【数据结构:树与堆】向上/下调整算法和复杂度的分析、堆排序以及topk问题
文章目录
- 1.树的概念
- 1.1树的相关概念
- 1.2树的表示
- 2.二叉树
- 2.1概念
- 2.2特殊二叉树
- 2.3二叉树的存储
- 3.堆
- 3.1堆的插入(向上调整)
- 3.2堆的删除(向下调整)
- 3.3堆的创建
- 3.3.1使用向上调整
- 3.3.2使用向下调整
- 3.3.3两种建堆方式的比较
- 3.4堆排序
- 3.5TopK问题

1.树的概念
树是一种非线性的数据结构,它是由n(n>=0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。如下图:
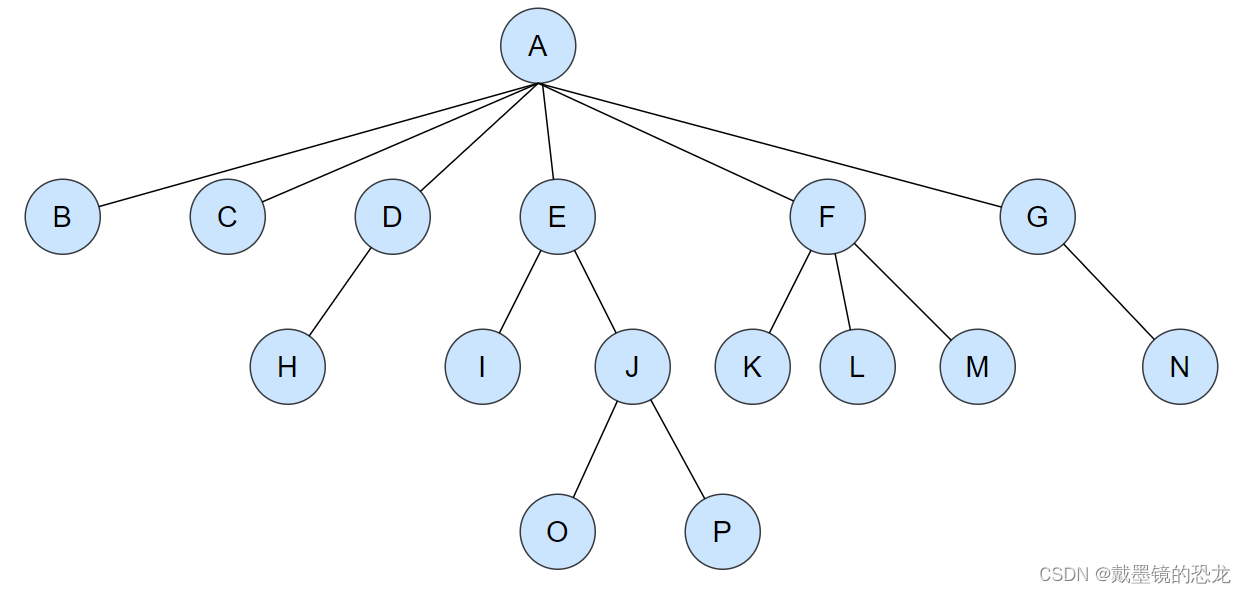
有一个特殊的结点,称为根结点,根节点没有前驱结点。例如A节点
除根节点外,其余结点被分成M(M>0)个互不相交的集合T1、T2、……、Tm,其中每一个集合Ti(1<= i <= m)又是一棵结构与树类似的子树。
例如:B节点又可以分成一棵树,该树只有根,没有子树。
D节点可以分为根节点和子树。D为根节点,只有一棵子树H。
因此树可以拆分为:根和子树。 每棵子树的根结点有且只有一个前驱,可以有0个或多个后继;所以,树是递归定义的。
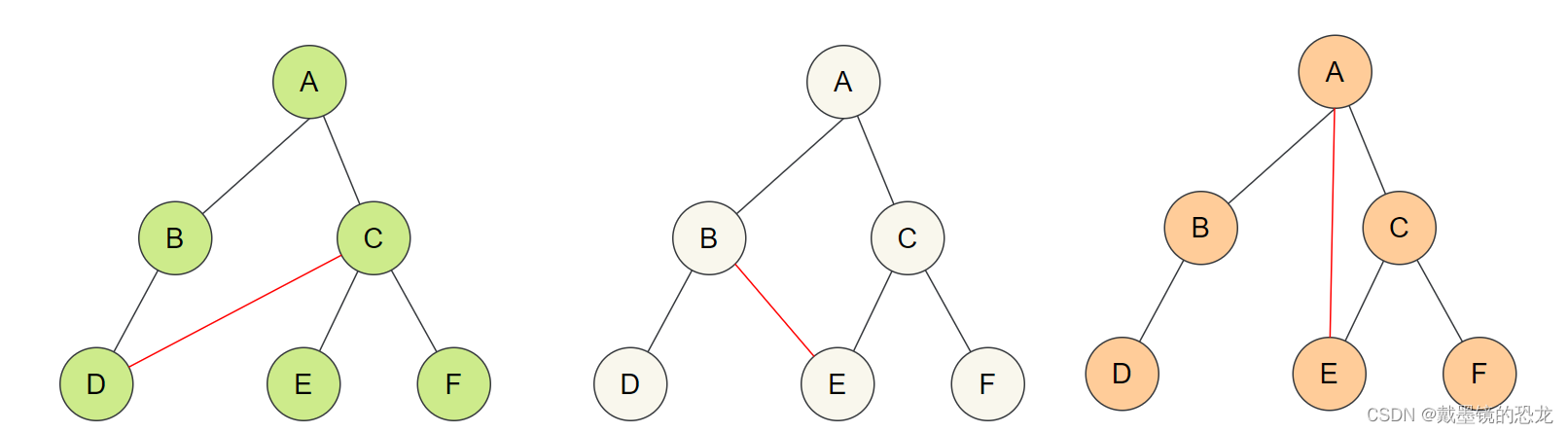
注意:树形结构中,子树之间不能有交集,否则就不是树形结构,即:树中不能有环!。例如:

1.1树的相关概念
- 节点的度:一个
节点含有的子树的个数称为该节点的度; 如上图:A的为6 - 叶节点或终端节点:
度为0的节点称为叶节点; 如上图:B、C、H、I…等节点为叶节点 - 分支节点或非终端节点:
度不为0的节点; 如上图:D、E、F、G…等节点为分支节点 - 双亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点; 如上图:A是B的父节点
- 孩子节点或子节点:一个节点含有的
子树的根节点称为该节点的子节点; 如上图:B是A的孩子节点,H是D的孩子节点 - 兄弟节点:具有
相同父节点的节点互称为兄弟节点; 如上图:B、C是兄弟节点 - 树的度:一棵树中,
最大的节点的度称为树的度; 如上图:树的度为6 - 节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
- 树的高度或深度:树中
节点的最大层次; 如上图:树的高度为4 - 堂兄弟节点:
双亲在同一层的节点互为堂兄弟;如上图:H、I互为兄弟节点 - 节点的祖先:从根到该节点所经分支上的所有节点;如上图:A是所有节点的祖先;P的祖先是A、E、J
- 子孙:以某节点为根的子树中任一节点都称为该节点的子孙。如上图:所有节点都是A的子孙
- 森林:由m(m>0)棵互不相交的树的集合称为森林;
1.2树的表示
树结构相对线性表就比较复杂了,要存储表示起来就比较麻烦了,既然保存值域,也要保存结点和结点之间的关系。所以树的结构应该怎么定义呢?
