摸鱼大数据——Hive表操作——分区表
1、介绍
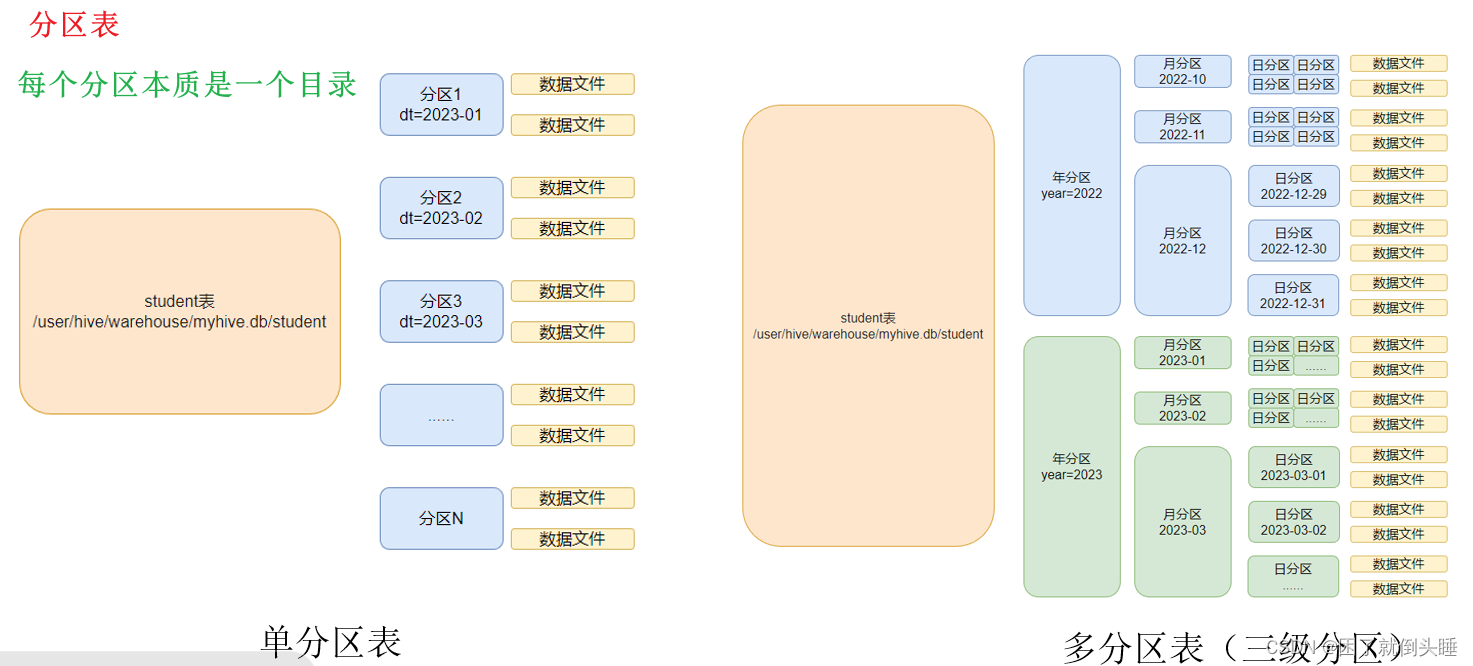
特点: 分区表会在HDFS上产生目录。查询数据的时候使用分区字段筛选数据,可以避免全表扫描,从而提升查询效率
注意: 如果是分区表,在查询数据的时候,如果没有使用分区字段,它回去进行全表扫描,会降低效率
只需要记住一点,分区表是用来提升Hive的数据分析效率
2、一级分区
创建分区表: create [external] table [if not exists] 表名称(字段名称1 字段数据类型,字段名称2 字段数据类型..) partitioned by (分区字段 字段数据类型); 自动生成分区目录并插入数据: load data [local] inpath '文件路径' into table 表名称 partition (分区字段=值); 注意: 如果使用load导入数据,没有写local,文件路径就是HDFS上的路径。否则就是linux的路径
示例:
use day06; -- 1- 创建分区表 create table one_part_tb(id int,name string,price double,num int ) partitioned by (year int) row format delimited fields terminated by ' '; -- 2- 通过load将HDFS中的文件导入到Hive表中 load data inpath '/source/order202251.txt' into table one_part_tb partition (year=2022); load data inpath '/source/order202351.txt' into table one_part_tb partition (year=2023); load data inpath '/source/order202352.txt' into table one_part_tb partition (year=2023); load data inpath '/source/order2023415.txt' into