【深度学习】YOLOv10实战:20行代码将笔记本摄像头改装成目标检测监控
目录
一、引言
二、YOLOv10视觉目标检测—原理概述
2.1 什么是YOLO
2.2 YOLO的网络结构
三、YOLOv10视觉目标检测—训练推理
3.1 YOLOv10安装
3.1.1 克隆项目
3.1.2 创建conda环境
3.1.3 下载并编译依赖
3.2 YOLOv10模型推理
3.2.1 模型下载
3.2.2 WebUI推理
3.2.3 命令行推理
3.2.4 推理格式转换
3.3 YOLOv10模型训练
四、YOLOv10实战:20行代码构建基于YOLOv10的实时视频监控
五、总结
一、引言
人工智能的终极形态,应该就是“具身机器人”——像人一样有眼睛(视觉)、耳朵(听觉)、嘴巴(语言)、舌头(味觉)、鼻子(嗅觉)等器官,味觉、嗅觉目前没有大的进展,视觉、听觉、语言能力在科学界与工程界已经取得重大突破:
- 视觉模型:YOLOv10、LLaVA、Qwen-VL等大语言模型的Vision版本
- 听觉模型:TTS(文字转语音)、Whisper(ASR,语音转文字)
- 语言模型:GPT4、LLaMA、Qwen、文心一言等等大语言模型
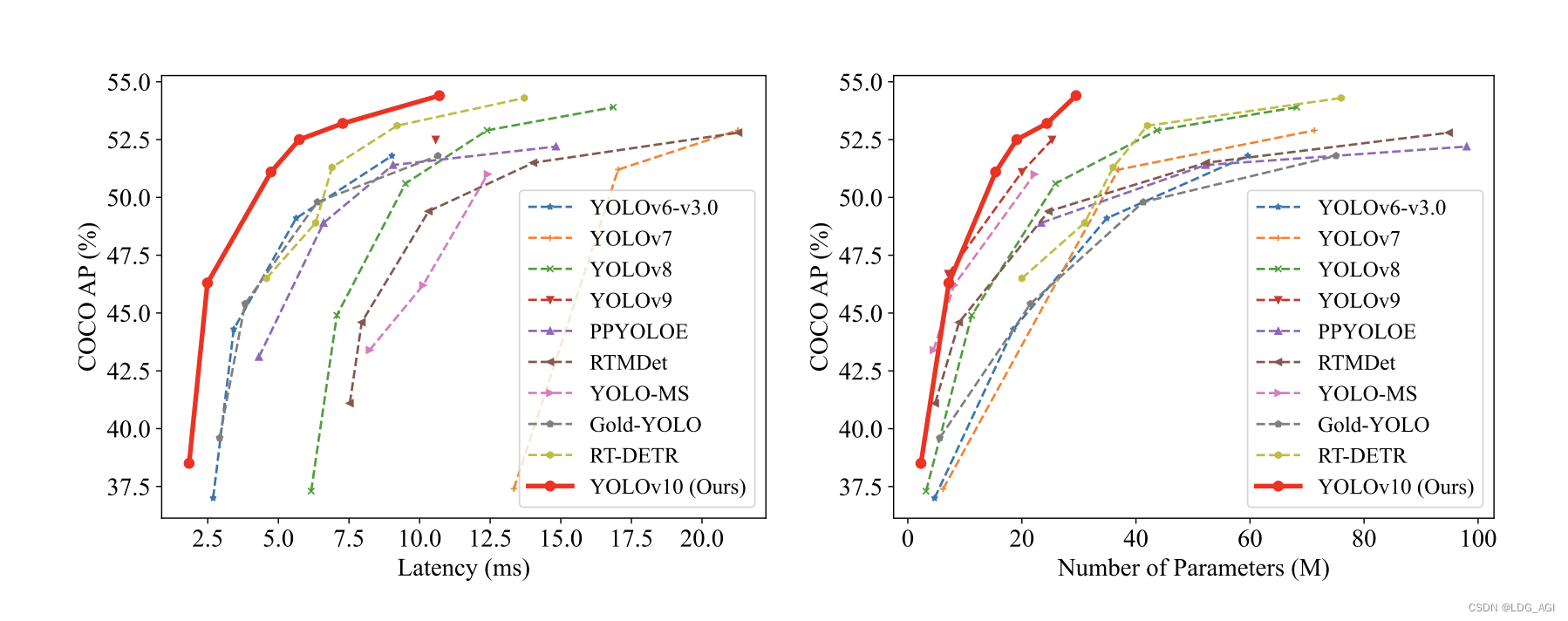
今天我们讲一下最近大火的YOLOv10(You Only Look Once v10),由清华大学5月23日发布,比YOLOv9在相同性能下延迟减少了46%,参数减少了25%。
