Spark SQL 中DataFrame DSL的使用
在上一篇文章中已经大致说明了DataFrame APi,下面我们具体介绍DataFrame DSL的使用。DataFrame DSL是一种命令式编写Spark SQL的方式,使用的是一种类sql的风格语法。
文章链接:
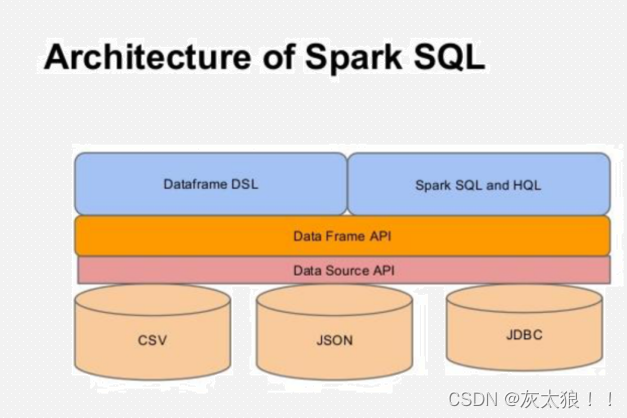
一、单词统计案例引入
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}object Demo2DSLWordCount {def main(args: Array[String]): Unit = {/*** 在新版本的spark中,如果想要编写spark sql的话,需要使用新的spark入口类:SparkSession*/val sparkSession: SparkSession = SparkSession.builder().master("local").appName("wc spark sql").getOrCreate()/*** spark sql和spark core的核心数据类型不太一样** 1、读取数据构建一个DataFrame,相当于一张表*/val linesDF: DataFrame = sparkSession.read.format("csv") //指定读取数据的格式.schema("line STRING") //指定列的名和列的类型,多个列之间使用,分割.option("sep", "\n") //指定分割符,csv格式读取默认是英文逗号.load("spark/data/words.txt") // 指定要读取数据的位置,可以使用相对路径/*** DSL: 类SQL语法 api 介于代码和纯sql之间的一种api** spark在DSL语法api中,将纯sql中的函数都使用了隐式转换变成一个scala中的函数* 如果想要在DSL语法中使用这些函数,需要导入隐式转换**///导入Spark sql中所有的sql隐式转换函数import org.apache.spark.sql.functions._//导入另一个隐式转换,后面可以直接使用$函数引用字段进行处理import sparkSession.implicits._// linesDF.select(explode(split($"line","\\|")) as "word")
// .groupBy($"word")
// .count().show()val resultDF: DataFrame = linesDF.select(explode(split($"line", "\\|")) as "word").groupBy($"word").agg(count($"word") as "counts")/*** 保存数据*/resultDF.repartition(1).write.format("csv").option("sep","\t").mode(SaveMode.Overwrite).save("spark/data/sqlout2")}}注意:show()可以指定两个参数,第一个参数为展现的条数,不指定默认展示前20条数据,第二个参数默认为false,代表的是如果数据过长展示就会不完全,可以指定为true,使得数据展示完整,比如 : show(200,truncate = false)
二、数据源获取
查看官方文档:Data Sources - Spark 3.5.1 Documentation,看到DataFrame支持多种数据源的获取。
1、csv-->json
val sparkSession: SparkSession = SparkSession.builder().master("local[2]").appName("多种类型数据源读取演示").config("spark.sql.shuffer.partitions", 1) //指定分区数为1,默认分区数是200个.getOrCreate()//导入spark sql中所有的隐式转换函数import org.apache.spark.sql.functions._//导入sparkSession下的所有隐式转换函数,后面可以直接使用$函数引用字段import sparkSession.implicits._/*** 读csv格式的文件-->写到json格式文件中*///1500100967,能映秋,21,女,文科五班val studentsDF: DataFrame = sparkSession.read.format("csv").schema("id String,name String,age Int,gender String,clazz String").option("sep", ",").load("spark/data/student.csv")studentsDF.write.format("json").mode(SaveMode.Overwrite).save("spark/data/students_out_json.json")2、json-->parquet
val sparkSession: SparkSession = SparkSession.builder().master("local").appName("").config("spark.sql.shuffer.partitions", 1) //指定分区数为1,默认分区数是200个.getOrCreate()//导入spark sql中所有的隐式转换函数//导入sparkSession下的所有隐式转换函数,后面可以直接使用$函数引用字段/*** 读取json数据格式,因为json数据有键值对,会自动的将健作为列名,值作为列值,不需要手动的设置表结构*///1500100967,能映秋,21,女,文科五班//方式1:// val studentsJsonDF: DataFrame = sparkSession.read// .format("json")// .load("spark/data/students_out_json.json/part-00000-3f086bb2-23d9-4904-9814-3a34b21020ab-c000.json")//方式2:实际上也是调用方式1,只是更简洁了// def json(paths: String*): DataFrame = format("json").load(paths : _*)val studebtsReadDF: DataFrame = sparkSession.read.json("spark/data/students_out_json.json/part-00000-3f086bb2-23d9-4904-9814-3a34b21020ab-c000.json")studebtsReadDF.write.format("parquet").mode(SaveMode.Overwrite).save("spark/data/students_parquet")3、parquet-->csv
