datawhale大模型应用开发夏令营学习笔记一
参考自
- 基于LangChain+LLM的本地知识库问答:从企业单文档问答到批量文档问答
- datawhale的llm-universe
作者现在在datawhale夏令营的大模型应用开发这个班中,作为一个小白,为了能为团队做出一点贡献,现在就要开始学习怎么使用langchain的api来实现基本的功能!
随便谈谈
由于科大讯飞的星火杯已经为我们提供了 星火大模型 的API,我也不好进行模型调参,现在能做的就是开展prompt工程,结合RAG,给到模型优质的输入信息,帮助它正确回答我提出的疑问和要求。我首先学的就是这两个。
我一开始的想法是做本地知识库,那么模型是怎么知道这些知识呢?我们知道一个人的知识储备,可以来自他的积累,也可以来自他现在手里正翻着的书(或者当场百度:))。大模型也一样。我们可以在训练大模型时让他学习庞大的知识,也可以在提问一些小众知识时附加可参考的内容(比如在询问一个rust的第三方库怎么用时,顺带把这个库的文档文本一起给他,让他参考这些文档进行回答)
- 参数知识:在训练期间学习到的知识,隐式存储在神经网络的权重中。
- 非参数知识:存储在外部知识源中,例如向量数据库。
当然,直接传整篇文档的方式比较粗暴,可以事先将全篇文档放入向量数据库或知识图谱(统称为知识库)。那么一次问答的过程为:首先用户提问请回答我的xx问题,然后大模型根据用户的提问去知识库中匹配并获取相关的参考资料,然后再将用户输入改为根据 xxxxx 这些参考资料,请回答我的xx问题并传入大模型。
一步步基于langchain实现讯飞大模型的调用和RAG
主要参考自datawhale的教程https://github.com/datawhalechina/llm-universe/tree/main/notebook,确实比较详细
我实操的大概过程为:
- 调用星火大模型
- 读取Markdown或pdf作为本地知识,并解析出其中的文本,并进行数据清洗
- 对解析出的文本进行文本切分。因为单个文档的长度往往会超过模型支持的上下文,导致检索得到的知识太长超出模型的处理能力
- 调用星火的文本向量化接口
- 使用Chroma存储向量并检索,即建立本地知识库
- 使用template,并使用langchain的
LCEL语法实现一条链式处理,该链将获取输入变量,将这些变量传递给提示模板以创建提示,将提示传递给语言模型,然后通过(可选)输出解析器传递输出。 - 将"知识库检索"这一过程加入处理链中,实现大模型链接本地知识库
- 基于Memory模块让大模型能使用到历史对话,实现带上下文的对话
- streamlit的教学我没看,目前考虑使用Gradio
以上过程均基于langchain的api。
我这里只放一些重点内容,对详细过程感兴趣的同学可以跟着教程继续学习,我就不粘贴一遍教程里的代码了
RAG和微调的对比
| 特征比较 | RAG | 微调 |
|---|---|---|
| 知识更新 | 直接更新检索知识库,无需重新训练。信息更新成本低,适合动态变化的数据。 | 通常需要重新训练来保持知识和数据的更新。更新成本高,适合静态数据。 |
| 外部知识 | 擅长利用外部资源,特别适合处理文档或其他结构化/非结构化数据库。 | 将外部知识学习到 LLM 内部。 |
| 数据处理 | 对数据的处理和操作要求极低。 | 依赖于构建高质量的数据集,有限的数据集可能无法显著提高性能。 |
| 模型定制 | 侧重于信息检索和融合外部知识,但可能无法充分定制模型行为或写作风格。 | 可以根据特定风格或术语调整 LLM 行为、写作风格或特定领域知识。 |
| 可解释性 | 可以追溯到具体的数据来源,有较好的可解释性和可追踪性。 | 黑盒子,可解释性相对较低。 |
| 计算资源 | 需要额外的资源来支持检索机制和数据库的维护。 | 依赖高质量的训练数据集和微调目标,对计算资源的要求较高。 |
| 推理延迟 | 增加了检索步骤的耗时 | 单纯 LLM 生成的耗时 |
| 降低幻觉 | 通过检索到的真实信息生成回答,降低了产生幻觉的概率。 | 模型学习特定领域的数据有助于减少幻觉,但面对未见过的输入时仍可能出现幻觉。 |
| 伦理隐私 | 检索和使用外部数据可能引发伦理和隐私方面的问题。 | 训练数据中的敏感信息需要妥善处理,以防泄露。 |
LangChain
封装了很多模型的调用方式以及工具比如chain、memory等
https://python.langchain.com/v0.2/docs/integrations/llms/
Prompt
在 ChatGPT 推出并获得大量应用之后,Prompt 开始被推广为给大模型的所有输入。即,我们每一次访问大模型的输入为一个 Prompt,而大模型给我们的返回结果则被称为 Completion。
Temperature
LLM 生成是具有随机性的,我们一般可以通过控制 temperature 参数来控制 LLM 生成结果的随机性与创造性。
Temperature 一般取值在 0~1 之间,当取值较低接近 0 时,预测的随机性会较低,产生更保守、可预测的文本,不太可能生成意想不到或不寻常的词。当取值较高接近 1 时,预测的随机性会较高,所有词被选择的可能性更大,会产生更有创意、多样化的文本,更有可能生成不寻常或意想不到的词。
对于不同的问题与应用场景,我们可能需要设置不同的 temperature。例如,在个人知识库助手项目中,我们一般将 temperature 设置为 0,从而保证助手对知识库内容的稳定使用,规避错误内容、模型幻觉;在产品智能客服、科研论文写作等场景中,我们同样更需要稳定性而不是创造性;但在个性化 AI、创意营销文案生成等场景中,我们就更需要创意性,从而更倾向于将 temperature 设置为较高的值。
System Prompt
在使用 ChatGPT API 时,你可以设置两种 Prompt:一种是 System Prompt,该种 Prompt 内容会在整个会话过程中持久地影响模型的回复,且相比于普通 Prompt 具有更高的重要性;另一种是 User Prompt,这更偏向于我们平时提到的 Prompt,即需要模型做出回复的输入。
System Prompt 一般在一个会话中仅有一个。在通过 System Prompt 设定好模型的人设或是初始设置后,我们可以通过 User Prompt 给出模型需要遵循的指令。
例如,当我们需要一个幽默风趣的个人知识库助手,并向这个助手提问我今天有什么事时,可以构造如下的 Prompt:
{"system prompt": "你是一个幽默风趣的个人知识库助手,可以根据给定的知识库内容回答用户的提问,注意,你的回答风格应是幽默风趣的","user prompt": "我今天有什么事务?"
}
Prompt工程
可以理解为使用结构化的提问方式,向模型传入更详细的提问内容,引导大模型进行更精确和正确的回答
具体可参考https://github.com/datawhalechina/llm-universe/blob/main/notebook/C2%20%E4%BD%BF%E7%94%A8%20LLM%20API%20%E5%BC%80%E5%8F%91%E5%BA%94%E7%94%A8/3.%20Prompt%20Engineering.ipynb
此次开发用到的官方文档
- langchain中使用sparkllm
- langchain中使用spark的文本向量化
- langchain中解析文件中的文本
- langchain中使用Chroma
还是贴个代码
知识库为一篇Markdown https://github.com/sunface/rust-course/blob/main/src/advance/macro.md
这里的代码参考datawhale的代码,只实现了链接知识库和结合上下文对话,没有用到LCEL。深入源码以及看官方文档后发现,LangChain非常多的API弃用或将被弃用,API改动这么频繁,而且有些API都不好在IDE里跳到源码,难怪langchain的争议这么大。
import os
import re
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.llms.sparkllm import SparkLLM
from langchain_community.embeddings import SparkLLMTextEmbeddings
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain.prompts.chat import ChatPromptTemplate,SystemMessagePromptTemplate,HumanMessagePromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain.prompts import PromptTemplate
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain# 通过环境变量的方式设置秘钥,具体的key-value可以在IDE内点进源码查看
def load_env():# 星火认知大模型Spark Max的URL值,其他版本大模型URL值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看#星火认知大模型调用秘钥信息,请前往讯飞开放平台控制台(https://console.xfyun.cn/services/bm35)查看#星火认知大模型Spark Max的domain值,其他版本大模型domain值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看os.environ["IFLYTEK_SPARK_API_URL"] = "wss://spark-api.xf-yun.com/v3.5/chat"os.environ["IFLYTEK_SPARK_API_KEY"] = ""os.environ["IFLYTEK_SPARK_API_SECRET"] = ""os.environ["IFLYTEK_SPARK_APP_ID"] = ""os.environ["IFLYTEK_SPARK_LLM_DOMAIN"] = "generalv3.5"# 文本向量化os.environ["SPARK_APP_ID"] = ""os.environ["SPARK_API_KEY"] = ""os.environ["SPARK_API_SECRET"] = ""# 使用UnstructuredMarkdownLoader读取时似乎不能读emoji
# 此时需要预先处理文件,再使用API解析无emoji的Markdown文件
def remove_emojis(text):try:co = re.compile(u'[\U00010000-\U0010ffff]')except re.error:co = re.compile(u'[\uD800-\uDBFF][\uDC00-\uDFFF]')no_emojis_text = co.sub(r'', text)return no_emojis_text# 长文本切分为多个小文档
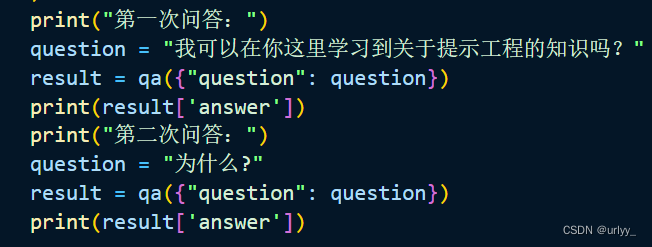
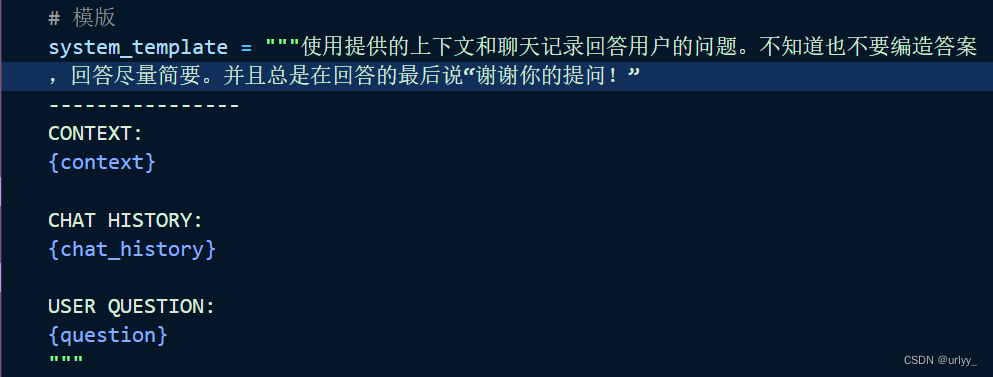
def text_split(doc):# 知识库中单段文本长度CHUNK_SIZE = 500# 知识库中相邻文本重合长度OVERLAP_SIZE = 50# 使用递归字符文本分割器text_splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE,chunk_overlap=OVERLAP_SIZE)return text_splitter.split_documents(doc)def prepare_knowledge():# 此篇文章无emojifiles = ["macro.md"]md_pages = []for f in files:loader = UnstructuredMarkdownLoader(f)md_page = loader.load()# 打印这个文档来自哪个的文件名# source = md_page.metadata['source']# print(source)# 删除无必要的连续换行md_page[0].page_content = md_page[0].page_content.replace('\n\n', '\n')md_pages.extend(md_page)# 文本切分docs = text_split(md_pages)# 实例化星火文本向量化接口的调用工具embeddings = SparkLLMTextEmbeddings()# 可以直接调用来向量化文本# embeddings.aembed_query(text)/aembed_documents(doc)# 初始化一个Chroma向量数据库,让Chroma将文档向量化# 并将数据库文件和向量数据保存到文件夹中vectordb = Chroma.from_documents(documents=docs,embedding=embeddings,persist_directory='./vector')vectordb.persist()if __name__ == '__main__':# 设置环境变量load_env()# 实例化星火大模型调用工具llm = SparkLLM(temperature=0.95)# 初始化知识库prepare_knowledge()# 加载本地知识库embeddings = SparkLLMTextEmbeddings()vector_db = Chroma(persist_directory="./vector", embedding_function=embeddings)# 对话历史记录memory = ConversationBufferMemory(memory_key="chat_history",return_messages=True, # 将以消息列表的形式返回聊天记录,而不是单个字符串)# 模版system_template = """使用提供的上下文和聊天记录回答用户的问题。不知道也不要编造答案,回答尽量简要。并且总是在回答的最后说“谢谢你的提问!”----------------CONTEXT:{context}CHAT HISTORY:{chat_history}USER QUESTION:{question}"""messages = [SystemMessagePromptTemplate.from_template(system_template),HumanMessagePromptTemplate.from_template("{question}")]qa_prompt = ChatPromptTemplate.from_messages(messages)# 创建问答链,为其添加检索知识库和历史记录的功能qa = ConversationalRetrievalChain.from_llm(llm,retriever=vector_db.as_retriever(),combine_docs_chain_kwargs={'prompt': qa_prompt},memory=memory)print("第一次问答:")question = "我可以在你这里学习到关于提示工程的知识吗?"result = qa({"question": question})print(result['answer'])print("第二次问答:")question = "为什么?"result = qa({"question": question})print(result['answer'])
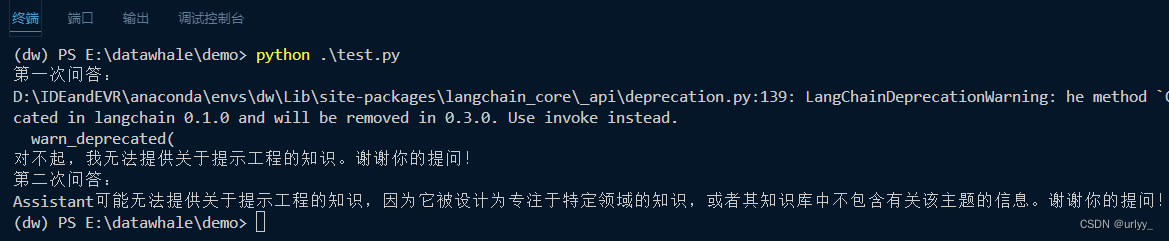
由于突然文本向量化接口突然报错,上述代码我这里测试不了构建知识库了。但好在可以加载之前构建好的知识库来测试后面的代码。代码总体应该没问题,之后再看看
Request error: 11202, {‘header’: {‘code’: 11202, ‘message’: ‘licc failed’, ‘sid’: ‘emb000fc090@dx1907452bed6738d882’}}
Request error: 11202, {‘header’: {‘code’: 11202, ‘message’: ‘licc failed’, ‘sid’: ‘emb000ebcb7@dx1907452bf547020882’}}
TODO
- 怎么持久化以及加载历史信息,这篇博客到时候可以参考:【LangChain】对话式问答(Conversational Retrieval QA)
- 怎么将知识图谱作为知识库
- 评测和优化