MySQL学习之DQL语句(数据查询语言)
准备SQL
CREATE TABLE student ( id int, -- 编号 name varchar(20), -- 姓名 age int, -- 年龄 sex varchar(5), -- 性别 address varchar(100), -- 地址 math int, -- 数学 english int -- 英语 );INSERT INTO student(id,NAME,age,sex,address,math,english) VALUES (1,'马云',55,'男', '杭州',66,78),(2,'马化腾',45,'女','深圳',98,87),(3,'马景涛',55,'男','香港',56,77),(4,'柳岩',20,'女','湖南',76,65),(5,'柳青',20,'男','湖南',86,NULL),(6,'刘德华',57,'男','香港',99, 99),(7,'马德',22,'女','香港',99,99),(8,'德玛西亚',18,'男','南京',56,65); 
DQL概述
1)SELECT语句
SELECT语句是用于查看计算结果、或者查看从数据表中筛选出的数据的。
SELECT语句的基本语法:
SELECT 常量;
SELECT 表达式;
SELECT 函数;
例如
SELECT 1;
SELECT 9/2;
SELECT NOW(); 
2)使用别名
在当前select语句中给某个字段或表达式计算结果,或表等取个临时名称,便于当前select语句的编写和理解。这个临时名称称为别名。
select 字段名1 as "别名1", 字段名2 as "别名2" from 表名称 as 别名;-
列的别名有空格时,请加双引号。==列的别名==中没有空格时,双引号可以加也可以不加。
-
==表的别名不能加双引号==,表的别名中间不能包含空格。
-
as大小写都可以,as也完全可以省略。
mysql> select * from student;
+------+------+
| id | name |
+------+------+
| 1 | 张三 |
| 2 | 李四 |
+------+------+
2 rows in set (0.00 sec)mysql> select id "学号",name "姓名" from student;
+------+------+
| 学号 | 姓名 |
+------+------+
| 1 | 张三 |
| 2 | 李四 |
+------+------+
2 rows in set (0.00 sec)mysql> select id 学号,name 姓名 from student;
+------+------+
| 学号 | 姓名 |
+------+------+
| 1 | 张三 |
| 2 | 李四 |
+------+------+
2 rows in set (0.00 sec)mysql> select id 学 号,name 姓 名 from student;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use n
ear '号,name 姓 名 from student' at line 13)结果去重
mysql可以在查询结果中使用distinct关键字去重。
select distinct 字段列表 from 表名称 【where 条件】; select distinct did from t_employee;一、基础查询
(1)需求:查询指定数据表中所有数据
语法:select * from 数据表名;
代码:select * from student;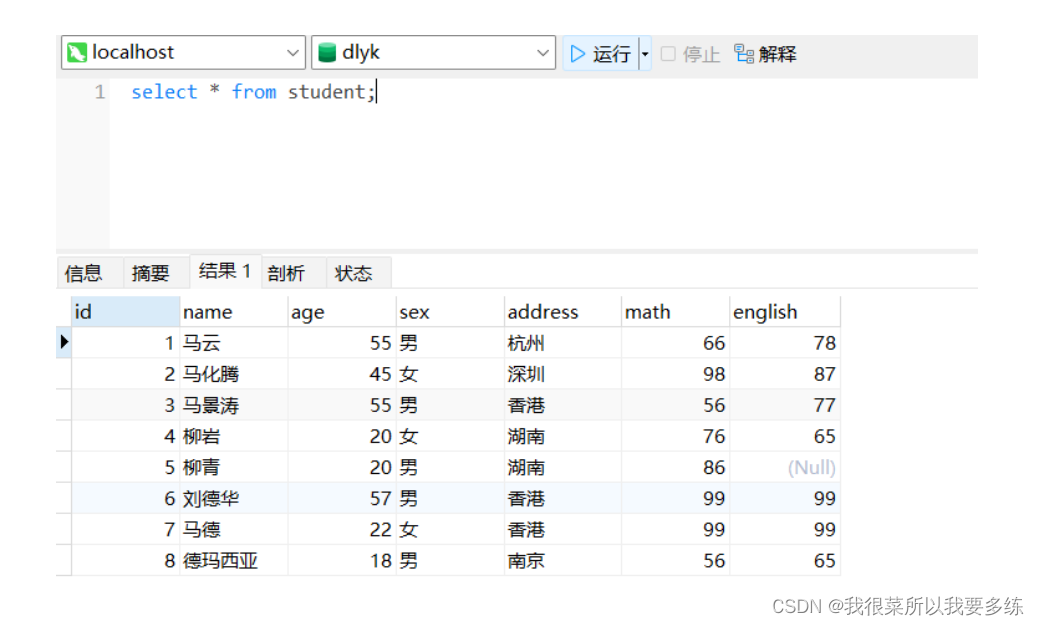
(2)需求:查询指定数据表中指定列所有数据(查询所有的数学和英语成绩)
语法:select 列名1,列名2,......,列名n from 数据表名;
代码:select name,math,english from student;
(3)需求:去掉指定数据表中指定列中重复的数据(去掉地址中的重复数据)
语法:select distinct 列名1,列名2,......,列名n from 数据表名;
代码:select distinct address from student;(4)需求:获取每个同学的总分
代码:select name,math,english,math+english from student;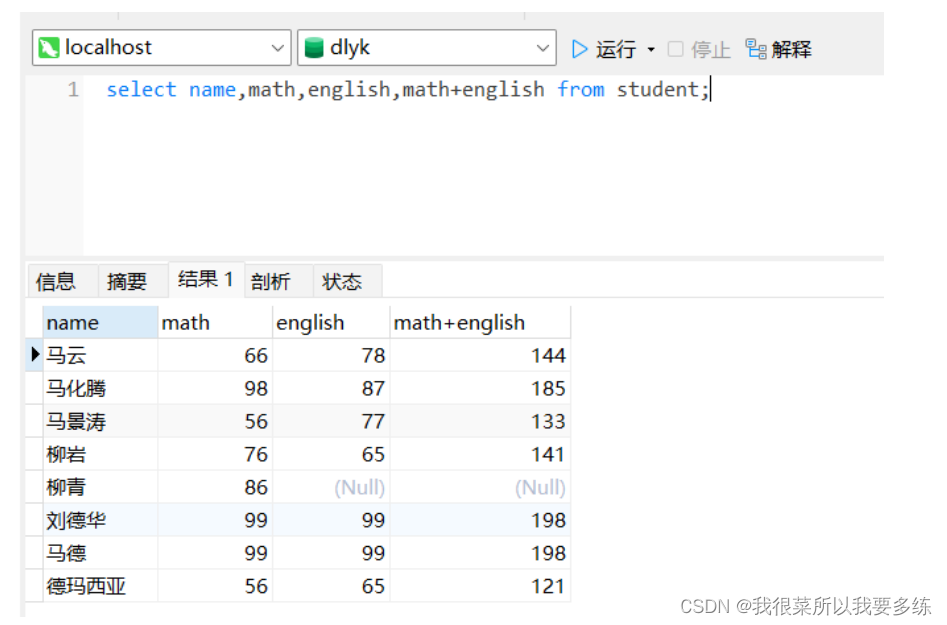
注意:数据表中数据的默认值是null,任何值与null进行计算结果都为null,可以使用非空判断解决null值的问题
语法:ifnull(x,y);
x:可能出现null值的列名
y:该列名对应的条目如果出现null值后,需要替换的数据
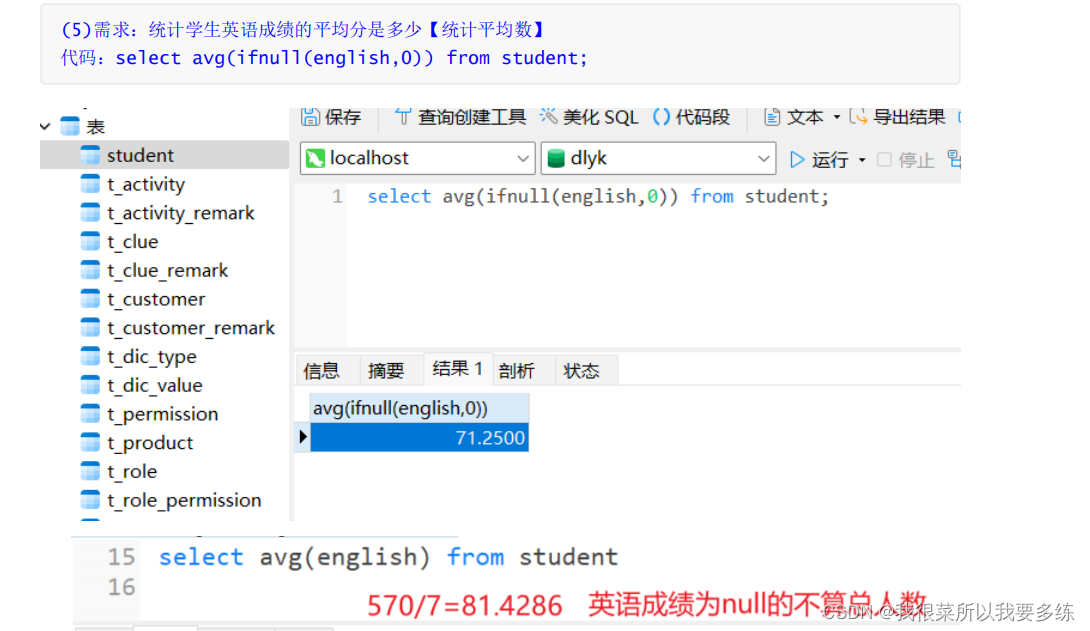
代码:select name,ifnull(math,0),ifnull(english,0),ifnull(math,0)+ifnull(english,0) from student;
二、条件查询
预备知识
条件查询需要用到where语句,where必须放到from语句表的后面
支持如下运算符
| 运算符 | 说明 |
| = | 等于 |
| <>或!= | 不等于 |
| < | 小于 |
| <= | 小于等于 |
| > | 大于 |
| >= | 大于等于 |
| between … and …. | 两个值之间,等同于 >= and <= |
| is null | 为null(is not null 不为空) |
| and | 并且 |
| or | 或者 |
| in | 包含,相当于多个or(not in不在这个范围中) |
| not | not可以取非,主要用在is 或in中 |
| like | like称为模糊查询,支持%或下划线匹配 %匹配任意个字符 下划线,一个下划线只匹配一个字符 |
运算符
(1)算数运算符
加:+
在MySQL +就是求和,没有字符串拼接
减:-
乘:*
除:/ div(只保留整数部分)
div:两个数相除只保留整数部分
/:数学中的除
模:% modmysql中没有 +=等运算符
#select 表达式
select 1+1;
update t_employee set salary = salary+100 where eid=27;select 9/2, 9 div 2;mysql> select 9/2, 9 div 2;
+--------+---------+
| 9/2 | 9 div 2 |
+--------+---------+
| 4.5000 | 4 |
+--------+---------+
1 row in set (0.00 sec)select 9.5 / 1.5 , 9.5 div 1.5;mysql> select 9.5 / 1.5 , 9.5 div 1.5;
+-----------+-------------+
| 9.5 / 1.5 | 9.5 div 1.5 |
+-----------+-------------+
| 6.33333 | 6 |
+-----------+-------------+
1 row in set (0.00 sec)select 9 % 2, 9 mod 2;
select 9.5 % 1.5 , 9.5 mod 1.5;select 'hello' + 'world';
mysql> select 'hello' + 'world';
+-------------------+
| 'hello' + 'world' |
+-------------------+
| 0 |
+-------------------+
1 row in set, 2 warnings (0.00 sec)(2)比较运算符
大于:>
小于:<
大于等于:>=
小于等于:>=
等于:= 不能用于null判断
不等于:!= 或 <> 不能用于null判断
#查询薪资高于15000的员工姓名和薪资
select ename,salary from t_employee where salary>15000;mysql> select ename,salary from t_employee where salary>15000;
+--------+--------+
| ename | salary |
+--------+--------+
| 孙洪亮 | 28000 |
| 贾宝玉 | 15700 |
| 黄冰茹 | 15678 |
| 李冰冰 | 18760 |
| 谢吉娜 | 18978 |
| 舒淇格 | 16788 |
| 章嘉怡 | 15099 |
+--------+--------+
7 rows in set (0.00 sec)#查询薪资正好是9000的员工姓名和薪资
select ename,salary from t_employee where salary = 9000;
select ename,salary from t_employee where salary == 9000;#错误,不支持== #注意Java中判断用==,mysql判断用=mysql> select ename,salary from t_employee where salary == 9000;
