PostgreSQL的学习心得和知识总结(一百四十四)|深入理解PostgreSQL数据库之sendTuples的实现原理及功能修改
目录结构
注:提前言明 本文借鉴了以下博主、书籍或网站的内容,其列表如下:
1、参考书籍:《PostgreSQL数据库内核分析》
2、参考书籍:《数据库事务处理的艺术:事务管理与并发控制》
3、PostgreSQL数据库仓库链接,点击前往
4、日本著名PostgreSQL数据库专家 铃木启修 网站主页,点击前往
5、参考书籍:《PostgreSQL中文手册》
6、参考书籍:《PostgreSQL指南:内幕探索》,点击前往
1、本文内容全部来源于开源社区 GitHub和以上博主的贡献,本文也免费开源(可能会存在问题,评论区等待大佬们的指正)
2、本文目的:开源共享 抛砖引玉 一起学习
3、本文不提供任何资源 不存在任何交易 与任何组织和机构无关
4、大家可以根据需要自行 复制粘贴以及作为其他个人用途,但是不允许转载 不允许商用 (写作不易,还请见谅 💖)
5、本文内容基于PostgreSQL master源码开发而成
深入理解PostgreSQL数据库之sendTuples的实现原理及功能修改
- 文章快速说明索引
- 功能使用背景说明
- 报文解析
- 结果接收
- 源码改造实现分析

文章快速说明索引
学习目标:
做数据库内核开发久了就会有一种 少年得志,年少轻狂 的错觉,然鹅细细一品觉得自己其实不算特别优秀 远远没有达到自己想要的。也许光鲜的表面掩盖了空洞的内在,每每想到于此,皆有夜半临渊如履薄冰之感。为了睡上几个踏实觉,即日起 暂缓其他基于PostgreSQL数据库的兼容功能开发,近段时间 将着重于学习分享Postgres的基础知识和实践内幕。
学习内容:(详见目录)
1、深入理解PostgreSQL数据库之sendTuples的实现原理及功能修改
学习时间:
2024年05月30日 21:22:11
学习产出:
1、PostgreSQL数据库基础知识回顾 1个
2、CSDN 技术博客 1篇
3、PostgreSQL数据库内核深入学习
注:下面我们所有的学习环境是Centos8+PostgreSQL master+Oracle19C+MySQL8.0
postgres=# select version();version
------------------------------------------------------------------------------------------------------------PostgreSQL 17devel on x86_64-pc-linux-gnu, compiled by gcc (GCC) 8.5.0 20210514 (Red Hat 8.5.0-21), 64-bit
(1 row)postgres=##-----------------------------------------------------------------------------#SQL> select * from v$version; BANNER Oracle Database 19c EE Extreme Perf Release 19.0.0.0.0 - Production
BANNER_FULL Oracle Database 19c EE Extreme Perf Release 19.0.0.0.0 - Production Version 19.17.0.0.0
BANNER_LEGACY Oracle Database 19c EE Extreme Perf Release 19.0.0.0.0 - Production
CON_ID 0#-----------------------------------------------------------------------------#mysql> select version();
+-----------+
| version() |
+-----------+
| 8.0.27 |
+-----------+
1 row in set (0.06 sec)mysql>
功能使用背景说明
我们先看一个例子,如下:
postgres=# create table t1 (id int);
2024-05-30 06:35:26.573 PDT [72446] LOG: duration: 2.073 ms
CREATE TABLE
postgres=# insert into t1 select generate_series(1, 2);
2024-05-30 06:35:38.353 PDT [72446] LOG: duration: 0.927 ms
INSERT 0 2
postgres=# create table t2 as select * from t1;
2024-05-30 06:35:42.241 PDT [72446] LOG: duration: 1.356 ms
SELECT 2
postgres=# select * from t1, t2;
2024-05-30 06:35:48.143 PDT [72446] LOG: duration: 0.380 msid | id
----+----1 | 11 | 22 | 12 | 2
(4 rows)postgres=#
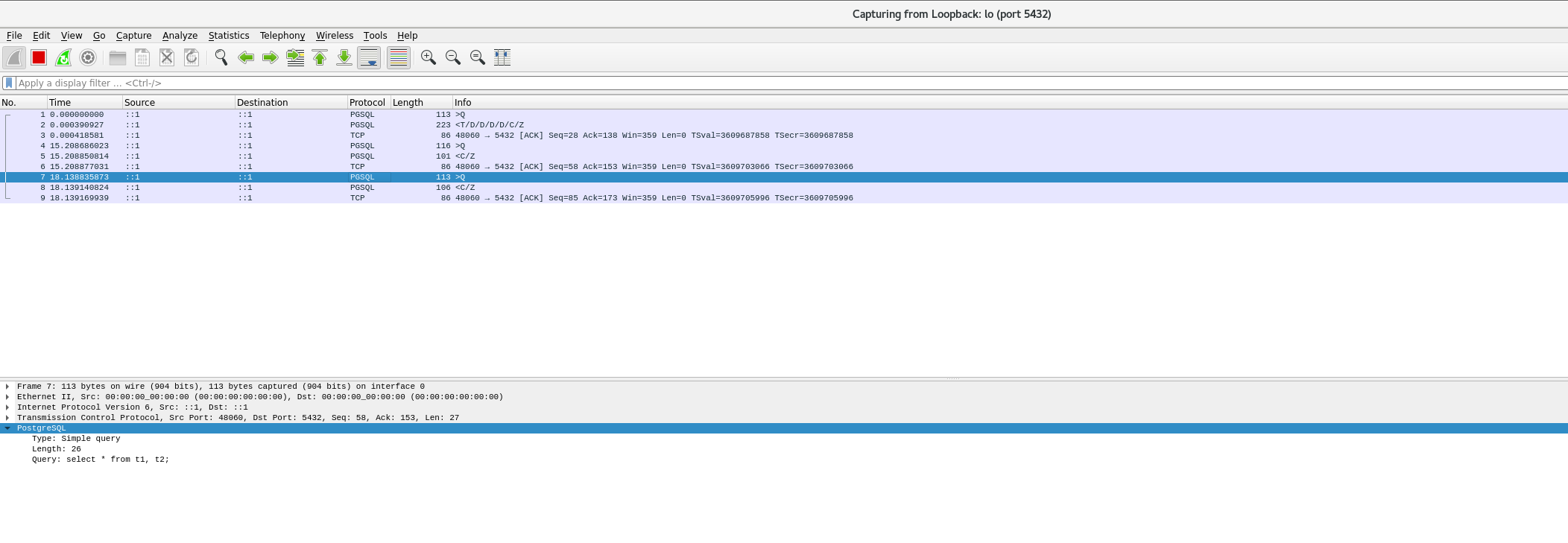
这是一个非常简单的select语句,接下来我们使用抓包工具捕获通信协议,如下:
有兴趣的小伙伴们可以看一下本人之前的博客,如下:
- PostgreSQL的学习心得和知识总结(一百一十三)|Linux环境下Wireshark工具的安装及抓包PostgreSQL建立连接过程,点击前往
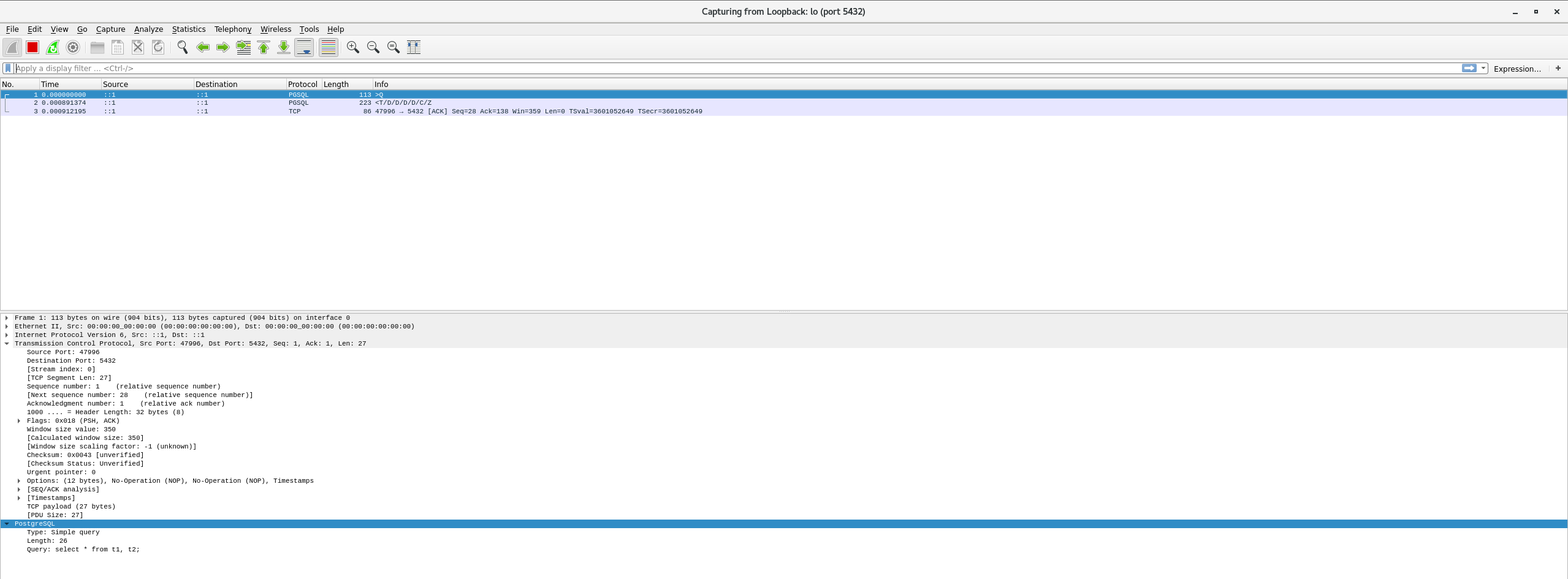
报文解析
Q报文,如下:
Frame 1: 113 bytes on wire (904 bits), 113 bytes captured (904 bits) on interface 0
Ethernet II, Src: 00:00:00_00:00:00 (00:00:00:00:00:00), Dst: 00:00:00_00:00:00 (00:00:00:00:00:00)
