Python 很好用的爬虫框架:Scrapy:
了解Scrapy 爬虫框架的工作流程:

在scrapy中, 具体工作流程是这样的:
首先第一步 当爬虫引擎<engine>启动后, 引擎会到 spider 中获取 start_url<起始url> 然后将其封装为一个request对象, 交给调度器<scheduler>, 这个调度器中存的是一个又一个的待请求的url request对象, 然后调度器会通过引擎将请求对象交给 下载器<downloader> 下载器获取到请求对象后, 发送请求,获取响应, 然后将获取的响应封装成一个响应对象 response 后通过引擎再交给spider 来进行数据解析, 数据的解析结果如果是 Url, 则通过引擎继续交给调度器, 如果是数据, 则会通过引擎,将数据交给管道<pipline>, 这就是scrapy的工作流程,
下载:
pip install scrapy创建爬虫项目:
在终端中使用scrapy命令来创建一个爬虫项目:
scrapy startproject 项目名字当我们使用命令完成创建项目的时候, scrapy会自动给我们创建一个有关 项目名 的文件夹:
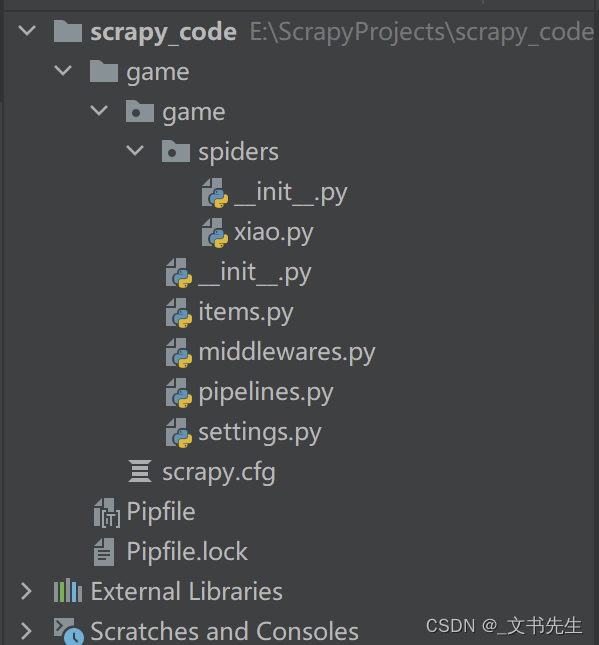
第一个 game 只是scrapy 创建的项目文件, 也就是项目根目录。
第二个game 目录则是我们的scrapy项目了, 项目目录下的 spiders 目录就是 有关 spider 爬虫脚本的目录
items: 暂时先不了解
middlewares: 中间件
pipelines: 管道, 所有爬虫获取到的数据最终都会到管道来
settings: 项目配置文件
创建爬虫:
使用scrapy命令创建爬虫, 但在运行命令之前,需要 cd 进入到爬虫项目中
scrapy genspider <spidername><域名>
scrapy genspider myspider baidu.com
然后你会发现在spiders目录下,会多出一个爬虫脚本,点开脚本 :
 你会发现scrapy为我们创建了一个爬虫类, 集成之Spider
你会发现scrapy为我们创建了一个爬虫类, 集成之Spider
name 则是爬虫的名字
allowed_domains 则是允许爬取的域名, 除此以外的域名都会被过滤掉
start_urls 则就是起始URL了
而此爬虫类中, 还提供了一个 parse 方法, 此方法就是用来解析获取的响应结果的,
启动爬虫:
启动爬虫也很简单, 使用命令启动爬虫
scrapy crawl 爬虫名字
你会看到控制台打印很多东西, 不用着急, 这只是scrapy的输出日志而已, 我们可以通过命令行或者在settings中配置一下日志输出级别:
楼主这里是在settings 文件中配置的:
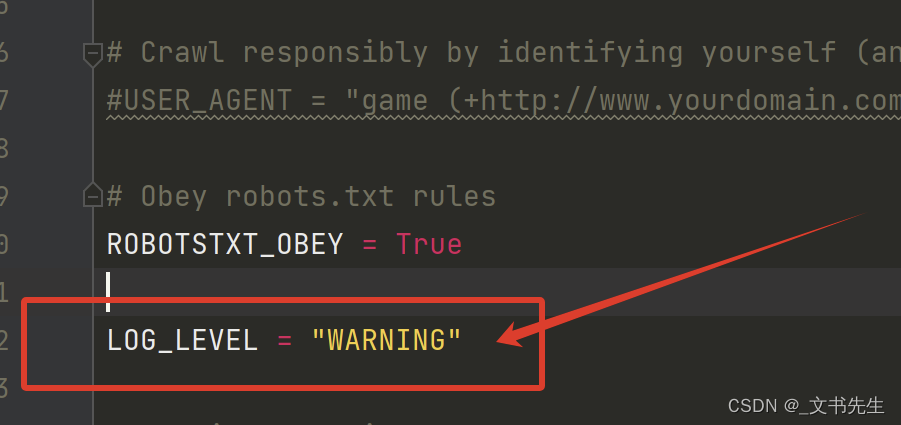
加上这句, 配置日志级别为 warning, 那么控制台就只能打印 warning及以上级别的信息了