Flink-简介与基础
Flink-简介与基础
- 一、Flink起源
- 二、Flink数据处理模式
- 1.批处理
- 2.流处理
- 3.Flink流批一体处理
- 三、Flink架构
- 1.Flink集群
- 2.Flink Program
- 3.JobManager
- 4.TaskManager
- 四、Flink应用程序
- 五、Flink高级特性
- 1.时间流(Time)和窗口(Window)
- 2.状态流(State)
- 3.快照(Checkpoint)
- 总结
- 参考文档
一、Flink起源
大数据计算引擎由批处理项流处理发展,由处理单一类型数据到批流一体方法发展。由单一功能逐步发展成更通用、更高效、更易用的一站式(混合架构)的计算引擎。计算引擎发展过程中典型架构:
- MapReduce:批处理引擎,hadoop中核心组件,开创大数据处理核心思想,即map、reduce。
- Storm:流处理引擎,为了满足更高时效性而产生
- Spark:支持流式处理和批处理的统一计算引擎,基于内存计算、提高性能
- Flink:支持流式处理和批处理的统一计算引擎,支持状态流、时间流等流处理
Flink诞生于柏林工业大学的一个大数据研究项目StratoSphere,2014年被捐献给Apache,成为Apache的顶级大数据项目。Flink将计算的主要方向定位为流处理,将批处理作为流处理的一个特殊情况。并提供了一些如数据状态、事件时间、分布式快照、watermark等高级功能。
二、Flink数据处理模式
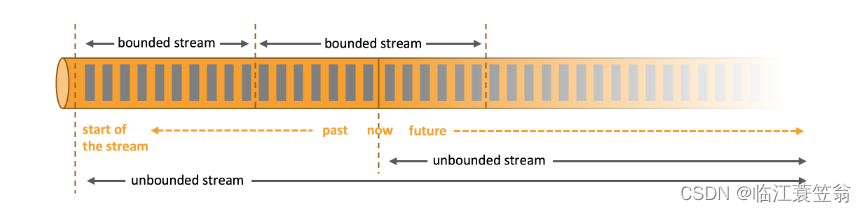
在大数据领域早期基本都是批处理,后期随着大数据处理应用范围的拓展,逐步发到到流处理。
1.批处理
批处理就是对整个有界数据集进行排序、统计或者汇总计算后输出结果。批处理的数据主要有以下特点:
- 有界:批处理数据集代表数据的有限集合
- 持久:数据通常存储在可重复获取的持久存储设备中
- 就绪:数据在计算之前已经就绪,不会发生变化
- 大量:批处理操作通常是处理海量数据集的唯一方法
2.流处理
流处理是无界数据流,更符合实际情况,例如交易数据、传感器数据等都是不断产生而不会结束。流处理是产生一条数据就会处理一条数据,流处理系统需要对进入系统的数据进行实时计算。而且流数据不一定是持久化的,可能是业务系统实时产生的。
3.Flink流批一体处理
Flink即可以进行流处理,也支持对有界数据进行批处理。也就是Flink可以处理消息队列或者日志这类流式数据源的实时数据,也支持从各种数据源消费有界的历史数据。

三、Flink架构
Flink是一个分布式系统,采用master/slave架构,可以有效的分配和管理计算资源。集成了常见的集群资源管理器、也可以作为单独集群运行。
1.Flink集群
Flink运行时主要由一个JobManager和多个TaskManager组成。

2.Flink Program
Flink应用程序不是运行时程序执行的一部分,主要是将用户的Flink作业提交到JobManager,并触发执行Flink程序。
3.JobManager
JobManger主要职责是协调Flink应用程序的分布式执行,主要是调度task、监控task执行情况、协调checkpoint、故障恢复等。
4.TaskManager
TaskManager主要是执行作业流中的task,并且缓存和交换数据流。
四、Flink应用程序
Flink应用程序编写主要是指用户对数据需要进行的操作,Flink将对数据的处理分为输入、处理、输出三个步骤。其中Source负责管理数据源输入、Transformation负责数据计算、Sink负责将结果输出。Transformation是根据需求由Flink提供的算子组合而成的一个处理流程。
Flink首先会将应用构建成一个Dataflow graph。当调用env.execute()时,graph会被打包并发送到JobManager上,JobManager会协调并执行应用。

五、Flink高级特性
1.时间流(Time)和窗口(Window)
实际应用中有时需要对历史数据进行重新处理和分析。如果时间流只能依靠机器时钟,一些基于时间的统计与运算得出的结果可能会有错误和偏差,因为为了满足以上场景,Flink支持用数据流中的事件时间作为时间依据,而不是处理数据时的机器时间。
2.状态流(State)
流处理过程中,很多操作如何处理都需要依据之前所有数据的累积结果、一些窗口函数也需要缓存之前的数据。Flink中的算子都可以是由状态的,这些状态都是本地访问,这样可以提高吞吐量和减低延迟。
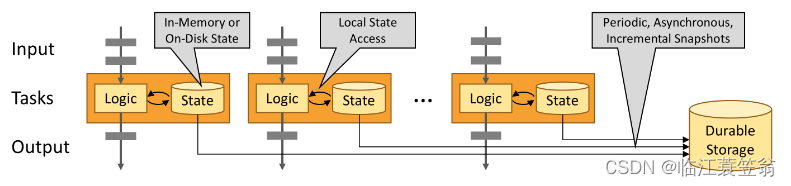
3.快照(Checkpoint)
大数据运行过程中无法避免故障的出现,因此需要一定的故障恢复机制。Flink通过定期状态快照和流重放来实现故障恢复和精确的一次计算。
总结
主要介绍了Flink背景和以流处理为主的设计理念,Flink的运行时架构、Flink作业的编程以及Flink的高级特性。
参考文档
1.Flink基础概念
2.Flink产生的背景以及简介
3.Flink架构