(2024,Vision-LSTM,ViL,xLSTM,ViT,ViM,双向扫描)xLSTM 作为通用视觉骨干
Vision-LSTM: xLSTM as Generic Vision Backbone
公和众与号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)

目录
0. 摘要
2 方法
3 实验
3.1 分类设计
4 结论
0. 摘要
Transformer 被广泛用作计算机视觉中的通用骨干网络,尽管它最初是为自然语言处理引入的。最近,长短期记忆网络(LSTM)被扩展为一种可扩展且高性能的架构——xLSTM,通过指数门控和可并行的矩阵存储结构克服了长期存在的 LSTM 局限性。在这份报告中,我们介绍了视觉 LSTM(Vision-LSTM,ViL),这是 xLSTM 构建模块在计算机视觉中的一种改编。ViL 由一堆 xLSTM 模块组成,奇数模块从上到下处理补丁标记序列,而偶数模块则从下到上处理。实验表明,ViL 有望进一步作为新的计算机视觉架构通用骨干网络进行部署。
项目页面:https://nx-ai.github.io/vision-lstm/
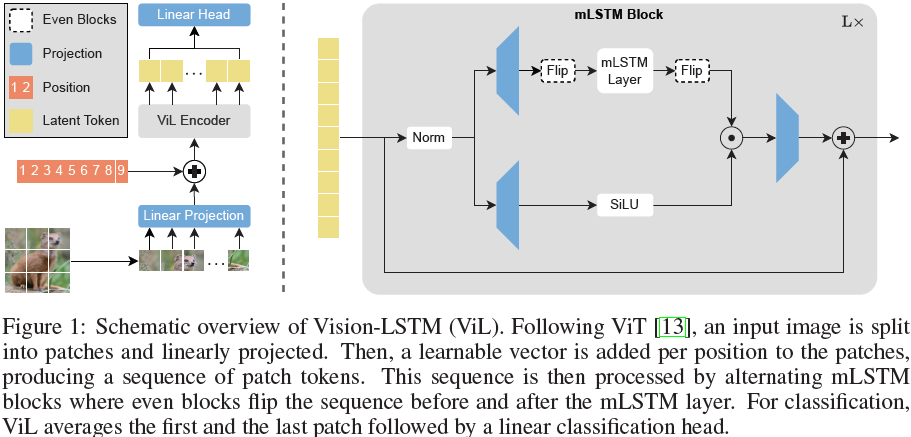
2 方法
Vision-LSTM(ViL)是一个用于计算机视觉任务的通用骨干网络,它是由 xLSTM 模块构建而成的,如图 1 所示。按照 ViT [13] 的方法,ViL 首先通过共享的线性投影将图像分割成不重叠的补丁(patch),然后为每个补丁标记(token)添加可学习的位置嵌入。ViL 的核心是交替的 mLSTM 模块,这些模块是完全可并行化的,并配备了矩阵存储和协方差更新规则。奇数 mLSTM 模块从左上角到右下角处理补丁标记,而偶数模块则从右下角处理到左上角。
(2024,LSTM,Transformer,指数门控,归一化器状态,多头内存混合)xLSTM:扩展的 LSTM
3 实验
我们在 ImageNet-1K [12] 上进行实验,该数据集包含 130 万张训练图像和 5 万张验证图像,每张图像属于 1000 个类别之一。我们的比较主要集中在使用序列建模骨干网络并且参数数量大致相当的模型上。
我们在 224x224 分辨率下训练 ViL 模型 800 个 epochs(tiny, tiny+)或 400 个 epochs(small, small+, base),学习率为 1e-3,使用余弦衰减调度。详细的超参数可以在附录 5 中找到。

(2024,ViM,双向 SSM 骨干,序列建模)利用双向状态空间模型进行高效视觉表示学习
为了与 Vision Mamba (Vim) [44] 进行公平比较,我们在模型中添加了额外的模块,以匹配 tiny 和 small 变体的参数数量(分别记为 ViL-T+ 和 ViL-S+)。需要注意的是,ViL 所需的计算量显著少于 Vim,因为 ViL 以交替方式遍历序列,而 Vim 每个模块遍历序列两次。这一点即使在 Vim 使用优化的 CUDA 内核的情况下依然成立,目前 mLSTM 尚无优化的 CUDA 内核(可进一步加速 ViL)。我们在附录 A.1 中比较了运行时间,ViL 比 Vim 快达 69%。