//假设树的度为6
#define N 6
struct TreeNode
{int val;struct TreeNode* Child[N];
};
如果这样定义的话,不管你子树有没有孩子都开辟了空间,会比较浪费。
struct TreeNode
{int val;struct TreeNode** Child;//使用顺序表存储孩子int size;//当前个数int capacity;//容量
};
既然浪费了空间,那咱们就动态申请,有几个孩子由size决定,不够就扩容,但这种结构好像也不太好。
struct TreeNode
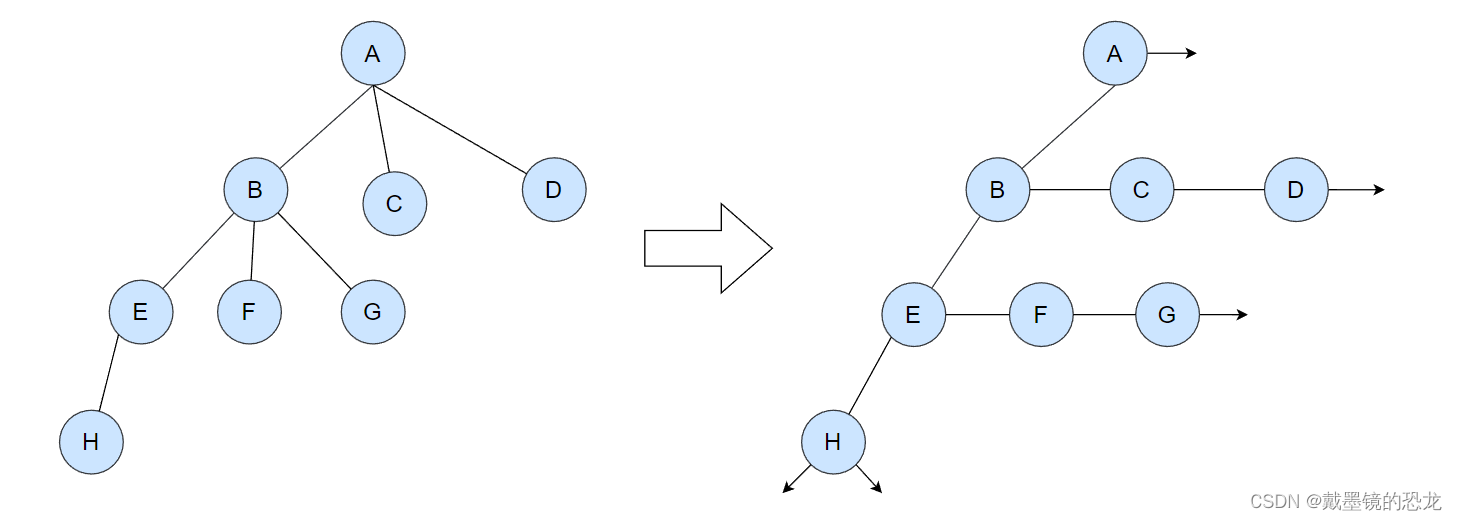
{int val;struct TreeNode* leftChile;//左孩子struct TreeNode* nextBrother;//右兄弟
};
左孩子右兄弟法:这种方法设计的非常巧妙,每个节点只记录它左边第一个孩子,其它孩子是第一个孩子的兄弟,由第一个孩子记录。这种方法好像看起来是最好的
2.二叉树
2.1概念
二叉树是从树衍生出来的。
那什么叫二叉树呢?
二叉树:首先它是一棵树,其次它每个节点最多有两个分支;并且对两个分支进行区分,分别叫做左子树和右子树。如下图
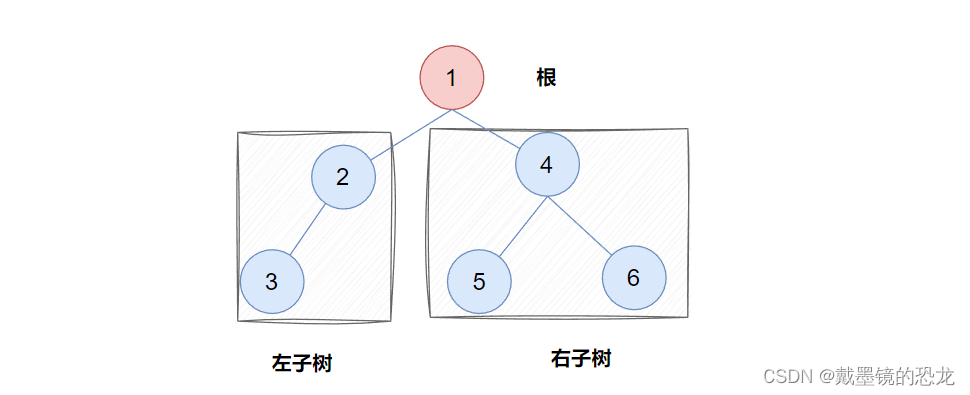
从上图可以看出:
- 二叉树不存在度大于2的结点
- 二叉树的子树有左右之分,次序不能颠倒,因此二叉树是有序树
注意:对于任意的二叉树都是由以下几种情况复合而成的:
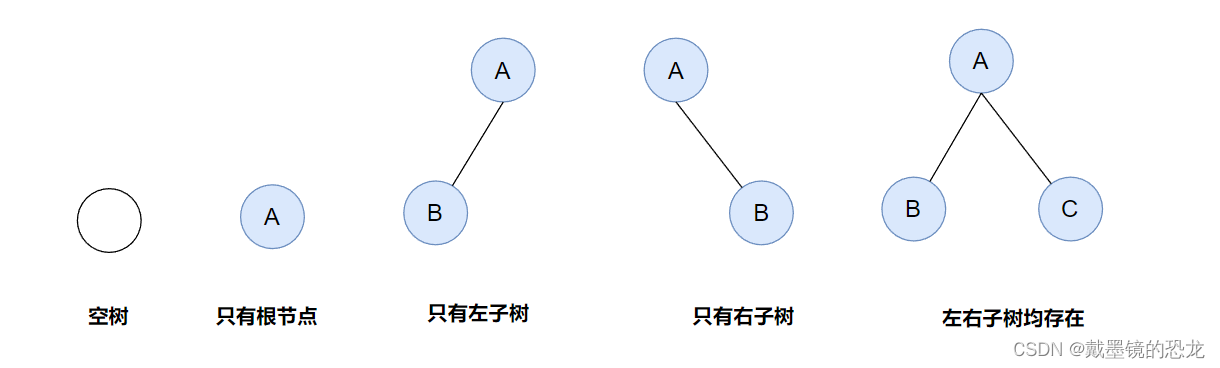
2.2特殊二叉树
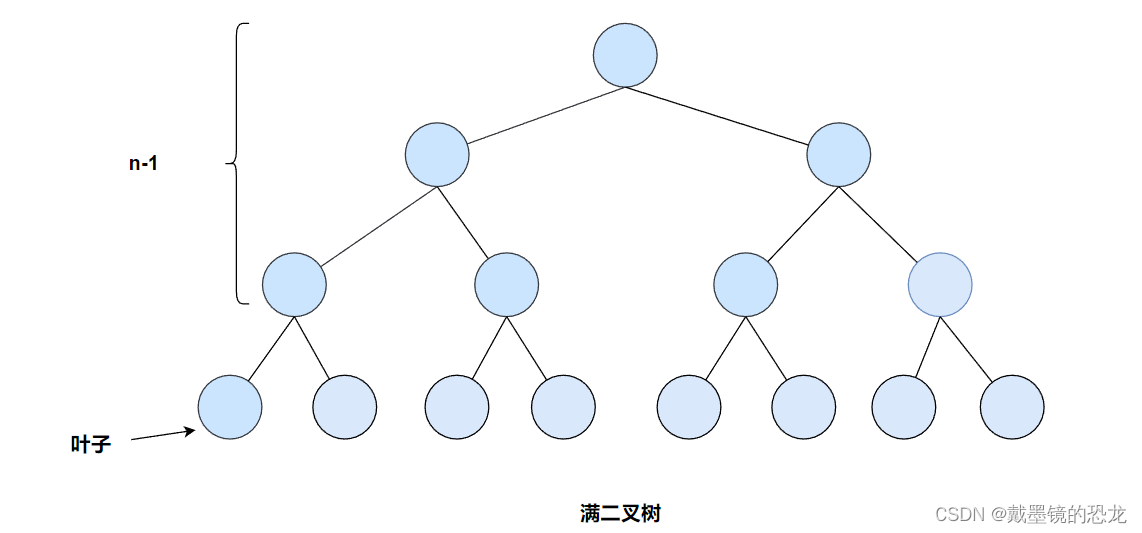
- 满二叉树
满二叉树:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。
满二叉树的前n-1层全是满的(度为2),叶子全在最后一层
如果一个二叉树的层数为K,且结点总数是2k-1,则这个二叉树就是满二叉树。
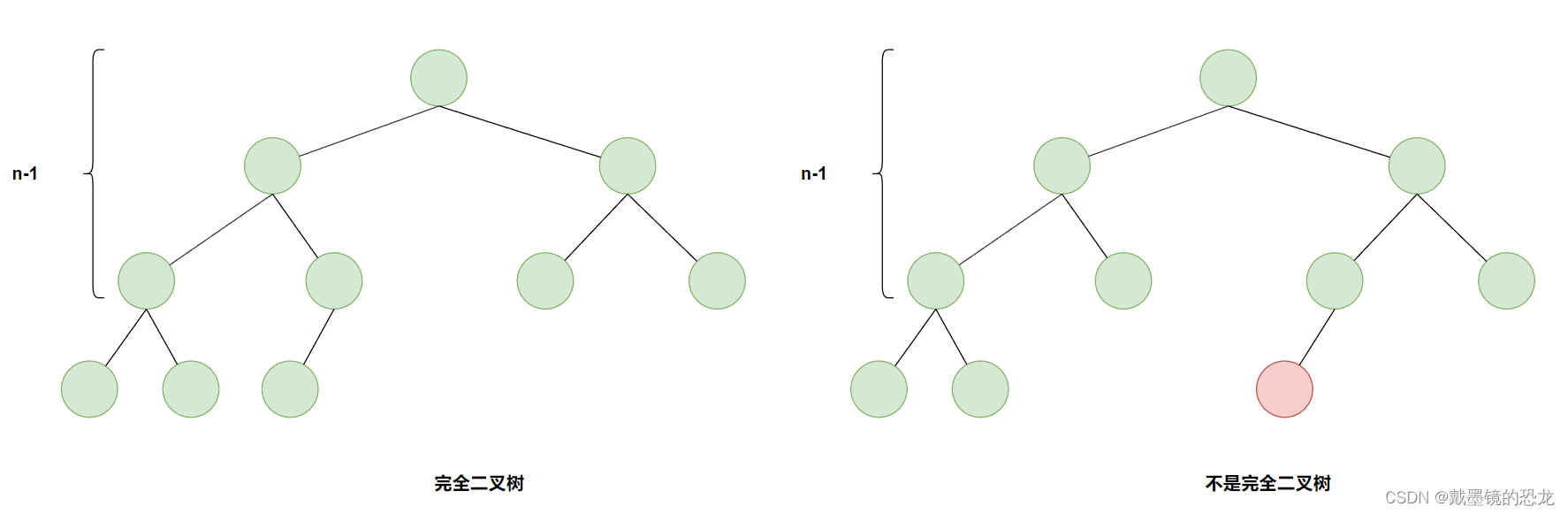
