#数据结构 笔记一
数据结构是计算机存储、组织数据的方式。
数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。数据结构是带有结构特性的数据元素的集合,它研究的是数据的逻辑结构和物理结构以及它们之间的相互关系,并对这种结构定义相适应的运算,设计出相应的算法,并确保经过这些运算以后所得到的新结构仍保持原来的结构类型。 通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率。
总结:
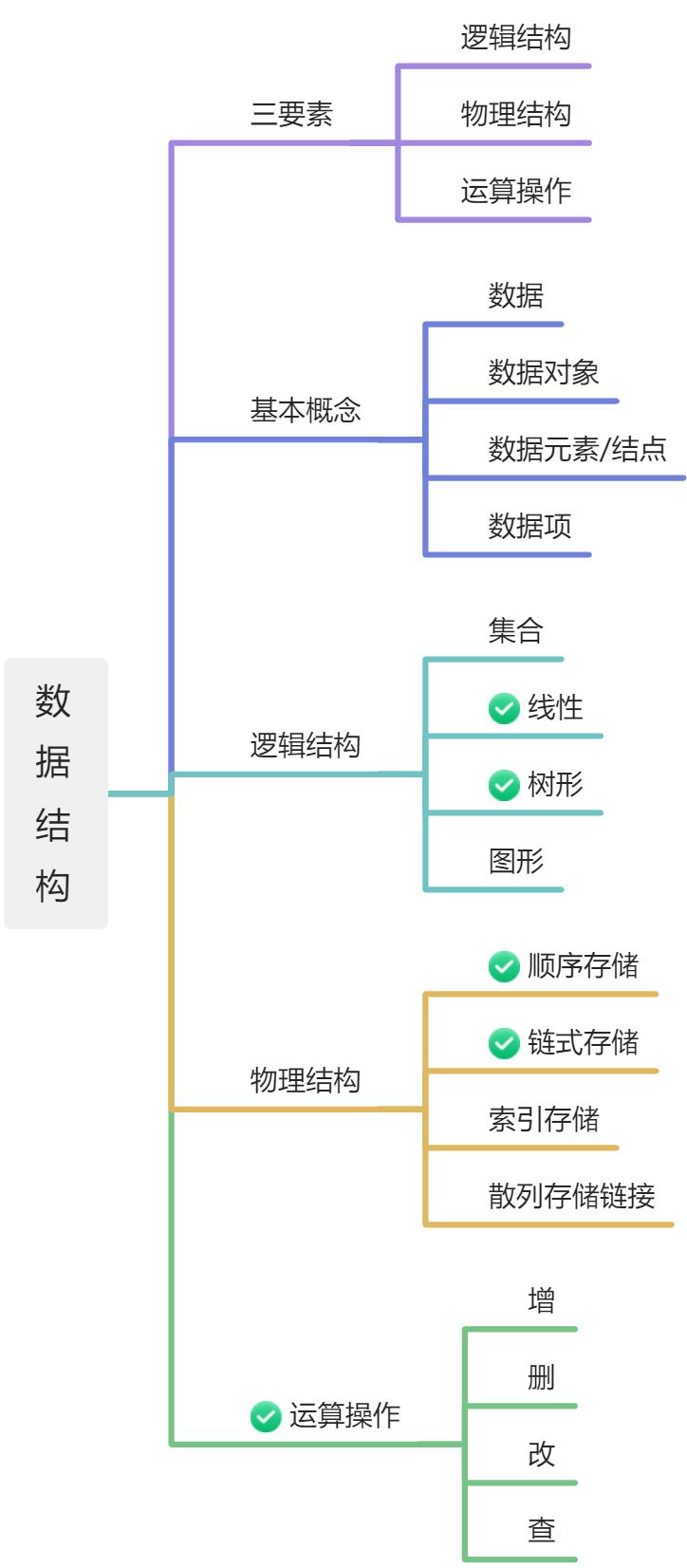
学习数据结构主要学习数据元素集合的逻辑结构、物理结构以及对数据元素集合的运算操作。
数据结构三要素:
1. 逻辑结构
2. 物理结构(计算机里面存储方式)
3. 运算操作
1. 基本概念
数据:描述客观事物的符号,是计算机中可以操作的对象,是能被计算机识别,并输入给计算机处理的符号集合。
数据不仅仅包括整型、实型等数值类型,还包括字符及声音、图像、视频等非数值类型。
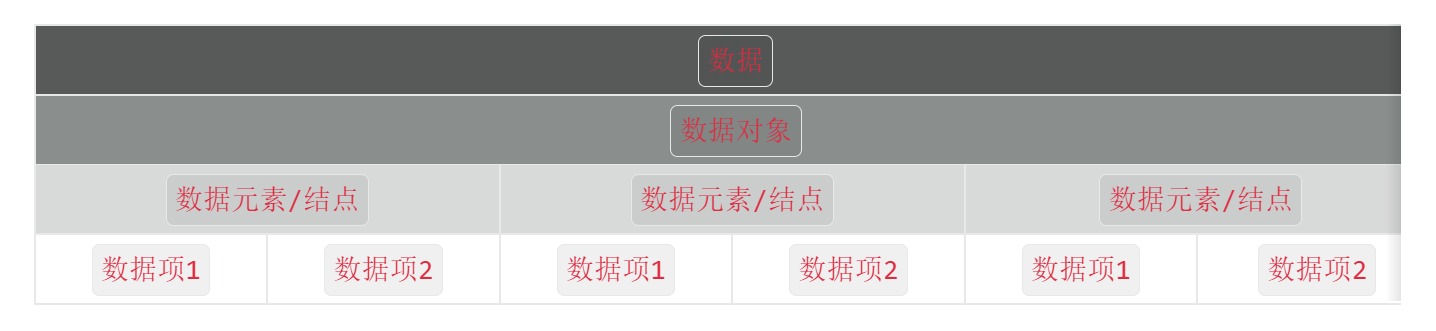
数据元素:数据元素是组成数据且有一定意义的基本单位,在计算机中通常作为整体处理。又被称为结点。
结点这个词一定要熟悉,在链表中会大量出现。
数据项:一个数据元素可以由若干个数据项组成。数据项是数据不可分割的最小单位。
数据对象:是性质相同的数据元素/结点的集合,是数据的子集。
struct student
{float weight;float height;int age;
};
int main(int argc, char const *argv[])
{struct student t1; // 数据元素/结点t1.weight = 123.6; // 数据项struct student stu_arr_23061[49]; // 数据对象return 0;
}代码中用结构体类型定义的变量叫数据元素,用该数据类型定义的数组叫数据对象,每一个字段叫数据项。
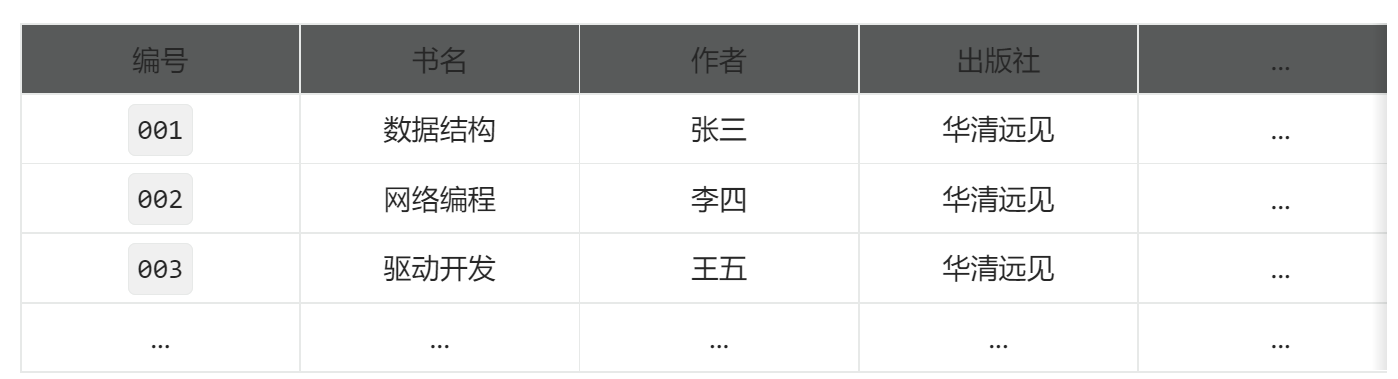
思考:这里的数据元素、数据项以及数据对象都是什么呢?
数据元素:从第二行开始每一行就是一个数据元素。
数据项:对于某数据元素来说,它的编号、书名、作者以及出版社等为数据项。
数据对象:该表格除去第一行结构体定义外,剩下的整体就相当于一个结构体数组。
2. 逻辑结构
数据对象中 数据元素/结点 之间的相互关系。
逻辑结构通常分为以下几种:
2.1、集合结构
数据元素/结点 除了同属于一个集合外,他们之间没有其他关系。
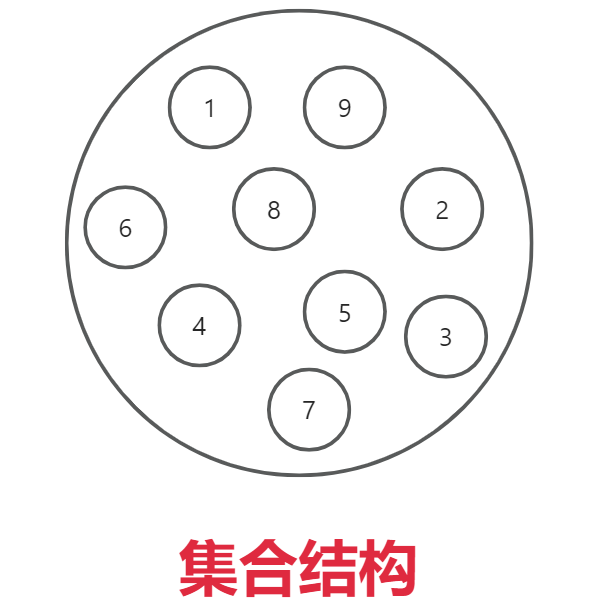
大学同班同学。
2.2、线性结构
数据元素/结点 是一对一的关系。
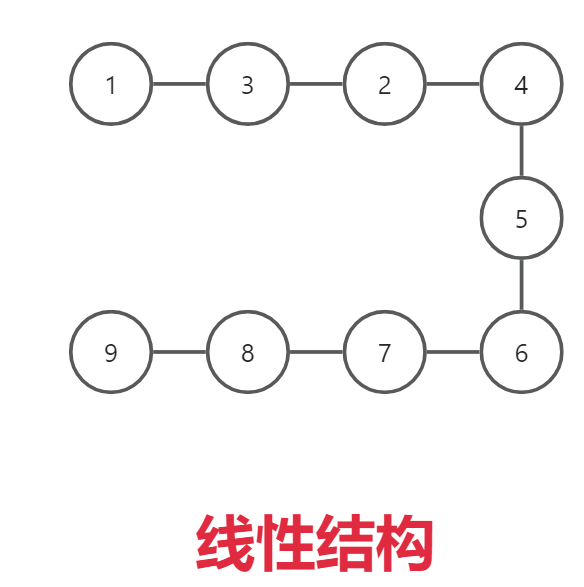
拜把子兄弟十三人。
2.3、树形结构
数据元素/结点 之间存在一种一对多的关系。
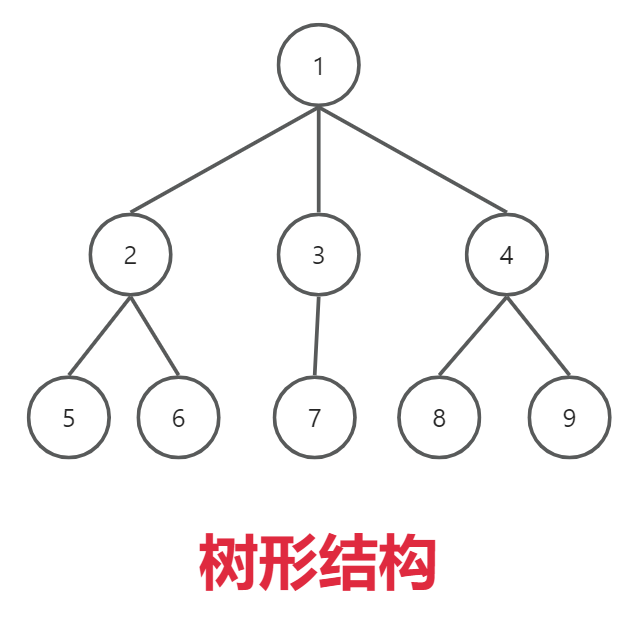
家族中所有男丁
2.4、图形结构
数据元素/结点 之间是多对多的关系

人际关系网
3. 物理结构
数据的逻辑结构在计算机内存中的存储形式。
物理结构通常分为以下几种:
- 顺序存储结构
- 链式存储结构
- 索引存储结构
- 散列存储结构
3.1、顺序存储结构
兄弟十三人或者家族所有男丁,在实际生活中每个人的的家庭住址是挨着的。
把 数据元素/结点 存放在地址连续的存储单元里,这样的存储成为顺序存储结构。
特点:
- 内存连续。
- 相对于链式存储结构每个元素占用的空间少。
3.2、链式存储结构
兄弟十三人或者家族所有男丁,在实际生活中每个人的的家庭住址是分散的,需要依靠地址来联系起来。
把 数据元素/结点 存放在任意的内存单元里。数据元素/结点 之间的逻辑关系通过附设的指针域来表示,由此得到的存储表示成为链式存储结构。
特点:
- 内存不连续(可以连续,只是不关注,默认不连续)
- 通过指针连接
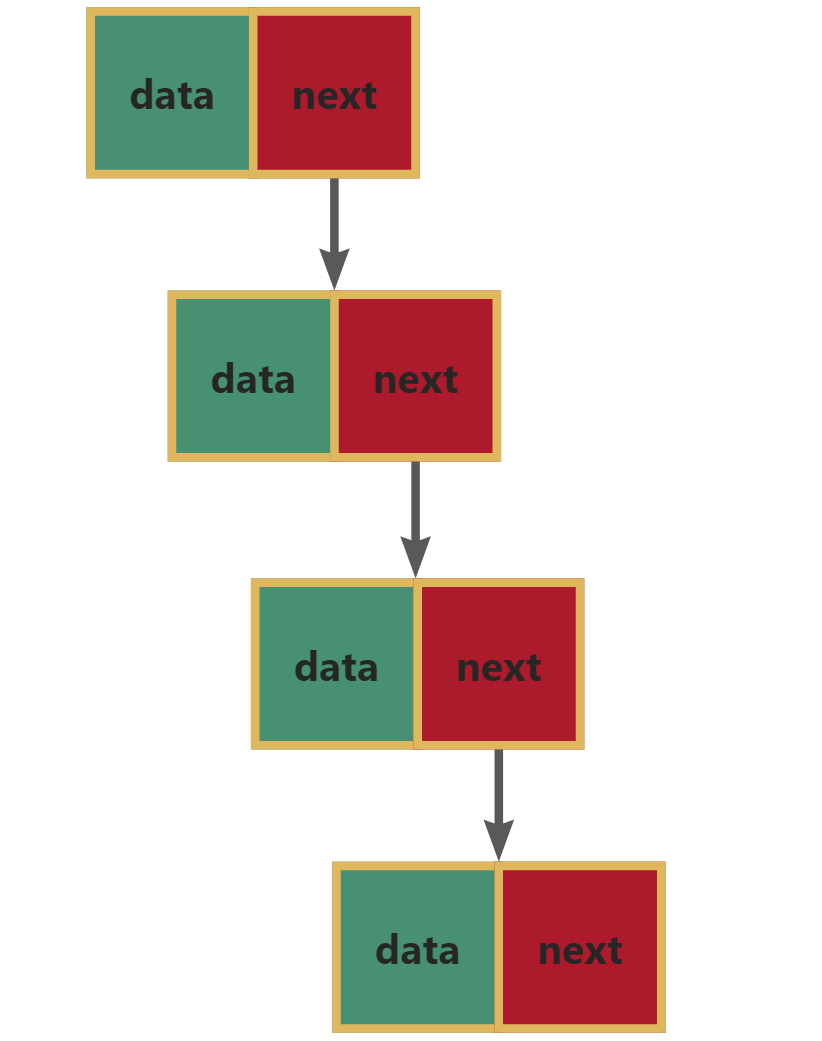
struct Node{int data; // 数据域struct Node *next; // 指针域(指向和自身结构体类型一样的、逻辑上的下一个结点
};// 定义四个节点 ABCD
struct Node A = {1, NULL};
struct Node B = {2, NULL};
struct Node C = {3, NULL};
struct Node D = {4, NULL};// 用指针链接ABCD
A.next = &B;
B.next = &C;
C.next = &D;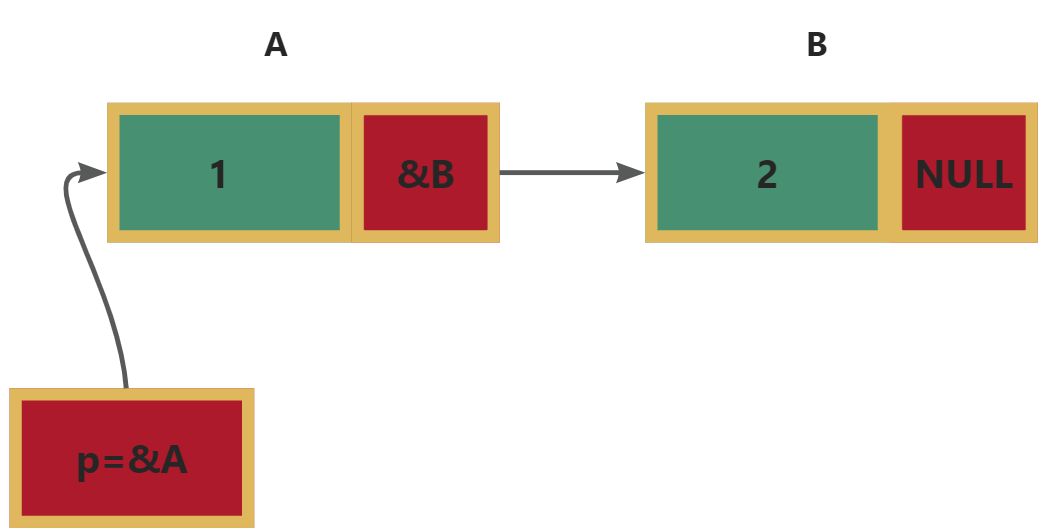
#include <stdio.h>
//构造结构体类型
struct node
{int data;struct node *next;
};
int main(int argc, const char *argv[])
{//定义结构体类型所对应的变量struct node A;A.data = 1;A.next = NULL; struct node B = {2,NULL};//A的第二个成员指向BA.next = &B;//定义p指针遍历A节点和B节点struct node *p = &A;while(p != NULL){//p指向A,A.data <=>p->dataprintf("%d ",p->data);//p指向B,需要把B的地址赋给p//A.next <=>p->next;p = p->next;}printf("\n");return 0;
}输出结果:
1 2
3.3、索引存储结构
在存储数据的同时,建立一个附加的索引表,即索引存储结构 = 数据文件 + 索引表。
电话号码查询问题:为提高查询速度,在存储用户数据文件的同时建立一张姓氏索引表,如下所示:

查找一个人的电话就可以先查索引表,再查相应的数据文件,加快了查询速度。
特点:
- 检索速度快。
- 多了一张索引表,故占用内存多。
- 删除数据文件时要及时更改索引表。
3.4、散列存储结构
通过构造相应散列函数,由散列函数的值来确定 数据元素/结点 存放的地址。
特点:
- 存的时候按照对应关系存。
- 取的时候按照对应关系取。
逻辑结构是面向问题的,物理结构是面向计算机的。
其基本目标就是将数据及其逻辑关系存储到计算机的内存中。
4. 运算操作
最基本的四个操作:增删改查。
以图书管理系统为例:
将一本新书录入系统 增
书丢了需要从系统删除 删
书名写错了需要在系统修改 改
查找某个图书信息 查
回顾
2
6. 算法
概念
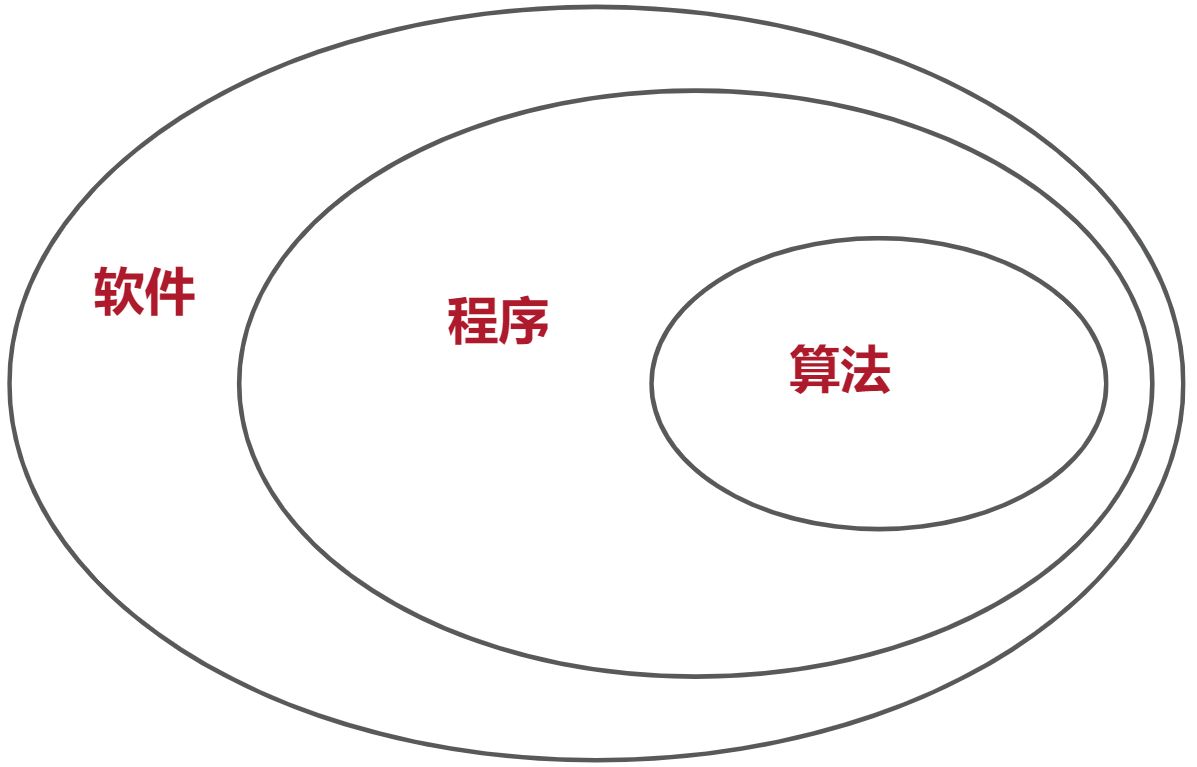
软件 = 程序 + 文档
程序 = 数据结构 + 算法
软件 = 数据结构 + 算法 + 文档
算法 = 对结点集合的运算和操作 + 控制结构
算法(Algorithm)的概念在计算机科学领域中几乎无处不在,在各种计算机系统的实现中,算法的设计往往处于核心的位置。计算机的问世是20世纪算法是计算机科学的重要基础,就像算盘一样,人们需要为计算机编制各种各样的“口诀”即算法,才能使其工作。
算法用来描述对特定问题的求解步骤,它是指令的有限序列,其中每一条指令代表一个或多个操作。
特征
算法五大特征:
- 有穷性:一个算法必须总是(对任何合法的输入值)在执行有穷步以后结束,且每一步都可以在有穷的时间内完成。
- 确切性:算法中每一个指令都必须有确切的含义,读者和计算机在理解时不会产生二义性。
- 可行性:一个算法是能行的,即算法中描述的操作都是可以通过执行有效次基本运算来实现。
- 输入性:一个算法有零个输入或多个输入,以刻画运算对象的初始情况。
所谓零个输入就是指算法本身给出了初始条件,int a = 5;
5。输出性:一个算法必须有一个输出或多个输出,以反映出对输入数据加工后的结果,没有输出的算法是毫无意义的。
描述
算法的描述形式多种多样,不同的描述形式对算法的质量有一定的影响。描述同一个算法可以采用自然语言、流程图、盒图、伪代码以及程序设计语言等,常用的描述算法方法有如下四种。
1. 自然语言描述法
最简单的描述算法的方法是使用自然语言,用自然语言来描述算法的优点是简单且便于人们对算法的理解和阅读,缺点是不够严谨,易产生歧义。当算法比较复杂且包含很多转移分支时,用自然语言描述就不是那么直观清晰了。
2。 算法框图法
使用程序流程图、盒图等算法描述工具来描述算法。其特点是简洁明了、便于理解和交流。
3. 伪代码语言描述法
用上述两种方法描述的算法并不能够直接在计算机上执行。为了解决理解与执行之间的矛盾,人们常常使用一种称为伪代码语言的描述方法来对算法进行描述。伪代码语言介于高级程序设计语言和自然语言之间,它忽略高级程序设计语言中一些严格的语法规则与描述细节,因此它比程序设计语言更容易描述和被人理解,而比自然语言或算法框图更接近程序设计语言。
4. 高级程序设计语言描述法
使用特定的可以直接在计算机上执行的程序描述算法。优点是不用转换直接可以编译执行,缺点是需要对特定的程序设计语言比较理解。大部分的算法最终是需要通过能够向计算机发送一系列命令的程序来实现的。
所谓“程序”是指对所要解决问题的各个对象和处理规则的描述,或者说是数据结构和算法的描述,因此有人说“数据结构+算法 = 程序”。
程序与算法不同。
程序可以不满足算法的有穷性,例如,操作系统,它是在无限循环中执行的程序,因而不是算法。然而可以把操作系统的各种任务看作一些单独的问题,每一个问题由操作系统中的一个子程序通过特定的算法实现,该子程序得到输出结果后便终止。
标准
在现实社会中,不同的人对于同一问题会有不同的看法或解决方法。同样,在计算机领域,对于同一问题可能存在多种算法也是很自然的事情。例如,对于一批数据的排序问题,就存在多种排序方法。判断一个算法的好坏主要依据以下四个标准。
衡量一个算法的好坏的四个标准:正确性、可读性、健壮性、高效率和低存储量的特征。
1. 正确性
算法至少应该具有输出、输出和加工处理无歧义性、能正确反映问题的需求、能够得到问题的正确答案。
2. 可读性
便于阅读、理解和交流。
3. 健壮性
当输入数据不合法时,算法也能做出相关处理,而不是产生异常或莫名其妙的结果。
4. 时间效率高与低存储量需求
时间效率指算法的执行时间,存储量主要指算法程序运行时所占用的内存或外部硬盘空间。设计算法应该尽量班组时间效率高和存储量低的要求。
时间复杂度
1. 前言
对于一个算法的复杂性分析主要是对算法效率的分析,包括衡量其运行速度的时间效率,以及其运行时所需要占用的空间大小。对于算法的时间效率的计算,通常是抛开与计算机硬件、软件有关的因素,仅考虑实现该算法的高级语言程序。
算法的时间复杂度是一个函数,它定性描述该算法的运行时间,时间复杂度常用 O 表述,它衡量着一个程序的好坏,时间复杂度的估算是算法题的重中之重。
2. 概念
要想计算时间复杂度首先得找到该算法中的循环,算法中循环执行的次数就是算法的时间复杂度。
通常时间复杂度用一个问题规模函数来表达:T(n) = O(f(n))
T(n) 问题规模的时间函数
n 代表的是问题的规模 输入数据量的大小
O 时间数量级
f(n) 算法中可执行语句重复执行的次数3. 计算
给定N个元素的数组a[N],求其中奇数多少个。
判断一个数是偶数还是奇数,只需要判断它除上2的余数是0还是1,把所有数都判断一遍,并且对符合条件的情况进行计数,最后返回这个计数就是答案,需要遍历所有的数,因此代码为:
for (i = 0; i < n; i++)if (a[i] % 2)num++;由代码段知,该函数中只有一层for循环,而该循环执行了n次,因此时间复杂度为O(N)。
求下面函数的时间复杂度。
void func()
{int num = 0;for (int i = 0; i < N; i++)for (int j = 0; j < N; j++)num++; // 两层循环,每次循环n次,因此为n*nfor (int k = 0; k < N; k++)++num; // 一层循环,循环n次for (int l = 0; l < 10; l++)++num; // 一层循环,循环10次
}由注释,可列出计算时间的复杂度的表达式:N*N+N+10但是我们能写成O(N*N+N+10)吗?