ERROR 1064 (42000): You have an error in your SQL syntax;check the manual that corresponds to your MySQL server version for the right syntax to use near '== 9000' at line 1#查询籍贯native_place不是北京的
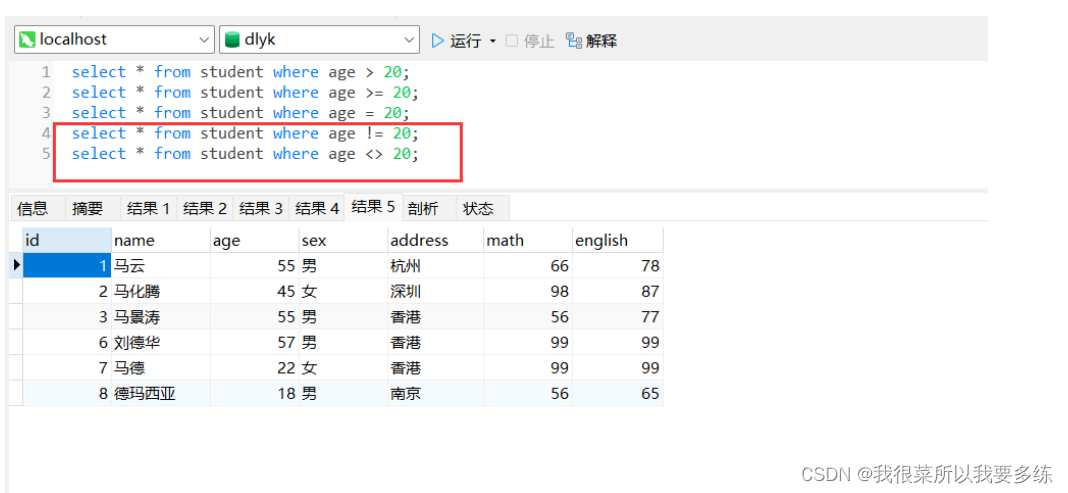
select * from t_employee where native_place != '北京';
select * from t_employee where native_place <> '北京';#查询员工表中部门编号不是1
select * from t_employee where did != 1;
select * from t_employee where did <> 1;#查询奖金比例是NULL
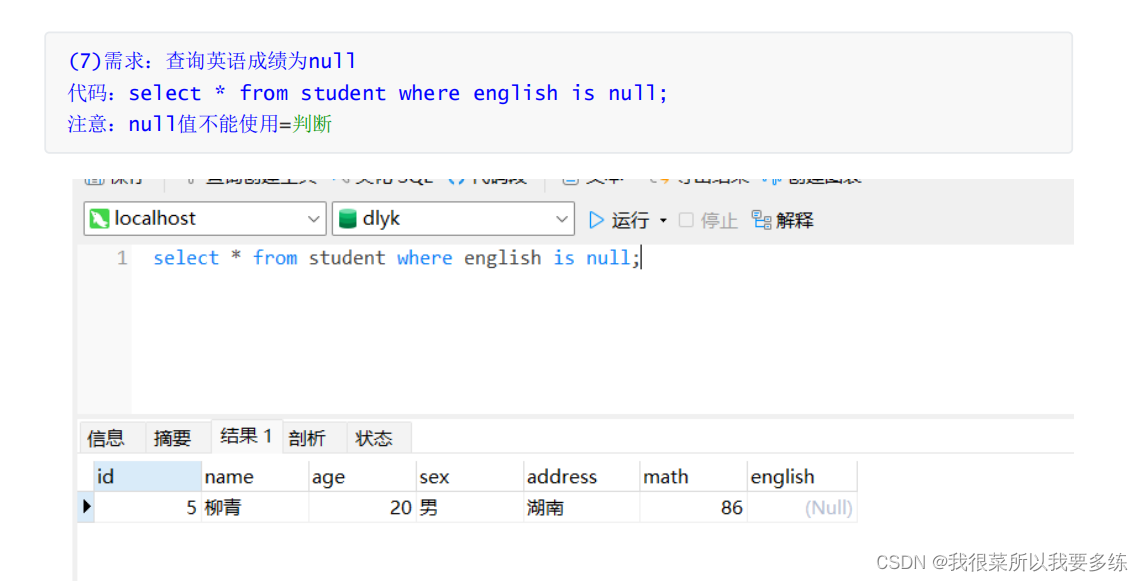
select * from t_employee where commission_pct = null; mysql> select * from t_employee where commission_pct = null; #无法用=null判断
Empty set (0.00 sec)
#mysql中只要有null值参与运算和比较,结果就是null,底层就是0,表示条件不成立。#查询奖金比例是NULL
select * from t_employee where commission_pct <=> null;
select * from t_employee where commission_pct is null; #查询“李冰冰”、“周旭飞”、“李易峰”这几个员工的信息
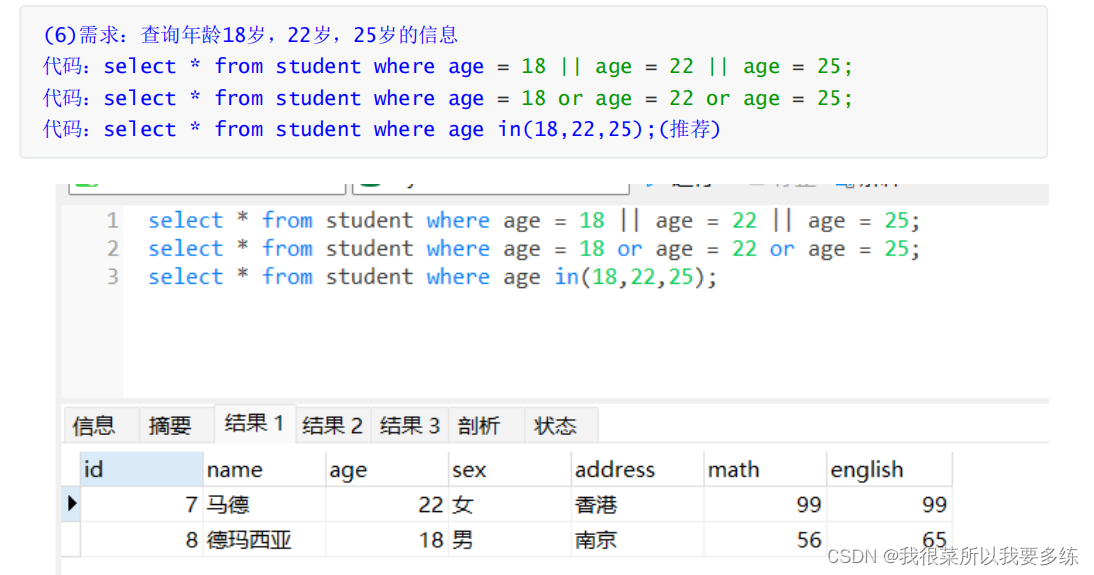
select * from t_employee where ename in ('李冰冰','周旭飞','李易峰');#查询部门编号为2、3的员工信息
select * from t_employee where did in(2,3);#查询部门编号不是2、3的员工信息
select * from t_employee where did not in(2,3);#查询薪资在[10000,15000]之间
select * from t_employee where salary between 10000 and 15000;#查询姓名中第二个字是'冰'的员工
select * from t_employee where ename like '冰'; #这么写等价于 ename='冰'
select * from t_employee where ename like '_冰%';
#这么写匹配的是第二个字是冰,后面可能没有第三个字,或者有好几个字update t_employee set ename = '王冰' where ename = '李冰冰';select * from t_employee where ename like '_冰_';
#这么写匹配的是第二个字是冰,后面有第三个字,且只有三个字#查询员工的姓名、薪资、奖金比例、实发工资
#实发工资 = 薪资 + 薪资 * 奖金比例
select ename as 姓名,
salary as 薪资,
commission_pct as 奖金比例,
salary + salary * commission_pct as 实发工资
from t_employee;#NULL在mysql中比较和计算都有特殊性,所有的计算遇到的null都是null。
#实发工资 = 薪资 + 薪资 * 奖金比例
select ename as 姓名,
salary as 薪资,
commission_pct as 奖金比例,
salary + salary * ifnull(commission_pct,0) as 实发工资
from t_employee;(3)区间或集合范围比较运算符
区间范围:between x and y
not between x and y
集合范围:in (x,x,x)
not in(x,x,x)
#查询薪资在[10000,15000]
select * from t_employee where salary>=10000 && salary<=15000;
select * from t_employee where salary between 10000 and 15000;#查询籍贯在这几个地方的
select * from t_employee where native_place in ('北京', '浙江', '江西');#查询薪资不在[10000,15000]
select * from t_employee where salary not between 10000 and 15000;#查询籍贯不在这几个地方的
select * from t_employee where native_place not in ('北京', '浙江', '江西');(4)模糊匹配比较运算符
%:代表任意个字符
_:代表一个字符,如果两个下划线代表两个字符
#查询名字中包含'冰'字
select * from t_employee where ename like '%冰%';#查询名字以‘雷'结尾的
select * from t_employee where ename like '%雷';#查询名字以’李'开头
select * from t_employee where ename like '李%';#查询名字有冰这个字,但是冰的前面只能有1个字
select * from t_employee where ename like '_冰%';#查询当前mysql数据库的字符集情况
show variables like '%character%';(5)逻辑运算符
逻辑与:&& 或 and
逻辑或:|| 或 or
逻辑非:! 或 not
逻辑异或: xor
#查询薪资高于15000,并且性别是男的员工
select * from t_employee where salary>15000 and gender='男';
select * from t_employee where salary>15000 && gender='男';select * from t_employee where salary>15000 & gender='男';#错误 &按位与
select * from t_employee where (salary>15000) & (gender='男');#查询薪资高于15000,或者did为1的员工
select * from t_employee where salary>15000 or did = 1;
select * from t_employee where salary>15000 || did = 1;#查询薪资不在[15000,20000]范围的
select * from t_employee where salary not between 15000 and 20000;
select * from t_employee where !(salary between 15000 and 20000);#查询薪资高于15000,或者did为1的员工,两者只能满足其一
select * from t_employee where salary>15000 xor did = 1;
select * from t_employee where (salary>15000) ^ (did = 1);(6)关于NUll值的问题(掌握)
#(1)判断时
xx is null
xx is not null
xx <=> null#(2)计算时
ifnull(xx,代替值) 当xx是null时,用代替值计算
#查询奖金比例为null的员工
select * from t_employee where commission_pct = null; #失败
select * from t_employee where commission_pct = NULL; #失败
select * from t_employee where commission_pct = 'NULL'; #失败select * from t_employee where commission_pct is null; #成功
select * from t_employee where commission_pct <=> null; #成功 <=>安全等于#查询员工的实发工资,实发工资 = 薪资 + 薪资 * 奖金比例
select ename , salary + salary * commission_pct "实发工资" from t_employee; #失败,当commission_pct为null,结果都为nullselect ename ,salary , commission_pct, salary + salary * ifnull(commission_pct,0) "实发工资" from t_employee;(7)位运算符-----了解
基本不用,了解一下
左移:<<
右移:>>
按位与:&
按位或:|
按位异或:^
按位取反:~条件查询案例演示
语法:select * from 数据表名 where 条件;
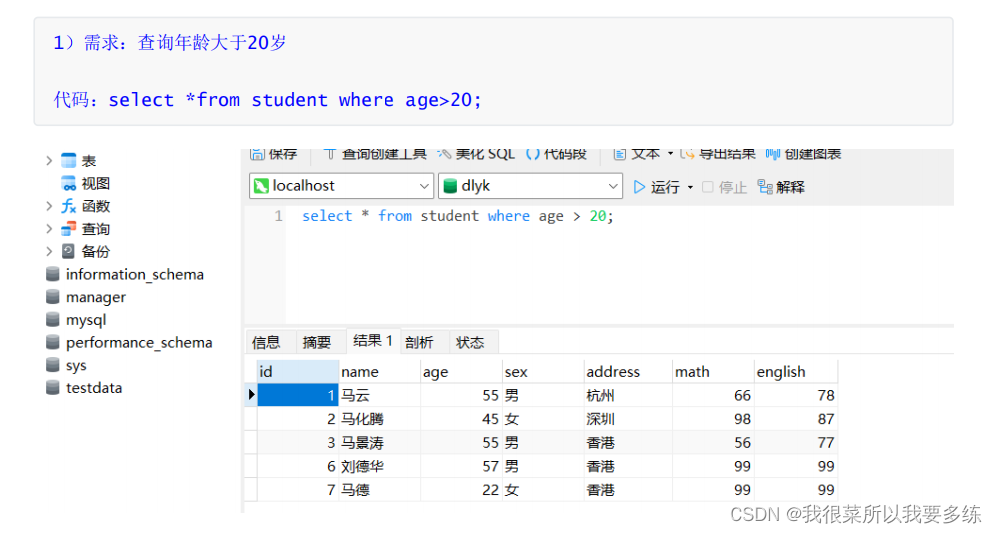

