尝试编译 AMD ROCm 的 llvm-project
0,环境
ubuntu 22.04
gcc-11
x86_64 18cores/36threads
256GB RAM
rocm 6.0.2
Radeon VII
1,第一次尝试
构建命令:
cmake -G "Unix Makefiles" ../llvm \
-DLLVM_ENABLE_PROJECTS="clang;lld;lldb;mlir;openmp" \
-DLLVM_BUILD_EXAMPLES=ON \
-DLLVM_TARGETS_TO_BUILD="host;AMDGPU" \
-DCMAKE_BUILD_TYPE=Debug \
-DLLVM_ENABLE_ASSERTIONS=ON \
-DLLVM_ENABLE_RUNTIMES=all \
-DLLVM_BUILD_LLVM_DYLIB=ON \
-DCMAKE_INSTALL_PREFIX=../../local_amdgpumake -j32
![]()
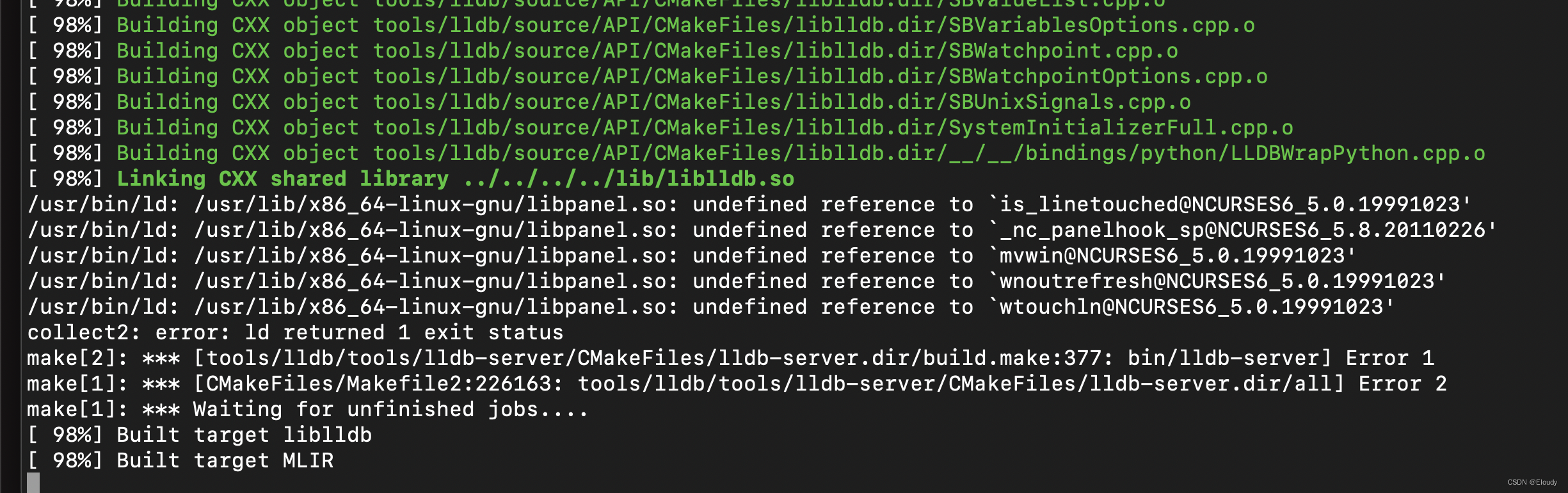
效果:
由于 ncurses 库没有搞定,所以失败了:
估计是lldb的layout src之类的命令会用到 ncurses,
对策:不编译 lldb项目
2,第二次尝试
删掉了 lldb 和 openmp,调整了TARGET,加入了 NVPTX,
重来:
cmake -G "Unix Makefiles" ../llvm \
-DLLVM_ENABLE_PROJECTS="clang;lld;mlir" \
-DLLVM_BUILD_EXAMPLES=ON \
-DLLVM_TARGETS_TO_BUILD="Native;NVPTX;AMDGPU" \
-DCMAKE_BUILD_TYPE=Debug \
-DLLVM_ENABLE_ASSERTIONS=ON \
-DLLVM_ENABLE_RUNTIMES=all \
-DLLVM_BUILD_LLVM_DYLIB=ON \
-DCMAKE_INSTALL_PREFIX=../../local_amdgpumake -j34
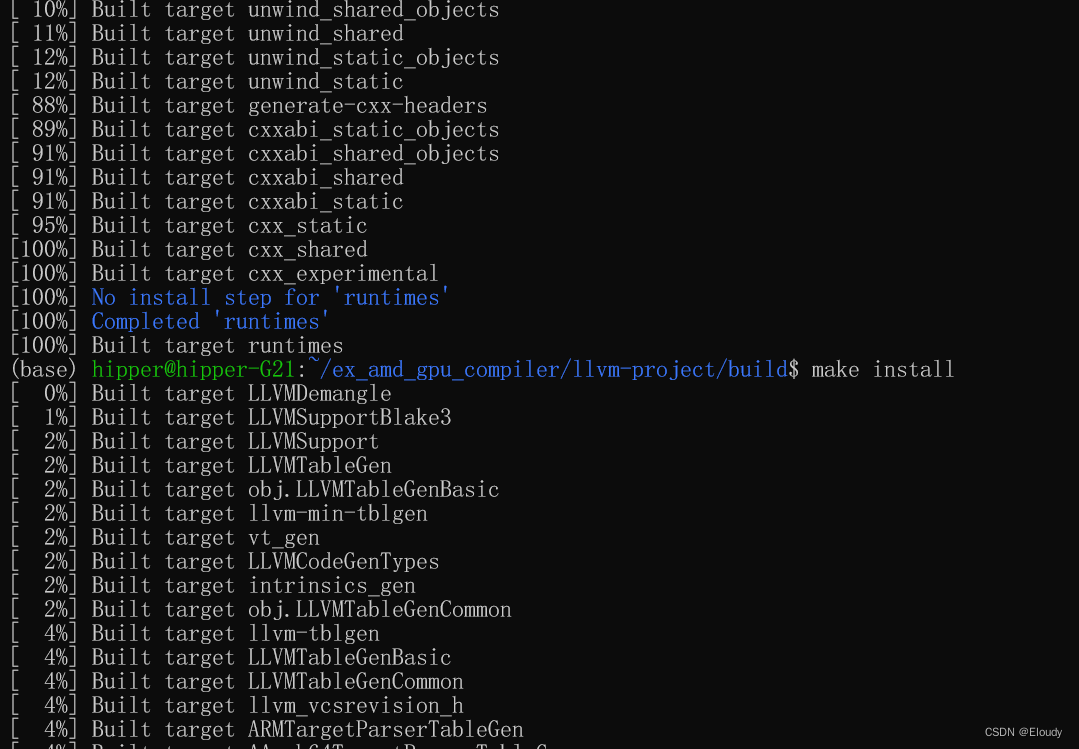
编译成功,
安装 make install
效果:
3,测试编译rocm hip源码
3.1 源码示例
vectorAdd.hip
#include <stdio.h>
#include <hip/hip_runtime.h>__global__ void vectorAdd(const float *A, const float *B, float *C) {int i = blockDim.x * blockIdx.x + threadIdx.x;C[i] = A[i] + B[i] + 0.0f;
}int main(void) {hipError_t err = hipSuccess;int numElements = 512;size_t size = numElements * sizeof(float);printf("[Vector addition of %d elements]\n", numElements);float *h_A = (float *)malloc(size);float *h_B = (float *)malloc(size);float *h_C = (float *)malloc(size);if (h_A == NULL || h_B == NULL || h_C == NULL) {fprintf(stderr, "Failed to allocate host vectors!