Internet Protocol Version 6, Src: ::1, Dst: ::1
Transmission Control Protocol, Src Port: 47996, Dst Port: 5432, Seq: 1, Ack: 1, Len: 27
PostgreSQLType: Simple queryLength: 26Query: select * from t1, t2;
T D C Z报文,如下:
Frame 2: 223 bytes on wire (1784 bits), 223 bytes captured (1784 bits) on interface 0
Ethernet II, Src: 00:00:00_00:00:00 (00:00:00:00:00:00), Dst: 00:00:00_00:00:00 (00:00:00:00:00:00)
Internet Protocol Version 6, Src: ::1, Dst: ::1
Transmission Control Protocol, Src Port: 5432, Dst Port: 47996, Seq: 1, Ack: 28, Len: 137
PostgreSQLType: Row descriptionLength: 48Field count: 2
PostgreSQLType: Data rowLength: 16Field count: 2
PostgreSQLType: Data rowLength: 16Field count: 2
PostgreSQLType: Data rowLength: 16Field count: 2
PostgreSQLType: Data rowLength: 16Field count: 2
PostgreSQLType: Command completionLength: 13Tag: SELECT 4
PostgreSQLType: Ready for queryLength: 5Status: Idle (73)
我们这里不再详解PostgreSQL所有报文的含义及源码实现,我们这里只看一下以上几种的即可,如下:
Q报文的发送,如下:
// src/interfaces/libpq/fe-exec.cstatic int
PQsendQueryInternal(PGconn *conn, const char *query, bool newQuery)
{.../* Send the query message(s) *//* construct the outgoing Query message */if (pqPutMsgStart(PqMsg_Query, conn) < 0 ||pqPuts(query, conn) < 0 ||pqPutMsgEnd(conn) < 0){/* error message should be set up already */pqRecycleCmdQueueEntry(conn, entry);return 0;}...
