多模态大模型通用模式
MM-LLMs(多模态大模型)是目前比较新的和实用价值越发显著的方向。其指的是基于LLM的模型,具有接收、推理和输出多模态信息的能力。这里主要指图文的多模态。
代表模型:GPT-4o、Gemini-1.5-Pro、GPT-4v、Qwen-VL、CogVLM2、GLM4V、InternVL-Chat-V1.5、MiniCPM-Llama3-V2.5

1.模型结构
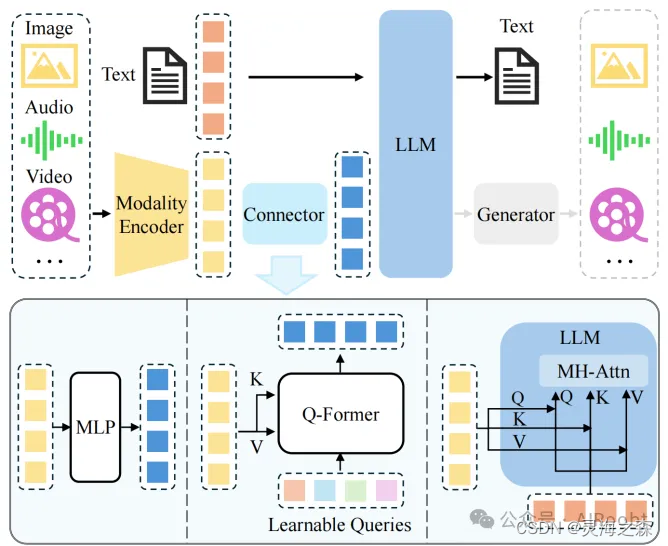
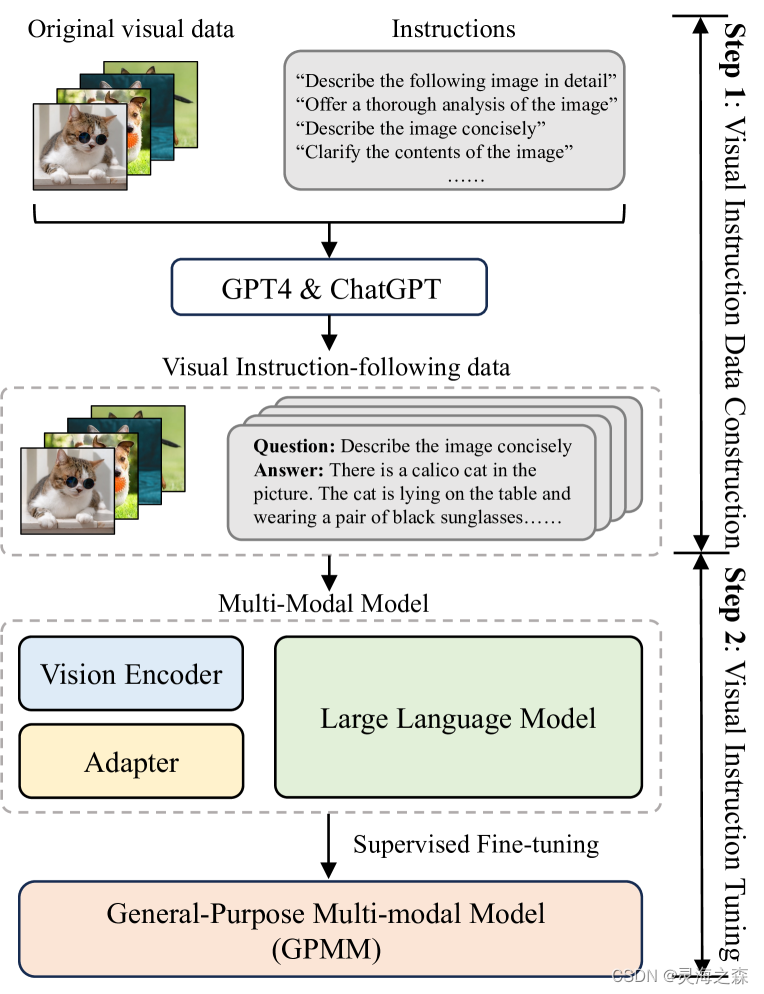
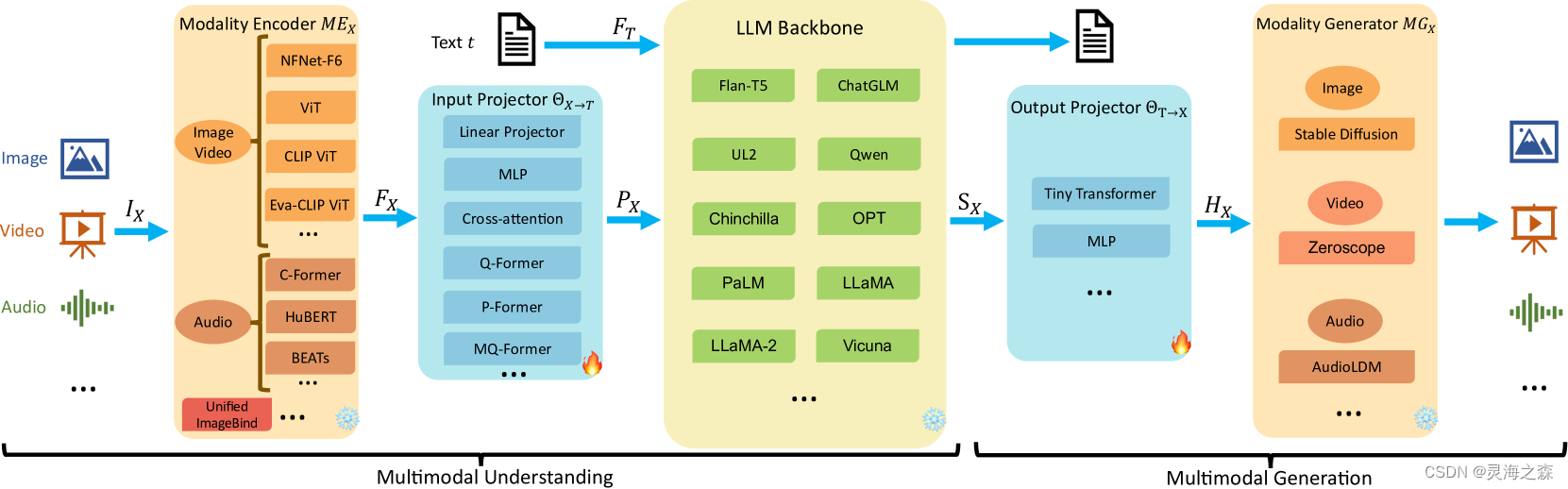
主要由编码器、连接器、LLM组成:
编码器 Modality Encoder (ME):编码器是处理输入数据的组件,它可以接收多种模态的输入,如图像、音频或视频。编码器的任务是将这些原始的多模态数据转换成模型可以理解的特征表示。
连接器:连接器是连接编码器输出和大型语言模型(LLM)的桥梁。它的主要作用是将编码器输出的特征进一步处理,使其能够与LLM的输入格式兼容,从而让LLM能够更好地理解这些特征。
LLM:LLM是MLLM的核心,通常是一个预训练的语言模型,负责处理和生成文本。它能够根据输入的文本和其他模态的特征,进行语言理解、生成或推理等任务。
生成器:是可选的。可以附加到LLM上,用于生成除文本之外的其他模态输出,如图像、音频或视频。
(1)模态编码器
通常使用预训练的编码器。常见的有CLIP、EVA-CLIP、EVA2-CLIP-E、InternViT-6B、VILT。
优化要点:更高的分辨率能带来更高的性能提升。
一文看完多模态:从视觉表征到多模态大模型 - 菜人卷的文章 - 知乎
https://zhuanlan.zhihu.com/p/684472814
(2)连接器
该模块用于对齐不同模态和LLM的文本模态。
The Input Projector is tasked with aligning the encoded features of other modalities with the text feature space .
