TransFormer学习之VIT算法解析
1.算法简介
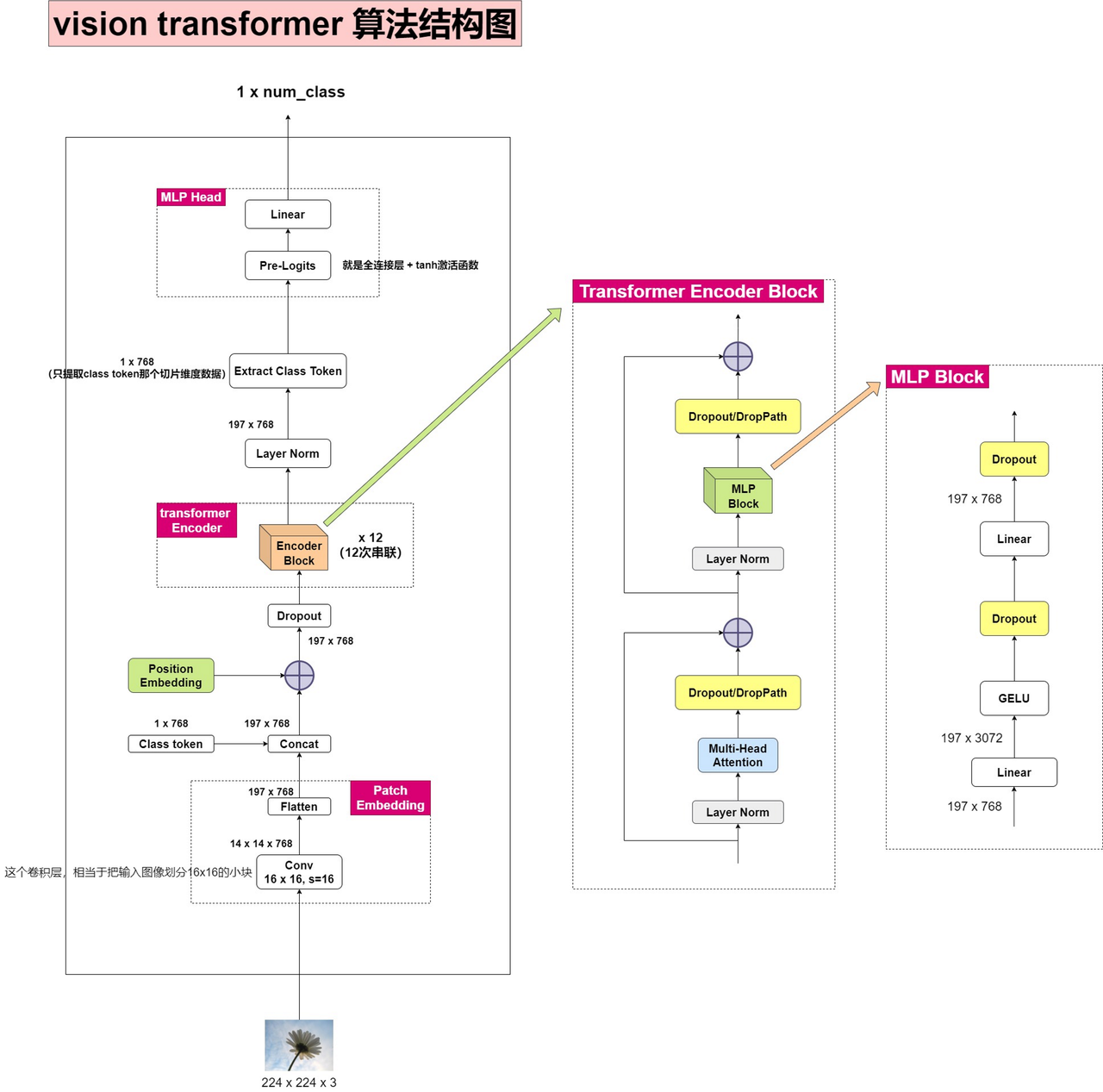
本文主要对VIT算法原理进行简单梳理,下图是一个大佬整理的网络整体的流程图,清晰明了,其实再了解自注意力机制和多头自注意力机制后,再看VIT就很简单了
受到NLP领域中Transformer成功应用的启发,ViT算法尝试将标准的Transformer结构直接应用于图像,并对整个图像分类流程进行最少的修改。具体来讲,ViT算法将整幅图像拆分成小图像块,将图像块转换为类似于NLP中的Sequence后再执行TransFormer操作。
参考链接:一文带你掌(放)握(弃)ViT(Vision Transformer)(原理解读+实践代码)
参考链接:Vision Transformer (ViT):图像分块、图像块嵌入、类别标记、QKV矩阵与自注意力机制的解析
参考链接:ViT(vision transformer)原理快速入门
参考链接:逐步解析Vision Transformer各细节
2.图像分块和Embedding
这一步是为了后面的TransFormer操作对数据进行预处理,将图像转换为Sequence的形式。
2.1原理简介
(1)如图所示,输入图像为224*224*3的图像,将其分割为大小等于16*16的图像块,图像块数量为224*224/16*16=196。

(2)图像分块后再将其展平为一个序列,序列的shape为:196*16*16*3

(3)为了实现最后的分类任务,需要添加一个Class Token的信息(图中橙色部分),则输入序列变为197*16*16*3

(4)生成特定通道的sequence
经过上述步骤处理后,每个图像块的维度是 16 ∗ 16 ∗ 3 16*16*3 16∗16∗3,而我们实际需要的向量维度是D,因此我们还需要对图像块进行 Embedding。这里 Embedding的方式非常简单,只需要对每个 16 ∗ 16 ∗ 3 16*16*3 16∗16∗3的图像块做一个线性变换,将维度压缩为 D 即可。
输入:196*(16*16*3)
输出:196*D,D表示最终需要的通道数
至此,通过patch embedding将一个视觉问题转化为了一个seq2seq问题。
2.2 代码实现
(1)图像分块:代码中采用大小 16 ∗ 16 16*16 16∗16、步长为16,数量为768的一组卷积核完成图像分块操作
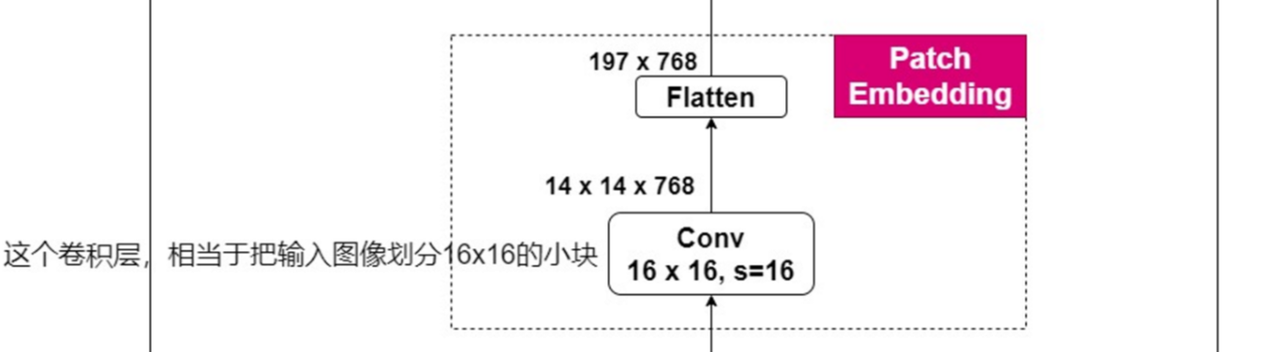
(2)Patch Embedding:14*14*768,表示图像分块后的patch长和宽为14*14,共768个通道,然后将其展平为196*768的特征序列,这里的196是指14*14个patch(图中的197为笔误),展平的过程即将2D展开为1维
(3)添加类别Token

3.TransFormer Encoder
在对图像进行图像分块和patch embedding等预处理操作后得到一个197*768的特征序列,后面就是进入TransFormer Encoder操作。
网络中的TransFormer Encoder模块会执行12次Encoder Block串联操作,每个Enconder Block都包括一个多头注意力机制模块和一次MLP操作。
在每个 Transformer Block 的多头自注意力层和前馈神经网络中都会包含残差连接和层归一化操作,这有助于缓解梯度消失问题和加速训练过程。