- 完全二叉树
完全二叉树跟满二叉树的区别是:完全二叉树的前n-1层也都是满的,最后一层不一定满,但是要求从左到右的节点连续,不能空。(没有左孩子就不能有右孩子)
2.3二叉树的存储
二叉树一般可以使用两种结构存储,一种顺序结构,一种链式结构。
- 顺序存储
顺序结构存储就是使用数组来存储,一般使用数组只适合表示完全二叉树,因为不是完全二叉树会有空间的浪费。而现实中使用中只有堆才会使用数组来存储。二叉树顺序存储在物理上是一个数组,在逻辑上是一颗二叉树
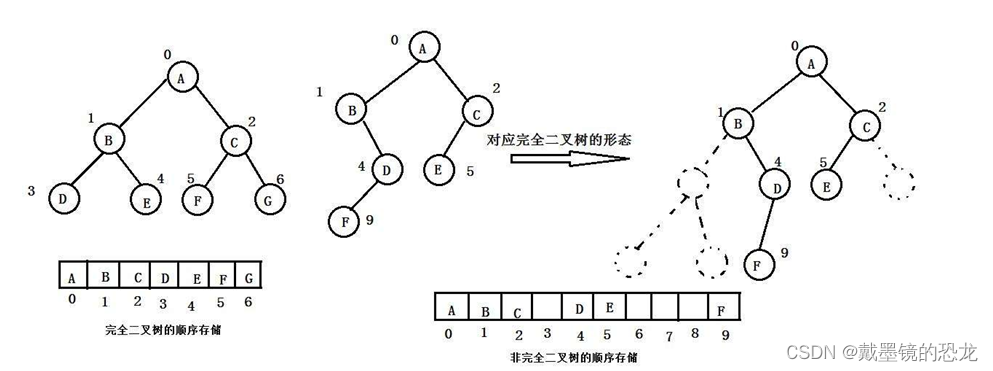
使用顺序存储存在一个规律:
-
leftChild = parent*2+1
- 例:C的左孩子的下标为2 * 2+1 = 5
-
rightChild = parent*2+2
- 例:C的右孩子的下标为2 * 2+2 = 6
-
parent = (Child - 1) / 2
- 例:F的父亲下标为(5-1)/ 2 = 2 G的父亲下标为(6-1)/ 2 = 2
-
有了这个规律我就不需要存储我的孩子或父亲在哪里,我使用下标算就可以了。
- 链式存储
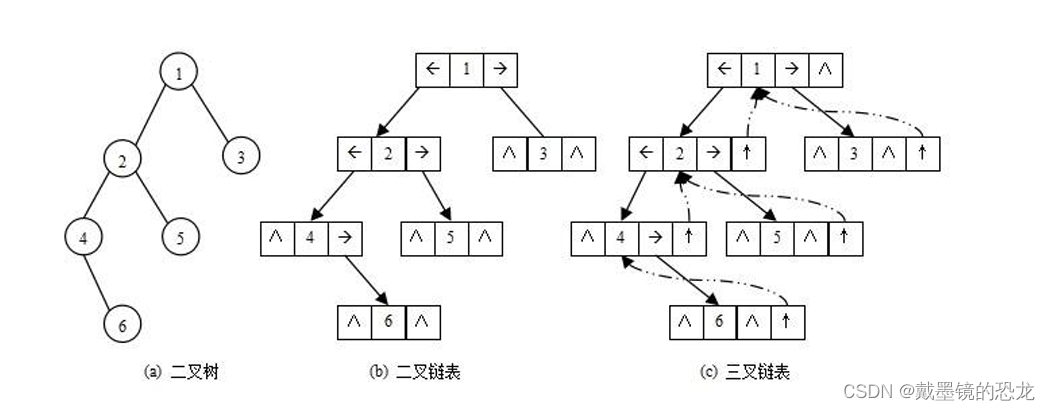
二叉树的链式存储结构是指,用链表来表示一棵二叉树,即用链来指示元素的逻辑关系。 通常的方法是链表中每个结点由三个域组成,数据域和左右指针域,左右指针分别 用来给出该结点左孩子和右孩子所在的链结点的存储地址,链式结构又分为二叉链和三叉链, 。
该结构一般用来存储非完全二叉树,不会有空间的浪费。
3.堆
- 普通的二叉树是不适合用数组来存储的,因为可能会存在大量的空间浪费。
- 完全二叉树更适合使用顺序结构存储。现实中我们通常把堆(一种二叉树)使用顺序结构的数组来存储
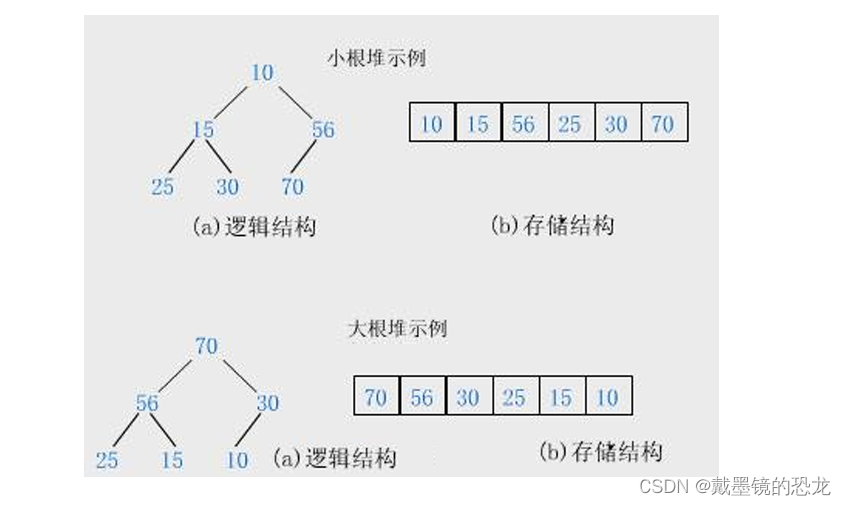
堆:
- 堆是一棵完全二叉树。
- 小堆:任何一个父亲 <= 孩子
- 大堆:任何一个父亲 >= 孩子
- 将根节点最大的堆叫做最大堆或大根堆,
根节点最小的堆叫做最小堆或小根堆
使用堆这种数据结构有什么好处呢?