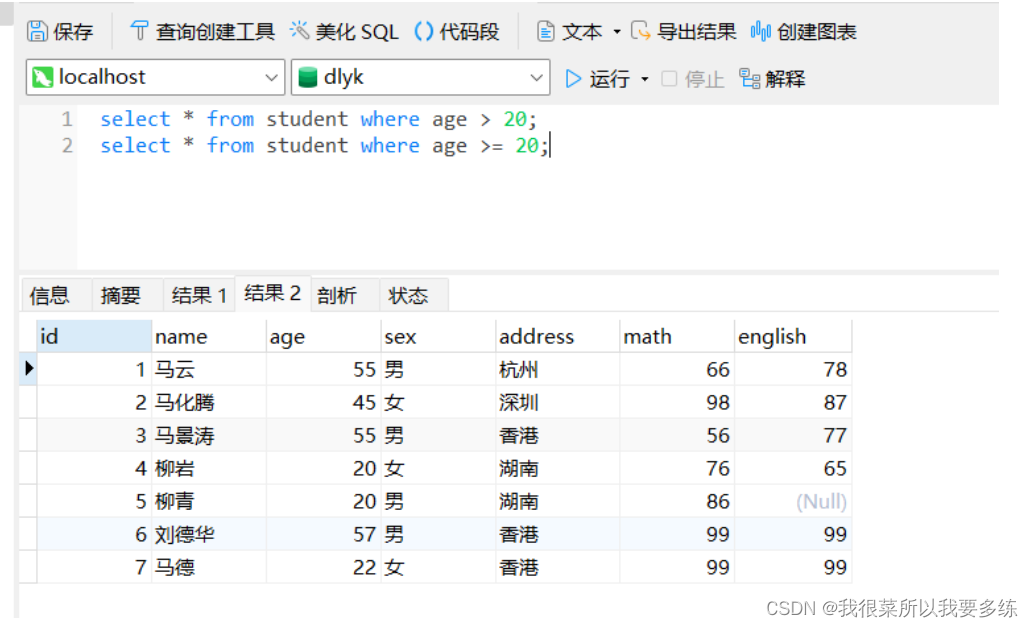



三、模糊查询
语法:select * from 数据表名 where 列名 like 模糊查询的数据值;

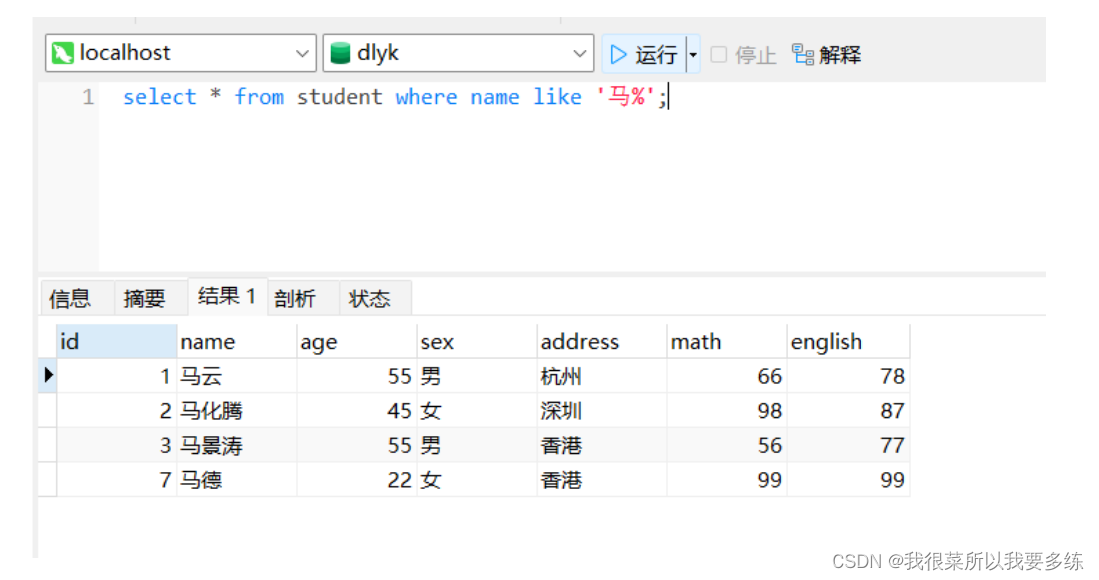

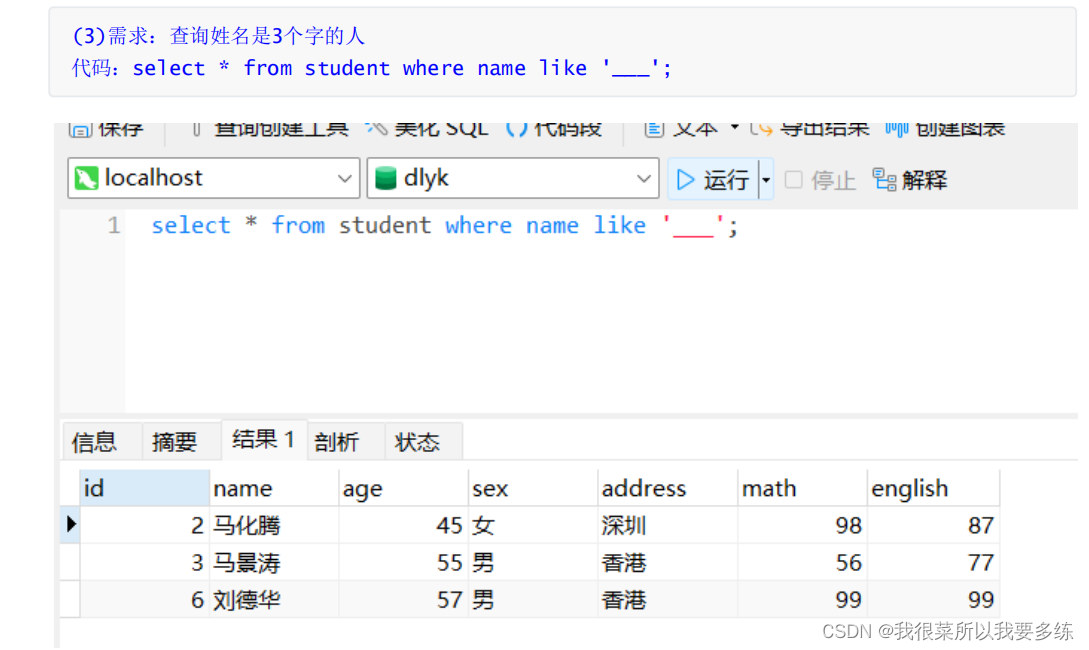
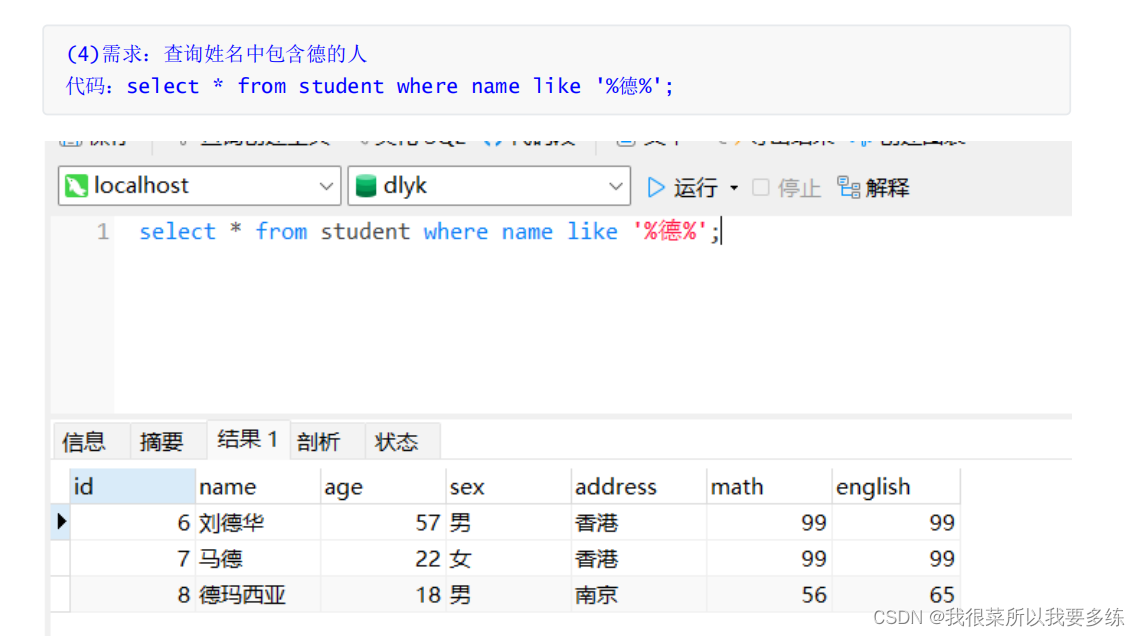
四、排序查询
语法:select * from 数据表名 order by 排序列名1 排序规则1,排序列名2 排序规则2,......,排序列名n 排序规则n;
规则:
升序规则:asc
降序规则:desc
注意:
如果使用排序查询,不指定排序规则,SQL语句会以"默认的升序"进行排序,建议写上
如果通过排序规则1后,数据没有重复元素,则不会启动后续的排序规则
排序采用order by子句,order by后面跟上排序字段,排序字段可以放多个,多个采用逗号间隔,order by默认采用升序,如果存在where子句那么order by必须放到where语句的后面
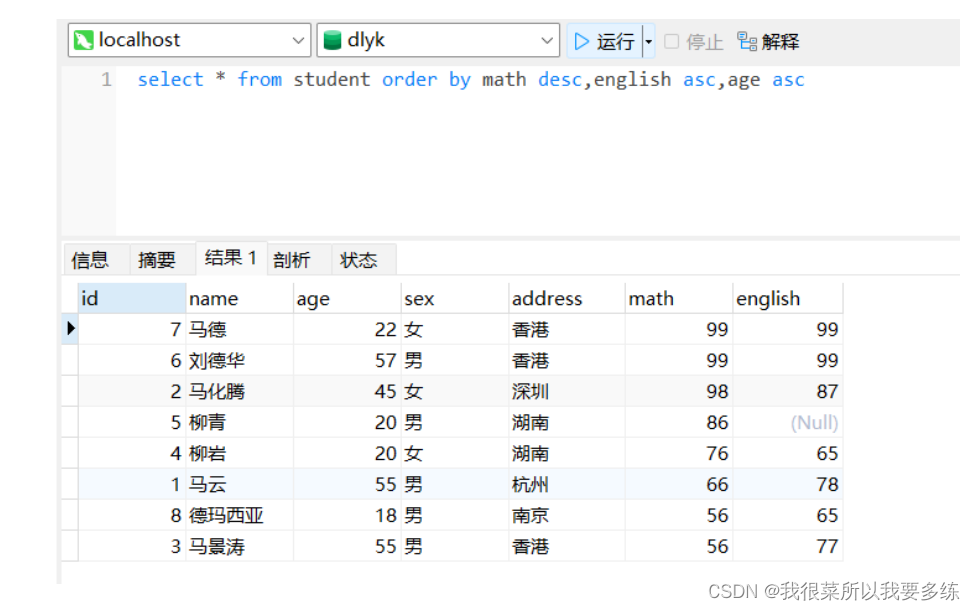
(1)需求:针对学生表中数学成绩进行降序排序
代码:select * from student order by math desc;