二、YOLOv10视觉目标检测—原理概述
2.1 什么是YOLO
YOLO(You Only Look Once)是基于深度神经网络的目标检测算法,用在图像或视频中实时识别和定位多个对象。YOLO的主要特点是速度快且准确度较高,能够在实时场景下实现快速目标检测,被广泛应用于计算机视觉领域,包括实时视频分析、自动驾驶、智能医疗等。
在YOLO出现前,主流算法为R-CNN,可以称之为“二阶段算法”:先锚框,再预测框内的物体。YOLO出现后,可以“一阶段”直接端到端的输出物料和位置。
- 一阶段算法:模型直接做回归任务,输出目标的概率值和位置坐标。例如:SSD, YOLO,MTCNN等
- 二阶段算法:首先生成多个锚框,然后利用卷积神经网络输出概率值和位置坐标。例如:R-CNN系列
2.2 YOLO的网络结构
YOLOv10是YOLOv8的改进,这里简单看一下YOLOv8的网络结构,由于本篇文章的主旨是快速部署自己的YOLOv10模型,原理暂且按下不表,如果想深入了解可以关注迪菲赫尔曼-CSDN博客大佬。
YOLOv8网络结构图:
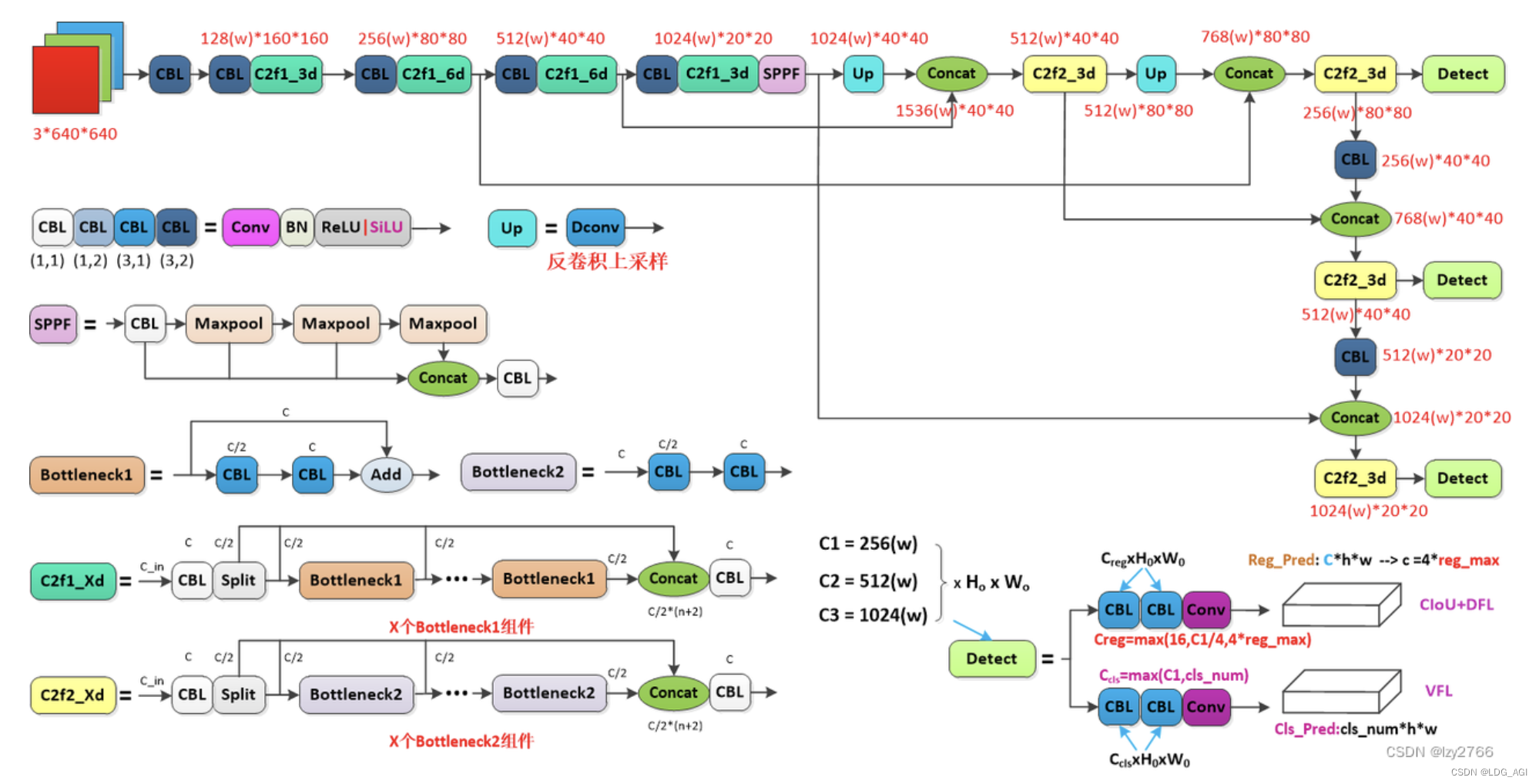
图片来源:yolov8网络结构详解(逐行解析)_yolov8网络架构-CSDN博客
三、YOLOv10视觉目标检测—训练推理
3.1 YOLOv10安装
3.1.1 克隆项目
git clone https://github.com/THU-MIG/yolov10.git3.1.2 创建conda环境
conda create -n yolov10 python=3.9
conda activate yolov103.1.3 下载并编译依赖
这里推荐使用腾讯pip源,真的很快
pip install -r requirements.txt -i https://mirrors.cloud.tencent.com/pypi/simple
pip install -e . -i https://mirrors.cloud.tencent.com/pypi/simple3.2 YOLOv10模型推理
3.2.1 模型下载
可以直接点击链接下载:
YOLOv10-N:https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10n.pt
YOLOv10-S:https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10s.pt
YOLOv10-M:https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10m.pt
YOLOv10-B:https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10b.pt
YOLOv10-L:https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10l.pt
YOLOv10-X:https://github.com/THU-MIG/yolov10/releases/download/v1.1/yolov10x.pt
3.2.2 WebUI推理
项目根目录下运行:
python app.py执行成功后显示:

报错解决:
我在执行时出现了报错:ImportError: libGL.so.1: cannot open shared object file: No such file or dir
在启动前出现了这个错误,主要因为opencv-python-headless版本导致,重新安装解决
pip uninstall opencv-python -y pip install opencv-python-headless -i https://mirrors.cloud.tencent.com/pypi/simple
在浏览器输入127.0.0.1:7861,见证奇迹的时刻: 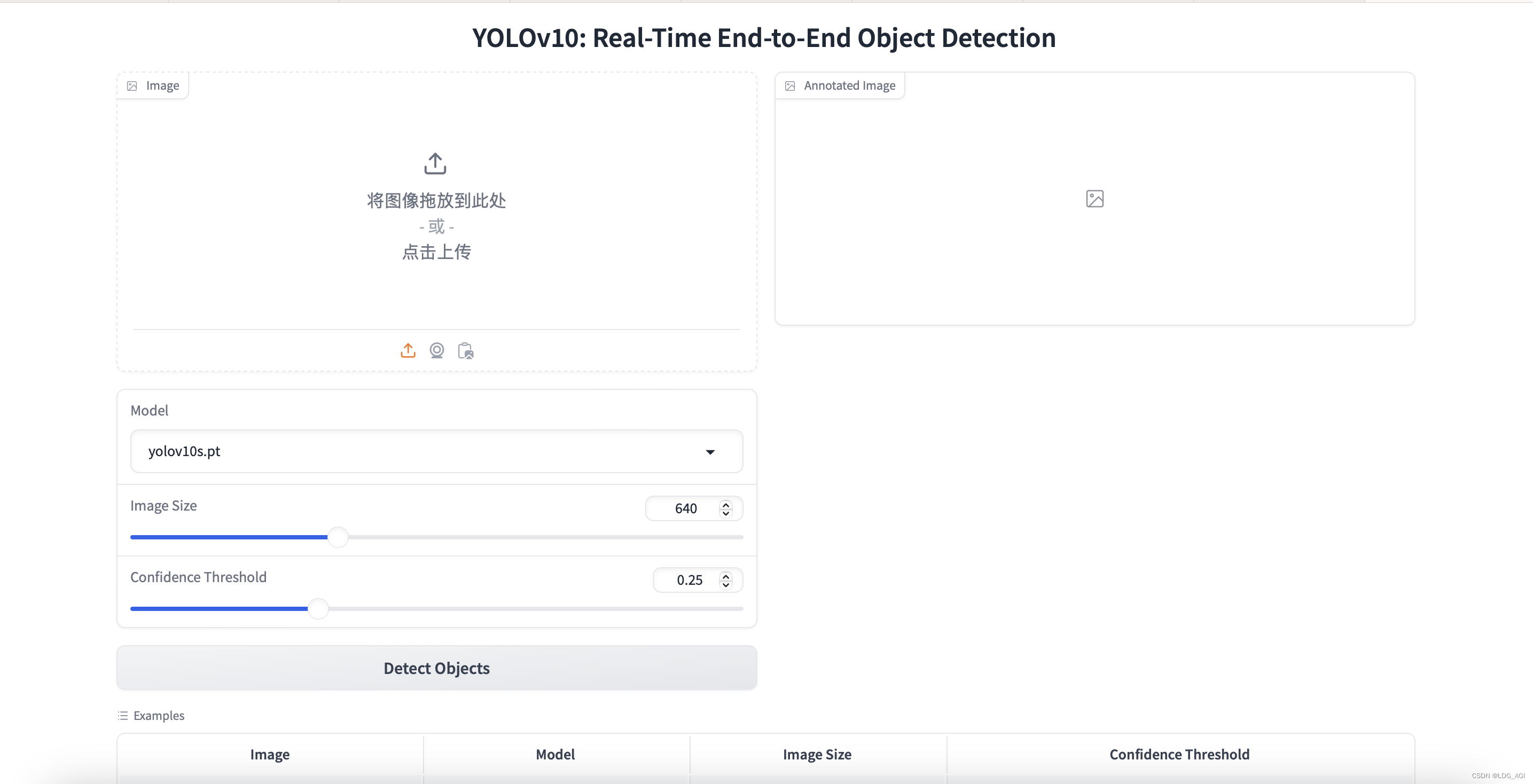
- 上传图片检测:毫秒级瞬间级就检测出来了
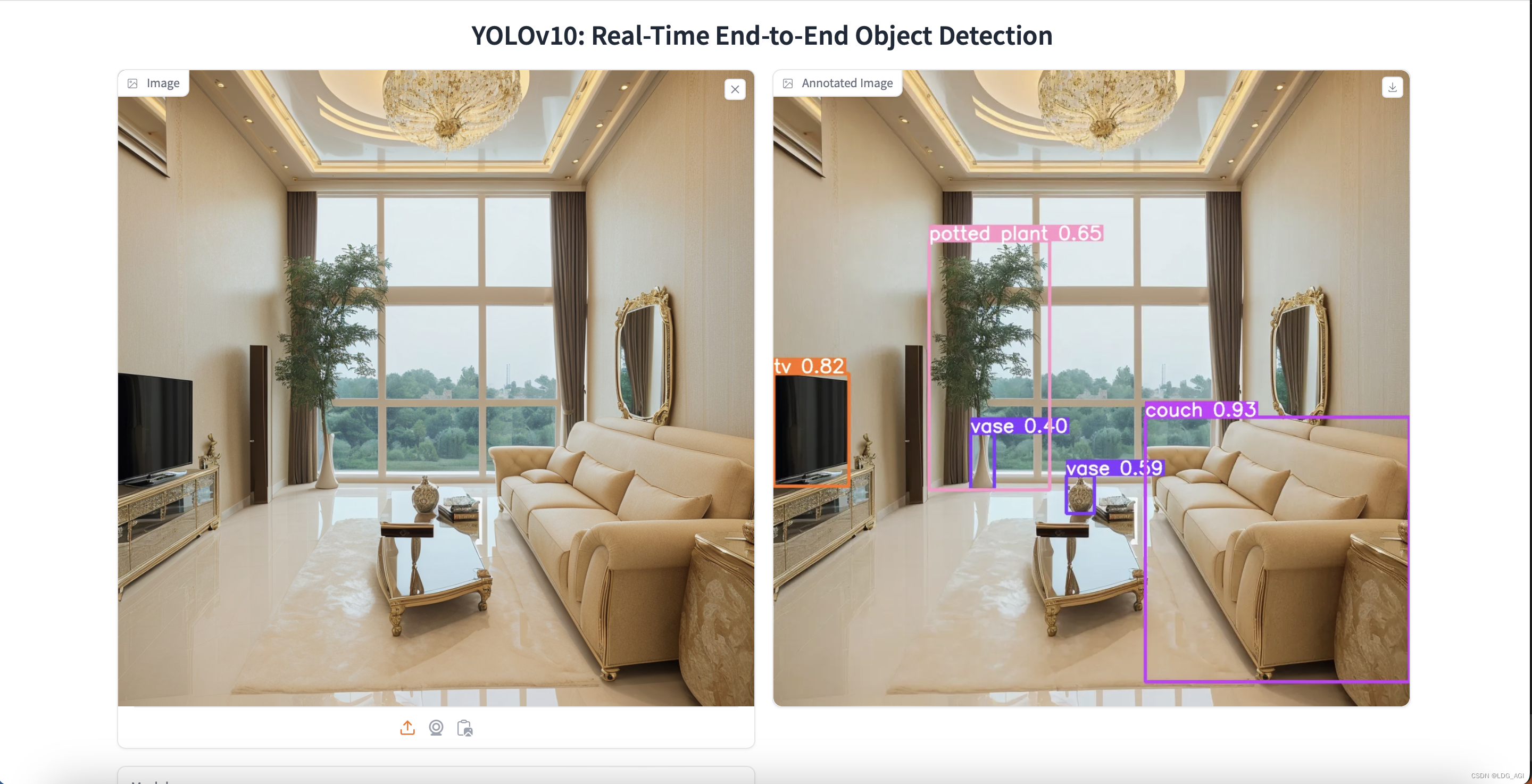
- 摄像头拍照检测: 人、手机、表均不完整,但可以快速识别,nice!
