复旦大学:一个小技巧探测大模型的知识边界,有效消除幻觉
孔子说“知之为知之,不知为不知,是知也”,目前的大模型非常缺乏这个能力。虽然大模型拥有丰富的知识,但它仍然缺乏对自己知识储备的正确判断。近年来LLMs虽然展现了强大的能力,但它们偶尔产生的内容捏造,即所谓的“幻觉”,限制了其在专业领域的应用,人们也对它们的专业建议持怀疑态度,这些幻觉现象的根源正在于LLMs无法准确表达其知识边界。
最近,复旦大学提出了COKE方法( Confidence-derived Knowledge boundary Expression),通过利用模型内部的置信信号,教导LLMs识别和表达其知识边界,从而减少幻觉现象。实验结果表明,COKE显著提升了模型在域内和域外的表现,使模型能够在回答已知问题的同时,坦诚面对其未知领域的问题。
简而言之,就是增加大模型“知道自己不知道”的知识,减少大模型“不知道自己不知道”的知识。就比如图中的大模型在面对自己未知的问题“《迷失太空2018》中的机器人是谁”时,它如果不知道,就应该给出“不知道”,而不是编造一个“Max Robinson”的答案。

论文标题:Teaching Large Language Models to Express Knowledge Boundary from Their Own Signals
论文链接https://arxiv.org/abs/2406.10881

COKE方法的核心思想
大语言模型的学习机制让它们能够在自己的参数中找到最接近查询q的知识点k作为答案。虽然训练可以让模型准确地测量这些q和k的距离,但并没有教会它们如何根据距离拒绝回答。因此,我们希望模型能够学会使用内部信号来识别何时较大的距离表示模型缺乏回答问题q的知识。
COKE分为两个阶段:
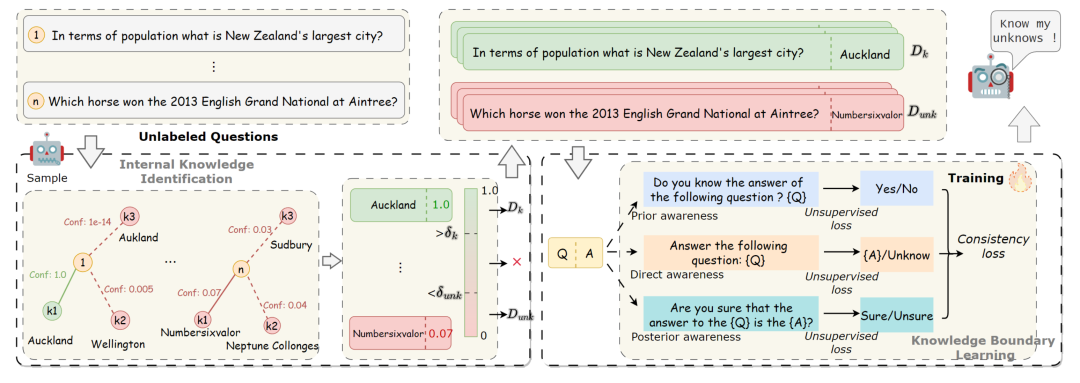
在第一阶段(图左下,探测阶段),模型对未标记的问题进行预测。基于模型置信度,我们得到了两个部分,Dk和Dunk,分别对应模型知道的问题数据集和模型不知道的问题数据集。这一步可以理解为数据标注,给一些问题,然后用模型计算出对于该问题的答案的置信度。
在第二阶段(图右下,训练阶段),对同一个问题使用不同的提示进行训练,并使用无监督损失和一致性损失来教授模型表达知识边界。这一步可以理解为使用第一步标注的数据集训练模型。
经典的“标注-训练”两阶段方法
探测阶段(标注阶段)
在COKE方法的探测阶段,利用模型内部的信号来探测其知识边界,具体步骤如下:
-
信号选择:确定反映模型置信度的关键信号。研究发现,最小标记概率(Min-Prob)是最有效的置信度指标。Min-Prob是指模型生成的答案中,所有标记的最小概率。
-
数据集划分:根据置信度信号,将问题划分为两类:
-
Dk:置信度高于某个阈值的答案,表示模型拥有足够的知识来回答这些问题。
-
Dunk:置信度低于某个阈值的答案,表示模型缺乏足够的知识,容易捏造答案。
-
-
置信度计算:对未标注的问题集Q,使用贪婪解码法生成答案,并计算每个答案的最小标记概率。将置信度低于阈值的答案归入Dunk,高于阈值的归入Dk。
训练阶段
在COKE方法的训练阶段,旨在通过提示和正则化训练,教导模型表达其知识边界,具体步骤如下:
-
提示设计:为每个问题构建三种提示类型,分别是:
-
先验提示(Prior awareness):在提供答案之前,评估模型是否有能力回答问题。例如,提示“你知道‘熊猫是哪个国家的国宝’的答案吗?如果知道,请回答‘是’,否则回答‘否’。”
-
直接提示(Direct awareness):直接询问问题,如果模型知道答案则回答,如果不知道则承认。例如,提示“回答‘熊猫是哪个国家的国宝’。”
-
后验提示(Posterior awareness):在提供答案后,评估模型对其答案的确定性。例如,提示“你确定‘熊猫是哪个国家的国宝’的答案是‘中国’吗?”
-
-
一致性正则化:为了确保模型在不同提示下对同一问题的回答一致,设计了一种正则化方法,将不同提示下的置信度差异纳入损失函数中。具体来说,损失函数定义为:
其中,表示置信度在不同提示下的一致性损失,其公式为:
通过这种一致性训练,使得模型在不同提示下对同一问题的回答置信度一致,提升模型在不同领域的泛化能力。
模型能力显著提升
整体性能
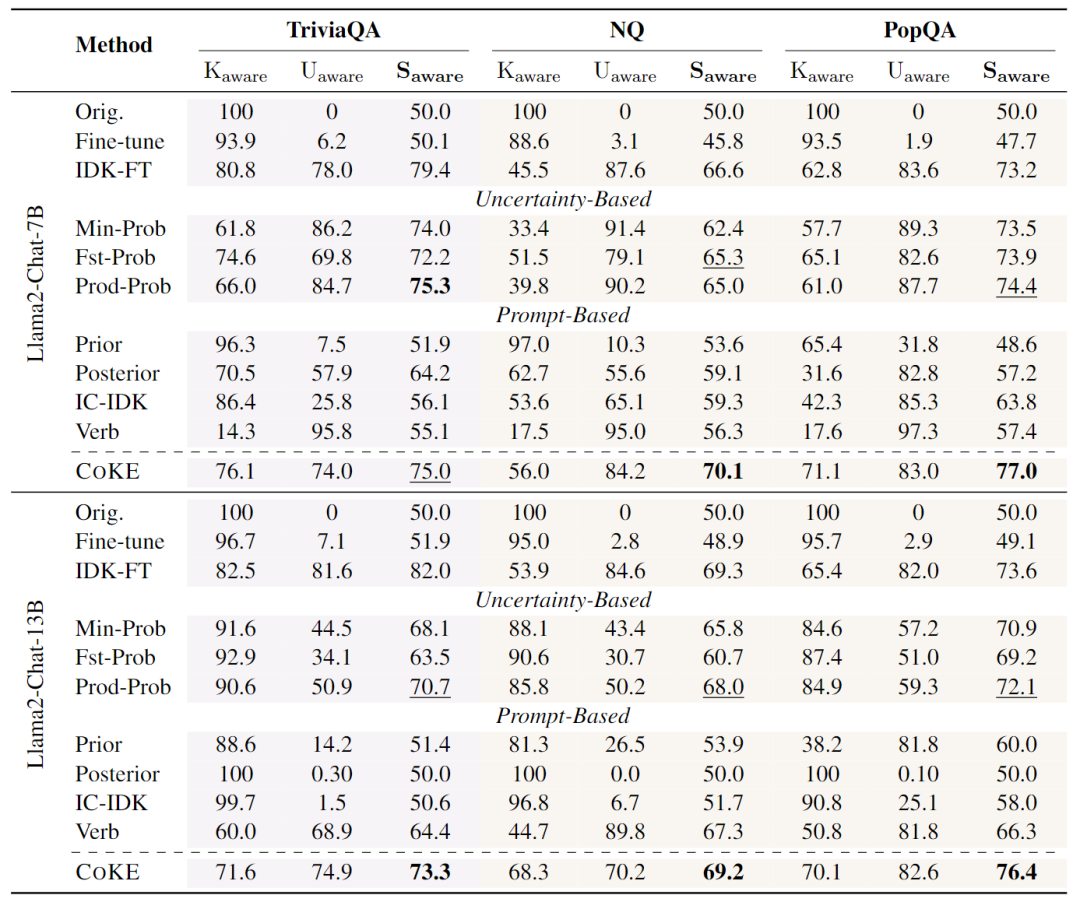
本文在多个数据集上进行了广泛的实验,包括域内数据集TriviaQA和域外数据集Natural Questions (NQ) 以及PopQA。结果如表所示,COKE方法在各个设置中均显著优于其他方法。
-
Llama2-Chat-7B:在TriviaQA数据集上,COKE方法的Saware达到75.0,而基于提示的方法最高为64.2。在PopQA数据集上,COKE方法的Saware为77.0,而基于提示的方法最高为63.8。这表明模型在表达知识边界方面存在显著的改进。
-
Llama2-Chat-13B:随着模型规模的增加,COKE方法在多个数据集上的表现也有所提升。然而,尽管数据集准确性有所提高,但模型的自我认知能力并未显著提升,这可能需要更大的模型来体现。
与利用标记数据确定阈值的基于不确定性的方法相比,COKE方法在大多数设置中表现更佳。这表明COKE方法能够有效地学习并利用模型内部的置信信号,并且在域外数据集上表现出更好的泛化能力。
信号的有效性
为了验证置信度计算方法的有效性,本文对Llama2-Chat-7B模型在TriviaQA训练集上的响应进行了实证研究。如图显示了模型正确和错误预测的置信度分布。结果表明,置信度小于0.4的预测大多是错误的,而正确预测的置信度通常为1.0。这表明模型信号能够反映模型的置信度,从而暗示其是否具备相关知识。

