人脸识别系统之动态人脸识别
二.动态人脸识别
1.摄像头人脸识别
1.1.导入资源包
import dlib
import cv2
import face_recognition
from PIL import Image, ImageTk
import tkinter as tk
import os
注:这些导入语句允许您在代码中使用这些库和模块提供的功能,例如创建图形用户界面、处理文件、进行图像处理和人脸识别等。
Dlib:是一个开源的机器学习库,包含了许多常用的机器学习算法。它还包含了一个名为shape_predictor的模块,用于检测人脸的关键点。
1.2.初始化摄像头
# 初始化摄像头
cap = cv2.VideoCapture(0)
#参数0指定要使用的摄像头设备。在大多数情况下,0表示默认摄像头。
注:这行代码初始化了摄像头,并将其作为cap对象返回。cv2.VideoCapture(0)中的0参数通常表示默认摄像头。这行代码是用于从摄像头上捕获实时视频流。
1.3.创建主窗口
root = tk.Tk()
root.title("人脸识别程序")
root.geometry('600x600')
注:这段代码通常用于创建一个Tkinter窗口,并为其设置一个标题和一个初始大小。在后续的代码中,您可以添加更多的组件,如按钮、标签、图像等,来构建图形用户界面。
1.4.创建画布
# 创建画布
canvas = tk.Canvas(root, width=600, height=600)
canvas.pack()
注:这段代码首先导入了 Tkinter 模块,并创建了一个名为 root 的窗口。然后,它创建了一个画布(canvas),并设置了其宽度和高度。最后,它将画布添加到窗口中,并启动了 Tkinter 的主循环,这样窗口才会显示出来。
1.5.显示摄像头部分
# 摄像头画面显示部分
camera_frame = tk.Label(root)
camera_frame.place(x=50, y=50, width=400, height=400)
注:这段代码创建了一个 Label 对象,并将其放置在窗口(root)的坐标 (50, 50) 处,大小为 400x400。然而,由于 Label 控件本身不支持显示动态内容,如摄像头捕获的帧,您需要使用其他方法(如前面提到的 Canvas 控件和 PIL/Pillow 库)来显示摄像头画面。
1.6.显示文本
# 文本显示部分
text_label = tk.Label(root, text="", font=('Helvetica', 12))
text_label.place(x=50, y=460, width=500, height=100)
注:这段代码创建了一个 Label 对象,并将其放置在窗口(root)的坐标 (50, 460) 处,大小为 500x100。标签的初始文本内容为空,字体为 Helvetica 字体,字号为 12。
1.7.按钮的点击事件处理函数
# 按钮部分
def capture_face():ret, frame = cap.read()if ret:# 将人脸图像转换为RGBrgb_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)# 检测人脸位置face_locations = face_recognition.face_locations(rgb_frame)# 如果检测到人脸if face_locations:# 对检测到的人脸进行编码face_encoding = face_recognition.face_encodings(rgb_frame, face_locations)[0]# 加载已保存的人脸编码known_face_encodings = []known_face_names = []for file in os.listdir("facecomparison"):image = face_recognition.load_image_file(f"facecomparison/{file}")encoding = face_recognition.face_encodings(image)[0]known_face_encodings.append(encoding)known_face_names.append(file)# 比较当前人脸与已知人脸matches = face_recognition.compare_faces(known_face_encodings, face_encoding)if True in matches:text_label.config(text="该人脸已存在,请勿重复录入")else:# 裁剪人脸图像top, right, bottom, left = face_locations[0]face_image = frame[top:bottom, left:right]# 生成唯一的文件名unique_filename = f"facecomparison/face_{len(os.listdir('facecomparison')) + 1}.jpg"# 保存人脸到指定文件夹cv2.imwrite(unique_filename, face_image)text_label.config(text="人脸已录入")else:text_label.config(text="未检测到人脸")else:text_label.config(text="无法从摄像头读取帧")
注:这段代码的作用是实现一个面部识别系统,该系统能够从摄像头捕获实时帧,检测帧中的人脸,并将新检测到的人脸与已保存的人脸编码进行比较。如果新检测到的人脸与已保存的人脸匹配,它会显示一个消息,告知用户该人脸已存在,不应该重复录入。如果新检测到的人脸与已保存的人脸不匹配,它会将新的人脸图像保存到指定的文件夹中,并显示一个消息,告知用户人脸已录入。如果无法从摄像头读取帧,或者没有检测到人脸,它会显示相应的错误消息。
1.8.识别摄像头捕获的人脸
def recognize_face():# 识别摄像头捕获的人脸ret, frame = cap.read()if ret:frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)rgb_frame = frame.copy()face_locations = face_recognition.face_locations(rgb_frame)face_encodings = face_recognition.face_encodings(rgb_frame, face_locations)# 加载已保存的人脸编码和文件名known_face_encodings = []known_face_names = []for file in os.listdir("facecomparison"):image = face_recognition.load_image_file(f"facecomparison/{file}")encoding = face_recognition.face_encodings(image)[0]known_face_encodings.append(encoding)known_face_names.append(file)# 标记人脸并显示信息for (top, right, bottom, left), face_encoding in zip(face_locations, face_encodings):matches = face_recognition.compare_faces(known_face_encodings, face_encoding)if True in matches:first_match_index = matches.index(True)text_label.config(text=f"识别到人脸,人脸属于:{known_face_names[first_match_index]}")else:cv2.rectangle(frame, (left, top), (right, bottom), (255, 0, 0), 2) # 使用蓝色线条画框cv2.putText(frame, "新的人脸", (left + 10, top + 20), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 0, 0), 1)text_label.config(text="人脸不存在,请先录入人脸")# 更新画布image = Image.fromarray(frame)image = ImageTk.PhotoImage(image)camera_frame.configure(image=image)camera_frame.image = imageelse:text_label.config(text="无法从摄像头读取帧")
注:这段代码是一个函数,当按钮被点击时,它会执行这个函数。这个函数的作用是识别摄像头捕获的实时帧中的人脸,并与已保存的人脸编码进行比较,以确定是否已存在。如果人脸存在,它会标记并显示该人脸的名称;如果人脸不存在,它会标记新的人脸并提示用户先录入人脸。
1.9.点击关闭程序的按钮
def close_program():
#关闭 Tkinter 应用程序root.quit()
#释放摄像头(cap)资源cap.release()
注:当用户点击关闭程序的按钮时,这两个操作会确保 Tkinter 应用程序和摄像头资源都能被正确地关闭和释放,从而避免资源泄漏和潜在的系统问题。
1.10.创建按钮
button1 = tk.Button(root, text="录入人脸", command=capture_face, width=10, height=2)
button1.place(x=460, y=50, width=100, height=100)button2 = tk.Button(root, text="识别人脸", command=recognize_face, width=10, height=2)
button2.place(x=460, y=200, width=100, height=100)button3 = tk.Button(root, text="结束程序", command=close_program, width=10, height=2)
button3.place(x=460, y=350, width=100, height=100)
注:这三行代码分别创建了三个按钮,并设置了它们的位置、大小和功能,当用户点击这些按钮时,会触发相应的函数执行。
1.11.更新摄像头的画面
# 更新摄像头画面的函数
def update_image():ret, frame = cap.read()if ret:frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)face_locations = face_recognition.face_locations(frame)for (top, right, bottom, left) in face_locations:cv2.rectangle(frame, (left, top), (right, bottom), (0, 255, 0), 2) # 使用绿色线条画框image = Image.fromarray(frame)image = ImageTk.PhotoImage(image)camera_frame.configure(image=image)camera_frame.image = imageroot.after(10, update_image)# 开始更新画面
update_image()# 主循环
root.mainloop()# 释放摄像头
cap.release()
注:这段代码的作用是在 Tkinter 窗口(root)中创建一个循环,用于从摄像头捕获实时帧,并在窗口中显示这些帧。这个循环会在每次捕获新帧后立即更新显示的图像。
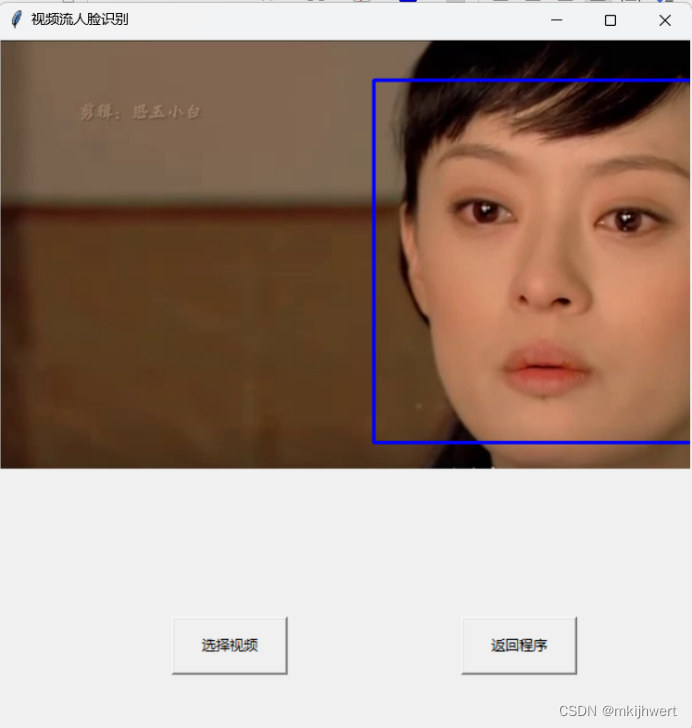
运行结果:

2.视频流人脸识别
2.1.导入资源包
import tkinter as tk
from tkinter import filedialog
from PIL import Image, ImageTk
import cv2
import os
import subprocess
from pathlib import Path
注:导入了所需的模块,这些模块将用于创建一个图形用户界面 (GUI) 应用程序,该应用程序可以处理图像文件、使用摄像头、执行命令行操作等。
cv2:这是 OpenCV 模块,用于处理图像和视频,包括摄像头捕捉、图像处理、特征检测等。os:这是 Python 的标准库,用于操作文件和目录,例如创建目录、删除文件、获取文件路径等。
pathlib:这是 Python 的标准库,用于处理文件和目录路径,提供了一个面向对象的接口,可以更方便地处理路径。
2.2.创建界面窗口
# 初始化窗口
win = tk.Tk()
win.title('视频流人脸识别')
win.geometry('600x600')
#创建了一个字体对象 title_font,用于设置标题的字体、大小和样式。title_font = ("Verdana", 20, 'italic')
注:这段代码创建了一个名为 “视频流人脸识别” 的窗口,窗口的初始大小为 600x600 像素,并准备了一个斜体字体的对象,用于后续设置窗口标题的字体。
2.3.创建视频播放框架
# 视频播放框架
video_frame = tk.Frame(win, width=300, height=300, bg='black')
video_frame.pack()
#将 video_frame 框架放置在窗口中
注:这段代码创建了一个视频播放框架,并将其放置在窗口中,设置其大小为 300x300 像素,背景颜色为黑色。这个框架可以用来显示摄像头捕捉的实时帧或视频文件。
在视频播放框架 video_frame 中创建一个画布
# 视频播放的Canvas
canvas = tk.Canvas(video_frame, width=900, height=900)
canvas.pack(side=tk.TOP, anchor=tk.CENTER)
注:这段代码创建了一个画布,并将其放置在视频播放框架中,设置其大小为 900x900 像素。这个画布可以用来显示摄像头捕捉的实时帧或视频文件。
2.5. 加载人脸识别预训练的模型
# 加载人脸识别的预训练模型
face_cascade=cv2.CascadeClassifier(cv2.data.haarcascades+'haarcascade_frontalface_default.xml')
注:这段代码创建了一个名为 face_cascade 的级联分类器对象,用于检测图像或视频帧中的人脸。OpenCV 提供了许多预训练的级联分类器,包括正面人脸检测、眼睛检测等,这些分类器可以提高检测的准确性和效率。
2.6.人脸检测
# 人脸检测函数
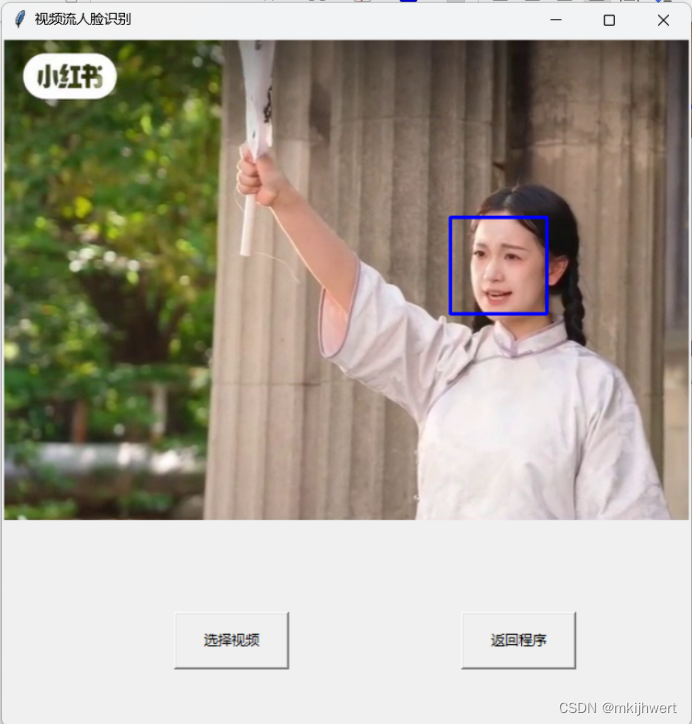
def detect_faces(frame):gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)faces = face_cascade.detectMultiScale(gray, 1.3, 5)for (x, y, w, h) in faces:cv2.rectangle(frame, (x, y), (x+w, y+h), (255, 0, 0), 2)return frame, faces
注:这个函数通过级联分类器在输入图像中检测人脸,并在图像上标记出这些人脸,以便进一步的处理或显示。
1.3:是尺度缩放因子,用于调整检测窗口大小。
5:是邻域内像素的最低匹配数,用于确定检测到的候选框是否真正是人脸。
2.7.在循环外部创建全局的PhotoImage对象
# 在循环外部创建全局的PhotoImage对象
imgtk = None
注:在 Tkinter 中,PhotoImage 是一个用于在 Tkinter 控件中显示图像的类。当您创建一个 PhotoImage 对象时,它会占用一些内存来存储图像数据。如果您在循环中创建多个 PhotoImage 对象,并且循环会多次迭代,那么每次迭代都会创建一个新的对象,这将导致内存占用逐渐增加。为了避免这种情况,您可以创建一个全局的 PhotoImage 对象,并在循环中使用它。这样做的好处是,无论循环迭代多少次,都只会有一个 PhotoImage 对象在内存中。
2.8.定义播放视频的函数
# 播放视频的函数
def play_video():global imgtkvideo_path = filedialog.askopenfilename(title='选择视频', filetypes=[('视频文件', '*.mp4')])if video_path:cap = cv2.VideoCapture(video_path)while cap.isOpened():ret, frame = cap.read()if ret:frame, faces = detect_faces(frame)display_frame(frame)else:breakcap.release()
#在循环后释放视频文件资源
注:这个函数允许用户选择一个视频文件,并播放该视频。在播放过程中,它将视频帧显示在窗口中,并使用人脸检测算法检测帧中的人脸。
2.9.在 Tkinter 窗口的画布上显示图像帧。
#定义了一个函数 display_frame,它接受一个名为 frame 的参数,该参数是一个表示图像的 NumPy 数组。
def display_frame(frame):global imgtkif imgtk:canvas.delete(imgtk)imgtk = Noneframe = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)img = Image.fromarray(frame)imgtk = ImageTk.PhotoImage(image=img)
#在画布上创建图像canvas.create_image(0, 0, anchor=tk.NW, image=imgtk)
#更新image属性canvas.image = imgtk
#更新窗口状态win.update_idletasks()win.update()
注:这个函数负责将处理后的图像帧转换为 Tkinter 可以显示的格式,并在画布上显示这些帧。
2.10.让用户选择要查看的人脸图片,并在图像上显示这些图片
def view_faces():directory = 'C:/Users/HUAWEI/Desktop/机器学习的人脸识别/机器学习的人脸识别/动态人脸识别/视频流人脸识别/保存图片'[os.path.join(directory, f) for f in os.listdir(directory) if f.endswith('.jpg')]face_paths = filedialog.askopenfilenames(title='查看人脸', initialdir=directory, filetypes=[('图片文件', '*.jpg')])if face_paths:for face_path in face_paths:img = cv2.imread(face_path)if img is not None:cv2.imshow('Face', img)cv2.waitKey(0)cv2.destroyAllWindows()else:print(f"无法加载图片: {face_path}")
注:这行代码检查用户是否选择了图片文件。如果选择了,它将遍历用户选择的图片文件,并使用 cv2.imread() 函数尝试读取每个图片文件。如果成功读取,它将使用 cv2.imshow() 函数在窗口中显示图片,并使用 cv2.waitKey(0) 函数等待用户按键,然后使用 cv2.destroyAllWindows() 函数关闭所有打开的 OpenCV 窗口。如果无法加载图片,它会打印一个错误消息。
2.11.返回到主界面
def return_to_system():subprocess.Popen(["python", "rlsb.py"])win.destroy()
#调用 win.destroy() 方法来关闭当前的 Tkinter 窗口。
注:这个函数的作用是在当前 Tkinter 窗口中执行 rlsb.py 脚本,并在脚本执行完毕后关闭窗口。这通常用于将控制权返回到操作系统或另一个应用程序。
subprocess.Popen([“python”, “rlsb.py”]):这行代码使用 subprocess.Popen() 函数启动一个新的进程,该进程将执行 rlsb.py 脚本。subprocess.Popen() 函数用于执行外部命令和程序,参数 [“python”, “rlsb.py”] 指定使用 Python 解释器执行 rlsb.py 脚本。
2.12.创建按钮
# 创建播放视频按钮,并放置在窗口的右侧
button1 = tk.Button(win, text="选择视频", command=play_video, width=10, height=2)
button1.place(x=150, y=500, width=100, height=50)# 创建返回程序按钮,并放置在窗口的右侧
button2 = tk.Button(win, text="返回程序", command=return_to_system, width=10, height=2)
button2.place(x=400, y=500, width=100, height=50)
注:这两行代码分别创建了两个按钮,并设置了它们的位置、大小和功能。当用户点击这些按钮时,会触发相应的函数执行。
2.13.更新窗口以确保按钮大小被计算
# 更新窗口以确保按钮大小被计算
win.update_idletasks()
注:这行代码的作用是更新 Tkinter 窗口,以确保按钮的大小被正确计算。在 Tkinter 中,按钮的大小是通过其 place 或 pack 方法设置的,但这些方法并不会立即更新按钮的实际大小。update_idletasks() 方法用于在布局管理器(如 pack 或 grid)计算所有控件的最终位置和大小后更新窗口。
2.14.事件循环
# 进入Tkinter事件循环
win.mainloop()
注:这行代码确保了 Tkinter 窗口和所有绑定的事件处理函数能够正常工作,并且用户可以与应用程序进行交互。它是 Tkinter 应用程序中不可或缺的一部分。
运行结果: