深度学习——卷积神经网络
卷积神经网络
- 1.导入需要的包
- 2.数据导入与数据观察
- 3.卷积层
- 4.汇聚层
- 最大汇聚
- 平均汇聚
- 全局平均汇聚
- 5.搭建卷积神经网络进行手写数字识别
- 导入并对数据进行预处理
- 搭建卷积神经网络
- 6.利用函数式API与子类API搭建复杂神经网络
- 残差层
1.导入需要的包
numpy as np: NumPy是一个用于科学计算的库,它提供了高效的数组处理能力,对于图像处理等任务非常有用。
pandas as pd: Pandas是一个强大的数据分析和处理库,它提供了数据结构(如DataFrame)和工具,用于数据操作和分析。
matplotlib.pyplot as plt: Matplotlib是一个绘图库,pyplot是其中的一个模块,它提供了一个类似于MATLAB的绘图框架。
sklearn: Scikit-Learn是一个用于机器学习的库,它提供了各种分类器、回归器、聚类算法等。
tensorflow as tf: TensorFlow是一个开源的机器学习库,用于构建和训练各种类型的机器学习模型。
from tensorflow import keras: Keras是TensorFlow的一个高级API,它允许您轻松地构建和训练复杂的神经网络。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import sklearn
import tensorflow as tf
from tensorflow import keras
2.数据导入与数据观察
从sklearn中导两张大小为的图像,并组成一个简单数据集image。数据集image的4维张量分别对应着
数据集中的样本数2
图像高度427
图像宽度640
图像通道3
from sklearn.datasets import load_sample_imagechina = load_sample_image("china.jpg") / 255
flower = load_sample_image("flower.jpg") / 255
plt.subplot(1,2,1)
plt.imshow(china)
plt.subplot(1,2,2)
plt.imshow(flower)
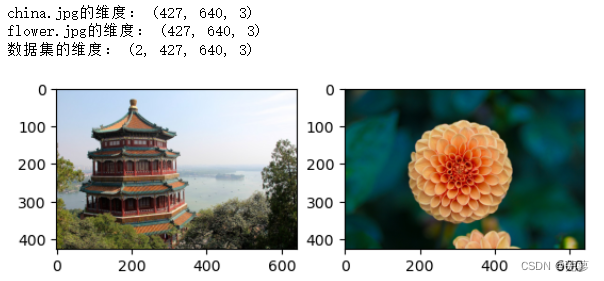
print("china.jpg的维度:",china.shape)
print("flower.jpg的维度:",flower.shape)images = np.array([china,flower])
images_shape = images.shapeprint("数据集的维度:",images_shape)
3.卷积层
u = 7 #卷积核边长
s = 1 #滑动步长
p = 5 #输出特征图数目
filters: 整数,指定卷积核的数量,即输出的维度
kernel_size: 一个整数或元组((height, width)),指定卷积核的尺寸
strides: 一个整数或元组((stride_height, stride_width)),指定卷积的步长
padding: 字符串,指定边缘填充方式。有两个选项:
"VALID":不进行填充,卷积的边缘部分将被忽略。
"SAME":进行填充,使得输出的高度和宽度与输入相同(或根据步长缩小)。填充通常是通过在输入周围添加零来实现。
input_shape: 一个整数元组,指定输入数据的形状。对于 Conv2D 层,input_shape 应该包含三个整数,分别是输入的高度、宽度和通道数。
conv = keras.layers.Conv2D(filters= p, kernel_size= u, strides= s,padding="SAME", activation="relu", input_shape=images_shape)
卷积后的图像的4维张量分别对应着 - 数据集大小2 - 图像的高427与宽640,正是由于padding==“SAME”,所以图像大小并没有发生变化 - 输出特征图个数5。
image_after_conv = conv(images)
print("卷积后的张量大小:", image_after_conv.shape)
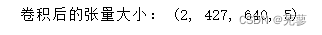
4.汇聚层
最大汇聚
最大汇聚是在下采样区域范围内提取所有元素数值的最大值,参数pool_size决定下采样区域的大小。
由于pool_size = 2,最大汇聚以后图像的特征图大小在高度与宽度上都各自缩小一半。
pool_max = keras.layers.MaxPool2D(pool_size=2)
image_after_pool_max = pool_max(image_after_conv)
print("最大汇聚后的张量大小:",image_after_pool_max.shape)
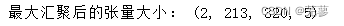
平均汇聚
平均汇聚是将下采样区域内的所有元素的数值取平均,参数pool_size决定下采样区域的大小。
pool_avg = keras.layers.AvgPool2D(pool_size=2)
image_after_pool_avg = pool_avg(image_after_conv)
print("平均汇聚后的张量大小:",image_after_pool_avg.shape)
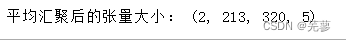
全局平均汇聚
全局平均汇聚是将特征图内的所有元素的数值取平均,输出的特征图只有一个单值。
pool_global_avg = keras.layers.GlobalAvgPool2D()
image_after_pool_global_avg = pool_global_avg(image_after_conv)
print("全局平均汇聚后的张量大小:",image_after_pool_global_avg.shape)

5.搭建卷积神经网络进行手写数字识别
导入并对数据进行预处理
path = "D:/rgzn/神经网络/" #存放.csv的文件夹
train_Data = pd.read_csv( path+'mnist_train.csv', header = None) #训练数据
test_Data = pd.read_csv( path+'mnist_test.csv', header = None) #测试数据
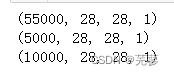
X, y = train_Data.iloc[:,1:].values/255, train_Data.iloc[:,0].values #数据归一化X_valid, X_train = X[:5000].reshape(5000,28,28) , X[5000:].reshape(55000,28,28) #验证集与训练集
y_valid, y_train = y[:5000], y[5000:]X_test,y_test = test_Data.iloc[:,1:].values.reshape(10000,28,28)/255, test_Data.iloc[:,0].values #测试集
print(X_train.shape)
print(X_valid.shape)
print(X_test.shape)

此时数据还是三维的张量,由于手写数字图像是灰度图像,通道只有1,因此,需要将数据扩展为四维张量。
X_train = X_train[..., np.newaxis]
X_valid = X_valid[..., np.newaxis]
X_test = X_test[..., np.newaxis]print(X_train.shape)
print(X_valid.shape)
print(X_test.shape)
搭建卷积神经网络
model_cnn_mnist = keras.models.Sequential([keras.layers.Conv2D(32, kernel_size=3, padding="same", activation="relu"),keras.layers.Conv2D(64, kernel_size=3, padding="same", activation="relu"),keras.layers.MaxPool2D(pool_size=2),keras.layers.Flatten(),keras.layers.Dropout(0.25),keras.layers.Dense(128, activation="relu"),keras.layers.Dropout(0.5),keras.layers.Dense(10, activation="softmax")
])
第一层卷积层,使用32个大小的卷积核
第二层卷积层,使用64个大小的卷积核
第三层汇聚层,将所有特征映射的维度缩小至原先一半
第四层是平展层,将原先四维张量(55000,14,14,64)平展成两维张量(55000,),即将一个样本的所有参数项平展成一个维度。
后续是全连接层。
model_cnn_mnist.compile(loss="sparse_categorical_crossentropy", optimizer="nadam", metrics=["accuracy"])
model_cnn_mnist.fit(X_train, y_train, epochs=10, validation_data=(X_valid, y_valid))

查看准确率
model_cnn_mnist.evaluate(X_test, y_test, batch_size=1)

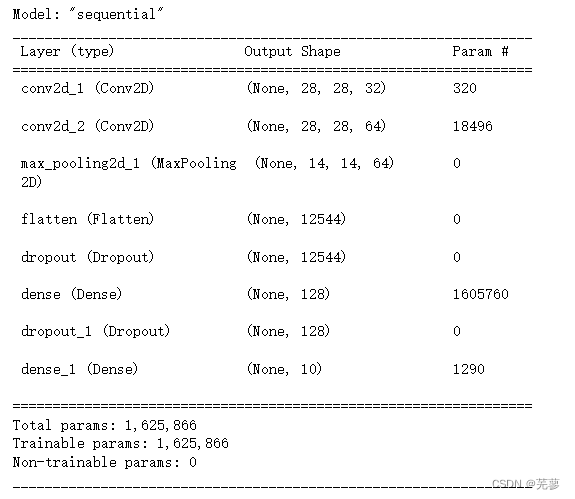
用.summary()观察神经网络的整体情况
model_cnn_mnist.summary()
之前在全连接前馈神经网络中,我们手写数字识别的准确率大约在97%左右,而利用卷积神经网络,可以将准确率提升到99%。
6.利用函数式API与子类API搭建复杂神经网络
残差层
输出的特征图数目每隔一阵就会扩大一倍,且在扩大的同时,特征图的高度、宽度减半(滑动步长s=2),共计经过特征图数目为
- 64的残差块3个
- 128的残差块4个
- 256的残差块6个
- 以及512的残差块3个
其中,残差连接分为实线连接与虚线连接
实线连接即残差块的输入直接跨层与经过卷积的结果相加
虚线连接主要针对的是滑动步长为2的部分,由于特征图的大小减小了,所以输入无法直接与卷积结果相加,也需要减小特征图大小
class ResidualUnit(keras.layers.Layer):def __init__(self, filters, strides=1, activation="relu"):super().__init__()self.activation = keras.activations.get(activation)self.main_layers = [keras.layers.Conv2D(filters, 3, strides=strides, padding = "SAME", use_bias = False), keras.layers.BatchNormalization(),self.activation,keras.layers.Conv2D(filters, 3, strides=1, padding = "SAME", use_bias = False),keras.layers.BatchNormalization()]# 当滑动步长s = 1时,残差连接直接将输入与卷积结果相加,skip_layers为空,即实线连接self.skip_layers = [] # 当滑动步长s = 2时,残差连接无法直接将输入与卷积结果相加,需要对输入进行卷积处理,即虚线连接if strides > 1:self.skip_layers = [keras.layers.Conv2D(filters, 1, strides=strides, padding = "SAME", use_bias = False),keras.layers.BatchNormalization()]def call(self, inputs):Z = inputsfor layer in self.main_layers:Z = layer(Z)skip_Z = inputsfor layer in self.skip_layers:skip_Z = layer(skip_Z)return self.activation(Z + skip_Z)搭建完整的ResNet-34神经网络
model = keras.models.Sequential()model.add(keras.layers.Conv2D(64, 7, strides=2, padding = "SAME", use_bias = False))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Activation("relu"))
model.add(keras.layers.MaxPool2D(pool_size=3, strides=2, padding="SAME"))prev_filters = 64
for filters in [64] * 3 + [128] * 4 + [256] * 6 + [512] * 3:strides = 1 if filters == prev_filters else 2 #在每次特征图数目扩展时,设置滑动步长为2model.add(ResidualUnit(filters, strides=strides))prev_filters = filtersmodel.add(keras.layers.GlobalAvgPool2D())
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(10, activation="softmax"))
训练:
model.compile(loss="sparse_categorical_crossentropy", optimizer="nadam", metrics=["accuracy"])
model.fit(X_train, y_train, epochs=10, validation_data=(X_valid, y_valid))
查看准确率:
model.evaluate(X_test,y_test,batch_size=1)
