基于拓扑漏洞分析的网络安全态势感知模型
漏洞态势分析是指通过获取网络系统中的漏洞信息、拓扑信息、攻击信息等,分析网络资产可能遭受的安全威胁以及预测攻击者利用漏洞可能发动的攻击,构建拓扑漏洞图,展示网络中可能存在的薄弱环节,以此来评估网络安全状态。
在网络安全形势日益恶化的今天,如何快速有效地获取网络系统的安全状况、提高网络安全应对水平、增大网络安全的预警时间,成为网络空间安全领域研究的重要问题。网络漏洞态势感知研究存在的问题是缺乏有效的网络漏洞势数据采集和要素提取方法,使得网络资产漏洞态势的理解和分析计算难以进行。针对这一研究现状,提出一种基于拓扑漏洞分析的网络安全态势感知模型,从网络漏洞态势数据获取入手,通过网络资产漏洞态势要素的获取、理解和分析处理,采用形式化的方式描述获取要素及其关联关系,计算网络系统安全态势值,实现网络资产漏洞态势感知。模型的结果易于理解,优化了传统的纯数值表示,与实际结果更相符。
1)拓扑漏洞分析
拓扑漏洞分析为网络安全态势感知的“态势识别”“态势理解”和“态势展示”提供了技术支持,是通过对网络系统中漏洞间依赖关系和网络攻击路径的分析,获知网络系统安全态势的一种方法,也是实现网络安全防御的一项技术。拓扑漏洞分析由三个部分组成:信息获取、信息理解和信息展示。
(1)信息获取,是采用扫描或者探测的手段获取网络系统中拓扑漏洞分析所需信息的方法。根据获取信息对象的不同,拓扑漏洞的信息获取方法可分为面向主机的拓扑漏洞分析方法和面向网络系统的拓扑漏洞分析方法。
(2)信息理解,是对获取的网络信息采用拓扑漏洞分析的方法进行处理,包括信息现状分析和信息状态转换处理。
(3)信息展示,是对信息理解分析结果的图形化展示和对网络系统安全状况调整的建议。
网络漏洞态势感知是对所收集的网络资产漏洞态势信息融合分析、计算理解,判断网络资产漏洞态势状况并对漏洞态势进行预测。网络漏洞态势感知包括资产漏洞信息的获取、识别、确认和评估,不论是漏洞态势的获取和识别还是漏洞态势的确认和评估,都需要相应的理论和方法。拓扑漏洞分析技术的“信息获取”“信息理解”和“信息展示”为解决网络漏洞态势感知的获取、识别、确认和评估提供了技术支持。因此,利用拓扑漏洞分析技术的“面向主机”和“面向网络系统”的信息获取方法,获取网络资产漏洞态势信息,通过对获取的漏洞态势信息提炼和分析,能够得到网络资产漏洞态势感知态势理解所需的参数,为态势理解提供支持;利用拓扑漏洞分析技术中的态势信息分析计算、安全状态描述、网络系统安全评估、网络系统安全威胁预测的方法,对网络资产漏洞态势感知中的漏洞状况进行理解、评估和预测。
2)漏洞态势感知建模
要获取网络资产漏洞态势,就需要对网络系统的安全状态信息数据进行分析、处理,因此需要建立网络资产漏洞态势感知模型。模型用于感知网络资产漏洞态势,应解决两个问题:态势要素的分析处理和态势值的计算。对获取的要素分析处理时需要描述要素之间
的状态转换关系,掌握要素信息及其关联关系;态势值的计算是在状态分析处理的基础上,针对当前及可能发生的状态,计算态势值,明确漏洞态势,因此所建立的网络资产漏洞态势感知模型是一个基于拓扑漏洞分析的态势感知模型,如下图所示。