val sparkSession: SparkSession = SparkSession.builder().master("local").appName("").config("spark.sql.shuffer.partitions", 1) //指定分区数为1,默认分区数是200个.getOrCreate()//导入Spark sql中所有的sql隐式转换函数import org.apache.spark.sql.functions._//导入另一个隐式转换,后面可以直接使用$函数引用字段进行处理import sparkSession.implicits._/*** parquet:压缩的比例由信息熵决定,通俗的说就是数据的重复程度决定*/val studebtsReadDF: DataFrame = sparkSession.read.format("parquet").load("spark/data/students_parquet/part-00000-8b815a03-97f7-4d71-8b71-4e7e30f60995-c000.snappy.parquet")studebtsReadDF.write.format("csv").mode(SaveMode.Overwrite).save("spark/data/students_csv")4、数据库
下面我们以mysql为例:
val sparkSession: SparkSession = SparkSession.builder().master("local").appName("连接数据库").config("spark.sql.shuffle.partitions",1) //默认分区的数量是200个.getOrCreate()/*** 读取数据库中的数据,mysql* 如果链接失败,可以将参数补全:jdbc:mysql://192.168.19.100:3306?useUnicode=true&allowPublicKeyRetrieval=true&characterEncoding=utf8&useSSL=false*/val jdDF: DataFrame = sparkSession.read.format("jdbc").option("url", "jdbc:mysql://192.168.19.100:3306?useSSL=false").option("dbtable", "bigdata29.emp").option("user", "root").option("password", "123456").load()jdDF.show(10,truncate = false)三、DataFrame DSL API的使用
1、select
import org.apache.spark.sql.{DataFrame, SparkSession}object Demo1Select {def main(args: Array[String]): Unit = {val sparkSession: SparkSession = SparkSession.builder().master("local").appName("select函数演示").getOrCreate()//导入Spark sql中所有的sql隐式转换函数import org.apache.spark.sql.functions._//导入另一个隐式转换,后面可以直接使用$函数引用字段进行处理import sparkSession.implicits._val studentsDF: DataFrame = sparkSession.read.format("csv").schema("id String,name String,age String,gender String,clazz String").option("sep", ",").load("spark/data/student.csv")/*** select函数*///方式1:只能查询原有字段,不能对字段做出处理,比如加减、起别名之类studentsDF.select("id", "name", "age")//方式2:弥补了方式1的不足studentsDF.selectExpr("id","name","age+1 as new_age")//方式3:使用隐式转换函数中的$将字段变为一个对象val stuDF: DataFrame = studentsDF.select($"id", $"name", $"age")//3.1使用对象对字段进行处理
// stuDF.select($"id", $"name", $"age",$"age".+(1) as "new_age").show() //不可使用未变为对象的字段stuDF.select($"id", $"name", $"age",$"age" + 1 as "new_age") // +是函数,可以等价于该语句//3.2可以在select中使用sql函数studentsDF.select($"id", $"name", $"age", substring($"id", 0, 2))}
}
2、where
/*** where函数:过滤数据*///方式1:直接将sql中的where语句以字符串形式传参studentsDF.where("clazz='文科一班' and gender='男'")//方式2:使用$列对象形式过滤/*** 注意在此种方式下:等于和不等于符号与我们平常使用的有所不同* 等于:===* 不等于:=!=*/studentsDF.where($"clazz" === "文科一班" and $"gender"=!="男").show()3、groupBy和agg
/*** groupby:分组函数 agg:聚合函数* 注意:* 1、groupby与agg函数通常都是一起使用* 2、分组聚合之后的结果DataFrame中只会包含分组字段与聚合字段* 3、分组聚合之后select中无法出现不是分组的字段*///需求:根据班级分组,求每个班级的人数和平均年龄studentsDF.groupBy($"clazz").agg(count($"clazz") as "clazz_number",avg($"age") as "avg_age").show()4、join