}
T报文的发送,如下:
// src/backend/access/common/printtup.c/** SendRowDescriptionMessage --- send a RowDescription message to the frontend* SendRowDescriptionMessage --- 向前端发送 RowDescription 消息** Notes: the TupleDesc has typically been manufactured by ExecTypeFromTL()* or some similar function; it does not contain a full set of fields.* 注意:TupleDesc 通常由 ExecTypeFromTL() 或某些类似函数生成;它不包含完整的字段集* * The targetlist will be NIL when executing a utility function that does* not have a plan. If the targetlist isn't NIL then it is a Query node's* targetlist; it is up to us to ignore resjunk columns in it. The formats[]* array pointer might be NULL (if we are doing Describe on a prepared stmt);* send zeroes for the format codes in that case.* 执行没有计划的实用程序函数时,目标列表将为 NIL* 如果目标列表不是 NIL,则它就是查询节点的目标列表;我们可以忽略其中的 resjunk 列* formats[] 数组指针可能为 NULL(如果我们在准备好的 stmt 上执行 Describe)* 在这种情况下,为格式代码发送零*/
void
SendRowDescriptionMessage(StringInfo buf, TupleDesc typeinfo,List *targetlist, int16 *formats)
{int natts = typeinfo->natts;int i;ListCell *tlist_item = list_head(targetlist);/* tuple descriptor message type */pq_beginmessage_reuse(buf, 'T');/* # of attrs in tuples */pq_sendint16(buf, natts);/** Preallocate memory for the entire message to be sent. That allows to* use the significantly faster inline pqformat.h functions and to avoid* reallocations.** Have to overestimate the size of the column-names, to account for* character set overhead.*/enlargeStringInfo(buf, (NAMEDATALEN * MAX_CONVERSION_GROWTH /* attname */+ sizeof(Oid) /* resorigtbl */+ sizeof(AttrNumber) /* resorigcol */+ sizeof(Oid) /* atttypid */+ sizeof(int16) /* attlen */+ sizeof(int32) /* attypmod */+ sizeof(int16) /* format */) * natts);for (i = 0; i < natts; ++i){Form_pg_attribute att = TupleDescAttr(typeinfo, i);...pq_writestring(buf, NameStr(att->attname));pq_writeint32(buf, resorigtbl);pq_writeint16(buf, resorigcol);pq_writeint32(buf, atttypid);pq_writeint16(buf, att->attlen);pq_writeint32(buf, atttypmod);pq_writeint16(buf, format);}pq_endmessage_reuse(buf);
}
D报文的发送,如下:
// src/backend/access/common/printtup.c/* ----------------* printtup --- send a tuple to the client** Note: if you change this function, see also serializeAnalyzeReceive* in explain.c, which is meant to replicate the computations done here.* * 注意:如果您更改此函数,另请参阅 explain.c 中的 serializeAnalyzeReceive,旨在复制此处完成的计算* ----------------*/
static bool
printtup(TupleTableSlot *slot, DestReceiver *self)
{TupleDesc typeinfo = slot->tts_tupleDescriptor;DR_printtup *myState = (DR_printtup *) self;MemoryContext oldcontext;StringInfo buf = &myState->buf;int natts = typeinfo->natts;int i;/* Set or update my derived attribute info, if needed */if (myState->attrinfo != typeinfo || myState->nattrs != natts)printtup_prepare_info(myState, typeinfo, natts);/* Make sure the tuple is fully deconstructed */slot_getallattrs(slot);/* Switch into per-row context so we can recover memory below */oldcontext = MemoryContextSwitchTo(myState->tmpcontext);/** Prepare a DataRow message (note buffer is in per-query context)*/pq_beginmessage_reuse(buf, 'D');pq_sendint16(buf, natts);/** send the attributes of this tuple*/for (i = 0; i < natts; ++i){PrinttupAttrInfo *thisState = myState->myinfo + i;Datum attr = slot->tts_values[i];...}pq_endmessage_reuse(buf);/* Return to caller's context, and flush row's temporary memory */MemoryContextSwitchTo(oldcontext);MemoryContextReset(myState->tmpcontext);return true;
}
这里发送一个tuple,如下:
C报文的发送,如下:
// src/backend/tcop/dest.c/* ----------------* EndCommand - clean up the destination at end of command* ----------------*/