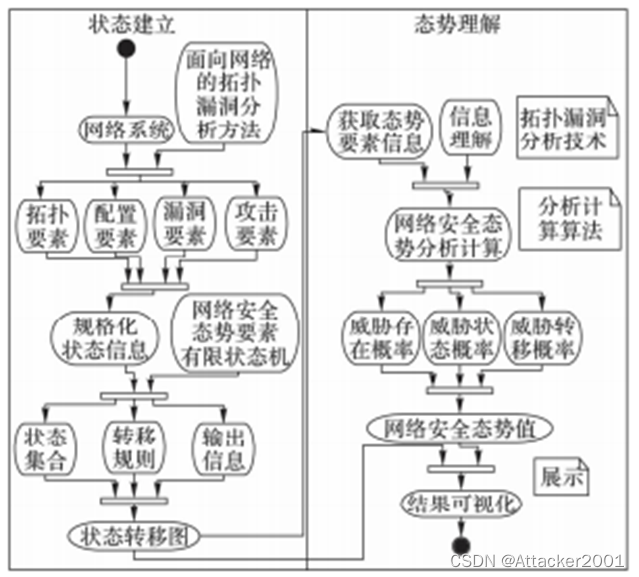
- 1 态势感知模型
从上图可以看到,基于拓扑漏洞分析的漏洞态势感知模型是通过两个步骤实现:第一步状态建立。对网络系统采用面向网络的拓扑漏洞分析方法得到拓扑要素、配置要素、漏洞要素和攻击要素,规格化形成状态,作为输入,采用拓扑漏洞分析技术中信息状态转换处理方法,利用有限状态机的形式化表示方法建立状态语义、输出语义及状态转换规则。第二步态势理解。以状态建立结果为输入,采用拓扑漏洞分析技术中信息理解方法,建立公式计算网络中威胁存在概率、状态转移概率和威胁损失等数据,得到态势值。
第一步:状态建立
状态建立是建立有限状态机描述漏洞态势,即建立漏洞态势有限状态机。漏洞态势包括网络中当前状态和可能发生的状态。
漏洞态势来源于规格化的态势信息,即当前漏洞状态包括拓扑结构、配置,可能发生状态是指漏洞攻击状态。由于网络受到自身原因或者外界干扰会导致漏洞态势发生改变,所以网络中状态会发生转移,因此使用有限状态自动机对形成的状态进行分析描述。态势有限状态机包括三个:拓扑结构有限状态机、配置状态有限状态机和漏洞攻击有限状态机。
定义态势有限状态机(Situation Patulous Finite State Machine,SPFSM)是扩展的有限状态机,用六元组表示:
SPFSM=(S,I,s0,F,T,δ)(1)
S={s0,s1,…,sn },状态的集合,表示在任意时刻,有限状态机只能处于一个确定的状态。对拓扑结构、配置和漏洞攻击描述时,将存在不同的状态,具体状态语义如下表所示。

- 2 语义解释
I:输入集合,网络系统中拓扑、配置、漏洞攻击等安全状态。
s0:初始状态,即当前由拓扑、配置、漏洞攻击等组成的网络安全状态。
F:结束状态,表示所有可作为状态分析终点的状态。
T:输出集合,表示态势发生改变可能导致的变化或者空输出(无变化)。
拓扑结构、配置和漏洞攻击因状态转移将产生不同的输出,具体输出语义如下图所示。
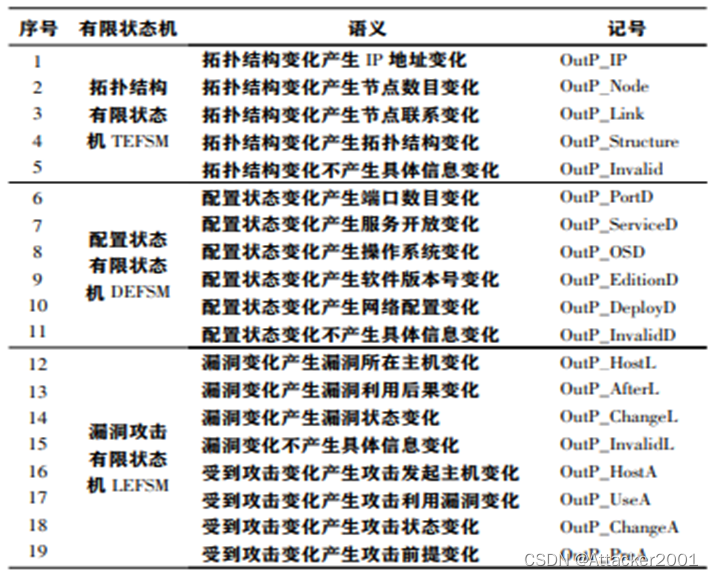
- 3 语义解释
δ=S×I→S是转移函数,由当前状态和输入决定,通过状态转移规则产生相应的状态转移。拓扑结构、配置和漏洞攻击由于当前状态和输入不同,状态转移规则也不同。
拓扑结构有限状态机(Topology Elements Finite State Machine,TEFSM)是一个用式(1)定义的网络安全有限状态机,描述网络系统拓扑状态的变化。其中:S、I、s0、F、T与网络安全有限状态机的定义相同。δ是拓扑结构有限状态机的状态转移规则,简称拓扑状态转移规则,用于描述转移函数,定义不同状态发生转移的条件,包括初始状态、结构变化状态、节点信息状态和节点联系状态、结束状态之间的相互转移。
拓扑状态转移规则如下:
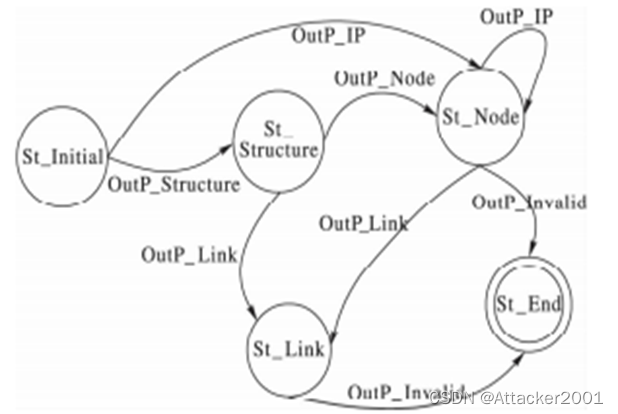
在某拓扑结构状态下,当网络系统拓扑结构未发生变化,而IP地址改变OutP_IP时,初始状态迁移到节点信息状态St_Node。
当检测到拓扑结构变化,即输出拓扑变化产生拓扑结构变化OutP_Structure,从初始状态St_Initial转移到结构变化状态St_Structure。
当处于结构变化状态St_Structure,若有节点增加或者减少,节点数目变化OutP_Node,将转移到节点信息状态St_Node。
当处于结构变化状态St_Structure,若有节点联系增加或者减少,节点联系变化OutP_Link,将迁移到节点联系状态St_Link。
当处于节点信息状态St_Node,若节点增加或者减少,则导致节点联系变化OutP_Link,将迁移到节点联系状态St_Link。
当处于节点信息状态St_Node,若IP地址改变OutP_IP,将状态迁移到自身。
当处于节点信息状态St_Node,若无具体信息变化产生OutP_Invalid,将状态迁移到结束状态St_End。
当处于节点联系状态St_Link,若无具体信息变化产生OutP_Invalid,将状态迁移到结束状态St_End。
拓扑结构有限状态自动机TEFSM状态之间的转移图,如下图所示。
- 4 转移
配置状态有限状态机(Deployments Finite State Machine,DEFSM)是一个用式(1)定义的网络安全有限状态机,描述网络系统配置状态的变化其中:S、I、s0、F、T与式网络安全有限状态机的定义相同。δ是配置状态有限状态机的状态转移规则,简称配置状态转移规则,用于描述转移函数,定义不同状态发生转移的条件,包括初始状态、配置变化状态、端口状态、服务状态、操作系统状态、软件版本状态和结束状态之间的相互转移。
配置状态转移规则如下:
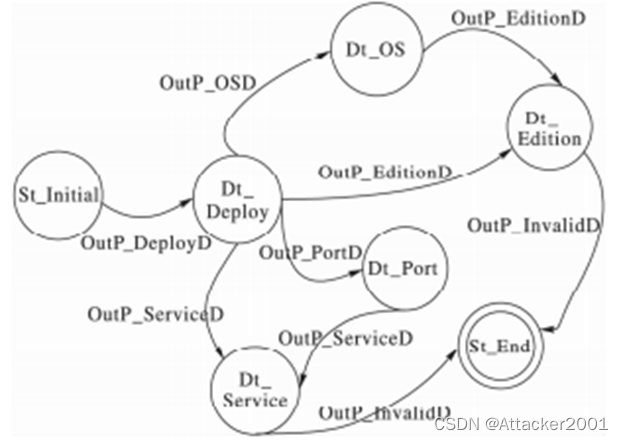
在某配置内容状态下,当网络配置发生变化OutP_DeployD,将从初始状态Dt_Initial迁移到配置变化状态Dt_Deploy。
当处于配置变化状态Dt_Deploy,若端口开放或者关闭,导致端口数目变化OutP_PortD,将从配置变化状态Dt_Deploy迁移到端口状态Dt_Port。
当处于端口状态Dt_Port,若由于端口开放关闭导致开放服务的增加或者减少,将导致服务开放变化OutP_ServiceD,从端口状态Dt_Port迁移到服务状态Dt_Service。
当处于配置变化状态Dt_Deploy,若之间出现服务的开放或者关闭,将从配置变化状态Dt_Deploy迁移到服务状态Dt_Service。
当处于服务状态Dt_Service,若无具体信息变化产生OutP_InvalidD,将状态迁移到结束状态Dt_End。
当处于配置变化状态Dt_Deploy,若出现操作系统更OutP_OSD,将从配置变化状态Dt_Deploy迁移到操作系统状态Dt_OS。
当处于操作系统状态Dt_OS,由于操作系统版本变化导致软件版本变化OutP_EditionD,将从操作系统状态Dt_OS迁移到软件版本状态Dt_Edition。
当处于软件版本状态Dt_Edition,若无具体信息变化产生OutP_InvalidD,将状态迁移到结束状态Dt_End。
当处于配置变化状态Dt_Deploy,若出现软件版本变化OutP_EditionD,将从配置变化状态Dt_Deploy迁移到软件版本状态Dt_Edition。
配置状态有限状态自动机DEFSM状态之间的转移图,如下图所示。
- 5 转移
漏洞攻击有限状态机(Leak Elements Finite State Machine,LEFSM)是一个用式(1)定义的网络安全有限状态机,描述网络系统安全状态的变化。其中:S、I、s0、F、T与式(1)网络安全有限状态机的定义相同。δ表示状态转移规则,简称漏洞攻击状态转移规则,用于描述转移函数,定义不同状态发生转移的条件,包括初始状态、漏洞变化状态、主机状态、漏洞利用后果状态和结束状态等状态之间的相互转移。
漏洞攻击状态转移规则如下:
在某漏洞攻击状态下,当漏洞状态发生变化OutP_ChangeL,将从初始状态Lt_Initial迁移到漏洞变化状态Lt_Change。
当处于漏洞变化状态Lt_Change,若漏洞所在主机发生变化OutP_HostL,将从漏洞变化状态Lt_Change迁移到主机状态Lt_Host。
当处于主机状态Lt_Host,若由于主机的变化导致漏洞利用后果发生改变OutP_AfterL,将从主机状态Lt_Host迁移到漏洞利用后果状态Lt_After。
当处于漏洞利用后果状态Lt_After,若无具体信息变化产生OutP_InvalidL,将状态迁移到结束状态Lt_End。
当处于漏洞变化状态Lt_Change,若对漏洞采用不同的利用方式产生不同的漏洞利用后果发生改变OutP_AfterL,将从漏洞变化状态Lt_Change迁移到漏洞利用后果状态Lt_After。
当处于主机状态Lt_Host,若无具体信息变化产OutP_InvalidL,将状态迁移到结束状态Lt_End。
在某漏洞攻击状态下,当攻击状态发生变化OutP_ChangeA,将从初始状态Lt_Initial迁移到攻击变化状态Lt_ChangeA。
当处于攻击变化状态Lt_ChangeA,若漏洞的攻击发起主机发生变化OutP_HostA,将从攻击变化状态Lt_ChangeA迁移至攻击源状态Lt_HostA。
当处于攻击源状态Lt_HostA,通过检查发现由于攻击发起主机改变,导致攻击前提改变OutP_PreA,将从攻击源状态Lt_Hos迁移至攻击前提状态Lt_Pre。
当处于攻击前提状态Lt_Pre,由于攻击前提发生改变,导致漏洞利用后果状态改变OutP_AfterL,将从攻击前提状态Lt_Pre迁移至漏洞利用后果状态Lt_After。
当处于攻击变化状态Lt_ChangeA,若攻击发起主机未变,但攻击前提发生改变OutP_PreA,将从攻击变化状态Lt_ChangeA迁移至攻击前提状态Lt_Pre。
当处于攻击变化状态Lt_ChangeA,若攻击发起主机未变,但攻击利用漏洞改变OutP_UseA,将从攻击变化状态Lt_ChangeA迁移至漏洞利用状态Lt_Use。
