【云原生】Kubernetes----POD控制器
目录
引言
一、Pod控制器概述
二、Pod控制器的种类
(一)ReplicaSet
(二)Deployment
(三)StatefulSet
(四)DaemonSet
(五)Job
三、使用POD控制器
(一)部署动态PV
(二)使用Deployment控制器
1.创建控制器
2.参考链接
(三)使用StatefulSet控制器
1.主要特性
2.控制器组件
2.1 无头服务
2.2 存储卷申请模板
2.3 StatefulSet
3.示例
3.1 安装CoreDNS
3.2 创建service
3.3 创建StatefulSet
3.4 使用service访问
3.5 删除与创建
4.小结
(四)DaemonSet控制器
1.定义与功能
2.工作原理
3.示例
(五)Job控制器
1.创建job
2.追踪查看执行状况
3.Job的清理
3.应用场景
(六)CronJob控制器
1.基本定义
2.使用Cronjob
引言
在Kubernetes(K8s)的庞大生态系统中,Pod控制器是一个核心组件,它负责管理和控制Pod的生命周期。Pod是Kubernetes中最小的可部署计算单元,而Pod控制器则确保Pod按照预期的状态运行,无论面临何种挑战。本文将深入探讨Pod控制器的概念、种类以及它们是如何工作的。
一、Pod控制器概述
Pod控制器是Kubernetes中用于管理Pod生命周期的组件。它们通过监视和管理Pod的集合来确保Pod始终按照预期运行。当Pod因为某些原因(如节点故障、资源不足等)而失败时,Pod控制器会尝试重新创建Pod,以保持Pod集合的稳定性和可用性。
二、Pod控制器的种类
(一)ReplicaSet
ReplicaSet是Deployment的基础,它直接管理Pod的副本数。ReplicaSet确保在任何时候都有指定数量的Pod副本在运行。它有以下几个特点
1.用户期望的pod副本数量
2.标签选择器,判断哪个pod归自己管理
3.现存的pod数量不足,会根据pod资源模板进行新建
它会帮助用户管理无状态的pod资源,精确反应用户定义的目标数量,但是RelicaSet不是直接使用的控制器,而是使用Deployment
(二)Deployment
Deployment是最常用的Pod控制器之一,建立在ReplicaSet之上,它用于部署无状态应用程序。Deployment定义了Pod的期望副本数,并通过滚动更新和回滚机制来管理Pod的升级和降级。
Deployment还提供了声明式更新和版本控制功能,使得应用程序的升级和回滚变得简单和可靠。
(三)StatefulSet
StatefulSet用于部署有状态应用程序,如有状态数据库或分布式存储系统。StatefulSet为Pod提供了一个稳定的网络标识和持久化存储,确保Pod在重新调度时能够保持其状态。
StatefulSet还提供了有序部署和扩展的功能,使得有状态应用程序的升级和扩展变得更加容易。
(四)DaemonSet
DaemonSet确保在每个节点上运行一个Pod的副本。它通常用于运行守护进程,如系统监控代理、日志收集器等。
DaemonSet中的Pod通常具有节点级别的存储和网络需求,并且需要在每个节点上运行。
(五)Job
Job用于运行一次性任务,如批处理作业或短生命周期的应用程序。Job会创建Pod来执行任务,并在任务完成后删除Pod。
Job还提供了重试和并行执行的选项,使得一次性任务的执行变得更加灵活和可靠。
三、使用POD控制器
(一)部署动态PV
首先部署动态PV,其目的主要是在部署StatefulSet控制器时,它常与 PersistentVolumeClaims一起使用
具体的部署方法,可以访问:【云原生】Kubernetes----PersistentVolume(PV)与PersistentVolumeClaim(PVC)详解-CSDN博客
进行查看
(二)使用Deployment控制器
主要用于管理POD,保证用户的期望值,其建立在ReplicaSet的基础之上
1.创建控制器
[root@master01 pod]#vim deployment.yaml
[root@master01 pod]#cat deployment.yaml
apiVersion: apps/v1 #指定API版本
kind: Deployment #指定创建资源类型为Deployment
metadata: #定义资源的元数据信息name: nginx-deployment #指定资源的名称labels: #设置标签app: nginx #标签以键值表示,标签键为app,标签值为nginx
spec: #定义资源的规格replicas: 3 #指定创建pod数量为3个selector: #选择由Deployment管理的Pod的标签选择器matchLabels: #指定用于匹配的标签app: nginx #设置标签需要与模板标签一致template: #创建pod的模板,deployment管理的pod实例,都由此模板定义metadata: #模板的元数据信息labels: #定义pod的标签app: nginx #此处需要与deployment管理pod的标签选择器一致spec: #pod的规格信息containers: #定义pod中运行的容器列表- name: nginx #指定容器名称image: nginx:1.18.0 #指定镜像版本ports: #定义端口- containerPort: 80 #定义容器内部的监听端口使用命令创建deployment控制器
[root@master01 pod]#kubectl apply -f deployment.yaml
deployment.apps/nginx-deployment created
[root@master01 pod]#kubectl get pod
NAME READY STATUS RESTARTS AGE
nfs-client-provisioner-794bf7886f-85bwb 1/1 Running 0 4h18m
nginx-deployment-67dfd6c8f9-75cqk 1/1 Running 0 9s
nginx-deployment-67dfd6c8f9-8nnjr 1/1 Running 0 9s
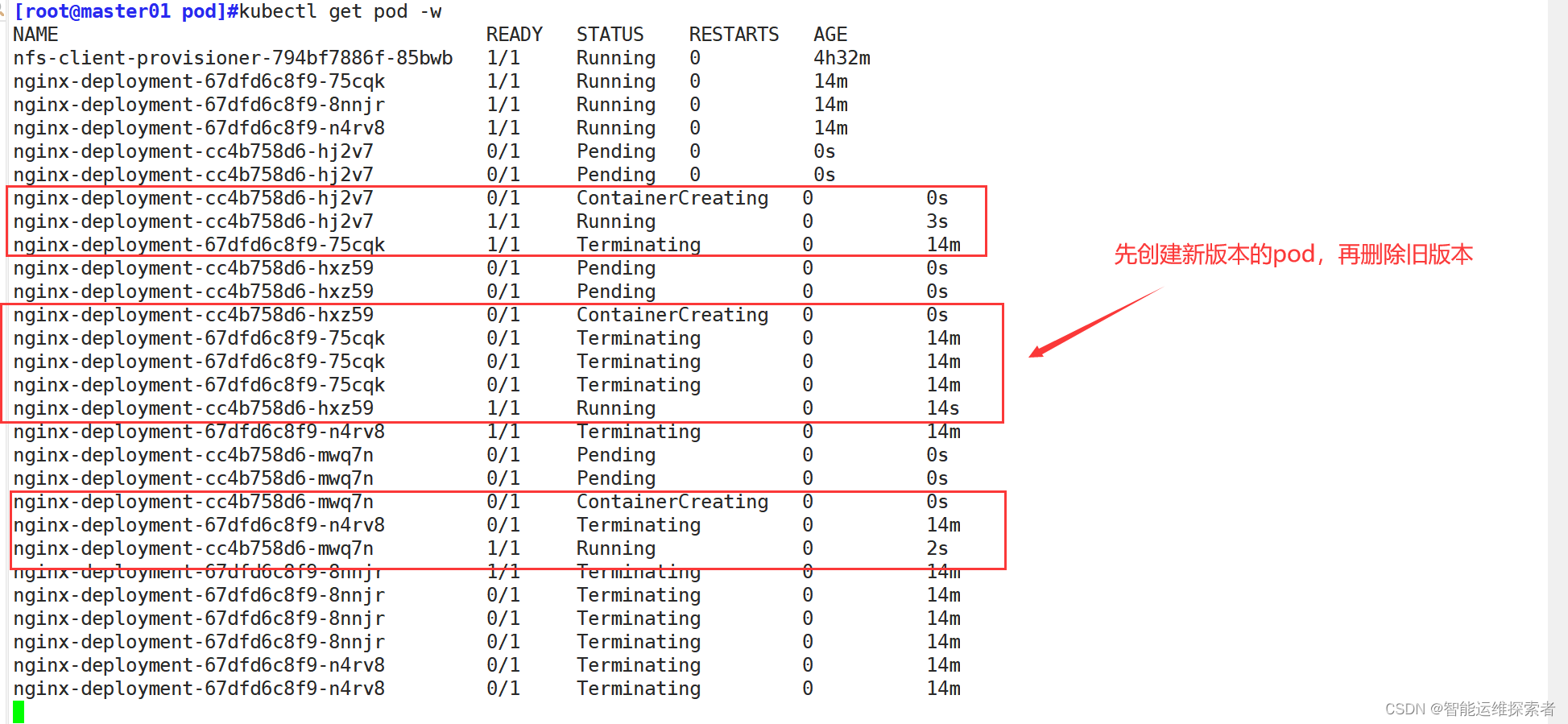
nginx-deployment-67dfd6c8f9-n4rv8 1/1 Running 0 9s----------------------------------------------------------------------------------
第一个pod为基于nfs的动态创建PV的pod
下面三个pod为控制器管理的pod创建deployment控制器后,会根据yaml文件定义的内容,创建三个pod实例

升级时,修改yaml文件,并重新加载即可完成升级
[root@master01 pod]#vim deployment.yaml
......spec:containers:- name: nginximage: nginx:1.20.2 #修改版本
[root@master01 pod]#kubectl apply -f deployment.yaml
deployment.apps/nginx-deployment configured
此控制器在之前的文章中也多次提到,可以访问网站进行详细查看
2.参考链接
官方网站:Deployments | Kubernetes
文章链接:【云原生】kubernetes声明式管理-----YAML文件-CSDN博客
(三)使用StatefulSet控制器
StatefulSet 是 Kubernetes 中的一个资源控制器,它用于管理有状态的应用。与 Deployment 和 ReplicaSet 这样的无状态工作负载不同,StatefulSet 为每个 Pod 提供了一个稳定的、唯一的标识符,并且能够保证 Pod 的部署顺序和终止顺序。
1.主要特性
稳定的标识符:每个Pod都有一个唯一的、持久的标识符,这个标识符在 Pod 的整个生命周期中都是不变的。这使得即使 Pod 被重新调度,其标识符也会保持不变。这一功能常常基于Headless(无头模式,即没有Cluster IP的Service)实现
有序的部署和扩展:Pod 是按照特定的顺序进行创建和扩展(0到N-1)的。这允许应用程序在部署时按照特定的顺序进行初始化。
有序的终止和缩容:当缩容或删除 StatefulSet 时,Pod 会按照相反的顺序(N-1到0)进行终止。这允许应用程序在关闭时按照特定的顺序进行清理。
持久化存储:StatefulSet 常常与 PersistentVolumeClaims(PVCs)一起使用,以提供稳定的存储。即使 Pod 被重新调度,其存储卷也会被保留并重新附加到新的 Pod 上。
2.控制器组件
StatefulSet控制器,主要有以下三个组件
2.1 无头服务
2.1.1 定义
Headless Service(无头服务):用于为Pod资源标识符生成可解析的DNS记录,它是一种特殊类型的Kubernetes服务,它不分配Cluster IP地址。
2.1.2 特点
无Cluster IP:无头服务不分配Cluster IP,因此客户端不能通过服务的Cluster IP地址访问后端Pod,而是直接通过Pod的具体地址进行通信。
DNS解析:Kubernetes的DNS系统会为无头服务生成一条特殊的DNS记录,列出所有关联Pod的IP地址,允许客户端通过域名解析直接获得Pod列表。
适用于状态服务应用:特别适合那些需要直接与特定实例通信的应用场景,如分布式数据库、消息队列等有状态服务。
2.1.3 DNS记录生成
当在Kubernetes中创建一个无头服务时,DNS系统会为该服务生成一条特殊的DNS记录。
这条DNS记录列出了所有与该服务相关联的Pod的IP地址。
命名规则:对于无头服务,Kubernetes会以<service-name>.<namespace>.svc.cluster-domain.example的形式为其分配一个DNS记录。
其中,<service-name>是服务的名称,<namespace>是服务所在的命名空间,svc.cluster-domain.example是集群的DNS后缀。
解析过程:当客户端需要访问无头服务时,它会查询DNS服务器以解析该服务的名称。
DNS服务器会返回与该服务相关联的所有Pod的IP地址列表。客户端可以根据这个IP地址列表直接访问到具体的Pod实例。
当Pod重启后,Kubernetes的控制器会更新这个DNS记录,将新的Pod IP地址添加到列表中
因此,客户端只需要继续解析该服务的DNS名称,即可获得最新的Pod IP地址列表。
应用场景:无头服务的DNS解析方式特别适用于需要直接与Pod实例通信的场景,如有状态应用(StatefulSet)、分布式数据库集群、消息队列等。
2.1.4 在控制器中的作用
Deployment控制器创建的pod一旦重新创建以后,它的IP地址与pod名称都会发生改变,这样当基于IP地址与端口号的访问服务,就会因为地址改变而无法访问,例如MySQL,这时,只需要给pod设定一个固定的pod名称,service的cluster IP设置为None,service只与pod的固定名称进行绑定,而后通过coreDNS去解析service,得到关联的pod的IP地址,这里看不懂没有关系,可以在下面结合示例进行理解
2.2 存储卷申请模板
volumeClaimTemplates(存储卷申请模板):基于静态或动态PV供给方式为Pod资源提供专有的固定存储
大部分有状态副本集都会用到持久存储,比如分布式系统来说,由于数据是不一样的,每个节点都需要自己专用的存储节点。而在 deployment中pod模板中创建的存储卷是一个共享的存储卷,多个pod使用同一个存储卷,而statefulset定义中的每一个pod都不能使用同一个存储卷,由此基于pod模板创建pod是不适应的,这就需要引入volumeClainTemplate,当在使用statefulset创建pod时,会自动生成一个PVC,从而请求绑定一个PV,从而有自己专用的存储卷
其中包括:访问模式、存储大小,动态PV指定storageClassName名称
2.3 StatefulSet
用于管控Pod资源
3.示例
[root@master01 pod]#kubectl delete deployments.apps nginx-deployment
deployment.apps "nginx-deployment" deleted
#删除deployment 控制器3.1 安装CoreDNS
CoreDNS用于提供解析服务与自动发现,使K8S集群能够自动关联Service资源的“名称”和“CLUSTER-IP”,从而达到服务被集群自动发现的目的
使用kubeadm安装或其它一键安装k8s集群的,会默认安装CoreDNS,只有当使用二进制安装的时候,需要手动去安装CoreDNS
k8s集群二进制安装链接:Kubernetes二进制集群部署_kubernetes集群启动-CSDN博客

验证DNS是否可以使用
[root@master01 pod]#kubectl run busybox --image=busybox:1.28 -- sleep 36000
pod/busybox created
#创建一个busybox的pod,该容器提供一些基本的命令,主要用于测试环境
[root@master01 pod]#kubectl get pod busybox
NAME READY STATUS RESTARTS AGE
busybox 1/1 Running 0 4s
[root@master01 pod]#kubectl exec -it busybox sh
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
/ # nslookup kubernetes #测试svc能否正常解析,可以使用kubectl get svc查看有哪些svc
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.localName: kubernetes
Address 1: 10.96.0.1 kubernetes.default.svc.cluster.local
#解析正常,解析kubernetes的地址为10.96.0.1[root@master01 pod]#kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 13d
mydb ClusterIP 10.96.50.193 <none> 80/TCP 5d17h
myservice ClusterIP 10.96.33.11 <none> 80/TCP 5d17h
nginx ClusterIP 10.96.222.66 <none> 80/TCP 3d20h3.2 创建service
StatefulSet 资源依赖于无头模式的service
[root@master01 pod]#vim service.yaml
[root@master01 pod]#cat service.yaml
apiVersion: v1 #指定API版本
kind: Service #创建资源类型为Service
metadata:name: headless-svc #指定service名称labels:app: headless-svc #设置service标签
spec:ports:- port: 80 #service端口name: web #端口名称targetport: 80 #指定流量转发的目标端口,与pod暴露的端口一致clusterIP: None #将clusterIP地址的值设置为None,表示无IP地址,即无头模式selector: #选择管理的标签app: state #此标签需要与StatefulSet控制器管理的pod模板中定义的标签一致type: ClusterIP #设置类型为ClusterIP,此为默认设置,可以省略
创建service
[root@master01 pod]#kubectl apply -f service.yaml
service/headless-svc created
[root@master01 pod]#kubectl get svc headless-svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
headless-svc ClusterIP None <none> 80/TCP 10s3.3 创建StatefulSet
[root@master01 pod]#vim statefulset.yaml
[root@master01 pod]#cat statefulset.yaml
apiVersion: apps/v1
kind: StatefulSet #创建资源类型为StatefulSet
metadata:name: state #指定资源名称
spec:serviceName: headless-svc #指定需要绑定的service名称replicas: 3 #创建pod数量为三个selector: #标签选择器,指定StatefulSet要管理哪些podmatchLabels: #指定标签名称app: state #必须与service中selector定义的标签一致。pod含有此标签的,都会去管理template: #指定pod创建模板metadata:labels:app: state #设置pod标签,与上面标签选择器相同,StatefulSet才会管理spec:containers: #定义pod中运行的容器- name: nginx-pod #应当设置有状态的服务,在此以nginx为例,官方文档有MySQL示例image: nginx:1.18.0 #定义镜像ports:- containerPort: 80 #定义容器监听端口name: web #端口名称volumeMounts: #定义将存储卷卷挂载到指定目录- name: html #指定存储卷名称mountPath: /usr/share/nginx/html #挂载到此目录,此目录为nginx服务的站点目录volumeClaimTemplates: #PVC的请求模板- metadata:name: html #定义PVC的名称annotations:volume.beta.kubernetes.io/storage-class: nfs-client-storageclass
#用于指定存储类的注解。该存储类定义了用于动态卷供应的后端存储类型spec:accessModes: ["ReadWriteOnce"] #指定访问模式为RWOresources:requests:storage: 2Gi #指定存储卷的使用大小创建pod查看
[root@master01 pod]#kubectl apply -f statefulset.yaml
statefulset.apps/state created
[root@master01 pod]#kubectl get statefulsets.apps state
NAME READY AGE
state 2/3 14s
[root@master01 pod]#kubectl get statefulsets.apps state
NAME READY AGE
state 3/3 17s
[root@master01 pod]#kubectl get pod
NAME READY STATUS RESTARTS AGE
busybox 1/1 Running 0 40m
nfs-client-provisioner-794bf7886f-85bwb 1/1 Running 0 5h51m
state-0 1/1 Running 0 25s
state-1 1/1 Running 0 19s
state-2 1/1 Running 0 13s
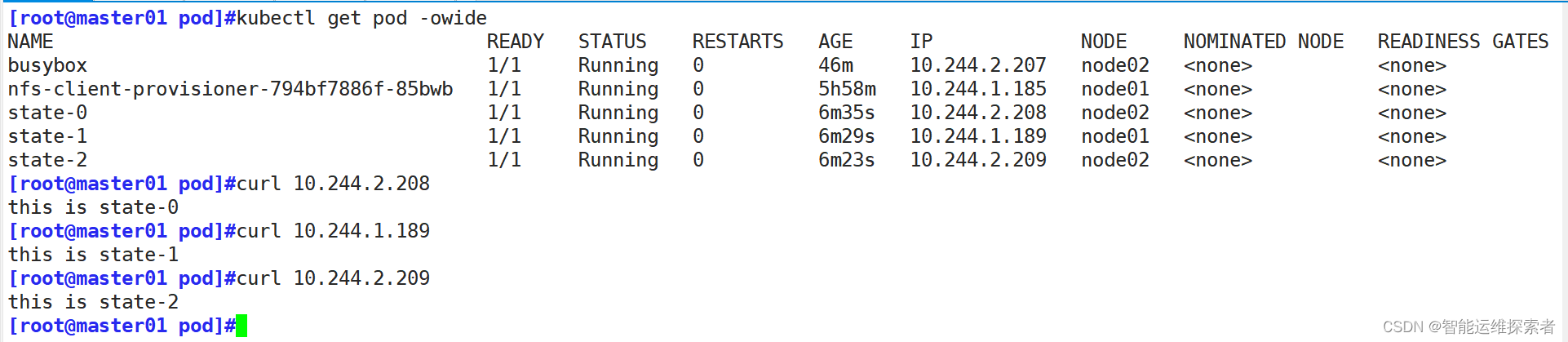
#它会按照0到N-1的顺序去指定pod名称,一定建立,指定pod生命周期结束,否则IP地址改变,它的名称也不会改变创建完之后,查看一下PV与PVC

在NFS服务器上自定义web界面
[root@nfs k8s]#ls
default-html-state-0-pvc-0bffc66c-b29e-40cd-bef5-18c1abe250af #state-0的PV卷
default-html-state-1-pvc-1aaee76c-7c94-4a8d-abc3-0b4f804239bc #state-1的PV卷
default-html-state-2-pvc-f82bb183-c3d8-49b1-be39-c4ee96f7e076 #state-2的PV卷
[root@nfs k8s]#echo "this is state-0" > default-html-state-0-pvc-0bffc66c-b29e-40cd-bef5-18c1abe250af/index.html
[root@nfs k8s]#echo "this is state-1" > default-html-state-1-pvc-1aaee76c-7c94-4a8d-abc3-0b4f804239bc/index.html
[root@nfs k8s]#echo "this is state-2" > default-html-state-2-pvc-f82bb183-c3d8-49b1-be39-c4ee96f7e076/index.html由于没有ClusterIP地址,想要通过IP地址访问,只能在k8s集群中直接访问podIP
3.4 使用service访问
此时,创建的service是可以进行解析的
[root@master01 pod]#kubectl exec -it busybox sh
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
/ # nslookup headless-svc
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.localName: headless-svc
Address 1: 10.244.2.208 state-0.headless-svc.default.svc.cluster.local
Address 2: 10.244.1.189 state-1.headless-svc.default.svc.cluster.local
Address 3: 10.244.2.209 state-2.headless-svc.default.svc.cluster.local
#该service会通过endpoint关联到后端的pod由于pod的IP地址是k8s集群内部的IP地址,且并没有clusterIP去绑定podIP,只有域名管理,宿主机的DNS解析,无法解析k8s集群内部的域名与地址,所以使用宿主机无法访问pod。只能通过创建pod,在pod中进行访问
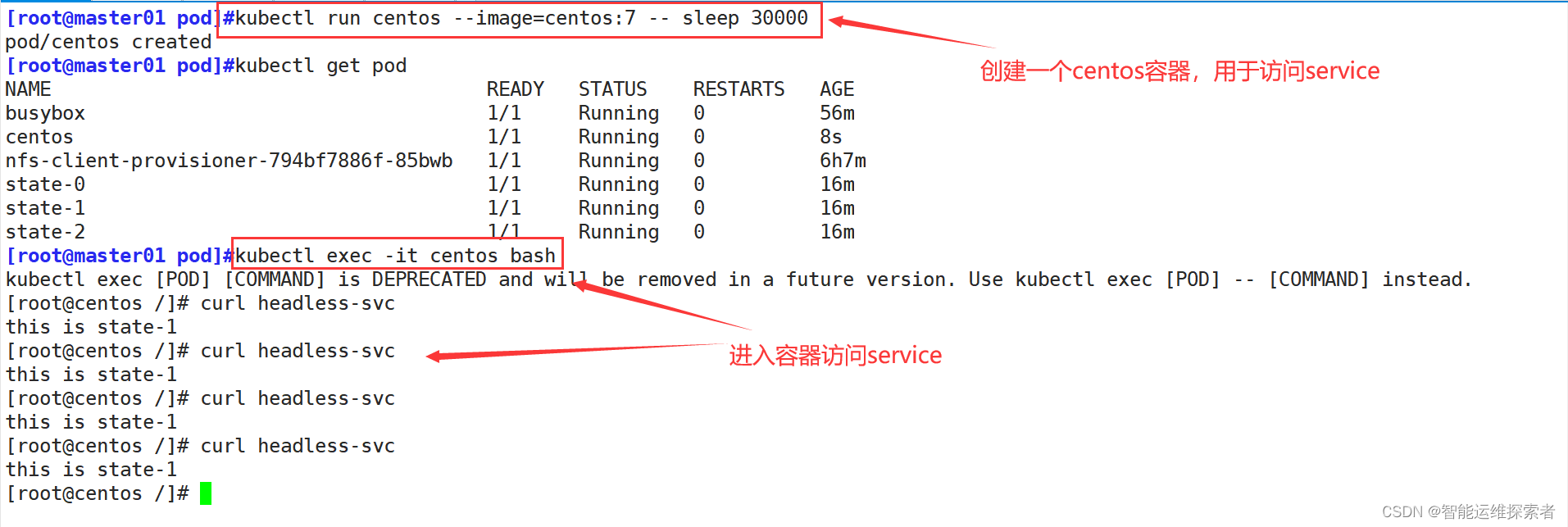
可以看到,访问的pod是随机的,因为k8s内部的负载均衡方式,是通过资源的使用率进行分配的,它会将请求优先分配到资源使用率较少的pod上,可以使用压测工具去测试,而后再进行访问
3.5 删除与创建
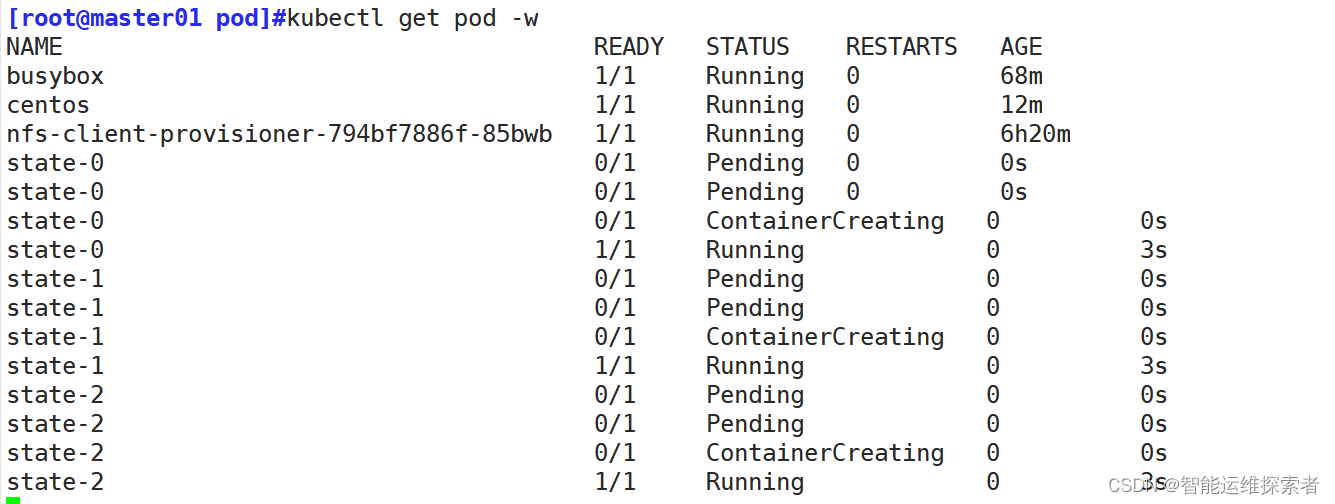
当pod删除时,会按照N-1到0的顺序,倒序删除
[root@master01 pod]#kubectl delete -f statefulset.yaml
statefulset.apps "state" deleted
[root@master01 pod]#kubectl get pod -w
NAME READY STATUS RESTARTS AGE
busybox 1/1 Running 0 65m
centos 1/1 Running 0 9m12s
nfs-client-provisioner-794bf7886f-85bwb 1/1 Running 0 6h16m
state-0 1/1 Running 0 25m
state-1 1/1 Running 0 25m
state-2 1/1 Running 0 25m
state-2 1/1 Terminating 0 25m
state-1 1/1 Terminating 0 25m
state-0 1/1 Terminating 0 25m
state-2 0/1 Terminating 0 25m
state-1 0/1 Terminating 0 25m
state-0 0/1 Terminating 0 25m
state-2 0/1 Terminating 0 25m
state-1 0/1 Terminating 0 25m
state-0 0/1 Terminating 0 25m重新创建的时候,数据会持久化 ,而且创建的顺序还是按照0到N-1的顺序创建
 重新创建之后再次访问,数据不会丢失
重新创建之后再次访问,数据不会丢失
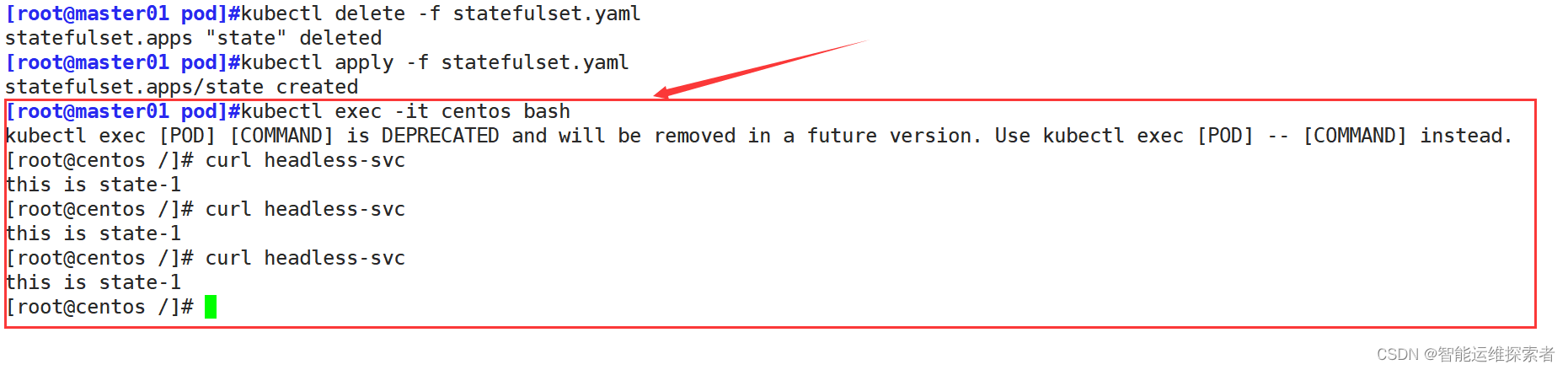
再次解析service的话,它的解析地址会发生改变
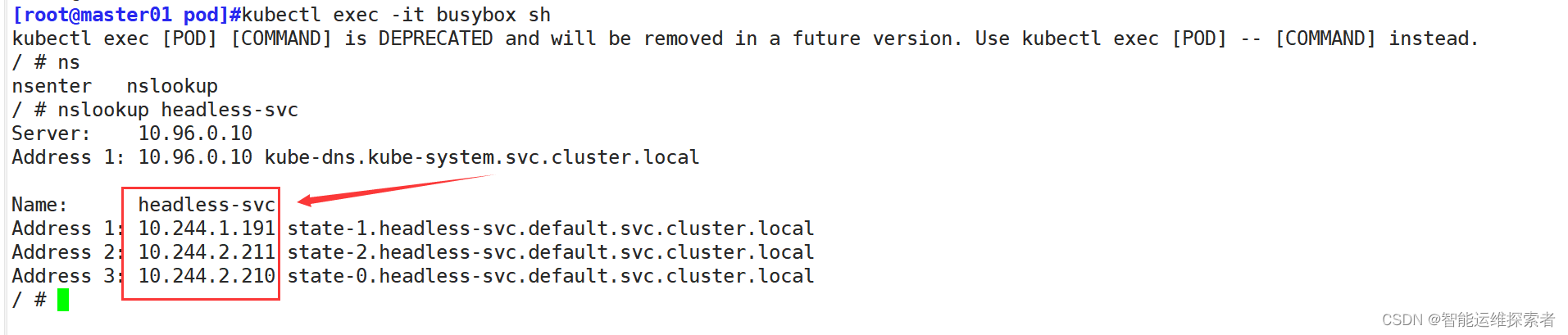
这就是无头模式的作用,不论后端的IP地址如何变化,只通过DNS来解析service,从而绑定后端的IP地址,得到数据
4.小结
StatefulSet控制器的实现,是一个相对复杂的过程,需要大家在平时多练多学,在生成环境中才能避免出现问题,因为StatefulSet管理的都是一些有状态的服务,一旦容器失败,导致数据丢失,可能会造成不好的影响
deployment与statefulset的区别
4.1 应用场景
Deployment:主要用于部署无状态服务,即服务实例之间可以相互替换且不需要保留特定的网络标识或存储数据。它适用于那些不需要关心Pod具体身份且可任意替换的弹性服务。
StatefulSet:适用于部署有状态的服务,比如数据库集群、消息队列等。这些服务需要稳定的持久化存储和唯一、有序的网络标识。StatefulSet为Pod分配的网络标识符和存储都是稳定的,使得应用能够维持跨重启或再调度的持久状态。
4.2 Pod管理
Deployment:通过ReplicaSet确保指定数量的Pod副本始终运行,提供水平扩展和滚动更新能力。Pod由Deployment创建时,虽然可以自定义名称,但通常由系统生成,并在重建或扩展时可能会发生变化。
StatefulSet:Pods在创建、更新和删除时按照顺序进行,以满足那些依赖于严格顺序启动或停止的应用场景需求。每个Pod都有一个固定的、唯一的网络标识符,并且其持久卷声明(PVC)会绑定到持久化的存储,即使Pod被删除后重新创建,存储的数据也会保留。
4.3 存储与网络
Deployment:通常不直接管理Pod的存储和网络,而是依赖于其他Kubernetes资源(如PersistentVolume和Service)来实现这些功能。
StatefulSet:为Pod提供稳定的存储和网络标识,确保有状态应用能够正常运行。StatefulSet通常与Headless Service和volumeClaimTemplate一起使用,以提供可解析的DNS资源记录和专有且固定的存储。