void
EndCommand(const QueryCompletion *qc, CommandDest dest, bool force_undecorated_output)
{char completionTag[COMPLETION_TAG_BUFSIZE];Size len;switch (dest){case DestRemote:case DestRemoteExecute:case DestRemoteSimple:len = BuildQueryCompletionString(completionTag, qc,force_undecorated_output);pq_putmessage(PqMsg_CommandComplete, completionTag, len + 1);case DestNone:case DestDebug:case DestSPI:case DestTuplestore:case DestIntoRel:case DestCopyOut:case DestSQLFunction:case DestTransientRel:case DestTupleQueue:case DestExplainSerialize:break;}
}
Z报文的发送,如下:
// src/backend/tcop/dest.c/* ----------------* ReadyForQuery - tell dest that we are ready for a new query** The ReadyForQuery message is sent so that the FE can tell when* we are done processing a query string.* In versions 3.0 and up, it also carries a transaction state indicator.* 发送 ReadyForQuery 消息是为了让 FE 知道我们何时处理完查询字符串* 在 3.0 及更高版本中,它还带有事务状态指示器** Note that by flushing the stdio buffer here, we can avoid doing it* most other places and thus reduce the number of separate packets sent.* 请注意,通过在此处刷新 stdio 缓冲区,我们可以避免在大多数其他地方执行此操作,从而减少发送的单独数据包的数量* ----------------*/
void
ReadyForQuery(CommandDest dest)
{switch (dest){case DestRemote:case DestRemoteExecute:case DestRemoteSimple:{StringInfoData buf;pq_beginmessage(&buf, PqMsg_ReadyForQuery);pq_sendbyte(&buf, TransactionBlockStatusCode());pq_endmessage(&buf);}/* Flush output at end of cycle in any case. */pq_flush();break;case DestNone:case DestDebug:case DestSPI:case DestTuplestore:case DestIntoRel:case DestCopyOut:case DestSQLFunction:case DestTransientRel:case DestTupleQueue:case DestExplainSerialize:break;}
}
上面D报文的发送,也就是结果集的发送,这里不再深入介绍。接下来详细看一下client一侧接收这种结果(也即解析D报文)的逻辑,如下:
结果接收
/** parseInput: if appropriate, parse input data from backend* until input is exhausted or a stopping state is reached.* Note that this function will NOT attempt to read more data from the backend.* * parseInput:如果合适,解析来自后端的输入数据* 直到输入耗尽或达到停止状态* 请注意,此函数不会尝试从后端读取更多数据*/
void
pqParseInput3(PGconn *conn)
{char id;int msgLength;int avail;/** Loop to parse successive complete messages available in the buffer.* 循环解析缓冲区中可用的连续完整消息*/for (;;){/** Try to read a message. First get the type code and length. Return* if not enough data.* 尝试读取一条消息。首先获取类型代码和长度。如果数据不足则返回*/...if (id == PqMsg_NotificationResponse){if (getNotify(conn))return;}else if (id == PqMsg_NoticeResponse){if (pqGetErrorNotice3(conn, false))return;}else if (conn->asyncStatus != PGASYNC_BUSY){...}else{/** In BUSY state, we can process everything.*/switch (id){case PqMsg_CommandComplete:if (pqGets(&conn->workBuffer, conn))return;if (!pgHavePendingResult(conn)){conn->result = PQmakeEmptyPGresult(conn,PGRES_COMMAND_OK);if (!conn->result){libpq_append_conn_error(conn, "out of memory");pqSaveErrorResult(conn);}}if (conn->result)strlcpy(conn->result->cmdStatus, conn->workBuffer.data,CMDSTATUS_LEN);conn->asyncStatus = PGASYNC_READY;break;...case PqMsg_DataRow:if (conn->result != NULL &&(conn->result->resultStatus == PGRES_TUPLES_OK ||conn->result->resultStatus == PGRES_TUPLES_CHUNK)){/* Read another tuple of a normal query response *//* 读取正常查询响应的另一个元组 */if (getAnotherTuple(conn, msgLength))return;}else if (conn->error_result ||(conn->result != NULL &&conn->result->resultStatus == PGRES_FATAL_ERROR)){/** We've already choked for some reason. Just discard* tuples till we get to the end of the query.