大模型的一些思考
迄今为止,应该没有人还怀疑大模型的能力吧?但目前大模型实现真正落地,其实还有一段艰难的路要走。
和大模型相关的一些术语
**1. 大模型:**一般指1亿以上参数的模型,但是这个标准一直在升级,目前万亿参数以上的模型也有了。大语言模型(Large Language Model,LLM)是针对语言的大模型。
**2. 175B、60B、540B等:**这些一般指参数的个数,B是Billion/十亿的意思,175B是1750亿参数,这是ChatGPT大约的参数规模。
3. 强化学习:(Reinforcement Learning)一种机器学习的方法,通过从外部获得激励来校正学习方向从而获得一种自适应的学习能力。
4. 基于人工反馈的强化学习(RLHF):(Reinforcement Learning from Human Feedback)构建人类反馈数据集,训练一个激励模型,模仿人类偏好对结果打分,这是GPT-3后时代大语言模型越来越像人类对话核心技术。
5. 涌现:(Emergence)或称创发、突现、呈展、演生,是一种现象。许多小实体相互作用后产生了大实体,而这个大实体展现了组成它的小实体所不具有的特性。研究发现,模型规模达到一定阈值以上后,会在多步算术、大学考试、单词释义等场景的准确性显著提升,称为涌现。
6. 泛化:(Generalization)模型泛化是指一些模型可以应用(泛化)到其他场景,通常为采用迁移学习、微调等手段实现泛化。
7. 微调:(FineTuning)针对大量数据训练出来的预训练模型,后期采用业务相关数据进一步训练原先模型的相关部分,得到准确度更高的模型,或者更好的泛化。
8. 指令微调:(Instruction FineTuning),针对已经存在的预训练模型,给出额外的指令或者标注数据集来提升模型的性能。
9. 思维链:(Chain-of-Thought,CoT)。通过让大语言模型(LLM)将一个问题拆解为多个步骤,一步一步分析,逐步得出正确答案。需指出,针对复杂问题,LLM直接给出错误答案的概率比较高。思维链可以看成是一种指令微调。
10**. prompt:**是输入给大模型的文本,用来提示或引导大模型给出符合预期的输出。**Prompt = 提示词 = 人与大模型交互的媒介。**打个比方,假如我们是产品经理,大模型是一名研发工程师的话,那么提示词就是需求,产品经理在提需求的时候,需要在需求里面包含背景说明、需求说明、版本要求、方案建议等信息,只有把需求描述得足够清晰,工程师才能够按照需求输出符合要求的代码,提示词就相当于人向大模型提需求时的需求文档。
11.**** **Token:**Token是大模型处理的最小单元,比如英文单词或者汉字。Token长度 = 与大模型交互时使用的单词、汉字数。
12.Emdedding**:**是将段落文本编码成固定维度的向量,便于进行语义相似度的比较。
**13.Fine-Tune:**在已经训练好的模型基础上进一步调整模型的过程吗,是一种使用高质量数据对模型参数进行微调的知识迁移技术,目的是让模型更匹配对特定任务的理解。
对于ToC来说,大众的口味已经被ChatGPT给养叼了,市场基本上被ChatGPT吃的干干净净。虽然国内大厂在紧追不舍,但目前绝大多数都还在实行内测机制,大概率是不会广泛开放的(毕竟各大厂还是主盯ToB、ToG市场的,从华为在WAIC的汇报就可以看出)。而对于ToB和ToG端来说,本地化部署、领域or行业内效果绝群、国产化无疑就成为了重要的考核指标。
个人觉得垂直领域大模型或者说大模型领域化、行业化才是大模型落地的核心要素。恰好前几天ChatLaw(一款法律领域大模型产品)也是大火,当时也是拿到了一手内测资格测试了一阵,也跟该模型的作者聊了很久。正好利用周末的时间,好好思考、梳理、汇总了一些垂直领域大模型内容。
内容将从ChatLaw展开、到垂直领域大模型的一些讨论、最后汇总一下现有的开源领域大模型。
聊聊对ChatLaw的看法
ChatLaw的出现,让我更加肯定未来大模型落地需要具有领域特性。相较于目前领域大模型,ChatLaw不仅仅是一个模型,而是一个经过设计的大模型领域产品,已经在法律领域具有很好的产品形态。
Paper: https://arxiv.org/pdf/2306.16092.pdf
Github: https://github.com/PKU-YuanGroup/ChatLaw
官网: https://www.chatlaw.cloud/ 可能会有一些质疑,比如:不就是一个langchain吗?法律领域它能保证事实性问题吗?等等等。但,我觉得在否定一件事物的前提,是先去更深地了解它。
ChatLaw共存在两种模式:普通模型和专业模型。普通模式就是仅基于大模型进行问答。而专业模式是借助检索的手段,对用户查询进行匹配从知识库中筛选出合适的证据,再根据大模型汇总能力,得到最终答案。
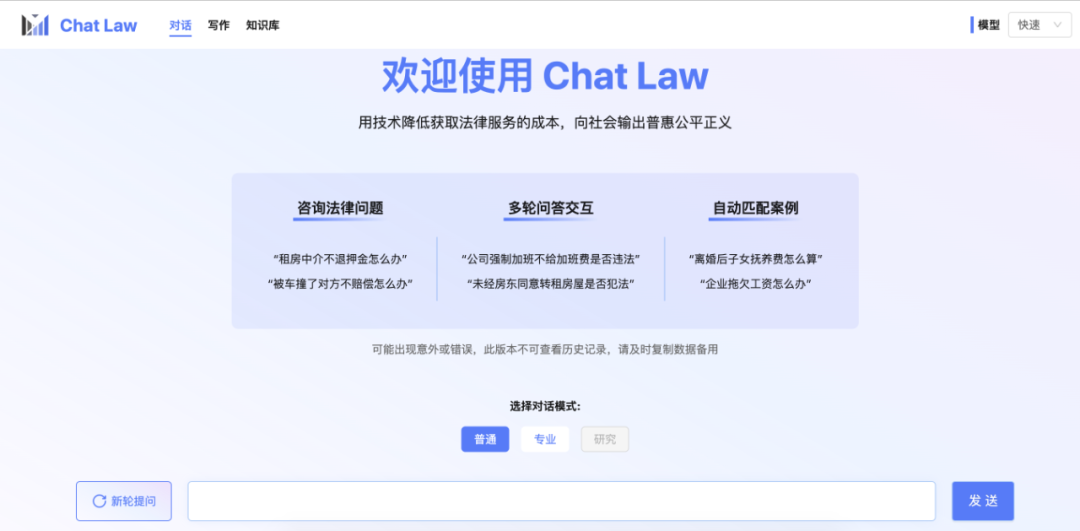
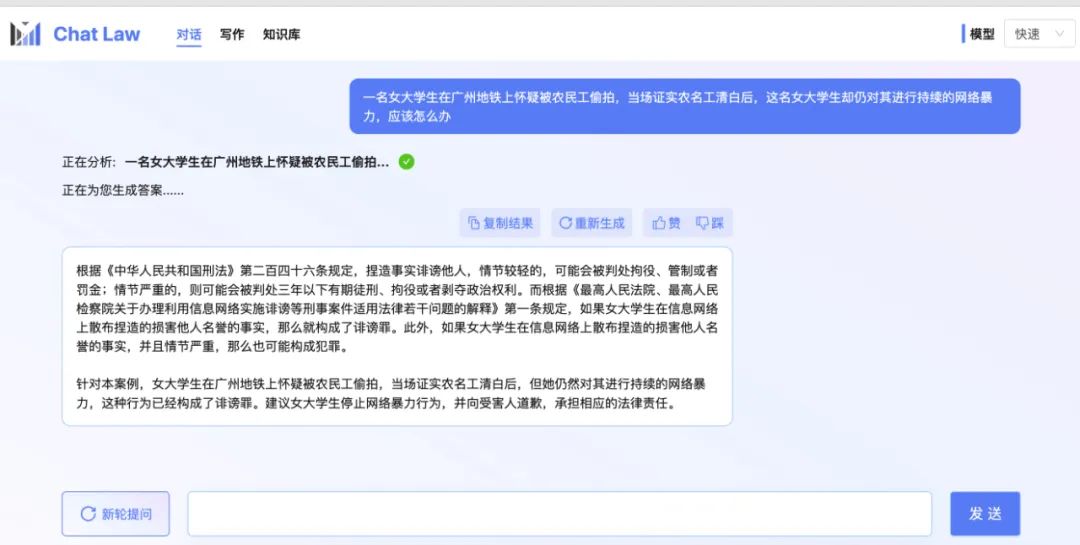
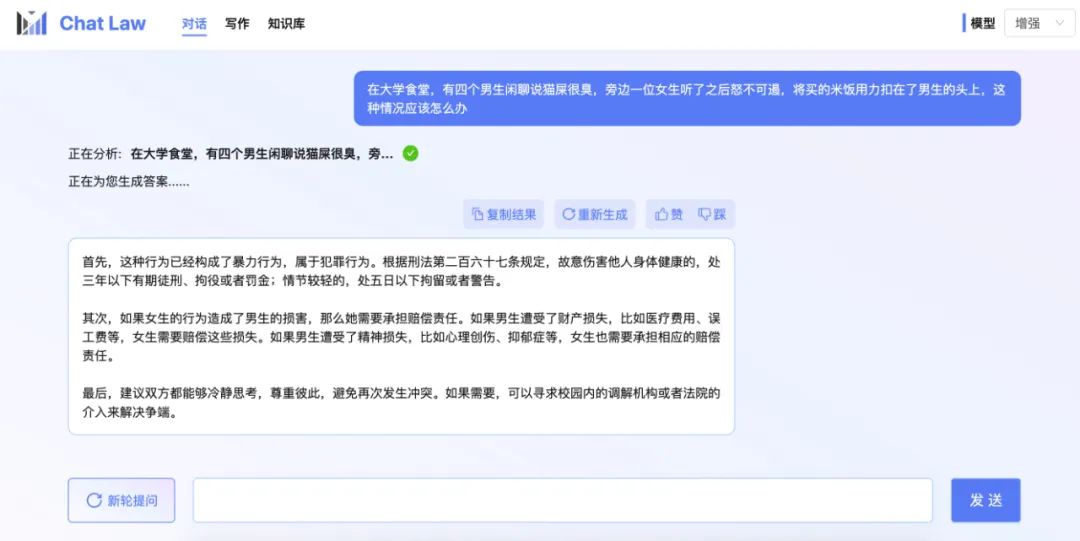
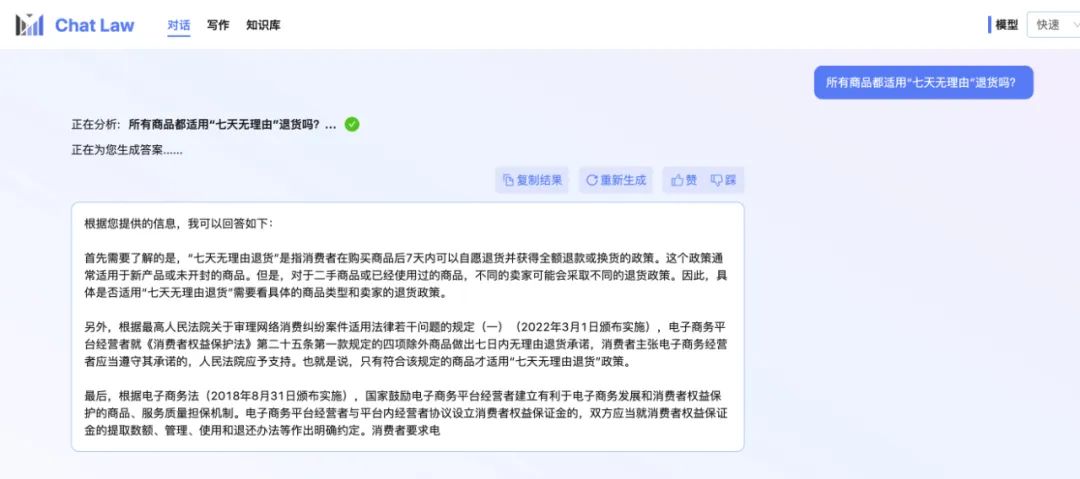
由于专业模式,借助了知识库的内容,也会使得用户得到的效果更加精准。而在专业版中,ChatLaw制定了一整套流程,如上图所示,存在反问提示进行信息补全,用户信息确认、相似案例检索、建议汇总等。
其实ChatLaw=ChatLaw LLM + keyword LLM + laws LLM。而keyword LLM真的让我眼前一亮的,之前对关键词抽取的理解,一直是从文本中找到正确的词语,在传统检索中使用同义词等方法来提高检索效果。而keyword LLM利用大模型生成关键词,不仅可以找到文本中的重点内容,还可以总结并释义出一些词。使得整个产品在检索证据内容时,效果更加出色。
同时,由于不同模型对不同类型问题解决效果并不相同,所以在真正使用阶段,采用HuggingGPT作为调度器的方式,在每次用户请求的时候去选择调用更加适配的模型。也就是让适合的模型做更适合的事情。
聊聊对垂直领域大模型的看法
现在大模型的使用主要就是两种模型,第一种是仅利用大模型本身解决用户问题;第二种就是借助外部知识来解决用户问题。而我个人觉得是**“借助外部知识进行问答”**才是未来,虽然会对模型推理增加额外成本,但是外部知识是缓解模型幻觉的有效方法。
但随着通用大模型底层能力越来越强,以及可接受文本越来越长,在解决垂直领域问题时,完全可以采用ICL技术,来提升通用大模型在垂直领域上的效果,那么训练一个垂直领域大模型是否是一个伪命题,我们还有必要做吗?
个人认为是需要的,下面从几个方面来讨论:
-
1、个人觉得真正垂直领域大模型的做法,应该从Pre-Train做起。SFT只是激发原有大模型的能力,预训练才是真正知识灌输阶段,让模型真正学习领域数据知识,做到适配领域。但目前很多垂直领域大模型还停留在SFT阶段。
-
2、对于很多企业来说,领域大模型在某几个能力上绝群就可以了。难道我能源行业,还需要care模型诗写的如何吗?所以领域大模型在行业领域上效果是优于通用大模型即可,不需要“即要又要还要”。
-
3、不应某些垂直领域大模型效果不如ChatGPT,就否定垂直领域大模型。有没有想过一件可怕的事情,ChatGPT见的垂直领域数据,比你的领域大模型见的还多。但某些领域数据,ChatGPT还是见不到的。
-
4、考虑到部署成本得问题,我觉得在7B、13B两种规模的参数下,通用模型真地干不过领域模型。及时175B的领域大模型没有打过175B的通用模型又能怎么样呢?模型参数越大,需要数据量越大,领域可能真的没有那么多数据。
PS:很多非NLP算法人员对大模型产品落地往往会有一些疑问:
Q:我有很多的技术标准和领域文本数据,直接给你就能训练领域大模型了吧?
A:是也不是,纯文本只能用于模型的预训练,真正可以进行后续问答,需要的是指令数据。当然可以采用一些人工智能方法生成一些指数据,但为了保证事实性,还是需要进行人工校对的。高质量SFT数据,才是模型微调的关键。
Q:你用领域数据微调过的大模型,为什么不直接问答,还要用你的知识库?
A:外部知识主要是为了解决模型幻觉、提高模型回复准确。
Q:为什么两次回复结果不一样?
A:大模型一般为了保证多样性,解码常采用Top-P、Top-K解码,这种解码会导致生成结果不可控。如果直接采用贪婪解码,模型生成结果会是局部最优。
Q:我是不是用开源6B、7B模型自己训练一个模型就够了?
A:兄弟,没有训练过33B模型的人,永远只觉得13B就够了。
以上是个人的一些想法,以及一些常见问题的回复,不喜勿喷,欢迎讨论,毕竟每个人对每件事的看法都不同。
开源垂直领域大模型
目前有很多的垂直领域大模型已经开源,主要在医疗、金融、法律、教育等领域,本小节主要进行**「中文开源」**模型的汇总及介绍。
医疗领域
非中文项目:BioMedLM、PMC-LLaMA、ChatDoctor、BioMedGPT等,这里不做介绍。
MedicalGPT-zh
Github: https://github.com/MediaBrain-SJTU/MedicalGPT-zh -
简介:基于ChatGLM-6B指令微调的中文医疗通用模型。
-
数据:通过对16组诊疗情景和28个科室医用指南借助ChatGPT构造182k条数据。数据也已开源。
-
训练方法:基于ChatGLM-6B,采用Lora&16bit方法进行模型训练。
DoctorGLM
Github: https://github.com/xionghonglin/DoctorGLM -
简介:一个基于ChatGLM-6B的中文问诊模型。
-
数据:主要采用CMD(Chinese Medical Dialogue Data)数据。
-
训练方法:基于ChatGLM-6B模型,采用Lora和P-tuning-v2两种方法进行模型训练。
PS:数据来自Chinese-medical-dialogue-data项目。
Huatuo-Llama-Med-Chinese
Github: https://github.com/SCIR-HI/Huatuo-Llama-Med-Chinese -
简介:本草(原名:华驼-HuaTuo): 基于中文医学知识的LLaMA微调模型。
-
数据:通过医学知识图谱和GPT3.5 API构建了中文医学指令数据集,数据共开源9k条。
-
训练方法:基于Llama-7B模型,采用Lora方法进行模型训练。
Med-ChatGLM
Github: https://github.com/SCIR-HI/Med-ChatGLM -
简介:基于中文医学知识的ChatGLM模型微调,与本草为兄弟项目。
-
数据:与Huatuo-Llama-Med-Chinese相同。
-
训练方法:基于ChatGLM-6B模型,采用Lora方法进行模型训练。
ChatMed
Github: https://github.com/michael-wzhu/ChatMed -
简介:中文医疗大模型,善于在线回答患者/用户的日常医疗相关问题.
-
数据:50w+在线问诊+ChatGPT回复作为训练集。
-
训练方法:基于Llama-7B模型,采用Lora方法进行模型训练。
ShenNong-TCM-LLM
Github: https://github.com/michael-wzhu/ShenNong-TCM-LLM -
简介:“神农”大模型,首个中医药中文大模型,与ChatMed为兄弟项目。
-
数据:以中医药知识图谱为基础,采用以实体为中心的自指令方法,调用ChatGPT得到11w+的围绕中医药的指令数据。
-
训练方法:基于Llama-7B模型,采用Lora方法进行模型训练。
BianQue
Github: https://github.com/scutcyr/BianQue -
简介:扁鹊,中文医疗对话模型。
-
数据:结合当前开源的中文医疗问答数据集(MedDialog-CN、IMCS-V2、CHIP-MDCFNPC、MedDG、cMedQA2、Chinese-medical-dialogue-data),分析其中的单轮/多轮特性以及医生问询特性,结合实验室长期自建的生活空间健康对话大数据,构建了千万级别规模的扁鹊健康大数据BianQueCorpus。
-
训练方法:扁鹊-1.0以ChatYuan-large-v2作为底座模型全量参数训练得来,扁鹊-2.0以ChatGLM-6B作为底座模型全量参数训练得来。
SoulChat
Github: https://github.com/scutcyr/SoulChat -
简介:中文领域心理健康对话大模型,与BianQue为兄弟项目。
-
数据:构建了超过15万规模的单轮长文本心理咨询指令数据,并利用ChatGPT与GPT4,生成总共约100万轮次的多轮回答数据。
-
训练方法:基于ChatGLM-6B模型,采用全量参数微调方法进行模型训练。
法律领域
LaWGPT
Github: https://github.com/pengxiao-song/LaWGPT -
简介:基于中文法律知识的大语言模型。
-
数据:基于中文裁判文书网公开法律文书数据、司法考试数据等数据集展开,利用Stanford_alpaca、self-instruct方式生成对话问答数据,利用知识引导的数据生成,引入ChatGPT清洗数据,辅助构造高质量数据集。
-
训练方法:(1)Legal-Base-7B模型:法律基座模型,使用50w中文裁判文书数据二次预训练。(2)LaWGPT-7B-beta1.0模型:法律对话模型,构造30w高质量法律问答数据集基于Legal-Base-7B指令精调。(3)LaWGPT-7B-alpha模型:在Chinese-LLaMA-7B的基础上直接构造30w法律问答数据集指令精调。(4)LaWGPT-7B-beta1.1模型:法律对话模型,构造35w高质量法律问答数据集基于Chinese-alpaca-plus-7B指令精调。
ChatLaw
Github: https://github.com/PKU-YuanGroup/ChatLaw -
简介:中文法律大模型
-
数据:主要由论坛、新闻、法条、司法解释、法律咨询、法考题、判决文书组成,随后经过清洗、数据增强等来构造对话数据。
-
训练方法:(1)ChatLaw-13B:基于姜子牙Ziya-LLaMA-13B-v1模型采用Lora方式训练而来。(2)ChatLaw-33B:基于Anima-33B采用Lora方式训练而来。
LexiLaw
Github: https://github.com/CSHaitao/LexiLaw -
简介:中文法律大模型
-
数据:BELLE-1.5M通用数据、LawGPT项目中52k单轮问答数据和92k带有法律依据的情景问答数据、Lawyer LLaMA项目中法考数据和法律指令微调数据、华律网20k高质量问答数据、百度知道收集的36k条法律问答数据、法律法规、法律参考书籍、法律文书。
-
训练方法:基于ChatGLM-6B模型,采用Freeze、Lora、P-Tuning-V2三种方法进行模型训练。
LAW-GPT
Github: https://github.com/LiuHC0428/LAW-GPT -
简介:中文法律大模型(獬豸)
-
数据:现有的法律问答数据集和基于法条和真实案例指导的self-Instruct构建的高质量法律文本问答数据。
-
训练方法:基于ChatGLM-6B,采用Lora&16bit方法进行模型训练。
Chinese-LLaMA-Alpaca
Github: https://github.com/ymcui/Chinese-LLaMA-Alpaca -
简介:中文LLaMA模型和指令精调的Alpaca大模型
-
数据:互联网数据。
-
训练方法:在原版LLaMA的基础上扩充了中文词表并使用了中文数据进行二次预训练,进一步提升了中文基础语义理解能力。同时,中文Alpaca模型进一步使用了中文指令数据进行精调,显著提升了模型对指令的理解和执行能力。
lawyer-llama
Github: https://github.com/AndrewZhe/lawyer-llama -
简介:中文法律LLaMA
-
数据:法考数据7k、法律咨询数据14k
-
训练方法:以Chinese-LLaMA-13B为底座,未经过法律语料continual training,使用通用instruction和法律instruction进行SFT。
金融领域
非中文较好的项目:BloombergGPT、PIXIU等,在此不做介绍。
FinGPT
Github: https://github.com/AI4Finance-Foundation/FinGPT -
简介:金融大模型
-
数据:来自东方财富
-
训练方法:基于ChatGLM-6B,采用Lora方法训练模型。
FinTuo
Github: https://github.com/qiyuan-chen/FinTuo-Chinese-Finance-LLM -
简介:一个中文金融大模型项目,旨在提供开箱即用且易于拓展的金融领域大模型工具链。
-
数据:暂未完成。
-
训练方法:暂未完成。
教育领域
EduChat
Github: https://github.com/icalk-nlp/EduChat -
简介:以预训练大模型为基底的教育对话大模型相关技术,提供教育场景下自动出题、作业批改、情感支持、课程辅导、高考咨询等丰富功能,服务于广大老师、学生和家长群体,助力实现因材施教、公平公正、富有温度的智能教育。
-
数据:混合多个开源中英指令、对话数据,并去重后得到,约400w。
-
训练方法:基于LLaMA模型训练而来。
如何评估大模型的好坏
现有的LLMs评估框架有哪些?
评估大语言模型来确定它们在各种应用中的质量和实用性是比较重要的。市面上已经存在多个评估LLMs的框架,但是没有一个框架足够全面,可以覆盖所有自然语言处理任务。让我们看一下这些现有的主流评估框架。
| 框架名称 | 评估时考虑的因素 | 框架链接 |
|---|---|---|
| Big Bench | 泛化能力 | https://github.com/google/BIG-bench |
| GLUE Benchmark | 语法、释义、文本相似度、推理、文本关联性、解决代词引用问题的能力 | https://gluebenchmark.com/ |
| SuperGLUE Benchmark | 自然语言理解、推理,理解训练数据之外的复杂句子,连贯和规范的自然语言生成,与人对话,常识推理(日常场景、社会规范和惯例),信息检索,阅读理解 | https://super.gluebenchmark.com/ |
| OpenAI Moderation API | 过滤有害或不安全的内容 | https://platform.openai.com/docs/api-reference/moderations |
| MMLU | 跨各种任务和领域的语言理解 | https://github.com/hendrycks/test |
| EleutherAI LM Eval | 在最小程度的微调情况下,使用小样本进行评估,并能够在多种任务发挥性能的能力。 | https://github.com/EleutherAI/lm-evaluation-harness |
| OpenAI Evals | https://github.com/EleutherAI/lm-evaluation-harness 文本生成的准确性,多样性,一致性,鲁棒性,可转移性,效率,公平性 | https://github.com/openai/evals |