table one_part_tb partition (year=2023); -- 3- 数据验证 select * from one_part_tb; -- 4- 使用分区 select * from one_part_tb where year=2022; -- 5- 如果没有指定分区,那么会进行全表扫描,拖慢了效率 select * from one_part_tb where price>=20;
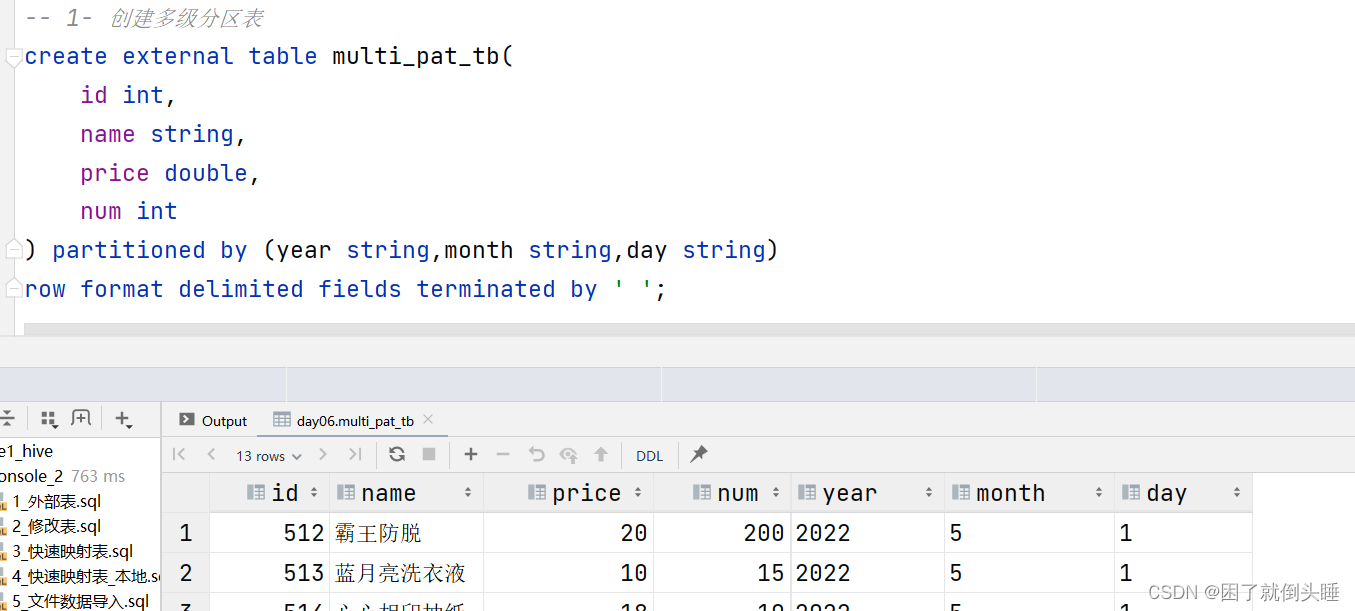
3、多级分区
创建分区表: create [external] table [if not exists] 表名称(字段名称1 字段数据类型,字段名称2 字段数据类型..) partitioned by (分区字段1 字段数据类型,分区字段2 字段数据类型...); 自动生成分区目录并插入数据: load data [local] inpath '文件路径' into table 表名称 partition (分区字段1=值,分区字段2=值....); 注意: 如果使用load导入数据,没有写local,文件路径就是HDFS上的路径。否则就是linux的路径
示例:
use day06; -- 1- 创建多级分区表 create external table multi_pat_tb(id int,name string,price double,num int ) partitioned by (year string,month string,day string) row format delimited fields terminated by ' '; -- 2- 加载HDFS数据到Hive表中 load data inpath '/source/order202251.txt' into table multi_pat_tb partition (year="2022",month="5",day="1"); load data inpath '/source/order202351.txt' into table multi_pat_tb partition (year="2023",month="5",day="1"); load data inpath '/source/order202352.txt' into table multi_pat_tb partition (year="2023",month="5",day="2"); load data inpath '/source/order2023415.txt' into table multi_pat_tb partition (year="2023",month="4",day="15"); -- 3- 数据验证 select * from multi_pat_tb; -- 4- 使用分区 -- 注意: 如果是多分区,使用分区来提升效率的时候,需要根据需求来决定到底使用几个分区。并不需要所有的分区都用到 -- 需求:要对2023全年的销售情况进行分析 select * from multi_pat_tb where year="2023"; -- 需求:要对2023年5月整个月的销售情况进行分析 select * from multi_pat_tb where year="2023" and month="5"; select * from multi_pat_tb where year="2023" and month="5" and day="2"; -- 5- 不使用分区 select * from multi_pat_tb where price>=20;
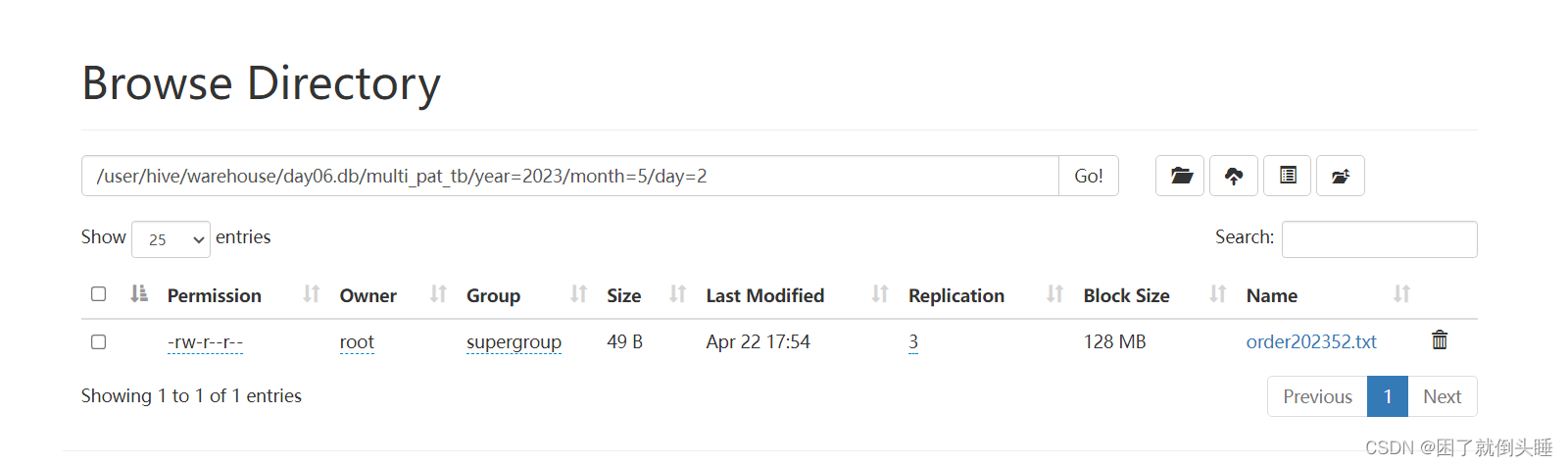
4、分区操作
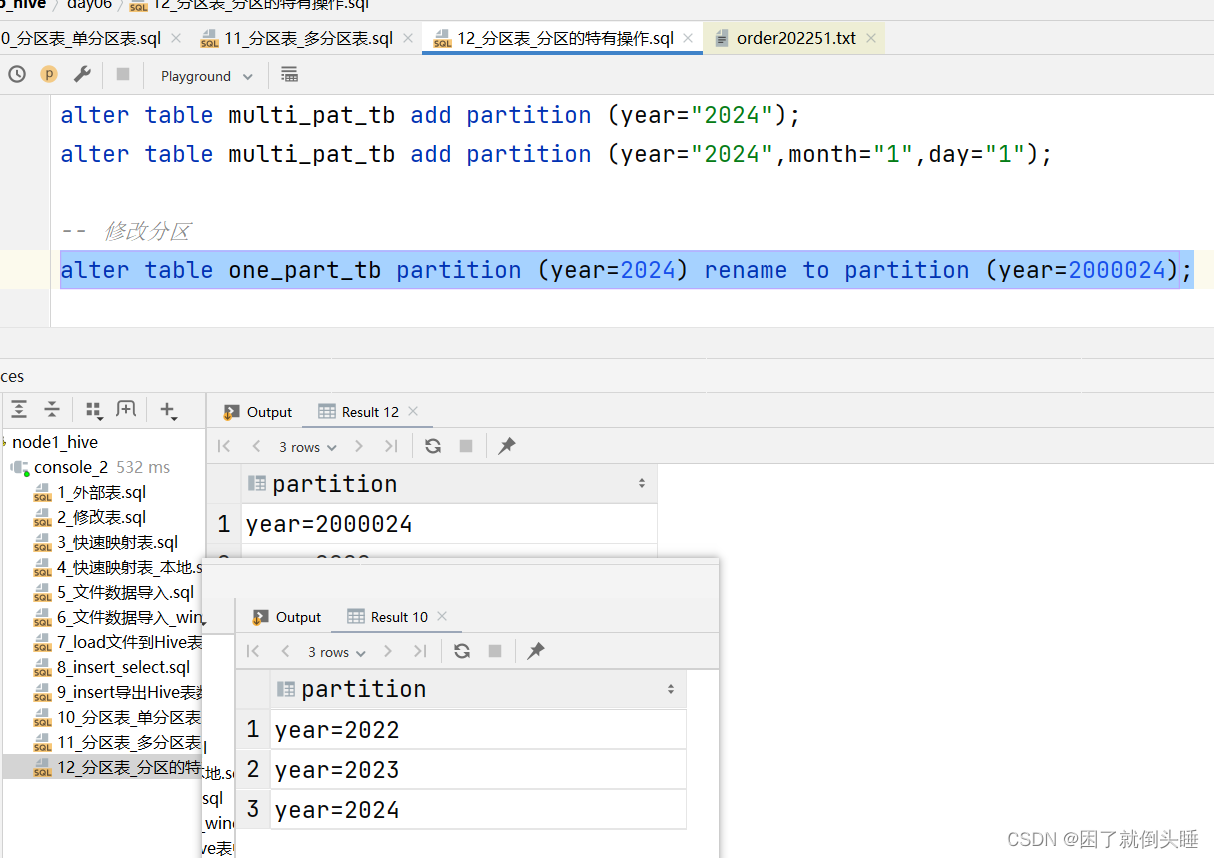
添加分区: alter table 分区表名 add partition (分区字段1=值,分区字段2=值..); 删除分区: alter table 分区表名 drop partition (分区字段1=值,分区字段2=值..); 修改分区名: alter table 分区表名 partition (分区字段1=旧分区值,分区字段2=旧分区值..) rename to partition (分区字段1=新分区值,分区字段2=新分区值..); 查看所有分区: show partitions 分区表名; 同步/修复分区: msck repair table 分区表名; 注意: 如果删除内部表的分区,那么对应的HDFS分区目录也被删除了;如果删除外部表的分区,那么对应的HDFS分区目录还保留着
