阶段三:项目开发---大数据系统基础环境准备:任务1:准备系统运行的先决条件
任务描述
知识点:
大数据基础环境准备
重 点:
SSH免密码连接
安装配置JDK
安装配置Scala
难 点:
无
内 容:
项目开发测试环境为分布式集群环境,在当前项目中使用多台基于CentOS 64bit 的虚拟机来模拟生产环境。在生产环境中建议使用高性能物理主机或云主机搭建集群环境。
- 规划服务节点的功能和数量,以及网络分配情况
- 配置虚拟机的主机名称和网络,确保各主机之间可以通过主机名和IP互相ping通
- 配置各虚拟机之间可以SSH免密码连接
- 在各虚拟机上安装JDK并配置环境变量
任务指导
1、规划服务节点的功能和数量,以及网络分配情况
- 当前项目所使用的服务器集群包括1个client节点和3个大数据集群的节点,节点IP地址和主机名分布如下:
| 序号 | IP地址 | 机器名 | 运行的守护进程 |
|---|---|---|---|
| 1 | xxx.xxx.xxx.xxx | client1 | 客户机(开发服务器) |
| 2 | xxx.xxx.xxx.xxx | client2 | 客户机(开发服务器) |
| 3 | xxx.xxx.xxx.xxx | client3 | 客户机(开发服务器) |
| 4 | xxx.xxx.xxx.xxx | node1 | Hadoop、Kafka、ZooKeeper、HBase、Spark、Redis |
| 5 | xxx.xxx.xxx.xxx | node2 | Hadoop、Kafka、ZooKeeper、HBase、Spark |
| 6 | xxx.xxx.xxx.xxx | node3 | Hadoop、Kafka、ZooKeeper、HBase、Spark、Web服务 |
- 所有节点均是CentOS 64bit系统,且已经关闭防火墙,禁用selinux
- 所有机器的登录用户名:root,密码:可从以下方式获取(例如,将鼠标移动到 node1 节点上时,会弹出提示框,显示主机名、虚拟机IP、用户名、密码等)

2、配置虚拟机的主机名称和网络,确保各主机之间可以通过主机名和IP互相ping通
- 修改hosts文件,添加主机名和IP地址的映射,IP地址根据自已的实验环境进行设置,可以使用ifconfig命令查看主机的IP地址,如下图所示,查看当前环境的IP地址:
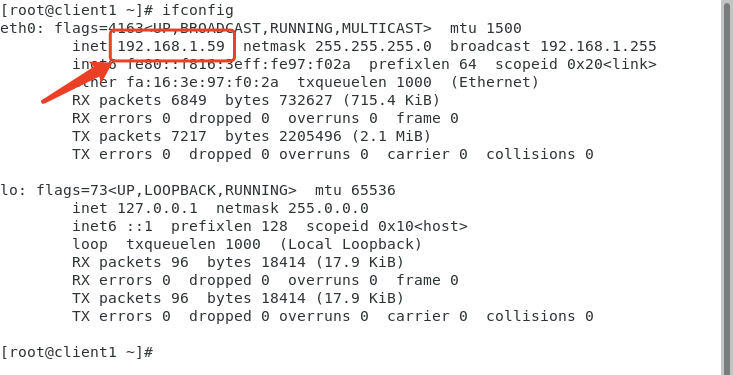
- 输入【vim /etc/hosts】命令,修改/etc/hosts文件添加如下内容(注意:IP地址根据自己的实验环境进行设置):
xxx.xxx.xxx.xxx node1
xxx.xxx.xxx.xxx node2
xxx.xxx.xxx.xxx node3
xxx.xxx.xxx.xxx client1
xxx.xxx.xxx.xxx client2
xxx.xxx.xxx.xxx client3- 在每一个节点上使用ping命令,分别去ping其它节点的主机名,测试是否可以ping通,例如:
[root@client ~] # ping node2 3、配置各虚拟机之间可以SSH免密码连接
Hadoop分布式集群是由多个节点组成,各节点之间需要通过网络访问,如果每次都需要输入密码,非常不方便,所以可以考虑设置各节点之间免密码连接。任务的内容为在各个节点配置SSH,生成密钥对,然后再将公钥分发到所有节点,这样就可以实现各节点之间的免密码连通了。
4、在各虚拟机上安装JDK并配置环境变量
Hadoop 2.6 之后的最低需要JDK 1.6,Hadoop 3.x之后的版本需要JDK 1.8(这里建议使用JDK 1.8),如果CentOS是最小化安装,可能没有Open JDK,即使已经安装过Open JDK也可以使用JDK 1.8替换系统自带的Open JDK。任务的内容为检查各个节点的JDK的安装情况,卸载Open JDK,同时安装Oracle JDK并配置环境变量。
任务实现
1、规划服务节点的功能和数量,以及网络分配情况
- 当前项目所使用的服务器集群包括1个client节点和3个大数据集群的节点,节点IP地址和主机名分布如下:
| 序号 | IP地址 | 机器名 | 运行的守护进程 |
|---|---|---|---|
| 1 | xxx.xxx.xxx.xxx | client1 | 客户机(开发服务器) |
| 2 | xxx.xxx.xxx.xxx | client2 | 客户机(开发服务器) |
| 3 | xxx.xxx.xxx.xxx | client3 | 客户机(开发服务器) |
| 4 | xxx.xxx.xxx.xxx | node1 | Hadoop、Kafka、ZooKeeper、HBase、Spark、Redis |
| 5 | xxx.xxx.xxx.xxx | node2 | Hadoop、Kafka、ZooKeeper、HBase、Spark |
| 6 | xxx.xxx.xxx.xxx | node3 | Hadoop、Kafka、ZooKeeper、HBase、Spark、Web服务 |
- 所有节点均是CentOS 64bit系统,且已经关闭防火墙,禁用selinux
- 所有机器的登录用户名:root,密码:可从以下方式获取(例如,将鼠标移动到 node1 节点上时,会弹出提示框,显示主机名、虚拟机IP、用户名、密码等)
2、配置虚拟机的主机名称和网络,确保各主机之间可以通过主机名和IP互相ping通
- 在所有节点上,修改hosts文件,添加主机名和IP地址的映射,IP地址根据自已的实验环境进行设置,可以使用ifconfig命令查看主机的IP地址,如下图所示,查看当前环境的IP地址:
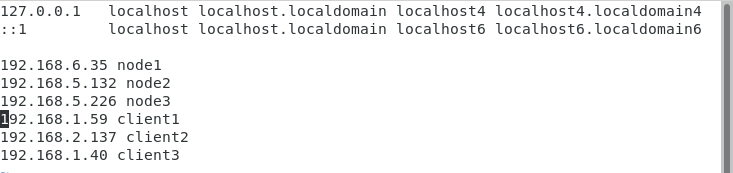
- 输入【vim /etc/hosts】命令,修改/etc/hosts文件添加如下内容(注意:IP地址根据自己的实验环境进行设置):
192.168.6.35 node1
192.168.5.132 node2
192.168.5.226 node3
192.168.1.59 client1
192.168.2.137 client2
192.168.1.40 client3例如(注意:IP地址根据自己的实验环境进行设置):
- 注意所有节点都要按上面的内容配置hosts文件。
- 在每一个节点上使用ping命令,分别去ping其它节点的主机名,测试是否可以ping通,例如:
# ping node2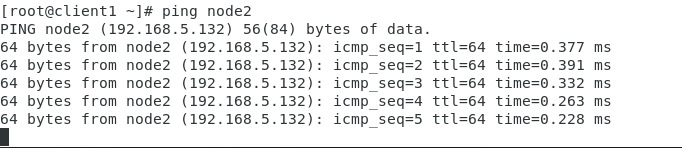
3、配置SSH免密码连接
- 注意
1)当前环境已经配置好SSH免密码连接,如果出现无法实现SSH免密码连接的情况,可以先刷新网页,以尝试重新初始化环境;如果还是无效,可按下面的步骤自行手动配置SSH免密码连接。
2)当前环境已经配置好SSH免密码连接,以下步骤仅供:1.没有配置过SSH免密码连接的;2.需要重新配置免密码连接的;3.在其他新的环境中配置免密码连接的;等情况参考使用。
SSH免密码登录,因为Hadoop需要通过SSH登录到各个节点进行操作,我用的是root用户,每台服务器都生成公钥,再合并到authorized_keys。
- 输入命令【ssh-keygen -t rsa】生成key,一直回车,都不输入密码,/root就会生成.ssh文件夹,注意,每台服务器都要设置,例如:
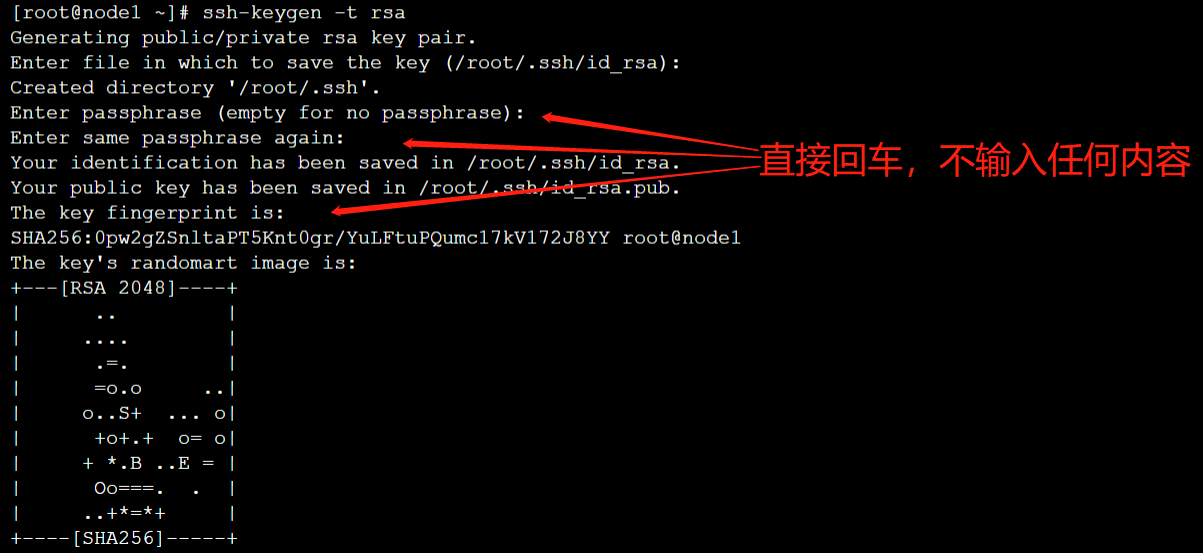
- 在client节点服务器,合并公钥到authorized_keys文件,进入/root/.ssh目录,使用SSH命令合并,如下所示:
[root@client1 ~]# cd /root/.ssh
[root@client1 .ssh]# cat id_rsa.pub >> authorized_keys使用ssh命令将其他节点的id_rsa.pub公钥合并到client节点的authorized_keys文件中,注意,第一次连接可能需要输入密码,密码可以按如下方式获取:
[root@client1 .ssh]# ssh root@client2 cat ~/.ssh/id_rsa.pub >> authorized_keys
[root@client1 .ssh]# ssh root@client3 cat ~/.ssh/id_rsa.pub >> authorized_keys
[root@client1 .ssh]# ssh root@node1 cat ~/.ssh/id_rsa.pub >> authorized_keys
[root@client1 .ssh]# ssh root@node2 cat ~/.ssh/id_rsa.pub >> authorized_keys
[root@client1 .ssh]# ssh root@node3 cat ~/.ssh/id_rsa.pub >> authorized_keys 效果如下:

- 将client节点服务器上/root/.ssh/目录下的authorized_keys、known_hosts复制到其他的节点服务器的/root/.ssh目录中,在client节点上使用如下命令。注意,第一次连接可能需要输入密码,密码获取方式同上。
[root@client1 .ssh]# scp -rq /root/.ssh/authorized_keys client2:/root/.ssh/
[root@client1 .ssh]# scp -rq /root/.ssh/authorized_keys client3:/root/.ssh/
[root@client1 .ssh]# scp -rq /root/.ssh/authorized_keys node1:/root/.ssh/
[root@client1 .ssh]# scp -rq /root/.ssh/authorized_keys node2:/root/.ssh/
[root@client1 .ssh]# scp -rq /root/.ssh/authorized_keys node3:/root/.ssh/
[root@client1 .ssh]# scp -rq /root/.ssh/known_hosts client2:/root/.ssh/
[root@client1 .ssh]# scp -rq /root/.ssh/known_hosts client3:/root/.ssh/
[root@client1 .ssh]# scp -rq /root/.ssh/known_hosts node1:/root/.ssh/
[root@client1 .ssh]# scp -rq /root/.ssh/known_hosts node2:/root/.ssh/
[root@client1 .ssh]# scp -rq /root/.ssh/known_hosts node3:/root/.ssh/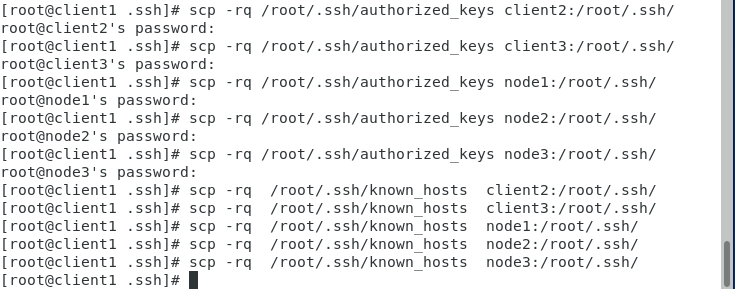
- 可以使用SSH命令连接其它节点,例如:
[root@client1 .ssh]# ssh node2- 使用【exit】命令退出SSH连接。
[root@node2 ~]# exit 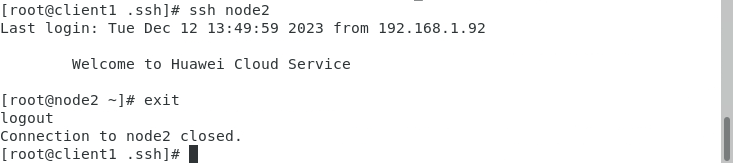
4、在各虚拟机上安装JDK并配置环境变量
Hadoop 2.6需要JDK 1.6及以上版本,如果系统自带Open JDK,强烈建议使用JDK 1.8替换系统自带的Open JDK。(在node1节点上安装配置JDK,然后将安装目录及配置文件拷贝到其他节点)
- 步骤一:查询系统是否以安装jdk
[root@node1~]# rpm -qa|grep jdk
- 步骤二:如果没有安装过jdk,则跳过此步骤,如果安装过jdk,则可以使用【rpm -e --nodeps 软件包名】命令卸载已安装的jdk
- 步骤三:验证一下是否还有jdk
[root@node1~]# rpm -qa|grep java
[root@node1~]# java -version
- 步骤四:在node1节点上,直接解压下载的JDK并配置变量即可。具体的步骤如下:
输入【cd /opt/software】命令,进入软件安装目录。
[root@node1 ~]# cd /opt/software/输入【tar -zxvf jdk-8u301-linux-x64.tar.gz -C /opt/module】 命令解压
[root@node1 software]# tar -zxvf jdk-8u301-linux-x64.tar.gz -C /opt/module/输入【vim /etc/profile】编辑profile文件,配置JDK环境变量,在文件尾部增加如下内容:
export JAVA_HOME=/opt/module/jdk1.8.0_301
export PATH=$PATH:$JAVA_HOME/bin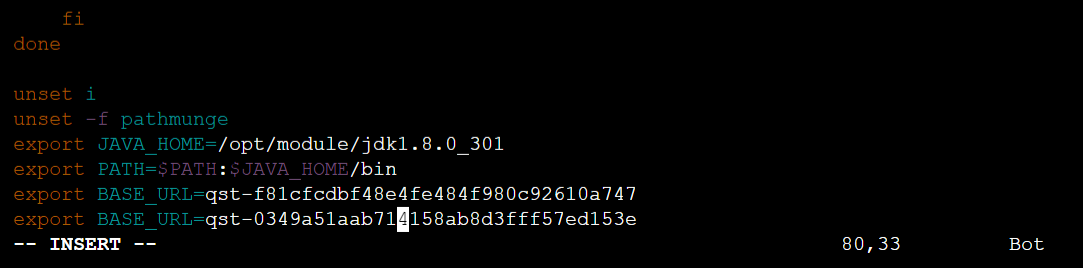
输入【source /etc/profile】命令使配置生效。
输入【java -version】命令查看JDK的版本。

- 步骤五:将node1节点上的JDK拷贝到其它服务器、/home/scala目录和/etc/profile文件拷贝到其它机器
| 例:scp -rq /opt/module/jdk1.8.0_301 主机名:/opt/module/ 例:scp /etc/profile 主机名:/etc/ |
具体操作如下:
[root@node1 module]# scp -rq /opt/module/jdk1.8.0_301 node2:/opt/module/
[root@node1 module]# scp -rq /opt/module/jdk1.8.0_301 node3:/opt/module/
[root@node1 module]# scp -rq /etc/profile node2:/etc/
[root@node1 module]# scp -rq /etc/profile node3:/etc/
在node2、node3执行【source /etc/profile】使环境变量生效,例如:

