LLM-阿里 DashVector + langchain self-querying retriever 优化 RAG 实践【Query 优化】
文章目录
- 前言
- self querying 简介
- 代码实现
- 总结
前言
现在比较流行的 RAG 检索就是通过大模型 embedding 算法将数据嵌入向量数据库中,然后在将用户的查询向量化,从向量数据库中召回相似性数据,构造成 context template, 放到 LLM 中进行查询。
如果说将用户的查询语句直接转换为向量查询可能并不会得到很好的结果,比如说我们往向量数据库中存入了一些商品向量,现在用户说:“我想要一条价格低于20块的黑色羊毛衫”,如果使用传统的嵌入算法,该查询语句转换为向量查询就可能“失帧”,被转换为查询黑色羊毛衫。
针对这种情况我们就会使用一些优化检索查询语句方式来优化 RAG 查询,其中 langchain 的 self-querying 就是一种很好的方式,这里使用阿里云的 DashVector 向量数据库和 DashScope LLM 来进行尝试,优化后的查询效果还是挺不错的。
现在很多网上的资料都是使用 OpenAI 的 Embedding 和 LLM,但是个人角色现在国内阿里的 LLM 和向量数据库已经非常好了,而且 OpenAI 已经禁用了国内的 API 调用,国内的云服务又便宜又好用,真的不尝试一下么?关于 DashVector 和 DashScope 我之前写了几篇实践篇,大家感兴趣的可以参考下:
LLM-文本分块(langchain)与向量化(阿里云DashVector)存储,嵌入LLM实践
LLM-阿里云 DashVector + ModelScope 多模态向量化实时文本搜图实战总结
LLM-langchain 与阿里 DashScop (通义千问大模型) 和 DashVector(向量数据库) 结合使用总结
前提条件
- 确保开通了通义千问 API key 和 向量检索服务 API KEY
- 安装依赖:
pip install langchain
pip install langchain-community
pip install dashVector
pip install dashscope
self querying 简介
简单来说就是通过 self-querying 的方式我们可以将用户的查询语句进行结构化转换,转换为包含两层意思的向量化数据:
- Query: 和查询语义相近的向量查询
- Filter: 关于查询内容的一些 metadata 数据
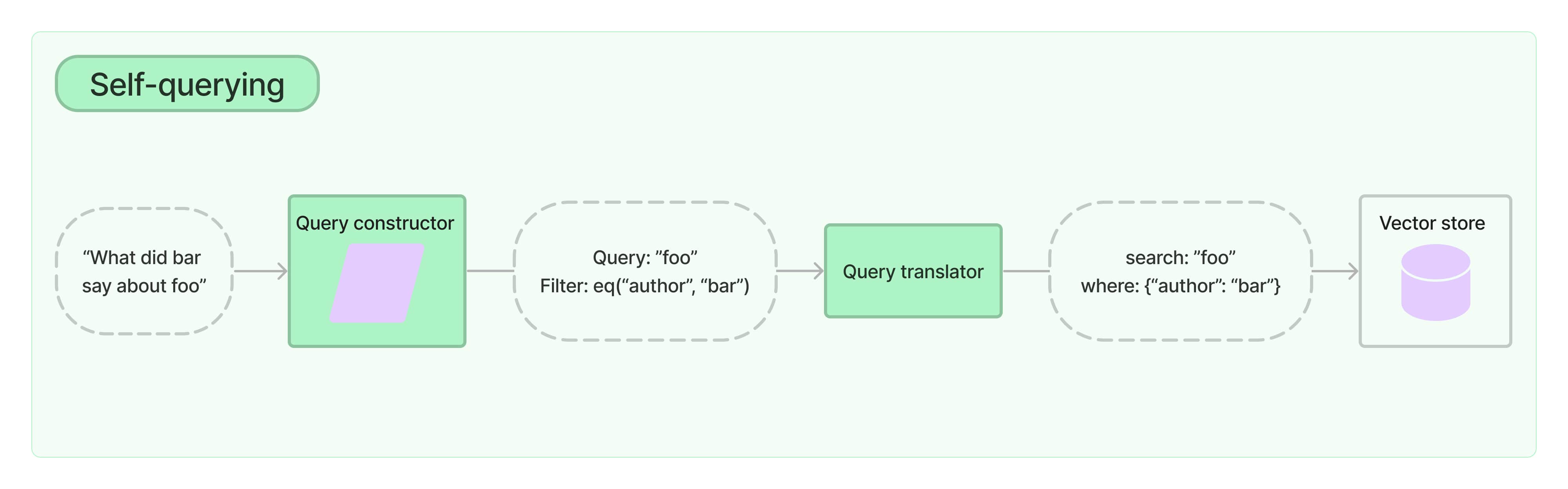
比如说上图中用户输入:“bar 说了关于 foo 的什么东西?”,self-querying 结构化转换后就变为了两层含义:
- 查询关于 foo 的数据
- 其中作者为 bar
代码实现
将DASHSCOPE_API_KEY, DASHVECTOR_API_KEY, DASHVECTOR_ENDPOINT替换为自己在阿里云开通的。
import osfrom langchain_core.documents import Document
from langchain_community.vectorstores.dashvector import DashVector
from langchain_community.embeddings.dashscope import DashScopeEmbeddings
from langchain.chains.query_constructor.base import AttributeInfo
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.vectorstores import VectorStoreclass SelfQuerying:def __init__(self):# 我们需要同时开通 DASHSCOPE_API_KEY 和 DASHVECTOR_API_KEYos.environ["DASHSCOPE_API_KEY"] = ""os.environ["DASHVECTOR_API_KEY"] = ""os.environ["DASHVECTOR_ENDPOINT"] = ""self.llm = ChatTongyi(temperature=0)def handle_embeddings(self)->'VectorStore':docs = [Document(page_content="A bunch of scientists bring back dinosaurs and mayhem breaks loose",metadata={"year": 1993, "rating": 7.7, "genre": "science fiction"},),Document(page_content="Leo DiCaprio gets lost in a dream within a dream within a dream within a ...",metadata={"year": 2010, "director": "Christopher Nolan", "rating": 8.2},),Document(page_content="A psychologist / detective gets lost in a series of dreams within dreams within dreams and Inception reused the idea",metadata={"year": 2006, "director": "Satoshi Kon", "rating": 8.6},),Document(page_content="A bunch of normal-sized women are supremely wholesome and some men pine after them",metadata={"year": 2019, "director": "Greta Gerwig", "rating": 8.3},),Document(page_content="Toys come alive and have a blast doing so",metadata={"year": 1995, "genre": "animated"},),Document(page_content="Three men walk into the Zone, three men walk out of the Zone",metadata={"year": 1979,"director": "Andrei Tarkovsky","genre": "thriller","rating": 9.9,},),]# 指定向量数据库中的 Collection namevectorstore = DashVector.from_documents(docs, DashScopeEmbeddings(), collection_name="langchain")return vectorstoredef build_querying_retriever(self, vectorstore: 'VectorStore', enable_limit: bool=False)->'SelfQueryRetriever':"""构造优化检索:param vectorstore: 向量数据库:param enable_limit: 是否查询 Top k:return:"""metadata_field_info = [AttributeInfo(name="genre",description="The genre of the movie. One of ['science fiction', 'comedy', 'drama', 'thriller', 'romance', 'action', 'animated']",type="string",),AttributeInfo(name="year",description="The year the movie was released",type="integer",),AttributeInfo(name="director",description="The name of the movie director",type="string",),AttributeInfo(name="rating", description="A 1-10 rating for the movie", type="float"),]document_content_description = "Brief summary of a movie"retriever = SelfQueryRetriever.from_llm(self.llm,vectorstore,document_content_description,metadata_field_info,enable_limit=enable_limit)return retrieverdef handle_query(self, query: str):"""返回优化查询后的检索结果:param query::return:"""# 使用 LLM 优化查询向量,构造优化后的检索retriever = self.build_querying_retriever(self.handle_embeddings())response = retriever.invoke(query)return responseif __name__ == '__main__':q = SelfQuerying()# 只通过查询属性过滤print(q.handle_query("I want to watch a movie rated higher than 8.5"))# 通过查询属性和查询语义内容过滤print(q.handle_query("Has Greta Gerwig directed any movies about women"))# 复杂过滤查询print(q.handle_query("What's a highly rated (above 8.5) science fiction film?"))# 复杂语义和过滤查询print(q.handle_query("What's a movie after 1990 but before 2005 that's all about toys, and preferably is animated"))上边的代码主要步骤有三步:
- 执行 embedding, 将带有 metadata 的 Doc 嵌入 DashVector
- 构造 self-querying retriever,需要预先提供一些关于我们的文档支持的元数据字段的信息以及文档内容的简短描述。
- 执行查询语句
执行代码输出查询内容如下:
# "I want to watch a movie rated higher than 8.5"
[Document(page_content='Three men walk into the Zone, three men walk out of the Zone', metadata={'director': 'Andrei Tarkovsky', 'genre': 'thriller', 'rating': 9.9, 'year': 1979}),Document(page_content='A psychologist / detective gets lost in a series of dreams within dreams within dreams and Inception reused the idea', metadata={'director': 'Satoshi Kon', 'rating': 8.6, 'year': 2006})]# "Has Greta Gerwig directed any movies about women"
[Document(page_content='A bunch of normal-sized women are supremely wholesome and some men pine after them', metadata={'director': 'Greta Gerwig', 'rating': 8.3, 'year': 2019})]# "What's a highly rated (above 8.5) science fiction film?"
[Document(page_content='A bunch of normal-sized women are supremely wholesome and some men pine after them', metadata={'director': 'Greta Gerwig', 'rating': 8.3, 'year': 2019})]# "What's a movie after 1990 but before 2005 that's all about toys, and preferably is animated"
[Document(page_content='Toys come alive and have a blast doing so', metadata={'genre': 'animated', 'year': 1995})]
总结
本文主要讲了如何使用 langchain 的 self-query 来优化向量检索,我们使用的是阿里云的 DashVector 和 DashScope LLM 进行的代码演示,读者可以开通下,体验尝试一下。