(2)需求:针对学生表中数学成绩进行降序排序,如果数学成绩相等,按照英语成绩进行升序排序
代码:select * from student order by math desc,english asc;
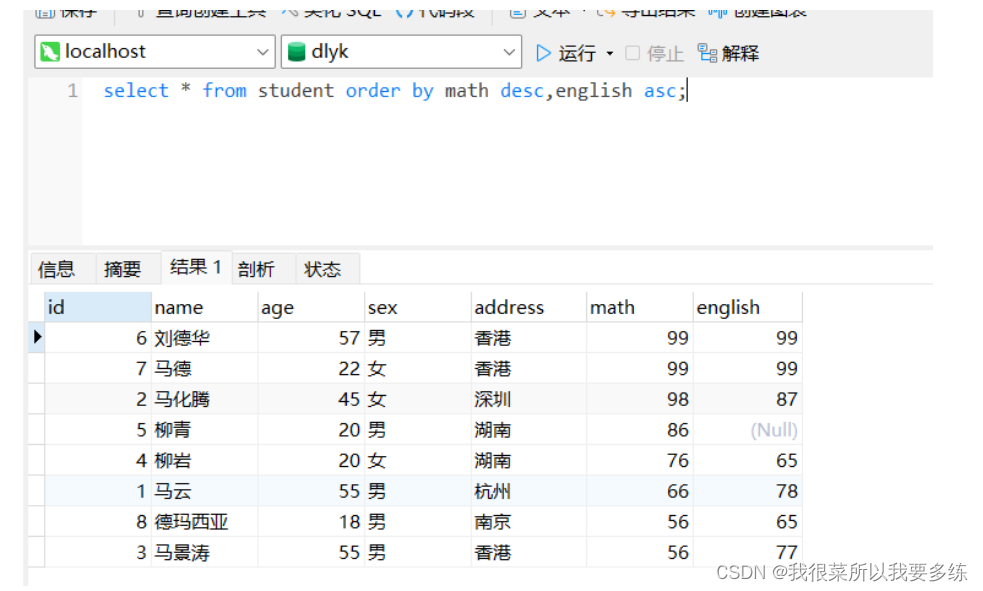
(3)需求:针对学生表中数学成绩进行降序排序,如果数学成绩相等,按照英语成绩进行升序排序;如果英语成绩相等,按照年龄的升序进行排序
代码:select * from student order by math desc,english asc,age asc;
五、系统预定义函数
函数:代表一个独立的可复用的功能。
和Java中的方法有所不同,不同点在于:MySQL中的函数必须有返回值,参数可以有可以没有。
MySQL中函数分为:
(1)系统预定义函数:MySQL数据库管理软件给我提供好的函数,直接用就可以,任何数据库都可以用公共的函数。
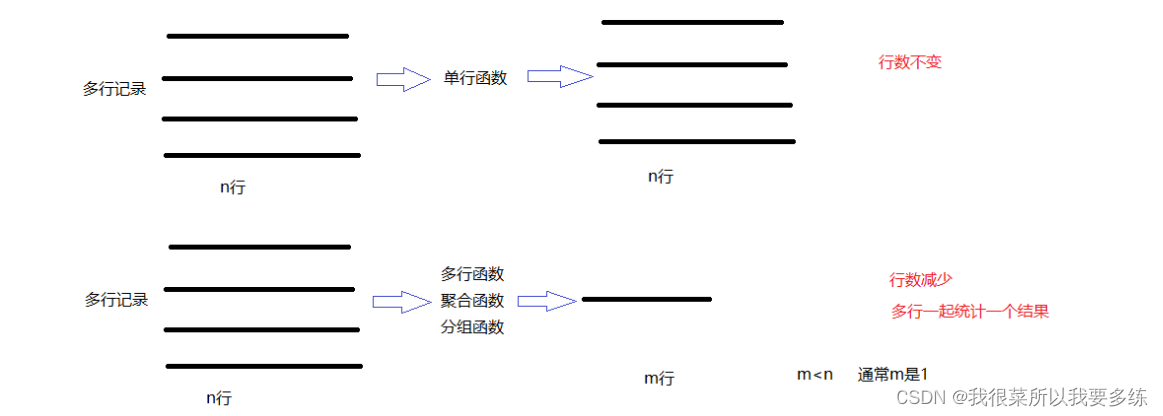
- 分组函数:或者又称为聚合函数,多行函数,表示会对表中的多行记录一起做一个“运算”,得到一个结果。
- 求平均值的avg,求最大值的max,求最小值的min,求总和sum,求个数的count等
- 单行函数:表示会对表中的每一行记录分别计算,有n行得到还是n行结果
- 数学函数、字符串函数、日期时间函数、条件判断函数、窗口函数等
(2)用户自定义函数:由开发人员自己定义的,通过CREATE FUNCTION语句定义,是属于某个数据库的对象。