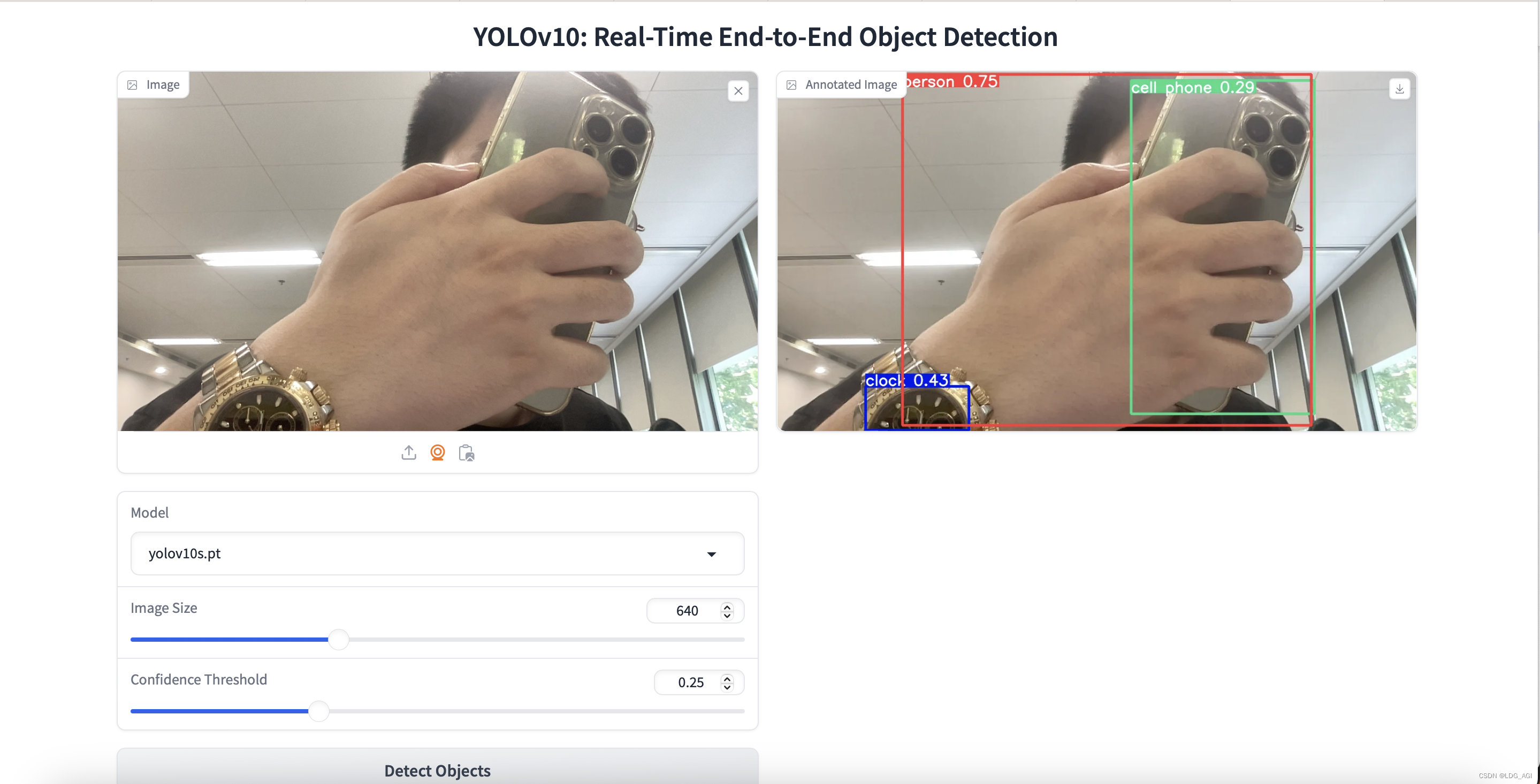
3.2.3 命令行推理
conda环境内用yolo启动,predict参数预测,model用于指定下载好的模型,device指定GPU,source指定要检测的图片。
yolo predict model=yolov10n.pt device=2 source=/aigc_dev/yolov10/ultralytics/assets默认待检测图片存放在yolov10/ultralytics/assets目录下,检测后存放于yolov10/runs/detect/predictxx目录
可以看到,yolov10n在V100显卡下,平均检测时长为78.7ms
官方采用COCO数据集对每种模型进行评测,仅供参考。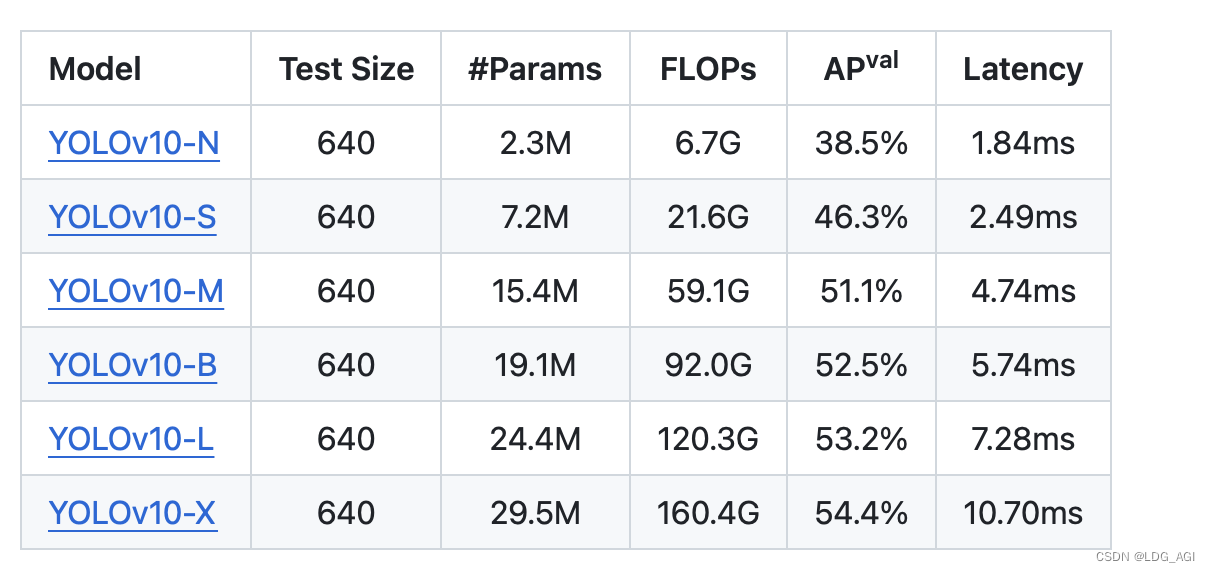
检测结果展示:
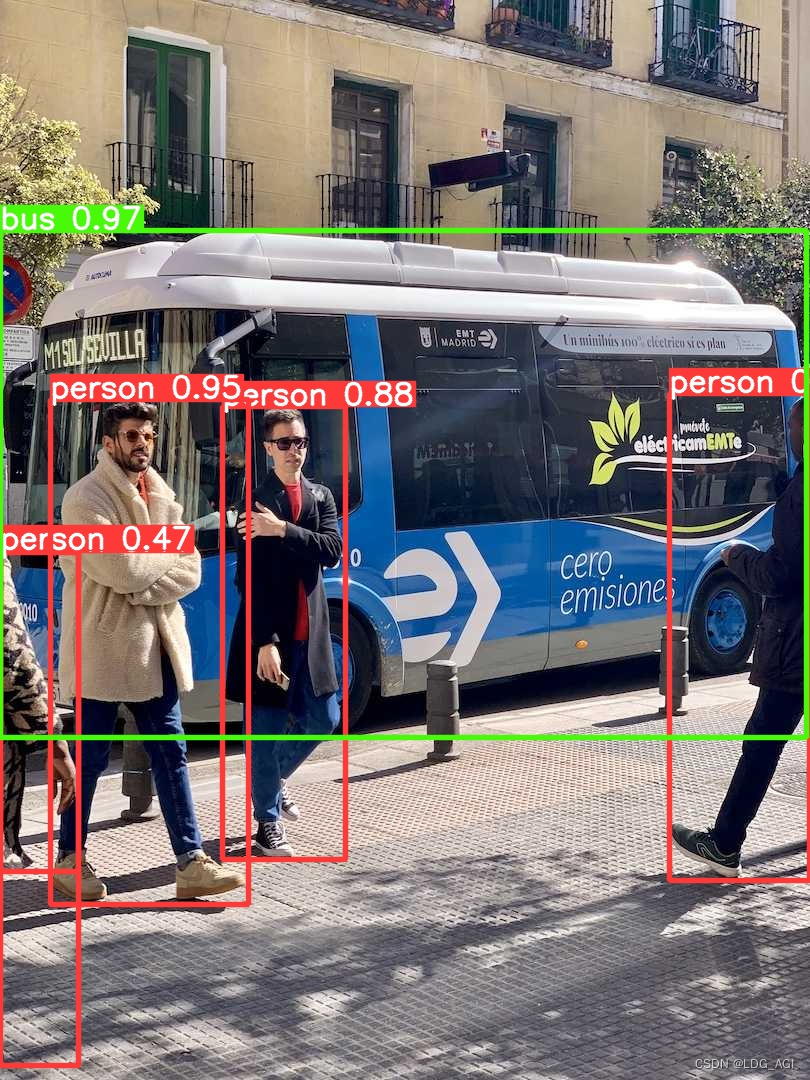
3.2.4 推理格式转换
项目可以方便的转换为ONNX和TensorRT格式,用于跨平台推理与部署。
yolo export model=yolov10n.pt format=onnx opset=13 simplify device=2
yolo predict model=yolov10n.onnx device=2
- ONNX(Open Neural Network Exchange)是一个开放的格式,用于表示深度学习模型,使得模型可以在不同的框架之间轻松迁移。它支持多种深度学习框架,如PyTorch、TensorFlow、MXNet等,允许开发者在不同的生态系统中选择最合适的工具进行模型训练,然后导出到ONNX格式,以便在其他支持ONNX的平台上进行部署。