TopK问题(找最值),最值就在根上。
3.1堆的插入(向上调整)
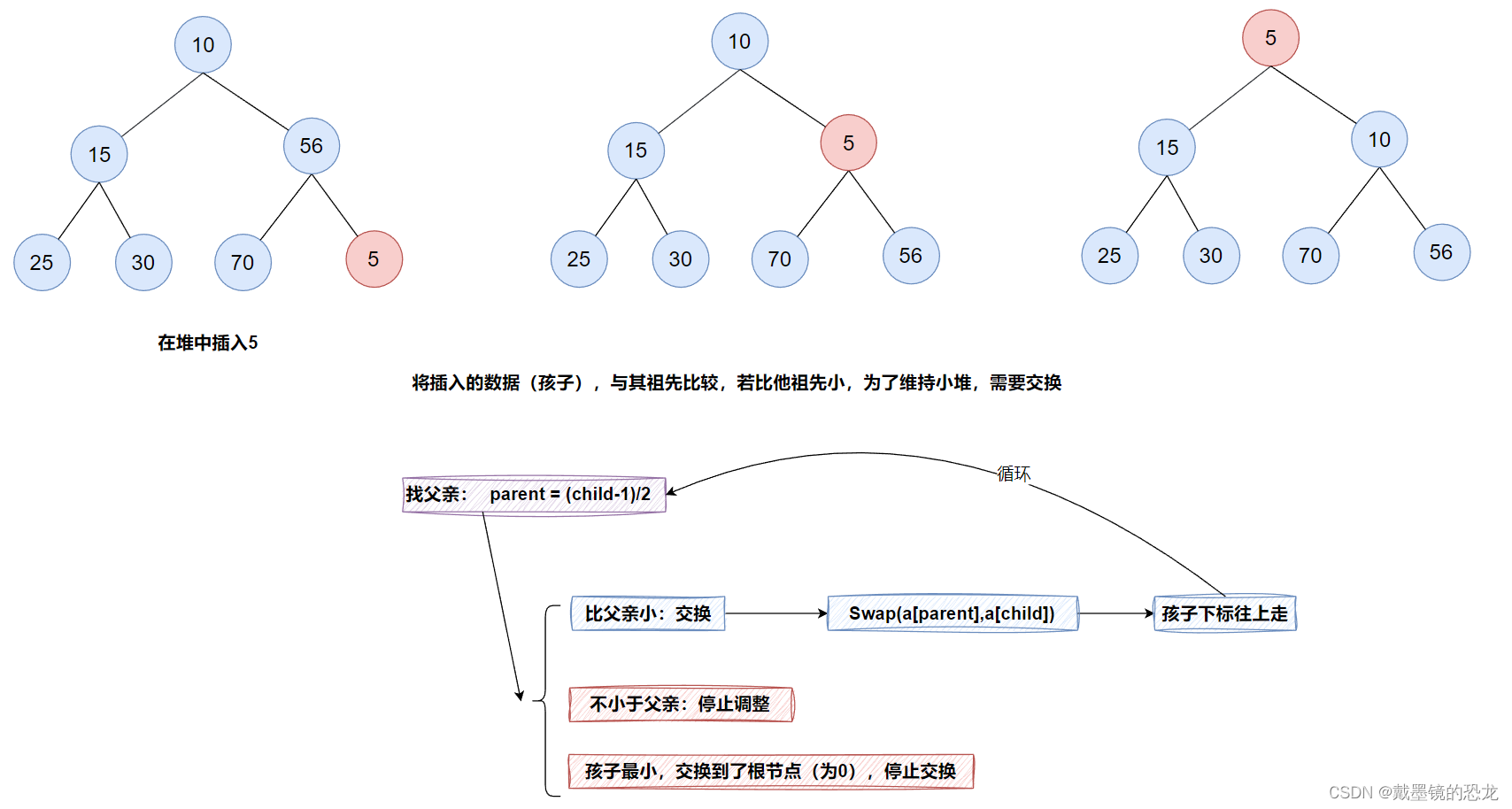
假设已存在一个堆,现需向堆中插入元素5。
void Swap(HeapDataType* x, HeapDataType* y)
{HeapDataType tmp = *x;*x = *y;*y = tmp;
}void AdjustUp(HeapDataType* a, int child)
{int parent = (child - 1) / 2;//while(parent >= 0)while (child){//孩子小于父亲if (a[child] < a[parent]){//交换Swap(&a[child], &a[parent]);//改变下标child = parent;//继续找父亲parent = (child - 1) / 2;}else{break;}}
}// 堆的插入
void HeapPush(Heap* php, HeapDataType x)
{assert(php);//扩容if (php->size == php->capacity){int newcapacity = php->capacity == 0 ? 4 : 2 * php->capacity;HeapDataType* tmp = (HeapDataType*)realloc(php->a, sizeof(HeapDataType)*newcapacity);if (tmp == NULL){perror("realloc");return;}php->a = tmp;php->capacity = newcapacity;}//将数据先插入到堆中php->a[php->size] = x;php->size++;//插入后向上调整,使其仍然是堆//开始调整的位置为数组末尾位置:size-1AdjustUp(php->a, php->size - 1);
}
思考:如何让一个数组变成堆?