| Adversarial NLI (ANLI) | 鲁棒性,泛化性,对推理的连贯性解释,在类似示例中推理的一致性,资源使用方面的效率(内存使用、推理时间和训练时间) | https://github.com/facebookresearch/anli |
| LIT (Language Interpretability Tool) | 以用户定义的指标进行评估的平台。了解其优势、劣势和潜在的偏见 | https://pair-code.github.io/lit/ |
| ParlAI | 准确率,F1分数,困惑度(模型在预测序列中下一个单词的表现),按相关性,流畅性和连贯性等标准进行人工评估,速度和资源利用率,鲁棒性(评估模型在不同条件下的表现,如噪声输入、对抗攻击或不同水平的数据质量),泛化性 | https://github.com/facebookresearch/ParlAI |
| CoQA | 理解文本段落并回答出现在对话中的一系列相互关联的问题。 | https://stanfordnlp.github.io/coqa/ |
| LAMBADA | 预测一段文本的最后一个词。 | https://zenodo.org/record/2630551#.ZFUKS-zML0p |
| HellaSwag | 推理能力 | https://rowanzellers.com/hellaswag/ |
| LogiQA | 逻辑推理能力 | https://github.com/lgw863/LogiQA-dataset |
| MultiNLI | 了解不同体裁的句子之间的关系 | https://cims.nyu.edu/~sbowman/multinli/ |
| SQUAD | 阅读理解任务 | https://rajpurkar.github.io/SQuAD-explorer/ |
在评估LLMs时应考虑哪些因素?
经过审查现有的大模型评估框架存在的问题之后,下一步是确定在评估大型语言模型(LLMs)的质量时应考虑哪些因素。我们听取12名数据科学专业人员的意见,这12名专家对LLMs的工作原理和工作能力有一定的了解,并且他们曾经尝试过测试多个LLMs。该调查旨在根据他们的理解列出所有重要因素,并在此基础之上评估LLMs的质量。
最终,我们发现有几个关键因素应该被考虑:
1. 真实性
LLMs生成的结果准确性至关重要。包括事实的正确性以及推理和解决方案的准确性。
2. 速度
模型产生结果的速度很重要,特别是当大模型需要部署到关键功能(critical use cases)时。虽然在某些情况下速度较慢的大模型可能可以可接受,但这些rapid action团队需要速度更快的模型。
3. 正确的语法和可读性
LLMs必须以具备可读性的格式生成自然语言。确保正确、合适的语法和句子结构至关重要。
4. 没有偏见
LLMs必须不受与性别、种族和其他因素相关的社会偏见影响。
5. 回溯回答的参考来源
了解模型回答的来源对于我们来说是十分必要的,以便我们可以重复检查其 basis。如果没有这个,LLMs的性能将始终是一个黑匣子。
6. 安全和责任
AI模型的安全保障是必要的。尽管大多数公司正在努力使这些大模型安全,但仍然有显着的改进空间。
7. 理解上下文
当人类向AI聊天机器人咨询有关个人生活的建议时,重要的是该模型需要基于特定的条件提供更好的解决方案。在不同的上下文中提出同样的问题可能会有不同的答案。
8. 文本操作
LLMs需要能够执行基本的文本操作,如文本分类、翻译、摘要等。
9. 智商
智商是用来评判人类智力的一项指标,也可以应用于机器。
10. 情商
情商是人类智力的另一方面,也可应用于LLMs。具有更高情商的模型将更安全地被使用。
11. 具备多功能
模型可以涵盖的领域和语言数量是另一个重要因素,可以用于将模型分类为通用AI或特定领域的AI。
12. 实时更新
一个能够实时进行信息更新的模型可以做出更大范围的贡献,产生更好的结果。
13. 成本
开发和运维成本也应该考虑在内。
14. 一致性
相同或类似的提示应该产生相同或几乎相同的响应,否则确保部署于商业环境的质量将会很困难。
15. 提示工程的需要程度
需要使用多少详细和结构化的提示工程才能获得最佳响应,也可以用来比较两个模型。
免责声明:NLP工作站和DevOps,部分图文来源于互联网及公众平台,内容仅供各位学习参考,版权归原作者所有,如有侵犯版权请告知,我们将及时删除!