在 ViT 模型中,多个 Transformer Block 会串联在一起,构成整个 Transformer Encoder。输入特征会经过多个 Transformer Block 的处理,每个块产生一系列更具语义信息的特征表示。通过反复堆叠和叠加多个 Transformer Block,ViT 模型能够有效地学习输入图像的复杂特征和结构信息。
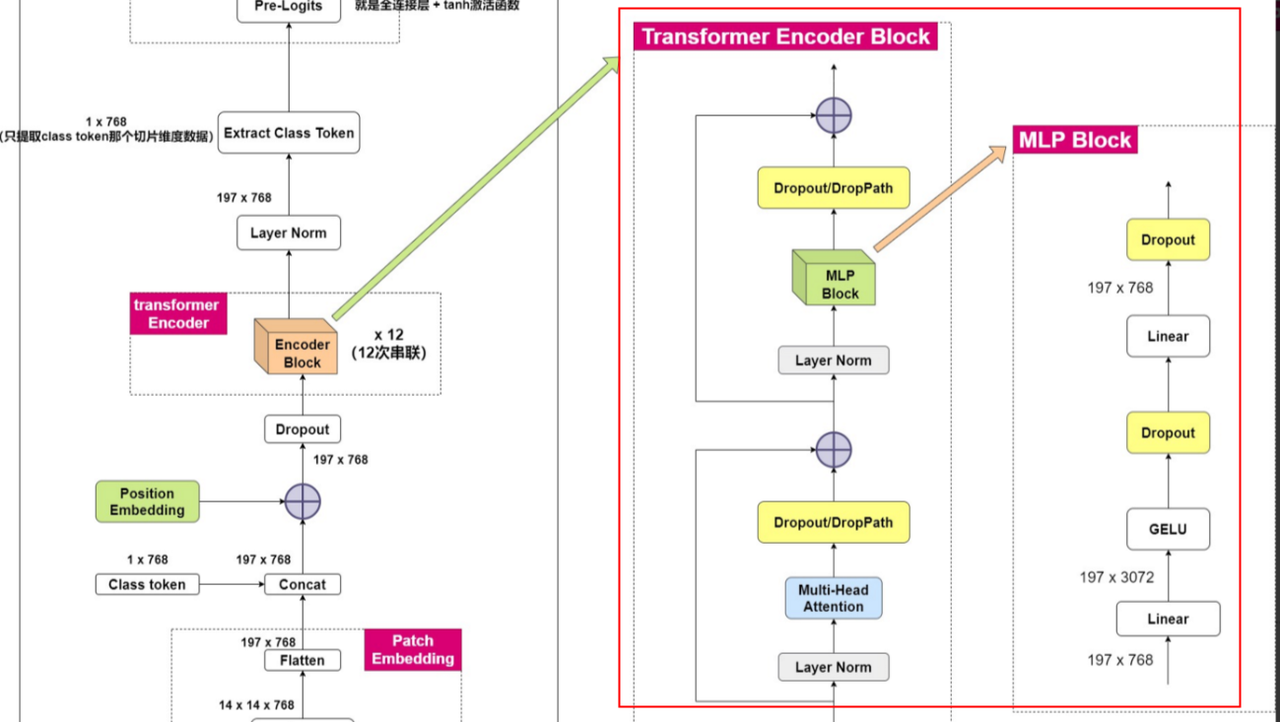
3.1 Multi-Head Attention
详细见博客:《TransFormer学习之基础知识:STN、SENet、CBAM、Self-Attention》
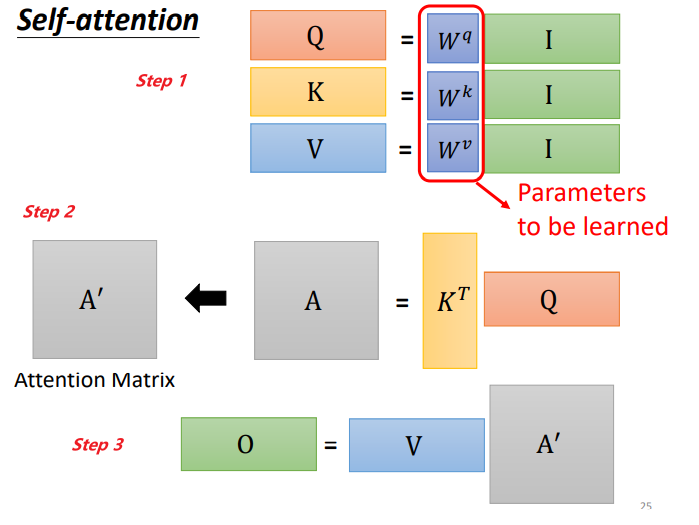
首先通过之前了解到的内容回顾一下self-attention的内容:
- 输入序列I乘以权重矩阵后分别得到对应的QKV
- 通过将序列各自的query和key值相乘并进行归一化,可以得到向量之间的相关性 A ′ A^{'} A′
- 将权重矩阵 A ′ A^{'} A′和value相乘可以得到输出向量O
因为相关性有很多种不同的形式,有很多种不同的定义,所以有时不能只有一个q,要有多个q,不同的q负责不同种类的相关性。
3.1.1 计算单个输入a:
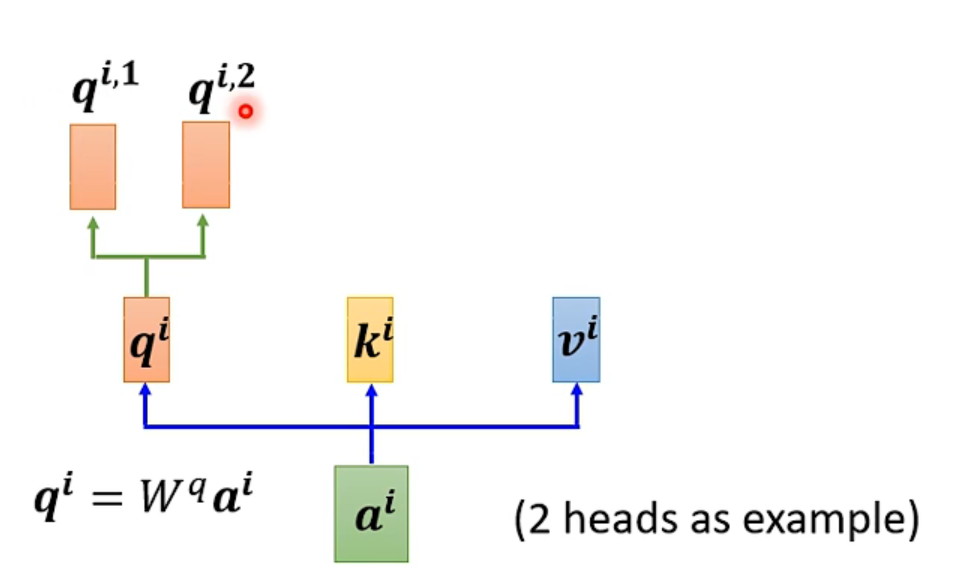
首先,和上面一样,用a乘权重矩阵 W q W_q Wq得到q,然后q再乘两个不同的 W q , i W^{q,i} Wq,i,得到两个不同的 q i , j q^{i,j} qi,j,i代表的是位置,1和2代表的是这个位置的第几个q。

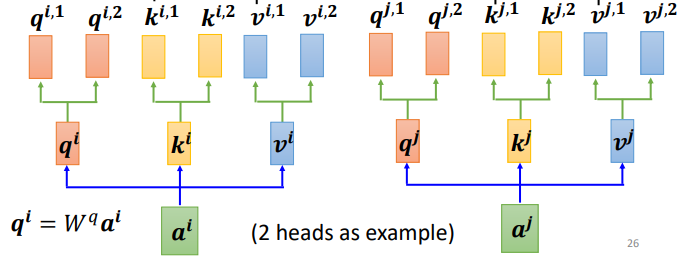
3.1.2 计算多个head