示例:
use day06; -- 查询表的分区信息 show partitions one_part_tb; show partitions multi_pat_tb; -- 添加分区 alter table one_part_tb add partition (year=2024); -- 如果是多级分区,那么添加分区的时候,需要将所有的分区都添加上 alter table multi_pat_tb add partition (year="2024"); alter table multi_pat_tb add partition (year="2024",month="1",day="1"); -- 修改分区 alter table one_part_tb partition (year=2024) rename to partition (year=2000024); -- 删除分区 -- 注意:如果删除内部表的分区,那么对应的分区目录也被删除了;如果删除外部表的分区,那么对应的HDFS分区目录还保留着 alter table one_part_tb drop partition (year=2000024); alter table multi_pat_tb drop partition (year="2024",month="1",day="1"); -- 修复分区 -- 在执行下面的语句之前,需要手动去/user/hive/warehouse/day06.db/one_part_tb路径下创建一个year=2025分区目录 msck repair table one_part_tb;
给多级分区表添加分区遇到的错误:
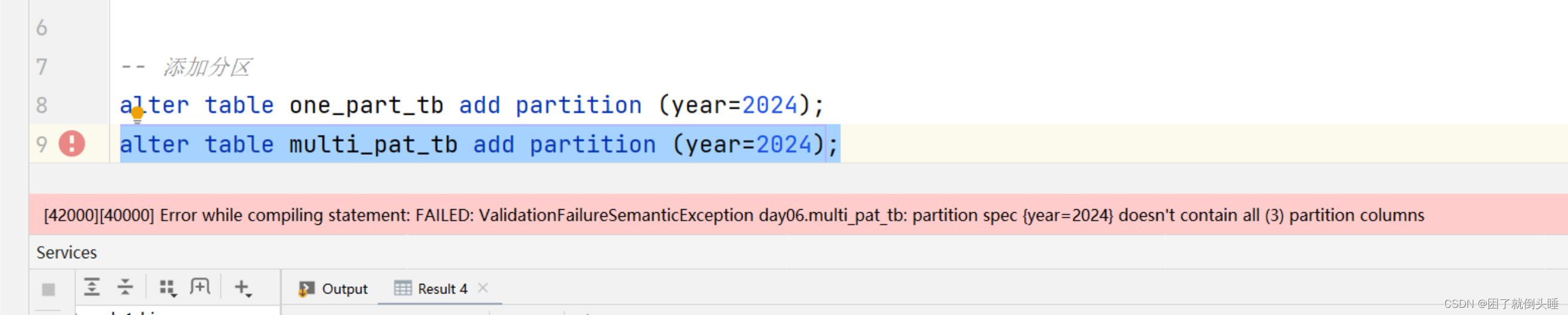
原因: 如果是多级分区,那么添加分区的时候,需要将所有的分区都添加上
修改分区效果: