【初阶数据结构】二叉树(附题)
目录
1.树概念及结构
1.1树的概念
1.2 树的相关概念(树结构的相关概念命名参考自然树和人的血缘关系)
1.3 树的表示
1.4 树在实际中的运用(表示文件系统的目录树结构,初次之外网盘中使用到)
2.二叉树概念及结构
2.1概念
2.2现实中的二叉树:
2.3 特殊的二叉树:
2.4 二叉树的性质
2.5 二叉树的存储结构
1. 顺序存储
2. 链式存储
3 . 二叉树的顺序结构及实现
3 . 1二叉树的顺序结构
3.2 堆的概念及结构
3.3 堆的实现
3.2.1堆的结构体
3.2.2.堆的初始化及销毁
3.2.3 堆的插入
3.2.4.堆的删除
3.2.2堆的创建
3.2.5 堆的删除
3.2.6 堆的代码实现
Heap.h
Heap.c
3.4 堆的应用
3.4.1 堆排序
1. 建堆:
向上建堆算法:
向下建堆算法·:
向上建堆时间复杂度:
向下建堆时间复杂度:
2.利用堆删除思想来进行排序:
3.4.2 TOP-K问题
TOP-K问题:即求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
方法一:
方法二:
总结:总的来说,方法一与方法二的时间差别不带,但是方法二会节省较多的空间。
4.二叉树链式结构的实现
4.2二叉树的遍历
4.2.1 前序、中序以及后序遍历(深度优先遍历)
前序遍历递归图解:
4.2.2 层序遍历(广度优先遍历)
练习:请写出下面的前序/中序/后序/层序遍历:
选择题
题目
答案
4.3 二叉树其他功能实现
4.3.1二叉树节点个数
思路一:遍历
思路二:分治递归
4.3.2.二叉树叶子节点个数
4.3.3.二叉树第k层节点个数
4.3.4.二叉树查找值为x的节点
4.3.5判断二叉树是否是完全二叉树
4.4.6二叉树的高度
4.4 二叉树基础oj练习
1. 单值二叉树。Oj链接
2. 检查两颗树是否相同。OJ链接
3. 对称二叉树。OJ链接
4. 二叉树的前序遍历。 OJ链接
5. 二叉树中序遍历 。OJ链接
6. 二叉树的后序遍历 。OJ链接
7. 另一颗树的子树。OJ链接
4.5 二叉树的创建和销毁
二叉树的构建及遍历。OJ链接
附录:
queue.h
queue.c
1.树概念及结构
1.1树的概念
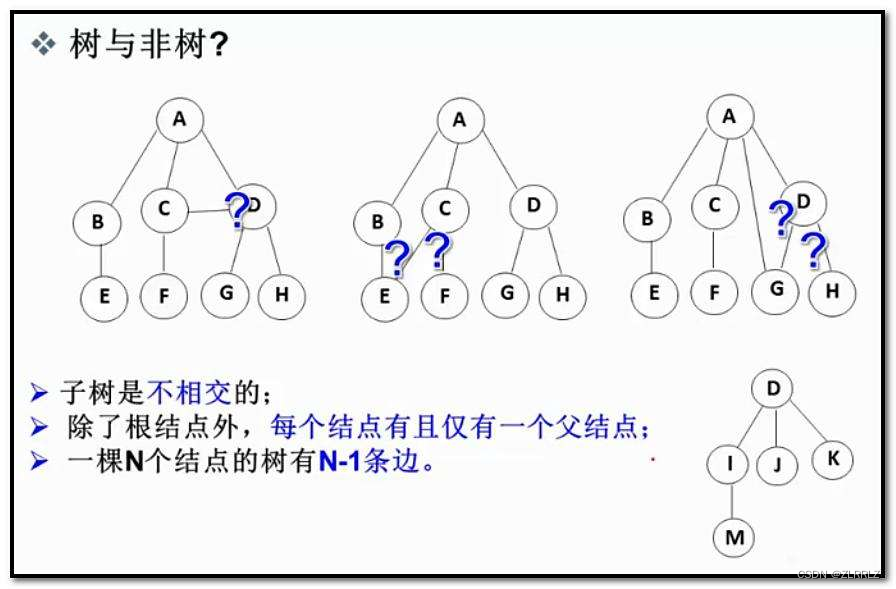
树是一种非线性的数据结构,它是由n(n>=0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
●一个特殊的结点,称为根结点,根结点没有前驱结点。
●除根结点外,其余结点被分成M(M>0)个互不相交的集合T1、T2、……、Tm,其中每一个集合Ti(1又是一棵结构与树类似的子树。每棵子树的根结点有且只有一个前驱,可以有0个或多个后继
(我们发现每一棵树都可以拆成根+N棵子树(N >= 0a),子树又可以拆成根+子树,不断拆,大树变成小树,小树一直拆到根节点。如下图的大树可以拆成根A和B、C、D三棵子树,B树又可以拆成根节点B和E、F两棵树,E树可以拆成根节点E和J树,J树只能拆出根节点J和空树,拆分结束。)
●因此,树是递归(套娃)定义的。

注意:树形结构中,子树之间不能有交集,否则就不是树形结构,而是图结构了。
1.2 树的相关概念(树结构的相关概念命名参考自然树和人的血缘关系)

根节点:一个特殊的结点,称为根结点,根结点没有前驱结点,如上图中的A就是这一棵大树的根节点,需要注意的是某种程度上来说,根节点的概念是相对的,如上图,E节点,我们可以说是绿色范围内这一棵大树的根节点,同样的,J节点我们可以说是橙色范围内这一棵树的根节点。
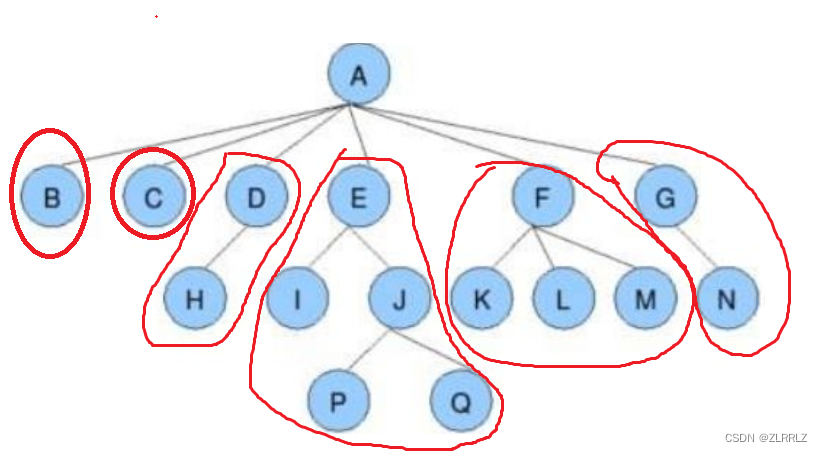
子树:从根节点出发向下延伸出去的不同分支,一个分支就是一颗树;如上图中根节点A向下延伸出去B、C、D、E、F、G这几个分支,每一颗分支就是一棵树。
结点的度:一个结点含有的子树的个数(孩子的个数)称为该结点的度; 如上图:A的为6。
叶结点或终端结点:度为0(没有子树(孩子))的结点称为叶结点; 如上图:B、C、H、I、P、Q、K、M、N等结点没有向下延伸出的子树(孩子),度为0,即为叶结点。
非终端结点或分支结点:度不为0(有子树(孩子))的结点; 如上图:D、E、F、G、J等结点为分支结点
双亲结点或父结点:若一个结点含有子结点,则这个结点称为其子结点的父结点(同人类血缘关系); 如上图:A是B的父结点,J是P的父节点。
孩子结点或子结点:一个结点含有的子树的根结点称为该结点的子结点; 如上图:B是A的孩子结点
兄弟结点:具有相同父结点的结点互称为兄弟结点; 如上图:B、C是兄弟结点,I、J也是兄弟节点。
树的度:一棵树中,最大的结点的度称为树的度; 如上图:A的度最大为6,因此树的度最大为6.
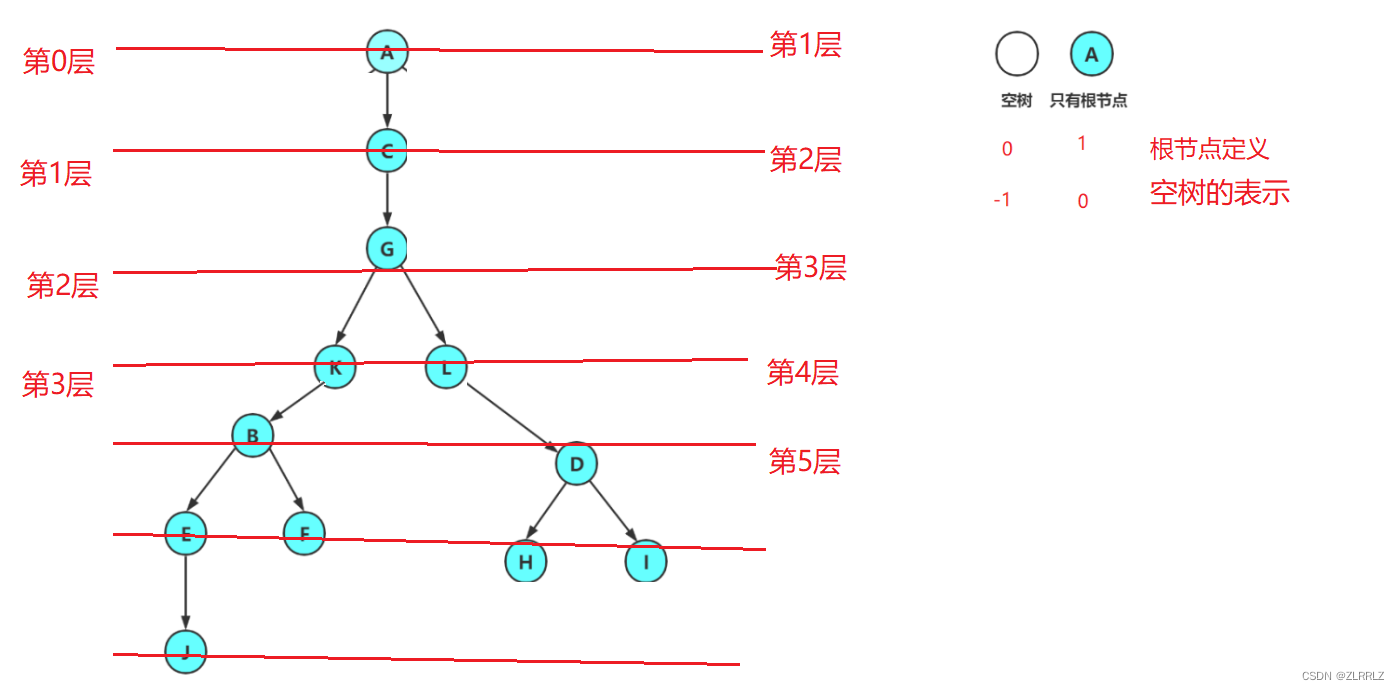
结点的层次:一般从根开始定义起,根为第1层,根的子结点为第2层,以此类推;我们也可以定义根为第0层,根的子结点为第1层,以此类推;不过第二种定义,如果出现空树(没有节点),那么为了表示,我们只能将其定义为-1层,相较于第一种定义可以定义为0层,表示并不好,因此我们正常使用第一种层的定义方法。
树的高度或深度:树中结点的最大层次; 如上图:树的高度为4
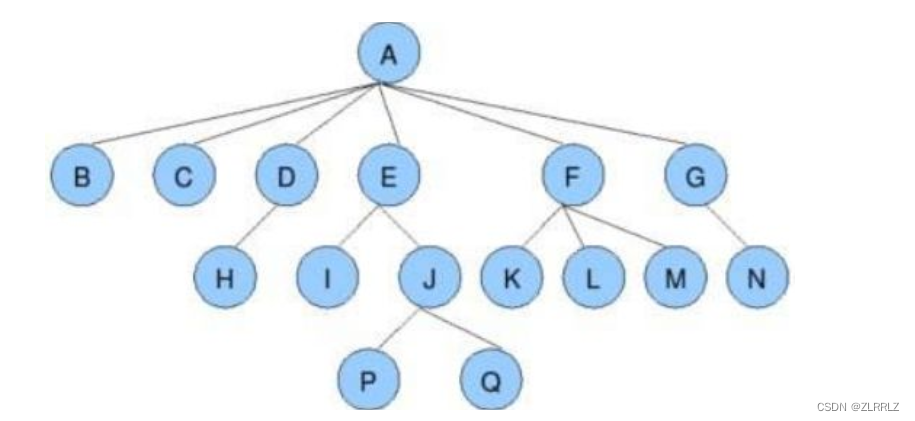
堂兄弟结点:具有的不同父节点在同一层的结点互为堂兄弟;如上图:H、I互为堂兄弟结点,j、k也互为堂兄弟结点。
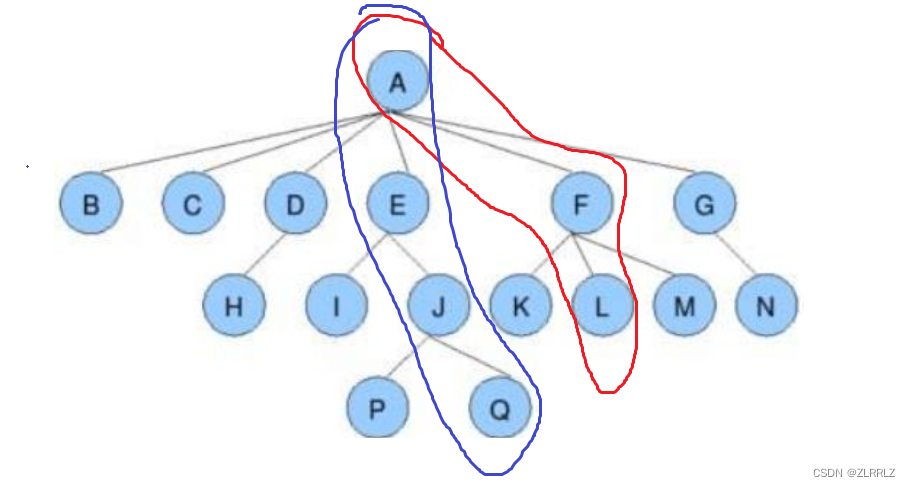
结点的祖先:从根到该结点所经分支上的所有结点(祖先都是该节点的直系血脉亲属);如上图:对于L来说A到L这一分支上,A、F都是祖先,对于Q来说A到Q这一分支,上A、E、J都是祖先,
子孙:以某结点为根的子树中任一结点都称为该结点的子孙。如上图:所有结点都是A的子孙
森林:由m(m>0)棵互不相交的树的集合称为森林,即多棵树就是森林,后期并查集就会使用到森林,除此之外,文件系统使用到森林。
1.3 树的表示
树结构相对线性表就比较复杂了,要存储表示起来就比较麻烦了,既然保存值域,也要保存结点和结点之间 的关系,如果通过顺序结构存储,我们需要将孩子节点存储起来。
//明确树的度是N
#define N 4
struct TreeNode
{int val;struct TreeNode* subs[N];//开辟数组将孩子节点储存起来
};// 如果没有明确树的度
struct TreeNode
{int val;SeqList subs; // C:顺序表内部存struct TreeNode*//vector<struct TreeNode*> subs;//C++:
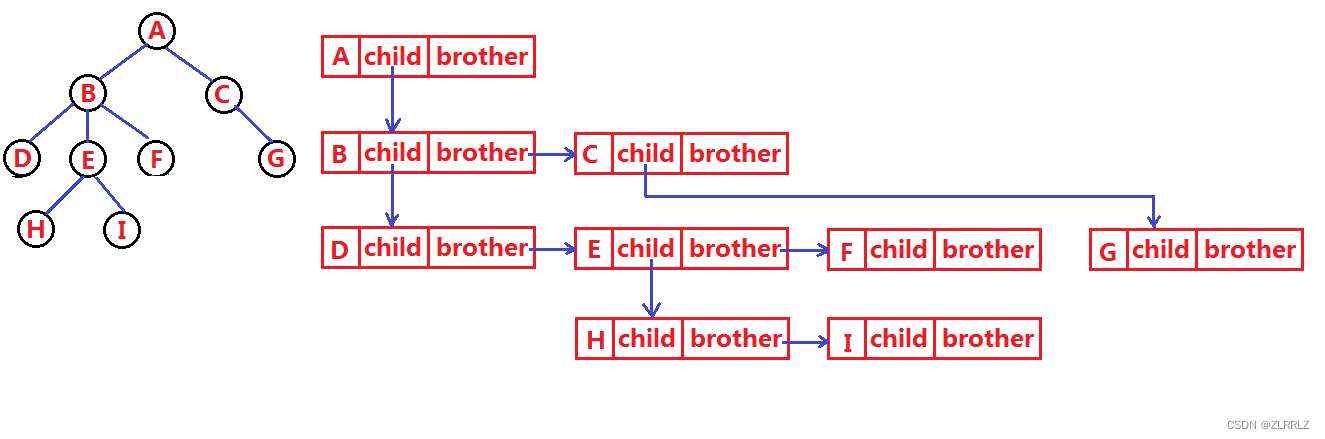
};实际中树有很多链式表示方式如:双亲表示法,孩子表示法、孩子双亲表示法以及孩子兄弟表示法 等。我们这里就简单的了解其中最常用的孩子兄弟表示法。该方法仅仅通过创建两个指针,一带一,就可以表示出整棵树来。需要注意的是该方法中,无论父亲节点有多少孩子,child指向左边开始的第一个孩子。
typedef int DataType;
struct Node
{struct Node* firstChild1; // 第一个孩子结点struct Node* pNextBrother; // 指向其下一个兄弟结点DataType data; // 结点中的数据域
};
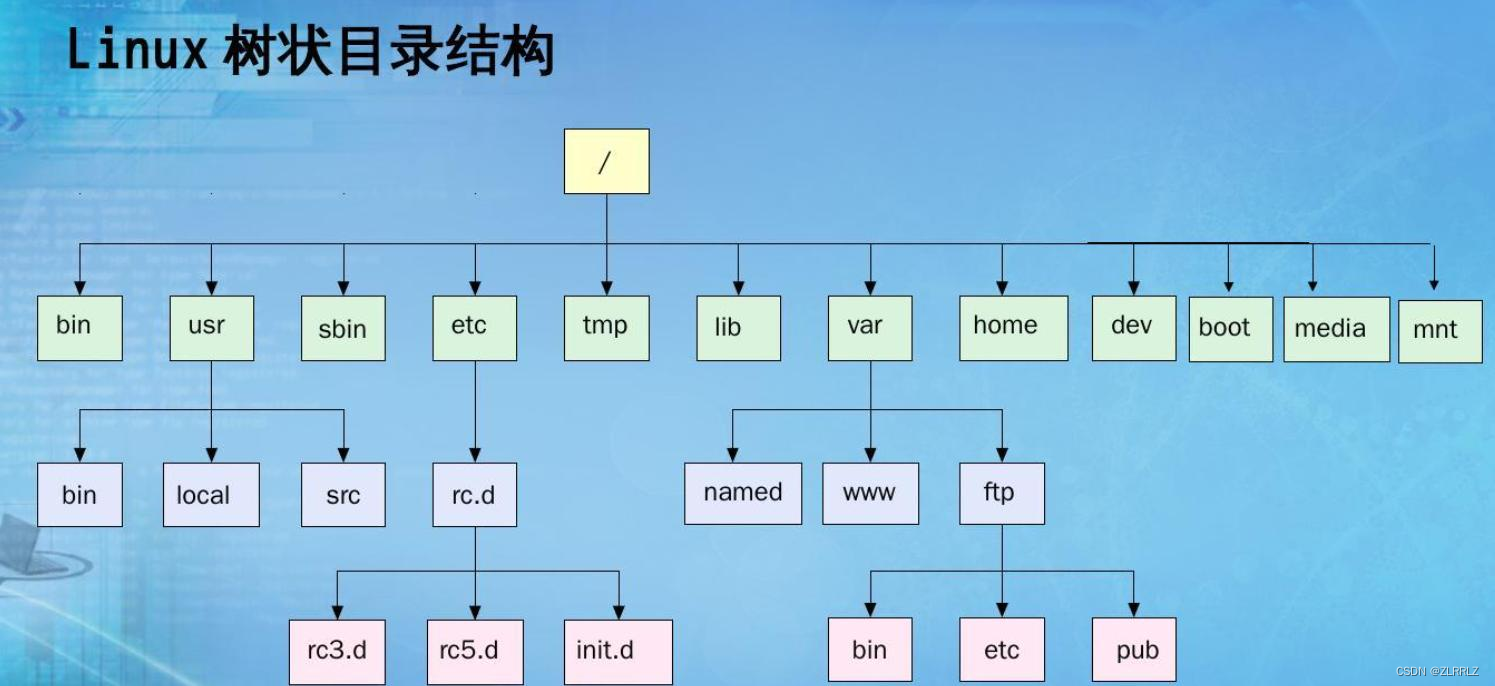
1.4 树在实际中的运用(表示文件系统的目录树结构,初次之外网盘中使用到)
2.二叉树概念及结构
与链表相比,树的结构过于复杂,因此单纯的树正常使用并没有那么多,相反当树的度限制最大为2时,使用更多。
2.1概念
一棵二叉树是结点的一个有限集合,该集合:
1. 或者为空
2. 由一个根结点加上两棵别称为左子树和右子树的二叉树组成

从上图可以看出:
1. 二叉树不存在度大于2的结点
2. 二叉树的子树有左右之分,次序不能颠倒,因此二叉树是有序树
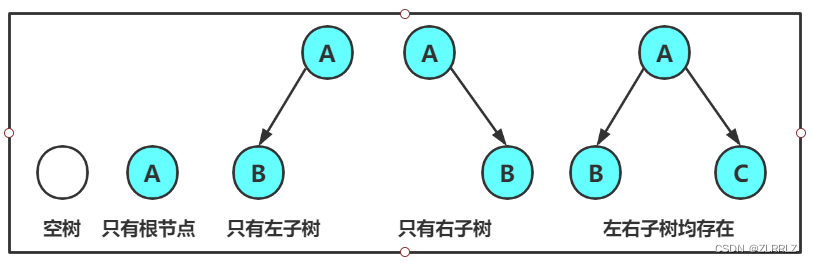
注意:对于任意的二叉树都是由以下几种情况复合而成的:
2.2现实中的二叉树:

2.3 特殊的二叉树:
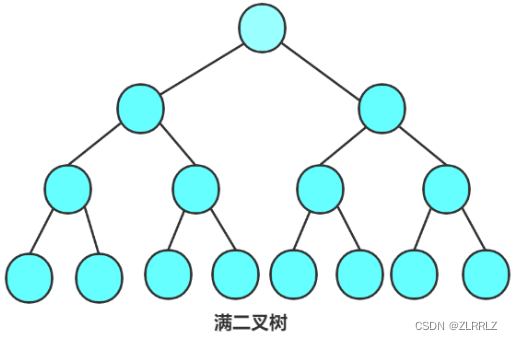
1. 满二叉树:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是 说,如果一个二叉树的层数为K,且结点总数是 ,则它就是满二叉树。
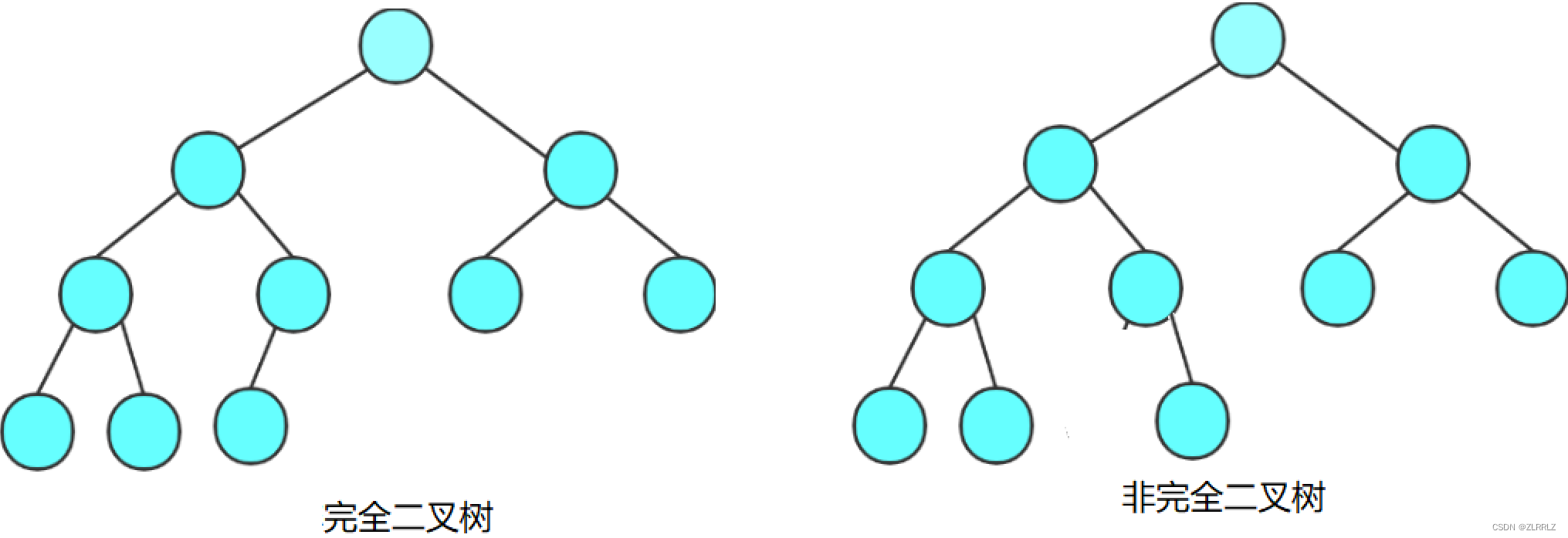
2. 完全二叉树:完全二叉树是效率很高的数据结构,完全二叉树是由满二叉树而引出来的。对于深度为K 的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对应时称之为完全二叉树(最后一层不满,前面层全满,且最后一层节点排布必须是从左到右连续)。 要注意的是满二叉树是一种特殊的完全二叉树。
2.4 二叉树的性质
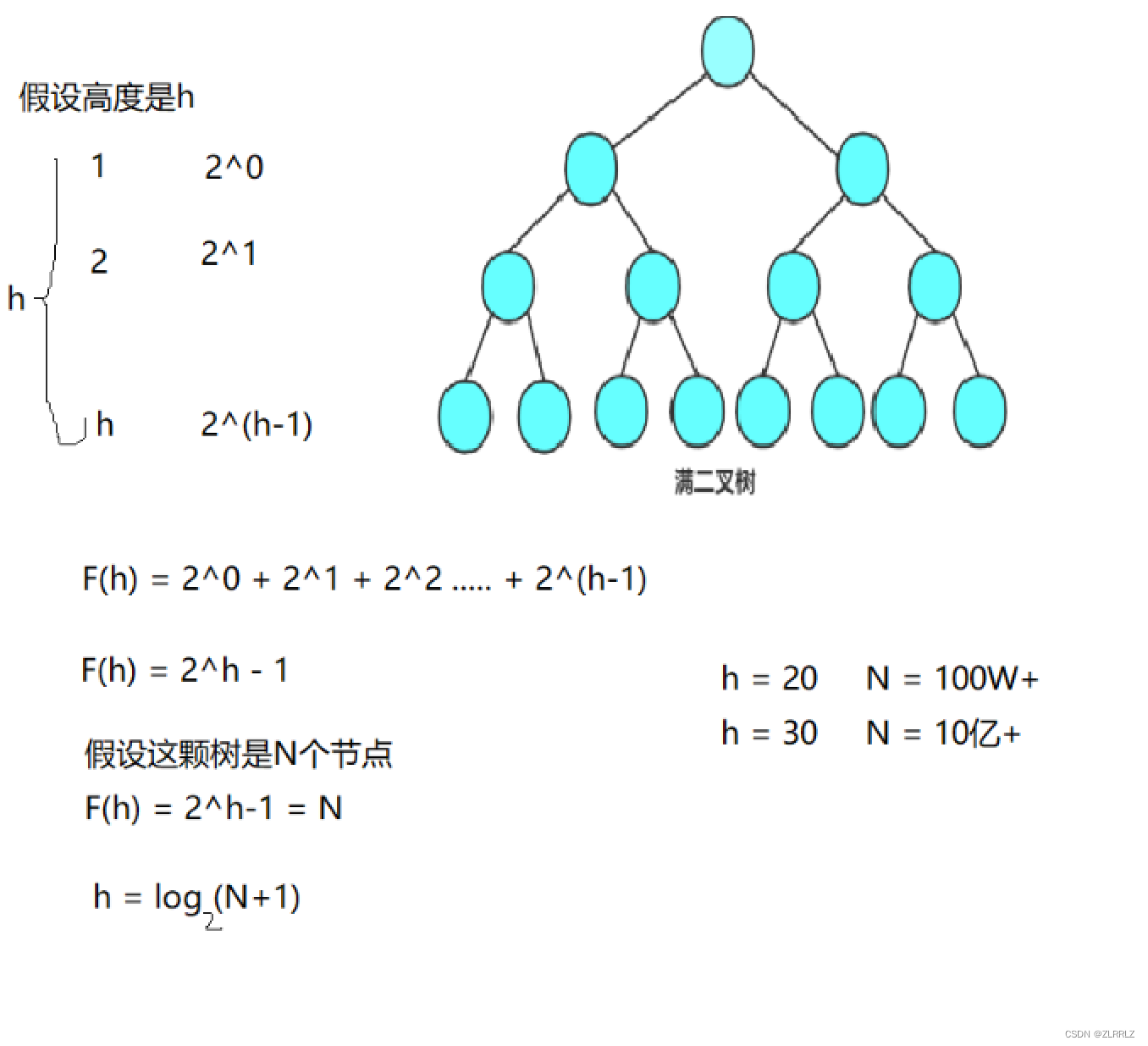
1. 若规定根结点的层数为1,则一棵非空二叉树的第i层上最多有 个结点.
2. 若规定根结点的层数为1,则深度为h的二叉树的最大结点数是 -1(最大情况为满为满二叉树).
3. 对任何一棵二叉树, 如果度为0其叶结点个数为 , 度为2的分支结点个数为
,则有
=
+1
/*
* 假设二叉树有N个结点
* 从总结点数角度考虑:N = n0 + n1 + n2 ①
*
* 从边的角度考虑,N个结点的任意二叉树,总共有N-1条边
* 因为二叉树中每个结点都有父节点,根结点没有父节点,每个节点向上与其双亲之间存在一条边
* 因此N个结点的二叉树总共有N-1条边
* *因为度为0的结点没有孩子,故度为0的结点不产生边; 度为1的结点只有一个孩子,故每个度为1的结点
* 产生一条边; 度为2的结点有2个孩子,故每个度为2的结点产生两条边,所以总边数为: n1+2*n2
* 故从边的角度考虑:N-1 = n1 + 2*n2 ②
* 结合① 和 ②得:n0 + n1 + n2 = n1 + 2*n2 - 1
* 即:n0 = n2 + 1
*/
4. 若规定根结点的层数为1,具有n个结点的满二叉树的深度,h= . (ps: 是log以2 为底,n+1为对数)
5. 对于具有n个结点的完全二叉树,如果按照从上至下从左至右的数组顺序对所有结点从0开始编号,则对 于序号为i的结点有:
1. 若i>0,i位置结点的双亲序号:(i-1)/2;i=0,i为根结点编号,无双亲结点
2. 若2i+1,左孩子序号:2i+1,2i+1>=n否则无左孩子
3. 若2i+2,右孩子序号:2i+2,2i+2>=n否则无右孩子
1. 某二叉树共有 399 个结点,其中有 199 个度为 2 的结点,则该二叉树中的叶子结点数为( )
A 不存在这样的二叉树
B 200
C 198
D 199
2.下列数据结构中,不适合采用顺序存储结构的是( )
A 非完全二叉树
B 堆
C 队列
D 栈
3.在具有 2n 个结点的完全二叉树中,叶子结点个数为( )
A n
B n+1
C n-1
D n/2
4.一棵完全二叉树的结点数位为531个,那么这棵树的高度为( )
A 11
B 10
C 8
D 12
5.一个具有767个结点的完全二叉树,其叶子结点个数为()
A 383
B 384
C 385
D 386
答案:
1.B
2.A
3.A
4.B
5.B
2.5 二叉树的存储结构
二叉树一般可以使用两种结构存储,一种顺序结构(因为二叉树的度最大不超过2,因此使用顺序结构存储也挺好的),一种链式结构。
1. 顺序存储
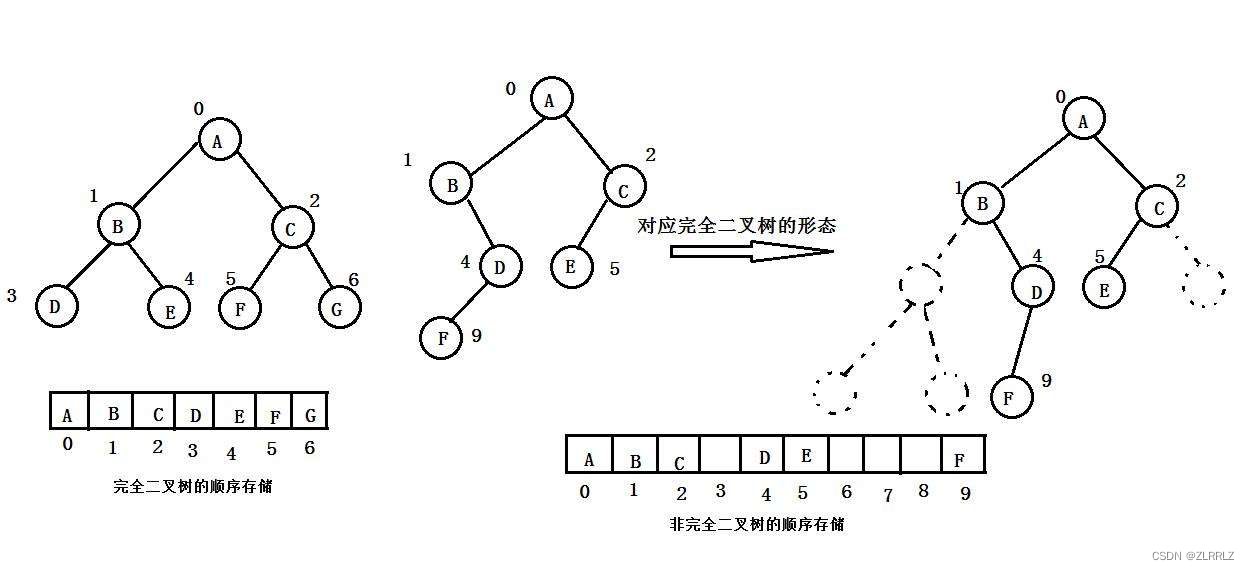
顺序结构存储就是使用数组来存储,一般使用数组只适合表示完全二叉树。二叉树顺序存储在物理上是一个数组,在逻辑上是一颗二叉树(逻辑和物理分离)。不同数据之间存在逻辑上的空间关系,因此根据数据间父子关系,我们知道父子间任意一者的关系,我们就可以求出另一方的数组下标。需要说明的是,当我们知道两个孩子其中一个时,求父亲下标,统一使用孩子下标减一除二就可以了,无论是左孩子(下标为奇数)还是右孩子(下标为偶数),因为int类型做除法时,会自动取整,因此小数部分会舍去。

不是完全二叉树也可以使用顺序结构来表示,不过为了保持顺序结构中父子下标的对应关系,我们需要将非完全二叉树补全,不足的地方用空代替,因此会有空间的浪费。
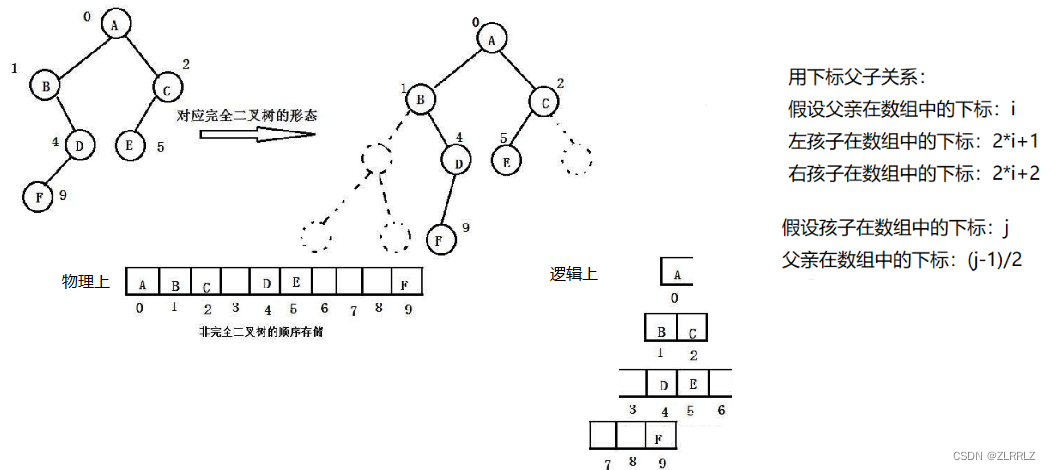
而现实中使用中只有堆才会使用数组来存储,关于堆后面会专门讲解。
2. 链式存储
二叉树的链式存储结构是指,用链表来表示一棵二叉树,即用链来指示元素的逻辑关系。 通常的方法是 链表中每个结点由三个域组成,数据域和左右指针域,左右指针分别用来给出该结点左孩子和右孩子所在的链结点的存储地址。链式结构又分为二叉链和三叉链,当前初阶结构学习中一般都是二叉链,高阶数据结构如红黑树等会用到三叉链。

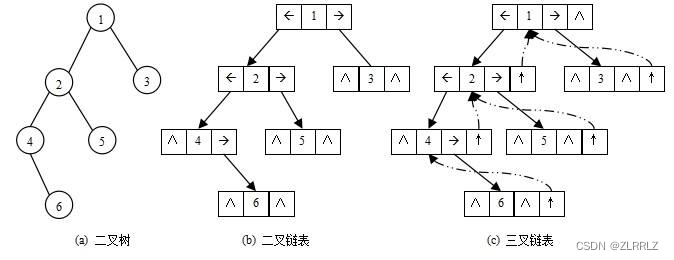
typedef int BTDataType;
//二叉链
struct BinaryTreeNode
{
struct BinaryTreeNode*left;//指向当前节点的左孩子
struct BinaryTreeNode*right;//指向当前节点的右孩子
BTDataType data;//当前节点的值};//三叉链
struct BinaryTreeNode
{
struct BinaryTreeNode*parent;//指向当前节点的双亲
struct BinaryTreeNode*left;//指向当前节点的左孩子
struct BinaryTreeNode*right;//指向当前节点的右孩子
BTDataType data;//当前节点的值};3 . 二叉树的顺序结构及实现
3 . 1二叉树的顺序结构
普通的二叉树是不适合用数组来存储的,因为可能会存在大量的空间浪费。而完全二叉树更适合使用顺序结 构存储。现实中我们通常把堆(一种二叉树)使用顺序结构的数组来存储,需要注意的是这里的堆和操作系统 虚拟进程地址空间中的堆是两回事,一个是数据结构,一个是操作系统中管理内存的一块区域分段。
3.2 堆的概念及结构
如果有一个关键码的集合K = { ,
,
,…,
},把它的所有元素按完全二叉树的顺序存储方式存储在一个一维数组中,并满足:
且
(
且
)i = 0,1, 2…,则称为小堆(或大堆)。将根结点最大的堆叫做最大堆或大根堆,根结点最小的堆叫做最小堆或小根堆。
堆的性质:
堆中某个结点的值总是不大于或不小于其父结点的值;
堆总是一棵完全二叉树。

需要注意的是对于堆来说,只有父子之间有明确的大小关系,因此堆内数据不一定是有序的(数据巧的话会有序。)
3.3 堆的实现
3.2.1堆的结构体
typedef int HPDataType;
typedef struct Heap
{HPDataType* _a;//使用顺序结构来维护堆int _size;//数据个数int _capacity;//数组的容量
}HP;3.2.2.堆的初始化及销毁
//堆的初始化
void HeapInit(HP* php)
{assert(php);php->_a = NULL;php->_capacity = php->_size = 0;}// 堆的销毁
void HeapDestory(HP* hp)
{assert(hp);free(hp->_a);hp->_a = NULL;hp->_capacity = hp->_size = 0;}3.2.3 堆的插入
当我们进行堆的插入时,当我们插入一个数据之后,这时的数组并不一定是堆,这个插入的数据可能很大,也可能很小,因此我们需要进行向上调整算法。
向上调整算法:向上不断比较孩子与父亲大小,小堆中(大堆中),将小(大)的节点充当父亲大(小)的节点充当孩子,直到所有节点满足小堆(大堆)的性质,或者插入的数据成为新的堆顶的数据。(使用向上调整的原数组必须是堆才有意义。)(数据最多挪动高度次,时间复杂度为)
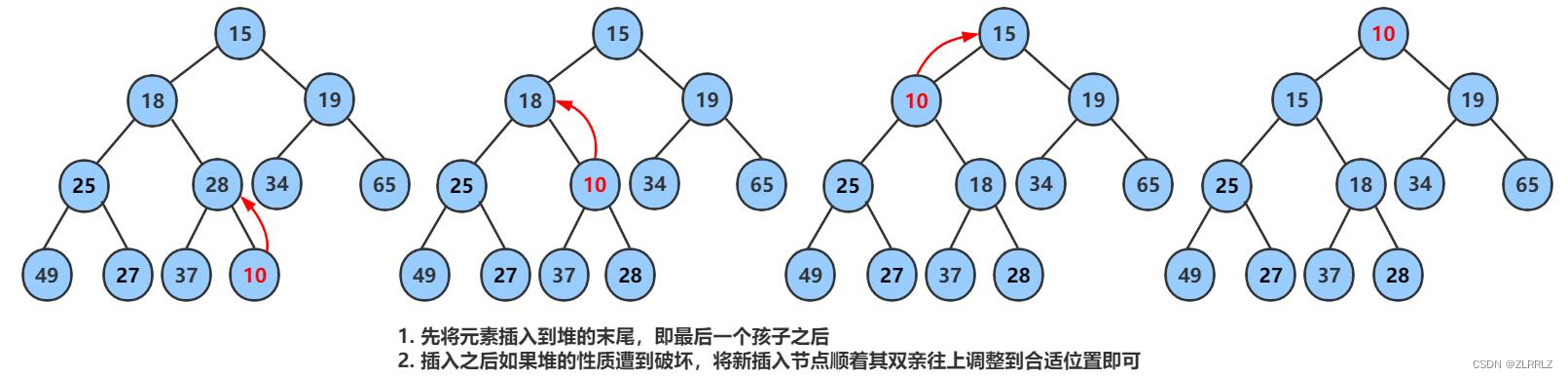
//交换
void Swap(HPDataType* a, HPDataType* b)
{HPDataType temp = *a;*a = *b;*b = temp;}
//向上调整算法
void AdjustUp(HPDataType* a, int child)传入存储堆的数组以及调整数据下表
{assert(a);int parent = (child - 1) / 2;//调整数据的父亲下标while (child > 0){if (a[child] < a[parent]){Swap(&a[child], &a[parent]);//当前展示堆为小堆,孩子小于父亲,进行交换child = parent;parent = (child - 1) / 2;}else//如果不小于,符合堆的父子关系,退出循环{break;}}
}需要注意的是使用向上调整算法,循环的判断条件,我们不能使用parent>=0来作为判断条件,因为当child为0的情况,由于int除法取整,parent是不会出现为负数的情况(虽然child与parent在同一处,最终会由于值相同break出来,但是这样的逻辑不好)
// 堆的插入
void HeapPush(HP* hp, HPDataType x)
{assert(hp);if (hp->_capacity == hp->_size)//首先判断堆的空间是否足够新输入的插入{int newcapacity = hp->_capacity == 0 ? 4 : 2 * hp->_capacity;HPDataType* newnode = (HPDataType*)realloc(hp->_a, newcapacity * sizeof(HPDataType));if (NULL == newnode){perror("StackInit:realloc");exit(1);}hp->_a = newnode;hp->_capacity = newcapacity;}hp->_a[hp->_size] = x;//插入数据、相关信息更新hp->_size++;AdjustUp(hp->_a, hp->_size - 1);}3.2.4.堆的删除
对于堆的删除,由于堆顶的数据最大或最小的特性(兄弟节点之间关系不确定),所以只有对于堆顶的数据的删除是有意义的。此外,直接删除堆顶的数据,在将后面的数据向前挪动的操作是不行的,因为直接的挪动,原有的数据之间的父子关系会全部乱掉,重新建堆代价较大。

因此删除操作时将堆顶的数据跟最后一个数据一换,然后删除数组最后一个数据,再进行向下调整算法。
向下调整算法:将待调整数据与其孩子进行比较,小堆中(大堆中),将小(大)的节点充当父亲大(小)的节点充当孩子,直到所有节点满足小堆(大堆)的性质,或者调整数据到达堆底(成为叶节点)。(使用向下调整的原数组必须是堆才有意义。)(数据最多挪动高度次,时间复杂度为)
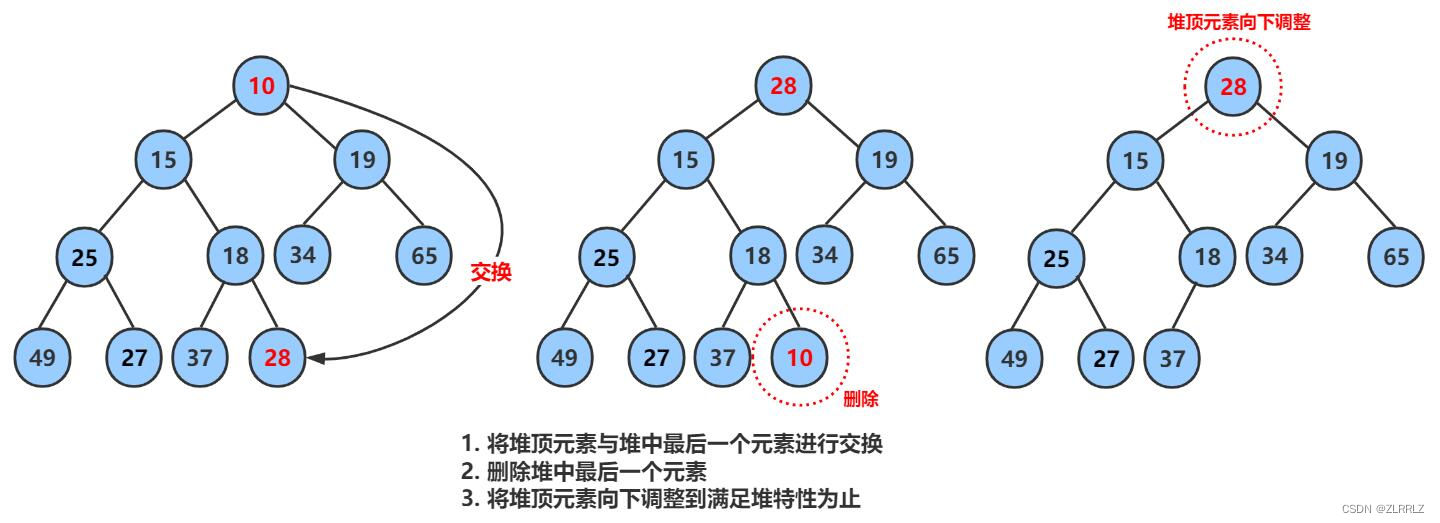
//向下调整算法
void AdjustDown(HPDataType* a, int n, int parent)
{assert(a);int child = parent * 2 + 1;//为了方便比较先假设左孩子比右孩子小while (child < n)// child >= n说明孩子不存在,调整到叶子了{if(child + 1 < n && a[child] < a[child + 1])//比较左右孩子的大小{ //比较时候下标不能越界child = child + 1;}if(a[child] > a[parent])//调整{Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}}
// 堆的删除
void HeapPop(HP* hp)
{assert(hp);assert(hp->_size > 0);Swap(&hp->_a[0],&hp->_a[hp->_size - 1]);//交换首尾数据hp->_size--;//删除数据AdjustDown(hp->_a, hp->_size, 0);调整数组} 3.2.2堆的创建
现在我们给出一个数组,逻辑上看做一颗完全二叉树。我们通过从根结点开始的向下调整算法可以把它调整成一个小堆。向下调整算法有一个前提:左右子树必须是一个堆,才能调整。我们将堆顶
int array[] = {27,15,19,18,28,34,65,49,25,37};
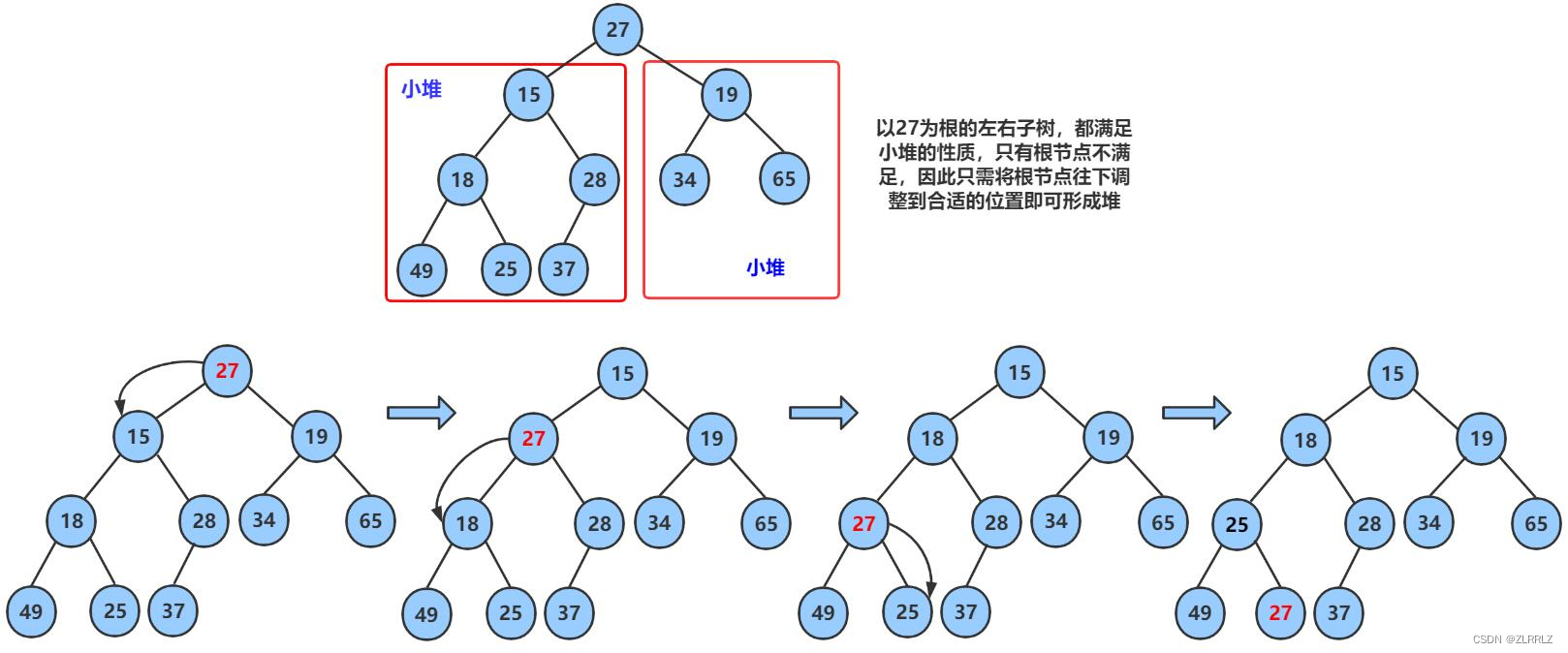
下面我们给出一个数组,这个数组逻辑上可以看做一颗完全二叉树,但是还不是一个堆,现在我们通过算法,把它构建成一个堆。根结点左右子树不是堆,我们怎么调整呢?这里我们从倒数的第一个非叶子结点的子树开始调整,一直调整到根结点的树,就可以调整成堆。
int a[] = {1,5,3,8,7,6};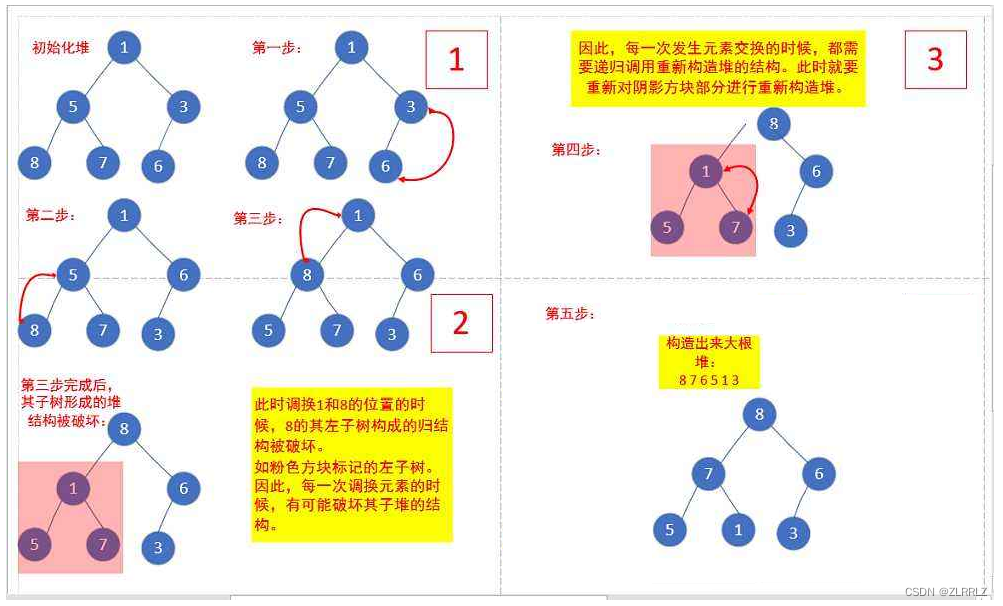
3.2.5 堆的删除
删除堆是删除堆顶的数据,将堆顶的数据根最后一个数据一换,然后删除数组最后一个数据,再进行向下调 整算法。

3.2.6 堆的代码实现
Heap.h
#pragma once
#define _CRT_SECURE_NO_WARNINGS 1
#include<assert.h>
#include<stdio.h>
#include<stdlib.h>typedef int HPDataType;
typedef struct Heap
{HPDataType* _a;int _size;int _capacity;
}HP;//堆的初始化
void HeapInit(HP* php);void HeapSort(int* a, int n);// 堆的销毁
void HeapDestory(HP* hp);// 堆的插入
void HeapPush(HP* hp, HPDataType x);//向上调整算法
void AdjustUp(HPDataType* a, int child);//向下调整算法
void AdjustDown(HPDataType* a, int n, int parent);//交换
void Swap(int* a, int* b);// 堆的删除
void HeapPop(HP* hp);// 取堆顶的数据
HPDataType HeapTop(HP* hp);// 堆的数据个数
int HeapSize(HP* hp);// 堆的判空
int HeapEmpty(HP* hp);Heap.c
#include"Heap.h"//堆的初始化
void HeapInit(HP* php)
{assert(php);php->_a = NULL;php->_capacity = php->_size = 0;}// 堆的销毁
void HeapDestory(HP* hp)
{assert(hp);free(hp->_a);hp->_a = NULL;hp->_capacity = hp->_size = 0;}//交换
void Swap(HPDataType* a, HPDataType* b)
{HPDataType temp = *a;*a = *b;*b = temp;}//向上调整算法
void AdjustUp(HPDataType* a, int child)
{assert(a);int parent = (child - 1) / 2;while (child > 0){if (a[child] > a[parent]){Swap(&a[child], &a[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}
}// 堆的插入
void HeapPush(HP* hp, HPDataType x)
{assert(hp);if (hp->_capacity == hp->_size){int newcapacity = hp->_capacity == 0 ? 4 : 2 * hp->_capacity;HPDataType* newnode = (HPDataType*)realloc(hp->_a, newcapacity * sizeof(HPDataType));if (NULL == newnode){perror("StackInit:realloc");exit(1);}hp->_a = newnode;hp->_capacity = newcapacity;}hp->_a[hp->_size] = x;hp->_size++;AdjustUp(hp->_a, hp->_size - 1);}//向下调整算法
void AdjustDown(HPDataType* a, int n, int parent)
{assert(a);int child = parent * 2 + 1;while (child < n){if(child + 1 < n && a[child] < a[child + 1]){child = child + 1;}if(a[child] > a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}} // 堆的删除
void HeapPop(HP* hp)
{assert(hp);assert(hp->_size > 0);Swap(&hp->_a[0],&hp->_a[hp->_size - 1]);hp->_size--;AdjustDown(hp->_a, hp->_size, 0);}// 取堆顶的数据
HPDataType HeapTop(HP* hp)
{assert(hp);assert(hp->_size > 0);return hp->_a[0];
}// 堆的数据个数
int HeapSize(HP* hp)
{assert(hp);return hp->_size;
}// 堆的判空
int HeapEmpty(HP* hp)
{assert(hp);return hp->_size == 0;}3.4 堆的应用
3.4.1 堆排序
在实际运用中,对于现有的数据,如果我们通开辟新数组再使用堆的插入来进行建堆,相对来说代价较大,所以我们通常直接在原数组上建堆,而堆排序即利用堆的思想,先对原数组建堆,再排序,总共分为两个步骤:
1. 建堆:
下面我们给出一个数组,这个数组逻辑上可以看做一颗完全二叉树,但是还不是一个堆,现在我们通过算法,把它构建成一个堆。根结点左右子树不是堆,我们怎么调整呢?这里我们从倒数的第一个非叶子结点的子树开始调整,一直调整到根结点的树,就可以调整成堆。
int a[] = {1,5,3,8,7,6}; 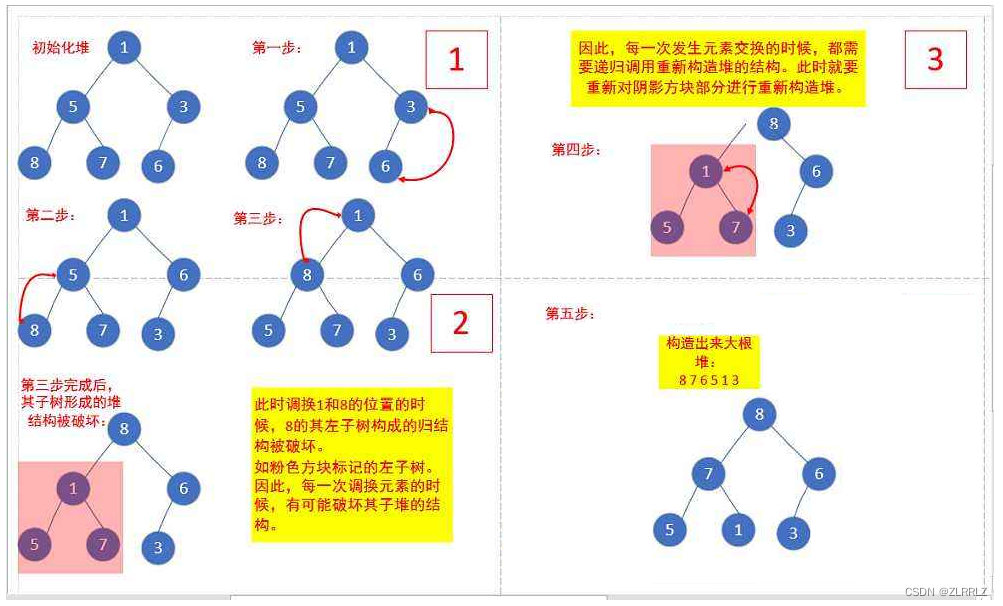
向上建堆算法:
向上调整从整棵树的根节点向后的所有节点(根节点没有父亲,相当于已经向上调整完毕),这样所有节点都调整后,就近似可以看成所有节点都相互比较过,小堆中把小的数据往上调,大堆中把大堆数据往上调,使父子之间的关系满足堆的要求,堆就建好了。
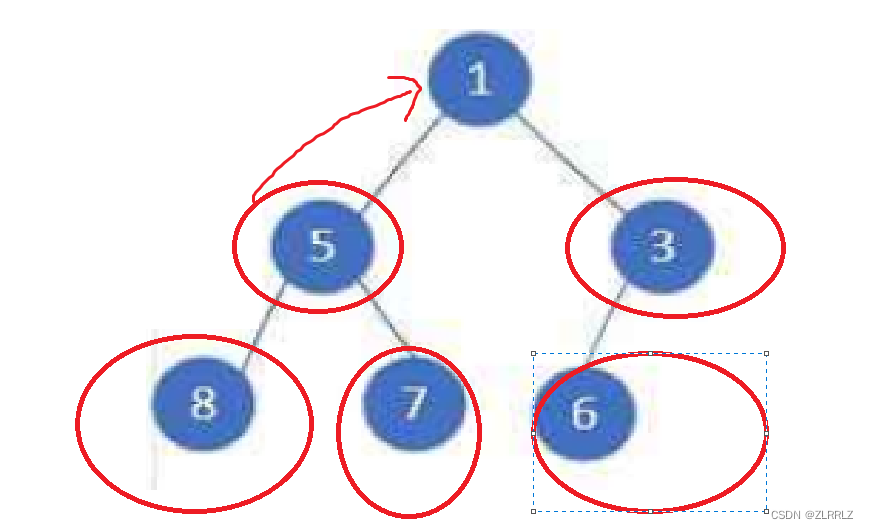
for(int i = 1;i < n;i++){AdjustUp(a, i);}向下建堆算法·:
向下调整从整棵树的最底层最右边节点的父节点(倒数第一个非叶子节点)开始向前的所有节点(向下调整前提是该节点的左右子树必须是堆,因此不能是从根节点开始向下调整,这没有意义。最底层的叶节点没有孩子,相当于已经向下调整完毕,是堆。),这样所有节点都调整后,就近似可以看成所有节点都相互比较过,小堆中把小的数据往上调,大堆中把大堆数据往上调,使父子之间的关系满足堆的要求,堆就建好了。
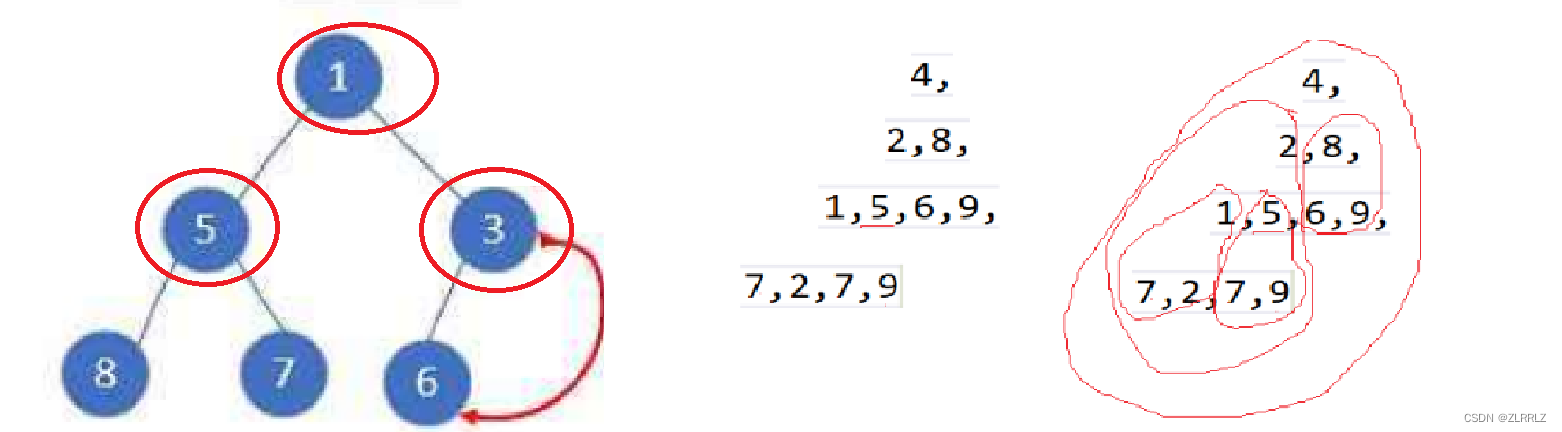
for(int i = (n - 2) / 2;i >= 0;i--){AdjustDown(a,n,i);}向上建堆时间复杂度:
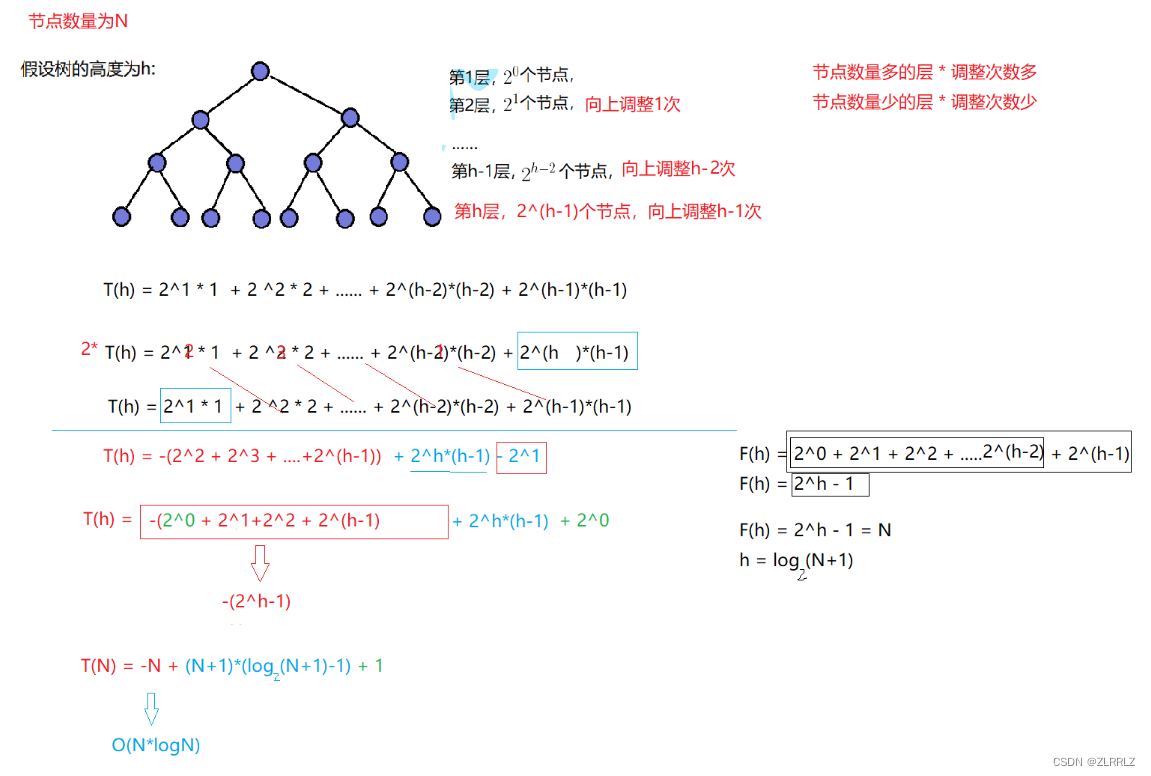
向下建堆时间复杂度: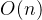
因为堆是完全二叉树,而满二叉树也是完全二叉树,此处为了简化使用满二叉树来证明(时间复杂度本来看的 就是近似值,多几个结点不影响最终结果):
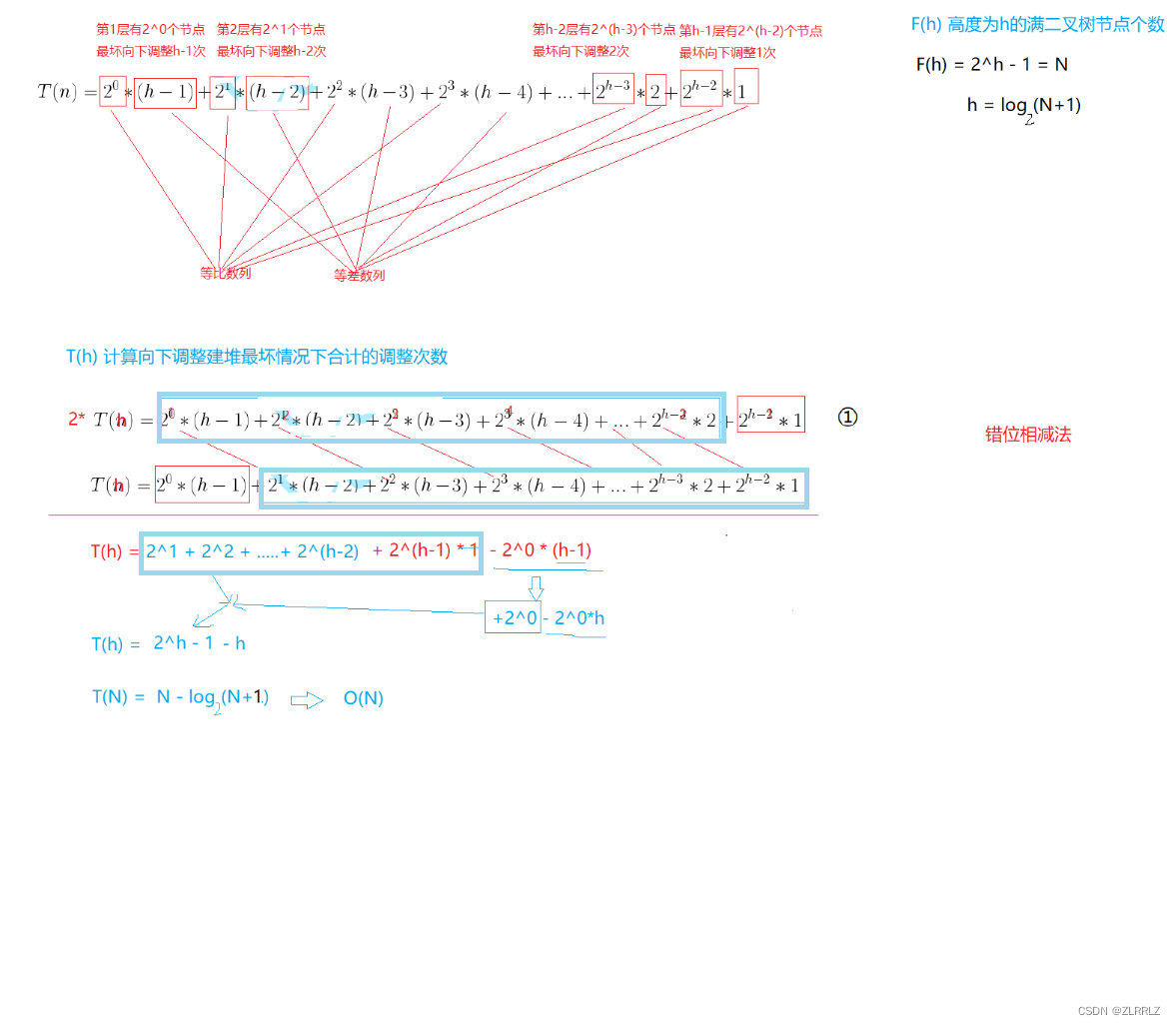
因此:堆排序的建堆算法选向下建堆算法。
2.利用堆删除思想来进行排序:
升序:建大堆:将堆顶的最大数与数组最后一个数交换再删除最大的数,再选出最大的数,重复上述操作至堆删空。
降序:建小堆:将堆顶的最小数与数组最后一个数交换再删除最小的数,再选出最小的数,重复上述操作至堆删空。
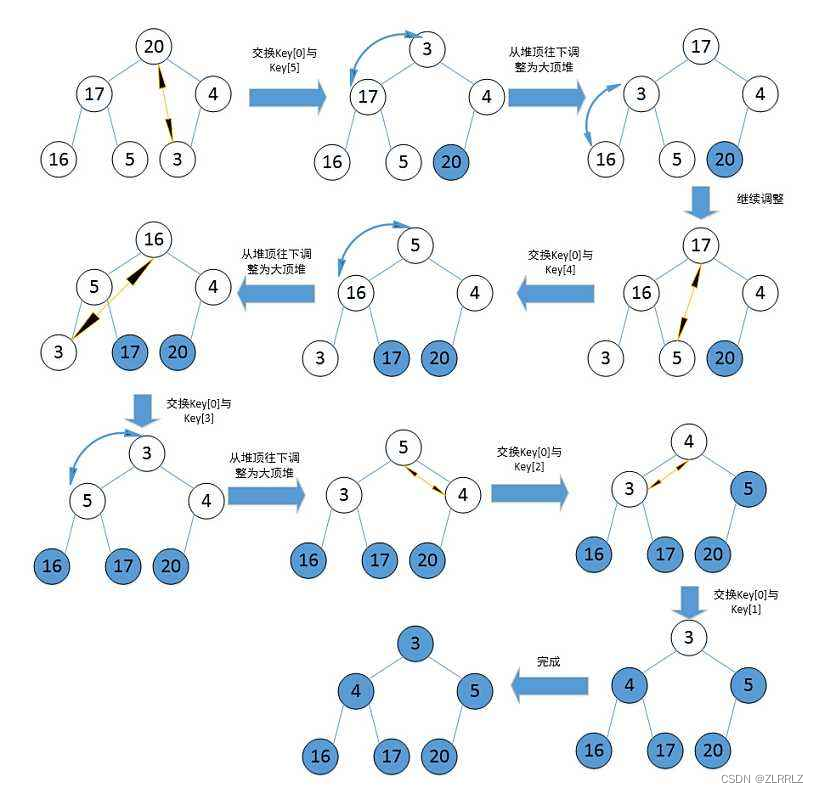
// 对数组进行堆排序
void HeapSort(int* a, int n)
{//for(int i = 1;i < n;i++)//{// AdjustUp(a, i);//}for(int i = (n - 2) / 2;i >= 0;i--){AdjustDown(a,n,i);}int end = n - 1;while(end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);--end;}
}3.4.2 TOP-K问题

TOP-K问题:即求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。 对于Top-K问题,能想到的最简单直接的方式就是排序,但是:如果数据量非常大,简单的排序就不太可取了(可能数据都不能一下子全部加载到内存中)。最佳的方式就是用堆排序来解决,基本思路如下:
方法一:
如下图,假设内存相对充裕,有1个G,要存储大约4G的内容,我们可以直接建1个G堆,每次比较1G的数据,选出10最大的数,共选4次,最后在这40个数内选10个最大的数。但是这个方法空间复杂度较大。

方法二:
如果现有内存较小,我们就可以通过如下操作。
1. 求前最大K个元素,集合数据前K个元素来建小堆,求前k个最小的元素,则建大堆
2. 用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素
将剩余N-K个元素依次与堆顶元素比完之后,堆中剩余的K个元素就是所求的前K个最小或者最大的元素。
这个方法中,由于堆的特性,堆顶的数据总是堆内数据最小(最大)的,通过与堆顶比较来决定是否进堆,交换进堆则进行调整,重复比较,最终堆内留下的就是所要求的数据。

void TestHeap()
{int k;printf("请输入k>:");scanf("%d", &k);int* kminheap = (int*)malloc(sizeof(int) * k);if (kminheap == NULL){perror("malloc fail");return;}const char* file = "data.txt";FILE* fout = fopen(file, "r");if (fout == NULL){perror("fopen error");return;}// 读取文件中前k个数for (int i = 0; i < k; i++){fscanf(fout, "%d", &kminheap[i]);}// 建K个数的小堆for (int i = (k-1-1)/2; i>=0 ; i--){AdjustDown(kminheap, k, i);}// 读取剩下的N-K个数int x = 0;while (fscanf(fout, "%d", &x) > 0){if (x > kminheap[0]){kminheap[0] = x;AdjustDown(kminheap, k, 0);}}printf("最大前%d个数:", k);for (int i = 0; i < k; i++){printf("%d ", kminheap[i]);}printf("\n");
}总结:总的来说,方法一与方法二的时间差别不带,但是方法二会节省较多的空间。
4.二叉树链式结构的实现
二叉树是:
1. 空树
2. 非空:根结点,根结点的左子树、根结点的右子树组成的。

从概念中可以看出,二叉树定义是递归式的,因此后序基本操作中基本都是按照该概念实现的。
4.2二叉树的遍历
4.2.1 前序、中序以及后序遍历(深度优先遍历)
学习二叉树结构,最简单的方式就是遍历。所谓二叉树遍历(Traversal)是按照某种特定的规则,依次对二叉 树中的结点进行相应的操作,并且每个结点只操作一次。访问结点所做的操作依赖于具体的应用问题。 遍历是二叉树上最重要的运算之一,也是二叉树上进行其它运算的基础。
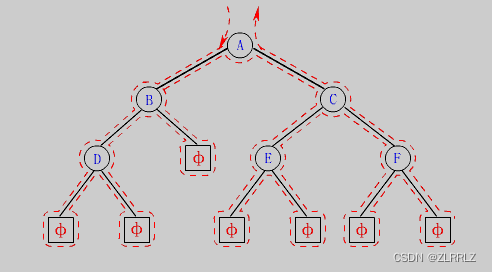
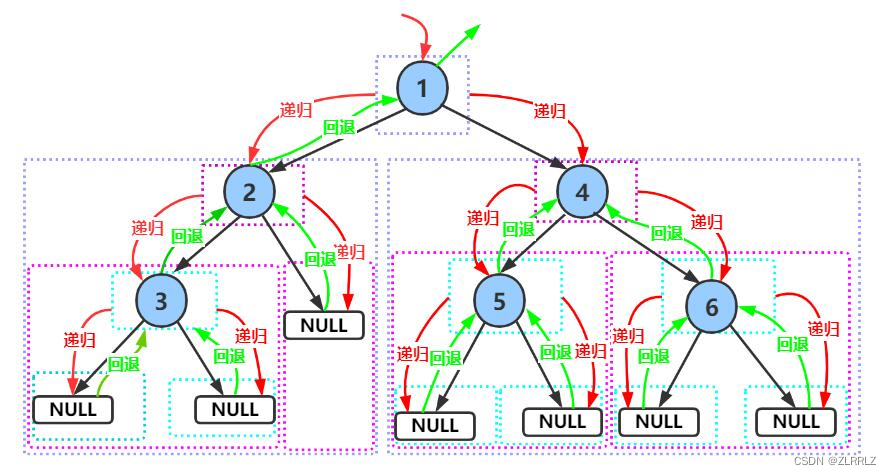
按照规则,二叉树的遍历有:前序/中序/后序的递归结构遍历:(需要注意每个节点都必须遵循相关遍历顺序,)
1. 前序遍历(Preorder Traversal 亦称先序遍历)——访问根结点的操作发生在遍历其左右子树之前。访问顺序:根节点-左子树-右子树
2. 中序遍历(Inorder Traversal)——访问根结点的操作发生在遍历其左右子树之中(间)。访问顺序:左子树-根节点-右子树
3. 后序遍历(Postorder Traversal)——访问根结点的操作发生在遍历其左右子树之后。访问顺序:左子树-右子树-根节点
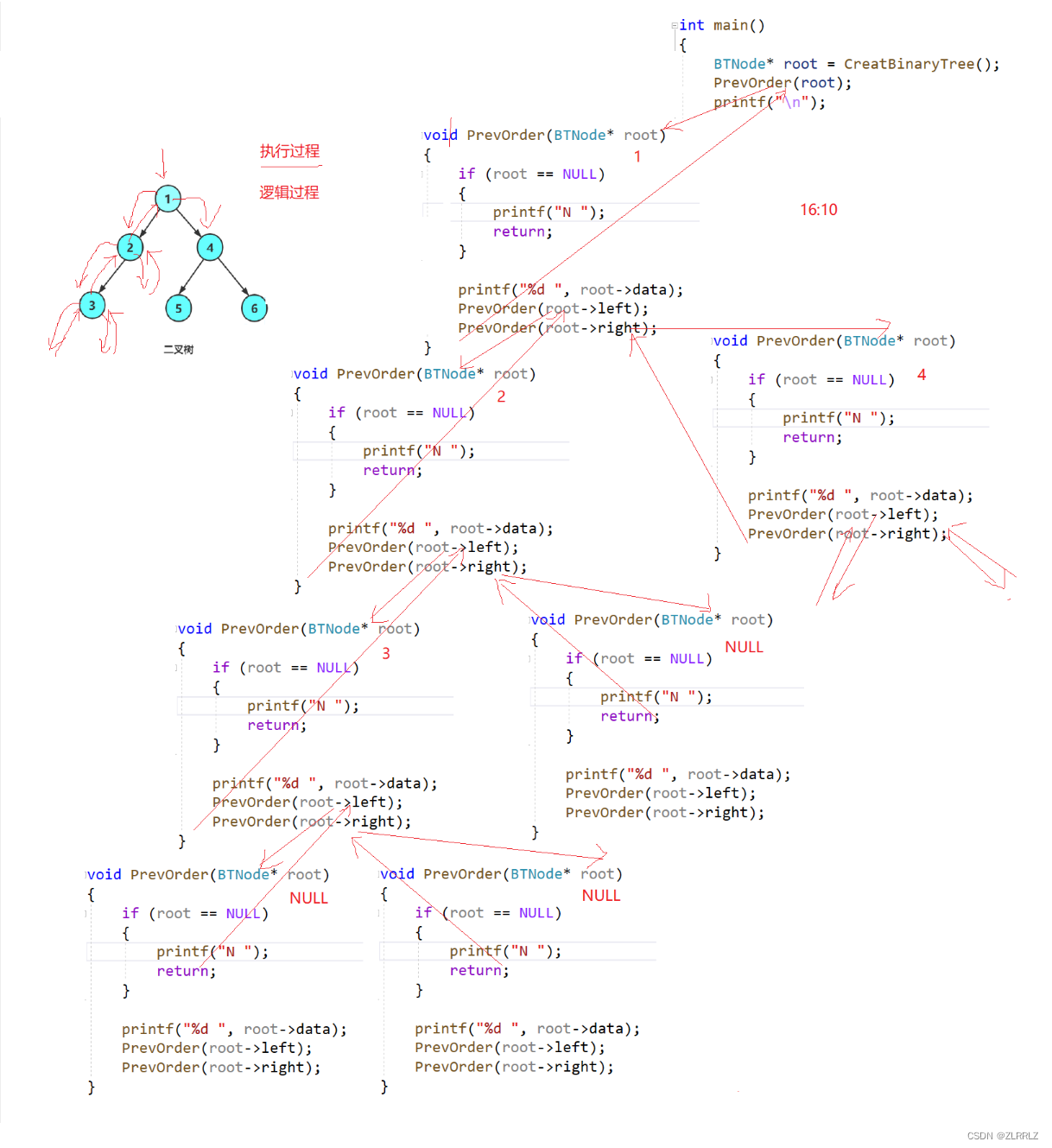
由于被访问的结点必是某子树的根,所以N(Node)、L(Left subtree)和R(Right subtree)又可解释为根、根的左子树和根的右子树。NLR、LNR和LRN分别又称为先根遍历、中根遍历和后根遍历。
下面主要分析前序递归遍历,中序与后序图解类似,
前序遍历递归图解:
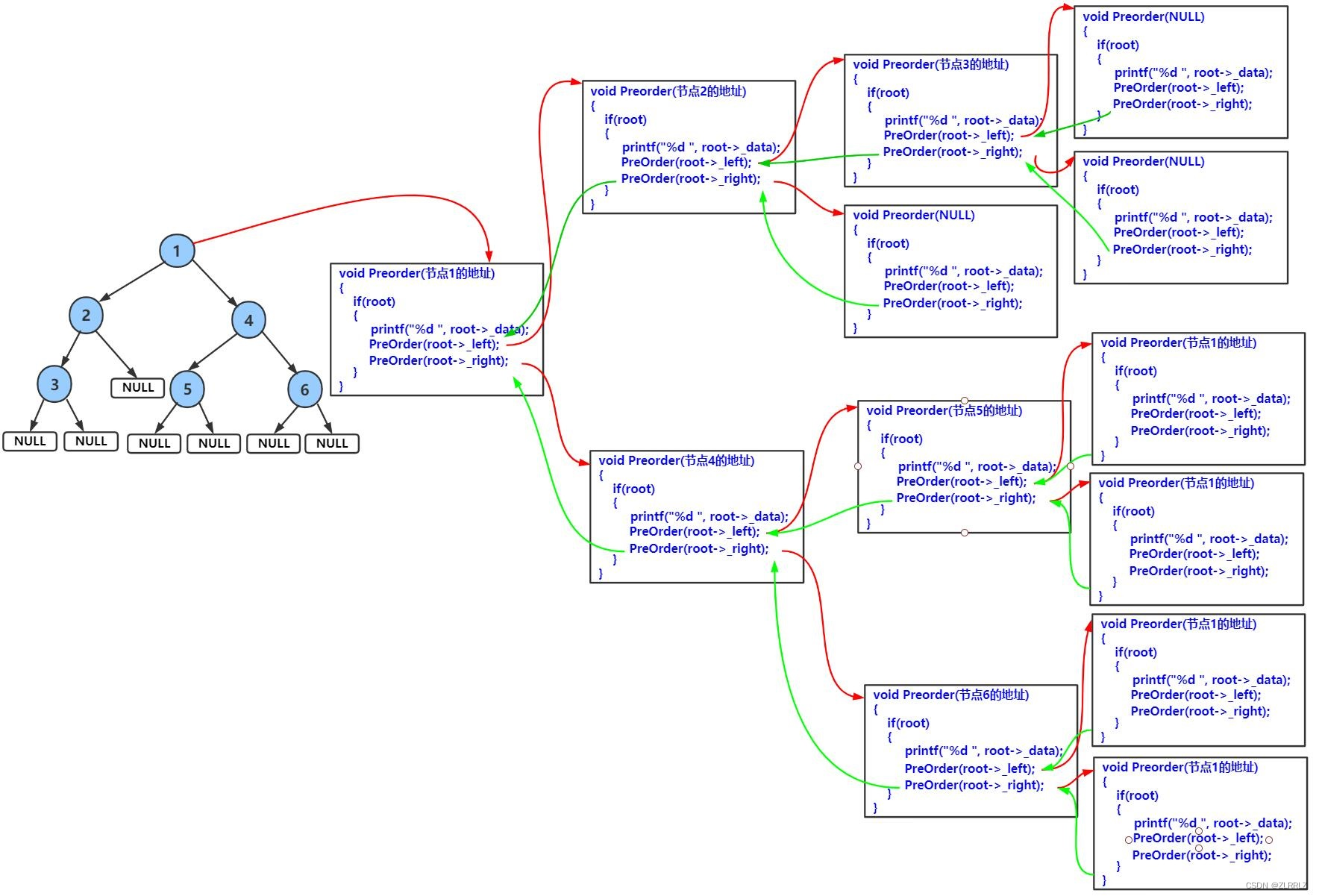
前序遍历结果:

// 二叉树前序遍历
void BinaryTreePrevOrder(BTNode* root)
{if (root == NULL){printf("N");return;}printf("%d",root->_data);//访问根节点BinaryTreePrevOrder(root->_left);//访问根节点的左子树BinaryTreePrevOrder(root->_right);//访问根节点的右子树}在上述代码中,我们通过printf打印来表示访问节点(根据具体情境不同),需要注意的是递归调用函数,开辟栈帧,需要一个最基本、不可再调用的条件(基底)来结束递归,虽然前序遍历的返回值类型是void,但是遇到空节点,不可再分时,我们需要加上return;这样并不会返回实际的值,但是会结束本次的函数调用,并返回上一个栈帧,并进行接下来的操作,可能是访问右子树,如果本身是右子树,就执行完全部操作,结束本次调用,返回上一层栈帧,重复上诉操作。
中序遍历结果:

// 二叉树中序遍历
void BinaryTreeInOrder(BTNode* root)
{if (root == NULL){printf("NULL");}BinaryTreeInOrder(root->_left);//访问根节点的左子树printf("%d", root->_data);//访问根结点BinaryTreeInOrder(root->_right);访问根节点的右子树
}后序遍历结果:

// 二叉树后序遍历
void BinaryTreePostOrder(BTNode* root)
{if (root == NULL){printf("NULL");}BinaryTreePrevOrder(root->_left);访问根节点左子树BinaryTreePrevOrder(root->_right);访问根节点的右子树printf("%d", root->_data);//访问根节点
}
4.2.2 层序遍历(广度优先遍历)
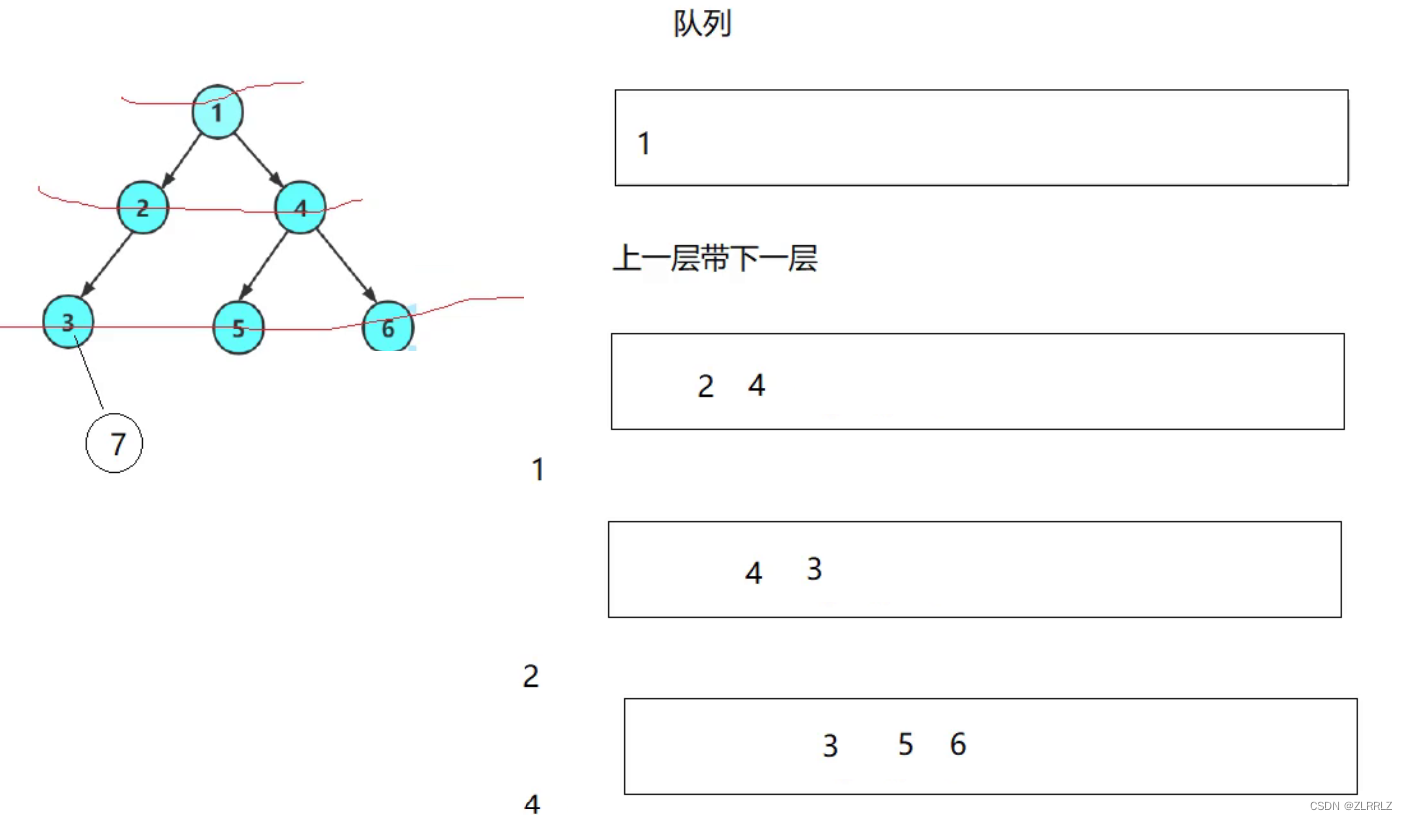
层序遍历:除了先序遍历、中序遍历、后序遍历外,还可以对二叉树进行层序遍历。设二叉树的根结点所在 层数为1,层序遍历就是从所在二叉树的根结点出发,首先访问第一层的树根结点,然后从左到右访问第2层 上的结点,接着是第三层的结点,以此类推,自上而下,自左至右逐层访问树的结点的过程就是层序遍历。
层序遍历的代码实现需要借助队列(队列的结构参考附录),如下图,当我们遍历到根节点1时,我们将队列中的1进行出队列操作,再将将1的左右子节点2,4入到队列中来,之后遍历到2,将2出队列,将左子树3入到队列中(空节点是否入看具体情境),之后节点遍历重复上述操作,我们就可以实现层序遍历。
// 层序遍历
void BinaryTreeLevelOrder(BTNode* root)
{Queue q;QueueInit(&q);if (root){QueuePush(&q, root);}else{QueueDestroy(&q);return ;}while (!QueueEmpty(&q)){BTNode* front = QueueFront(&q);QueuePop(&q);printf("%d",front->_data);if(front->_left)QueuePush(&q, front->_left);if(front->_right)QueuePush(&q, front->_right);}QueueDestroy(&q);
}练习:请写出下面的前序/中序/后序/层序遍历:
选择题
题目
1.某完全二叉树按层次输出(同一层从左到右)的序列为 ABCDEFGH 。该完全二叉树的前序序列为( )
A ABDHECFG
B ABCDEFGH
C HDBEAFCG
D HDEBFGCA
2.二叉树的先序遍历和中序遍历如下:先序遍历:EFHIGJK;中序遍历:HFIEJKG.则二叉树根结点为() A E
B F
C G
D H
3.设一课二叉树的中序遍历序列:badce,后序遍历序列:bdeca,则二叉树前序遍历序列为____。
A adbce
B decab
C debac
D abcde
4.某二叉树的后序遍历序列与中序遍历序列相同,均为 ABCDEF ,则按层次输出(同一层从左到右)的序列
为
A FEDCBA
B CBAFED
C DEFCBA
D ABCDEF
答案
1.A
2.A
3.D
4.A
4.3 二叉树其他功能实现
4.3.1二叉树节点个数
思路一:遍历
创建变量记录遍历过的节点,遍历一个节点变量加一。但是变量的创建与使用有不少需要注意的点。
错误做法
int TreeSize(BTNode* root)
{int size = 0;if (root == NULL)return 0;else++size;TreeSize(root->left);TreeSize(root->right);return size;
}如上图,每次函数递归创建的栈都会压在原来的栈上,不同栈之间传递的只是参数,因此size变量相当于是每个栈都重新开辟size,size无法记录节点个数。
方法一
int size = 0;
int TreeSize(BTNode* root)
{if (root == NULL)return 0;else++size;TreeSize(root->left);TreeSize(root->right);return size;
}方法二
void TreeSize(BTNode* root, int* psize)
{if (root == NULL)return 0;else++(*psize);TreeSize(root->left, psize);TreeSize(root->right, psize);
}上述两种方法,法一是创建静态变量,法二是创建变量,再将变量地址传入函数,每次通过地址访问对应空间,以上两种都能成功记录节点个数,但是由于一个是创建静态变量,一个是在函数外创建变量传递地址,因此如果我们再次调用求节点个数函数求另一棵树的节点,size的数据不会自动清零,会在原基础上累加,因此每次使用函数之前都需要手动置size为0。使用不太方便

思路二:分治递归
一棵树由根与左右子树构成,因此,我们求一棵树的就是求根的个数1加上左右子树上节点的个数,而左子树又可以分为根和左右子树,右子树同理,因此每一颗节点我们都可以这样不断分下去,直到叶节点左右子树为空,返回0,加上叶节点本身的1,然后叶节点,再把计算的结果向上一层返回,最终整棵树的根将节点返回。
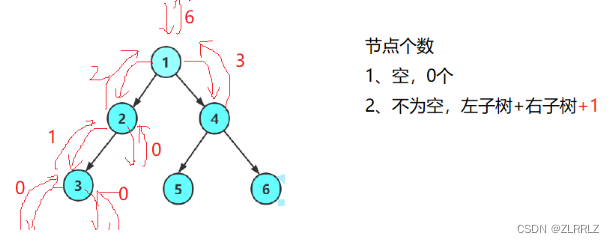
// 二叉树节点个数
int BinaryTreeSize(BTNode* root)
{return root == NULL ? 0 : BinaryTreeSize(root->_left) +
BinaryTreeSize(root->_right) + 1;
}4.3.2.二叉树叶子节点个数
对于一个节点,如果这个节点为空结束递归,向上返回0,;如果这个节点左右子树都为空,说明是这个节点是叶节点,叶节点的个数加1,函数向上返回到调用处1这个结果;如果左右子树不同时为空,说明这个节点不是叶节点,我们需要继续递归它的左右子树去找叶节点。

// 二叉树叶子节点个数
int BinaryTreeLeafSize(BTNode* root)
{if (root->_left == NULL && root->_right == NULL)return 1;return BinaryTreeLeafSize(root->_left) + BinaryTreeLeafSize(root->_right);}4.3.3.二叉树第k层节点个数
求第K层节点的个数,如下图,以求第三层节点为例,就是求相对于第二层的第二层节点个数,就是求相对与第三层的第一层的节点。按照这个分治思路,我们以K == 1表示该层就是所求层。如果该节点为空,返回0,如果K==1,也就是该节点就在要求的K层上,该节点需要纳入计算,返回1;如果K不等于1,说明说要求的那层还在下方,继续向左右左子树分。
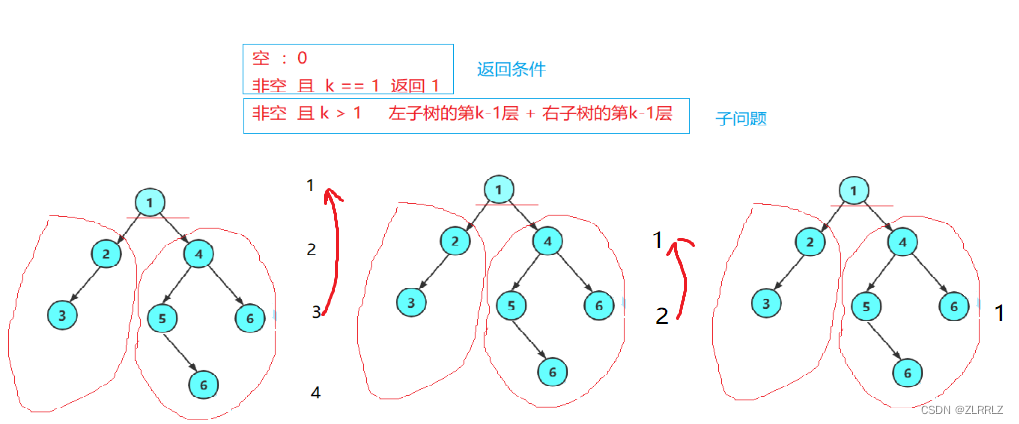
// 二叉树第k层节点个数
int BinaryTreeLevelKSize(BTNode* root, int k)
{if (NULL == root){return 0;}if(k == 1){return 1;}
//子问题return BinaryTreeLevelKSize(root->_left, k - 1) +
BinaryTreeLevelKSize(root->_right, k - 1);
}4.3.4.二叉树查找值为x的节点
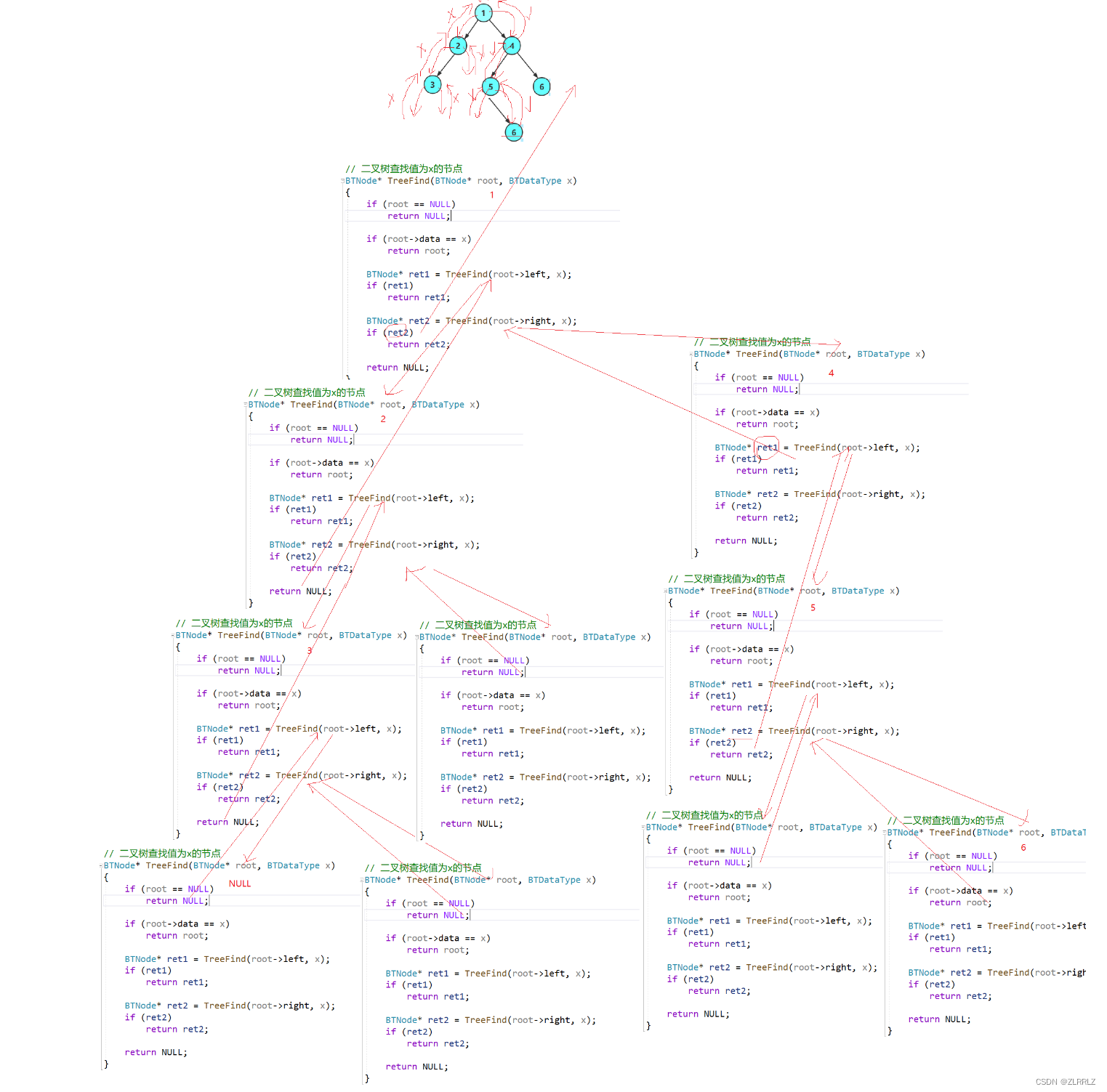
// 二叉树查找值为x的节点
BTNode* BinaryTreeFind(BTNode* root, BTDataType x)
{if(NULL == root)//节点为空,找不到节点,返回空{return NULL;}if(root->_data == x)//相等说明,找到节点,返回该节点{return root;}BTNode* find1 = BinaryTreeFind(root->_left, x);//当前节点不是所要找的节点,向左子树继续寻找BTNode* find2 = BinaryTreeFind(root->_right, x);//当前节点不是所要找的节点,向右子树继续寻找if (find1)//find1为true说明找到节点,返回find1的结果{return BinaryTreeFind(root->_left, x);}if (find2)//find2为true说明找到节点,返回find2的结果{return BinaryTreeFind(root->_right, x);}return NULL;//find1,find2左右子树都找不到,整棵树都找不到
}4.3.5判断二叉树是否是完全二叉树
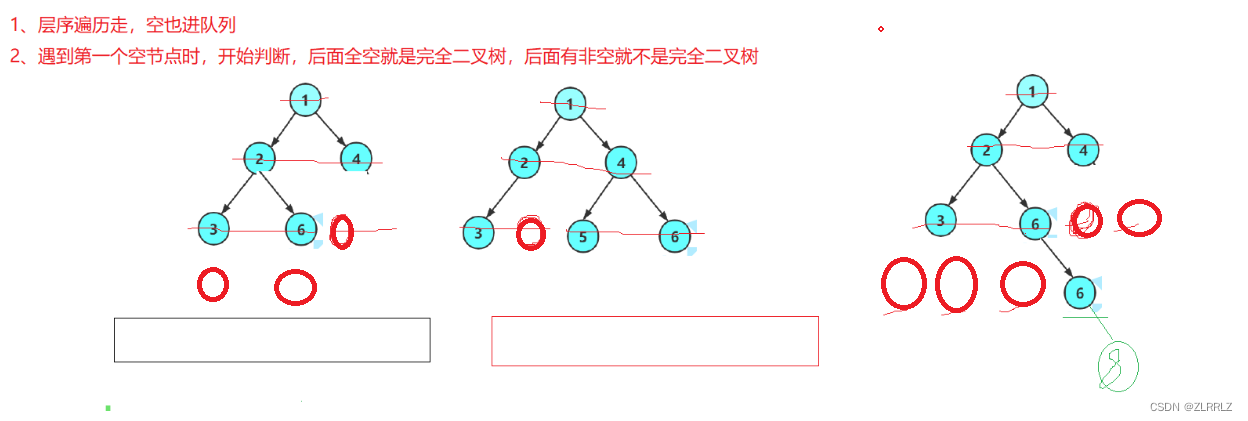
判断二叉树是否为为完全二叉树,我们借助层序遍历,将书上所有节点的都入队列(叶节点的左右子树为空,也入队列)这样,当我们当我们遇到第一个空节点,之后所有节点应该是空结点,如果出现非空节点,如上图最右边节点,那么就说明,这棵树不是完全二叉树。
// 判断二叉树是否是完全二叉树
int BinaryTreeComplete(BTNode* root)
{Queue q;QueueInit(&q);if (root) {QueuePush(&q, root);}else{QueueDestroy(&q);return false;}while (!QueueEmpty(&q)){BTNode* front = QueueFront(&q);QueuePop(&q);if (NULL == front){break;}QueuePush(&q, front->_left);QueuePush(&q, front->_right);}while (!(QueueEmpty(&q))){BTNode* front = QueueFront(&q);QueuePop(&q);if (front){QueueDestroy(&q);return false;}}QueueDestroy(&q);return true;
}4.4.6二叉树的高度
求二叉树的高度时,同样使用分治,大树化小树,树的根节点本身就是一层,接下来只需要求根节点的左子树,根的右子树,比较左右子树谁的高度更大,然后大的高度加上根节点的那一层就是整棵树的高度。
// 有效率问题
int TreeHeight(BTNode* root)
{if (root == NULL)return 0;return TreeHeight(root->left) > TreeHeight(root->right) ?TreeHeight(root->left) + 1 : TreeHeight(root->right) + 1;
}但需要注意的是,我们如果写成上述的形式,效率会非常低下,因为在比较是调用函数求出左右子树的高度,这个结果并没有通过变量记录下来,这就导致当我们计算将子树高度与根高度相加时,函数会重新调用,并且过程与比较时调用过程一模一样,对于每个节点来说都是这样。这就是严重的浪费了.
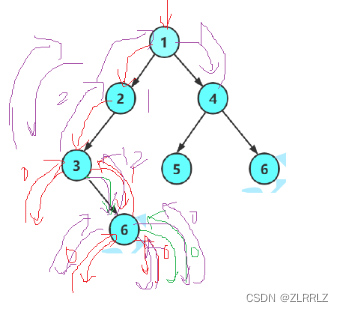
如上图,求树高时,递归到最底层6,时,为了比较先求6左右子树高,比较玩,为了返回再调用,再求了一次高,求3的高时,要先比较左右子树的高度,而右子树的求法就是刚刚求6的算法,接下来因为没有记录比较时算出的高度,我们需要再将上述运算过程重复,得到值再将3的结果返回给2,而2的过程与3类似,我们发现没有记录结果,就导致不同层节点返回值之间的计算量,相比于记录的计算量,每一层之间都是成倍数增加的。
//二叉树的高度
int TreeHeight(BTNode* root)
{if(NULL == root){return 0;}int leftheight = TreeHeight(root->_left);int rightheight = TreeHeight(root->_right);return leftheight > rightheight ? leftheight + 1 : rightheight + 1;}4.4 二叉树基础oj练习
1. 单值二叉树。Oj链接
与求树节点个数类似,如果创建变量来挨个遍历比较,这里变量的控制同样是个问题,因此这里我们同样采用分治的思路。

/*** Definition for a binary tree node.* struct TreeNode {* int val;* struct TreeNode *left;* struct TreeNode *right;* };*/
bool isUnivalTree(struct TreeNode* root) {//左右子树同时跟根子树比较条件控制较复杂,先一个一个比较if(root == NULL)//不存在节点,不存在节点不相等的可能return true;if(root->left && root->left->val != root->val)//先判断左子树是否相等存在,不存在没必要必较return false;//左子树存在则根节点先跟左子树比较if(root->right && root->right->val != root->val)//判断右子树是否相等存在,不存在没必要必较return false;//右子树存在则根节点再跟右子树比较return isUnivalTree(root->left)&&isUnivalTree(root->right);//当前根节点比较,再比较它的左右子树}2. 检查两颗树是否相同。OJ链接
/*** Definition for a binary tree node.* struct TreeNode {* int val;* struct TreeNode *left;* struct TreeNode *right;* };*/
bool isSameTree(struct TreeNode* p, struct TreeNode* q) {if(p == NULL && q == NULL)//两个节点都为空,对应位置相同return true;if(p == NULL || q == NULL)//一节点为空,另一节点不为空,对应位置不同return false;if(p->val != q->val)//节点都不为空,但是对应节点值不同return false;return isSameTree(p->right,q->right) && isSameTree(p->left,q->left);//左子树跟左子树比较,右子树跟右子树比较
}3. 对称二叉树。OJ链接
/*** Definition for a binary tree node.* struct TreeNode {* int val;* struct TreeNode *left;* struct TreeNode *right;* };*/
bool IsSymmetric(struct TreeNode* rootleft,struct TreeNode* rootright)
{if(rootleft == NULL && rootright == NULL)//两个节点都为空,对应位置相同return true;if(rootleft == NULL || rootright == NULL)//一节点为空,另一节点不为空,对应位置不同return false;if(rootleft->val != rootright->val)//节点都不为空,但是对应节点值不同return false;return IsSymmetric(rootleft->left , rootright->right) && IsSymmetric(rootleft->right , rootright->left);//因为对称左子树跟右子树比较,右子树跟左子树比较}bool isSymmetric(struct TreeNode* root) {return IsSymmetric(root->left,root->right);}4. 二叉树的前序遍历。 OJ链接
/*** Definition for a binary tree node.* struct TreeNode {* int val;* struct TreeNode *left;* struct TreeNode *right;* };*/
/*** Note: The returned array must be malloced, assume caller calls free().*/
int TreeSize(struct TreeNode* root)
{return root == NULL ? 0 : TreeSize(root->left) + TreeSize(root->right) + 1;
}void PrevOrder(struct TreeNode* root,int* arr,int* pi)
{if(root == NULL)return ;arr[(*pi)++] = root->val;PrevOrder(root->left,arr,pi);PrevOrder(root->right,arr,pi);}int* preorderTraversal(struct TreeNode* root, int* returnSize) {*returnSize = TreeSize(root);//以数组形式存储,为判定大小,先求节点个数int*arr = (int*)malloc(sizeof(int)*(*returnSize));int i = 0;PrevOrder(root,arr,&i);return arr;}5. 二叉树中序遍历 。OJ链接
/*** Definition for a binary tree node.* struct TreeNode {* int val;* struct TreeNode *left;* struct TreeNode *right;* };*/
/*** Note: The returned array must be malloced, assume caller calls free().*/int TreeSize(struct TreeNode* root)
{return root == NULL ? 0 : TreeSize(root->left) + TreeSize(root->right) + 1;
}void InOrder(struct TreeNode* root,int* arr,int* pi)
{if(root == NULL)return ;InOrder(root->left,arr,pi);arr[(*pi)++] = root->val;InOrder(root->right,arr,pi);}int* inorderTraversal(struct TreeNode* root, int* returnSize) {*returnSize = TreeSize(root);int*arr = (int*)malloc(sizeof(int)*(*returnSize));int i = 0;InOrder(root,arr,&i);return arr;
}6. 二叉树的后序遍历 。OJ链接
/*** Definition for a binary tree node.* struct TreeNode {* int val;* struct TreeNode *left;* struct TreeNode *right;* };*/
/*** Note: The returned array must be malloced, assume caller calls free().*/int TreeSize(struct TreeNode* root)
{return root == NULL ? 0 : TreeSize(root->left) + TreeSize(root->right) + 1;
}void PostOrder(struct TreeNode* root,int* arr,int* pi)
{if(root == NULL)return ;PostOrder(root->left,arr,pi);PostOrder(root->right,arr,pi);arr[(*pi)++] = root->val;}int* postorderTraversal(struct TreeNode* root, int* returnSize) {*returnSize = TreeSize(root);int*arr = (int*)malloc(sizeof(int)*(*returnSize));int i = 0;PostOrder(root,arr,&i);return arr;
}7. 另一颗树的子树。OJ链接
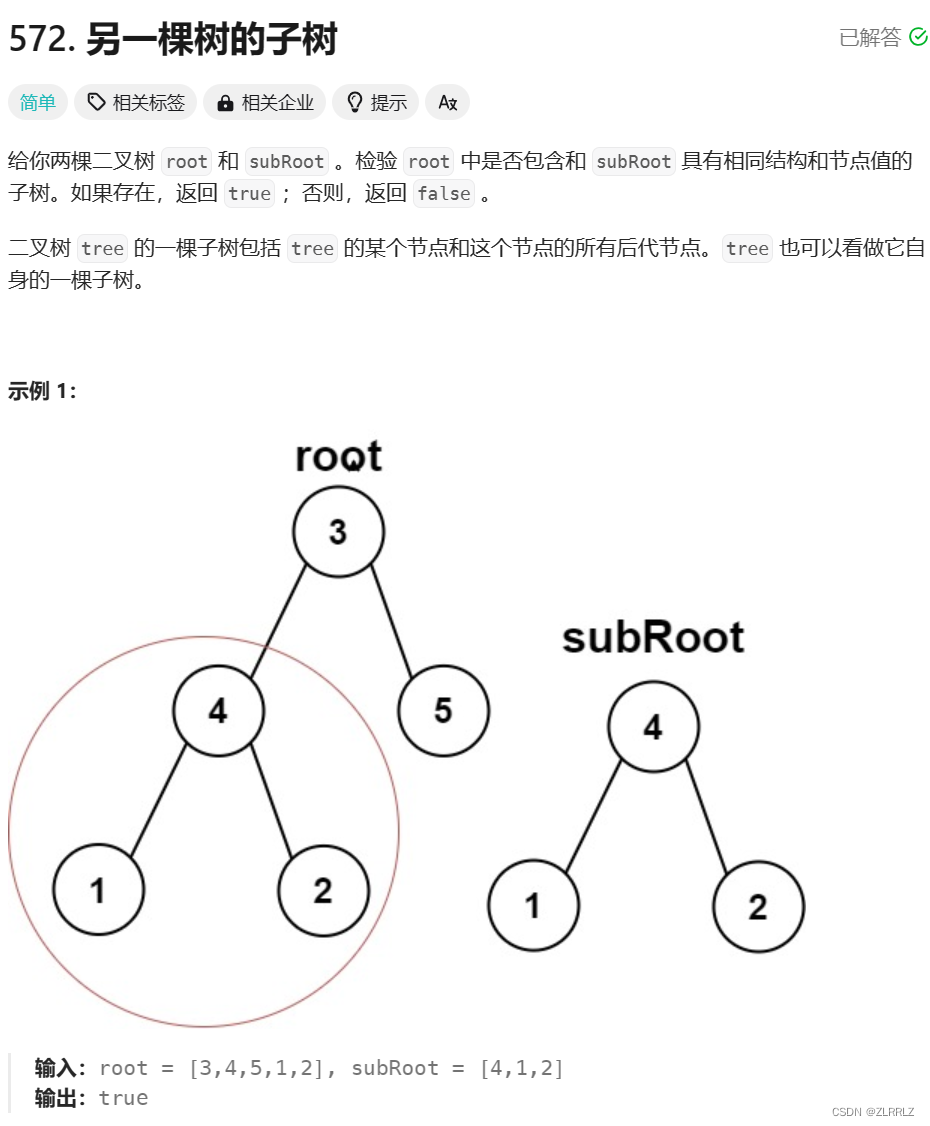
/*** Definition for a binary tree node.* struct TreeNode {* int val;* struct TreeNode *left;* struct TreeNode *right;* };*/
bool isSameTree(struct TreeNode* p, struct TreeNode* q) {if(p == NULL && q == NULL)return true;if(p == NULL || q == NULL)return false;if(p->val != q->val)return false;return isSameTree(p->right,q->right) && isSameTree(p->left,q->left);
}bool isSubtree(struct TreeNode* root, struct TreeNode* subRoot){if(root == NULL )//当前根节点为空,另一棵树一定不是它的子树return false;if(isSameTree(root,subRoot))//从当前节点开始比较return true; //如果subRoot与当前这棵子树相同,则subRoot是root的子树return isSubtree(root->left,subRoot) || isSubtree(root->right,subRoot);//如果当前根节点向下子树与subRoot不相同
} //继续向下比较root的左子树、右子树与subRoot4.5 二叉树的创建和销毁
二叉树的构建及遍历。OJ链接
#include <stdio.h>typedef char BTDataType;typedef struct BinaryTreeNode
{BTDataType _data;struct BinaryTreeNode* _left;struct BinaryTreeNode* _right;
}BTNode;BTNode* BuyNode(int x)//创建节点的函数
{BTNode* node = (BTNode*)malloc(sizeof(BTNode));if (node == NULL){perror("malloc fail");return NULL;}node->_data = x;node->_left = NULL;node->_right = NULL;return node;
}BTNode* BinaryTreeCreate(BTDataType* a, int n,int* pi)
{BTNode* node = NULL;if(a[*pi] == '#')//如果等'#',说明节点为空{(*pi)++;//跳过当前字符return NULL;//返回空}node = BuyNode(a[(*pi)++]);//当前位置创建根节点node->_left = BinaryTreeCreate(a,n,pi);//创建根节点的左子树node->_right = BinaryTreeCreate(a,n,pi);//创建根节点的右子树return node;//返回创建完的节点。
}// 二叉树中序遍历
void BinaryTreeInOrder(BTNode* root)
{if (root == NULL){return;}BinaryTreeInOrder(root->_left);printf("%c ", root->_data);BinaryTreeInOrder(root->_right);
}int main()
{char arr[100];scanf("%s",arr);//获取输入字符串int i = 0;BTNode*root = BinaryTreeCreate(arr,sizeof(arr)/sizeof(arr[0]),&i);BinaryTreeInOrder(root);}附录:
queue.h
#pragma once
#define _CRT_SECURE_NO_WARNINGS 1
#include<stdio.h>
#include<assert.h>
#include<stdlib.h>
#include"stdbool.h"typedef struct BinaryTreeNode* QDataType;// 链式结构:表示队列
typedef struct QListNode
{struct QListNode* _next;QDataType _data;}QNode;// 队列的结构
typedef struct Queue
{QNode* _front;QNode* _rear;int _size;
}Queue;// 初始化队列
void QueueInit(Queue* q);// 队尾入队列
void QueuePush(Queue* q, QDataType data);// 队头出队列
void QueuePop(Queue* q);// 获取队列头部元素
QDataType QueueFront(Queue* q);// 获取队列队尾元素
QDataType QueueBack(Queue* q);// 获取队列中有效元素个数
int QueueSize(Queue* q);// 检测队列是否为空,如果为空返回非零结果,如果非空返回0
bool QueueEmpty(Queue* q);// 销毁队列
void QueueDestroy(Queue* q);
queue.c
#include"queue.h"// 初始化队列
void QueueInit(Queue* q)
{q->_front = NULL;q->_rear = NULL;q->_size = 0;
}// 队尾入队列
void QueuePush(Queue* q, QDataType data)
{assert(q);QNode* newnode = (QNode*)malloc(sizeof(QNode));if (NULL == newnode){perror("QueuePush:malloc failed");exit(1);}newnode->_data = data;newnode->_next = NULL;if (0 == q->_size){q->_front = q->_rear = newnode;}else{q->_rear->_next = newnode;q->_rear = q->_rear->_next;}q->_size++;
}// 队头出队列
void QueuePop(Queue* q)
{assert(q);assert(q->_size);QNode* next = q->_front->_next;free(q->_front);q->_front = next;if (q->_size == 1){q->_rear = NULL;}q->_size--;}// 获取队列头部元素
QDataType QueueFront(Queue* q)
{assert(q);assert(q->_size);return q->_front->_data;
}// 获取队列队尾元素
QDataType QueueBack(Queue* q)
{assert(q);assert(q->_size);return q->_rear->_data;}// 获取队列中有效元素个数
int QueueSize(Queue* q)
{assert(q);return q->_size;
}// 检测队列是否为空,如果为空返回非零结果,如果非空返回0
bool QueueEmpty(Queue* q)
{assert(q);return q->_size == 0;
}// 销毁队列
void QueueDestroy(Queue* q)
{assert(q);QNode* cur = q->_front;while(cur){QNode* next = cur->_next;free(cur);cur = next;}q->_front = q->_rear = NULL;q->_size = 0;
}