https://arxiv.org/html/2401.13601v5
最主要的方法是在预训练的视觉编码器和LLM之间引入一个可学习的连接器,将信息投影到LLM可以高效理解的空间中。
可学习的连接器的分类:
①基于投影的连接器(Projection-based):这种连接器将编码器输出的特征投影到与LLM的词嵌入相同的维度空间,使得特征可以直接与文本令牌一起被LLM处理。如MLP。 (令牌级)
②基于查询的连接器(Query-based):这种连接器使用一组可学习的查询令牌来动态地从编码器输出的特征中提取信息。如Q-Former。 (令牌级)
③基于融合的连接器(Fusion-based):这种连接器在LLM内部实现特征级别的融合,允许文本特征和视觉特征在模型内部进行更深入的交互和整合。如Cross-attention。 (特征级)
其次可以使用专家模型,直接将图像描述语言作为文本发送给LLM。基本思想是在不训练的情况下将多模态输入转换为语言。通过这种方式,大型语言模型(LLMs)可以通过转换后的语言理解多模态性。
(3)LLM
预训练的LLM,如QwenLM、Yi-34B、Llama-3-8B-Instruct。
优化要点:更大的参数量能带来更高的性能提升;专家混合(MoE)架构较优。
2.训练流程
和语言模型一样,都要经过预训练和监督微调两个阶段。下图为Qwen-VL的训练流程。
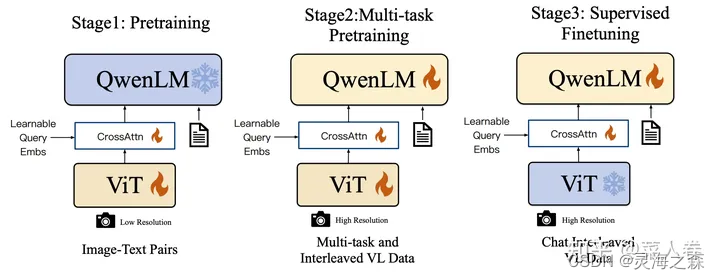
(1) MM PT 多模态预训练
预训练阶段通常涉及大规模图文Pair对数据,例如字幕数据。通过优化预定义的目标函数来训练连接器,以实现各种模态之间的对齐。冻结LLM的参数。
例如可以给定一张图像,模型被训练以自回归方式预测图像的字幕,使用标准的交叉熵损失。
语料类型:图文对(<img1><txt1>);图文交错语料(<txt1><img1><txt2><txt3><img2><txt4>)。

对于简短和嘈杂的字幕数据,可以采用较低分辨率(例如224)以加快训练过程,而对于更长和更清洁的数据,最好使用更高的分辨率(例如448或更高)以减少幻觉。
(2)MM IT 指令微调
指令微调旨在教模型更好地理解用户的指令并完成所需的任务。通过这种方式微调,LLM可以通过遵循新指令来泛化到未见过的任务,从而提升零样本性能。
MM IT包括监督微调(SFT)和基于人类反馈的强化学习(RLHF),旨在与人类意图对齐并增强MM-LLMs的交互能力。
①SFT
样本格式:包括一个可选的指令和一个输入输出对。

模型被预测响应的下一个标记,训练目标通常是用于训练LLM的原始自回归目标,使用交叉熵损失函数。
数据集:LLaVA-Instruct-150k。
数据质量的评价维度:提示多样性;任务覆盖。
②RLHF
人类偏好对齐。利用强化学习算法使LLM与人类偏好对齐,训练环节中以人类注释作为监督。
流程:监督微调;奖励建模;强化学习。
方法:PPO;DPO。
跟语言大模型一样,具体可以看对应的论文。
3.模型评估
MM LLM 评估可以根据问题类型大致分为两类:封闭集和开放集。
评估可以看这个:https://github.com/open-compass/VLMEvalKit/blob/main/README_zh-CN.md#data-model-results
(1)封闭集
封闭集问题指的是一种可能答案选项是预定义且有限的问题类型。评估通常在任务特定的数据集上进行。
也就是选择题。
数据集:ScienceQA、MMBench、RealWorldQA。
(2)开放集
与封闭集问题相比,开放集问题的回答更灵活。