1)分组函数
调用完函数后,结果的行数变少了,可能得到一行,可能得到少数几行。
分组函数有合并计算过程。

注意:分组函数自动忽略空值,不需要手动的加where条件排除空值。
select count(*) from emp where xxx; 符合条件的所有记录总数。
select count(comm) from emp; comm这个字段中不为空的元素总数。
注意:分组函数不能直接使用在where关键字后面。
mysql> select ename,sal from emp where sal > avg(sal);
ERROR 1111 (HY000): Invalid use of group function
#演示分组函数,聚合函数,多行函数
#统计t_employee表的员工的数量
SELECT COUNT(*) FROM t_employee;
SELECT COUNT(1) FROM t_employee;
SELECT COUNT(eid) FROM t_employee;
SELECT COUNT(commission_pct) FROM t_employee;/*
count(*)或count(常量值):都是统计实际的行数。
count(字段/表达式):只统计“字段/表达式”部分非NULL值的行数。
*/#找出t_employee表中最高的薪资值
SELECT MAX(salary) FROM t_employee;#找出t_employee表中最低的薪资值
SELECT MIN(salary) FROM t_employee;#统计t_employee表中平均薪资值
SELECT AVG(salary) FROM t_employee;#统计所有人的薪资总和,财务想看一下,一个月要准备多少钱发工资
SELECT SUM(salary) FROM t_employee; #没有考虑奖金
SELECT SUM(salary+salary*IFNULL(commission_pct,0)) FROM t_employee; #找出年龄最小、最大的员工的出生日期
SELECT MAX(birthday),MIN(birthday) FROM t_employee;#查询最新入职的员工的入职日期
SELECT MAX(hiredate) FROM t_employee;2)单行函数(了解,用的时候查,太多了,演示一小部分)
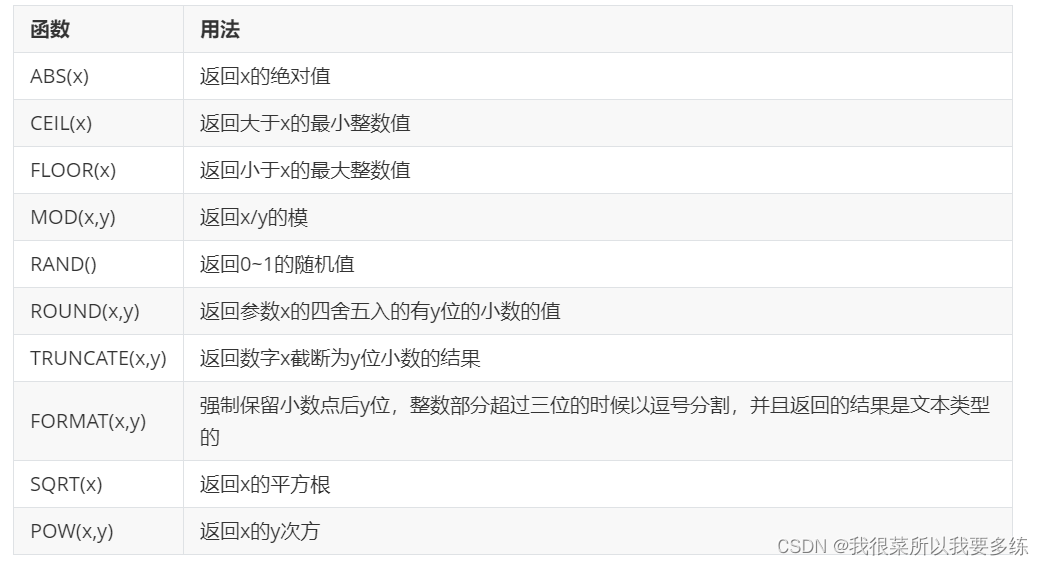
(1)数学函数(部分列出)
#单行函数
#演示数学函数
#在“t_employee”表中查询员工无故旷工一天扣多少钱,
#分别用CEIL、FLOOR、ROUND、TRUNCATE函数。
#假设本月工作日总天数是22天,
#旷工一天扣的钱=salary/22。
SELECT ename,salary/22,CEIL(salary/22),
FLOOR(salary/22),ROUND(salary/22,2),
TRUNCATE(salary/22,2) FROM t_employee; #查询公司平均薪资,并对平均薪资分别
#使用CEIL、FLOOR、ROUND、TRUNCATE函数
SELECT AVG(salary),CEIL(AVG(salary)),
FLOOR(AVG(salary)),ROUND(AVG(salary)),
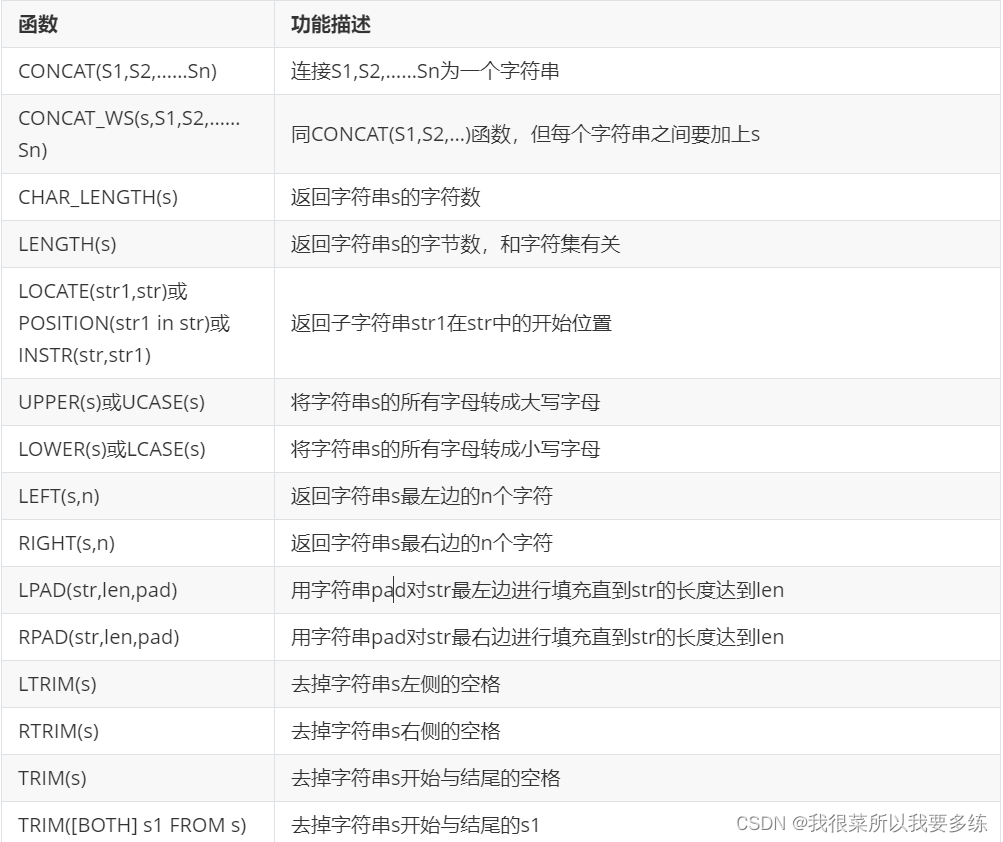
TRUNCATE(AVG(salary),2) FROM t_employee;(2)字符串函数(部分列出)

#字符串函数
#mysql中不支持 + 拼接字符串,需要调用函数来拼接
#(1)在“t_employee”表中查询员工姓名ename和电话tel,
#并使用CONCAT函数,CONCAT_WS函数。
SELECT CONCAT(ename,tel),CONCAT_WS('-',ename,tel) FROM t_employee;#(2)在“t_employee”表中查询薪资高于15000的男员工姓名,
#并把姓名处理成“张xx”的样式。
#LEFT(s,n)函数表示取字符串s最左边的n个字符,
#而RPAD(s,len,p)函数表示在字符串s的右边填充p使得字符串长度达到len。
SELECT RPAD(LEFT(ename,1),3,'x'),salary
FROM t_employee
WHERE salary>15000 AND gender ='男';#(3)在“t_employee”表中查询薪资高于10000的男员工姓名、
#姓名包含的字符数和占用的字节数。
SELECT ename,CHAR_LENGTH(ename) AS 占用字符数,LENGTH(ename) AS 占用字节数量
FROM t_employee
WHERE salary>10000 AND gender ='男';#(4)在“t_employee”表中查询薪资高于10000的男员工姓名和邮箱email,
#并把邮箱名“@”字符之前的字符串截取出来。
SELECT ename,email,
SUBSTRING(email,1, POSITION('@' IN email)-1)
FROM t_employee
WHERE salary > 10000 AND gender ='男';#mysql中 SUBSTRING截取字符串位置,下标从1开始,不是和Java一样从0开始。
#mysql中 position等指定字符串中某个字符,子串的位置也不是从0开始,都是从1开始。SELECT TRIM(' hello world '); #默认是去掉前后空白符
SELECT CONCAT('[',TRIM(' hello world '),']'); #默认是去掉前后空白符
SELECT TRIM(BOTH '&' FROM '&&&&hello world&&&&'); #去掉前后的&符号
SELECT TRIM(LEADING '&' FROM '&&&&hello world&&&&'); #去掉开头的&符号
SELECT TRIM(TRAILING '&' FROM '&&&&hello world&&&&'); #去掉结尾的&符号(3)日期和时间函数
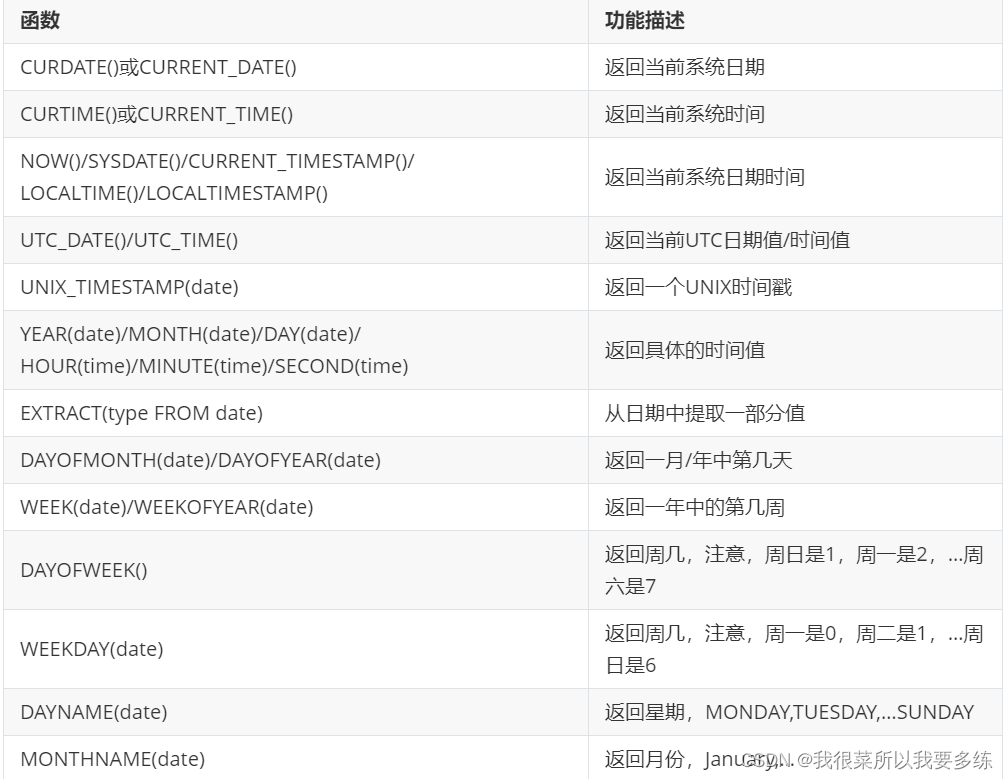


函数中的format格式说明
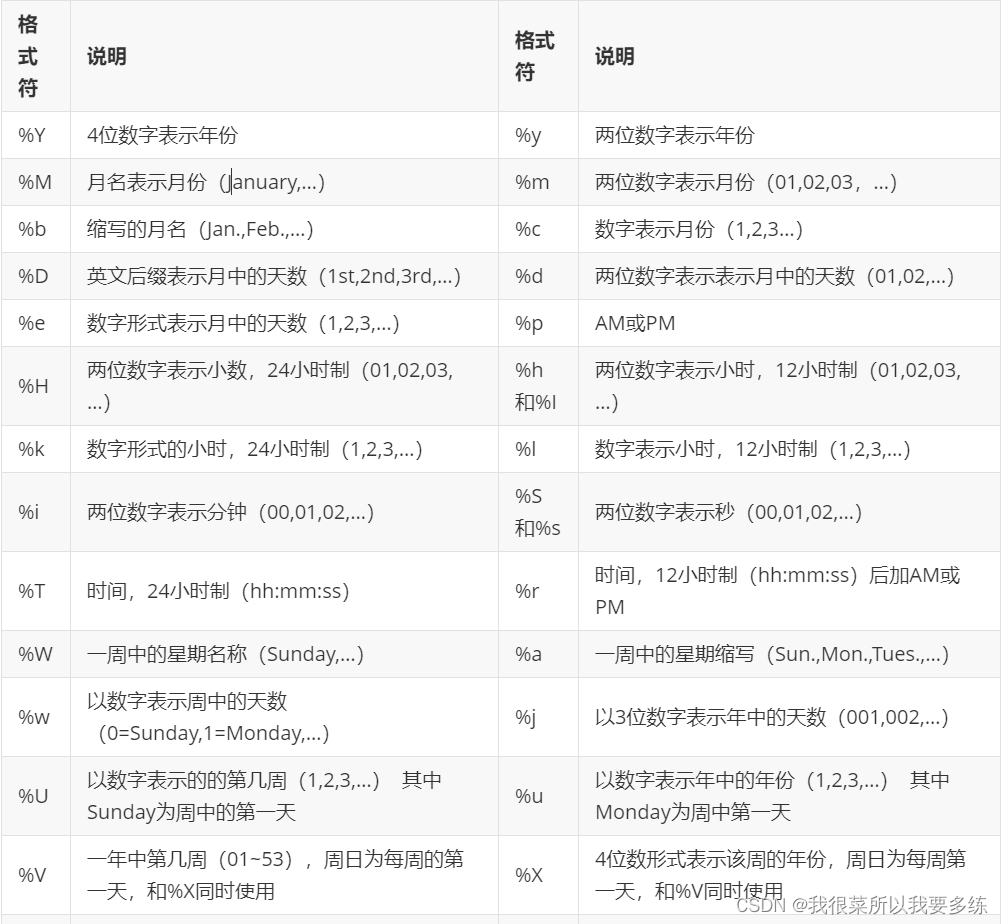

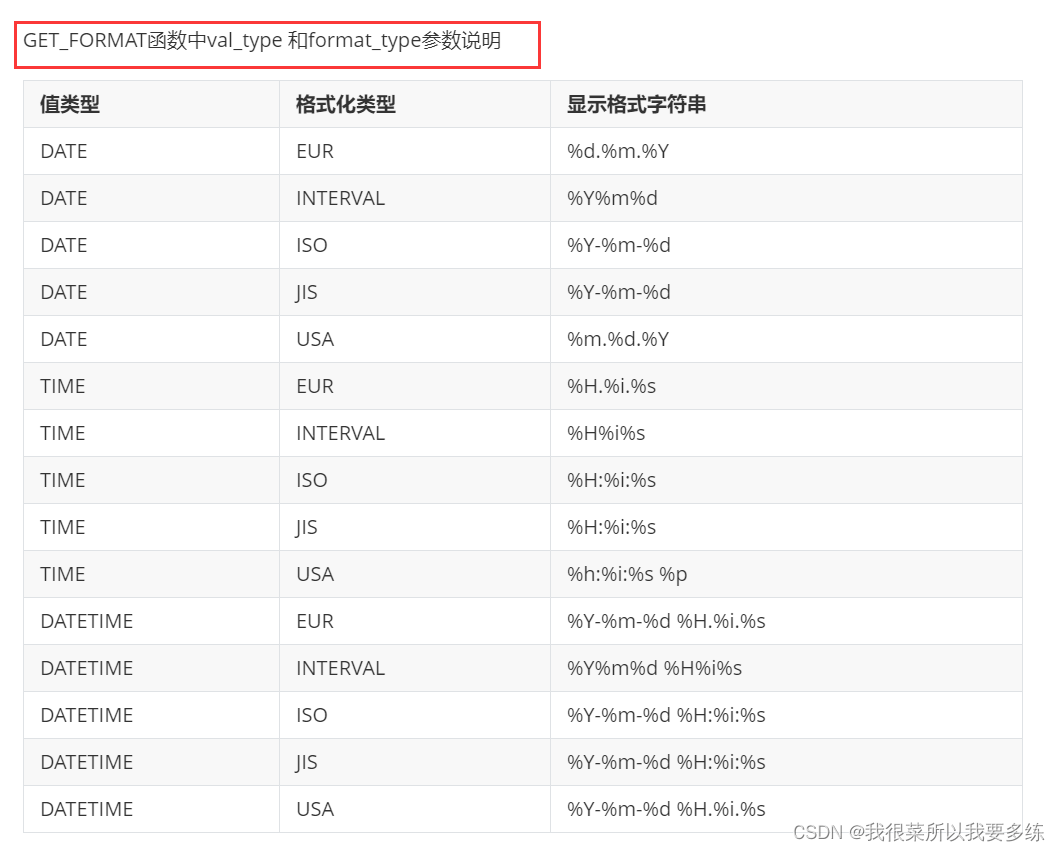
#日期时间函数
/*
获取系统日期时间值
获取某个日期或时间中的具体的年、月等值
获取星期、月份值,可以是当天的星期、当月的月份
获取一年中的第几个星期,一年的第几天
计算两个日期时间的间隔
获取一个日期或时间间隔一定时间后的另个日期或时间
和字符串之间的转换
*/
#(1)获取系统日期。CURDATE()和CURRENT_DATE()函数都可以获取当前系统日期。将日期值“+0”会怎么样?
SELECT CURDATE(),CURRENT_DATE();#(2)获取系统时间。CURTIME()和CURRENT_TIME()函数都可以获取当前系统时间。将时间值“+0”会怎么样?
SELECT CURTIME(),CURRENT_TIME();#(3)获取系统日期时间值。CURRENT_TIMESTAMP()、LOCALTIME()、SYSDATE()和NOW()
SELECT CURRENT_TIMESTAMP(),LOCALTIME(),SYSDATE(),NOW();#(4)获取当前UTC(世界标准时间)日期或时间值。
#本地时间是根据地球上不同时区所处的位置调整 UTC 得来的,
#例如,北京时间比UTC时间晚8个小时。
#UTC_DATE(),CURDATE(),UTC_TIME(), CURTIME()
SELECT UTC_DATE(),CURDATE(),UTC_TIME(), CURTIME();#(5)获取UNIX时间戳。
SELECT UNIX_TIMESTAMP(),UNIX_TIMESTAMP('2022-1-1');#(6)获取具体的时间值,比如年、月、日、时、分、秒。
#分别是YEAR(date)、MONTH(date)、DAY(date)、HOUR(time)、MINUTE(time)、SECOND(time)。
SELECT YEAR(CURDATE()),MONTH(CURDATE()),DAY(CURDATE());
SELECT HOUR(CURTIME()),MINUTE(CURTIME()),SECOND(CURTIME());#(7)获取日期时间的指定值。EXTRACT(type FROM date/time)函数
SELECT EXTRACT(YEAR_MONTH FROM CURDATE());#(8)获取两个日期或时间之间的间隔。
#DATEDIFF(date1,date2)函数表示返回两个日期之间间隔的天数。
#TIMEDIFF(time1,time2)函数表示返回两个时间之间间隔的时分秒。#查询今天距离员工入职的日期间隔天数
SELECT ename,DATEDIFF(CURDATE(),hiredate) FROM t_employee;#查询现在距离中午放学还有多少时间
SELECT TIMEDIFF(CURTIME(),'12:0:0');#(9)在“t_employee”表中查询本月生日的员工姓名、生日。
SELECT ename,birthday
FROM t_employee
WHERE MONTH(CURDATE()) = MONTH(birthday);#(10)#查询入职时间超过5年的
SELECT ename,hiredate,DATEDIFF(CURDATE(),hiredate)
FROM t_employee
WHERE DATEDIFF(CURDATE(),hiredate) > 365*5;(4)加密函数(部分)
#加密函数
/*
当用户需要对数据进行加密时,
比如做登录功能时,给用户的密码加密等。
*/
#password函数在mysql8已经移除了
SELECT PASSWORD('123456');#使用md5加密
SELECT MD5('123456'),SHA('123456'),sha2('123456',0);SELECT CHAR_LENGTH(MD5('123456')),SHA('123456'),sha2('123456',0);CREATE TABLE t_user(
id INT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(20),
PASSWORD VARCHAR(100)
);INSERT INTO t_user VALUES(NULL,'chai',MD5('123456'));SELECT * FROM t_user
WHERE username='chai' AND PASSWORD =MD5('123456');SELECT * FROM t_user
WHERE username='chai' AND PASSWORD ='123456';
(5)系统信息函数

(6)条件判断函数

#条件判断函数
/*
这个函数不是筛选记录的函数,
而是根据条件不同显示不同的结果的函数。
*/
#如果薪资大于20000,显示高薪,否则显示正常
SELECT ename,salary,IF(salary>20000,'高薪','正常')
FROM t_employee;#计算实发工资
#实发工资 = 薪资 + 薪资 * 奖金比例
SELECT ename,salary,commission_pct,
salary + salary * commission_pct
FROM t_employee;
#如果commission_pct是,计算完结果是NULLSELECT ename,salary,commission_pct,
salary + salary * IFNULL(commission_pct,0) AS 实发工资
FROM t_employee;SELECT ename,salary,commission_pct,
ROUND(salary + salary * IFNULL(commission_pct,0),2) AS 实发工资
FROM t_employee;#查询员工编号,姓名,薪资,等级,等级根据薪资判断,
#如果薪资大于20000,显示“羡慕级别”,
#如果薪资15000-20000,显示“努力级别”,
#如果薪资10000-15000,显示“平均级别”
#如果薪资10000以下,显示“保底级别”
/*mysql中没有if...elseif函数,有case 函数。
等价于if...elseif
*/
SELECT eid,ename,salary,
CASE WHEN salary>20000 THEN '羡慕级别'WHEN salary>15000 THEN '努力级别'WHEN salary>10000 THEN '平均级别'ELSE '保底级别'
END AS "等级"
FROM t_employee; #在“t_employee”表中查询入职7年以上的
#员工姓名、工作地点、轮岗的工作地点数量情况。
/*
计算工作地点的数量,转换为求 work_place中逗号的数量+1。work_place中逗号的数量 = work_place的总字符数 - work_place去掉,的字符数work_place去掉, ,使用replace函数
*/
SELECT work_place,
CHAR_LENGTH(work_place)-CHAR_LENGTH(REPLACE(work_place,',',''))
FROM t_employee;#类似于Java中switch...case
SELECT ename,work_place,
CASE (CHAR_LENGTH(work_place)-CHAR_LENGTH(REPLACE(work_place,',',''))+1)
WHEN 1 THEN '只在一个地方工作'
WHEN 2 THEN '在两个地方来回奔波'
WHEN 3 THEN '在三个地方流动'
ELSE '频繁出差'
END AS "工作地点数量情况"
FROM t_employee
WHERE DATEDIFF(CURDATE(),hiredate) > 365*7;(7)其他函数
从5.7.8版本之后开始支持JSON数据类型,并提供了操作JSON类型的数据的相关函数。
MySQL提供了非常丰富的空间函数以支持各种空间数据的查询和处理。
这两类函数基础阶段不讲,如果项目中有用到查询API使用。
3)窗口函数
窗口函数也叫OLAP函数(Online Anallytical Processing,联机分析处理),可以对数据进行实时分析处理。窗口函数是每条记录都会分析,有几条记录执行完还是几条,因此也属于单行函数。
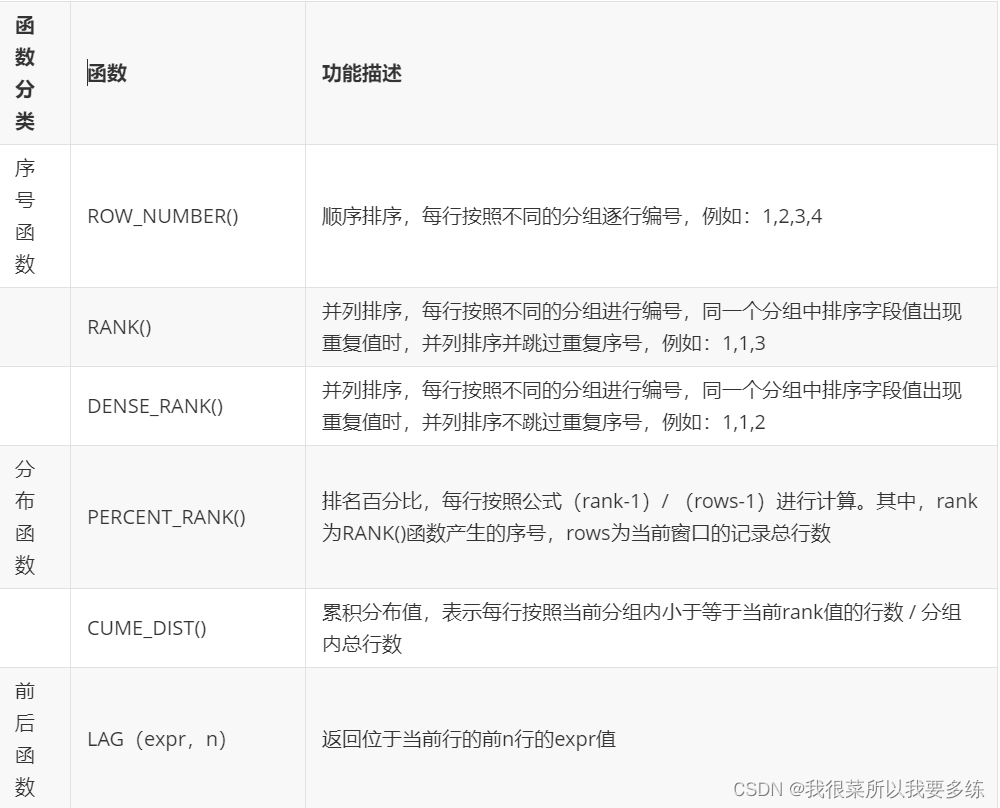

语法格式
函数名([参数列表]) OVER ()
函数名([参数列表]) OVER (子句)
over关键字用来指定窗口函数的窗口范围。如果OVER后面是空(),则表示SELECT语句筛选的所有行是一个窗口。OVER后面的()中支持以下4种语法来设置窗口范围。
- WINDOW:给窗口指定一个别名;
- PARTITION BY子句:一个窗口范围还可以分为多个区域。按照哪些字段进行分区/分组,窗口函数在不同的分组上分别处理分析;
- ORDER BY子句:按照哪些字段进行排序,窗口函数将按照排序后结果进行分析处理;
- FRAME子句:FRAME是当前分区的一个子集,FRAME子句用来定义子集的规则。
#(1)在“t_employee”表中查询薪资在[8000,10000]之间的员工姓名和薪资并给每一行记录编序号
SELECT ROW_NUMBER() OVER () AS "row_num",ename,salary
FROM t_employee WHERE salary BETWEEN 8000 AND 10000;#(2)计算每一个部门的平均薪资与全公司的平均薪资的差值。
SELECT did,AVG(salary) OVER() AS avg_all,
AVG(salary) OVER(PARTITION BY did) AS avg_did,
ROUND(AVG(salary) OVER()-AVG(salary) OVER(PARTITION BY did),2) AS deviation
FROM t_employee;#(3)在“t_employee”表中查询女员工姓名,部门编号,薪资,查询结果按照部门编号分组后在按薪资升序排列,并分别使用ROW_NUMBER()、RANK()、DENSE_RANK()三个序号函数给每一行记录编序号。
SELECT ename,did,salary,gender,
ROW_NUMBER() OVER (PARTITION BY did ORDER BY salary) AS "row_num",
RANK() OVER (PARTITION BY did ORDER BY salary) AS "rank_num" ,
DENSE_RANK() OVER (PARTITION BY did ORDER BY salary) AS "ds_rank_num"
FROM t_employee WHERE gender='女';#或SELECT ename,did,salary,
ROW_NUMBER() OVER w AS "row_num",
RANK() OVER w AS "rank_num" ,
DENSE_RANK() OVER w AS "ds_rank_num"
FROM t_employee WHERE gender='女'
WINDOW w AS (PARTITION BY did ORDER BY salary);#(4)在“t_employee”表中查询每个部门最低3个薪资值的女员工姓名,部门编号,薪资值。
SELECT ROW_NUMBER() OVER () AS "rn",temp.*
FROM(SELECT ename,did,salary,
ROW_NUMBER() OVER w AS "row_num",
RANK() OVER w AS "rank_num" ,
DENSE_RANK() OVER w AS "ds_rank_num"
FROM t_employee WHERE gender='女'
WINDOW w AS (PARTITION BY did ORDER BY salary))temp
WHERE temp.rank_num<=3;#或
SELECT ROW_NUMBER() OVER () AS "rn",temp.*
FROM(SELECT ename,did,salary,
ROW_NUMBER() OVER w AS "row_num",
RANK() OVER w AS "rank_num" ,
DENSE_RANK() OVER w AS "ds_rank_num"
FROM t_employee WHERE gender='女'
WINDOW w AS (PARTITION BY did ORDER BY salary))temp
WHERE temp.ds_rank_num<=3;#(5)在“t_employee”表中查询每个部门薪资排名前3的员工姓名,部门编号,薪资值。
SELECT temp.*
FROM(SELECT ename,did,salary,
DENSE_RANK() OVER w AS "ds_rank_num"
FROM t_employee
WINDOW w AS (PARTITION BY did ORDER BY salary DESC))temp
WHERE temp.ds_rank_num<=3;#(6)在“t_employee”表中查询全公司薪资排名前3的员工姓名,部门编号,薪资值。
SELECT temp.*
FROM(SELECT ename,did,salary,
DENSE_RANK() OVER w AS "ds_rank_num"
FROM t_employee
WINDOW w AS (ORDER BY salary DESC))temp
WHERE temp.ds_rank_num<=3;
六、分组查询与聚合函数
1)分组查询
分组查询主要涉及到两个子句,分别是:group by和having
语法:select * from 数据表名 group by 分组列名;
where 和 having 的区别?
1. 限定时机不同:
where:在分组之前进行限定,如果不满足条件,则不参与分组.
having:在分组之后进行限定,如果不满足结果,则不会被查询出来
2. 聚合函数不同:
where后不可以跟聚合函数
having可以进行聚合函数的判断。
【案例演示】
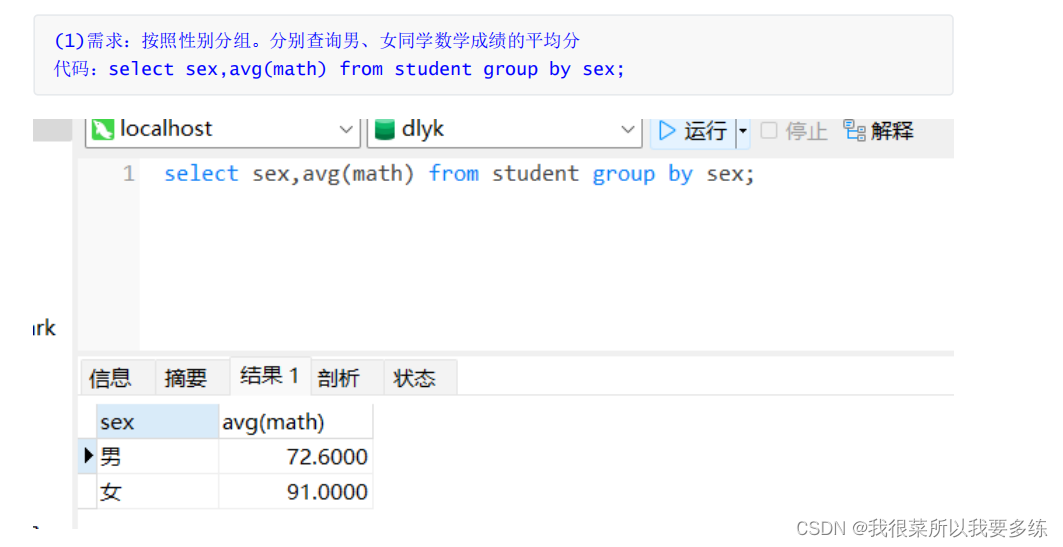
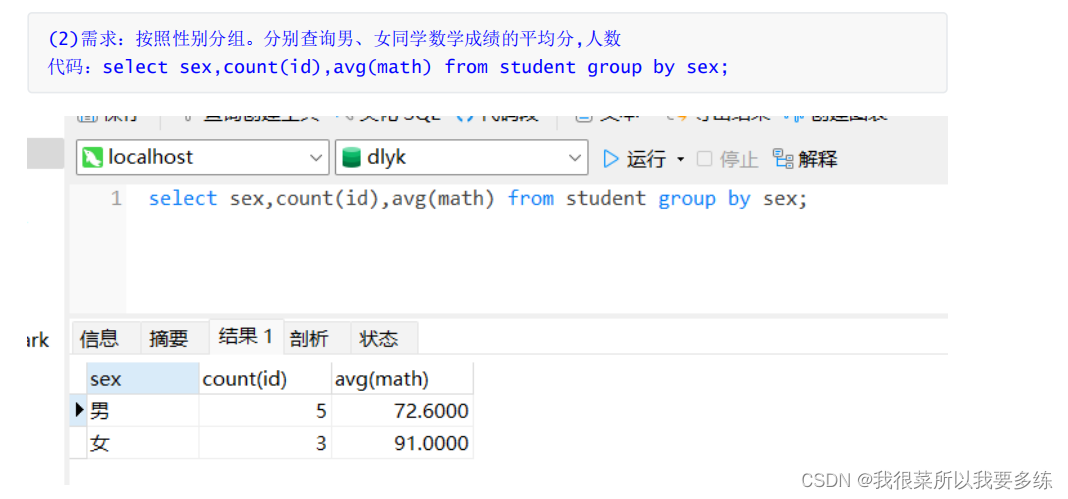


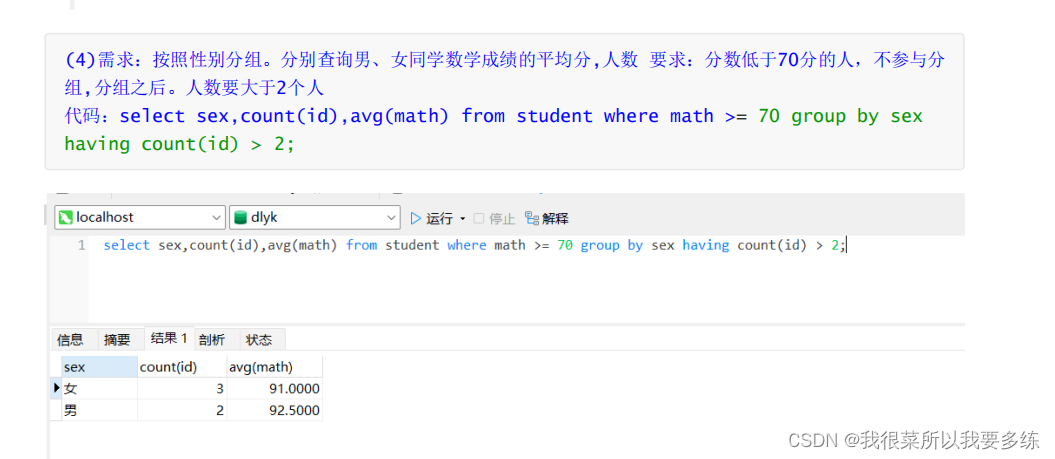
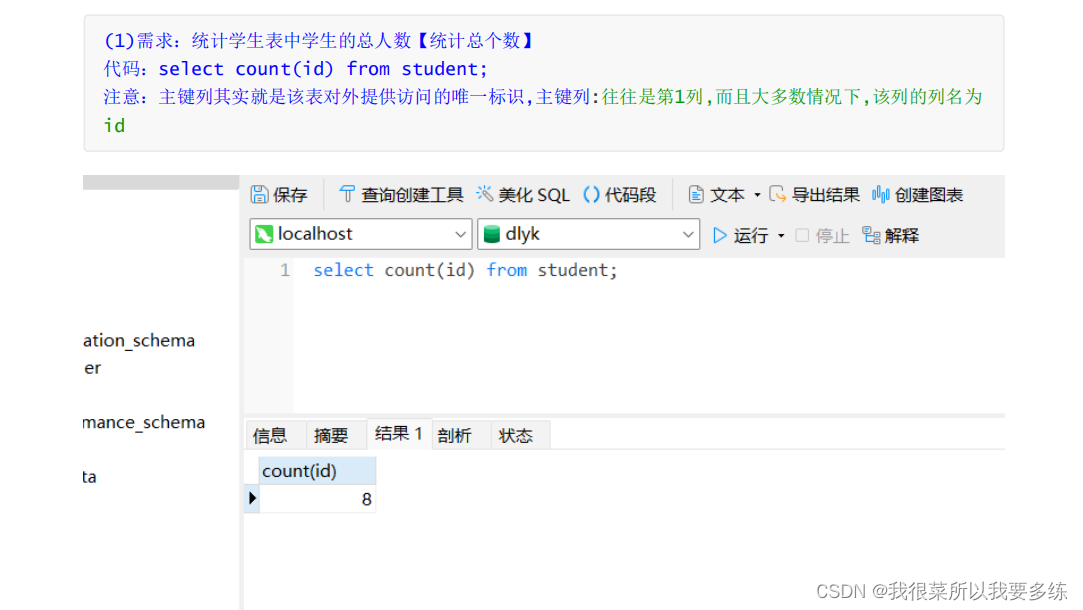
2)聚合函数
含义:SQL中提供的方法
语法:select 聚合函数名(列名) from 数据表名;





