SpreadsheetLLM:微软对Excel编码的“摊膀伏”

--->更多内容,请移步“鲁班秘笈”!!<---

SpreadsheetLLM
Excel的特点是二维数据格式、灵活的布局和多样化的格式选项。微软最近引入了SpreadsheetLLM,开创了一种高效的编码方法,用于释放和优化LLMs在电子表格上的强大理解和推理能力。最初研究人员提出一种包含单元格地址、值和格式的普通序列化方法。但是这种方法受到LLMs 上下文长度的约束,为此微软推出了SheetCompressor(下图绿色部分),它是一种创新的编码框架,可以有效地压缩电子表格。
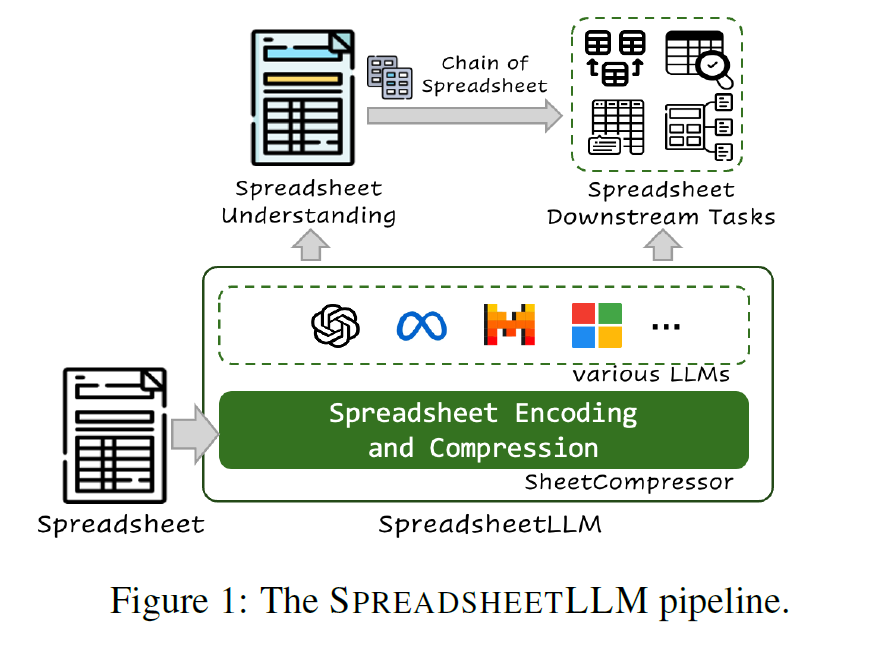
左边为文档输入,经过SheetCompressor的压缩编码,之后将编码输入到现有的大模型,进而加深大模型对电子表格的深入理解,最后利用chain of Spreadsheet完成下游任务。
SSLLM最终在GPT4的上下文学习中比普通方法高出25.6%。此外,利用SheetCompressor进行微调的平均压缩比为25×,却达到了最先进的 78.9%F1 分数,比目前的优等生高出12.3%。
最后研究人员还提出了电子表格链,用于电子表格理解的下游任务,事实证明SpreadsheetLLM在各种电子表格任务中非常有效。

SheetCompressor
SheetCompressor是这次研究的灵魂,本文重点来看看它的实现模式。它主要由三个模块组成:基于结构锚点的压缩、逆索引转换和数据格式感知聚合。
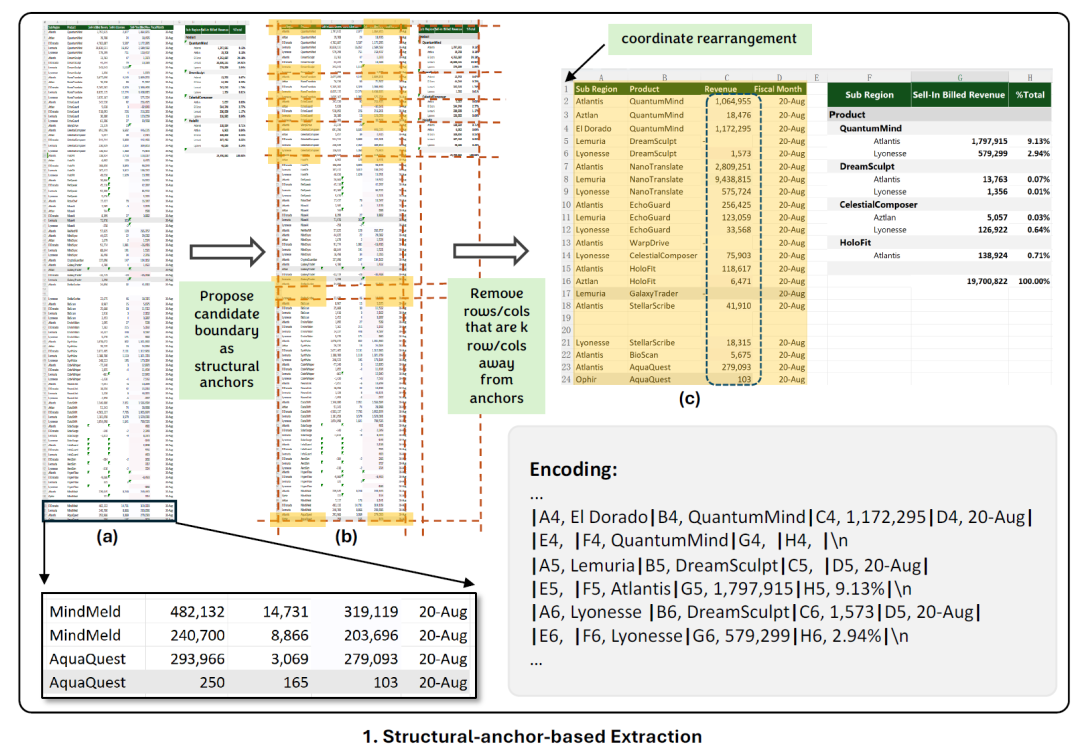
首先在在整个电子表格中放置“结构锚点”,以帮助LLM更好地了解正在发生什么。
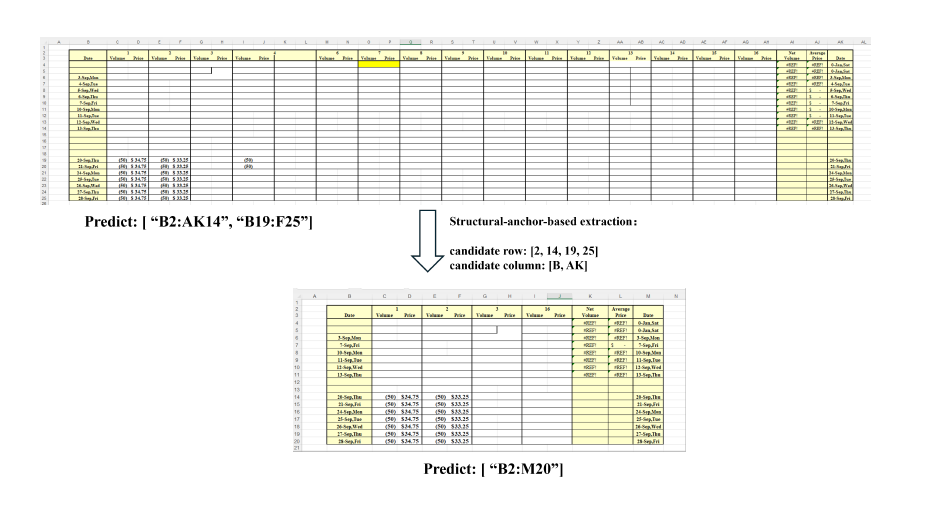
然后,删除“遥远的、均匀的行和列”,以生成电子表格的压缩“骨架”版本,如上图所示。

索引转换解决了由具有大量空单元格和重复值的电子表格引起的挑战。“为了提高效率,SheetCompressor摆脱了传统的逐行和逐列序列化,采用JSON格式的无损倒排索引翻译,” 研究人员表示 “这种方法创建了一个字典,该字典为非空单元格文本编制索引,并将具有相同文本的地址合并,在保证数据完整性的同时且优化Token长度。”
<输入Token的长度很重要,因为这些经过编码的Token下一步就会被送到各种大模型学习,而大模型对于输入Token是有限制的!>

认识到精确的数值对于掌握电子表格结构不太重要,研究人员从这些单元格中提取数字格式字符串和数据类型。
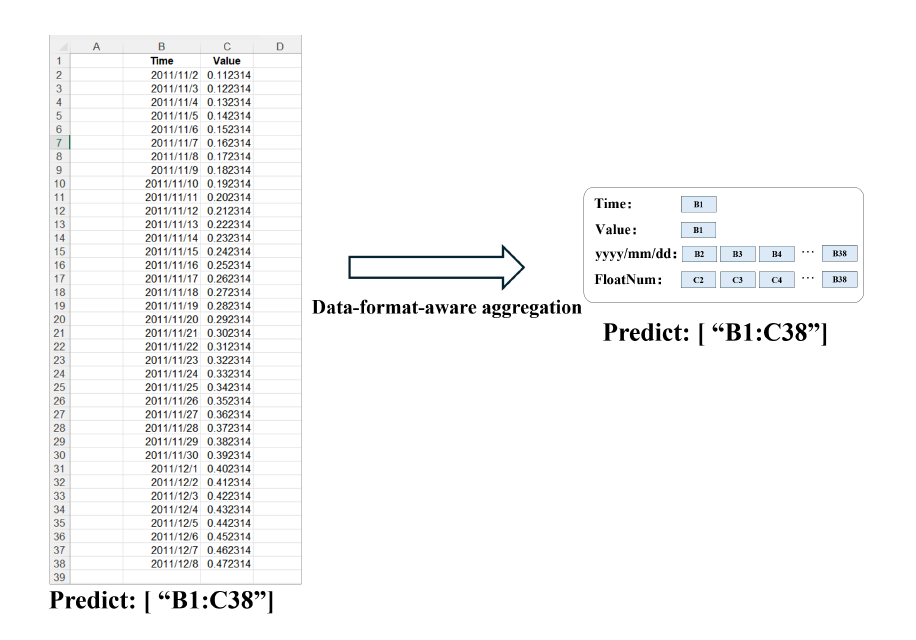
然后具有相同格式或类型的相邻单元格聚集在一起,进而简化对数值数据分布的理解,而不会浪费Token长度。
通过上面三种办法的叠加组合,SheetCompressor显着减少了96%的电子表格的Enbedding Token。在文中的一个示例中,电子表格由576行和23列组成,原始编码为61,240个标记。按照新的技术首先使用结构锚提取单元格,将它们重新排列成一个较小的24×8工作表。随后执行索引反转,删除空单元格。最后根据数据格式聚合单元格,实现电子表格的极其紧凑的表示,其中仅包含708个标记!

上表为三个组件在测试数据集上面的各种组合压缩比率清单,第一列为没有运用任何手段,所以压缩比率为1(原始的Token长度/压缩的Token长度)。可以观察到三种方法组合可以达到24.79的压缩比例。

性能对比
为了评估SpreadsheetLLM的性能,研究人员选择了TableSense-CNN作为基线,因为之前在电子表格检测任务中证明了有效性。本次采用F1分数作为主要指标来评估和比较不同模型的性能,它平衡了精确度和召回率,提供了模型准确性的整体视图。
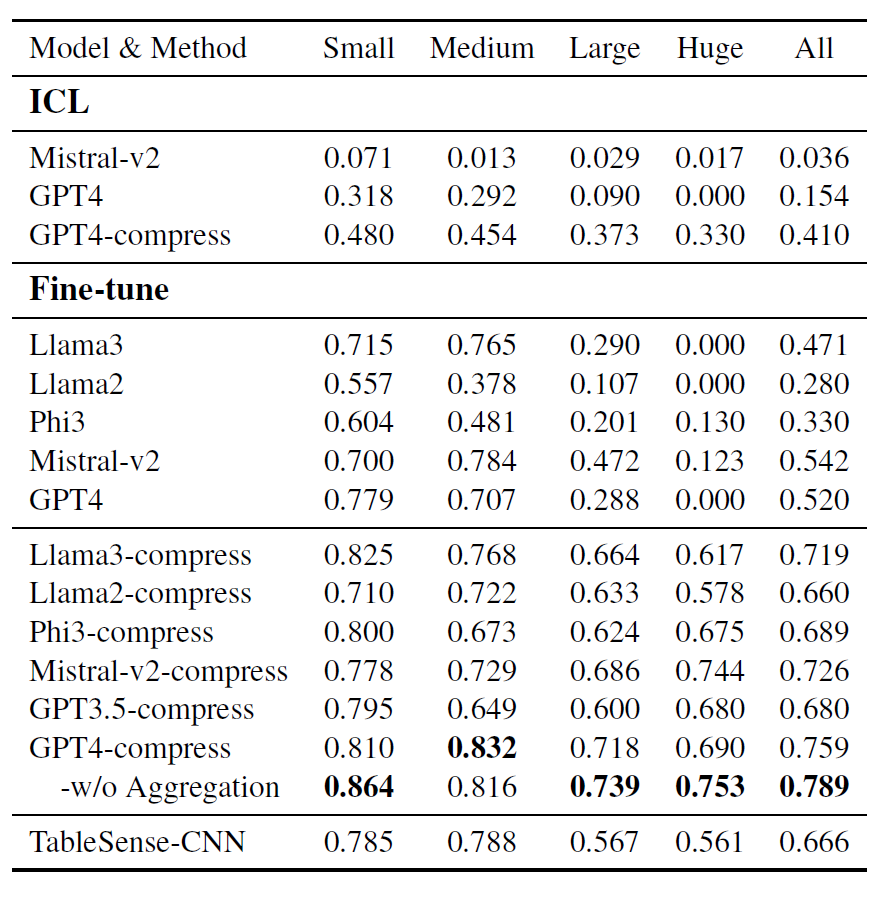
微调后GPT4模型在所有数据集上获得了约 76%的F1分数,而利用本文涉及的不带聚合编码的方法在所有数据集上获得了约79%的F1分数。
这标志着与在原始数据上微调的相同模型相比提高了27%,比 TableSense-CNN提高了13%,并成为新的王(SOTA)。整个编码方法在可容忍的范围内略微降低了F1分数,但取得了良好的压缩结果。
此外基于本文的压缩方法,Llama3的分数加了25%,Phi3增加了36%,Llama2增加了38%,Mistral-v2增加了18%。这些结果突显了编码方法显著增强了性能,也就是说它改善了上下文学习(In-Context Learning)。同时还节省了大量的成本,这种方法的成本几乎与输入Token成正比,根据ICL中GPT4和GPT3.5-turbo型号的价格,在测试集中降低了96%的成本。