我们知道,对于时间复杂度我们不需算出精确的数字,只需要算出这个算法属于什么量级即可,我们又如何知道它属于哪个量级呢?即我们将字母取无穷大,例如本题中字母为N,N取无穷大,而10对于N取无穷大后没有影响,因此10可以舍去,原表达式化为N*N+N+10但是我们能写成O(N*N+N+10)吗?
我们知道,对于时间复杂度我们不需算出精确的,再转化为N×(N+1),由于N为无穷大,因此+1也是没有影响的,原式就变成了O(N*N)即O(N2)。这就是大 O 渐近表示法,只是一种量级的估算,而不是准确的值。
由此可得计算时间复杂度的一般规律(大O表示法)N*N+N+10
- 如果有常数项将其置为
1。N*N+N+1 - 去除表达式中所有加法常数。
N*N+N - 修改的表达式中 只保留最高阶项,因为只有它才会对最终结果产生影响。
N*N - 如果最高阶项系数存在且不是
1,则将其系数变为1,得到最后的表达式。N*N
计算冒泡排序的时间复杂度。
for (i = 0; i < N-1; i++)for (j = 0; j < N-1-i; j++)if(a[j] > a[j+1]){a[j] ^= a[j+1];a[j+1] ^= a[j];a[j] ^= a[j+1];}![]()
例如在这个冒泡排序中,我们需要将无序数组转化为有序数组的一种算法,它并不像上题一样是简单的双层嵌套循环,很容易想到它的循环次数是一个等差数列,第一次循环N-1次,第二次N-2次.....一直到1。
因此为N-1 + N-2 + N-3 + ... + 1 = (N-1)*N/2由上面所说的规律时间复杂度为O(N2)。
通过上面的例子我们看出,大 O 渐近表示法去掉了对结果影响不大的项,简洁明了地表示出了时间复杂度。在实际情况中一般只关注算法的最坏运行情况。
例如在上述冒泡排序中如果给定的数组就已经是有序的了,那么就是它的最好情况,时间复杂度为O(N)。
但是如果有非常多的数据很显然我们看不出它到底是否为最好情况,所以我们必须用最坏的期望来计算所以它是O(N*N)。
函数内循环为常数次
int fun(int n)
{int i = 0, num = 0;for(; i<100; i++)num++;return num;
}此时时间复杂度为O(1),这里的1不是指一次,而是常数次,该循环执行了100次,不管n多大,他都执行100次,所以是O(1)。
4. 练习
f(n) = 3*n5 + 2*n3 + 6*n + 10
常数项10置为1 f(n) = 3*n5 + 2*n3 + 6*n + 1
保留最高项3*n5 f(n) = 3*n5 + 2*n3 + 6*n + 1
最高项3*n5系数不为1则除以3 f(n) = n5
T(n) = O(n5)
f(n) = 8
常数项8置为1
保留最高项1*n0
最高项1*n0系数为1
T(n) = O(n0) = O(1)
总结