将数组的值插入堆中即可
int main()
{Heap* heap = HeapCreate();int arr[] = { 1,4,7,3,9,10 };for (int i = 0; i < sizeof(arr)/sizeof(int); i++){HeapPush(heap, arr[i]);}HeapDestroy(heap);return 0;
}
3.2堆的删除(向下调整)
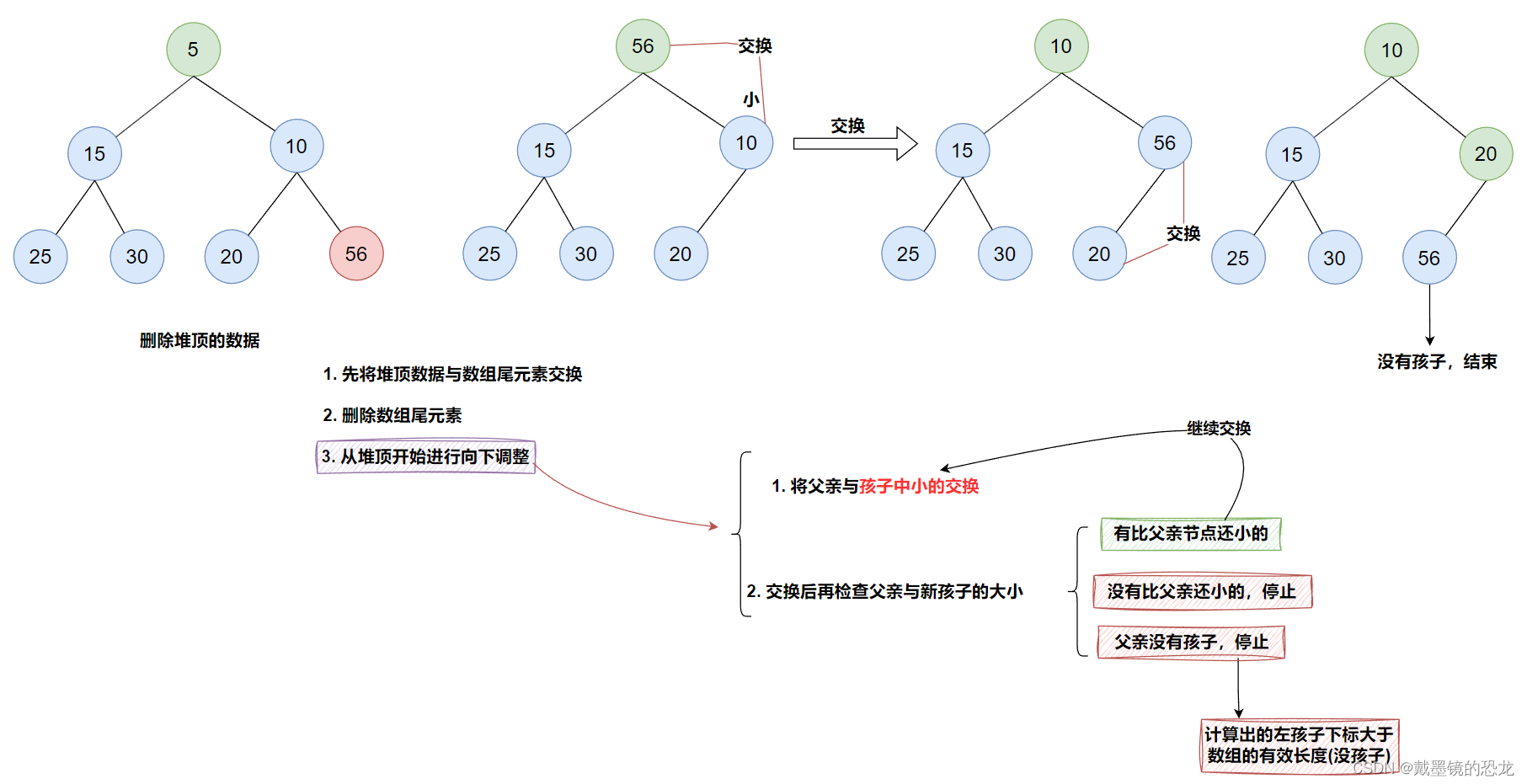
void AdjustDown(HeapDataType* a, int n, int parent)
{int child = parent * 2 + 1;while (child < n)//有左孩子就继续{//找小的孩子//若右孩子存在 且 右孩子小于左孩子,右孩子是小孩子if (child+1 < n && a[child+1] < a[child]){child++;}//小孩子小于父亲,交换if (a[child] < a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}// 堆的删除
void HeapPop(Heap* php)
{assert(php);assert(php->size);Swap(&php->a[0], &php->a[php->size - 1]);//交换php->size--;//删除数组尾位置AdjustDown(php->a, php->size, 0);
}
3.3堆的创建
下面我们给出一个数组,这个数组逻辑上可以看做一颗完全二叉树,但是还不是一个堆,现在我们通过算法,把它构建成一个堆。根节点左右子树不是堆,我们怎么调整呢?
3.3.1使用向上调整
从数组的第二个元素开始,使其按照小堆/大堆的规则调整成堆
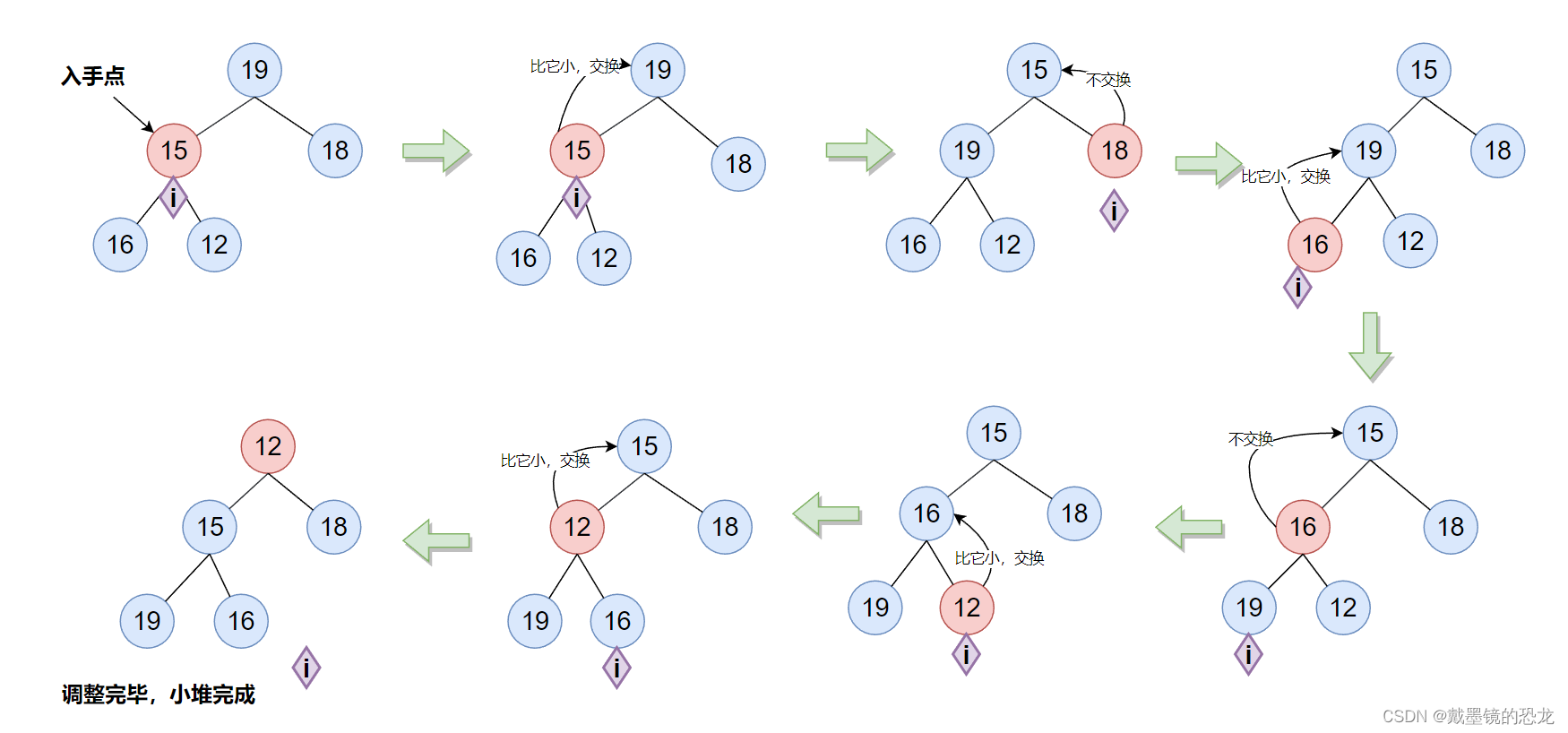
void HeapCreat(Heap* php, HeapDataType* a, int n)
{assert(php);php->a = (HeapDataType*)malloc(sizeof(HeapDataType) * n);//申请和数组同样大的空间if (php->a == NULL){perror("malloc fail");return;}memcpy(php->a, a, sizeof(HeapDataType) * n);//将数组中的元素拷贝进堆php->size = n;php->capacity = n;//向上调整,使其成堆for (int i = 1; i < n; i++){AdjustUp(php->a, i);}
}
3.3.2使用向下调整
用向下调整法,我们从倒数的第一个非叶子节点的子树开始调整,一直调整到根节点的树,就可以调整成堆。
其实本质上就是:从下往上,将根的每个子树调整成堆
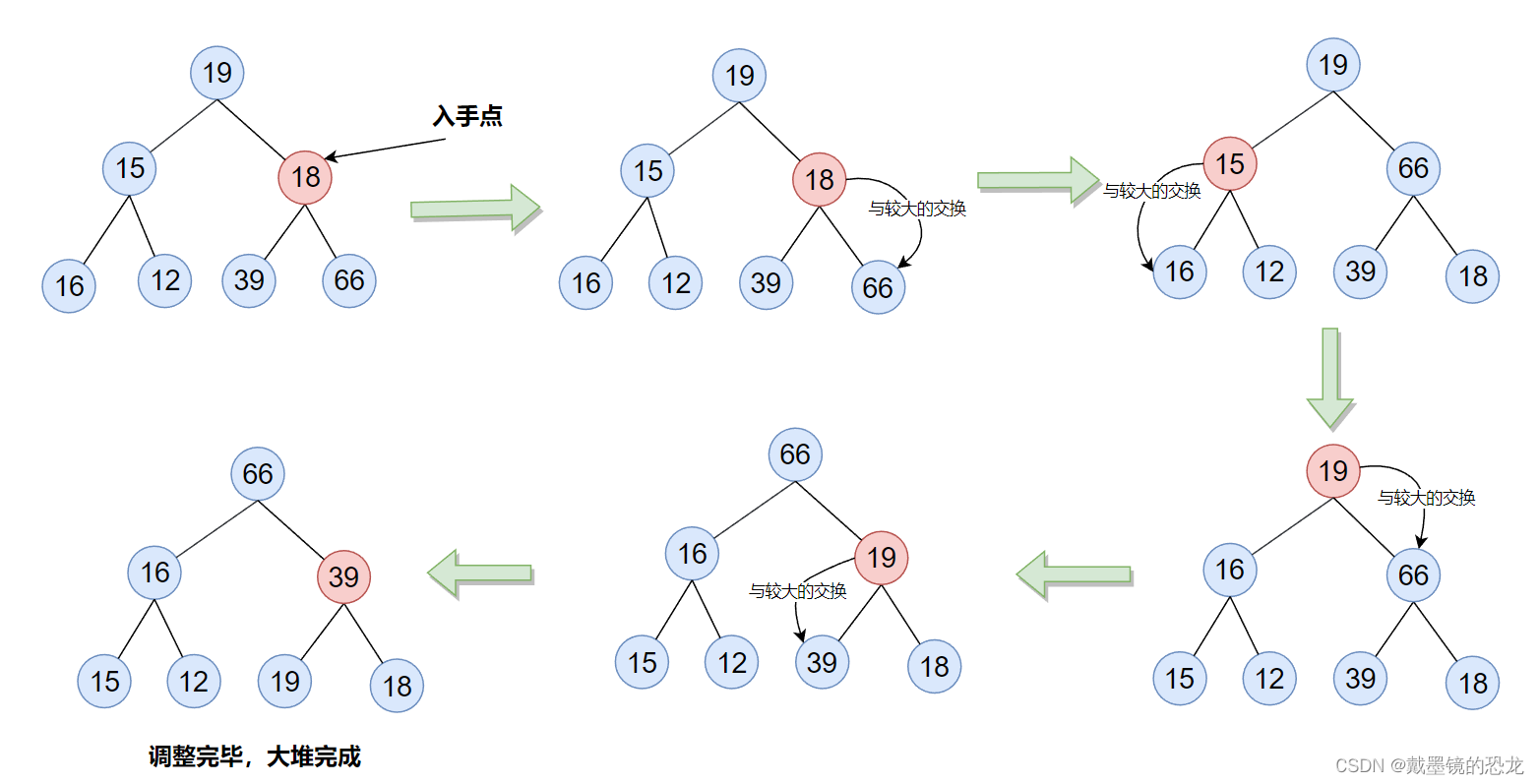
