!s.isOffList()) {
advanceHead(t, s);
if (x != null)
s.item = s;
s.waiter = null;
}
return (x != null) ? (E)x : e;
} else { //唤醒队列节点
// 取出当前节点
QNode m = h.next;
if (t != tail || m == null || h != head)
continue;
Object x = m.item;
if (isData == (x != null) ||
x == m ||
!m.casItem(x, e)) { //将被唤醒线程的值修改为当前线程的值
advanceHead(h, m);
continue;
}
advanceHead(h, m);
LockSupport.unpark(m.waiter); //唤醒线程
return (x != null) ? (E)x : e;
}
}
}
awaitFulfill
Object awaitFulfill(QNode s, E e, boolean timed, long nanos) {
/* Same idea as TransferStack.awaitFulfill */
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Thread w = Thread.currentThread();
int spins = ((head.next == s) ?
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
for (;;) {
if (w.isInterrupted())
s.tryCancel(e);
Object x = s.item;
if (x != e)
return x;
if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
s.tryCancel(e);
continue;
}
}
if (spins > 0)
--spins;
else if (s.waiter == null)
s.waiter = w;
else if (!timed)
LockSupport.park(this);
else if (nanos > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanos);
}
}
特别说明一下变量spins,所有进入阻塞队列的线程都不着急立即阻塞,而是会先自旋一段时间,然后再阻塞,因为阻塞线程再唤醒线程的代价就比让线程自选的大
TransferStack
里面存在一个内部类:SNode,TransferStack是由Snode单链表构建成的堆栈结构,只有一个head指针指向链表的表头;每次添加元素都是在表头处添加,新节点称为新的表头head,唤醒的线程的时候也是唤醒head节点,因此就形成了先进后出的堆栈结构,TransferStack中根据e也就线程分为两类,一类是获取元素:REQUEST,一类的添加元素:DATA,其中也只有一种节点只有被唤醒时候才会短暂出现2种节点
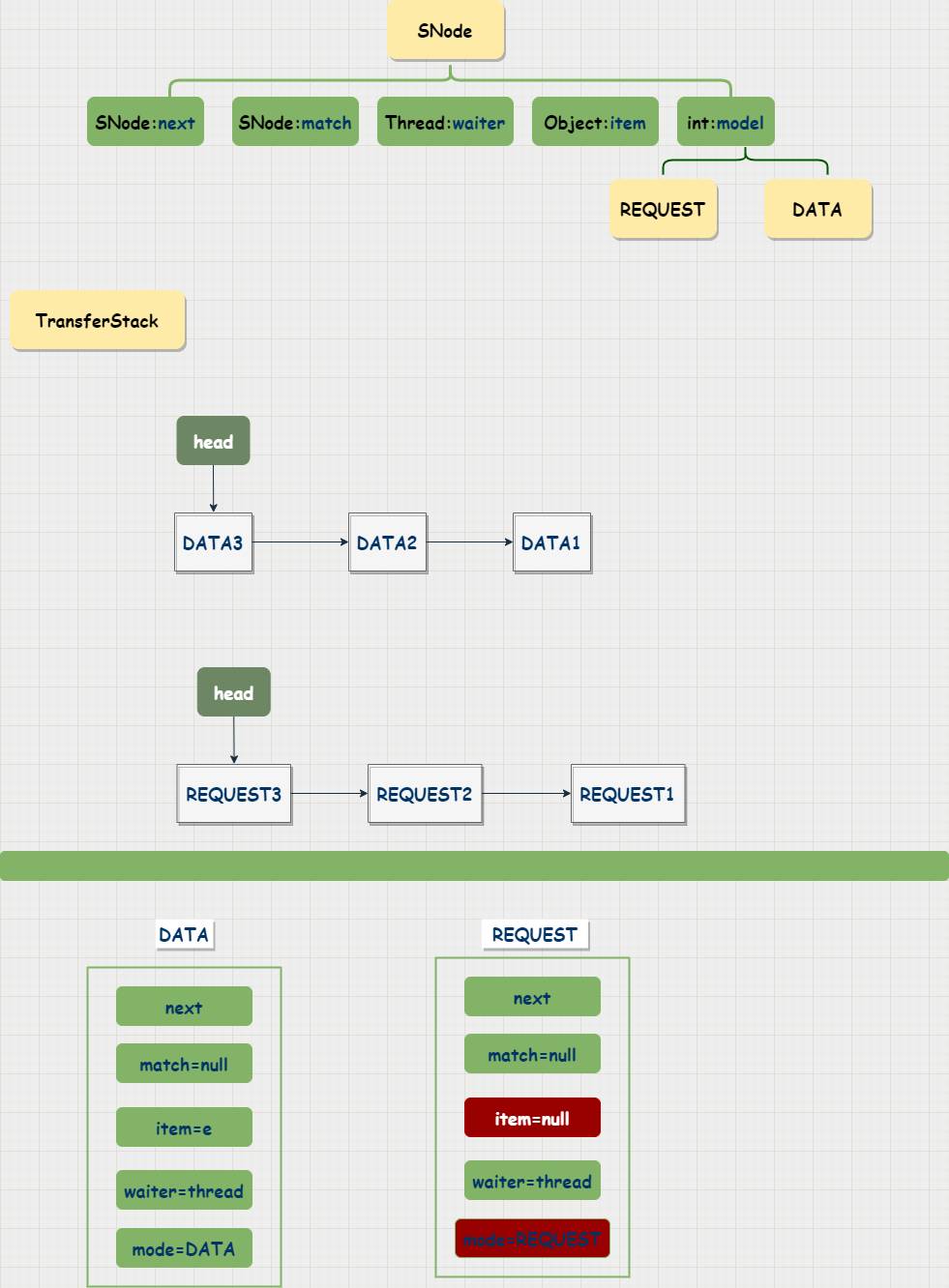
SNode
//下一个节点
volatile SNode next;
volatile SNode match;
//当前线程
volatile Thread waiter;
//值
Object item;
//模式
int mode;
在TransferStack的堆栈中,如果新加入的线程类型与堆栈中的节点类型不同,那么会先将新线程包装成Snode节点加入堆栈中,成为新的header节点并将旧的节点唤醒。然后更新head节点返回DATA类型节点的元素值
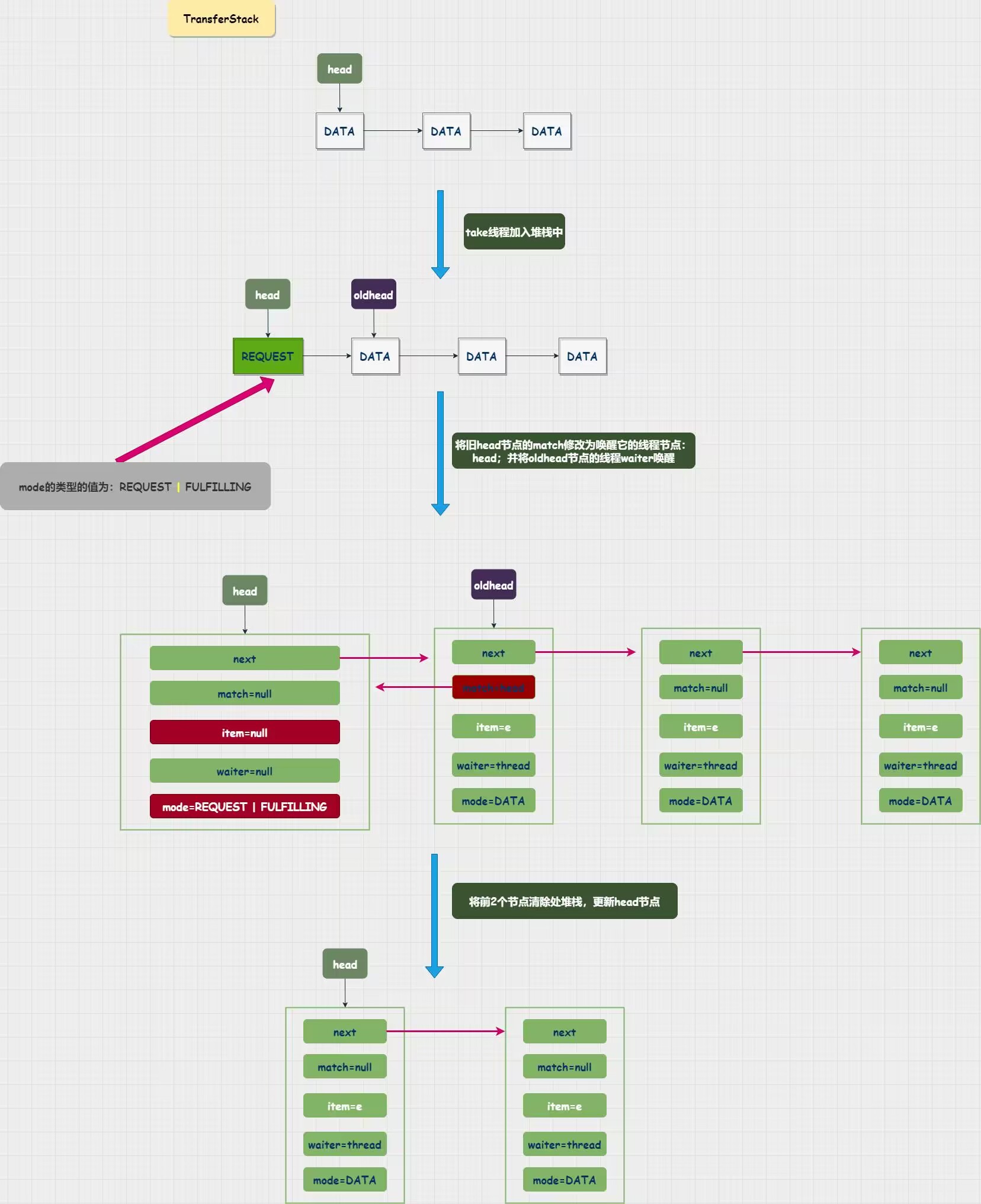
在有不同类型的节点进入堆栈中的时候,新节点添加到堆栈顶端并更新为新的head节点;这个节点的mode = REQUEST | FULFILLING ;FULFILLING 是用来标记,表示这个head节点正在唤醒堆栈中的一个节点线程;最后在新节点唤醒旧的head节点( oldHead节点)之后,更新堆栈的head节点;
TransferStack部分的源码就再不分析了,入队阻塞部分的源码几乎与TransferQ ueue一样;TransferStack唤醒节点的方式与TransferQueue有点差别,TransferStack是将新节点先包装成节点添加到堆栈中,再唤醒节点线程,最后重新设置堆栈的head指针并将这2个节点清除出堆栈。
SynchronousQueue 这位大佬写的SynchronousQueue感觉很好,画图也很好只有自己理解但是想不出这些理解的话,感谢这位大佬我只是资源的整合者