因此评测可以分为人工评测、GPT评分和案例研究。
①人工评测
人类评估可以从多个方面对微调后的模型进行评估,例如:
- 相关性:评估模型的响应是否与给定的指令相关。
- 连贯性:评估生成的文本在逻辑上一致且结构良好。
- 流利性:评估生成的响应是否自然并且正确遵循语法规则。
数据集:https://github.com/X-PLUG/mPLUG-Owl/blob/main/mPLUG-Owl/OwlEval/OwlEval.md
②GPT评分
使用GPT代替人工。
③案例研究
专为某一模型设计定性或综合的评估方案。
4.发展方向
(1)粒度深入:朝向像素级定位。
(2)模态扩展:文本、图像、音频、视频等。
(3)多语言:多语言能力。
(4)场景扩展:多端(如手机)部署;垂域模型。
5.多模态幻觉
模型一定会有幻觉。多模态模型幻觉可分为:
(1)存在性幻觉(Existence Hallucination):
这是最基本的形式,指模型错误地声称图像中存在某些物体。
(2)属性性幻觉(Attribute Hallucination):
指错误地描述某些物体的属性,例如未能正确识别狗的颜色。它通常与存在性幻觉相关,因为属性的描述应基于图像中存在的物体。
(3)关系性幻觉(Relationship Hallucination):
这是更复杂的一种类型,也是基于物体的存在。它指的是错误描述物体之间的关系,例如相对位置和互动。
6.幻觉缓解方法
分为预纠正、过程中纠正和后纠正。
(1)预纠正
一种直观而简单的解决幻觉的方法是收集专门的数据(例如,负面数据)并使用这些数据进行微调,从而得到幻觉响应较少的模型。 如 VictorSanh/LrvInstruction
(2)过程中纠正
指改进架构设计或特征表示。这些工作尝试探索幻觉的原因,并设计相应的补救措施,以在生成过程中减轻幻觉。
- HallE-Switch 对物体存在幻觉的可能因素进行了实证分析,并假设存在幻觉源于未被视觉编码器定位的物体,而这些物体实际上是基于嵌入在LLM中的知识推断出来的。基于这一假设,引入了一个连续控制因子和相应的训练方案,以在推理过程中控制模型输出的想象程度。
- VCD 提出物体幻觉源于两个主要原因,即训练语料库中的统计偏差和嵌入在LLM中的强语言先验。作者注意到,当向图像注入噪声时,MLLMs倾向于依赖语言先验而非图像内容进行响应生成,从而导致幻觉。相应地,这项工作设计了一种放大-对比解码方案,以抵消错误的偏差。
(3)后纠正
不同于先前的范式,后纠正以后期补救的方式减轻幻觉,在输出生成后进行纠正。
- Woodpecker 是一种无需训练的通用幻觉纠正框架。具体而言,该方法结合专家模型来补充图像的上下文信息,并设计了一条逐步纠正幻觉的流程。该方法具有可解释性,因为每一步的中间结果都可以检查,且物体是基于图像的。
参考:
1.https://arxiv.org/pdf/2401.13601
2.https://arxiv.org/pdf/2312.16602
3.https://arxiv.org/pdf/2306.13549
4.https://mp.weixin.qq.com/s/a1slqH2ScZnrFmDFpo0R7A
5.https://zhuanlan.zhihu.com/p/684472814
6.https://zhuanlan.zhihu.com/p/688215018
7.https://huggingface.co/spaces/opencompass/open_vlm_leaderboard
8.https://zhuanlan.zhihu.com/p/682893729