4.4 升级与回滚
Deployment:支持多种升级策略,如滚动更新和回滚,确保服务在整个升级过程中具有高可用性。通过更新Deployment的PodTemplateSpec字段来声明Pod的新状态,并逐步替换旧的Pod。
StatefulSet:也支持有序而自动的滚动更新,但由于涉及到有状态应用,更新过程可能更加复杂和严格。同时,StatefulSet也支持回滚到之前的版本。
4.5 扩展性
Deployment:可以根据系统负载进行水平扩展和缩容,通过调整ReplicaSet的副本数来实现。
StatefulSet:虽然也支持扩展和缩容操作,但由于涉及到有状态应用和数据一致性等问题,扩展性可能相对较弱。
(四)DaemonSet控制器
1.定义与功能
定义:DaemonSet是Kubernetes中的一个API对象,用于确保集群中的每个节点(或某些特定节点)都运行一个Pod的副本。
功能:当节点加入集群时,DaemonSet会自动在该节点上启动Pod;当节点从集群中移除时,DaemonSet也会自动删除该节点上的Pod。
应用场景:
①集群存储守护进程:在每个Node节点上运行。如glusterd、ceph等。
②日志收集守护进程:在每个Node节点上运行日志收集进程。如fluentd、logstash等。
③节点监控守护进程:在每个Node上运行监控。如Prometheus Node Exporter、collectd、Datadog agent等。
④网络插件:在每个节点上运行如Calico、Cilium或Flannel等。
2.工作原理
监听对象:DaemonSet控制器会监听Kubernetes集群中的daemonset对象、pod对象、node对象。
syncLoop循环:当上述被监听的对象发生变动时,DaemonSet控制器会触发syncLoop循环,确保Kubernetes集群朝着daemonset对象描述的状态进行演进
3.示例
[root@master01 pod]#vim daemonset.yaml
[root@master01 pod]#cat daemonset.yaml
apiVersion: apps/v1
kind: DaemonSet #创建资源类型为DaemonSet
metadata:name: nginx-daemonsetlabels:app: nginx
spec:selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: nginx:1.18.0ports:- containerPort: 80创建DaemonSet控制器后,它会在每个节点上运行你指定的pod与定义的容器,它不是根据node节点的资源负载来决定在哪一个node上运行,它会在所有的节点上运行同一个副本
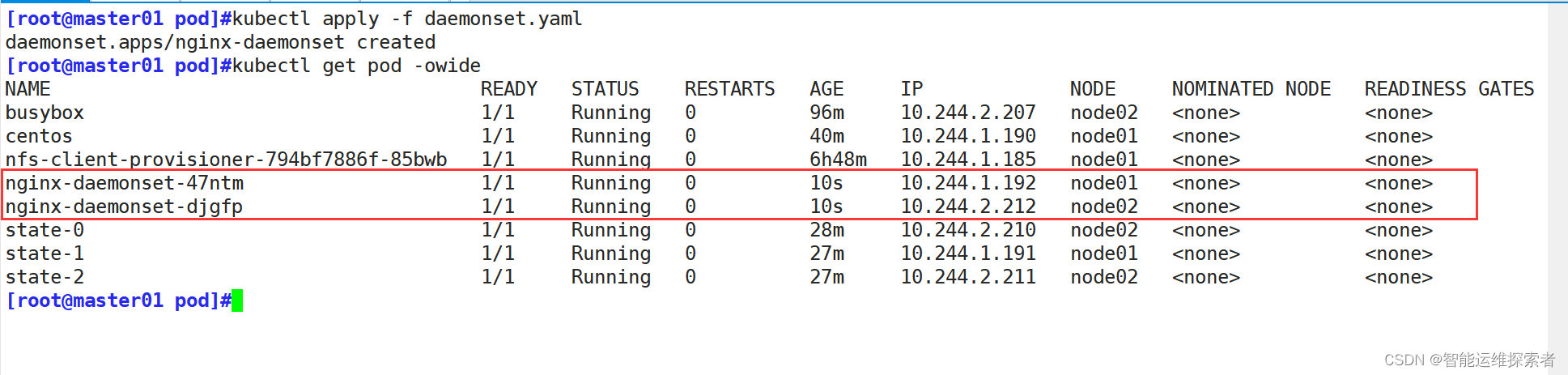
删除DaemonSet控制器时,所有DaemonSet控制器管理的副本也会同时删除
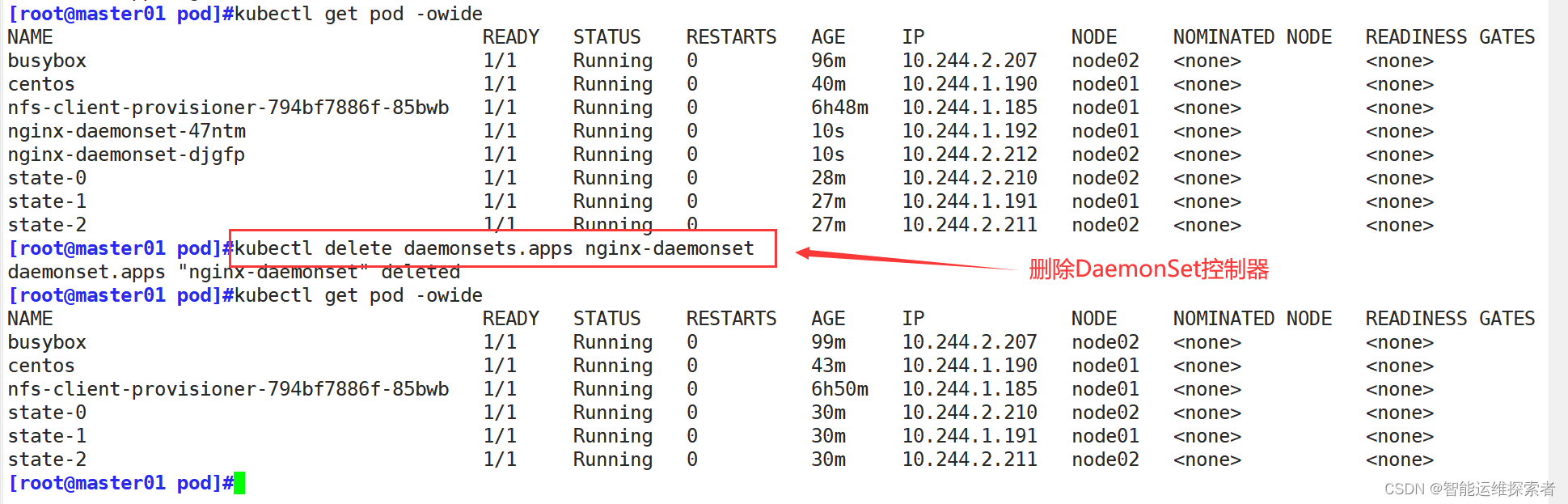
(五)Job控制器
Job控制器是Kubernetes中的一个核心组件,主要用于在集群中运行一次性或批处理任务。Job确保在集群中运行独立的任务,并在任务成功完成后自动终止,不会重启。
它的主要特点包括:
任务执行:Job控制器主要负责批量处理短暂的一次性任务。当任务执行完毕后,Job会自动将Pod的可用数设置为0,并将Pod的状态置为Complete。
任务记录:当Job创建的Pod成功执行完任务后,Job会记录成功结束的Pod数量。当成功结束的Pod数量达到指定的数量时,Job完成执行。
任务重试:Job支持定义任务的重试策略,通过backoffLimit字段指定Job失败后进行重试的次数。
并行任务:Job允许定义多个并行执行的任务,通过parallelism字段指定在任一时刻应该并发运行的Pod数量
[root@master01 pod]#vim job.yaml
[root@master01 pod]#cat job.yaml
apiVersion: batch/v1 #Batch API的第一个稳定版本
kind: Job #指定创建的资源类型是Job
metadata:name: job #资源名称
spec:completions: 5 #指定Job需要成功完成多少个Podparallelism: 3 #并发执行的最大数量,也就是同时运行几个podbackoffLimit: 2 #设置job失败后进行重试的次数template: #定义创建模板spec: #定义job的规格信息restartPolicy: Never #指定重启策略为Never,表示不重启containers:- name: busybox #容器名称image: busybox:1.28 #镜像名称command: ["/bin/sh","-c","for i in 1 2 3 4 5 6 7 8 9;do echo $i ;done"]
#容器内执行的程序,使用for循环打印1-9的数字,此命令执行完毕后,一次性任务结束,退出容器----------------------------------------------------------------------------------
completions:表示执行完指定的pod数量后,job这个一次性计划任务就结束了
parallelism:表示同时运行的pod数量
backoffLimit:用于设置job失败后进行重试的次数,默认值为6。默认情况下,除非Pod失败或容器异常退出Job任务将不间断的重试。一旦达到backoffLimit的值,作业将被标记为失败
restartPolicy:在Job中只能将此属性设置为OnFailure或Never,否则Job将不间断运行1.创建job
[root@master01 pod]#kubectl apply -f job.yaml
job.batch/job created
[root@master01 pod]#kubectl get job
NAME COMPLETIONS DURATION AGE
job 5/5 4s 8s--------------------------------------------------------------
NAME:Job的名称。
COMPLETIONS:这个字段显示了Job的完成情况。它由两部分组成:已完成的Pod数量:表示已经有5个Pod成功完成了任务。期望完成的Pod数量:表示这个Job期望有5个Pod成功完成。
DURATION:Job从开始到结束所花费的时间。表示Job在4秒内完成了所有的任务。
AGE:Job创建到现在的时间[root@master01 pod]#kubectl get pod
NAME READY STATUS RESTARTS AGE
job-5pcrc 0/1 Completed 0 98s
job-6wwtm 0/1 Completed 0 100s
job-cd8jq 0/1 Completed 0 100s
job-gdgbq 0/1 Completed 0 98s
job-rlpsr 0/1 Completed 0 100s
#执行完完毕之后,Completed正常退出2.追踪查看执行状况
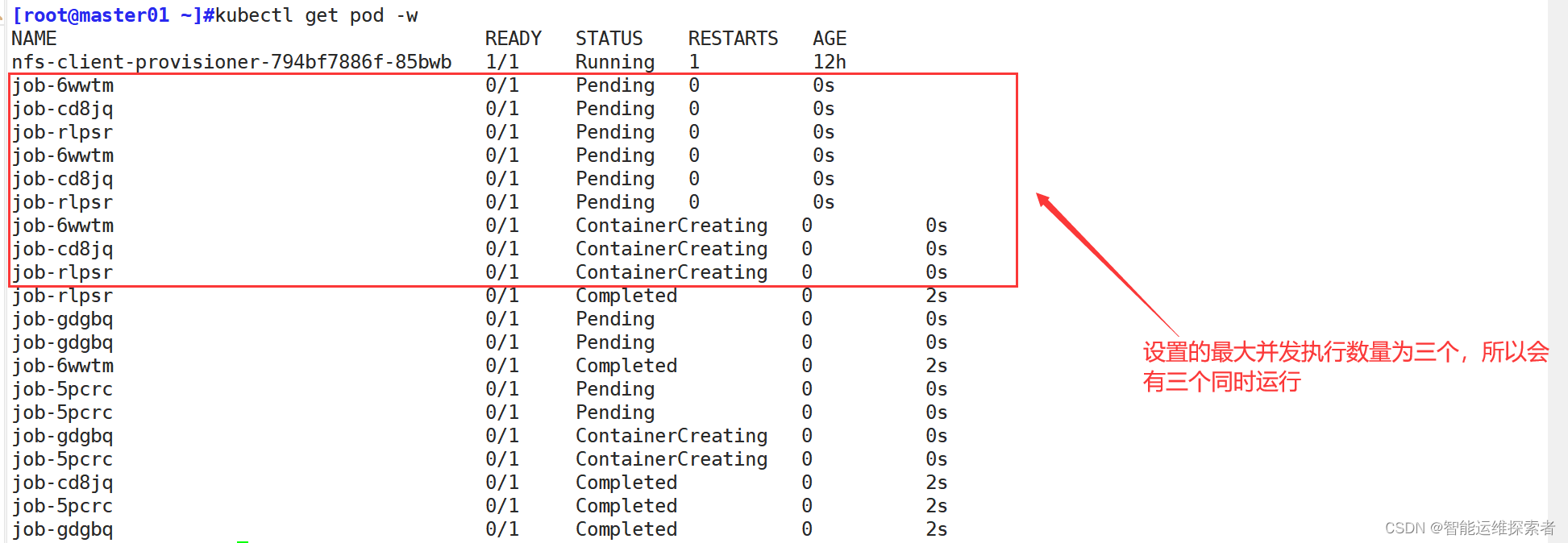
使用logs参数,查看执行结果
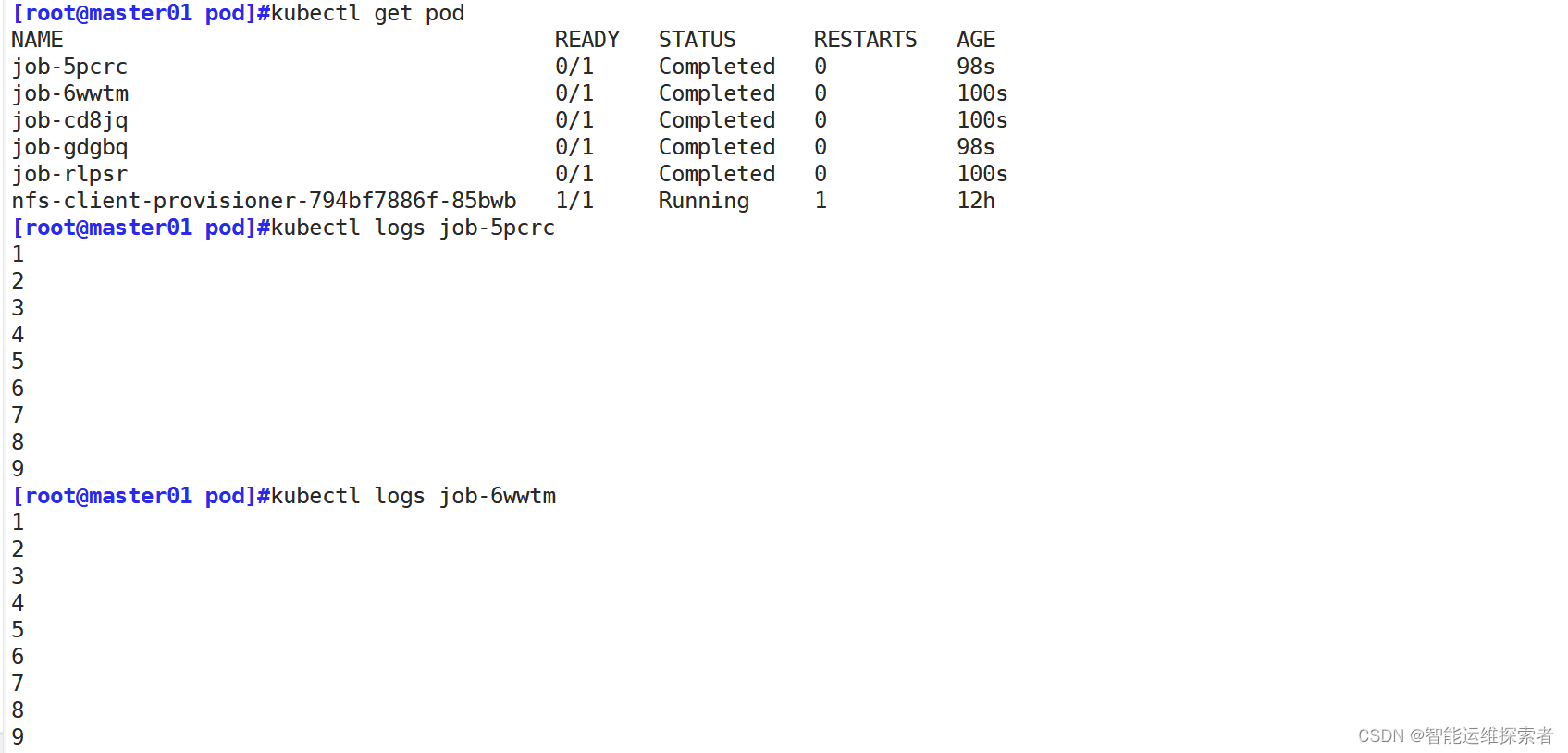
3.Job的清理
当你的 Job 已结束时,将 Job 保留在 API 中(而不是立即删除 Job)很有用, 这样你就可以判断 Job 是成功还是失败。
可以手动清理job资源,使用kubectl delete命令删除
[root@master01 pod]#kubectl get job
NAME COMPLETIONS DURATION AGE
job 5/5 4s 28m
[root@master01 pod]#kubectl delete -f job.yaml
job.batch "job" deleted
[root@master01 pod]#kubectl get job
No resources found in default namespace.
[root@master01 pod]#kubectl get pod
NAME READY STATUS RESTARTS AGE
nfs-client-provisioner-794bf7886f-85bwb 1/1 Running 1 12hKubernetes TTL-after-finished 控制器提供了一种 TTL 机制来限制已完成执行的 Job 对象的生命期
ttlSecondsAfterFinished 字段在 Kubernetes 1.21 版本中作为 alpha 特性被引入。在 kube-apiserver 的启动参数中设置
[root@master01 pod]#vim /etc/kubernetes/manifests/kube-apiserver.yaml
......
spec:containers:- command:- kube-apiserver- --feature-gates=TTLAfterFinished=true
......[root@master01 ~]#kubectl explain job.spec.ttlSecondsAfterFinished
KIND: Job
VERSION: batch/v1FIELD: ttlSecondsAfterFinished <integer>DESCRIPTION:ttlSecondsAfterFinished limits the lifetime of a Job that has finishedexecution (either Complete or Failed). If this field is set,ttlSecondsAfterFinished after the Job finishes, it is eligible to beautomatically deleted. When the Job is being deleted, its lifecycleguarantees (e.g. finalizers) will be honored. If this field is unset, theJob won't be automatically deleted. If this field is set to zero, the Jobbecomes eligible to be deleted immediately after it finishes. This field isalpha-level and is only honored by servers that enable the TTLAfterFinishedfeature.
