搜索进入AI蓝海时代:谁在成为新玩家?

有新人入场,也有老人退场。这个原本只有百度、360、谷歌、夸克等传统搜索企业的战场上,一众新的玩家正在踊跃出现,在AI的加持下,他们看到了另一种搜索业务发展且变现的可能,看到了另一个蓝海市场。
作者|思杭
编辑|皮爷
出品|产业家
我们一直使用的搜索,到底是什么样子的?
根据一份微软的调查数据显示,人们每天使用搜索的频次近乎超过百亿,问题覆盖方方面面,从天文到地理,从人文到赛博朋克等等。但在这些问题中,大约有一半问题都没有答案。
激发人们去感受探索的快乐和创造的力量,并驾驭世界知识,这是过去很长一段时间里搜索引擎被赋予的使命。更直白地说,搜索引擎和浏览器就是我们探索世界的最大入口。
但如今,这个模式正在发生微妙的变化。
在搜索引擎发展的数十载里,尽管一部分问题已经得到解决,比如搜索技术和商业模式,但有一个问题却始终困扰着海内外的搜索引擎巨头——“并不是所有问题都有答案”。
至于其中的原因,在他们看来是,人们所问的问题,并非是在搜索引擎设计过程中“定制”的那些问题,也就是说技术人员不会把所有人们要问的问题都想到,再输入给搜索引擎。
搜索引擎只可以用来回答一些简单的问题,比如2+2=4;再或者找网页也是它的强项。但对于复杂问题的回答,和复杂任务的处理,却力不从心。
而在今天,AI大模型的出现,对搜索引擎而言,则是出现一种新的想象力。这也是为什么微软、谷歌都在竞相推出AI搜索的主要原因。实际上,在搜索引擎领域,对于自然语言的探索,早在21世纪初期就开始了。只是受限于当时的人工智能发展,还未出现一个平台或一种技术,能对自然语言的理解达到有所突破。
那么,站在当下大模型以及AIGC应用爆发的风口下,AI又能赋予搜索引擎怎样的想象力?在国内,对百度、360、天工以及其它玩家,新的搜索形态到底意味着什么?而从商业模式而言,传统搜索固有的广告形态是否又在受到冲击?
这些变化正在发生。从某种程度来看,它不仅是搜索本身形态的变化,更是一面镜子,是一场其背后对应的商业模式、入场玩家的新排位战。
一、从“弄潮儿”到“破冰者”,是两波人
“在未来,基于语音识别技术的发展,搜索体验可以完全脱离搜索框。”早在2018年,原百度副总裁吴海锋就在媒体上发表文章,并站在“无框、无界和无极”三个角度阐释了AI搜索的未来。
语音识别技术也恰好是在这一年有所突破。那一年,百度推出了有语音识别和交互功能的小度智能音箱;也是在那一年的世界人工智能大会上,开始尝试用机器完成同声传译,提供该技术的厂商分别是腾讯和科大讯飞。
此后,各种智能设备层出不穷,其种类和功能也不断推陈出新。大家都在研究如何让自家的智能设备更能听得懂人话,而在这过程中,国内的语音识别技术就更是突飞猛进。
这也正应了吴海锋当年的观点——“无界强调无边界,任何智能设备都可以通过‘搜索入口’调用”。而站在当时的时代下,它所对应的则是一个更大的AI搜索的未来,即通过自然语言就可以完成传统搜索引擎的输入和输出。
听起来,这正是像如今文心一言、通义千问和kimi等AIGC应用所做的事。不同的是,AIGC重在“创作”,或者说“创意”;而搜索则需要绝对的精准。
从2018年到今天,过去六年的时间里,已经有无数的智能设备尝试了用自然语言来完成搜索这件事,它们也都实现了在各种场景下的应用和落地,比如汽车驾驶舱内的各种AI小助理,再比如智能家居甚至全屋智能的AI家电们。
站在助推语音识别技术发展的角度,它们都可以算作是AI搜索的“弄潮儿”。
可以说,两者是相互促进的。智能设备在推动语音识别技术的发展,反过来,自然语言处理、语言识别技术的进步,也在推动着智能设备的发展。比如在前不久的百度开发者大会,李彦宏现场演示小度,从其智能水平就可以看出,如今的小度已不同于之前的小度。这是用大模型重构之后的小度。
与此同时,它也是百度在AI搜索方面的尝试。而在软件侧,互联网厂商则几乎是在每一个移动端都嵌入了AI搜索,通过改变人们使用搜索的习惯,来试图重构搜索引擎。其中最为典型的尝试是,几乎可以代替搜索引擎的微信,和可以称得上第二个“百科全书”的百度文库。
然而就在AI到来之后,被认为“早已成定局”的搜索市场在2024年初发生了一些小变化。
多年以来,在全球搜索引擎市场,谷歌一直都居于霸主位置上,其市场占有率也稳居90%左右,留下剩余的10%给微软Bing等其他搜索引擎分割。然而,到了2024年初,据StatCounter的最新数据,微软在美国市场份额上涨了1.52%;谷歌则下降了1.5%。
这份数据统计时间为2023年2月到2024年1月。而就在一年前的2023年2月,微软CEO宣布其搜索引擎Bing正式接入ChatGPT。
一个问题被随之摆到桌面上:大模型时代,AI是否会改变搜索引擎的市场格局?如果是,又会如何改变?
2023年,海外一家以AI搜索起家的初创公司,在成立仅一年的时间里,就拿到了两笔巨额融资,且估值达5亿美元,甚至差点儿撼动谷歌搜索引擎巨头的位置。
据Similarweb数据,截至2023年10月25日,该搜索引擎的网页端周度访问量由275万增加至1,113万,增长3倍;而到了今年2月,其用户数甚至达到5000万。
这就是去年火爆一时的Perplexity,创始团队不仅有前OpenAI研究员,还有Meta研究科学家,以及Perplexity首席技术官等。
那么,一个纯技术出身的初创公司,还没有任何搜索相关的背景,Perplexity是如何做到这个成绩的?
首先,对于毫无搜索相关背景这一点,Perplexity则非常聪明地选择直接调用谷歌和微软必应等搜索引擎的API,可谓是站在巨人的肩膀上“看”世界,这同时也保证了搜索的实时性。
另一方面,这也是AI搜索需要克服的一大问题,即幻觉问题。对此,Perplexity的做法是通过RAG技术(检索增强生成),让AI搜索可以根据特定的问题在指定的“知识库”里寻找答案,这也保证了它的准确性。
2024年初,一款中国版Perplexity也横空出世。其火爆程度不亚于Perplexity,推出不到两个月的时间里,就有数百万访问量。据Similarweb数据,截至2024年3月24日,该搜索网站访问量达779.3万次。
这就是前猎豹移动首席科学家闵可锐于2018年成立的秘塔科技。只是与Perplexity不同的是,秘塔的创始团队既有来自谷歌的人才,也有来自微软的人才。
然而,在国内,“破冰者”并非是仿照Perplexity的秘塔科技,而是早在2023年8月就推出天工AI搜索的昆仑万维。
另外,2024年初,昔日与百度抗衡的搜素引擎巨头360也推出AI搜索,并在应用商店上线了其移动端App。而国内最大的搜索巨头百度则是将AI搜索这一功能嵌入到百度搜索、百度文库,以及包括小度在内的所有产品当中。
而不同的入局方式,又会产生怎样的“连锁反应”?
二、从浏览器到交互框:
搜索的惊喜与短板
如今,在国内搜索市场上,出现了两大阵营。一方是以360和昆仑万维为首,推出独立的“AI搜索”应用;另一方阵营则是以百度为首,将自身的GPT能力嵌入进去。
以目前已推出“AI搜索”应用的360和昆仑万维为例。
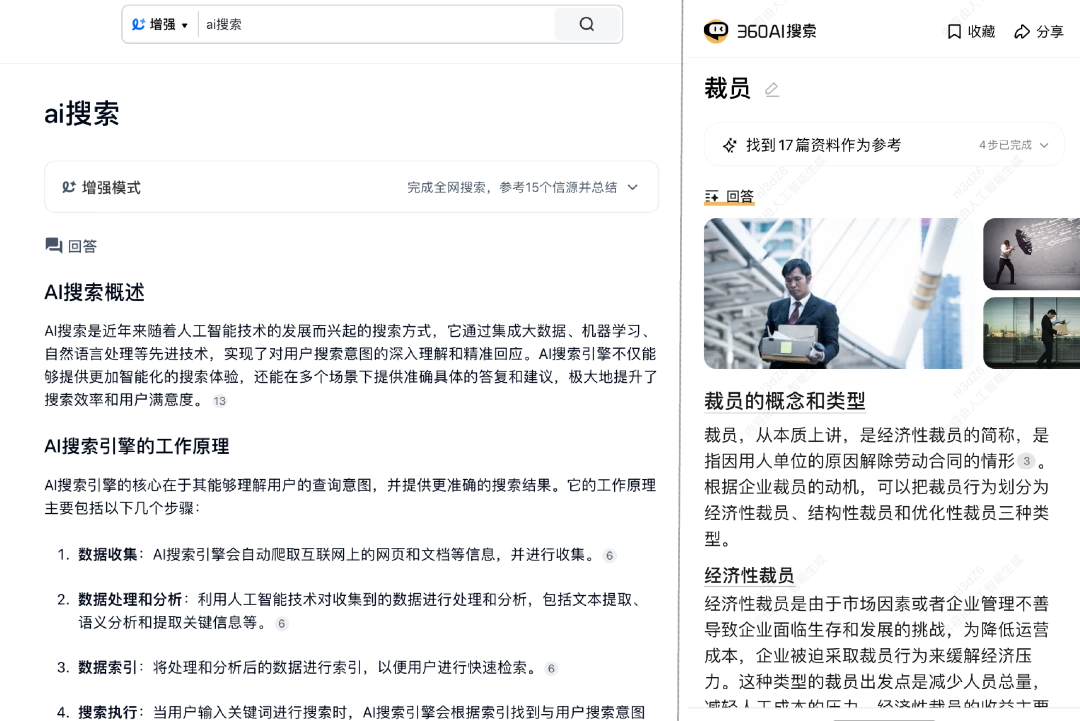
注:天工AI(左)、360AI搜索(右)
可以看到,无论是360AI搜索还是天工AI,在输入关键词后,都有完整且系统性的文字回答。而总结归纳也正是大模型的强项。另外,加持了大模型技术的AI搜索,还有效克服了过去很长一段时间传统搜索的弊病,即生成网页太多,总是让人眼花缭乱。
在过去传统搜索中,当用户输入关键词进行搜索之后,便会跳出成千上万个答案,更繁琐的是,这些答案来自于几百个网页。用户需要一一打开网页才能找到答案,一不小心就会掉进“信息茧房”当中。
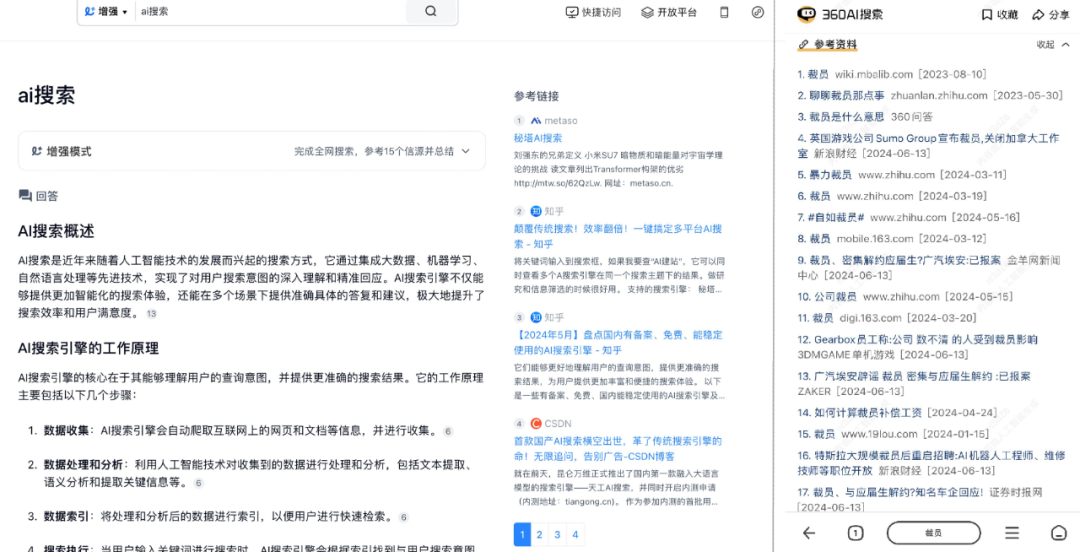
注:天工AI(左)、360AI搜索(右)
而从目前推出的AI搜索来看,天工AI和360AI搜索都是以“参考资料”或“参考链接”的方式呈现出相关网页。
如果说,传统的搜索引擎都是基于“查询(Query)”逻辑去海量互联网内容中给用户匹配答案,其底层架构均是“爬虫+索引+查询”。那么,AI搜索则添加了生成式搜索和多模态搜索,即利用大模型的归纳和推理能力来生成答案。
对于AI搜索,360创始人周鸿祎在其社交账号微信视频号中还提到了AI搜索需要突破的一点:如今的大模型对于prompt的精准性要求很高,但如果放在AI搜索中,这种精准的要求就会变得非常反人性。如何让prompt提示词从准确的一句话变成几个概括的关键词,则正是“AI搜索”要解决的问题。
从上述天工AI和360AI搜索的表现来看,很显然,实现这一突破对“AI搜索”而言并非难题。
但如果从搜索的本质出发,“激发人们去感受探索的快乐和创造的力量,并驾驭世界知识,”这是过去很长一段时间里搜索引擎被赋予的使命。
而仅仅16-17个相关网页既限制了想象空间,也并未起到“激发”人们探索欲的作用。如果仅仅从AI搜索生成的答案来看,它们所提供的“标准答案”也许并非是用户想得到的答案。一些曾经传统搜索无法回答的复杂问题,当前的AI搜索也未必能够回答。
而如果从商业模式的角度,仅提供十几个网页链接,也让“AI搜索”无法再延续过去传统搜索引擎的商业模式。
种种技术问题和商业模式等难题都预示着AI搜索并未成熟。
这也是为什么目前的搜索巨头谷歌、微软和百度选择的方式都是以嵌入式的方式入局,入口则并未发生变化。在前不久刚过去谷歌I/O大会上,谷歌宣布向美国用户推出AI Overviews服务,这是一个AI搜索服务,用户可以自行选择是否让AI来生成答案。
但在AI搜索的成熟度方面,谷歌CEO桑达尔·皮查伊也公开表示:“搜索的作用是给用户提供更多的上下文信息,可以让人们更深入地探索,而答案不准确或者有错误,这些都是我们需要不断改进的地方。”
如果抛开AI搜索目前存在的问题不谈,大模型赋予“搜索”更大的想象力则是,通过完成一个个的数据闭环,来补齐传统搜索引擎的最大短板——场景。
海内外传统的搜索引擎谷歌和百度并不缺算法、算力和数据,但对于发展AI,以及再进一步商业化落地而言,场景则是与前三者同样重要的存在。
在前Google亚洲区CMO王怀南与腾讯科技的访谈中,王怀南反思道,谷歌也存在很多问题。比如缺少数据闭环,谷歌知道用户点了什么网页,但并不知道具体做了什么。换句话说,谷歌无法追踪到一个完整的线路。但大模型可以做到。
用户向大模型问问题的过程,也是大模型在自我学习的过程。这样一来,用户在AIGC应用和AI搜索上做的每一件事,大模型都可以追踪到。这种商业闭环反过来,带给大模型的则是越来越快的成长速度。
而如果说大模型可以反哺给AI搜索更多的场景,那么对于本身已经聚齐了算法、算力、数据和场景的中型公司而言,则面临着更大的商业机会。
值得一提的是,除了中型公司,目前正在崛起的AI创业公司更是一股不可忽视的力量。以OpenAI为例,作为一个创业公司,其本身并没有足够的数据。但OpenAI背后的微软有,同样地,国内的智谱科技和百川智能,背后也站着国内的一众互联网大厂。
与此同时,这意味着,未来的AI搜索“明星公司”也许未必出现在如今的传统搜索巨头中,而是新的AI初创企业。
但一个值得思考的问题,届时,传统的搜索巨头是否会允许类似情况发生?
三、搜索,变化背后的新排位战
“现在大部分AI的应用主要是在搜索。”腾讯元宝相关负责人表示,“甚至从比例来看,这个功能的占比几乎超过70%。”
这个数据在和字节豆包、kimi、阿里通义千问、智谱清语等相关企业的沟通交流中更是得到证实。
从某种层面来看,搜索是如今AI大模型在C端的主要形态,尽管有层出不穷的智能体应用和新玩法,但基于主交互框的搜索仍然是C端用户的主要选择。相较于人们之前一问一答的形式,人们基于大模型更多能得到的是一个具备逻辑性和完整性的回答,这种回答是过去的搜索引擎所不具备的。
但从不同家的模式来看,这种搜索又带有一定程度的特殊性和企业性。比如腾讯元宝的搜索更多是把公众号文章作为信息的引用来源,而文心一言、天工等则是基于百度公开数据进行整理,对于豆包而言,其更大的数据底池来自字节产品体系的文字和视频语料,这些数据来源的不确定性也恰构成了人们在基于AI搜索提问时的不同。
也或者可以说,搜索这个功能背后,也更像是一个中国企业过去产品矩阵和底层积累的镜子,其中的展现形态、对问题回答的逻辑方式以及引用来源,恰对应的是企业过去多年的底盘。
而如果从更深层次来看,尽管如今基于AI的搜索仍然未成为主流,包括传统的如百度、360等企业也对应产出自身的copilot嵌入到自身的产品中,但能感知到的是,搜索这个功能仍然在平民化和普惠化。
如果说过去二三十年里,搜索的入场券必须是浏览器(PC或者移动),那么如今,这个入场券不再被局限形态,在交互框对应的模式背后,它未来的形态会是机器人、车机、智能家居,乃至一切可以被智能化的组件。
有新人入场,也有老人退场。这个原本只有百度、360、谷歌、夸克等等传统搜索企业的战场上,一众新的玩家已经出现,在AI的加持下,它们看到了另一种搜索业务发展且变现的可能。
虽然AI搜索实现的时间尚早,但故事的大幕已被悄然拉开。