当处于漏洞利用状态Lt_Use,由于漏洞改变,攻击前提条件随之改变OutP_PreA,将从漏洞利用状态Lt_Use迁移至攻击前提状态Lt_Pre。
当处于漏洞利用状态Lt_Use,由于漏洞改变,导致漏洞利用后果状态改变OutP_AfterL,将从漏洞利用状Lt_Use迁移至漏洞利用后果状态Lt_After。
当处于攻击源状态Lt_HostA,若攻击利用漏洞改变OutP_UseA,将从攻击源状态Lt_HostA迁移至漏洞利用状态Lt_Use。
第二步:态势理解
态势理解是指在获取态势信息数据的基础上,通过分析计算状态建立的结果,获取态势,计算威胁存在概率、威胁状态概率、威胁损失等态势组成值,综合得出态势,计算结果以数值形式呈现。
威胁存在概率:指通过网络安全态势信息获取,得到某种漏洞、攻击或者威胁存在的可能性,用I表示。威胁存在概率与获取到与该威胁的相关的态势信息In及其权重wn相关,结合DS证据理论,可得威胁存在概率计算公式,公式表明威胁存在概率I与态势信息In成正比,且权重越大的对结果影响越大。
威胁状态概率:指通过网络安全态势信息获取,得到已经发生的攻击在网络安全状态转移图中处于某个中间状态的可能性,用C表示。威胁状态概率由威胁存在概率、攻击相关度共同决定,威胁存在概率越大,受到同一攻击的可能性越大,则该节点处于越有可能威胁的状态。
攻击相关度:指两个或者多个攻击信息之间的相关程度,用rel(x,y)表示。攻击相关度与信息获取时确定的特征关联度和权重有关,特征关联度越大,则权重越大,则x,y受到同一攻击的可能性越大。
威胁损失:指网络系统某个漏洞或者攻击影响,处于该状态时将带来的损失,用L表示。威胁损失L采用通用漏洞评分系统(Common Vulnerability Scoring System,CVSS)进行赋值。
网络安全态势分析计算,采用先局部后整体、自下向上的原则,通过分析计算网络系统中设备态势组成值,分类累加得到整个网络系统的安全态势值。
网络安全态势值:表示网络系统受威胁的程度,其值是用0~1的数字表示。
网络安全态势值的计算步骤如下:
(1)计算设备态势组成值,将攻击状态概率C、状态转移概率E与当前状态对应的威胁损失L相结合,得到该状态下设备的态势值D:
D=C·E·L
(2)当设备在同一状态下受到多个攻击时,则该状态下设备的态势值Ac需要进行累加。计算公式如下所示,其中i为受到攻击数:
Ac=∑_(i=1)^d▒D_i
(3)依据设备的态势组成值,考虑设备重要程度不一样,分别加以权重赋值,得到整个态势值WAc:
WAc=∑_(i=1)^d▒〖Ac〗_i ∙w_i
这里需要说明的是,态势值反映了网络受攻击威胁的程度,势值越大越容易受到威胁,网络的安全性越低。态势值与网络实际受威胁的程度间的对应关系如下图所示。

- 7 态势值与网络威胁程度说明
必要性