----------------------------------------------------------------------------------
ttlSecondsAfterFinished 是 Kubernetes Job 资源中的一个可选字段,用于指定 Job 在完成
后(无论是成功完成还是失败)可以保留的时间长度(以秒为单位)。这个字段允许你设置一个时间限制
,在该时间限制之后,Kubernetes 系统会自动删除已完成的 Job。具体来说:
如果ttlSecondsAfterFinished字段被设置了,那么在Job完成后,经过指定的秒数,该Job会成为自动删除的候选对象。
当Kubernetes系统删除Job时,会尊重Job的生命周期保证(例如finalizers)。
如果ttlSecondsAfterFinished字段未设置,那么Job将不会自动删除。
如果ttlSecondsAfterFinished字段被设置为0,那么Job会在完成后立即成为自动删除的候选对象使用TTL清理,使用1.28版本的k8s集群
[root@master01 opt]#kubectl version
Client Version: v1.28.2
Kustomize Version: v5.0.4-0.20230601165947-6ce0bf390ce3
Server Version: v1.28.2
[root@master01 opt]#vim job.yaml
[root@master01 opt]#cat job.yaml
apiVersion: batch/v1
kind: Job
metadata:name: busybox
spec:template:spec:containers:- name: busyboximage: busybox:1.28command: ["/bin/sh", "-c", "sleep 10;date;exit"]restartPolicy: NeverbackoffLimit: 2ttlSecondsAfterFinished: 10 #容器不论是失败还是成功,10秒钟之后删除
[root@master01 opt]#kubectl apply -f job.yaml
job.batch/busybox created
[root@master01 opt]#kubectl get job -w
NAME COMPLETIONS DURATION AGE
busybox 0/1 5s 5s
busybox 0/1 13s 13s
busybox 0/1 14s 14s
busybox 1/1 14s 14s
busybox 1/1 14s 24s
busybox 1/1 14s 24s追踪pod查看
[root@master01 opt]#kubectl get pod -w
NAME READY STATUS RESTARTS AGE
busybox-llg27 0/1 Pending 0 0s
busybox-llg27 0/1 Pending 0 0s
busybox-llg27 0/1 ContainerCreating 0 0s
busybox-llg27 0/1 ContainerCreating 0 1s
busybox-llg27 1/1 Running 0 1s
busybox-llg27 0/1 Completed 0 12s
busybox-llg27 0/1 Completed 0 14s
busybox-llg27 0/1 Completed 0 14s
busybox-llg27 0/1 Completed 0 14s
busybox-llg27 0/1 Completed 0 14s
busybox-llg27 0/1 Terminating 0 24s #退出后10秒钟后进行删除
busybox-llg27 0/1 Terminating 0 24s
[root@master01 opt]#kubectl get pod
No resources found in default namespace.
[root@master01 opt]#kubectl get job
No resources found in default namespace.
3.应用场景
Job常用于运行那些仅需要执行一次的任务
批处理作业
Kubernetes Job主要被用于执行一次性批处理作业,如每日数据分析、事务处理等。
数据迁移和清理
Job可以用来定时迁移大量数据,以及维护数据库
后台任务
Job可以用来执行后台任务,如计算任务、日志采集等
日志打包和压缩
例如按时间段打包日志文件、将多个日志文件压缩成一个文件等。
备份和恢复操作
例如备份数据库、配置文件等,并将其存储到云存储服务中以便后续恢复
其它应用场景
kube-bench扫描、离线数据处理,视频解码等业务
(六)CronJob控制器
1.基本定义
在Kubernetes中,CronJob控制器用于运行定时任务,例如备份、生成报告等。这些任务在指定的时间周期上自动执行。一个 CronJob 对象就像 Unix 系统上的 crontab(cron table)文件中的一行,使用Cron格式进行编写, 并周期性地在给定的调度时间执行Job。它在Kubernetes集群上运行的,可以管理多个Pod。
一个CronJob对象包含以下主要部分:
metadata:包含CronJob的名称、命名空间、标签和注解等。
spec:定义CronJob的规格。
schedule:一个符合cron格式的字符串,指定任务运行的时间表。与Linux系统中的crontab类似。* * * * *,表示分、时、日、月、周
jobTemplate:描述要运行的Job的模板。Job模板中的spec字段与标准的Job资源中的spec字段非常相似。
startingDeadlineSeconds(可选):如果由于某种原因(例如,由于系统资源不足)而错过了预定的启动时间,则此字段指定在开始失败之前允许错过的秒数。
concurrencyPolicy(可选):定义当多个Job同时被触发时应该如何处理。可以是"Allow"(允许同时运行)、"Forbid"(禁止同时运行,并跳过后续运行)或"Replace"(取消当前正在运行的Job并开始新的一个)。
suspend(可选):如果设置为true,则不会按照时间表启动新的Job
successfulJobsHistoryLimit 和 failedJobsHistoryLimit(可选):分别指定要保留的成功和失败Job的历史记录的最大数量。
2.使用Cronjob
[root@master01 pod]#vim cronjob.yaml
[root@master01 pod]#cat cronjob.yaml
apiVersion: batch/v1beta1 #设置版本为v1beta1
kind: CronJob #指示这是一个CronJob资源
metadata:name: cronjob #CronJob的名称
spec:schedule: "*/1 * * * *" #定义执行周期,此处表示每一分钟执行一次jobTemplate: #定义Job模板spec:template: #Pod模板spec:containers: #定义容器列表- name: echo #定义容器名称image: busybox:1.28command: #定义容器启动后要执行的命令 - /bin/sh- -c- date; echo this is busybox1.28 #在容器内执行date命令后,并输出指定信息restartPolicy: OnFailure #容器重启策略,非0状态则会重启,正常退出不重启----------------------------------------------------------------------------------
Kubernetes集群版本较旧,并且不支持batch/v1 API版本,需要使用batch/v1beta1 API版本指定文件创建Cronjob后,Kubernetes将创建一个名为cronjob的CronJob,并且每分钟都会按照定义运行一个新的Job
[root@master01 pod]#kubectl apply -f cronjob.yaml
cronjob.batch/cronjob created
[root@master01 pod]#kubectl get cronjobs
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
cronjob */1 * * * * False 0 <none> 3s
[root@master01 pod]#kubectl get jobs -w
NAME COMPLETIONS DURATION AGE
cronjob-1717083300 0/1 0s
cronjob-1717083300 0/1 0s 0s
cronjob-1717083300 1/1 2s 2s
cronjob-1717083360 0/1 0s
cronjob-1717083360 0/1 0s 0s
cronjob-1717083360 1/1 2s 2s
cronjob-1717083420 0/1 0s
cronjob-1717083420 0/1 0s 0s
cronjob-1717083420 1/1 3s 3s查看pod
[root@master01 pod]#kubectl get pod
NAME READY STATUS RESTARTS AGE
cronjob-1717083420-jw52p 0/1 Completed 0 2m30s
cronjob-1717083480-j87gz 0/1 Completed 0 89s
cronjob-1717083540-dz2hs 0/1 Completed 0 28s
nfs-client-provisioner-794bf7886f-85bwb 1/1 Running 3 13h
[root@master01 pod]#kubectl logs cronjob-1717083420-jw52p
Thu May 30 15:37:10 UTC 2024
this is busybox1.28
[root@master01 pod]#kubectl logs cronjob-1717083480-j87gz
Thu May 30 15:38:11 UTC 2024
this is busybox1.28
[root@master01 pod]#kubectl logs cronjob-1717083540-dz2hs
Thu May 30 15:39:12 UTC 2024
this is busybox1.28
#每隔一分钟执行一次,可能会加一两秒左右的容器创建时间# 查看CronJob的状态
kubectl get cronjobs
# 查看CronJob的详细信息
kubectl describe cronjobs cronjob
# 查看由CronJob创建的Job列表
kubectl get jobs
# 查看特定Job的详细信息
kubectl describe job <job-name>