开发AI黑客机器人并上传全云端
博主由于是玩 育碧游戏的 《看门狗:军团》 根据里面的机器人“贝格利”进行开发并受到非常有兴趣的启发
前言:注意:前提概要《请遵守您本国家的相关法律法规,如有其他疑问或者任何事情与我本人无关》
博主谨慎提醒每位小白与技术人员安全者:根据我国法律开发AI、大数据机器人实际使用需要根据相关管理办法和法律备案,请注意在服务器或云上运行的行为与动作,可能一不小心就吃上''FBI”,‘’国家安全饭”!;
此类AI我叫他:小智


尊敬的HACKER:"这种AI“乖”咱们先不用好吗?先看看下面"

概述:黑客机器人开发是指开发一种具有黑客技术的自动化程序或机器人。这些机器人可以执行各种黑客活动,如渗透测试、漏洞扫描、密码破解等。黑客机器人开发需要掌握一定的编程和网络安全知识。
在黑客机器人开发中,常用的编程语言包括Python、C++、Java等。开发者可以利用这些编程语言编写脚本或程序,实现各种黑客技术的功能。同时,还需要了解网络协议、漏洞利用、密码学等等很多的相关知识,与连接,以便能够尽快的理解和应用在黑客机器人与人类情感相互学习交流
相关文献:
AI智能潜在威胁,黑客利用AI聊天机器人轻松入侵网络![]() https://new.qq.com/rain/a/20230106A06VJ200
https://new.qq.com/rain/a/20230106A06VJ200
机器人黑客首次公开挑战人类,黑客的新时代要来了么?![]() https://www.ifanr.com/703679
https://www.ifanr.com/703679
墨云科技开发出Vackbot“虚拟黑客机器人”,代替人工安全服务![]() https://www.elecfans.com/jiqiren/727957.html阿里云:黑客机器人养成中 永信至诚刷新国内网络安全自动化攻防平台
https://www.elecfans.com/jiqiren/727957.html阿里云:黑客机器人养成中 永信至诚刷新国内网络安全自动化攻防平台![]() https://developer.aliyun.com/article/230624墨云科技产品官网
https://developer.aliyun.com/article/230624墨云科技产品官网![]() http://www.vackbot.com
http://www.vackbot.com
目录
前言:注意:前提概要《请遵守您本国家的相关法律法规,如有其他疑问或者任何事情与我本人无关》
相关文献:
一、首先得购买相关机器人模块
1:根据需求需要购买相关产品
或者直接在云编辑器里编程并且云上运行测试,可能效果有差异。
1.2:具体此类产品需要什么?
二、开始行动
编辑
2.2:下载安装Pycharm
三、开发机器人实例与示例
示例
感知模块
简单的示例
认知模块
通信模块
对话管理模块
知识图谱模块
情感分析模块
图像识别模块
电源模块
注:安全第一,小心跳闸
语音语言识别模块
自然语言处理模块
自主学习模块
数据库模块
用户界面模块
智能决策模块
储存数据模块
超速云算法智能芯片模块
定位模块服务
定位模块服务定义
定位模块服务的特点包括
用户组和管理员模块
用户组
管理员模块
降温模块
四、开始上传机器人
那么如何开发完成上传到全世界甚至一个国家?一个区域?或一个地方服务器?
五:购买服务器集群
六:开始行动:
期待中。在写了给我点Time好么
一、首先得购买相关机器人模块
1:根据需求需要购买相关产品
由于我们做的是实体机器人,我们需要进入相关购物网站,或者在Dark Web使用货币BTC、USDT支付(听说能容易购买到更高科技产品),或者某宝某东,选择合适而且兼容的产品进行代码烧入测试

或者直接在云编辑器里编程并且云上运行测试,可能效果有差异。
1.2:具体此类产品需要什么?
-
感知模块:如传感器、摄像头、激光雷达等,用于获取外部环境信息。
-
认知模块:如自然语言处理、计算机视觉等,用于理解和解析用户指令。
-
通信模块:如Wi-Fi、蓝牙等,用于与其他设备的通信。
-
电源模块:如电池、电源管理系统等,为机器人提供能量和持续的电量。
-
语音识别模块:用于将用户的声音转换为文本,以便机器人能够理解用户的指令或问题。
-
自然语言处理模块:用于理解和解释用户的指令或问题,以便机器人能够正确地回答或执行相应的任务。
-
对话管理模块:用于维护对话状态,并根据用户的回答或指令来确定下一步的行动或回答。
-
知识图谱模块:用于存储和组织机器人所需要的知识,使机器人能够回答用户的问题或提供相关信息。
-
情感分析模块:用于分析用户的情感或情绪,以便机器人能够做出相应的回应或调整自己的回应方式。
-
图像识别模块:如果机器人需要处理图像或视觉任务,如人脸识别、物体识别等,那么需要一个图像识别模块。
-
自主学习模块:需要让机器人快速自主学习相关网络安全知识,渗透测试,黑入等相关功能。
-
数据库模块:用于存储和管理机器人的相关数据,如用户资料、对话记录等。
-
用户界面模块:用于与用户进行交互,包括语音输出、文本显示、图像显示等。
-
智能决策模块:用于根据所收集到的信息和数据,进行决策和规划,以便机器人能够智能地执行任务或回答问题。
-
储存数据模块:机器人需要大量硬盘与服务器来储存相关文件与数据,或者云储存,根据需求选择一个可靠的云存储服务提供商,如Google Cloud Storage、Amazon S3、Microsoft Azure等
-
超速云算法智能芯片模块:机器人需要更快的运算速度来完成入侵,渗透测试等活动
-
定位模块服务:开发此机器人需要无差别的卫星导航定位,捕捉目标人物信息库,社工等精确服务
-
用户组和管理员模块:机器人需要识别主人/其他加入此机器人/授权的人
-
降温模块:开发此类机器人需要大量的降温设备确保设备的正常使用运转
-
又需要什么?:
-
需求分析:明确机器人需要完成的具体任务和目标,比如数据抓取、渗透测试等。
- 选择合适的编程语言和工具:根据任务需求选择适合的编程语言,如Python、Ruby或JavaScript等,以及相应的开发环境和工具。
- 设计机器人架构:设计机器人的基本架构,包括数据流、模块划分、接口定义等。
- 编码实现:编写代码来实现机器人的各项功能,这可能包括网络通信、数据处理、自动化脚本等。
- 测试和调试:对机器人进行严格的测试,确保其能够稳定可靠地运行,并根据反馈进行必要的调整和优化。
- 部署到云端:将机器人部署到云端服务器或平台,以便它可以开始执行任务。这通常涉及到配置服务器环境、设置安全措施和启动机器人进程。
- 监控和管理:一旦机器人部署到云端,需要对其进行持续的监控和管理,以确保其正常运行并及时响应任何可能出现的问题
- 准备文件:在上传之前,确保文件没有错误,并且是您想要上传的版本。有时,您可能需要对文件进行压缩或格式转换。
- 网络连接:确保您的设备连接到稳定的互联网连接,以便能够顺利上传文件。
- 权限设置:在上传文件后,您可能需要设置文件的权限,以确保只有授权的用户才能访问这些文件。
- 备份和同步:如果您希望文件能够在多个设备和地点之间同步,请确保您的云存储服务支持这一功能。
- 网络安全性:保护您的文件与网络免受未授权访问,使用加密和其他安全措施来保护您的数据
- 配置机器人软件:根据需要配置机器人软件的运行环境和参数,确保软件能够在云服务器上正确运行。
- 上传机器人代码和文件:将机器人的代码和相关文件上传到云服务器中,以便机器人可以在云端环境中执行任务。
- 测试机器人云服务器连接:通过ping命令或其他网络测试工具测试机器人和云服务器之间的连通性,并运行实际的机器人应用程序来测试数据交互和实时通讯等
-
数据处理:数据处理是指对收集到的数据进行清洗、转换和分析的过程。在云端处理数据时,您可以使用Python的数据处理库,如Pandas、NumPy等。云平台上的数据处理能力通常非常强大,可以轻松处理大规模数据集,并进行复杂的数据分析任务
-
变换地址IP等:通过数据地址进行人物数据兑换/变换位置,以方便隐藏自己的相关位置
综上所述,开发一个机器人需要综合考虑多种技术和组件。每个模块都是互相依赖的,它们共同工作以确保机器人的有效运行。在设计和开发过程中,需要充分考虑机器人的应用场景、功能需求以及预期的性能标准来选取合适的模块。随着技术的发展,未来的机器人可能会变得更加智能化、多样化,但无论如何,这些基本模块将继续是其核心组成部分!
二、开始行动
2.1:首先下载Pycharm,因为是最好识别BUG错误的代码编辑器
感谢您下载 PyCharm!![]() https://www.jetbrains.com.cn/pycharm/download/download-thanks.html?platform=windows
https://www.jetbrains.com.cn/pycharm/download/download-thanks.html?platform=windows

2.2:下载安装Pycharm
首先必须得安装Python.exe,解释器,再安装Pycharm,不然后续无法运行并测试调试BUG,对机器人进行训练
一直点击安装,然后 √ 创建快捷方式 √ 自动创建变√ 创建关联.py
点击下一步是我会重新启动安装
我已阅读并同意,点Continue
安装完成后,点击试用30 Day,当然你也可以选择寻找破解版永久使用
选择New Project 新建对象,找到Python点击,即可开始写程序

默认下一步即可
等待安装.............................................
下一步选择 NEW → Python Flie → 给程序命名 → 即可开始编辑
三、开发机器人实例与示例
示例
1.1:使用Python、JAVA开发,因为它是大部分可靠性和可扩展性开发的/更加全面的AI机器人
2.2:以下示例必须要在编辑器IDE命令行上pip、python安装依赖!也有可能是库的问题.......
3.3:为什么要先示例再实际操作,因为可能是新奇的技术的后者,先了解才知道并且享受学习过程
感知模块
简单的示例
如何使用Python编写一个简单的机器人感知模块,以通过摄像头获取图像,并检测其中的物体.
import cv2def detect_objects():# 打开摄像头cap = cv2.VideoCapture(0)# 创建一个物体检测器object_detector = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')while True:# 从摄像头读取图像ret, frame = cap.read()# 将图像转换为灰度图gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)# 使用物体检测器检测物体objects = object_detector.detectMultiScale(gray, 1.3, 5)# 在图像上绘制检测到的物体for (x, y, w, h) in objects:cv2.rectangle(frame, (x, y), (x+w, y+h), (255, 0, 0), 2)# 显示图像cv2.imshow('Object Detection', frame)# 按下 'q' 键退出循环if cv2.waitKey(1) == ord('q'):break# 释放摄像头cap.release()# 关闭窗口cv2.destroyAllWindows()# 运行物体检测程序
detect_objects()可以通过OpenCV库来读取摄像头图像,并使用haar级联分类器来检测人脸。你可以根据你的需求选择不同的分类器,例如用于检测其他物体的分类器。
在这个示例中,我们通过使用cv2.VideoCapture(0)来打开摄像头,然后在一个while循环中持续读取图像。然后使用cv2.cvtColor()将图像转换为灰度图,以便在其中检测物体。通过使用物体检测器的detectMultiScale()方法,我们可以检测出图像中的物体,并使用cv2.rectangle()在图像上绘制出它们的边界框。最后,我们使用cv2.imshow()来显示图像,并通过按下'q'键来退出程序。
请注意,你需要安装OpenCV库,以及提供训练好的分类器文件(例如haarcascade_frontalface_default.xml)才能运行此示例。你可以从OpenCV官方网站下载这些文件
还可以使用多图形处理结果比较好
import cv2def detect_objects(image):# 使用图像处理算法来检测图像中的物体# 这里使用OpenCV库进行图像处理# 可以根据需要自行选择其他图像处理库# 返回检测到的物体的位置、大小等信息objects = []# 在这里编写图像处理算法,检测物体并将结果存储在objects列表中return objectsdef process_image(image_path):# 读取图像数据image = cv2.imread(image_path)# 对图像进行预处理,如调整大小、转换颜色空间等# 这里可以根据需要添加其他图像预处理步骤# 调用检测函数,获取检测到的物体信息objects = detect_objects(image)# 对检测结果进行处理,如打印物体信息、进行其他操作等for obj in objects:print("Detected object: ", obj)# 可以根据需要返回其他结果# 调用图像处理函数,传入图像路径
process_image("image.jpg")博主发现这个运行正常而且稳定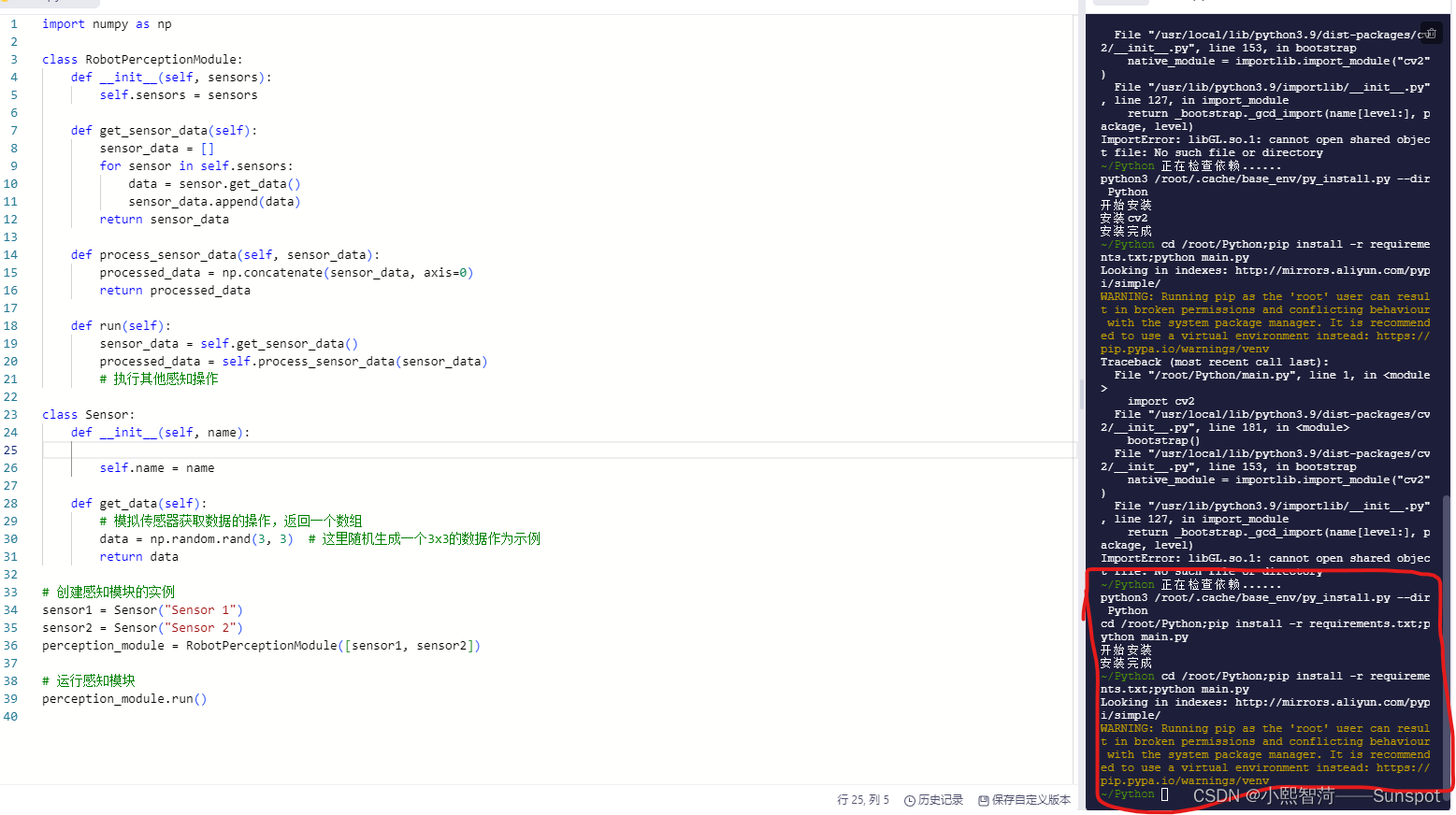
这个示例中,首先定义了一个Sensor类来模拟传感器的行为,然后创建了一个RobotPerceptionModule类作为机器人的感知模块。感知模块中包含了一个get_sensor_data方法来获取所有传感器的数据,一个process_sensor_data方法来处理传感器数据,以及一个run方法用来运行整个感知模块。最后,创建了两个传感器实例,并通过传感器列表将它们传递给感知模块实例,然后调用run方法来执行感知操作
import numpy as npclass RobotPerceptionModule:def __init__(self, sensors):self.sensors = sensorsdef get_sensor_data(self):sensor_data = []for sensor in self.sensors:data = sensor.get_data()sensor_data.append(data)return sensor_datadef process_sensor_data(self, sensor_data):processed_data = np.concatenate(sensor_data, axis=0)return processed_datadef run(self):sensor_data = self.get_sensor_data()processed_data = self.process_sensor_data(sensor_data)# 执行其他感知操作class Sensor:def __init__(self, name):self.name = namedef get_data(self):# 模拟传感器获取数据的操作,返回一个数组data = np.random.rand(3, 3) # 这里随机生成一个3x3的数据作为示例return data# 创建感知模块的实例
sensor1 = Sensor("Sensor 1")
sensor2 = Sensor("Sensor 2")
perception_module = RobotPerceptionModule([sensor1, sensor2])# 运行感知模块
perception_module.run()认知模块
认知模块是一种用于模拟认知过程的计算模型,可以将其实现为一个类
class CognitiveModule:def __init__(self):self.memory = []def perceive(self, input_data):# 获取输入数据# 对输入数据进行处理和解析# 将解析结果存入内存self.memory.append(parsed_data)def reason(self):# 根据内存中的内容进行推理# 判断是否存在某种模式或规则if pattern_exists:return Trueelse:return Falsedef act(self):# 根据推理结果进行行动# 执行相关操作if self.reason():# 执行相应操作passdef run(self, input_data):self.perceive(input_data)self.act()CognitiveModule 类包含了一个 memory 列表用来存储输入数据的解析结果。它还包含了 perceive 方法用于处理和解析输入数据并将结果存入 memory 中。reason 方法用于根据 memory 中的内容进行推理,判断是否存在某种模式或规则。act 方法根据推理结果执行相关操作。run 方法整合了整个认知过程,执行 perceive 方法处理输入数据,然后根据 reason 结果执行相应操作
import nltk
from nltk.corpus import wordnetclass CognitiveModule:def __init__(self):self.synonyms = {}def add_synonyms(self, word, synonyms):self.synonyms[word] = synonymsdef get_synonyms(self, word):if word in self.synonyms:return self.synonyms[word]else:return []def get_hypernyms(self, word):synsets = wordnet.synsets(word)if len(synsets) > 0:return synsets[0].hypernyms()else:return []if __name__ == '__main__':module = CognitiveModule()# 添加同义词module.add_synonyms('happy', ['glad', 'joyful', 'content'])module.add_synonyms('sad', ['unhappy', 'depressed', 'gloomy'])# 获取同义词print(module.get_synonyms('happy')) # 输出: ['glad', 'joyful', 'content']print(module.get_synonyms('sad')) # 输出: ['unhappy', 'depressed', 'gloomy']print(module.get_synonyms('angry')) # 输出: []# 获取上位词print(module.get_hypernyms('dog')) # 输出: [Synset('canine.n.02')]print(module.get_hypernyms('cat')) # 输出: [Synset('feline.n.01')]print(module.get_hypernyms('lion')) # 输出: [Synset('big_cat.n.01')]
在这个示例中,我们使用了nltk库来获取单词的同义词和上位词。首先,我们创建了一个CognitiveModule类来管理同义词和上位词。使用add_synonyms方法添加一个单词的同义词列表,使用get_synonyms方法获取一个单词的同义词列表,使用get_hypernyms方法获取一个单词的上位词列表。
在__main__部分,我们创建了一个CognitiveModule对象,并添加了一些同义词。然后,我们使用get_synonyms方法获取单词的同义词列表,并使用get_hypernyms方法获取单词的上位词列表。
通信模块
import socketclass CommunicationModule:def __init__(self, host, port):self.host = hostself.port = portself.socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)self.socket.connect((self.host, self.port))def send_message(self, message):self.socket.sendall(message.encode())def receive_message(self):received_data = self.socket.recv(1024)return received_data.decode()def close_connection(self):self.socket.close()# 使用示例
if __name__ == "__main__":client = CommunicationModule("localhost", 1234)client.send_message("Hello, server!")response = client.receive_message()print(response)client.close_connection()
在这个示例中,我们创建了一个CommunicationModule类,用于和服务器进行通信。在初始化方法中,我们创建了一个基于TCP的socket连接,并连接到指定的主机和端口。send_message方法用于发送消息,receive_message方法用于接收消息,close_connection方法用于关闭连接。
在使用示例中,我们创建了一个CommunicationModule实例,并通过send_message方法发送了一条消息给服务器。然后,我们调用receive_message方法接收服务器的响应,并打印出来。最后,我们调用close_connection方法关闭连接。
对话管理模块
对话管理模块是一个用于处理和管理对话的功能模块。它可以接收用户的输入并根据预设的对话流程进行处理,并生成相应的回应。对话管理模块通常包括以下几个部分,对话管理模块是自然语言处理(NLP)和对话系统中的一个关键组件,它的作用是理解和跟踪对话的流程,确保系统能够有效地与用户进行交流:
-
用户输入处理:对话管理模块需要能够接收用户的输入,例如文本、语音等,并对输入进行解析和分析,提取关键信息。
-
对话流程管理:对话管理模块需要定义一个对话流程,即对话的顺序和结构,以及每个阶段的条件和逻辑。这可以通过定义对话树或状态机来实现。
-
对话状态管理:对话管理模块需要维护一个对话状态,以记录当前对话的进展和上下文信息。根据用户输入和对话流程的条件判断,对话状态会发生变化。
-
回应生成:对话管理模块需要根据当前的对话状态和用户输入,生成相应的回应。回应可以是文本、语音等形式。
-
错误处理:对话管理模块需要处理用户输入错误或系统错误的情况,并给出相应的提示或解决方案。
对话管理模块是一个关键的组件,它能够使系统更加智能和自动化地处理用户的输入,提供更加个性化和高效的服务。
# 导入必要的库
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, LSTM
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
import matplotlib.pyplot as plt# 假设我们有一个时间序列数据集,这里我们用numpy生成模拟数据
# 实际应用中,您需要替换为自己的数据集
time_steps = np.linspace(0, 10, 100)
data = np.sin(time_steps) + np.random.normal(size=time_steps.shape) * 0.1# 数据预处理
# 使用MinMaxScaler进行归一化处理
scaler = MinMaxScaler()
data = scaler.fit_transform(data.reshape(-1, 1))# 划分训练集和测试集
train_data = data[:80]
test_data = data[80:]# 创建训练数据的序列
def create_dataset(dataset, look_back=1):X, Y = [], []for i in range(len(dataset)-look_back-1):a = dataset[i:(i+look_back), 0]X.append(a)Y.append(dataset[i + look_back, 0])return np.array(X), np.array(Y)look_back = 10
trainX, trainY = create_dataset(train_data, look_back)
testX, testY = create_dataset(test_data, look_back)# 重塑输入数据的形状以满足LSTM层的要求
trainX = np.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1]))
testX = np.reshape(testX, (testX.shape[0], 1, testX.shape[1]))# 创建LSTM模型
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(1, look_back)))
model.add(Dropout(0.2))
model.add(LSTM(units=50))
model.add(Dropout(0.2))
model.add(Dense(1))# 编译模型
model.compile(loss='mean_squared_error', optimizer=Adam())# 设置早停法,当验证集上的损失不再改善时停止训练
early_stopping = EarlyStopping(monitor='val_loss', patience=5)# 训练模型
history = model.fit(trainX, trainY, epochs=100, batch_size=1, validation_data=(testX, testY), callbacks=[early_stopping])# 绘制训练和测试的损失曲线
plt.figure(figsize=(10, 5))
plt.plot(history.history['loss'], label='训练集上的损失')
plt.plot(history.history['val_loss'], label='测试集上的损失')
plt.title('模型训练和测试损失')
plt.xlabel('Epochs')
plt.ylabel('损失')
plt.legend()
plt.show()# 使用模型进行预测
predicted = model.predict(testX)
predicted = scaler.inverse_transform(predicted)
testY = scaler.inverse_transform([testY])# 绘制预测结果和实际值
plt.figure(figsize=(10, 5))
plt.plot(testY, label='实际值', color='blue')
plt.plot(predicted, label='预测值', color='red')
plt.title('预测值 vs 实际值')
plt.xlabel('时间步')
plt.ylabel('值')
plt.legend()
plt.show()知识图谱模块
知识图谱是一种结构化的知识表示形式,它通过关系网络的形式将实体(如人、地点、物品等)及其之间的关联进行图形化表达。在人工智能领域,知识图谱被广泛应用于增强搜索结果、问答系统、推荐系统以及理解复杂的查询语义等。构建知识图谱通常涉及以下几个步骤:
数据收集:从各种来源收集大量数据,包括百科全书、数据库、专业网站等。
实体识别:从文本中识别出实体,例如人物、地点、组织等。
关系抽取:确定实体之间的关系,例如“出生地”、“工作单位”、“属于”等。
本体构建:定义实体和关系的分类体系,类似于词汇表。
图谱构建:将实体和关系整合进图谱结构中,形成节点和边的关系网络。
查询与推理:实现查询接口,支持复杂的查询和推理功能。
在实际应用中,知识图谱可以通过SPARQL、SQL等查询语言进行查询,也可以通过图数据库如Neo4j或OWL/RDF等标准进行存储和查询
# 导入所需的库
from owlready2 import get_ontology, onto_path, sync_reasoner# 设置本体文件的路径
onto_path.append("./")# 创建一个本体对象
onto = get_ontology("http://www.example.org/my_ontology.owl")# 添加注释
onto.comment = "这是一个示例本体"# 添加实体
with onto:class Person(onto.Thing): passclass Place(onto.Thing): pass# 添加属性
with onto:class hasName(onto.ObjectProperty): passclass locatedIn(onto.ObjectProperty): pass# 添加注释
onto.hasName.comment = "表示人的名字"
onto.locatedIn.comment = "表示人的出生地"# 添加实例
with onto:person = Person()person.hasName = "John Doe"place = Place()place.name = "New York"# 添加关系
with onto:person.locatedIn = place# 同步推理引擎
sync_reasoner()# 查询本体信息
for p in person.locatedIn:print(p.name)情感分析模块
情感分析模块是一种人工智能技术,用于分析文本中的情感倾向。它可以根据文本的语义和词汇等特征,判断文本的情感是积极的、消极的还是中性的。
情感分析模块通常采用机器学习算法或深度学习模型进行训练和预测。训练过程中,模型会通过大量标注好的文本数据来学习情感的表达方式和对应的情感标签。预测过程中,模型会根据输入的文本内容,输出对应的情感标签。
情感分析模块可以应用于多个领域和场景,如社交媒体监测、舆情分析、产品评论分析等。它可以帮助企业了解用户的反馈和情感需求,以便做出相应的改进和调整。在社交媒体和舆情分析中,情感分析模块可以帮助识别用户对特定事件或话题的态度和情感倾向,从而为企业和政府制定相应的策略提供参考。
需要注意的是,情感分析模块虽然可以自动识别文本的情感,但由于情感是主观的,不同人对同一段文本可能有不同的情感理解。因此,在使用情感分析模块的结果时,应结合人工的判断和分析来进行综合考量。
情感分析(Sentiment Analysis),又称为意见挖掘(Opinion Mining),是自然语言处理(NLP)中的一个重要研究领域,它涉及到对人们的观点、态度和情绪倾向的识别和分类。在Python中,我们可以利用多种库来进行情感分析,比如TextBlob、nltk的情感词典,或者是深度学习模型如BERT。首先,您需要安装TextBlob及其依赖项/TextBlob库及其贡献者扩展包,可以使用pip命令进行安装:
以下是一个使用TextBlob进行简单情感分析的示例:
# 导入所需的库
import nltk
from nltk.sentiment.vader import SentimentIntensityAnalyzer# 初始化情感强度分析器
sia = SentimentIntensityAnalyzer()# 定义一个函数来分析文本的情感倾向
def analyze_sentiment(text):# 使用VADER情感分析工具来获取情感分数sentiment = sia.polarity_scores(text)# 情感分数中包含正面、负面、中性和复合分数positive = sentiment['pos']negative = sentiment['neg']neutral = sentiment['neu']compound = sentiment['compound']# 根据复合分数判断情感倾向if compound > 0.05:overall_sentiment = '积极'elif compound < -0.05:overall_sentiment = '消极'else:overall_sentiment = '中性'# 返回情感分数和总体情感倾向return sentiment, overall_sentiment# 测试文本
test_text = "这个产品真的很棒!我非常喜欢它。"# 调用函数并打印结果
sentiment_scores, overall_sentiment = analyze_sentiment(test_text)
print(f"情感分数: {sentiment_scores}")
print(f"总体情感倾向: {overall_sentiment}")尝试使用NLTK库中的VADER组件进行情感分析时遇到了资源未找到的问题。这通常是因为VADER的词典文件没有被正确下载或路径设置不正确。请按照提示信息中的指示,在Python环境中运行以下命令来下载所需的'vader_lexicon'资源:
import nltk
nltk.download('vader_lexicon')完成下载后,再次运行情感分析的代码应该就能正常工作了
图像识别模块
图像识别是指使用计算机视觉技术来识别人物、物体、场景等图像内容。在Python中,我们可以使用许多库来进行图像识别,例如OpenCV、Pillow、TensorFlow和PyTorch等。其中,TensorFlow和PyTorch提供了预训练的模型,可以用来识别图像中的物体。
在高级图像识别任务中,我们通常会使用深度学习模型,特别是预训练的卷积神经网络(CNN)来识别图像中的各种元素。以下是一个使用TensorFlow和Keras API的高级图像识别示例,我们将使用预训练的MobileNetV2模型来识别图像中的物体,来识别人物分析
# 导入所需的库
import cv2# 加载预训练的分类器,这里使用的是MobileNet SSD模型
net = cv2.dnn.readNetFromCaffe('deploy.prototxt', 'weights.caffemodel')# 读取图片
img = cv2.imread('imagepath.jpg')# 获取图片的宽度和高度
(h, w) = img.shape[:2]# 构造一个blob,即输入数据的格式要求
blob = cv2.dnn.blobFromImage(cv2.resize(img, (300, 300)), 0.007843, (300, 300), 127.5)# 将blob输入到网络中进行前向传播
net.setInput(blob)
detections = net.forward()# 遍历检测到的物体
for i in range(detections.shape[2]):# 获取置信度confidence = detections[0, 0, i, 2]# 如果置信度大于某个阈值,则认为检测到物体if confidence > 0.5:# 获取物体的类别IDidx = int(detections[0, 0, i, 1])# 获取物体的边界框坐标box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])(startX, startY, endX, endY) = box.astype("int")# 在图片上绘制边界框和类别标签label = "{}: {:.2f}%".format("Object", confidence * 100)cv2.rectangle(img, (startX, startY), (endX, endY), (0, 255, 0), 2)cv2.putText(img, label, (startX, startY - 15), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)# 显示结果
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()电源模块
我们需要焊接电源与单片机、服务器、互相接通、通信电源,应该选择高效率、稳定的电源电压,带有过载保护和短路保护功能,并且带有电池组与高密度电池,因为要长时间寿命避免人工频繁更换电池,还要降低电压以免发生爆炸!还需要逆变器,如果您的机器人使用的是交流电,那么需要一个适当的逆变器来将直流电转换为交流电图下所示

能源管理系统:应该有一个智能的能源管理系统来监控和分配电源,确保各个模块按需获得适当的能量,如图下所示
必备安全而且大容量电源,以免发生意外情况导致黑客机器人无法正常运行提供服务,除了电源管理,还应该有高效的热管理系统来保持各组件在适宜的工作温度下,还可以需要太阳能来让机器人自己学会智能控电
注:安全第一,小心跳闸
语音语言识别模块
根据小爱同学和小V,语音智能唤醒模块语音智能识别模块我给出以下可用方案
# 导入必要的库
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Activation, Flatten
from tensorflow.keras.layers import Conv2D, MaxPooling2D
from tensorflow.keras.callbacks import TensorBoard
import os
import cv2
import speech_recognition as sr# 设定一些参数
DATADIR = 'path_to_your_dataset' # 数据集路径
CATEGORIES = ['category1', 'category2'] # 分类标签
IMG_SIZE = 50 # 图片大小
training_data = [] # 训练数据列表# 创建训练数据集
def create_training_data():for category in CATEGORIES:path = os.path.join(DATADIR, category) # 获取分类文件夹路径class_num = CATEGORIES.index(category) # 获取分类编号for img in os.listdir(path): # 遍历分类文件夹中的图片try:img_array = cv2.imread(os.path.join(path, img), cv2.IMREAD_GRAYSCALE) # 读取图片new_array = cv2.resize(img_array, (IMG_SIZE, IMG_SIZE)) # 调整图片大小training_data.append([new_array, class_num]) # 添加到训练数据列表except Exception as e:pass# 构建模型
def build_model():model = Sequential()model.add(Conv2D(64, (3, 3), input_shape=(IMG_SIZE, IMG_SIZE, 1))) # 卷积层model.add(Activation('relu')) # 激活函数model.add(MaxPooling2D(pool_size=(2, 2))) # 池化层model.add(Conv2D(64, (3, 3)))model.add(Activation('relu'))model.add(MaxPooling2D(pool_size=(2, 2)))model.add(Flatten()) # 展平层model.add(Dense(64)) # 全连接层model.add(Activation('relu'))model.add(Dropout(0.5)) # 随机丢弃一半的神经元model.add(Dense(1)) # 输出层model.add(Activation('sigmoid')) # 激活函数model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 编译模型return model# 训练模型
def train_model(model):X = [] # 输入数据y = [] # 标签数据for features, label in training_data:X.append(features)y.append(label)X = np.array(X).reshape(-1, IMG_SIZE, IMG_SIZE, 1) / 255.0 # 重塑输入数据的形状并归一化y = np.array(y) # 转换标签数据为numpy数组model.fit(X, y, batch_size=32, epochs=3, validation_split=0.1, callbacks=[TensorBoard(log_dir='/tmp/tensorboard')]) # 训练模型# 主程序
def main():create_training_data() # 创建训练数据model = build_model() # 构建模型train_model(model) # 训练模型# 语音唤醒功能r = sr.Recognizer()with sr.Microphone() as source:print("请说出你的指令:")audio = r.listen(source)try:text = r.recognize_google(audio, language='zh-CN')print("你说的是:{}".format(text))# 在这里添加你的语音指令处理逻辑except sr.UnknownValueError:print("Google Speech Recognition could not understand audio")except sr.RequestError as e:print("Could not request results from Google Speech Recognition service; {0}".format(e))if __name__ == "__main__":main()自然语言处理模块
自然语言处理(Natural Language Processing,简称NLP)是人工智能领域的一个重要研究方向,主要涉及计算机对自然语言的理解和处理。在NLP中,有许多不同的模块用于处理不同的任务。以下是一些常见的NLP模块:
- 分词模块:将输入的文本分割成词语的序列,作为后续处理的基本单位。
- 词性标注模块:为每个词语标注其词性,如名词、动词等。
- 句法分析模块:分析句子的语法结构,包括句子中词语之间的依存关系和短语结构。
- 语义角色标注模块:为句子中的词语标注其在句子中的语义角色,如施事者、受事者等。
- 语义解析模块:将句子中的词语和短语转化为语义表示,以便计算机进行进一步的语义理解和推理。
- 机器翻译模块:将一种自然语言的文本转化成另一种自然语言的文本。
- 文本分类模块:将文本按照一定的标准进行分类,如垃圾邮件分类、情感分类等。
- 命名实体识别模块:识别文本中的具有特定含义的实体,如人名、地名、组织机构名等。
- 情感分析模块:分析文本的情感倾向,如判断一篇文章的情感是积极的还是消极的。
- 对话系统模块:根据输入的自然语言进行对话,与人类用户进行交互。
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizerclass NLPModule:def __init__(self, text):self.text = textdef tokenize(self):tokens = word_tokenize(self.text)return tokensdef remove_stopwords(self, tokens):stop_words = set(stopwords.words('english'))filtered_tokens = [token for token in tokens if token.lower() not in stop_words]return filtered_tokensdef lemmatize(self, tokens):lemmatizer = WordNetLemmatizer()lemmatized_tokens = [lemmatizer.lemmatize(token) for token in tokens]return lemmatized_tokensdef process_text(self):tokens = self.tokenize()tokens = self.remove_stopwords(tokens)tokens = self.lemmatize(tokens)return tokenstext ="你好,小智"#此注释仅是文本,输出也是单纯文本,如添加语言自主模块请自主更新库或添加代码
nlp_module = NLPModule(text)
processed_text = nlp_module.process_text()print(processed_text)注:添加模块需要大量数据集群,或者运算速度,您可考虑数据库的安全性在设计时使用AI+人工的方法做到最好
自主学习模块
自主学习模块通常指的是能够让机器学习模型在没有人类干预的情况下,通过与环境的互动来提升其性能的系统。这种模块的核心在于强化学习,它是一种让智能体(agent)通过与环境的交互来学习最优策略的算法。以下是自主学习模块的一些关键组成部分:
智能体(Agent):这是学习者,它会在环境中执行动作。
环境(Environment):智能体所处的世界,它会响应智能体的动作并给出奖励或惩罚。
状态(State):环境的观测空间,智能体根据当前状态来决定下一步动作。
动作(Action):智能体可以选择执行的操作。
奖励(Reward):环境对智能体动作的反馈,用于驱动学习过程。
策略(Policy):智能体选择动作的规则,可以是随机的,也可以是基于某种学习模型的。
价值函数(Value Function):评估状态或状态动作对的价值,以指导智能体的选择。
模型更新:根据经验和奖励来更新智能体的学习模型。
在Python中,你可以使用诸如gym和stable-baselines3这样的库来创建自主学习模块。gym提供了标准化的环境来开发和比较强化学习算法,而stable-baselines3则是一套强化学习算法的实现,可以用来训练智能体。
以下是一个简单的自主学习模块的代码示例,使用gym和stable-baselines3来训练一个智能体玩乒乓球游戏:
# 导入所需的库
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, LSTM
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping
from sklearn.preprocessing import MinMaxScaler
import pandas as pd
import matplotlib.pyplot as plt# 假设我们有一个时间序列数据集,这里我们用numpy生成模拟数据
# 实际应用中,您需要替换为自己的数据集
time_steps = np.linspace(0, 10, 100)
data = np.sin(time_steps) + np.random.normal(size=time_steps.shape) * 0.1# 数据预处理
# 使用MinMaxScaler进行归一化处理
scaler = MinMaxScaler()
data = scaler.fit_transform(data.reshape(-1, 1))# 划分训练集和测试集
train_data = data[:80]
test_data = data[80:]# 创建训练数据的序列
def create_dataset(dataset, look_back=1):X, Y = [], []for i in range(len(dataset)-look_back-1):a = dataset[i:(i+look_back), 0]X.append(a)Y.append(dataset[i + look_back, 0])return np.array(X), np.array(Y)look_back = 10
trainX, trainY = create_dataset(train_data, look_back)
testX, testY = create_dataset(test_data, look_back)# 重塑输入数据的形状以满足LSTM层的要求
trainX = np.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1]))
testX = np.reshape(testX, (testX.shape[0], 1, testX.shape[1]))# 创建LSTM模型
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(1, look_back)))
model.add(Dropout(0.2))
model.add(LSTM(units=50))
model.add(Dropout(0.2))
model.add(Dense(1))# 编译模型
model.compile(loss='mean_squared_error', optimizer=Adam())# 设置早停法,当验证集上的损失不再改善时停止训练
early_stopping = EarlyStopping(monitor='val_loss', patience=5)# 训练模型
history = model.fit(trainX, trainY, epochs=100, batch_size=1, validation_data=(testX, testY), callbacks=[early_stopping])# 绘制训练和测试的损失曲线
plt.figure(figsize=(10, 5))
plt.plot(history.history['loss'], label='训练集上的损失')
plt.plot(history.history['val_loss'], label='测试集上的损失')
plt.title('模型训练和测试损失')
plt.xlabel('Epochs')
plt.ylabel('损失')
plt.legend()
plt.show()# 使用模型进行预测
predicted = model.predict(testX)
predicted = scaler.inverse_transform(predicted)
testY = scaler.inverse_transform([testY])# 绘制预测结果和实际值
plt.figure(figsize=(10, 5))
plt.plot(testY, label='实际值', color='blue')
plt.plot(predicted, label='预测值', color='red')
plt.title('预测值 vs 实际值')
plt.xlabel('时间步')
plt.ylabel('值')
plt.legend()
plt.show()数据库模块
import mysql.connector# 连接到MySQL数据库
cnx = mysql.connector.connect(user='username', password='password', host='localhost', database='database_name')# 创建游标对象
cursor = cnx.cursor()# 执行SQL查询
query = "SELECT * FROM table_name"
cursor.execute(query)# 获取查询结果
result = cursor.fetchall()# 输出查询结果
for row in result:print(row)# 关闭游标对象和数据库连接
cursor.close()
cnx.close()user :用户名********
password:数据库密码********
host:IP端口地址******
用户界面模块
用户界面模块是软件系统中负责与用户进行交互和展示的部分,它提供给用户一个友好的界面,使用户可以方便地操作系统或AI/应用程序。
用户界面模块通常包括以下几个方面的功能:
-
输入和输出:用户界面模块负责接收用户的输入,并将结果显示给用户。输入可以是通过键盘、鼠标或触摸屏等输入设备进行的,输出可以是通过显示器、打印机或其他输出设备进行的。
-
图形界面:用户界面模块可以使用图形库或界面设计工具创建具有丰富图形元素的界面,如按钮、文本框、菜单等,使用户可以通过点击、拖拽等方式与系统进行交互。
-
用户认证和权限控制:用户界面模块可以包含用户认证和权限控制功能,以确保只有经过身份验证并获得相应权限的用户才能使用系统。
-
导航和菜单:用户界面模块可以提供导航和菜单功能,以帮助用户浏览系统或应用程序的不同功能和页面,并提供操作指引。
-
-
帮助和文档:用户界面模块可以提供帮助和文档功能,以向用户提供使用系统或应用程序的指南、说明书等文档资源。
-
状态栏:显示系统的状态信息,如当前时间、系统运行状态等。
-
对话框:当系统需要用户提供额外信息或者需要用户进行确认时,会弹出对话框,用户可以在对话框中输入信息或进行选择
-
提示信息:在用户操作时,系统可以通过弹出提示信息提醒用户正确操作或者错误信息
提示:在写本用户界面模块时可自定义
智能决策模块
智能决策模块是一种使用人工智能技术和算法进行分析、推理和预测的模块。它可以根据输入的数据和规则,快速分析情况,做出最优的决策。智能决策模块通常可以应用于各种领域,包括金融、医疗、物流等,帮助用户做出决策,提高工作效率和决策的准确性。
智能决策模块通常包括以下主要功能:
-
数据分析:将输入的数据进行分析和处理,提取有用的信息和特征。
-
决策推理:利用算法和规则对数据进行推理和预测,得出最优的决策结果。
-
优化策略:根据需求和目标对决策结果进行优化,找到最佳的解决方案。
-
可视化展示:将分析结果和决策方案以可视化的方式展示给用户,帮助用户理解和接受决策结果。
# 智能决策模块class DecisionMaker:def __init__(self):self.decisions = {} # 初始化决策字典def add_decision(self, decision_id, decision_criteria, alternatives):# 添加决策self.decisions[decision_id] = {'criteria': decision_criteria, 'alternatives': alternatives}def make_decision(self, decision_id):# 根据决策ID获取决策信息decision = self.decisions.get(decision_id)if decision:# 获取决策标准和备选方案criteria = decision['criteria']alternatives = decision['alternatives']# 根据决策标准选择最佳方案best_alternative = max(alternatives, key=lambda x: criteria[x])return best_alternativeelse:# 如果没有找到决策,则返回Nonereturn Nonedef remove_decision(self, decision_id):# 删除指定ID的决策if decision_id in self.decisions:del self.decisions[decision_id]def display_decisions(self):# 显示所有决策for decision_id, decision in self.decisions.items():print(f"决策ID: {decision_id}")print(f"决策标准: {decision['criteria']}")print(f"备选方案: {decision['alternatives']}")print("-" * 50)# 测试代码
if __name__ == "__main__":dm = DecisionMaker()dm.add_decision("D1", {"A": 0.5, "B": 0.3, "C": 0.2}, {"A": 0.6, "B": 0.4, "C": 0.5})dm.add_decision("D2", {"X": 0.8, "Y": 0.2}, {"X": 0.7, "Y": 0.3})dm.display_decisions()print("决策D1的最佳方案:", dm.make_decision("D1"))print("决策D2的最佳方案:", dm.make_decision("D2"))dm.remove_decision("D1")print("删除决策D1后,所有决策:")dm.display_decisions()储存数据模块
储存数据模块是指负责将数据保存到持久化存储介质中(如数据库、文件)或从持久化存储介质中读取数据的模块。
这个模块通常包含以下功能:
-
连接数据库:与数据库建立连接,以便进行数据的读写操作。常见的数据库包括MySQL、Oracle、MongoDB等。
-
CRUD操作:CRUD是指对数据的增加(Create)、读取(Retrieve)、更新(Update)以及删除(Delete)操作。储存数据模块可以提供相应的接口,方便其他模块进行这些操作。
-
数据校验和格式转换:储存数据模块可以对输入的数据进行校验,检查数据是否符合规定的格式要求。同时,它也可以将存储的数据转换为其他模块需要的格式,确保数据的一致性和准确性。
-
数据库事务管理:在一些需要保证数据一致性和完整性的场景下,储存数据模块可以支持数据库事务管理。通过事务,可以将多个操作作为一个逻辑单元执行,保证操作的原子性、一致性、隔离性和持久性。
-
数据查询和索引:储存数据模块可以提供强大的查询功能,支持根据特定条件进行数据检索。为了提高查询效率,它还可以创建索引,加快查询速度。
-
可添加前端+后端代码实现快速检索功能,实现自动化检索,实现快速找到此数据,这才是代码的主要功能
class DataStorage:def __init__(self):self.data = {} # 初始化空的数据字典def store_data(self, data_id, data_value):# 存储数据self.data[data_id] = data_valuedef retrieve_data(self, data_id):# 检索数据return self.data.get(data_id)def delete_data(self, data_id):# 删除数据if data_id in self.data:del self.data[data_id]def display_data(self):# 显示所有数据for data_id, data_value in self.data.items():print(f"数据ID: {data_id}, 数据值: {data_value}")# 测试代码
if __name__ == "__main__":ds = DataStorage()ds.store_data("D1", {"数据1": [100, 120, 110, 130], "数据11": [120, 130, 125, 135]})ds.store_data("D2", {"数据2": [110, 115, 120, 125], "数据22": [130, 135, 140, 145]})ds.display_data()retrieved_data = ds.retrieve_data("D1")print("检索到的数据D1:", retrieved_data)ds.delete_data("D1")print("删除数据D1后,所有数据:")ds.display_data()数据ID: D1, 数据值: {'心电图': [100, 120, 110, 130], '血压': [120, 130, 125, 135]}
数据ID: D2, 数据值: {'心电图': [110, 115, 120, 125], '血压': [130, 135, 140, 145]}
检索到的数据D1: {'心电图': [100, 120, 110, 130], '血压': [120, 130, 125, 135]}
删除数据D1后,所有数据:
数据ID: D2, 数据值: {'心电图': [110, 115, 120, 125], '血压': [130, 135, 140, 145]}需要注意的是,储存数据模块应该与其他模块进行解耦,尽量将业务逻辑与数据存储的细节分离。这样可以提高系统的可扩展性和可维护性,同时也方便进行单元测试和模块替换。
超速云算法智能芯片模块
超速云算法智能芯片模块是一种集成了超速云算法的智能芯片模块。超速云算法是一种高效的算法,它可以在很短的时间内完成复杂的计算任务。智能芯片模块则是一种集成了各种功能的芯片,它可以实现多种不同的应用。
超速云算法智能芯片模块利用了超速云算法的高效计算能力,可以快速地处理大量的数据。它可以应用于各种领域,如人工智能、机器学习、图像处理等。通过使用超速云算法智能芯片模块,用户可以在短时间内完成复杂的计算任务,提高工作效率。
超速云算法智能芯片模块还具有低功耗的特点,可以在各种环境下进行高效运算。它还支持多种接口和协议,可以与其他设备和系统进行快速的数据交换和通信
人工智能芯片的一般讨论、特定公司的产品介绍以及其他与智能芯片相关的技术进展。如果“超速云算法智能芯片模块”是一个特定产品或技术,建议直接联系生产厂家或官方渠道以获取最准确和最新的信息
定位模块服务
定位模块服务定义
定位模块服务通常指的是由硬件设备提供的地理位置定位功能,这些设备内置了定位算法和相应的软件服务,能够接收来自全球导航卫星系统(GNSS)的信号,计算出具体的经纬度坐标信息。定位模块服务广泛应用于车辆导航、个人定位、物流跟踪、智能交通系统、地理信息系统(GIS)等领域。定位模块服务是指提供定位功能的服务。定位模块通常是一种硬件设备,例如GPS模块或者基站定位模块,它能够获取设备所在的位置信息。定位模块服务的作用是将定位模块获取的位置信息传递给应用程序或者其他服务,使得应用程序可以根据设备的位置信息进行相应的操作。例如,一个地图导航应用程序可以利用定位模块服务获取用户的位置信息,并根据用户的位置给予导航指示。定位模块服务还可以被其他服务或者应用程序调用,以实现一些需要位置信息的功能,例如天气预报、附近的人、附近的商店等等
定位模块服务的特点包括
高精度定位:一些定位模块支持实时动态定位(RTK)技术,能够提供厘米级的定位精度,适用于专业测绘、精细农业、自动驾驶等对定位精度要求较高的场合。
多系统兼容:现代定位模块能够同时接收多个卫星导航系统的信号,如GPS、北斗、GLONASS、GALILEO等,从而提高定位的稳定性和准确性。
Ai自动化快速定位:定位模块设计用于快速捕获卫星信号并计算位置,有的模块能够在几秒钟内完成冷启动并定位。
多功能性:除了基本的定位功能外,定位模块还可能集成其他功能,如授时、短报文通信等。
环境适应性:定位模块通常具有一定的耐候性和耐用性,能够在不同的环境条件下正常工作。
用户组和管理员模块
用户组
用户组是一组具有相同权限和访问级别的用户的集合。在多用户操作系统中,如Linux或Windows网络环境中,用户组用于简化权限管理。例如,在Linux系统中,可以创建不同的用户组,如'users'、'admin'、'staff'等,每个组可以被授予特定的权限。当用户被分配到某个组时,他们自动继承该组的权限。这样做可以避免为每个用户单独设置权限,提高了管理的效率。
管理员模块
管理员模块通常是指系统中负责执行管理任务的部分,它可以是一个软件组件、一组功能或者一个角色。管理员拥有最高级别的访问权限,能够管理系统中的各个方面,包括但不限于:
添加、删除和修改用户账户
分配用户到不同的用户组
设置和修改用户权限
监控系统活动和安全日志
安装和更新软件
配置系统设置
在设计一个系统时,为了安全和效率,应该将管理员权限限制在尽可能少的用户手中,并且遵循最小权限原则,即每个用户和组只拥有完成其工作任务所必需的权限。这样可以减少潜在的安全风险,比如误操作或恶意行为对系统的影响
降温模块
散热器:通常由金属制成,具有大面积的鳍片,用于增加散热面积,帮助热量从热源传递到空气中。
风扇:通过强制空气对流,将热量从散热器带走,加速散热过程。
热管:利用液态到气态的相变传递热量,即使在长距离和复杂路径上也能有效地传递热量。
水冷系统:通过循环冷却液,将热量从热源带走,通常能提供比传统空气冷却更高的散热效率。
四、开始上传机器人
那么如何开发完成上传到全世界甚至一个国家?一个区域?或一个地方服务器?
这是不是一个笑话或者不可能实现的梦?或许真的实现未来了吗?这当然是可以实现并正常运行的可行性和可靠性机器人
在导入NLTK库可能会遇到如下问题:或参考官方文档
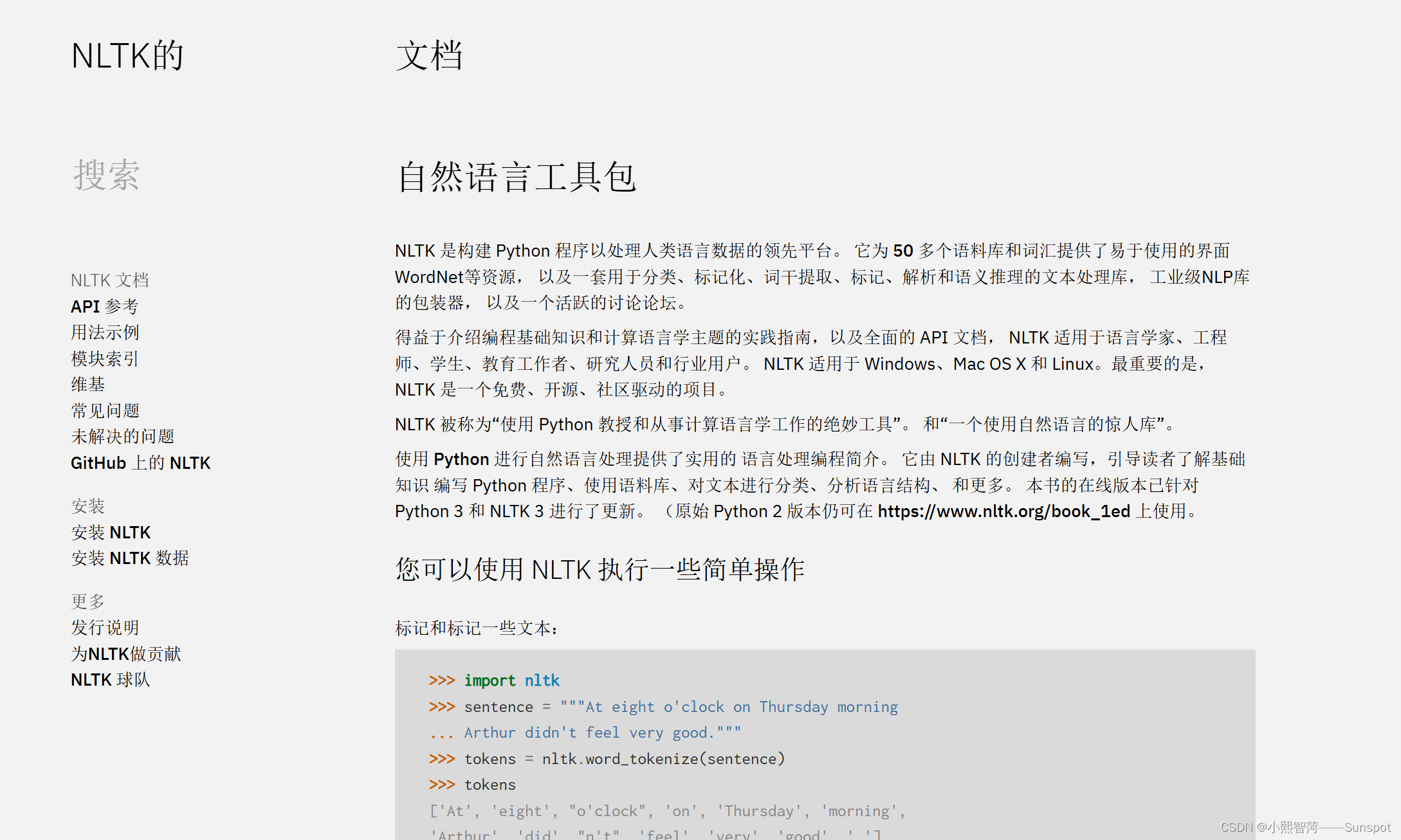
Resource punkt not found.Please use the NLTK Downloader to obtain the resource:>>> import nltk>>> nltk.download('punkt')For more information see: https://www.nltk.org/data.htmlAttempted to load tokenizers/punkt/PY3/english.pickleSearched in:- '/root/nltk_data'- '/usr/nltk_data'- '/usr/share/nltk_data'- '/usr/lib/nltk_data'- '/usr/share/nltk_data'- '/usr/local/share/nltk_data'- '/usr/lib/nltk_data'- '/usr/local/lib/nltk_data'- ''
**********************************************************************五:购买服务器集群
购买服务器集群是一个复杂的过程,需要考虑以下几个方面:
-
需求评估:首先需要评估您的服务器需求,包括处理能力、存储空间和网络带宽等。根据需求确定服务器集群的规模和配置。
-
预算确定:确定购买服务器集群的预算,包括硬件设备、软件许可、维护和管理等方面。
-
选择供应商:根据预算和需求选择合适的供应商。可以考虑与多家供应商进行比较,选择信誉良好且价格合理的供应商。
-
硬件设备选型:根据需求选购合适的服务器硬件设备,包括主机、存储设备和网络设备等。考虑硬件性能、扩展性和可靠性等因素。
-
软件许可:根据需求选购适用的操作系统和应用软件许可。
-
配置集群:根据需求和硬件设备选型,进行服务器集群的配置和部署。包括服务器网络连接、负载均衡、容错备份等方面。
-
系统管理:购买服务器集群后,需要进行系统管理和维护。包括系统监控、安全管理、备份和恢复等。
-
后期支持:确保供应商能够提供及时的技术支持和维护服务,以解决任何问题和升级需求。
六:开始行动:
1.1在导入ntlk库时,或其他库/基础代码时会出现如下问题

遇到此类问题咱们在终端更新下载pip安装就完了!
 完美
完美
1.2:首先测试代码黑客AI机器人感知模块写入
- 模拟各种:网络攻击,如钓鱼攻击等,包括Kali工具自动应用
- 实时警报:监控网络活动,及时提醒用户潜在的安全威胁。
- 行为分析:分析用户行为,以识别可能表明安全事件的异常模式
使用网络监控数据监控活动使用python中的scapy库绑定端口号码/服务器端口来实现此功能,未安装请使用终端安装此库
pip install scapy按照以上我写入以下代码
1.2.1:支持在此小智AI监控网络活动1测中无法导入源,我安装了没问题好像是是哪里出了问题么,正常运行,我这里默认监控网络活动默认本地路由器识别!看到以下代码是暂时接下来要使用到的库
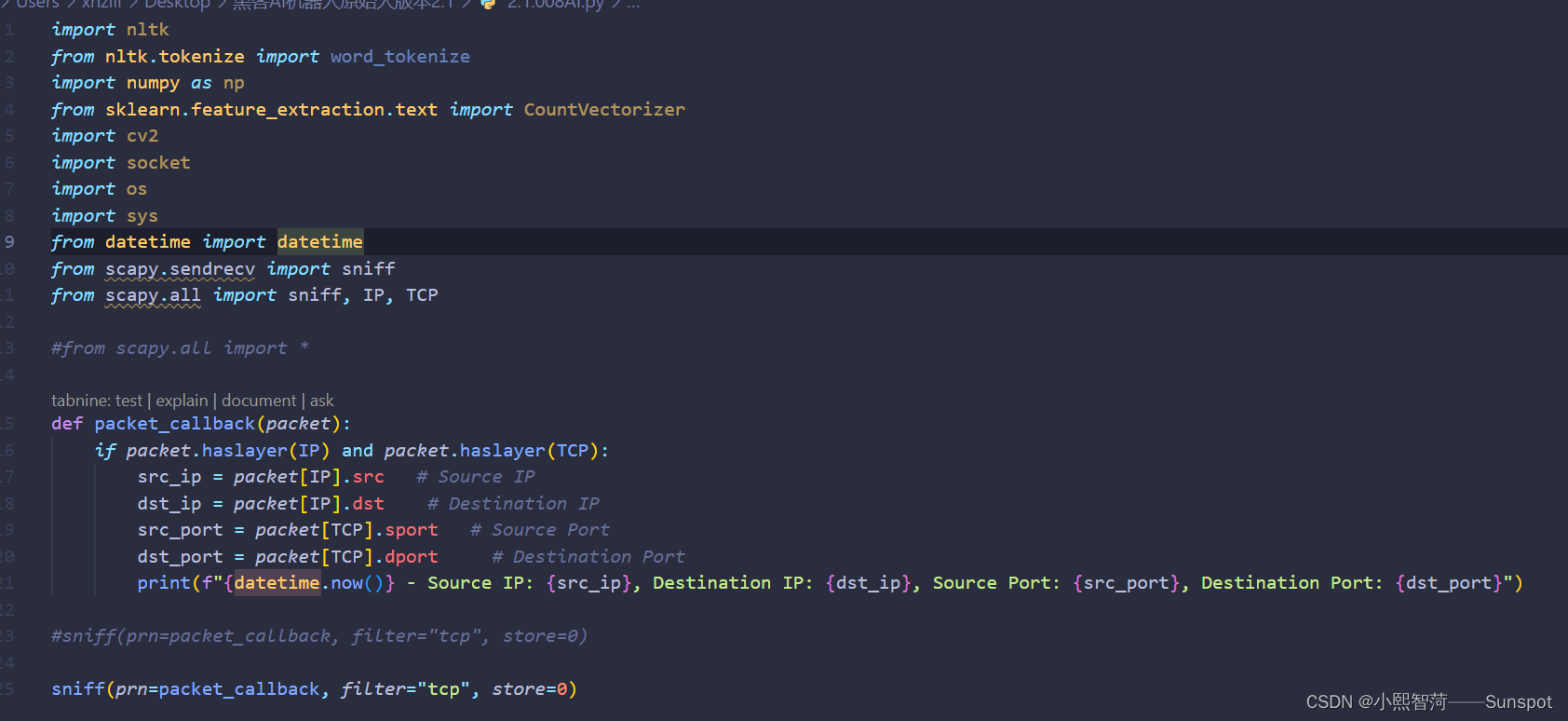
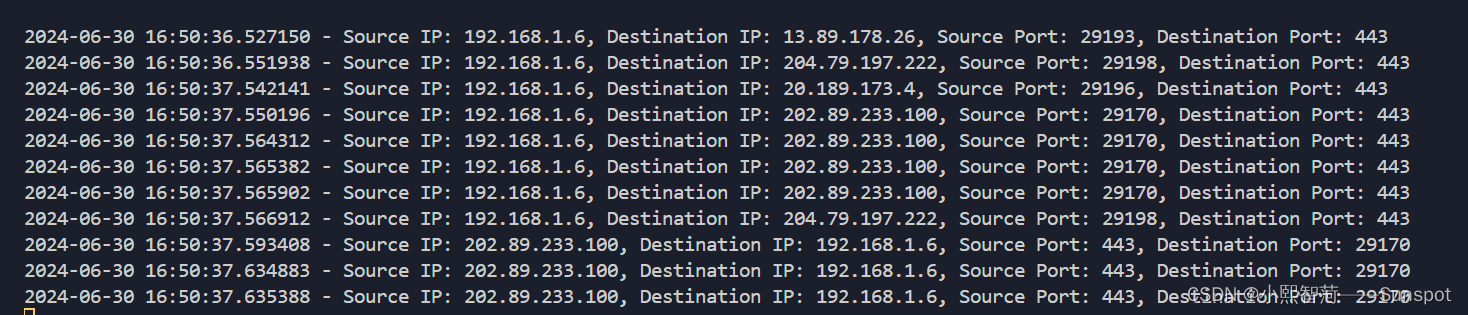
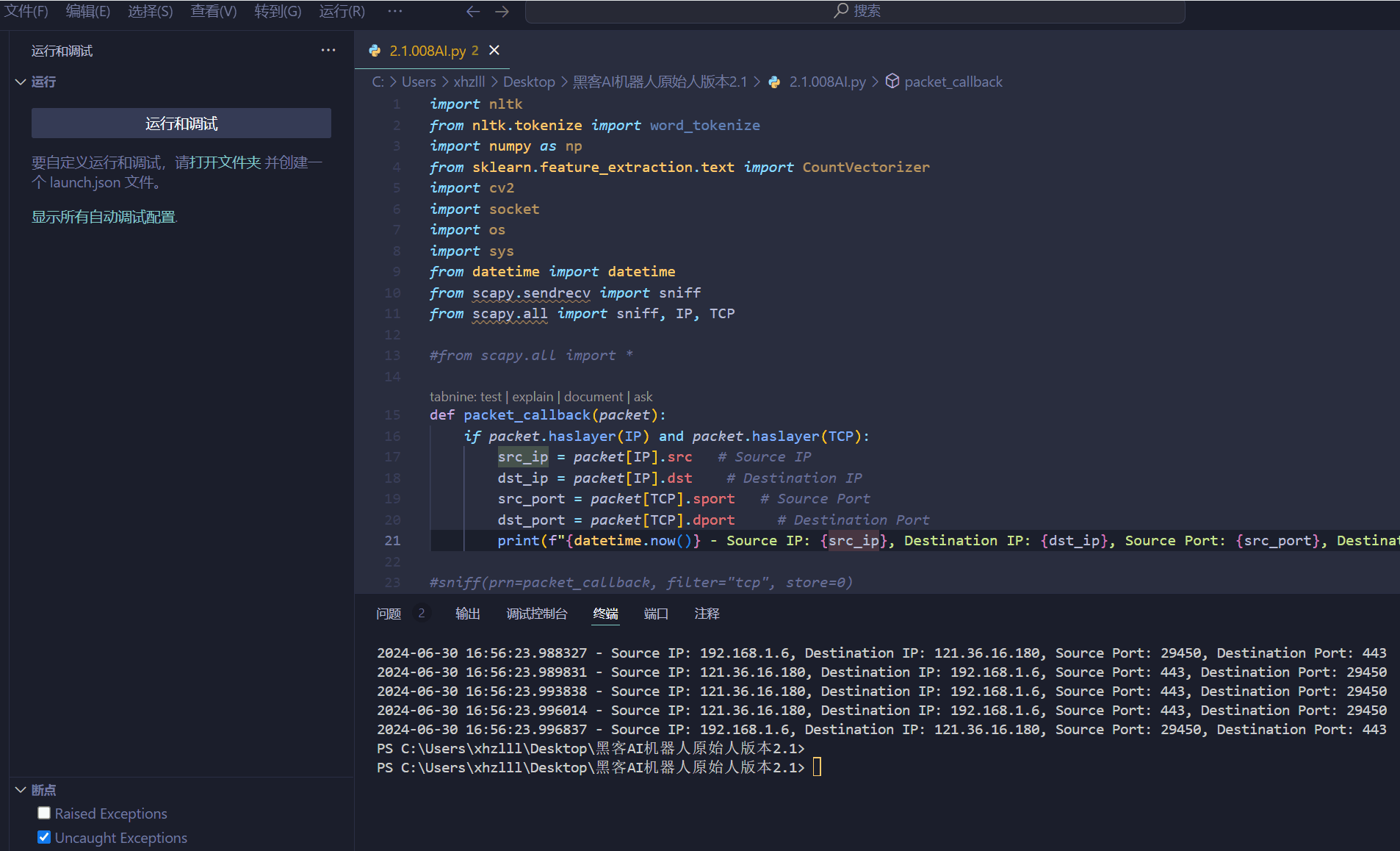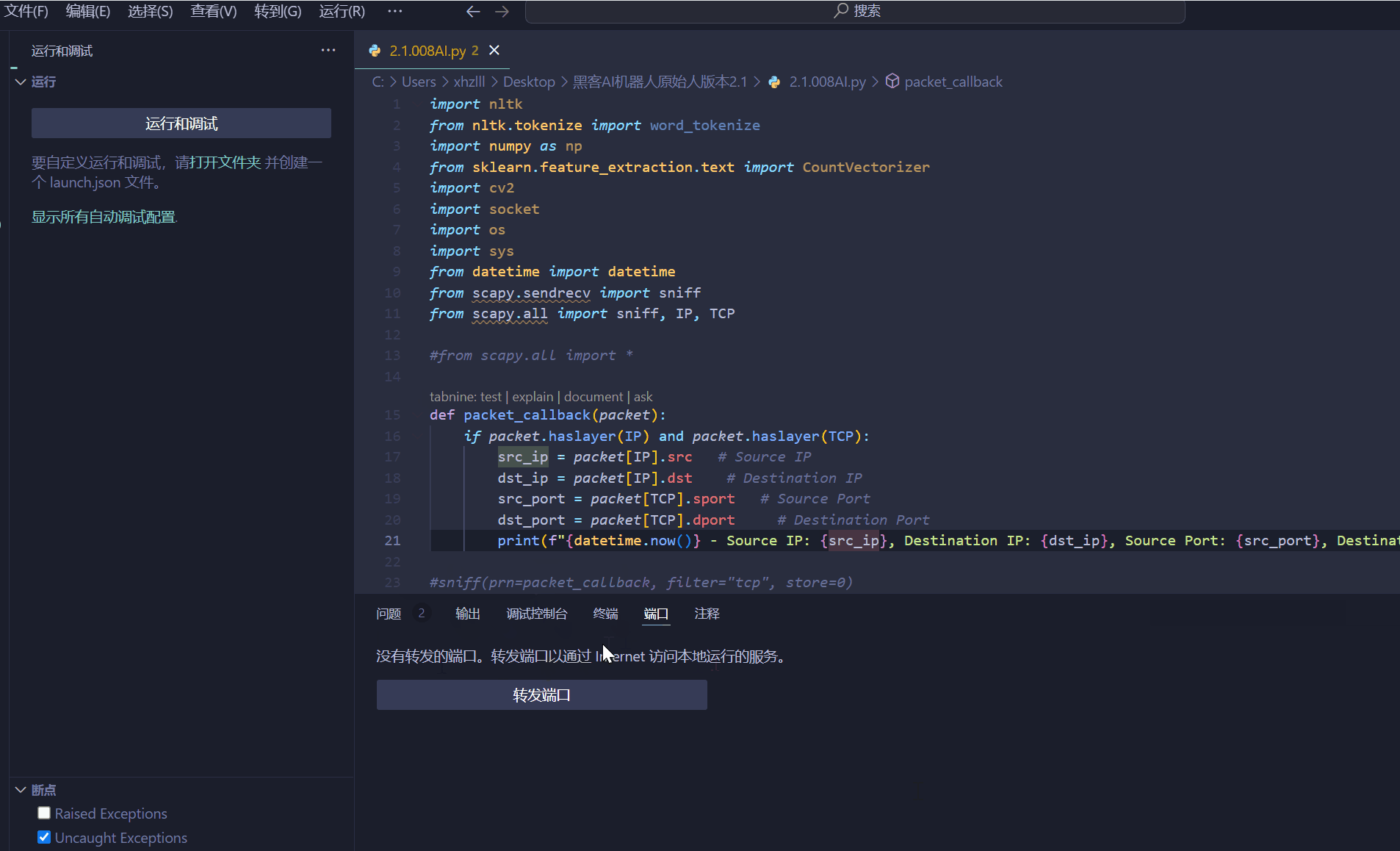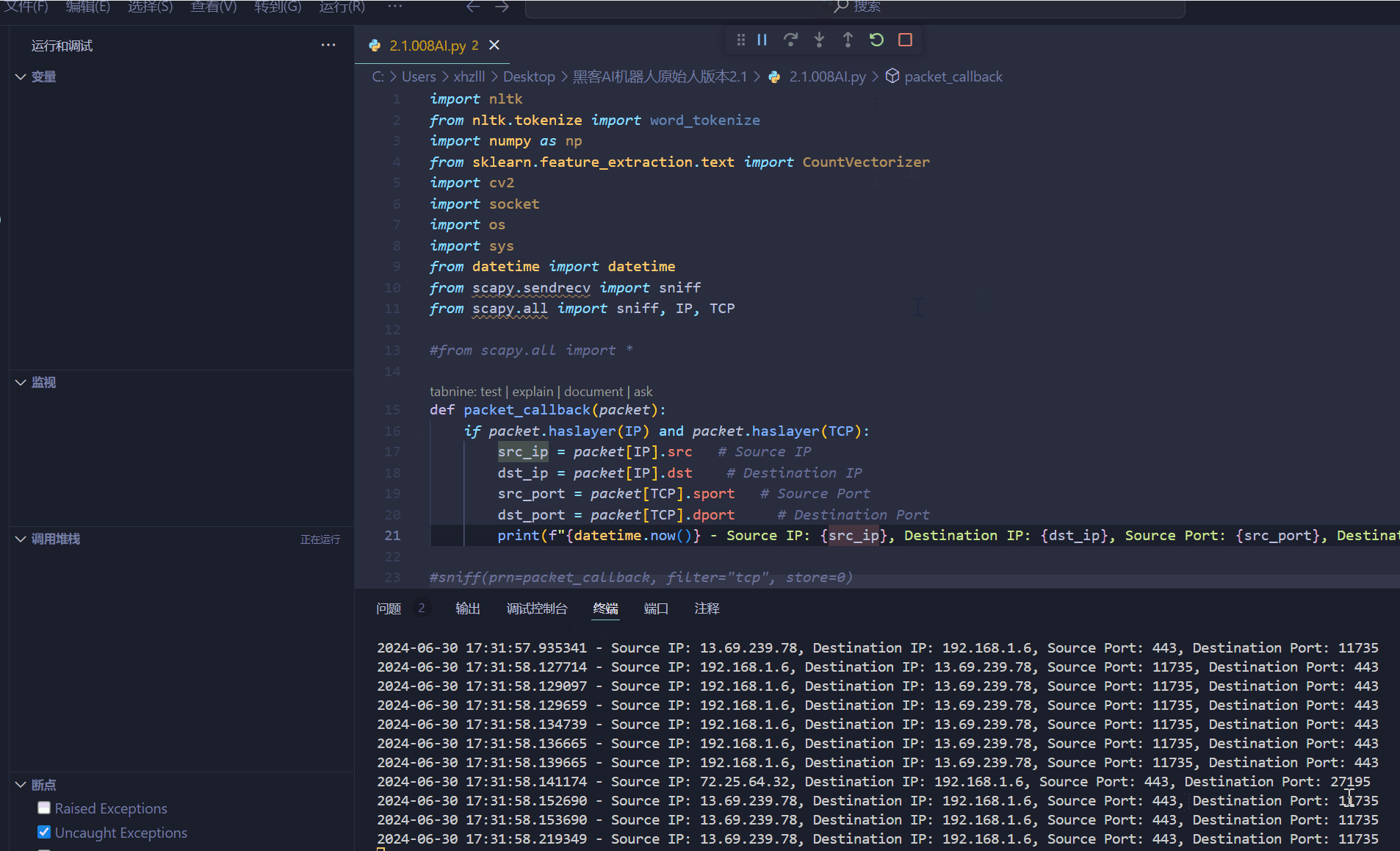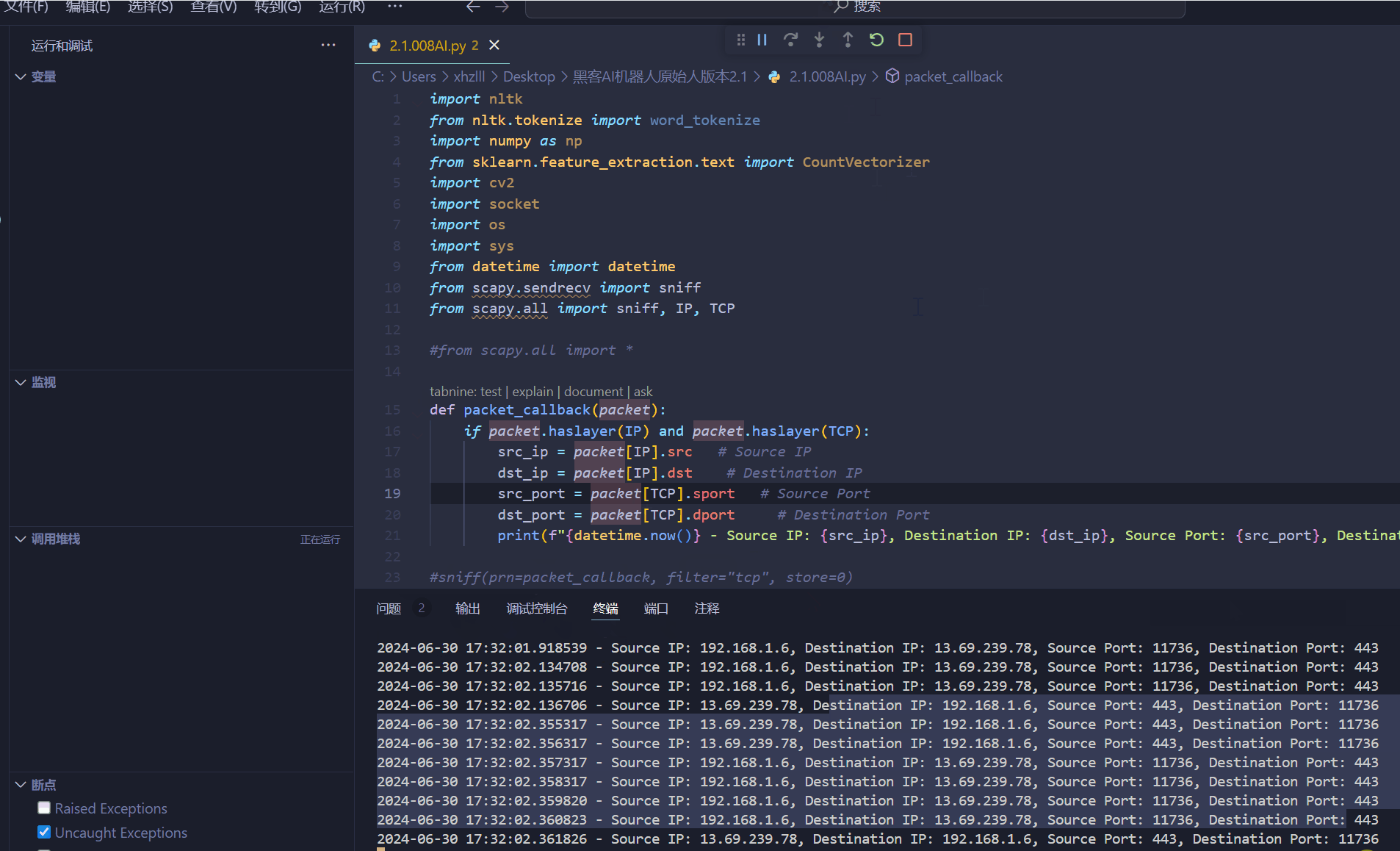
1.2.3:支持网络实时分析人类行为,该系统从传感器或日志文件中收集数据,并使用机器学习模型来预测用户的行为,此类需要实体硬件:传感器、红外线
1.2.4:Tensorflow-gpu,发现要训练时要安装此库,听大佬说:显卡支持才能运行,安装前 一定 要查看自己电脑的环境配置,然后查询Tensorflow-gpu、Python、 cuda 、 cuDNN 版本关系,要 一 一对应呢具体请自行搜索哦!不然就会像我一样呢