七、分页查询
1.语法:
select * from 表名 limit m,n
2.字母代表啥:
m:每页的起始位置
n:每页显示条数
3.小技巧:
我们将整个表的每一条数据进行编号,从0开始
4.每页的起始位置快速算法:
(当前页-1)*每页显示条数
5.其他分页参数:
a.每页的起始位置:
(当前页-1)*每页显示条数
b.int curPage = 2; -- 当前页数
c.int pageSize = 5; -- 每页显示数量
d.int startRow = (curPage - 1) * pageSize; -- 当前页, 记录开始的位置(行数)计算
e.int totalSize = select count(*) from products; -- 记录总数量
f.int totalPage = Math.ceil(totalSize * 1.0 / pageSize); -- 总页数
总页数 = (总记录数/每页显示条数)向上取整
-- 第一页
SELECT * FROM product LIMIT 0,5;-- 第二页
SELECT * FROM product LIMIT 5,5;-- 第三页
SELECT * FROM product LIMIT 10,5;-- 第四页
SELECT * FROM product LIMIT 15,5;
大总结
概括
一个完整的select语句格式应该如下:
(1)from:从哪些表中筛选
(2)on:关联多表查询时,去除笛卡尔积
(3)where:从表中筛选的条件
(4)group by:分组依据
(5)having:在统计结果中再次筛选(with rollup)
(6)order by:排序
(7)limit:分页
必须按照(1)-(7)的顺序编写子句。
..
以上语句的执行顺序
- 首先执行where语句过滤原始数据
- 执行group by进行分组
- 执行having对分组数据进行操作
- 执行select选出数据
- 执行order by排序
原则:能在where中过滤的数据,尽量在where中过滤,效率较高。having的过滤是专门对分组之后的数据进行过滤的。
具体演示
1)from子句
#1、from子句
SELECT *
FROM t_employee; #表示从某个表中筛选数据2)on子句
#2、on子句
/*
(1)on必须配合join使用
(2)on后面只写关联条件
所谓关联条件是两个表的关联字段的关系
(3)有n张表关联,就有n-1个关联条件
两张表关联,就有1个关联条件
三张表关联,就有2个关联条件
*/
SELECT *
FROM t_employee INNER JOIN t_department
ON t_employee.did = t_department.did; #1个关联条件#查询员工的编号,姓名,职位编号,职位名称,部门编号,部门名称
#需要t_employee员工表,t_department部门表,t_job职位表
SELECT eid,ename,t_job.job_id,t_job.job_name, `t_department`.`did`,`t_department`.`dname`
FROM t_employee INNER JOIN t_department INNER JOIN t_job
ON t_employee.did = t_department.did AND t_employee.job_id = t_job.job_id;
3)where
#3、where子句,在查询结果中筛选
#查询女员工的信息,以及女员工的部门信息
SELECT *
FROM t_employee INNER JOIN t_department
ON t_employee.did = t_department.did
WHERE gender = '女';4)group by子句
#4、group by分组
#查询所有员工的平均薪资
SELECT AVG(salary) FROM t_employee;#查询每一个部门的平均薪资
SELECT did,ROUND(AVG(salary),2 )
FROM t_employee
GROUP BY did;#查询每一个部门的平均薪资,显示部门编号,部门的名称,该部门的平均薪资
SELECT t_department.did,dname,ROUND(AVG(salary),2 )
FROM t_department LEFT JOIN t_employee
ON t_department.did = t_employee.did
GROUP BY t_department.did;#查询每一个部门的平均薪资,显示部门编号,部门的名称,该部门的平均薪资
#要求,如果没有员工的部门,平均薪资不显示null,显示0
SELECT t_department.did,dname,IFNULL(ROUND(AVG(salary),2),0)
FROM t_department LEFT JOIN t_employee
ON t_department.did = t_employee.did
GROUP BY t_department.did;#查询每一个部门的女员工的平均薪资,显示部门编号,部门的名称,该部门的平均薪资
#要求,如果没有员工的部门,平均薪资不显示null,显示0
SELECT t_department.did,dname,IFNULL(ROUND(AVG(salary),2),0)
FROM t_department LEFT JOIN t_employee
ON t_department.did = t_employee.did
WHERE gender = '女'
GROUP BY t_department.did;问题1:合计,WITH ROLLUP,加在group by后面
#问题1:合计,WITH ROLLUP,加在group by后面
#按照部门统计人数
SELECT did, COUNT(*) FROM t_employee GROUP BY did;
#按照部门统计人数,并合计总数
SELECT did, COUNT(*) FROM t_employee GROUP BY did WITH ROLLUP;
SELECT IFNULL(did,'合计'), COUNT(*) FROM t_employee GROUP BY did WITH ROLLUP;
SELECT IFNULL(did,'合计') AS "部门编号" , COUNT(*) AS "人数" FROM t_employee GROUP BY did WITH ROLLUP;
问题2:是否可以按照多个字段分组统计
#问题2:是否可以按照多个字段分组统计
#按照不同的部门,不同的职位,分别统计男和女的员工人数
SELECT did, job_id, gender, COUNT(*)
FROM t_employee
GROUP BY did, job_id, gender;问题3:分组统计时,select后面字段列表的问题
#问题4:分组统计时,select后面字段列表的问题
SELECT eid,ename, did, COUNT(*) FROM t_employee;
#eid,ename, did此时和count(*),不应该出现在select后面SELECT eid,ename, did, COUNT(*) FROM t_employee GROUP BY did;
#eid,ename此时和count(*),不应该出现在select后面SELECT did, COUNT(*) FROM t_employee GROUP BY did;
#分组统计时,select后面只写和分组统计有关的字段,其他无关字段不要出现,否则会引起歧义5)having子句
#5、having
/*
having子句也写条件
where的条件是针对原表中的记录的筛选。where后面不能出现分组函数。
having子句是对统计结果(分组函数计算后)的筛选。having可以加分组函数。
*/
#查询每一个部门的女员工的平均薪资,显示部门编号,部门的名称,该部门的平均薪资
#要求,如果没有员工的部门,平均薪资不显示null,显示0
#最后只显示平均薪资高于12000的部门信息
SELECT t_department.did,dname,IFNULL(ROUND(AVG(salary),2),0)
FROM t_department LEFT JOIN t_employee
ON t_department.did = t_employee.did
WHERE gender = '女'
GROUP BY t_department.did
HAVING IFNULL(ROUND(AVG(salary),2),0) >12000;#查询每一个部门的男和女员工的人数
SELECT did,gender,COUNT(*)
FROM t_employee
GROUP BY did,gender;#查询每一个部门的男和女员工的人数,显示部门编号,部门的名称,性别,人数
SELECT t_department.did,dname,gender,COUNT(eid)
FROM t_employee RIGHT JOIN t_department
ON t_employee.did = t_department.did
GROUP BY t_department.did,gender;#查询每一个部门薪资超过10000的男和女员工的人数,显示部门编号,部门的名称,性别,人数
#只显示人数低于3人
SELECT t_department.did,dname,gender,COUNT(eid)
FROM t_employee RIGHT JOIN t_department
ON t_employee.did = t_department.did
WHERE salary > 10000
GROUP BY t_department.did,gender
HAVING COUNT(eid) < 3;6)order by子句
#6、排序 order by
/*
升序和降序,默认是升序
asc代表升序
desc 代表降序
*/
#查询员工信息,按照薪资从高到低
SELECT * FROM t_employee
ORDER BY salary DESC;#查询每一个部门薪资超过10000的男和女员工的人数,显示部门编号,部门的名称,性别,人数
#只显示人数低于3人,按照人数升序排列
SELECT t_department.did,dname,gender,COUNT(eid)
FROM t_employee RIGHT JOIN t_department
ON t_employee.did = t_department.did
WHERE salary > 10000
GROUP BY t_department.did,gender
HAVING COUNT(eid) < 3
ORDER BY COUNT(eid);#查询员工的薪资,按照薪资从低到高,薪资相同按照员工编号从高到低
SELECT *
FROM t_employee
ORDER BY salary ASC , eid DESC;7)limit子句
#演示limit子句
/*
limit子句是用于分页显示结果。
limit m,n
n:表示最多该页显示几行
m:表示从第几行开始取记录,第一个行的索引是0
m = (page-1)*n page表示第几页每页最多显示5条,n=5
第1页,page=1,m = (1-1)*5 = 0; limit 0,5
第2页,page=2,m = (2-1)*5 = 5; limit 5,5
第3页,page=3,m = (3-1)*5 = 10; limit 10,5
*/
#查询员工表的数据,分页显示,每页显示5条记录
#第1页
SELECT * FROM t_employee LIMIT 0,5;
#第2页
SELECT * FROM t_employee LIMIT 5,5;
#第3页
SELECT * FROM t_employee LIMIT 10,5;
#第4页
SELECT * FROM t_employee LIMIT 15,5;
#第5页
SELECT * FROM t_employee LIMIT 20,5;
#第6页
SELECT * FROM t_employee LIMIT 25,5;#查询所有的男员工信息,分页显示,每页显示3条,第2页
#limit m,n n=3,page=2,m=(page-1)*n=3
SELECT *
FROM t_employee
WHERE gender ='男'
LIMIT 3,3#查询每一个编号为偶数的部门,显示部门编号,名称,员工数量,
#只显示员工数量>=2的结果,按照员工数量升序排列,
#每页显示2条,显示第1页
SELECT t_department.did,dname,COUNT(eid)
FROM t_employee RIGHT JOIN t_department
ON t_employee.did = t_department.did
WHERE t_department.did%2=0
GROUP BY t_department.did
HAVING COUNT(eid)>=2
ORDER BY COUNT(eid)
LIMIT 0,2;