- TensorRT是NVIDIA开发的一个高性能的深度学习推理(Inference)优化器和运行时,专为NVIDIA GPU设计。它接收训练好的模型(支持ONNX等格式),并对其进行优化,生成针对特定GPU硬件的高效执行代码。
3.3 YOLOv10模型训练
yolo不仅提供推理服务,还支持引入数据集进行训练:
yolo detect train data=coco.yaml model=yolov10s.yaml epochs=100 batch=128 imgsz=640 device=2detect train为检测训练命令,data指定数据集,默认数据集下载并存放在../datasets/coco,model指定训练模型配置,epochs代表迭代次数,imgsz代表图片缩放大小,batch代表批处理,device为指定GPU设备。
启动后进行COCO数据集的下载,非常庞大,由于服务器无法科学上网,需要下很久,这里不投入时间了,如果感兴趣可以前往COCO - Common Objects in Context 下载。也可以执行上面命令后自动下载。
四、YOLOv10实战:20行代码构建基于YOLOv10的实时视频监控
在根目录下建立run_python.py:
import cv2
from ultralytics import YOLOv10
model = YOLOv10("yolov10s.pt")
cap = cv2.VideoCapture(0)
while True:ret, frame = cap.read()if not ret:break # 如果没有读取到帧,退出循环results = model.predict(frame)# 遍历每个预测结果for result in results:# 结果中的每个元素对应一张图片的预测boxes = result.boxes # 获取边界框信息for box in boxes:x1,y1,x2,y2 = map(int, box.xyxy[0])cls = int(box.cls[0])conf = float(box.conf[0])cv2.rectangle(frame, (x1, y1), (x2, y2), (255, 0, 0), 2)cv2.putText(frame, f'{model.names[cls]} {conf:.2f}', (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 0, 0), 2)# 显示带有检测结果的帧cv2.imshow('YOLOv10实时检测', frame)# 按'q'键退出if cv2.waitKey(1) & 0xFF == ord('q'):break# 释放资源
cap.release()
cv2.destroyAllWindows()运行后电脑摄像头自动开启,实时检测摄像头内的目标:
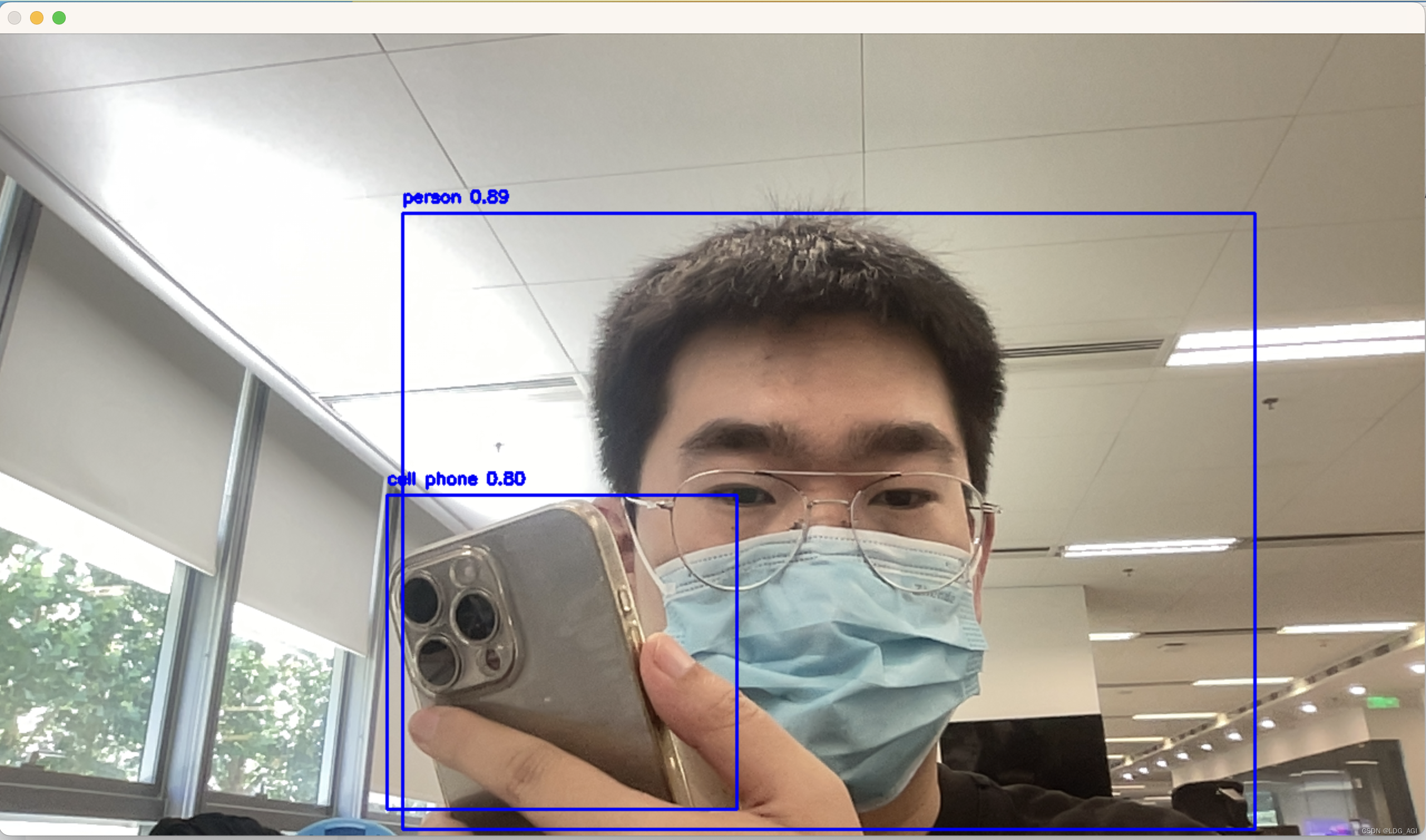
感受:由于使用个人mac笔记本,推理性能较差,取中等尺寸的yolov10b.pt模型,推理耗时达到了300-400ms,而对于很多物体,也很难有效识别,比如拿了盒烟,他会判定成一本书。真正应用到生产环境还需要在推理性能和模型训练上深耕。

五、总结