*/conn->inCursor += msgLength;}else{/* Set up to report error at end of query */libpq_append_conn_error(conn, "server sent data (\"D\" message) without prior row description (\"T\" message)");pqSaveErrorResult(conn);/* Discard the unexpected message */conn->inCursor += msgLength;}break;...} /* switch on protocol character */}/* Successfully consumed this message */if (conn->inCursor == conn->inStart + 5 + msgLength){/* trace server-to-client message */if (conn->Pfdebug)pqTraceOutputMessage(conn, conn->inBuffer + conn->inStart, false);/* Normal case: parsing agrees with specified length */conn->inStart = conn->inCursor;}else{/* Trouble --- report it */libpq_append_conn_error(conn, "message contents do not agree with length in message type \"%c\"", id);/* build an error result holding the error message */pqSaveErrorResult(conn);conn->asyncStatus = PGASYNC_READY;/* trust the specified message length as what to skip */conn->inStart += 5 + msgLength;}}
}
如上getAnotherTuple函数负责具体的tuple构造,如下:
// src/interfaces/libpq/fe-protocol3.c/** parseInput subroutine to read a 'D' (row data) message.* We fill rowbuf with column pointers and then call the row processor.* Returns: 0 if processed message successfully, EOF to suspend parsing* (the latter case is not actually used currently).* parseInput 子程序读取“D”(行数据)消息。* * 我们用列指针填充 rowbuf,然后调用行处理器* 返回:如果成功处理消息,则返回 0* 如果暂停解析,则返回 EOF(后一种情况目前实际上未使用)*/
static int
getAnotherTuple(PGconn *conn, int msgLength)
{PGresult *result = conn->result;int nfields = result->numAttributes;const char *errmsg;PGdataValue *rowbuf;int tupnfields; /* # fields from tuple */int vlen; /* length of the current field value */int i;/* Get the field count and make sure it's what we expect */if (pqGetInt(&tupnfields, 2, conn)){/* We should not run out of data here, so complain */errmsg = libpq_gettext("insufficient data in \"D\" message");goto advance_and_error;}if (tupnfields != nfields){errmsg = libpq_gettext("unexpected field count in \"D\" message");goto advance_and_error;}/* Resize row buffer if needed */rowbuf = conn->rowBuf;if (nfields > conn->rowBufLen){rowbuf = (PGdataValue *) realloc(rowbuf,nfields * sizeof(PGdataValue));if (!rowbuf){errmsg = NULL; /* means "out of memory", see below */goto advance_and_error;}conn->rowBuf = rowbuf;conn->rowBufLen = nfields;}/* Scan the fields */for (i = 0; i < nfields; i++){/* get the value length */if (pqGetInt(&vlen, 4, conn)){/* We should not run out of data here, so complain */errmsg = libpq_gettext("insufficient data in \"D\" message");goto advance_and_error;}rowbuf[i].len = vlen;/** rowbuf[i].value always points to the next address in the data* buffer even if the value is NULL. This allows row processors to* estimate data sizes more easily.*/rowbuf[i].value = conn->inBuffer + conn->inCursor;/* Skip over the data value */if (vlen > 0){if (pqSkipnchar(vlen, conn)){/* We should not run out of data here, so complain */errmsg = libpq_gettext("insufficient data in \"D\" message");goto advance_and_error;}}}/* Process the collected row */errmsg = NULL;if (pqRowProcessor(conn, &errmsg))return 0; /* normal, successful exit *//* pqRowProcessor failed, fall through to report it */advance_and_error:...return 0;
}
源码改造实现分析
这里tuple的发送 都是由这里的逻辑进行控制,如下:
sendTuples = (operation == CMD_SELECT ||queryDesc->plannedstmt->hasReturning);
我今天介绍的功能(不能称之为功能)的目的在于:
- 对于大批量查询等返回tuple的语句,D报文的发送 和 解析过程将非常耗时
- 我这里既希望该大SQL执行下去,又期望不产生D报文
- 相关的统计工作 C报文 足矣
基于以上思考,这里修改代码 如下:(切不可当真)
diff --git a/src/backend/executor/execMain.c b/src/backend/executor/execMain.c
index 4d7c92d63c..a1b824545b 100644
--- a/src/backend/executor/execMain.c