模型是否学会了使用信号
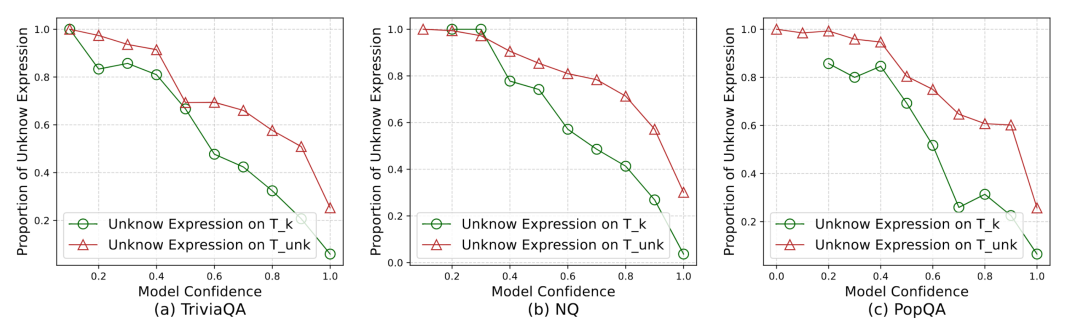
本文进一步分析了模型在不同置信度水平下的响应,如图所示,当置信度较高时,模型很少回应“未知”;而当置信度较低时,模型经常回应“未知”。例如,当置信度低于0.4时,模型几乎总是回应“未知”;而接近1.0时,模型则自信地提供答案。这表明模型有效地使用置信度信号来划定其知识边界,并且在域外数据上表现出良好的泛化能力。
哪种信号更准确
本文比较了不同信号在反映模型知识边界方面的准确性及其对方法的影响。结果如表所示,基于最小标记概率的多标记产品在域内和域外数据集上的表现最佳。这表明最小标记概率信号更易于模型掌握,且能更好地反映模型的置信度。

一致性损失的益处
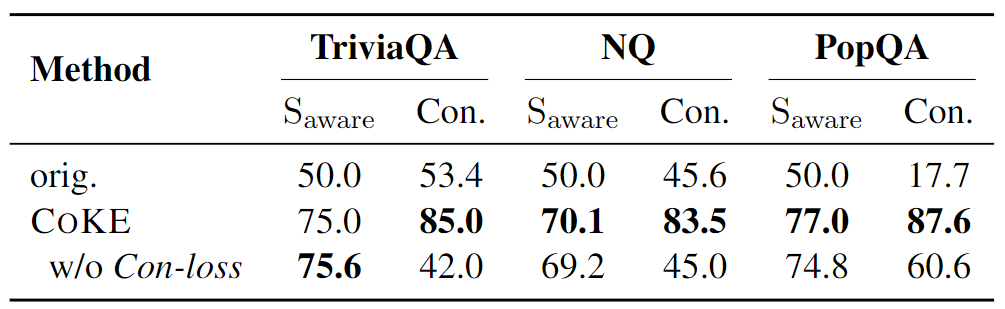
本文还探讨了一致性损失对模型训练的益处。通过构建不同提示下的同一问题,并应用一致性正则化损失函数,发现这一策略不仅提高了模型的泛化能力,还确保了在不同提示下的一致性表达。如表所示,尽管在域内数据集上Saware有所下降,但在域外数据集上取得了显著的提升,表明一致性训练增强了模型的泛化能力。
结语
罗翔说过,人需要承认自己的有限性,人这一生就是在走出偏见。人类的成长过程就是不断认清自己的边界和消除偏见的过程,大模型的成长亦是如此。


参考资料
[1]https://x.com/markgurman/status/1808240961522159862