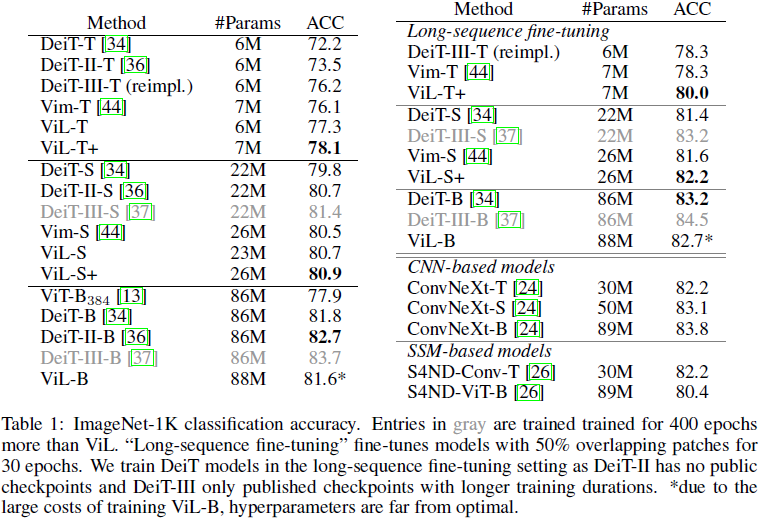
由于 ViT 在视觉领域已得到广泛应用,经过多年的多次优化循环 [13, 34, 36, 35, 37, 19]。作为首次将 xLSTM 应用于计算机视觉的工作,我们不期望在所有情况下都能超越多年超参数调优的ViT。然而,表 1 中的结果显示,ViL 在较小规模上显示出比经过大量优化的 ViT 协议(DeiT, DeiT-II, DeiT-III)更好的结果,只有经过双倍训练的 DeiT-III-S 略优于 ViL-S。在 “base” 规模上,ViL 表现优于初始 ViT [13] 模型,并且与 DeiT [34] 取得了可比的结果。需要注意的是,由于在这种规模上训练模型的成本很高,ViL-B 的超参数远未达到最佳。参考,训练 ViL-B 大约需要 600 A100 GPU 小时,或者在 32 个 A100 GPU 上约 19 小时。
通过在 “长序列微调” 设置中微调模型可以进一步提高性能 [44],该设置通过在连续补丁标记之间使用 50% 的重叠,增加序列长度到 729,并微调模型 30 个 epoches。
ViL 在与基于 CNN 的模型(如 ConvNeXt [24])的竞争中也表现出色,尽管没有利用卷积固有的归纳偏差。

块设计。我们在表 2 中研究了不同的 ViL 模块设计方法。简单的单向 xLSTM 模块未能达到竞争性能,因为 xLSTM 的自回归特性不适合图像分类。以双向方式遍历模块,即在每个模块中引入一个反向遍历序列的第二个 mLSTM 层(类似于 Vim [44]),可以提高性能,但也需要更多的参数和 FLOPS。共享前向和后向 mLSTM 的参数使模型更具参数效率,但仍需要更多的计算资源,并且会导致这些参数过载,从而导致性能下降。使用交替模块可以提高性能,同时保持计算和参数效率。我们还探索了四向设计(类似于 [23]),即行方向(双向)和列方向(双向)遍历序列。双向仅在行方向(双向)上遍历序列。图 2 可视化了不同的遍历路径。

由于双向和四向模块的成本增加,这项研究是在大幅减少的设置中进行的。我们在 ImageNet-1K 的一个子集上训练,该子集仅包含 100 个类别的样本,分辨率为 128x128,训练 400 个周期。这尤其必要,因为我们的四向实现不兼容 torch.compile(PyTorch [29] 的一种通用速度优化方法),这导致运行时间更长,如表 2 最后一列所示。由于这一技术限制,我们选择交替双向模块作为我们的核心设计。

3.1 分类设计
为了使用 ViT 进行分类,通常将标记序列池化为单个标记,然后用作分类头的输入。最常见的池化方法是:(i)在序列开始处添加一个可学习的 [CLS] 标记,或(ii)对所有补丁标记取平均值生成一个 [AVG] 标记。是否使用 [CLS] 或 [AVG] 标记通常是一个超参数,两种变体的性能大致相当。而自回归模型通常需要专门的分类设计。例如,Vim [44] 需要将 [CLS] 标记放在序列中间,如果使用其他分类设计(如 [AVG] 标记或在序列开始和结束处分别放置两个 [CLS] 标记),性能会大幅下降。由于其自回归特性,我们在表 3 中探索了不同的 ViL 分类设计。[AVG] 对所有补丁标记取平均值,“Middle Patch” 使用中间补丁标记,“Middle [CLS]” 在序列中间使用一个 [CLS] 标记,“Bilateral [AVG]” 使用第一个和最后一个补丁标记的平均值。我们发现,ViL 对分类设计相对鲁棒,所有性能差异都在 0.6% 以内。我们选择 “Bilateral [AVG]” 而不是 “Middle [CLS]”,因为 ImageNet-1K 已知具有中心偏差,即物体通常位于图片中央。通过使用 “Bilateral [AVG]”,我们避免了利用这种偏差,使我们的模型更具普适性。
为了与使用单一标记作为分类头输入的先前架构保持可比性,我们对第一个和最后一个补丁取平均值。为了实现最佳性能,我们建议将这两个标记连接起来(“Bilateral Concat”)而不是取平均值。这类似于自监督视 ViT 中的常见做法,如 DINOv2 [28],它们通过在 [CLS] 和 [AVG] 标记处分别附加两个目标进行训练,因此通过连接 [CLS] 和 [AVG] 标记的表示受益。这一方向也已在视觉 SSM 模型 [40] 中进行了探索,在序列中散布多个 [CLS] 标记并用作分类器的输入。类似的方法也可以提高 ViL 的性能。
4 结论
受 xLSTM 在语言建模中成功的启发,我们介绍了 ViL,这是一种将 xLSTM 架构改编到视觉任务中的方法。ViL 以交替方式处理补丁标记序列。奇数模块按行从左上角处理到右下角,而偶数模块从右下角处理到左上角。我们的新架构在 ImageNet-1K 分类中优于基于 SSM 的视觉架构和优化后的 ViT 模型。值得注意的是,ViL 在公平比较中能够超越经过多年超参数调优和改进的 ViT 训练管道。
未来,我们看到在需要高分辨率图像以获得最佳性能的场景中应用 ViL 的潜力,例如语义分割或医学成像。在这些设置中,transofrmer 由于自注意力的二次复杂性而面临高计算成本,而 ViL 由于其线性复杂性则不然。此外,改进预训练方案(如通过自监督学习),探索更好的超参数设置或迁移 transformer 中的技术(如 LayerScale [35])都是 ViL 的有前景的方向。