+++ b/src/backend/executor/execMain.c
@@ -345,8 +345,7 @@ standard_ExecutorRun(QueryDesc *queryDesc,*/estate->es_processed = 0;- sendTuples = (operation == CMD_SELECT ||
- queryDesc->plannedstmt->hasReturning);
+ sendTuples = ((operation == CMD_SELECT || queryDesc->plannedstmt->hasReturning) && (not_send_tuple == false));if (sendTuples)dest->rStartup(dest, operation, queryDesc->tupDesc);
diff --git a/src/backend/utils/misc/guc_tables.c b/src/backend/utils/misc/guc_tables.c
index 46c258be28..c166768dfe 100644
--- a/src/backend/utils/misc/guc_tables.c
+++ b/src/backend/utils/misc/guc_tables.c
@@ -501,6 +501,7 @@ bool Debug_print_plan = false;bool Debug_print_parse = false;bool Debug_print_rewritten = false;bool Debug_pretty_print = true;
+bool not_send_tuple = false;bool log_parser_stats = false;bool log_planner_stats = false;
@@ -1337,6 +1338,15 @@ struct config_bool ConfigureNamesBool[] =true,NULL, NULL, NULL},
+ {
+ {"not_send_tuple", PGC_USERSET, DEVELOPER_OPTIONS,
+ gettext_noop("Not send tuples for testing."),
+ NULL
+ },
+ ¬_send_tuple,
+ false,
+ NULL, NULL, NULL
+ },{{"log_parser_stats", PGC_SUSET, STATS_MONITORING,gettext_noop("Writes parser performance statistics to the server log."),
diff --git a/src/include/utils/guc.h b/src/include/utils/guc.h
index e4a594b5e8..07123dd83b 100644
--- a/src/include/utils/guc.h
+++ b/src/include/utils/guc.h
@@ -244,6 +244,7 @@ extern PGDLLIMPORT bool Debug_print_plan;extern PGDLLIMPORT bool Debug_print_parse;extern PGDLLIMPORT bool Debug_print_rewritten;extern PGDLLIMPORT bool Debug_pretty_print;
+extern PGDLLIMPORT bool not_send_tuple;extern PGDLLIMPORT bool log_parser_stats;
使用如下:
[postgres@localhost:~/test/bin]$ ./psql
psql (17beta1)
Type "help" for help.postgres=# create table t1 (id int);
2024-05-30 05:10:42.486 PDT [63041] LOG: duration: 2.423 ms
CREATE TABLE
postgres=# insert into t1 select generate_series(1, 10000);
2024-05-30 05:10:50.146 PDT [63041] LOG: duration: 18.665 ms
INSERT 0 10000
postgres=# create table t2 as select * from t1;
2024-05-30 05:10:55.843 PDT [63041] LOG: duration: 15.274 ms
SELECT 10000
postgres=# show not_send_tuple;
2024-05-30 05:10:59.054 PDT [63041] LOG: duration: 0.132 msnot_send_tuple
----------------off
(1 row)postgres=# \o /home/postgres/test/bin/1.txt
postgres=# select * from t1, t2;
2024-05-30 05:12:08.036 PDT [63041] LOG: duration: 45920.595 ms
postgres=# \o
postgres=#
postgres=# set not_send_tuple = on;
2024-05-30 05:15:18.267 PDT [63041] LOG: duration: 0.652 ms
SET
postgres=# \o /home/postgres/test/bin/2.txt
postgres=# select * from t1, t2;
2024-05-30 05:15:42.149 PDT [63041] LOG: duration: 11213.197 ms
postgres=# \o
postgres=#
[postgres@localhost:~/test/bin]$ ls -lht 1.txt
-rw-rw-r--. 1 postgres postgres 1.4G May 30 05:14 1.txt
[postgres@localhost:~/test/bin]$
[postgres@localhost:~/test/bin]$ ls -lht 2.txt
-rw-rw-r--. 1 postgres postgres 17 May 30 05:15 2.txt
[postgres@localhost:~/test/bin]$
[postgres@localhost:~/test/bin]$ cat 2.txt
SELECT 100000000
[postgres@localhost:~/test/bin]$ tail -10 1.txt 9993 | 100009994 | 100009995 | 100009996 | 100009997 | 100009998 | 100009999 | 1000010000 | 10000
(100000000 rows)[postgres@localhost:~/test/bin]$
使用抓包工具,如下:
postgres=# create table t1 (id int);
CREATE TABLE
postgres=# insert into t1 select generate_series(1, 2);
INSERT 0 2
postgres=# create table t2 as select * from t1;
SELECT 2
postgres=# select * from t1, t2;id | id
----+----1 | 11 | 22 | 12 | 2
(4 rows)postgres=# set not_send_tuple = on;
SET
postgres=# select * from t1, t2;
SELECT 4
postgres=#