/*** 5、join:表关联*/val subjectDF1: DataFrame = sparkSession.read.format("csv").option("sep", ",").schema("id String,subject_id String,score Int").load("spark/data/score.csv")val subjectDF2: DataFrame = sparkSession.read.format("csv").option("sep", ",").schema("sid String,subject_id String,score Int").load("spark/data/score.csv")//关联场景1:所关联的字段名字一样studentsDF.join(subjectDF1,"id")//关联场景2:所关联的字段名字不一样studentsDF.join(subjectDF2,$"id"===$"sid","inner")
// studentsDF.join(subjectDF2,$"id"===$"sid","left").show()/*** 上面两种关联场景默认inner连接方式(内连接),可以指定参数选择连接方式,比如左连接、右连接、全连接之类* * @param joinType Type of join to perform. Default `inner`. Must be one of:* * `inner`, `cross`, `outer`, `full`, `fullouter`,`full_outer`, `left`,* * `leftouter`, `left_outer`, `right`, `rightouter`, `right_outer`.*/
5、开窗
/*** 开窗函数* 1、ROW_NUMBER():为分区中的每一行分配一个唯一的序号。序号是根据ORDER BY子句定义的顺序分配的* 2、RANK()和DENSE_RANK():为分区中的每一行分配一个排名。RANK()在遇到相同值时会产生间隙,而DENSE_RANK()则不会。**///需求:统计每个班级总分前三的学生val stu_scoreDF: DataFrame = studentsDF.join(subjectDF2, $"id" === $"sid")//方式1:在select中使用row_number() over Window.partitionBy().orderBy()stu_scoreDF.groupBy($"clazz", $"id").agg(sum($"score") as "sum_score").select($"clazz", $"id", $"sum_score", row_number() over Window.partitionBy($"clazz").orderBy($"sum_score".desc) as "score_rank").where($"score_rank" <= 3)//方式2:使用withcolumn()函数,会新增一列,但是要预先指定列名stu_scoreDF.repartition(1).groupBy($"clazz", $"id").agg(sum($"score") as "sum_score").withColumn("score_rank",row_number() over Window.partitionBy($"clazz").orderBy($"sum_score".desc)).where($"score_rank" <= 3).show()注意:
DSL API 不直接对应 SQL 的关键字执行顺序(如 SELECT、FROM、WHERE、GROUP BY 等),但可以按照构建逻辑查询的方式来组织代码,使其与 SQL 查询的逻辑结构相似。
在构建 Spark DataFrame 转换和操作时,常用流程介绍:
- 选择数据源:使用
spark.read或从其他 DataFrame 派生。 - 转换:使用各种转换函数(如
select、filter、map、flatMap、join等)来修改 DataFrame。 - 聚合:使用
groupBy和聚合函数(如sum、avg、count等)对数据进行分组和汇总。 - 排序:使用
orderBy或sort对数据进行排序。 - 输出:使用
show、collect、write等函数将结果输出到控制台、收集到驱动程序或写入外部存储。
四、RDD与DataFrame的转换
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SparkSession}object RddToDf {def main(args: Array[String]): Unit = {val sparkSession: SparkSession = SparkSession.builder().appName("Rdd与Df之间的转换").master("local").config("spark.sql.shuffle.partitions", 1).getOrCreate()import org.apache.spark.sql.functions._import sparkSession.implicits._val sparkContext: SparkContext = sparkSession.sparkContextval idNameRdd: RDD[(String, String)] = sparkContext.textFile("spark/data/student.csv").map(_.split(",")).map {case Array(id: String, name: String, _, _, _) => (id, name)}/*** Rdd-->DF* 因为在Rdd中不会存储文件的结构(schema)信息,所以要指定字段*/val idNameDF: DataFrame = idNameRdd.toDF("id", "name")idNameDF.createOrReplaceTempView("idNameTb")sparkSession.sql("select id,name from idNameTb").show()/*** DF-->Rdd*/val idNameRdd2: RDD[Row] = idNameDF.rddidNameRdd2.foreach(println)}
}