传统的Traceroute方法在进行网络拓扑发现时会产生大量的冗余探测,无法高效的获得网络拓扑结构。因此,如何在提高拓扑发现效率的同时保证拓扑发现的完整性是高效的拓扑发现算法的主要关注点,同时这也关系到该算法的可用性。因此亟需对拓扑发现技术中的拓扑发现算法进行研究。本章首先阐述了经典的Doubletree算法并分析Doubletree算法的优缺点。其次在Doubletree算法的基础上进行改进和优化,提出了一种并行拓扑发现算法,并且提出了一种动态轮转模式用来实施并行拓扑发现算法。最后将两者结合为一种基于动态轮转的并行拓扑发现算法。
Doubletree算法是通过使用两种树形结构,分别是以探测目的节点为根的树形结构和以探测节点机为根的树形结构,以达到减少冗余探测的目的。当探测方向是向后进行探测时,停止规则是基于以探测源为根的树形结构,目的是减少探测点内冗余。当探测方向是向前进行探测时,停止规则是基于以探测目的节点为根的树形结构,目的是减少探测间内冗余。Doubletree算法根据拓扑探测的方向,设置了两个不同的停止集。当向前进行探测时,使用的是全局停止集,里面存储的是<目的节点,中间路由器节点>。当向后进行探测时,使用的是本地停止集,里面存储的是<中间路由器节点>。每个探测源都保存一个本地停止集,探测源之间需要共享全局停止集。
Doubletree算法的流程:首先将探测目的节点集平均划分成大小相同的若干个不同的探测目的集分组。探测源选择探测目的集分组中的一个目的节点D,并选取一个初始跳数h,发送TTL值为h,h+1,h+2的探测数据包,以TTL值递增的方式进行向前探测,根据响应数据包的路由器IP地址R判断是否存在全局停止集。如果不存在则将<D,R>保存到全局停止集中,继续向前探测。如果路由器IP地址R在全局停止集或者到达探测目的节点则停止向前探测,转而向后探测。探测源发送TTL值为h-1,h-2的探测数据包,以TTL值递减的方式进行向后探测,根据返回的数据包的路由器IP地址R判断是否在本地停止集中。如果不存在则将<R>加入到本地停止集中,同时将<D,R>加入到全局停止集中,继续向后探测。如果路由器IP地址R在本地停止集或者h=1则停止向后探测。然后选取探测目的集分组中的下一个目的节点进行探测。当探测源探测完当前探测目的集分组中的所有目的节点后,将全局停止集转发给总控节点机,目的是和其他探测源交换全局停止集,总控节点机汇总全部探测源的全局停止集后,向所有探测源下发更新后的全局停止集,探测源再对下一个探测目的节点集分组进行探测。
探测源共享全局探测集如下图所示,Doubletree算法要求每个探测源节点机(S1、S2、S3、S4、…、Sg)需要将每次探测更新后的全局停止集(P1、P2、P3、P4、…、Pg)传输到总控节点机,总控节点机将全局停止集汇总合并之后,形成新的全局停止集T,然后总控节点机将全局停止集T下发到所有探测源节点机,进行新一轮的探测。可以看出,Doubletree算法的这种通信方式会产生大量的通信量。当全局停止集的数量很大时,会给总控节点机造成很大的通信负担,从而降低了网络拓扑发现的效率。

- 8 贡献合并探测示意
探测过程中造成拓扑发现完整性不足的问题如下图所示,假设探测源S1首先对目的节点D进行探测,探测过程中将S1到D之间的路由器,以<目的节点,路由器节点>的形式(例如<D,A>)加入到全局停止集中。当探测源S2对目的节点D向前进行探测时,探测到路由器节点O时,发现<D,O>在全局停止集中,则停止向前探测,转而向后探测。这造成路由器L、M、N无法被发现。

- 9 路由寻址示意
综上所述,Doubletree算法虽然在保证网络拓扑发现完整度较高的前提下,减少了冗余探测,提高了探测的效率。但是仍然存在以下不足:一是Doubletree算法的关键在于初始跳数h的选择,如果h选择的太小跟传统的Traceroute方法接近,会造成大量的冗余探测,如果h选择的太大很容易会被认为是DDOS攻击;二是Doubletree算法在探测目的节点的每一跳路由时,必须等待发送探测数据包的反馈信息,然后才能进行下一跳路由的探测,降低了探测效率;三是Doubletree算法由于网络负载均衡和路由器的多址问题造成某些路由器接口无法被发现,从而导致完整性不足;四是Doubletree算法要求所有的探测源向总控节点机传输更新后的全局停止集来实现探测源之间共享全局停止集,导致探测源间通信量大。
有学者提出一种基于Doubletree算法的改进算法,针对Doubletree算法在通信量上存在的不足之处进行优化,将Doubletree算法的全局停止集的一维存储式改为二维储方式。并且为每个BloomFilter增加一个是否修改过的标志,这样探测源间每次交换数据时,只需要交换修改过的数据量。该方法在一定程度上降低了通信量,但是仍然需要总控节点机处理全局停止集,并没有减少总控节点机的通信负担。此外,该方法也并未解决Doubletree算法在网络拓扑探测中完整性不足的问题。
杨旭提出了一种基于回转探测的渐进式拓扑探测策略,对Doubletree算法在通信量的不足之处进行了改进,具体做法是将探测源平均分成若干个分组,在分组之间进行交换全局停止集。虽然该方法减少了通信次数和总的通信量,不需要总控节点机归并全局停止集,然后将新的全局停止集再传输给所有的探测源。但该方法中每个探测源分在同一时刻中只有一个探测节点机进行探测,另外每个探测源分组对前一个分组的依懒性太强,使得灵活性不强。
解决途径
Doubletree算法在探测目的节点的每一跳路由时,必须等待发送探测数据包的反馈信息,然后才能进行下一跳路由的探测,降低了探测效率。同时Doubletree算法由于网络负载均衡和路由器的多址问题可能会造成在网络拓扑发现中某些路由器接口无法被发现,从而导致拓扑发现的完整性不足。为了解决Doubletree算法的这两个不足,本系统采用了并行拓扑发现算法。该算法的实现框架结构如下图所示。
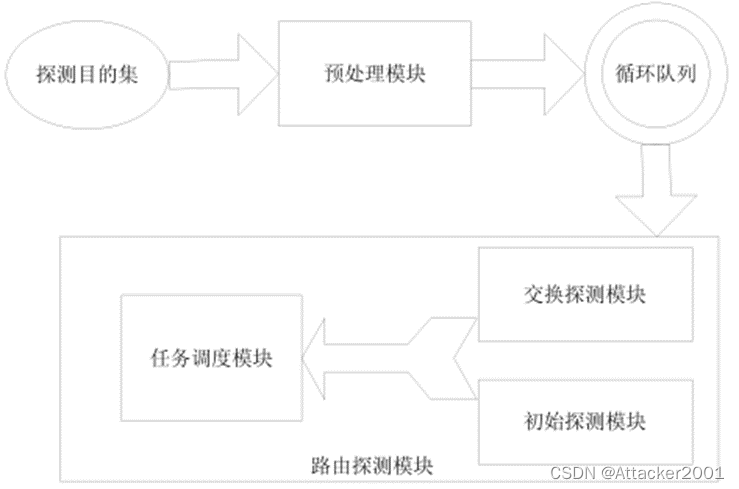
- 10 Doubletree算法流程示意
该拓扑发现算法主要是由预处理模块和路由探测模块组成。在预处理模块和路由探测模块之间通过循环队列进行数据共享。预处理模块和路由探测模块是并行执行的。设置预处理模块主要有两个目的:一是通过预处理模块过滤掉因为连通性问题导致的探测源和探测目的节点之间不连通的探测目的节点;二是计算出了探测源节点机到探测目的节点的总跳数TTL值,节省了路由探测模块的探测时间,从而提高探测的效率。