这上面这个图中,有两个head,代表这个问题有两种不同的相关性。
同样,k和v也需要有多个,两个k、v的计算方式和q相同,都是先算出来ki和vi,然后再乘两个不同的权重矩阵。

对于多个输入向量也一样,每个向量都有多个head:
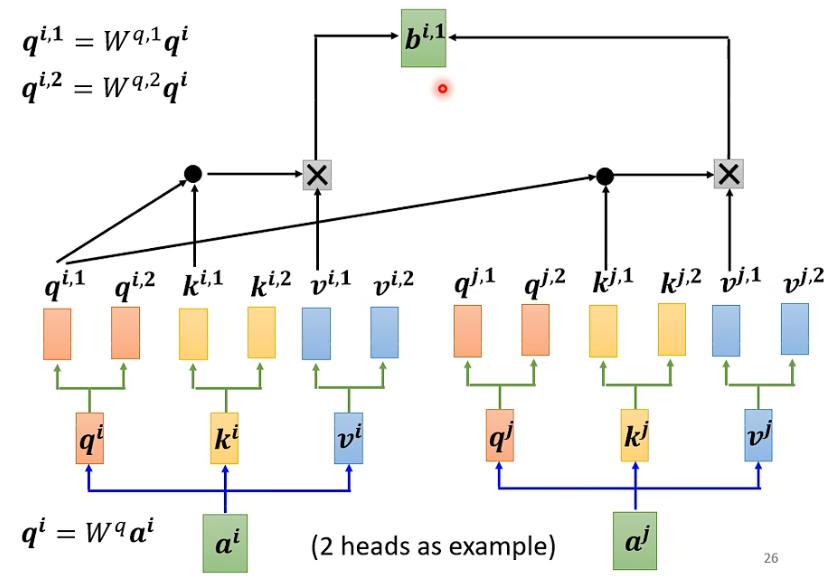
3.1.3 计算self-attention
和上面讲的过程一样,只不过是1那类的一起做,2那类的一起做,两个独立的过程,算出来两个b。
对于1:
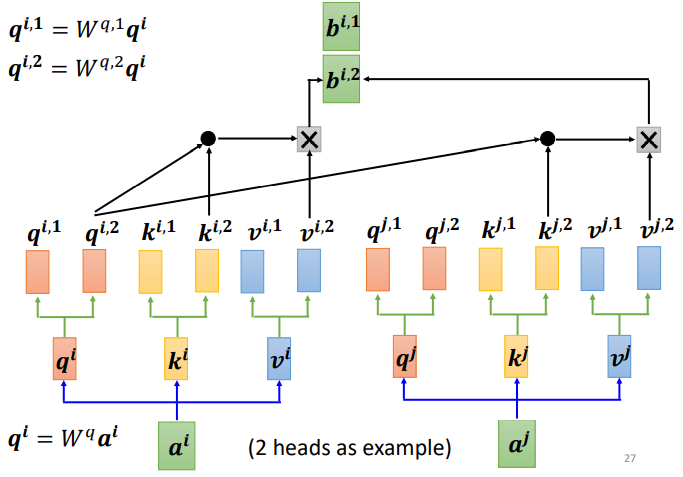
对于2:

3.2 MLP Block
MLP Head 是指位于模型顶部的全连接前馈神经网络模块,用于将提取的图像特征表示转换为最终的分类结果或其他预测任务输出。MLP Head 通常跟在 Transformer Encoder 的输出之后,作为整个模型的最后一层。

具体来说,当我们只需要分类信息时,只需要提取出class token生成的对应结果就行,即[197, 768]中抽取出class token对应的[1, 768]。接着我们通过MLP Head得到我们最终的分类结果。
MLP Head原论文中说在训练ImageNet21K时是由Linear+tanh激活函数+Linear组成。但是迁移到ImageNet1K上或者你自己的数据上时,只用一个Linear即可。
4.其他细节
4.1归纳偏置与混合架构
(1)归纳偏置: Vision Transformer 的图像特定归纳偏置比 CNN 少得多。在 CNN 中,局部性、二维邻域结构和平移等效性存在于整个模型的每一层中。而在ViT中,只有MLP层是局部和平移等变的,因为自注意力层都是全局的。
