17-3 向量数据库之野望3 - SingleStoreDB 实践教程
这场革命的核心是矢量数据库的概念,这是一项突破性的发展,正在重塑我们处理复杂数据的方式。与传统的关系数据库不同,矢量数据库具有独特的功能,可以管理和处理高维矢量数据,而高维矢量数据是许多人工智能和机器学习应用程序所固有的。随着我们深入进入高级人工智能时代,矢量数据库正成为关键工具,在处理生成式人工智能模型生成的庞大而复杂的数据集时,具有无与伦比的效率和准确性。
本文旨在探讨矢量数据库在生成 AI 领域的关键作用,重点介绍其功能、工作原理、用例和实践教程。
什么是矢量数据库?
矢量数据库是一种用于存储、索引和检索多维数据点(通常称为矢量)的数据库。与处理以表格形式组织的数据(如数字和字符串)的数据库不同,矢量数据库专门用于管理以多维矢量空间表示的数据。这使得它们非常适合人工智能和机器学习应用,其中数据通常采用矢量的形式,如图像嵌入、文本嵌入或其他类型的特征矢量。
这些数据库利用索引和搜索算法进行相似性搜索,使它们能够快速识别数据集中最相似的向量。这种能力对于推荐系统、图像和语音识别以及自然语言处理等任务至关重要,因为有效理解和处理高维数据起着至关重要的作用。因此,向量数据库代表了数据库技术的进步,旨在满足严重依赖大量数据的人工智能应用的需求。
向量嵌入
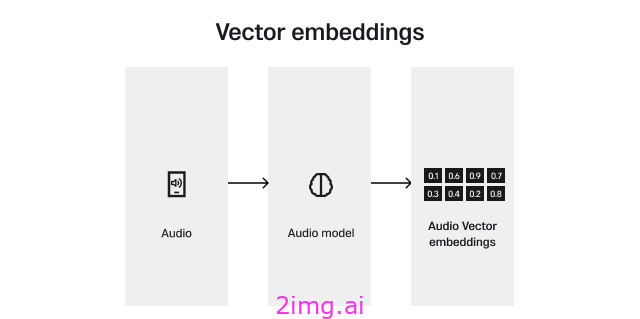
当我们谈论向量数据库时,我们肯定应该知道什么是向量嵌入——数据最终如何存储在向量数据库中。向量嵌入是一种数值代码,它封装了对象的关键特征;例如,音乐流媒体应用中的歌曲。通过分析和提取关键特征(如节奏和流派),每首歌曲都通过嵌入模型转换为向量嵌入。
此过程可确保具有相似属性的歌曲具有相似的向量代码。向量数据库存储这些嵌入,并在查询时比较这些向量以查找和推荐具有最接近匹配特征的歌曲 – 为用户提供高效且相关的搜索体验。
矢量数据库如何工作?

当用户发起查询时,各种类型的原始数据(包括图像、文档、视频和音频)首先通过嵌入模型进行处理,这些数据可以是非结构化的,也可以是结构化的。该模型通常是一个复杂的神经网络,将数据转换为高维数值向量,并有效地将数据的特征编码为向量嵌入,然后将其存储到SingleStoreDB 等向量数据库中。
当需要检索时,向量数据库会执行操作(如相似性搜索)以查找和检索与查询最相似的向量,从而高效处理复杂查询并向用户提供相关结果。整个过程使需要高速搜索和检索功能的应用程序中能够快速准确地管理大量多样的数据类型。
矢量数据库与传统数据库有何不同?
我们来探索一下矢量数据库和传统数据库的区别。
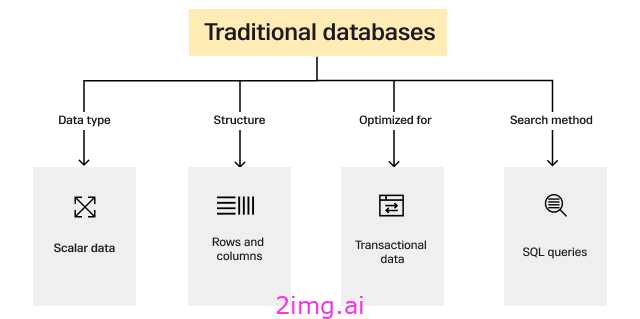
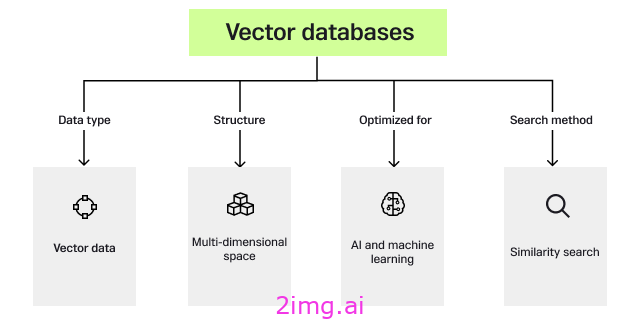
矢量数据库在数据组织和检索方法上与传统数据库有很大不同。传统数据库的结构是处理离散的标量数据类型(如数字和字符串),将它们组织成行和列。
这种结构非常适合事务数据,但对于通常用于人工智能和机器学习的复杂高维数据,效率较低。相比之下,矢量数据库旨在存储和管理矢量数据(表示多维空间中的点的数字数组)。
这使得它们天生就适合相似性搜索任务,其目标是在高维空间中找到最近的数据点,这是图像和语音识别、推荐系统和自然语言处理等人工智能应用的常见要求。通过利用针对高维向量空间优化的索引和搜索算法,向量数据库提供了一种更高效、更有效的方式来处理在高级人工智能和机器学习时代日益普遍的数据类型。