预处理模块从探测目的集中选取一个探测目的节点进行主机探测,获取探测源到探测目的节点的总跳数TTL值,并判断是否为初始探测。探测源节点机对各自对应的探测目的集进行探测的过程称为初始探测,探测源节点机在共享全局停止集后的探测过程称为交换探测。将探测过程划分成初始探测和交换探测的目的是提高探测效率。最后将目的节点、TTL值、探测标志以结构体的形式保存到循环队列中。共享的结构体如下:
structnode
{
chardst_ip;//探测目的节点
intttl;//探测源到探测目的节点的距离TTL值
intflag;//flag为0时表示是初始探测,flag为1时表示是交换探测
};
Doubletree算法为了减少探测间的冗余探测要求探测源间共享全局停止集,各个探测源每次将更新后的全局停止集发送给总控节点机,总控节点机将探测源的全局停止集合并后再发送给各个探测源,这种方式会导致探测源间产生大量的通信量。为了解决Doubletree算法探测源间共享全局停止集产生通信量大的问题,提出了动态轮转模式来实施并行拓扑发现算法。该模式如下图所示。
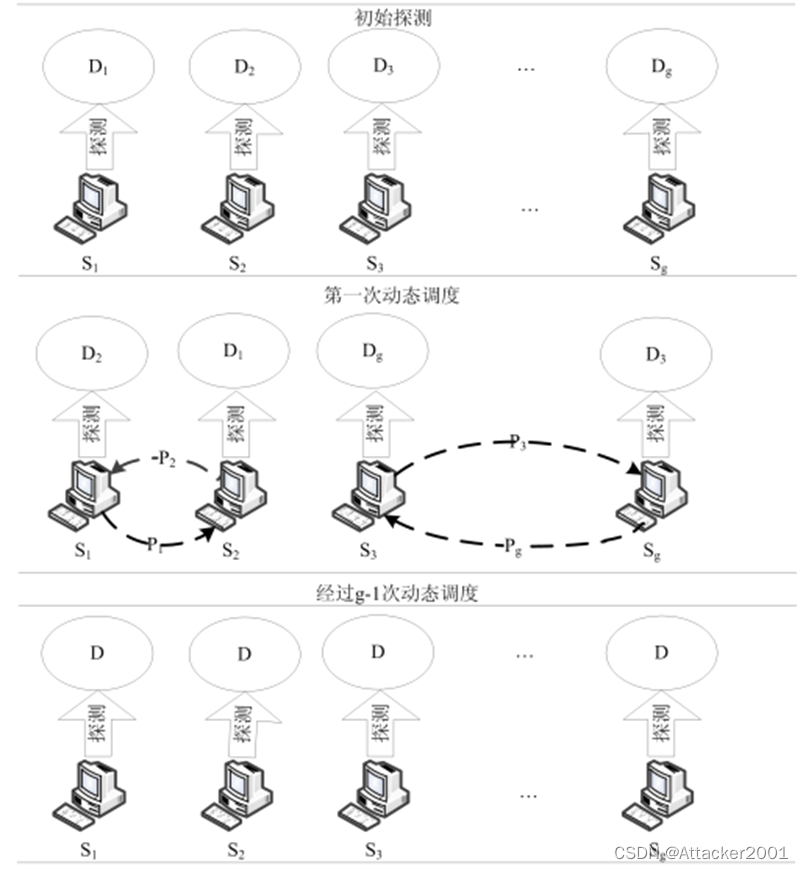
- 11 动态轮转模式流程示意
假设探测源有g个节点机,分别为S1、S2、S3、S4、…、Sg,将探测目的集D平均分成g个分组,分别为D1、D2、D3、D4、…、Dg,每个目的集分组都对应一个全局停止集分别为P1、P2、P3、P4、…、Pg。
步骤1:初始探测时,总控节点机给所有的探测源节点机发送探测指令,并指定探测源Si节点机应该探测的目的集分组Di,所有探测源Si节点机并行的探测相应的目的集Di分组。当探测源节点机Si探测完成相应目的集Di分组中的所有目的节点后,探测源向总控节点机发送自己已经完成目的集Di分组的探测。总控节点机在保证每个探测源节点机探测到所有探测目的集分组的基础上根据探测源节点机的处理性能进行动态任务调度,总控节点机给探测源节点机发送指令指明探测源节点机Si应该把目的集Di分组的全局停止集Pi发送给探测源节点机Sj,同时指明探测源节点机应该接受目的集Dk分组的全局停止集Pk。
步骤2:探测源Sj节点机接受目的集Di分组的全局停止集Pi,开始对目的集Di分组按照步骤1相应的方式进行探测。
步骤3:经过g-1次步骤2的动态轮转调度之后,每个的探测源节点机完成了对所有探测目的集分组的探测。
Doubletree算法中的本地停止集和全局停止集都采用BloomFilter,使用BloomFilter来节省存储空。基于动态轮转的并行拓扑发现算法中的本地停止集和全局停止集也采用BloomFilter。该算法对本地停止集的存储形式进行了修改,当TTL值大于等于总跳数的一半时,存储的是<中间路由器节点,TTL>,目的是减少一些重复探测;当TTL值小于等于总跳数的一半时,存储的是<中间路由器节点>。除了本地停止集和全局停止集之外,该算法还增加一个临时停止集。临时停止集使用共享内存,对探测结果进行存储,存储形式为<中间路由器节点,TTL>,临时停止集的作用域是当前的探测目的节点。