本文首先介绍视觉模型在人工智能领域的位置,其次对原理概念初步进行说明,之后对推理与训练过程进行详细阐述,最后通过一个实战例子,用极少的代码行数将笔记本电脑的摄像头改装为实时视频监控,目标是让读者通过读完此文,快速上手YOLOv10技术进行物体目标检测,
- 从应用角度讲,YOLO非常贴合实际应用,很多人基于YOLO创业并产生收益,比如智能驾驶、安全监控、医疗检测等
- 从研究角度讲,YOLO供发布10个版本,围绕效果和速度进行了频繁的迭代与优化,知识体系非常深入。
如果读者对YOLO有兴趣,我后期会持续更新,也可以通过站内搜索持续了解。
如果您还有时间,可以看看我的其他文章:
《AI—工程篇》
AI智能体研发之路-工程篇(一):Docker助力AI智能体开发提效
AI智能体研发之路-工程篇(二):Dify智能体开发平台一键部署
AI智能体研发之路-工程篇(三):大模型推理服务框架Ollama一键部署
AI智能体研发之路-工程篇(四):大模型推理服务框架Xinference一键部署
AI智能体研发之路-工程篇(五):大模型推理服务框架LocalAI一键部署
《AI—模型篇》
AI智能体研发之路-模型篇(一):大模型训练框架LLaMA-Factory在国内网络环境下的安装、部署及使用
AI智能体研发之路-模型篇(二):DeepSeek-V2-Chat 训练与推理实战
AI智能体研发之路-模型篇(三):中文大模型开、闭源之争
AI智能体研发之路-模型篇(四):一文入门pytorch开发
AI智能体研发之路-模型篇(五):pytorch vs tensorflow框架DNN网络结构源码级对比
AI智能体研发之路-模型篇(六):【机器学习】基于tensorflow实现你的第一个DNN网络