[论文笔记]Mixtral of Experts
引言
今天带来大名鼎鼎的Mixtral of Experts的论文笔记,即Mixtral-8x7B。
作者提出了Mixtral 8x7B,一种稀疏专家混合(Sparse Mixture of Experts,SMoE)语言模型。Mixtral与Mistral 7B具有相同的架构,不同之处在于每个层由8个前馈块(即专家)组成。对于每个令牌(Token),在每个层中,路由器网络选择两个专家处理当前状态并结合它们的输出。尽管每个令牌只看到两个专家,但在每个时间步长上选择的专家可以不同。因此,每个令牌可以访问47B参数,但在推理过程中只使用13B活跃参数。Mixtral在32k令牌的上下文大小下进行训练,并且在所有评估的基准测试中表现优于或与Llama 2 70B和GPT-3.5相匹配。还提供了一个经过微调以遵循指示的模型Mixtral 8x7B – Instruct,在人类基准测试中超过了GPT-3.5 Turbo。基础模型和指导模型都以Apache 2.0许可协议发布。
1. 总体介绍
在这篇工作中,作者介绍了Mixtral 8x7B,一个稀疏混合专家模型,其权重开放并在Apache 2.0下许可。Mixtral在大多数基准测试中优于Llama 2 70B和GPT-3.5。由于每个令牌仅使用其参数的子集,Mixtral可在低批量大小下实现更快的推理速度,并在大批量大小下实现更高的吞吐量。
Mixtral是一个稀疏专家混合网络。它是一个仅解码器模型,其中前馈块从8个不同组的参数集中进行选择。在每个层中,对于每个令牌,路由器网络选择其中的两个组(专家)来处理该令牌并将它们的输出按加法结合。这种技术可以增加模型的参数数量,同时控制成本和延迟,因为模型每个令牌只使用总参数集的一部分。
Mixtral是使用具有32k令牌的多语言数据进行预训练的。它在多个基准测试中要么匹配要么超越Llama 2 70B和GPT-3.5的性能。特别是在数学、代码生成以及需要多语言理解的任务中,Mixtral展示出优越的能力,明显优于Llama 2 70B在这些领域。实验证明,Mixtral能够成功地从其32k令牌的上下文窗口中检索信息,无论序列长度及信息在序列中的位置如何。