由于最后一个元素的下标为n-1,所以它的父亲应该是:(其下标-1)/2,也就是(n-1-1)/2。
void HeapCreat(Heap* php, HeapDataType* a, int n)
{assert(php);php->a = (HeapDataType*)malloc(sizeof(HeapDataType) * n);//申请和数组同样大的空间if (php->a == NULL){perror("malloc fail");return;}memcpy(php->a, a, sizeof(HeapDataType) * n);//将数组中的元素拷贝进堆php->size = n;php->capacity = n;//向下调整,使其成堆for (int i = (n - 1 - 1) / 2; i >= 0; i--){AdjustDown(php->a, n, i);}
}
3.3.3两种建堆方式的比较
- 树的高度与节点个数的关系
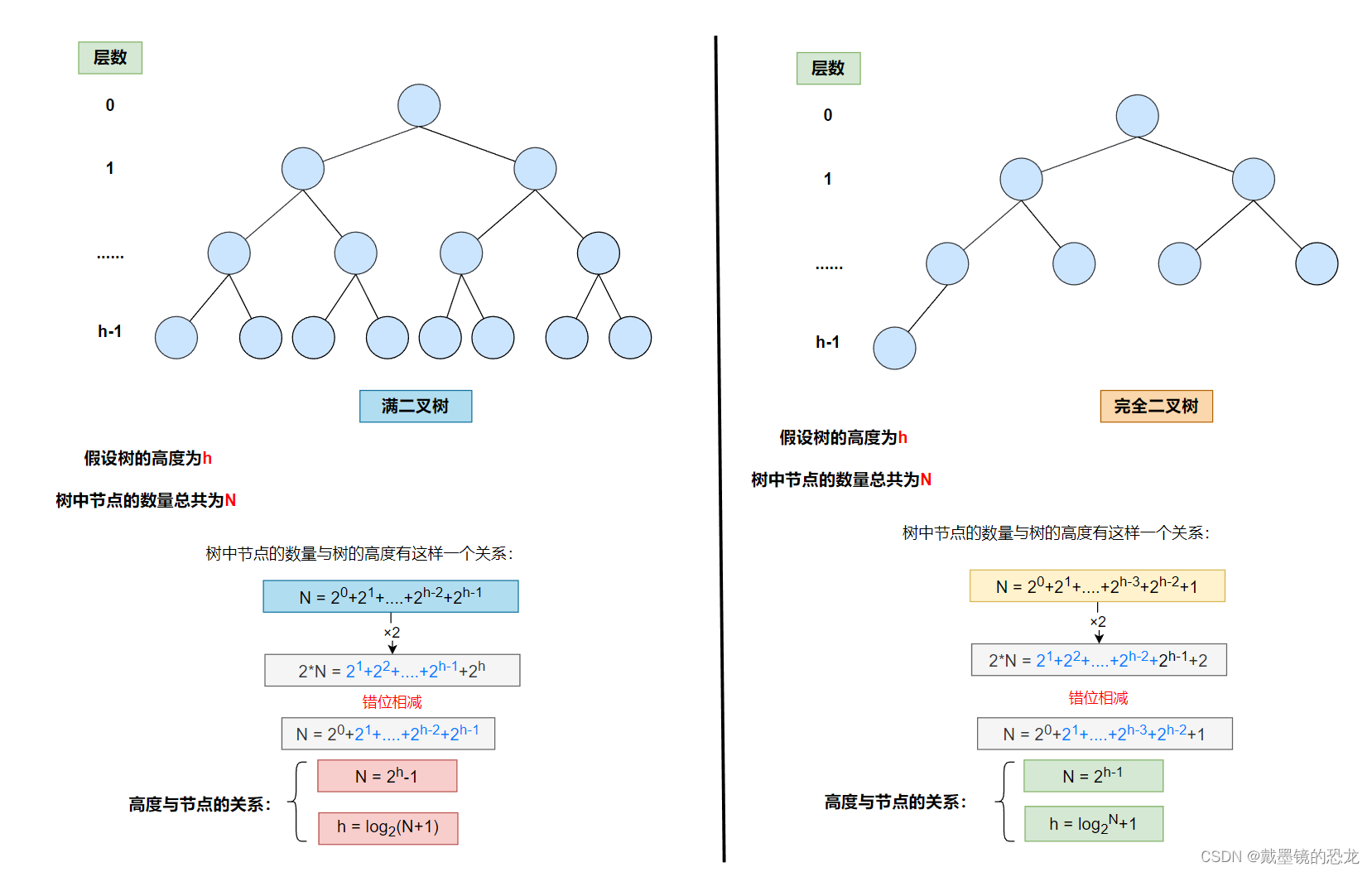
- 向上调整法建堆时间复杂度的分析
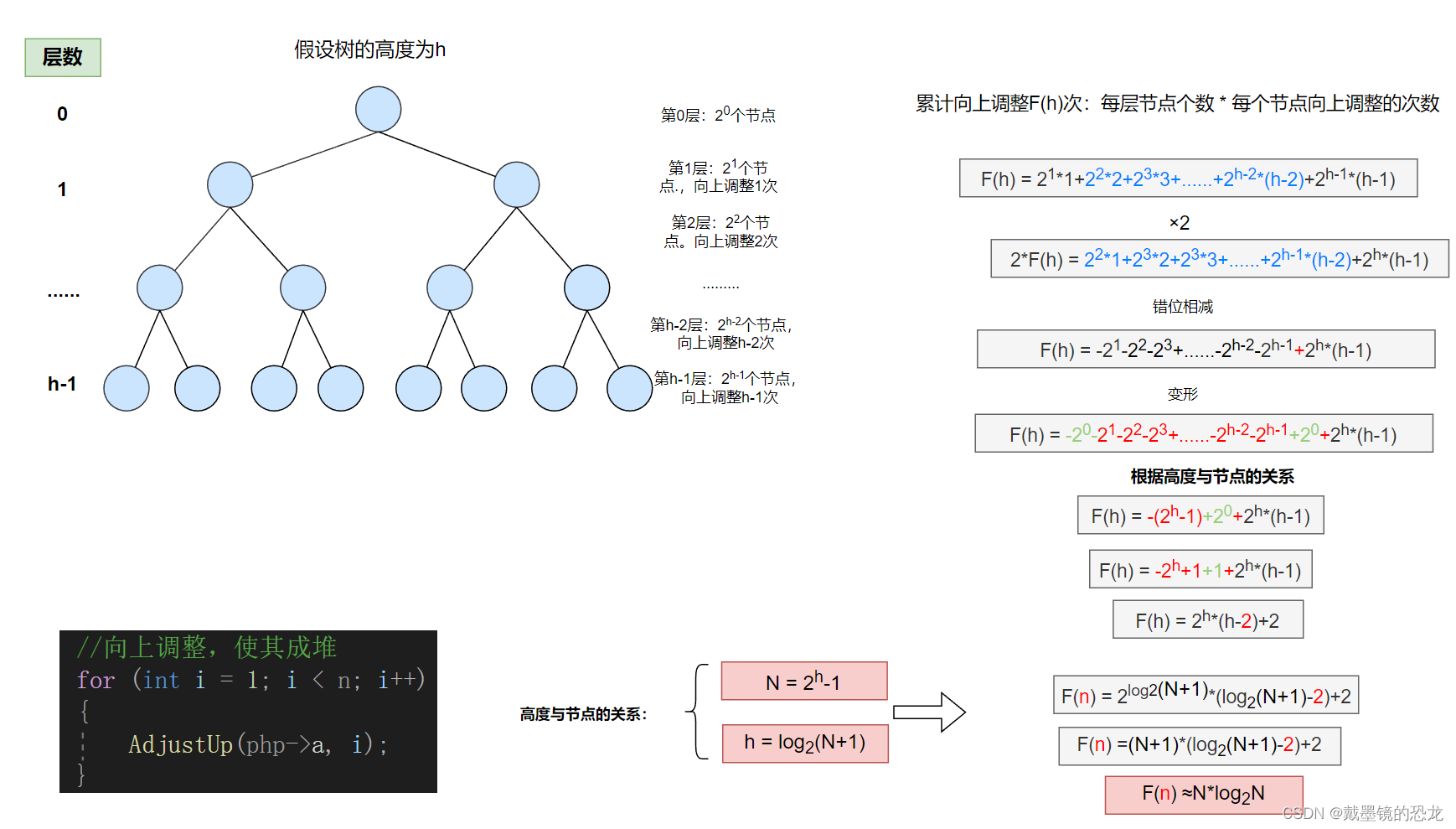
因此,向上调整建堆的时间复杂度为:O(N*log2N)
- 向下调整法建堆时间复杂度的分析
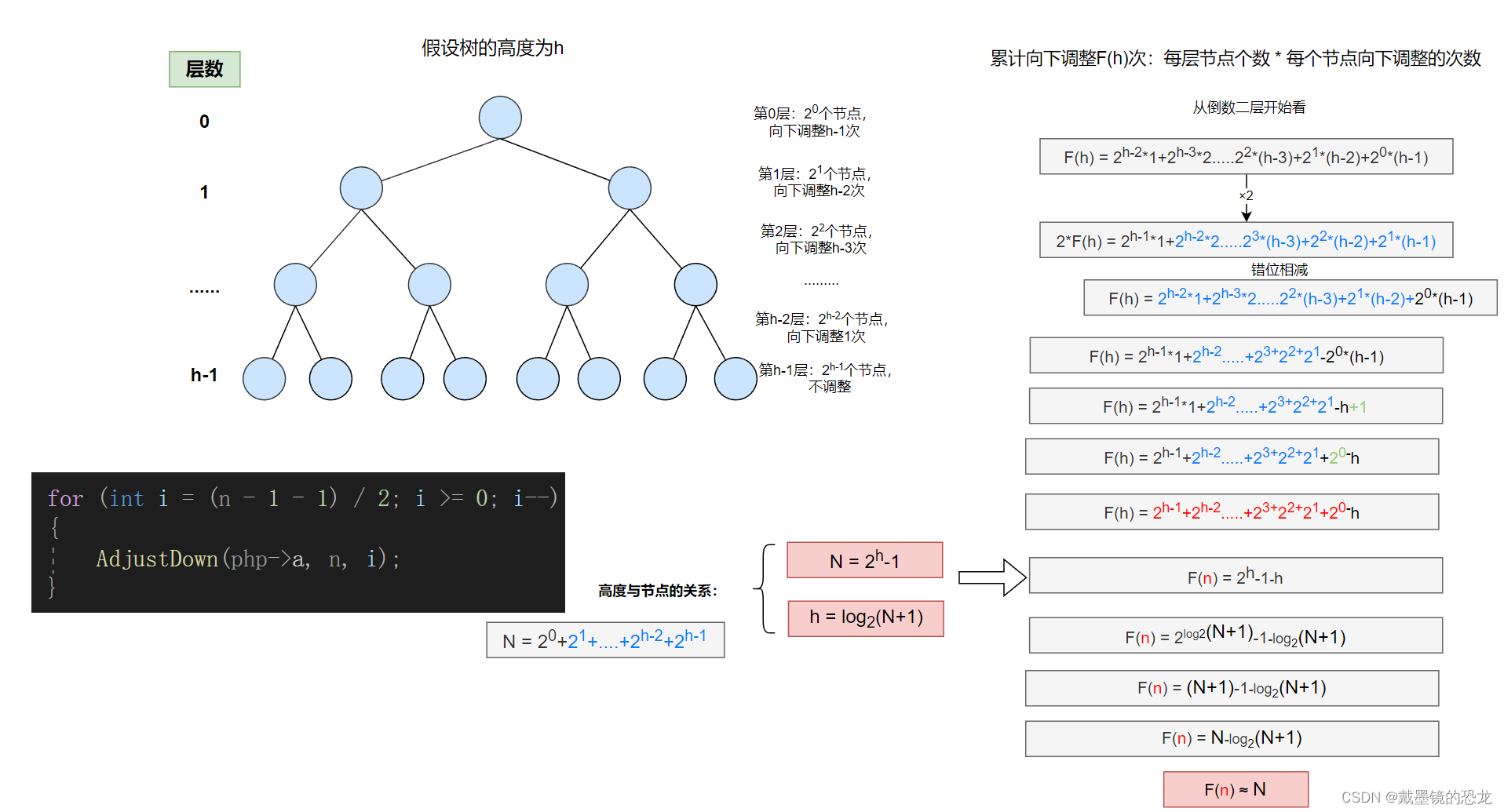
因此,向下调整建堆的时间复杂度为:O(N)
O(N*log2N) 与O(N)看来两种方法的效率差别还是挺大的。为什么差别这么大呢?