\n");exit(EXIT_FAILURE);}for (int i = 0; i < numElements; ++i) {h_A[i] = rand() / (float)RAND_MAX;h_B[i] = rand() / (float)RAND_MAX;}float *d_A = NULL;err = hipMalloc((void **)&d_A, size);if (err != hipSuccess) {fprintf(stderr, "Failed to allocate device vector A (error code %s)!\n",hipGetErrorString(err));exit(EXIT_FAILURE);}float *d_B = NULL;err = hipMalloc((void **)&d_B, size);if (err != hipSuccess) {fprintf(stderr, "Failed to allocate device vector B (error code %s)!\n",hipGetErrorString(err));exit(EXIT_FAILURE);}float *d_C = NULL;err = hipMalloc((void **)&d_C, size);if (err != hipSuccess) {fprintf(stderr, "Failed to allocate device vector C (error code %s)!\n",hipGetErrorString(err));exit(EXIT_FAILURE);}printf("Copy input data from the host memory to the CUDA device\n");err = hipMemcpy(d_A, h_A, size, hipMemcpyHostToDevice);if (err != hipSuccess) {fprintf(stderr,"Failed to copy vector A from host to device (error code %s)!\n",hipGetErrorString(err));exit(EXIT_FAILURE);}err = hipMemcpy(d_B, h_B, size, hipMemcpyHostToDevice);if (err != hipSuccess) {fprintf(stderr,"Failed to copy vector B from host to device (error code %s)!