LLM 理论知识
LLM 理论知识
- 一.大型语言模型LLM
- 1.1 大型语言模型 LLM 的概念
- 1.2 常见的 LLM 模型
- 1.2.1 闭源 LLM (未公开源代码)
- 1.2.1.1 GPT 系列
- 1.2.1.1.1 ChatGPT
- 1.2.1.1.2 GPT-4
- 1.2.1.2 Claude 系列
- 1.2.1.1.3 PaLM/Gemini 系列
- 1.2.1.1.4 文心一言
- 1.2.1.1.5 星火大模型
- 1.2.2. 开源 LLM
- 1.2.2.1 LLaMA 系列
- 1.2.2.2 通义千问
- 1.2.2.3 GLM 系列
- 1.2.2.4 Baichuan 系列
- 二.检索增强生成RAG
- 2.1 什么是 RAG
- 2.2 RAG 的工作流程
- 2.3 RAG VS Finetune
- 三.LangChain
- 3.1 什么是 LangChain
- 3.2 LangChain 的核心组件
- 四.开发 LLM 应用的整体流程
- 4.1 何为大模型开发
- 4.2 大模型开发的一般流程
- 4.3 搭建 LLM 项目的流程简析(以知识库助手为例)
- 步骤一:项目规划与需求分析
- 1.**项目目标**:基于个人知识库的问答助手
- 2.**核心功能**
- 3.**确定技术架构和工具**
- 步骤二:数据准备与向量知识库构建
- 1.收集和整理用户提供的文档
- 2.将文档词向量化
- 3.将向量化后的文档导入 Chroma 知识库,建立知识库索引
- 步骤三:大模型集成与 API 连接
- 步骤四:核心功能实现
- 步骤五:核心功能迭代优化
- 步骤六:前端与用户交互界面开发
- 步骤七:部署测试与上线
- 步骤八:维护与持续改进
一.大型语言模型LLM
1.1 大型语言模型 LLM 的概念
大语言模型(LLM,Large Language Model),也称大型语言模型,是一种旨在理解和生成人类语言的人工智能模型。
LLM 通常指包含数百亿(或更多)参数的语言模型,它们在海量的文本数据上进行训练,从而获得对语言深层次的理解。
目前,国外的知名 LLM 有 GPT-3.5、GPT-4、PaLM、Claude 和 LLaMA 等,国内的有文心一言、讯飞星火、通义千问、ChatGLM、百川等。
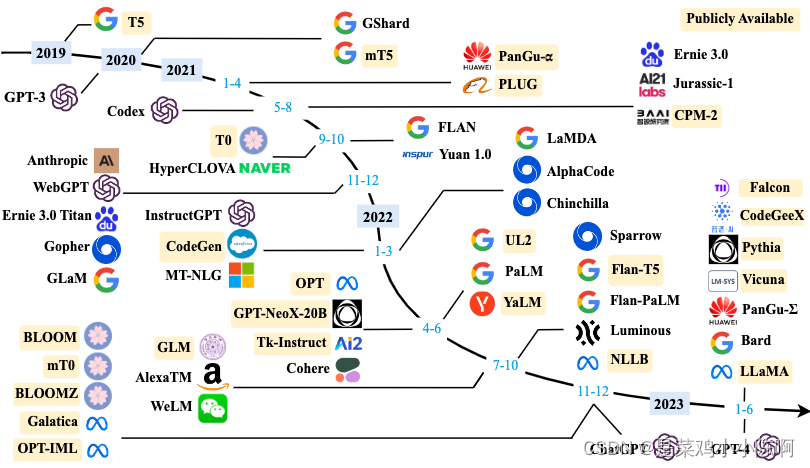
1.2 常见的 LLM 模型
下图按照时间线给出了 2019 年至 2023 年 6 月比较有影响力并且模型参数量超过 100 亿的大语言模型:

主要介绍几个国内外常见的大模型(包括开源和闭源)
1.2.1 闭源 LLM (未公开源代码)
1.2.1.1 GPT 系列
OpenAI 模型介绍
OpenAI 公司在 2018 年提出的 GPT(Generative Pre-Training) 模型是典型的 生成式预训练语言模型 之一。
GPT 模型的基本原则是通过语言建模将世界知识压缩到仅解码器 (decoder-only) 的 Transformer 模型中,这样它就可以恢复(或记忆)世界知识的语义,并充当通用任务求解器。它能够成功的两个关键点:
- 训练能够准确预测下一个单词的 decoder-only 的 Transformer 语言模型
- 扩展语言模型的大小
OpenAI 在 LLM 上的研究大致可以分为以下几个阶段:
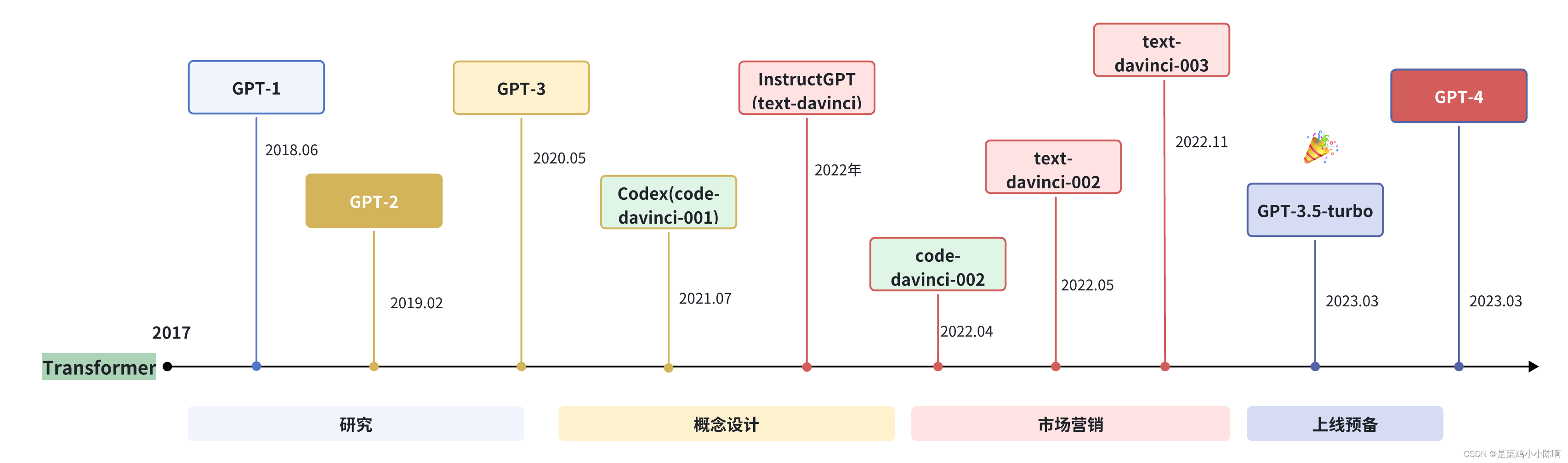
接下来,从模型规模、特点等方面,介绍ChatGPT 与 GPT4:
1.2.1.1.1 ChatGPT
ChatGPT 使用地址
2022 年 11 月,OpenAI 发布了基于 GPT 模型(GPT-3.5 和 GPT-4) 的会话应用 ChatGPT。由于与人类交流的出色能力,ChatGPT 自发布以来就引发了人工智能社区的兴奋。ChatGPT 是基于强大的 GPT 模型开发的,具有特别优化的会话能力。
ChatGPT 从本质上来说是一个 LLM 应用,是基于基座模型开发出来的,与基座模型有本质的区别。其支持 GPT-3.5 和 GPT-4 两个版本。
现在的 ChatGPT 支持最长达 32,000 个字符,知识截止日期是 2021 年 9 月,它可以执行各种任务,包括代码编写、数学问题求解、写作建议等。
1.2.1.1.2 GPT-4
2023 年 3 月发布的 GPT-4,它将文本输入扩展到多模态信号。GPT3.5 拥有 1750 亿 个参数,而 GPT4 的参数量官方并没有公布,但有相关人员猜测,GPT-4 在 120 层中总共包含了 1.8 万亿参数,也就是说,GPT-4 的规模是 GPT-3 的 10 倍以上。因此,GPT-4 比 GPT-3.5 解决复杂任务的能力更强,在许多评估任务上表现出较大的性能提升。
注意:2023 年 11 月 7 日, OpenAI 召开了首个开发者大会,会上推出了最新的大语言模型 GPT-4 Turbo,Turbo 相当于进阶版。它将上下文长度扩展到 128k,相当于 300 页文本,并且训练知识更新到 2023 年 4 月
GPT3.5 是免费的,而 GPT-4 是收费的。需要开通 plus 会员 20 美元/月。
2024 年 5 月 14 日,新一代旗舰生成模型 GPT-4o 正式发布。GPT-4o 具备了对文本、语音、图像三种模态的深度理解能力,反应迅速且富有情感色彩,极具人性化。而且 GPT-4o 是完全免费的,虽然每天的免费使用次数是有限的。
通常可以调用模型 API 来开发自己的应用,主流模型 API 对比如下:
| 语言模型名称 | 上下文长度 | 特点 | input 费用($/million tokens) | output 费用($/ 1M tokens) | 知识截止日期 |
|---|---|---|---|---|---|
| GPT-3.5-turbo-0125 | 16k | 经济,专门对话 | 0.5 | 1.5 | 2021 年 9 月 |
| GPT-3.5-turbo-instruct | 4k | 指令模型 | 1.5 | 2 | 2021 年 9 月 |
| GPT-4 | 8k | 性能更强 | 30 | 60 | 2021 年 9 月 |
| GPT-4-32k | 32k | 性能强,长上下文 | 60 | 120 | 2021 年 9 月 |
| GPT-4-turbo | 128k | 性能更强 | 10 | 30 | 2023 年 12 月 |
| GPT-4o | 128k | 性能最强,速度更快 | 5 | 15 | 2023 年 10 月 |
| Embedding 模型名称 | 维度 | 特点 | 费用($/ 1M tokens) |
|---|---|---|---|
| text-embedding-3-small | 512/1536 | 较小 | 0.02 |
| text-embedding-3-large | 256/1024/3072 | 较大 | 0.13 |
| ada v2 | 1536 | 传统 | 0.1 |
1.2.1.2 Claude 系列
Claude 系列模型是由 OpenAI 离职人员创建的 Anthropic 公司开发的闭源语言大模型。
Claude 使用地址
最早的 Claude 于 2023 年 3 月 15 日发布,在 2023 年 7 月 11 日,更新至 Claude-2, 并在 2024 年 3 月 4 日更新至 Claude-3。
Claude 3 系列包括三个不同的模型,分别是 Claude 3 Haiku、Claude 3 Sonnet 和 Claude 3 Opus,它们的能力依次递增,旨在满足不同用户和应用场景的需求。
| 模型名称 | 上下文长度 | 特点 | input 费用($/1M tokens) | output 费用($/1M tokens) |
|---|---|---|---|---|
| Claude 3 Haiku | 200k | 速度最快 | 0.25 | 1.25 |
| Claude 3 Sonnet | 200k | 平衡 | 3 | 15 |
| Claude 3 Opus | 200k | 性能最强 | 15 | 75 |
1.2.1.1.3 PaLM/Gemini 系列
PaLM 系列语言大模型由 Google 开发。其初始版本于 2022 年 4 月发布,并在 2023 年 3 月公开了 API。2023 年 5 月,Google 发布了 PaLM 2,2024 年 2 月 1 日,Google 将 Bard(之前发布的对话应用) 的底层大模型驱动由 PaLM2 更改为 Gemini,同时也将原先的 Bard 更名为 Gemini。
PaLM 官方地址
Gemini 使用地址
目前的 Gemini 是第一个版本,即 Gemini 1.0,根据参数量不同分为 Ultra, Pro 和 Nano 三个版本。
1.2.1.1.4 文心一言
文心一言使用地址
文心一言是基于百度文心大模型的知识增强语言大模型,于 2023 年 3 月在国内率先开启邀测。文心一言的基础模型文心大模型于 2019 年发布 1.0 版,现已更新到 4.0 版本。
文心一言网页版分为免费版和专业版。
- 免费版使用文心 3.5 版本,已经能够满足个人用户或小型企业的大部分需求。
- 专业版使用文心 4.0 版本。定价为 59.9 元/月,连续包月优惠价为 49.9 元/月
同时也可以使用 API 进行调用(计费详情)。
1.2.1.1.5 星火大模型
星火大模型使用地址
讯飞星火认知大模型是科大讯飞发布的语言大模型,支持多种自然语言处理任务。该模型于 2023 年 5 月首次发布,后续经过多次升级。2023 年 10 月,讯飞发布了讯飞星火认知大模型 V3.0。2024 年 1 月,讯飞发布了讯飞星火认知大模型 V3.5,在语言理解,文本生成,知识问答等七个方面进行了升级,并且支持 system 指令,插件调用等多项功能。
1.2.2. 开源 LLM
1.2.2.1 LLaMA 系列
LLaMA 官方地址
LLaMA 开源地址
LLaMA 系列模型是 Meta 开源的一组参数规模 从 7B 到 70B 的基础语言模型。LLaMA 13B 在 CommonsenseQA 等 9 个基准测试中超过了 GPT-3 (175B),而 LLaMA 65B 与最优秀的模型 Chinchilla-70B 和 PaLM-540B 相媲美。LLaMA 通过使用更少的字符来达到最佳性能,从而在各种推理预算下具有优势。
与 GPT 系列相同,LLaMA 模型也采用了 decoder-only 架构,同时结合了一些前人工作的改进:
Pre-normalization 正则化:为了提高训练稳定性,LLaMA 对每个 Transformer 子层的输入进行了 RMSNorm 归一化,这种归一化方法可以避免梯度爆炸和消失的问题,提高模型的收敛速度和性能;SwiGLU 激活函数:将 ReLU 非线性替换为 SwiGLU 激活函数,增加网络的表达能力和非线性,同时减少参数量和计算量;旋转位置编码(RoPE,Rotary Position Embedding):模型的输入不再使用位置编码,而是在网络的每一层添加了位置编码,RoPE 位置编码可以有效地捕捉输入序列中的相对位置信息,并且具有更好的泛化能力。
LLaMA3 在 LLaMA 系列模型的基础上进行了改进,提高了模型的性能和效率:
-
更多的训练数据量:LLaMA3 在 15 万亿个 token 的数据上进行预训练,相比 LLaMA2 的训练数据量增加了 7 倍,且代码数据增加了 4 倍。LLaMA3 能够接触到更多的文本信息,从而提高了其理解和生成文本的能力。 -
更长的上下文长度:LLaMA3 的上下文长度增加了一倍,从 LLaMA2 的 4096 个 token 增加到了 8192。这使得 LLaMA3 能够处理更长的文本序列,改善了对长文本的理解和生成能力。 -
分组查询注意力(GQA,Grouped-Query Attention):通过将查询(query)分组并在组内共享键(key)和值(value),减少了计算量,同时保持了模型性能,提高了大型模型的推理效率(LLaMA2 只有 70B 采用)。 -
更大的词表:LLaMA3 升级为了 128K 的 tokenizer,是前两代 32K 的 4 倍,这使得其语义编码能力得到了极大的增强,从而显著提升了模型的性能。
1.2.2.2 通义千问
通义千问使用地址
通义千问开源地址
通义千问由阿里巴巴基于“通义”大模型研发,于 2023 年 4 月正式发布。2023 年 9 月,阿里云开源了 Qwen(通义千问)系列工作。2024 年 2 月 5 日,开源了 Qwen1.5(Qwen2 的测试版)。并于 2024 年 6 月 6 日正式开源了 Qwen2。 Qwen2 是一个 decoder-Only 的模型,采用 SwiGLU 激活、RoPE、GQA的架构。中文能力相对来说非常不错的开源模型。
目前,已经开源了 5 种模型大小:0.5B、1.5B、7B、72B 的 Dense 模型和 57B (A14B)的 MoE 模型;所有模型均支持长度为 32768 token 的上下文。并将 Qwen2-7B-Instruct 和 Qwen2-72B-Instruct 的上下文长度扩展至 128K token。
1.2.2.3 GLM 系列
ChatGLM 使用地址
ChatGLM 开源地址
GLM 系列模型是清华大学和智谱 AI 等合作研发的语言大模型。2023 年 3 月 发布了 ChatGLM。6 月发布了 ChatGLM 2。10 月推出了 ChatGLM3。2024 年 1 月 16 日 发布了 GLM4,并于 2024 年 6 月 6 日正式开源。
GLM-4-9B-Chat 支持多轮对话的同时,还具备网页浏览、代码执行、自定义工具调用(Function Call)和长文本推理(支持最大 128K 上下文)等功能。
开源了对话模型 GLM-4-9B-Chat、基础模型 GLM-4-9B、长文本对话模型 GLM-4-9B-Chat-1M(支持 1M 上下文长度)、多模态模型GLM-4V-9B 等全面对标 OpenAI:
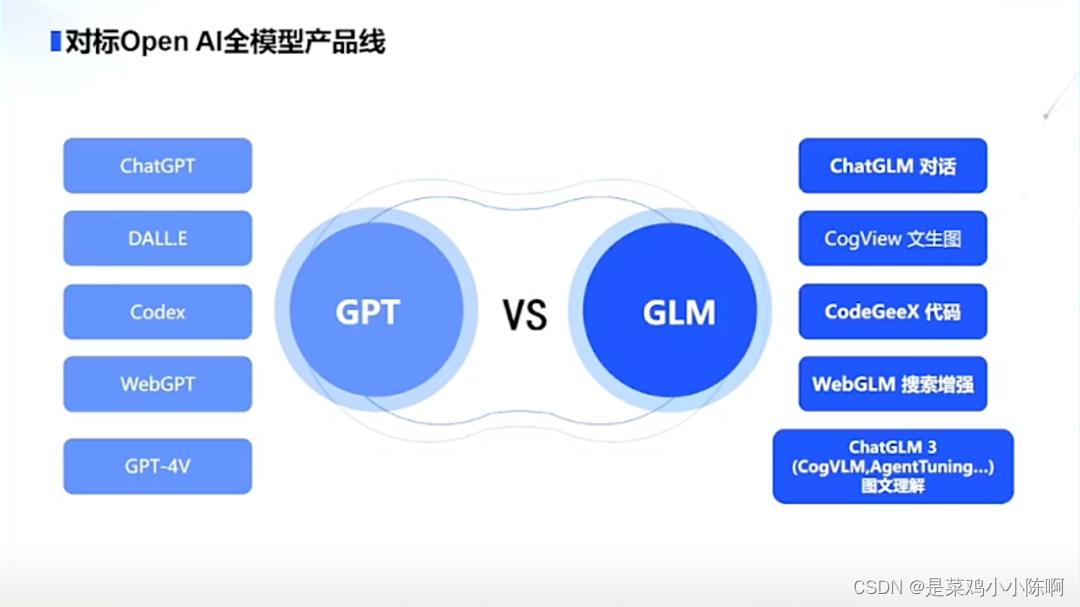
1.2.2.4 Baichuan 系列
百川使用地址
百川开源地址
Baichuan 是由百川智能开发的开源可商用的语言大模型。其基于Transformer 解码器架构(decoder-only)。
2023 年 6 月 15 日发布了 Baichuan-7B 和 Baichuan-13B。百川同时开源了预训练和对齐模型,预训练模型是面向开发者的“基座”,而对齐模型则面向广大需要对话功能的普通用户。
Baichuan2 于 2023年 9 月 6 日推出。发布了 7B、13B 的 Base 和 Chat 版本,并提供了 Chat 版本的 4bits 量化。
2024 年 1 月 29 日 发布了 Baichuan 3。但是目前还没有开源。
二.检索增强生成RAG
2.1 什么是 RAG
大型语言模型(LLM)相较于传统的语言模型具有更强大的能力,然而在某些情况下,它们仍可能无法提供准确的答案。为了解决大型语言模型在生成文本时面临的一系列挑战,提高模型的性能和输出质量,研究人员提出了一种新的模型架构:检索增强生成(RAG, Retrieval-Augmented Generation)。
该架构巧妙地整合了从庞大知识库中检索到的相关信息,并以此为基础,指导大型语言模型生成更为精准的答案,从而显著提升了回答的准确性与深度。
2.2 RAG 的工作流程
RAG 是一个完整的系统,其工作流程可以简单地分为数据处理、检索、增强和生成四个阶段:

- 数据处理阶段
- 对原始数据进行清洗和处理。
- 将处理后的数据转化为检索模型可以使用的格式。
- 将处理后的数据存储在对应的数据库中。
- 检索阶段
- 将用户的问题输入到检索系统中,从数据库中检索相关信息。
- 增强阶段
- 对检索到的信息进行处理和增强,以便生成模型可以更好地理解和使用。
- 生成阶段
- 将增强后的信息输入到生成模型中,生成模型根据这些信息生成答案。
2.3 RAG VS Finetune
在提升大语言模型效果中,RAG 和 微调(Finetune)是两种主流的方法。
微调: 通过在特定数据集上进一步训练大语言模型,来提升模型在特定任务上的表现。
RAG 和 微调的对比可以参考下表(表格来源[1][2])
| 特征比较 | RAG | 微调 |
|---|---|---|
| 知识更新 | 直接更新检索知识库,无需重新训练。信息更新成本低,适合动态变化的数据。 | 通常需要重新训练来保持知识和数据的更新。更新成本高,适合静态数据。 |
| 外部知识 | 擅长利用外部资源,特别适合处理文档或其他结构化/非结构化数据库。 | 将外部知识学习到 LLM 内部。 |
| 数据处理 | 对数据的处理和操作要求极低。 | 依赖于构建高质量的数据集,有限的数据集可能无法显著提高性能。 |
| 模型定制 | 侧重于信息检索和融合外部知识,但可能无法充分定制模型行为或写作风格。 | 可以根据特定风格或术语调整 LLM 行为、写作风格或特定领域知识。 |
| 可解释性 | 可以追溯到具体的数据来源,有较好的可解释性和可追踪性。 | 黑盒子,可解释性相对较低。 |
| 计算资源 | 需要额外的资源来支持检索机制和数据库的维护。 | 依赖高质量的训练数据集和微调目标,对计算资源的要求较高。 |
| 推理延迟 | 增加了检索步骤的耗时 | 单纯 LLM 生成的耗时 |
| 降低幻觉 | 通过检索到的真实信息生成回答,降低了产生幻觉的概率。 | 模型学习特定领域的数据有助于减少幻觉,但面对未见过的输入时仍可能出现幻觉。 |
| 伦理隐私 | 检索和使用外部数据可能引发伦理和隐私方面的问题。 | 训练数据中的敏感信息需要妥善处理,以防泄露。 |
三.LangChain
3.1 什么是 LangChain
LangChain 框架是一个开源工具,充分利用了大型语言模型的强大能力,以便开发各种下游应用。它的目标是为各种大型语言模型应用提供通用接口,从而简化应用程序的开发流程。具体来说,LangChain 框架可以实现数据感知和环境互动,也就是说,它能够让语言模型与其他数据来源连接,并且允许语言模型与其所处的环境进行互动。
利用 LangChain 框架,我们可以轻松地构建如下所示的 RAG 应用(图片来源)。在下图中,每个椭圆形代表了 LangChain 的一个模块,例如数据收集模块或预处理模块。每个矩形代表了一个数据状态,例如原始数据或预处理后的数据。箭头表示数据流的方向,从一个模块流向另一个模块。在每一步中,LangChain 都可以提供对应的解决方案,帮助我们处理各种任务。
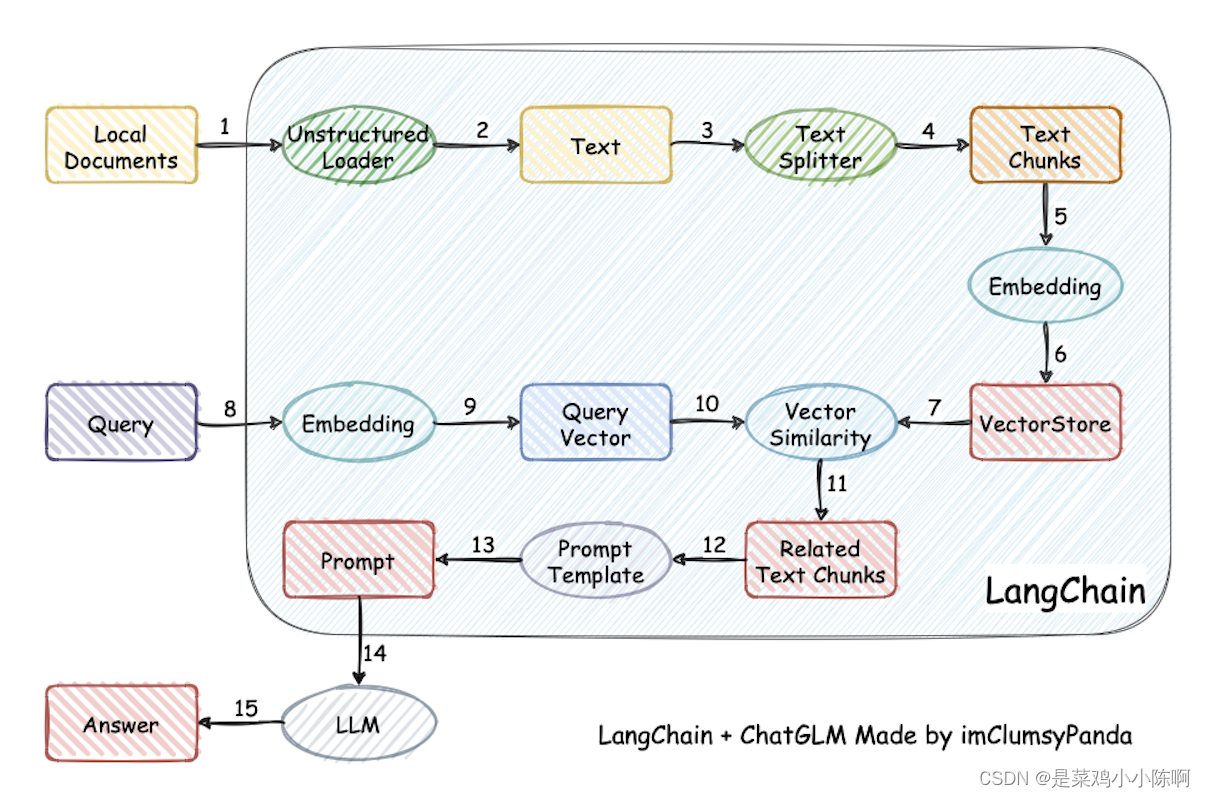
3.2 LangChain 的核心组件
LangChian 作为一个大语言模型开发框架,可以将 LLM 模型(对话模型、embedding 模型等)、向量数据库、交互层 Prompt、外部知识、外部代理工具整合到一起,进而可以自由构建 LLM 应用。 LangChain 主要由以下 6 个核心组件组成:
- 模型输入/输出(Model I/O):与语言模型交互的接口
- 数据连接(Data connection):与特定应用程序的数据进行交互的接口
- 链(Chains):将组件组合实现端到端应用。比如后续我们会将搭建
检索问答链来完成检索问答。 - 记忆(Memory):用于链的多次运行之间持久化应用程序状态;
- 代理(Agents):扩展模型的推理能力。用于复杂的应用的调用序列;
- 回调(Callbacks):扩展模型的推理能力。用于复杂的应用的调用序列;
在开发过程中,我们可以根据自身需求灵活地进行组合。
四.开发 LLM 应用的整体流程
4.1 何为大模型开发
以大语言模型为功能核心、通过大语言模型的强大理解能力和生成能力、结合特殊的数据或业务逻辑来提供独特功能的应用称为大模型开发。开发大模型相关应用,其技术核心点虽然在大语言模型上,但一般通过调用 API 或开源模型来实现核心的理解与生成,通过 Prompt Enginnering 来实现大语言模型的控制,因此,虽然大模型是深度学习领域的集大成之作,大模型开发却更多是一个工程问题。
在大模型开发中,一般不会去大幅度改动模型,而是将大模型作为一个调用工具,通过 Prompt Engineering、数据工程、业务逻辑分解等手段来充分发挥大模型能力,适配应用任务,而不会将精力聚焦在优化模型本身上。
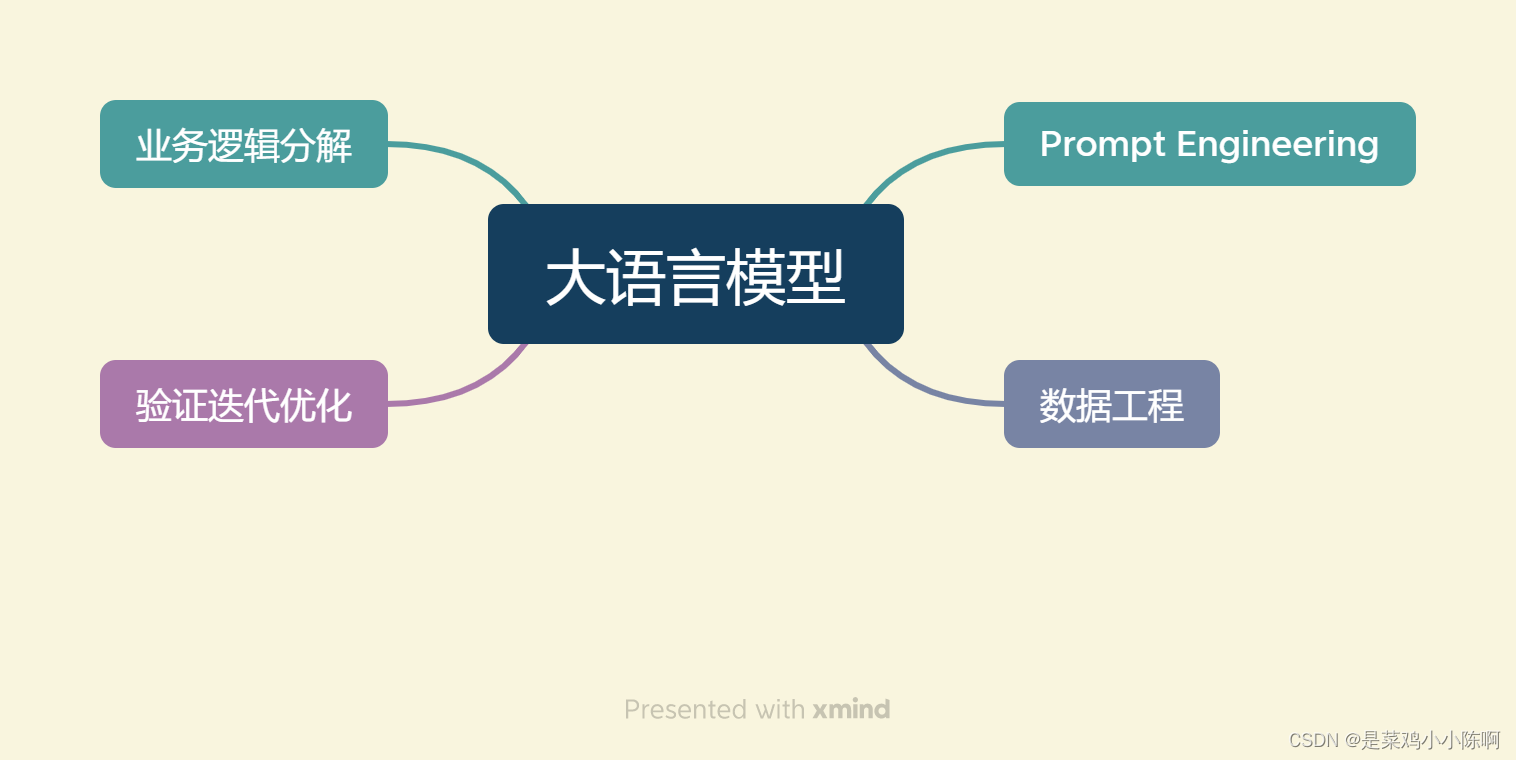
同时,以调用、发挥大模型为核心的大模型开发与传统的 AI 开发在整体思路上有着较大的不同。大语言模型的两个核心能力:指令遵循与文本生成提供了复杂业务逻辑的简单平替方案。
传统的 AI 开发:首先需要将非常复杂的业务逻辑依次拆解,对于每一个子业务构造训练数据与验证数据,对于每一个子业务训练优化模型,最后形成完整的模型链路来解决整个业务逻辑。大模型开发:用 Prompt Engineering 来替代子模型的训练调优,通过 Prompt 链路组合来实现业务逻辑,用一个通用大模型 + 若干业务 Prompt 来解决任务,从而将传统的模型训练调优转变成了更简单、轻松、低成本的 Prompt 设计调优。
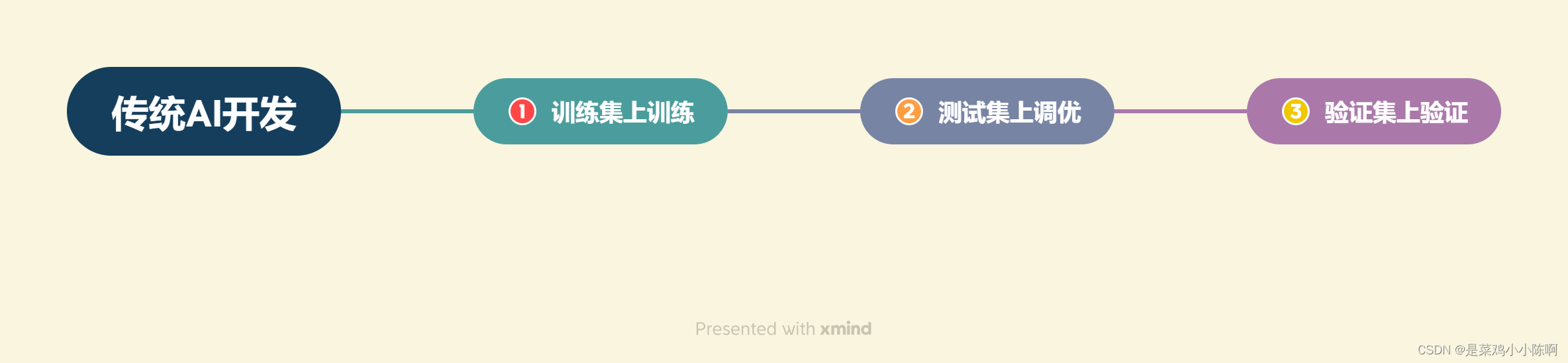
同时,在评估思路上,大模型开发与传统 AI 开发也有质的差异。
传统 AI 开发:需要首先构造训练集、测试集、验证集,通过在训练集上训练模型、在测试集上调优模型、在验证集上最终验证模型效果来实现性能的评估。大模型开发:流程更为灵活和敏捷。从实际业务需求出发构造小批量验证集,设计合理 Prompt 来满足验证集效果。然后,将不断从业务逻辑中收集当下 Prompt 的 Bad Case,并将 Bad Case 加入到验证集中,针对性优化 Prompt,最后实现较好的泛化效果。

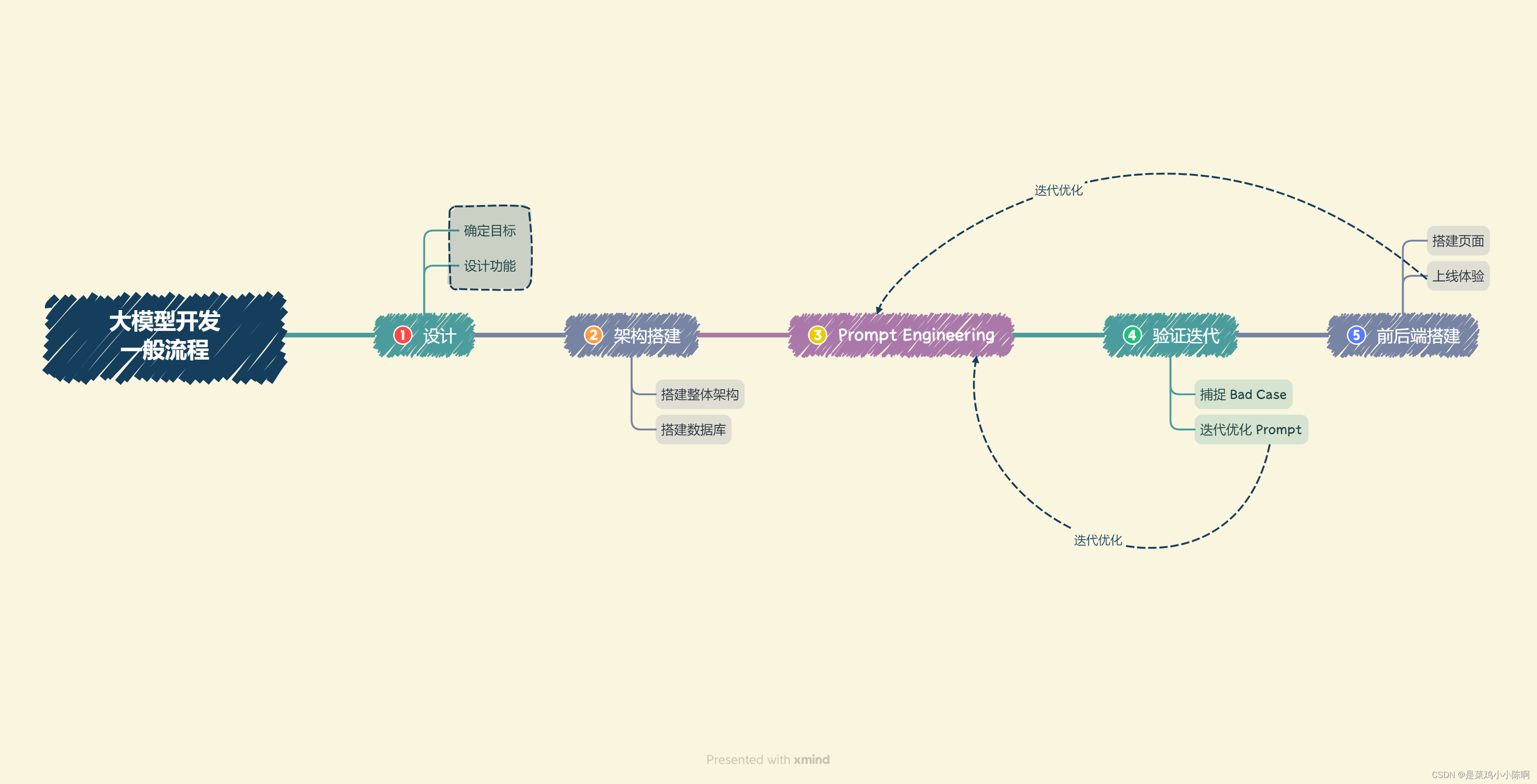
4.2 大模型开发的一般流程
结合上述分析,一般可以将大模型开发分解为以下几个流程:
-
确定目标。
-
设计功能。
-
搭建整体架构。目前,绝大部分大模型应用都是采用的特定数据库 + Prompt + 通用大模型的架构。一般来说,推荐基于 LangChain 框架进行开发。LangChain 提供了 Chain、Tool 等架构的实现,可以基于 LangChain 进行个性化定制,实现从用户输入到数据库再到大模型最后输出的整体架构连接。
-
搭建数据库。个性化大模型应用需要有个性化数据库进行支撑。由于大模型应用需要进行向量语义检索,一般使用诸如 Chroma 的向量数据库。在该步骤中,需要收集数据并进行预处理,再向量化存储到数据库中。数据预处理一般包括从多种格式向纯文本的转化,例如 PDF、MarkDown、HTML、音视频等,以及对错误数据、异常数据、脏数据进行清洗。完成预处理后,需要进行切片、向量化构建出个性化数据库。
-
Prompt Engineering。优质的 Prompt 对大模型能力具有极大影响,需要逐步迭代构建优质的 Prompt Engineering 来提升应用性能。在该步中,首先应该明确 Prompt 设计的一般原则及技巧,构建出一个来源于实际业务的小型验证集,基于小型验证集设计满足基本要求、具备基本能力的 Prompt。
-
验证迭代。验证迭代在大模型开发中是极其重要的一步,一般指通过不断发现 Bad Case 并针对性改进 Prompt Engineering 来提升系统效果、应对边界情况。在完成上一步的初始化 Prompt 设计后,应该进行实际业务测试,探讨边界情况,找到 Bad Case,并针对性分析 Prompt 存在的问题,从而不断迭代优化,直到达到一个较为稳定、可以基本实现目标的 Prompt 版本。
-
前后端搭建。需要搭建前后端,设计产品页面,让我们的应用能够上线成为产品。前后端开发是非常经典且成熟的领域,可以采用 Gradio 和 Streamlit,可以帮助个体开发者迅速搭建可视化页面实现 Demo 上线。
-
体验优化。在完成前后端搭建之后,应用就可以上线体验了。接下来就需要进行长期的用户体验跟踪,记录 Bad Case 与用户负反馈,再针对性进行优化即可。
4.3 搭建 LLM 项目的流程简析(以知识库助手为例)
以下结合本实践项目与上文的整体流程介绍,简要分析知识库助手项目开发流程:
步骤一:项目规划与需求分析
1.项目目标:基于个人知识库的问答助手
2.核心功能
- 将爬取并总结的 MarkDown 文件及用户上传文档向量化,并创建知识库;
- 选择知识库,检索用户提问的知识片段;
- 提供知识片段与提问,获取大模型回答;
- 流式回复;
- 历史对话记录
3.确定技术架构和工具
- 框架:LangChain
- Embedding 模型:GPT、智谱、M3E
- 数据库:Chroma
- 大模型:GPT、讯飞星火、文心一言、GLM 等
- 前后端:Gradio 和 Streamlit
步骤二:数据准备与向量知识库构建
本项目实现原理如下图所示(图片来源):加载本地文档 -> 读取文本 -> 文本分割 -> 文本向量化 -> question 向量化 -> 在文本向量中匹配出与问句向量最相似的 top k 个 -> 匹配出的文本作为上下文和问题一起添加到 Prompt 中 -> 提交给 LLM 生成回答。
1.收集和整理用户提供的文档
用户常用文档格式有 PDF、TXT、MD 等,首先,可以使用 LangChain 的文档加载器模块方便地加载用户提供的文档,或者使用一些成熟的 Python 包进行读取。
由于目前大模型使用 token 的限制,我们需要对读取的文本进行切分,将较长的文本切分为较小的文本,这时一段文本就是一个单位的知识。
2.将文档词向量化
使用文本嵌入(Embeddings)技术对分割后的文档进行向量化,使语义相似的文本片段具有接近的向量表示。然后,存入向量数据库,完成 索引(index) 的创建。
利用向量数据库对各文档片段进行索引,可以实现快速检索。
3.将向量化后的文档导入 Chroma 知识库,建立知识库索引
Langchain 集成了超过 30 个不同的向量数据库。Chroma 数据库轻量级且数据存储在内存中,这使得它非常容易启动和开始使用。
将用户知识库内容经过 Embedding 存入向量数据库,然后用户每一次提问也会经过 Embedding,利用向量相关性算法(例如余弦算法)找到最匹配的几个知识库片段,将这些知识库片段作为上下文,与用户问题一起作为 Prompt 提交给 LLM 回答。
步骤三:大模型集成与 API 连接
- 集成 GPT、星火、文心、GLM 等大模型,配置 API 连接。
- 编写代码,实现与大模型 API 的交互,以便获取问题回答。
步骤四:核心功能实现
- 构建 Prompt Engineering,实现大模型回答功能,根据用户提问和知识库内容生成回答。
- 实现流式回复,允许用户进行多轮对话。
- 添加历史对话记录功能,保存用户与助手的交互历史。
步骤五:核心功能迭代优化
- 进行验证评估,收集 Bad Case。
- 根据 Bad Case 迭代优化核心功能实现。
步骤六:前端与用户交互界面开发
- 使用 Gradio 和 Streamlit 搭建前端界面。
- 实现用户上传文档、创建知识库的功能。
- 设计用户界面,包括问题输入、知识库选择、历史记录展示等。
步骤七:部署测试与上线
- 部署问答助手到服务器或云平台,确保可在互联网上访问。
- 进行生产环境测试,确保系统稳定。
- 上线并向用户发布。
步骤八:维护与持续改进
- 监测系统性能和用户反馈,及时处理问题。
- 定期更新知识库,添加新的文档和信息。
- 收集用户需求,进行系统改进和功能扩展。
整个流程将确保项目从规划、开发、测试到上线和维护都能够顺利进行,为用户提供高质量的基于个人知识库的问答助手。