作者还介绍了Mixtral 8x7B – Instruct,这是一个经过监督微调和直接偏好优化以遵循指示的聊天模型。其性能明显优于GPT-3.5 Turbo等在人类评估基准上的聊天模型。

2. 架构细节
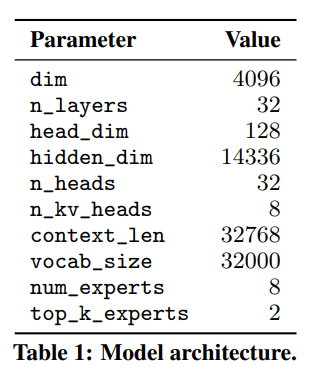
Mixtral基于一个transformer架构,并使用了和Mistral 7b中描述的相同的修改,但与之不同的是,Mixtral支持完全密集的32k token的上下文长度,并且将前馈块替换为专家混合层。模型架构参数总结如下表1所示。
2.1 稀疏混合专家
图1简要介绍了专家混合层。对于给定的输入 x x x,MoE模块的输出由专家网络输出的加权和确定,其中权重由门控网络的输出给出。即给定 n n n个专家网络 { E 0 , E i , . . . , E n − 1 } \{E_0, E_i, ..., E_{n−1}\} {E0,Ei,...,En−1},专家层的输出由以下公式给出:
∑ i = 0 n − 1 G ( x ) i ⋅ E i ( x ) \sum_{i=0}^{n-1} G(x)_i \cdot E_i(x) i=0∑n−1G(x)i⋅Ei(x)
这里, G ( x ) i G(x)_i G(x)i表示第 i i i个专家的门控网络的 n n n维输出,而 E i ( x ) E_i(x) Ei(x)表示第 i i i个专家网络的输出。如果门控向量是稀疏的,我们可以避免计算门控为零的专家的输出。有多种不同的方法可以实现 G ( x ) G(x) G(x) ,但一个简单而有效的方法是对线性层的Top-K个logits进行softmax运算。使用
G ( x ) : = Softmax ( TopK ( x ⋅ W g ) ) G(x) := \text{Softmax}(\text{TopK}(x\cdot W_g)) G(x):=Softmax(TopK(x⋅Wg))
其中, ( TopK ( ℓ ) ) i : = ℓ i (\text{TopK}(ℓ))_i := ℓ_i (TopK(ℓ))i:=ℓi,如果 ℓ i ℓ_i ℓi是logits ℓ ∈ R n ℓ ∈\R^n ℓ∈Rn的前K个元素之一,否则 ( TopK ( ℓ ) ) i : = − ∞ (\text{TopK}(ℓ))_i :=-\infty (TopK(ℓ))i:=−∞。 K K K的值,即每个标记使用的专家数量,是一个超参数,用于调节处理每个标记所需的计算量。如果保持 K K K不变而增加n,可以增加模型的参数数量,同时保持其计算成本基本恒定。
这引发了模型的总参数数量(通常称为稀疏参数数量)与用于处理单个标记的参数数量(称为活跃参数数量)之间的区别,其中稀疏参数数量随 n n n增加,而活跃参数数量随K增加直至 n n n。
MoE层可以在单个GPU上高效运行,并使用高性能的专门内核。例如,Megablocks将MoE层的前馈网络操作转换为大型稀疏矩阵乘法,显著提高执行速度,并自然处理不同的专家分配不同数量的标记的情况。此外,MoE层可以通过标准的模型并行技术将其分布到多个GPU,并通过一种称为专家并行的特定分区策略进行。在MoE层的执行过程中,要由特定专家处理的标记被路由到相应的GPU进行处理,并将专家的输出返回到原始标记位置。请注意,EP在负载平衡方面存在挑战,必须均匀分布工作负载到各个GPU,以防止单个GPU过载或遇到计算瓶颈。
在Transformer模型中,MoE层独立地应用于每个标记,并替换transformer块的前馈(FFN)子块。对于Mixtral,使用与专家函数 E i ( x ) E_i(x) Ei(x)相同的SwiGLU架构,并设置 K = 2 K = 2 K=2。这意味着每个标记被路由到两个具有不同权重集的SwiGLU子块中。综上所述,对于输入标记 x x x,输出 y y y的计算如下:
y = ∑ i = 0 n − 1 Softmax ( Top2 ( x ⋅ W g ) ) i ⋅ SwiGLU i ( x ) y = \sum_{i=0}^ {n-1} \text{Softmax}(\text{Top2}(x \cdot W_g))_i \cdot \text{SwiGLU}_i(x) y=i=0∑n−1Softmax(Top2(x⋅Wg))i⋅SwiGLUi(x)
这个公式与GShard架构相似,但有两个例外:所有的FFN子块替换为MoE层,而GShard替换其他块;此外,GShard对每个标记分配的第二个专家使用了更复杂的门控策略。
3. 结果
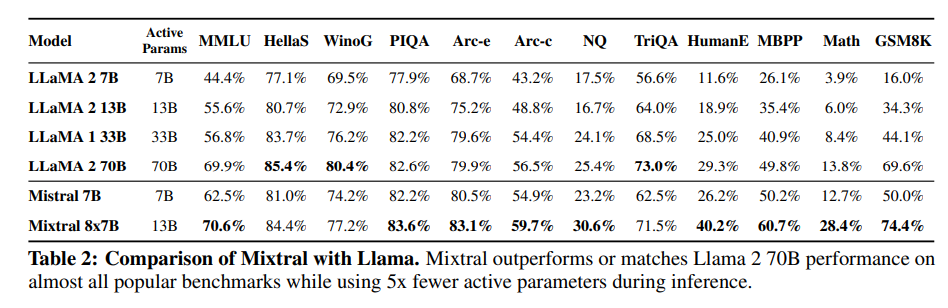
将Mistral 7B与Llama进行比较,并使用作者自己的评估流程重新运行所有基准测试,以进行公平比较。对各种任务的性能进行了测量,分类如下:
-
常识推理(0-shot):Hellaswag,Winogrande,PIQA,SIQA,OpenbookQA,ARC-Easy,ARC-Challenge ,CommonsenseQA
-
世界知识(5-shot):Natur alQuestions,TriviaQA
-
阅读理解(0-shot):BoolQ,QuAC
-
数学:GSM8K(8-shot,maj@8)和MATH(4-shot,maj@4)
-
代码:Humaneval (0-shot)和MBPP (3-shot)
-
热门聚合结果:MMLU(5-shot),BBH(3-shot),和AGI Eval(3-5-shot,仅限英文多项选择题)
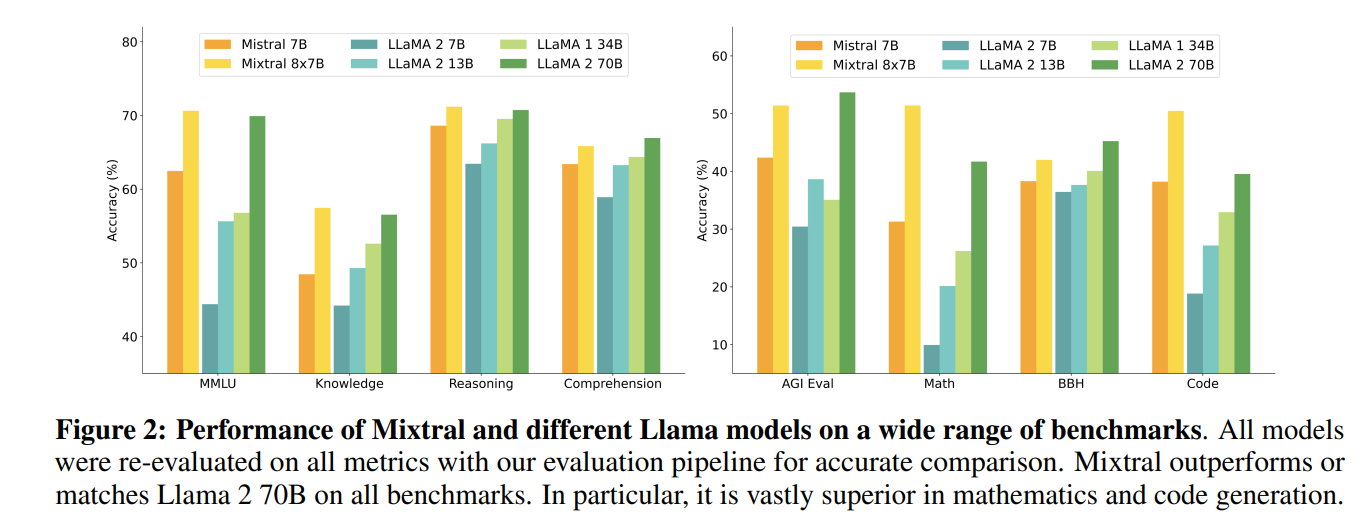
在表2中报告了Mixtral、Mistral 7B、Llama 2 7B/13B/70B和Llama 1 34B2的详细结果。图2比较了Mixtral在不同类别中与Llama模型的性能。在大多数指标上,Mixtral超过了Llama 2 70B。特别是,在代码和数学基准测试中,Mixtral展现出了卓越的性能。
大小和效率 将性能与Llama 2系列进行比较,旨在了解Mixtral模型在成本性能范围内的效率(见图3)。作为一种稀疏的Mixture-of-Experts模型,Mixtral每个标记只使用13B个活跃参数。以5倍较低的活跃参数,Mixtral能够在大多数类别中胜过Llama 2 70B。
注意,重点关注活跃参数数量,它与推理计算成本成正比,但不考虑内存成本和硬件利用率。为了提供Mixtral的内存成本与其稀疏参数数量47B成比例,这仍然小于Llama 2 70B。至于设备利用率,SMoEs层由于路由机制和在每个设备上运行多个专家时内存负载增加而引入了额外开销。它们更适合批处理工作负载,其中可以达到良好的算术强度。
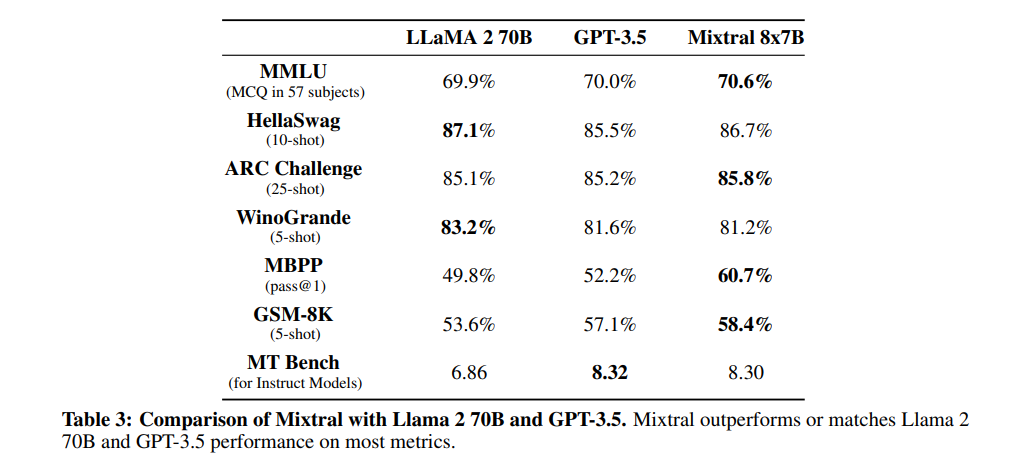
与Llama 2 70B和GPT-3.5的比较 在表3中,进行了Mixtral 8x7B与Llama 2 70B和GPT-3.5的性能比较。Mixtral的性能与其他两个模型相似或更好。在MMLU上,Mixtral获得了更好的性能,尽管其容量显着较小。
3.1 多语言基准测试
与Mistral 7B相比,作者在预训练期间显著提高了多语言数据的比例。额外的容量使得Mixtral在多语言基准测试中表现出色,同时在英语方面保持高准确性。特别是,在法语、德语、西班牙语和意大利语方面,Mixtral在表4中明显优于Llama 2 70B。

3.2 长距离性能
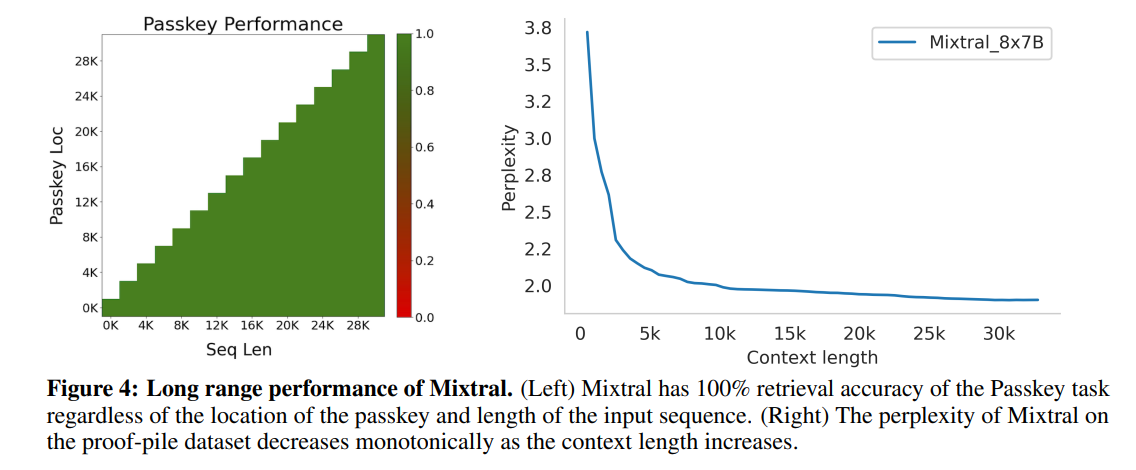
为了评估Mixtral处理长篇上下文的能力,引入的密钥(passkey)检索任务上对其进行评估,这是一个设计用来衡量模型在随机插入的长提示中检索密钥的能力的合成任务。图4(左)的结果显示,Mixtral无论上下文长度或密钥在序列中的位置如何,都能实现100%的检索准确率。图4(右)显示,在proof-pile数据集的一个子集上,随着上下文大小的增加,Mixtral的困惑度呈单调下降趋势。
3.3 偏见基准测试
为了确定可能需要通过微调/偏好建模进行修正的潜在缺陷,对基准模型在Bias Benchmark for QA (BBQ) 和Bias in Open-Ended Language Generation Dataset (BOLD) 上进行了性能测量。BBQ是一个手写的问题集数据集,旨在检测针对九个不同社会相关类别的社会偏见:年龄、残疾状态、性别认同、国籍、外貌、种族/民族、宗教、社会经济地位、性取向。BOLD是一个大规模数据集,包含23679个用于偏见基准测试的英文文本生成提示,涵盖五个领域。使用评估框架对Llama 2和Mixtral在BBQ和BOLD上进行基准测试,表5中显示结果。
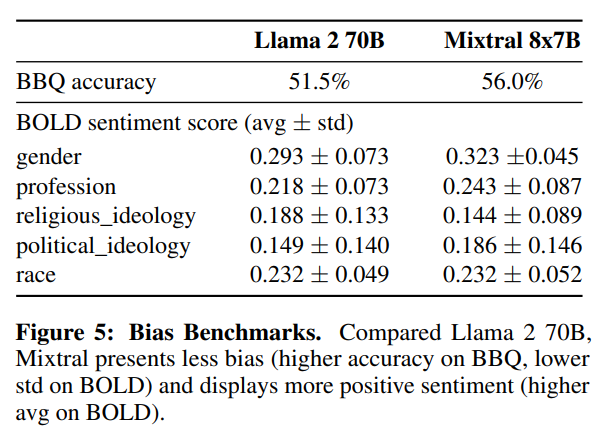
与Llama 2相比,Mixtral在BBQ基准测试上呈现出较少的偏见。对于BOLD中的每个组,更高的平均情感分数意味着更积极的情绪,较低的标准差表示组内偏见较少。总体而言,Mixtral表现出比Llama 2更积极的情感,在每个组内的方差相似。
4. 指令微调
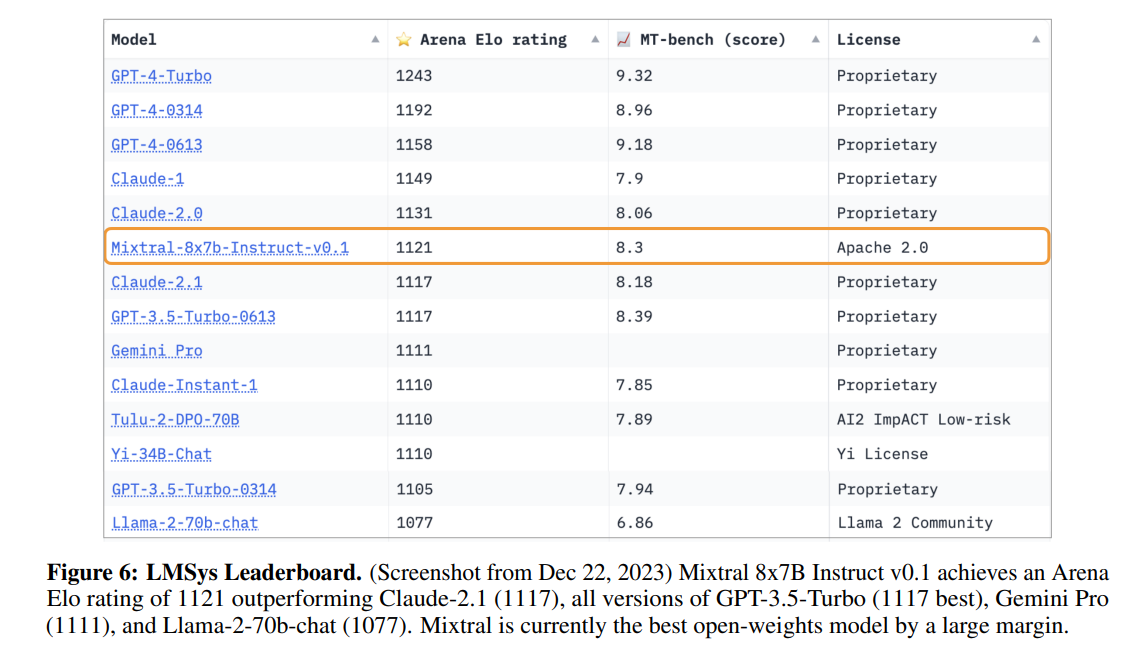
使用指令数据集进行监督微调(SFT),然后使用配对反馈数据集进行直接偏好优化(DPO)来训练Mixtral - Instruct。Mixtral - Instruct在MT-Bench上达到8.30的得分(见表2),使其成为截至2023年12月最好的开放权重模型。由LMSys进行的独立人工评估结果如图6所示,显示Mixtral - Instruct优于GPT-3.5-Turbo、Gemini Pro、Claude-2.1和Llama 2 70B chat。
5. 路由分析
在本节中,对路由器进行了一项关于专家选择的小型分析。具体而言,对训练过程中是否有一些专家专门针对某些特定领域(如数学、生物学、哲学等)进行了调查。
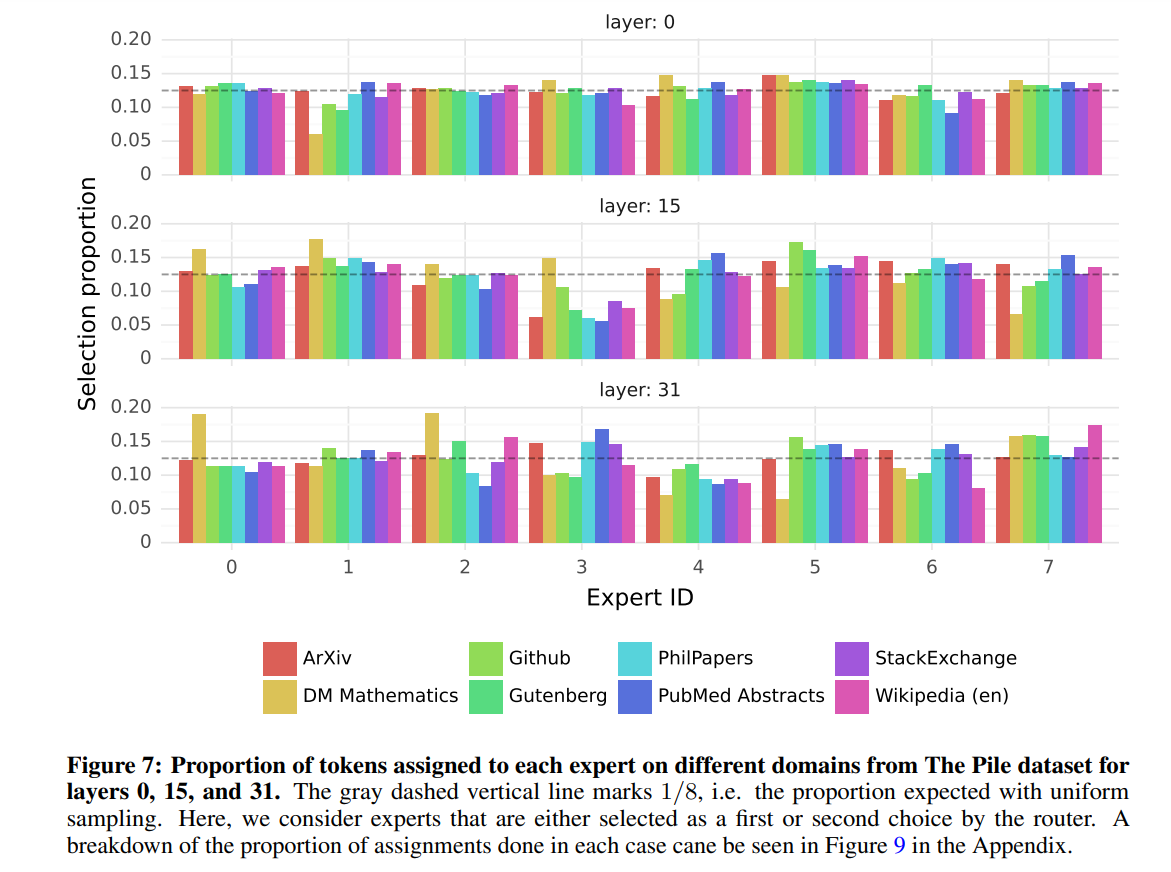
为了调查这一点,对The Pile验证数据集的不同子集上选择的专家进行了分布测量。结果如图7所示,分别对应模型的第0层、第15层和第31层(分别是模型的第一层和最后一层)。在基于主题的专家分配中没有观察到明显的模式。例如,在所有层级上,ArXiv论文(使用Latex编写)、生物学(PubMed摘要)和哲学(PhilPapers)文档的专家分配分布非常相似。
只有在DM Mathematics领域,专家分配存在略微不同的分布。这种差异可能是数据集的合成性质和自然语言范围有限的覆盖的结果,在第一层和最后一层尤为明显,因为这些层级的隐藏状态与输入和输出嵌入的相关性非常高。

这表明路由器确实表现出一些结构化的句法行为。图8展示了不同领域(Python代码、数学和英语)的文本示例,其中每个标记都用与其选择的专家相对应的背景颜色进行了突出显示。图示显示,例如,在Python中的self和英语中的Question等单词通常会通过相同的专家进行路由,即使它们涉及多个标记。同样,在代码中,缩进标记始终分配给同一专家,特别是在第一层和最后一层,其中隐藏状态与模型的输入和输出更相关。
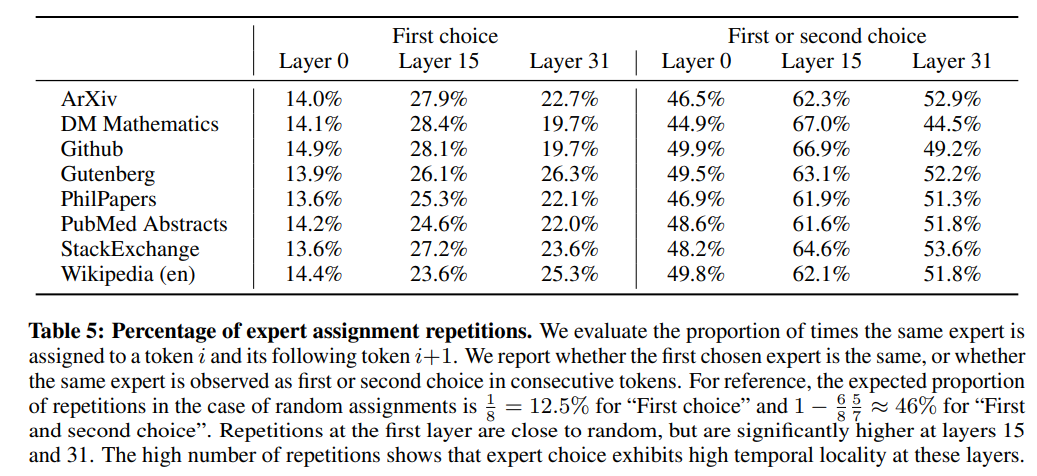
连续的标记通常被分配给同样的专家。实际上,在The Pile数据集中,观察到一定程度的位置局部性。表5显示了每个领域和层级中连续标记分配给相同专家的比例。对于较高层级,连续分配重复的比例显著高于随机分配。这对于如何优化模型的快速训练和推理具有影响。例如,在进行专家并行时,具有高局部性的情况更有可能导致某些专家的过度订阅。相反,这种局部性可以用于缓存。
6. 结论
在本论文中,作者介绍了Mixtral 8x7B,这是第一个在开源模型中达到最新技术水平的专家混合网络。由于每个时间步只使用两个专家,因此Mixtral每个标记只使用13B个活跃参数,同时表现优于之前每个标记使用70B参数的最佳模型Llama 2 70B。
总结
⭐ 作者提出了Mixtral-8x7B,是一种稀疏的混合专家模型,通过门控机制来选择专家(MoE层),每个时间步只激活少量的专家,可以加快推理计算,但实际上要存储所有的参数所需的资源也是不少的。