\n",hipGetErrorString(err));exit(EXIT_FAILURE);}int threadsPerBlock = 256;int blocksPerGrid = (numElements + threadsPerBlock - 1) / threadsPerBlock;printf("CUDA kernel launch with %d blocks of %d threads\n", blocksPerGrid,threadsPerBlock);vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C);err = hipGetLastError();if (err != hipSuccess) {fprintf(stderr, "Failed to launch vectorAdd kernel (error code %s)!\n",hipGetErrorString(err));exit(EXIT_FAILURE);}printf("Copy output data from the CUDA device to the host memory\n");err = hipMemcpy(h_C, d_C, size, hipMemcpyDeviceToHost);if (err != hipSuccess) {fprintf(stderr,"Failed to copy vector C from device to host (error code %s)!\n",hipGetErrorString(err));exit(EXIT_FAILURE);}for (int i = 0; i < numElements; ++i) {if (fabs(h_A[i] + h_B[i] - h_C[i]) > 1e-5) {fprintf(stderr, "Result verification failed at element %d!\n", i);exit(EXIT_FAILURE);}}printf("Test PASSED\n");err = hipFree(d_A);if (err != hipSuccess) {fprintf(stderr, "Failed to free device vector A (error code %s)!\n",hipGetErrorString(err));exit(EXIT_FAILURE);}err = hipFree(d_B);if (err != hipSuccess) {fprintf(stderr, "Failed to free device vector B (error code %s)!\n",hipGetErrorString(err));exit(EXIT_FAILURE);}err = hipFree(d_C);if (err != hipSuccess) {fprintf(stderr, "Failed to free device vector C (error code %s)!\n",hipGetErrorString(err));exit(EXIT_FAILURE);}free(h_A);free(h_B);free(h_C);printf("Done\n");return 0;
}3.2 编译运行
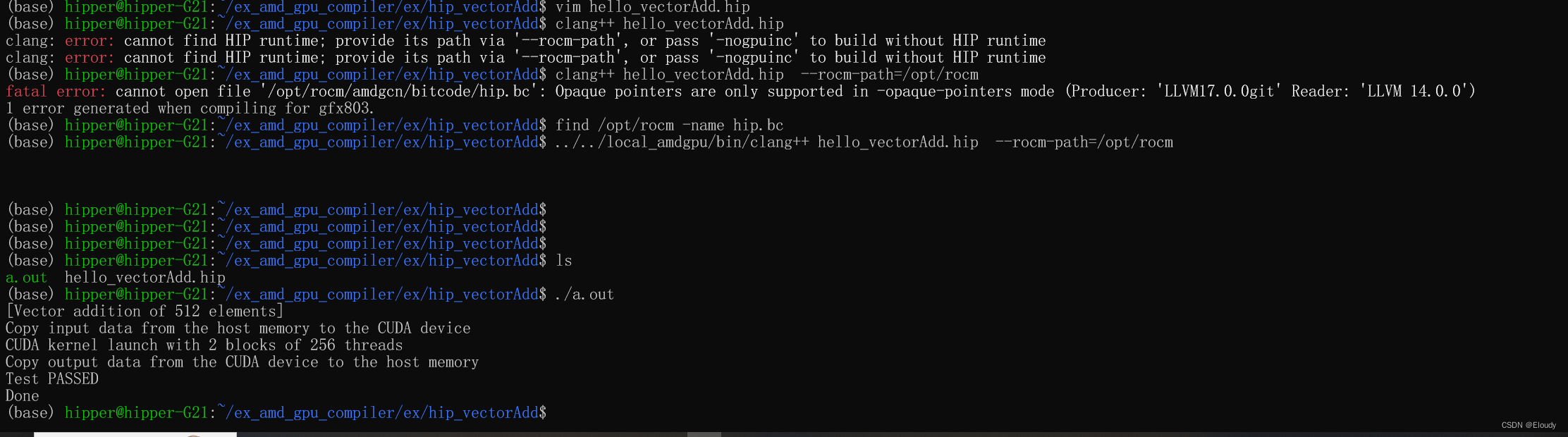
$ ../../local_amdgpu/bin/clang++ hello_vectorAdd.hip --rocm-path=/opt/rocm
这样简单的运行 clang++,还不太确定是不是仅仅起到了编译驱动的作用,后面进一步分析。
运行成功,
效果:
未完待续。。。