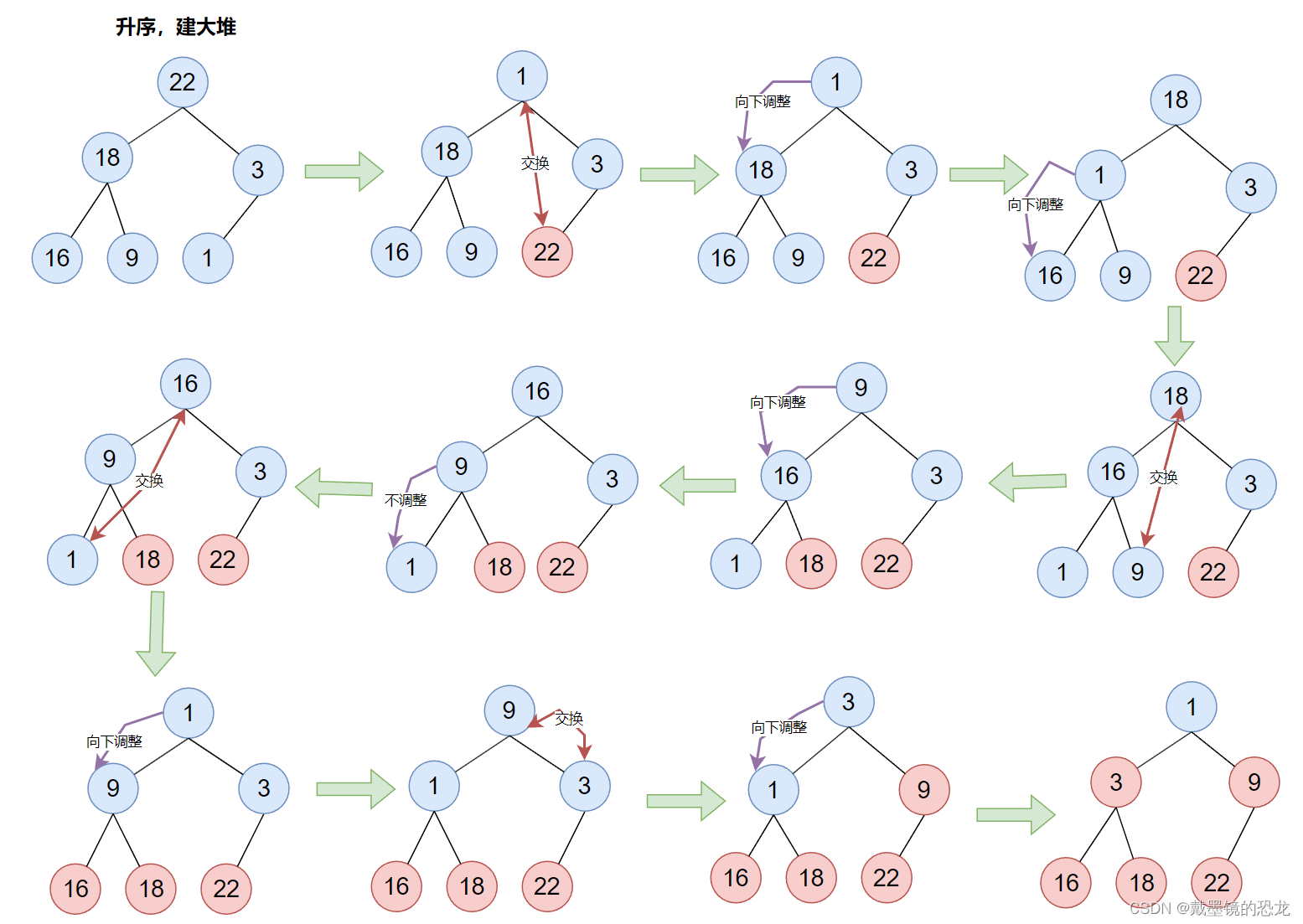
3.4堆排序
堆排序即利用堆的思想来进行排序,总共分为两个步骤:
-
建堆
升序:建大堆
降序:建小堆 -
利用堆删除思想来进行排序
首位交换
最后一个值不看做堆里面的,向下调整选出次大的数据
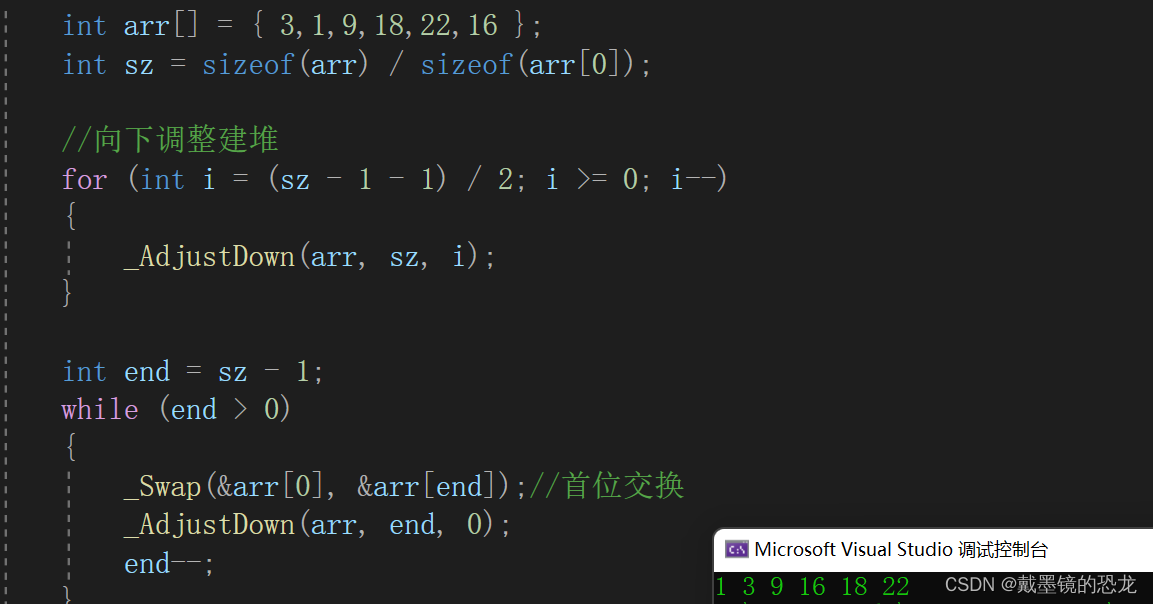
#include<stdio.h>
void _Swap(int* a, int* b)
{int tmp = *a;*a = *b;*b = tmp;
}void _AdjustDown(int* a, int n, int parent)
{int child = parent * 2 + 1;while (child < n){//右孩子存在,且大于左孩子if (child + 1 < n && a[child + 1] > a[child]){child++;}//孩子大于父亲,交换if (a[child] > a[parent]){_Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;//孩子不大于父亲,调整结束}}
}int main()
{int arr[] = { 3,1,9,18,22,16 };int sz = sizeof(arr) / sizeof(arr[0]);//向下调整建堆for (int i = (sz - 1 - 1) / 2; i >= 0; i--){_AdjustDown(arr, sz, i);}int end = sz - 1;while (end > 0){_Swap(&arr[0], &arr[end]);//首位交换_AdjustDown(arr, end, 0);end--;}for (int i = 0; i < sz; i++){printf("%d ", arr[i]);}return 0;
}
3.5TopK问题
TOP-K问题:即求数据中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。
对于Top-K问题,能想到的最简单直接的方式就是排序,但是:如果数据量非常大,排序就不太可取了(可能数据都不能一下子全部加载到内存中)。最佳的方式就是用堆来解决,基本思路如下:
- 用数据集合中前K个元素来建堆
前k个最大的元素,则建小堆
前k个最小的元素,则建大堆 - 用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素
- 将剩余N-K个元素依次与堆顶元素比完之后,堆中剩余的K个元素就是所求的前K个最小或者最大的元素。
void TopK(int k)
{FILE* fp = fopen("data.txt", "r");if (fp == NULL){return;}int* heap = (int*)malloc(sizeof(int) * k);if (heap == NULL){perror("malloc fail");return;}//先读取k个数据for (int i = 0; i < k; i++){fscanf(fp, "%d", &heap[i]);}//根据k个数据建小堆for (int i = (k - 1 - 1) / 2; i >= 0; i--){_AdjustDown(heap, k, i);}int num = 0;while (fscanf(fp, "%d", &num) != EOF){//读取堆顶数据,比它大就替换它,进堆if (num > heap[0]){heap[0] = num;_AdjustDown(heap, k, 0);}}for (int i = 0; i < k; i++){printf("%d ", heap[i]);}fclose(fp);
}