(2)混合架构: Hybrid 模型是一种结合传统卷积神经网络(CNN)和Transformer的方法,旨在兼顾两种模型的优势,从而更好地处理图像数据。论文通过对比发现,在训练epoch较少时Hybrid优于ViT,但当epoch增大后ViT优于Hybrid
4.2Vision Transformer维度变换
![[图片]](https://img-blog.csdnimg.cn/direct/61efc596f6f34cc3a097ac4837ec4e7c.png)
- 输入图像的
input shape=[1,3,224,224],1是batch_size,3是通道数,224是高和宽 - 输入图像经过patch Embedding,其中Patch大小是
14,卷积核是768,则经过分块后,获得的块数量是 224 × 224 / 14 × 14 = 196 224 \times224/14 \times 14 = 196 224×224/14×14=196,每个块的维度被转换为768,即得到的patch embedding的shape=[1,196,768] - 将可学习的**[class] token embedding拼接到patch embedding**前,得到shape=
[1,197,768] - 将position embedding加入到拼接后的embedding中,组成最终的输入嵌入,最终的输入
shape=[1,197,768] - 输入嵌入送入到Transformer encoder中,shape并不发生变化
- 最后transformer的输出被送入到MLP或FC中执行分类预测,选取**[class] token**作为分类器的输入,以表示整个图像的全局信息,假设分类的类目为K,最终的
shape=[1,768]*[768,K]=[1,K]