【多线程-从零开始-捌】阻塞队列,消费者生产者模型
什么是阻塞队列
阻塞队里是在普通的队列(先进先出队列)基础上,做出了扩充
- 线程安全
- 标准库中原有的队列 Queue 和其子类,默认都是线程不安全的
- 具有阻塞特性
- 如果队列为空,进行出队列操作,此时就会出现阻塞。一直阻塞到其他线程往队列里添加元素为止
- 如果队列满了,进行入队列操作,此时就会出现阻塞。一直阻塞到其他线程从队列里取走元素为止
基于阻塞队列,最大的应用场景,就是实现“生产者消费者模型”(日常开发中,常见的编程手法)
生产者消费者模型
比如:
小猪佩奇一家准备包饺子,成员有佩奇,猪爸爸和猪妈妈,外加一个桌子
- 佩奇负责擀面皮
- 猪爸爸和猪妈妈负责包饺子
- 桌子用来放你擀好的面皮
每次佩奇擀好一个面皮后,就放在桌子上,猪爸爸和猪妈妈就用这个面皮包出一个饺子
此时:
- 佩奇就是面皮的生产者——生产者
- 猪爸爸和猪妈妈就是面皮的消费者——消费者
- 桌子就是阻塞队列——阻塞队列
为什么是是阻塞队列而不是普通队列?
因为阻塞队列可以很好的协调生产者和消费者
- 若佩奇擀面皮很快,不一会桌子上就满了
- 阻塞队列:佩奇就休息一下,等面皮被消耗一些之后继续再擀
- 普通队列:不会停,放不下了也一直擀
- 若猪爸爸和猪妈妈包的很快,不一会桌子上就空了
- 阻塞队列:猪爸爸和猪妈妈休息一下,等到面皮擀出来之后再包
- 普通队列:不会停,没面皮了也一直包
好处
上述生产者消费者模型在后端开发中,经常会涉及到
当下后端开发,常见的结构——“分布式系统”,不是一台服务器解决所有问题,而是分成了多个服务器,服务器之间相互调用
主要有两方面的好处
1. 服务器之间解耦合
我们希望见到“低耦合”
- 模块之间的关联程度/影响程度
通常谈到的“阻塞队列”是代码中的一个数据结构
但是由于这个东西太好用了,以至于会把这样的数据结构单独封装成一个服务器程序,并且在单独的服务器机器上进行部署
此时,这样的饿阻塞队列有了一个新的名字,“消息队列”(Message Queue,MQ)
如果是直接调用: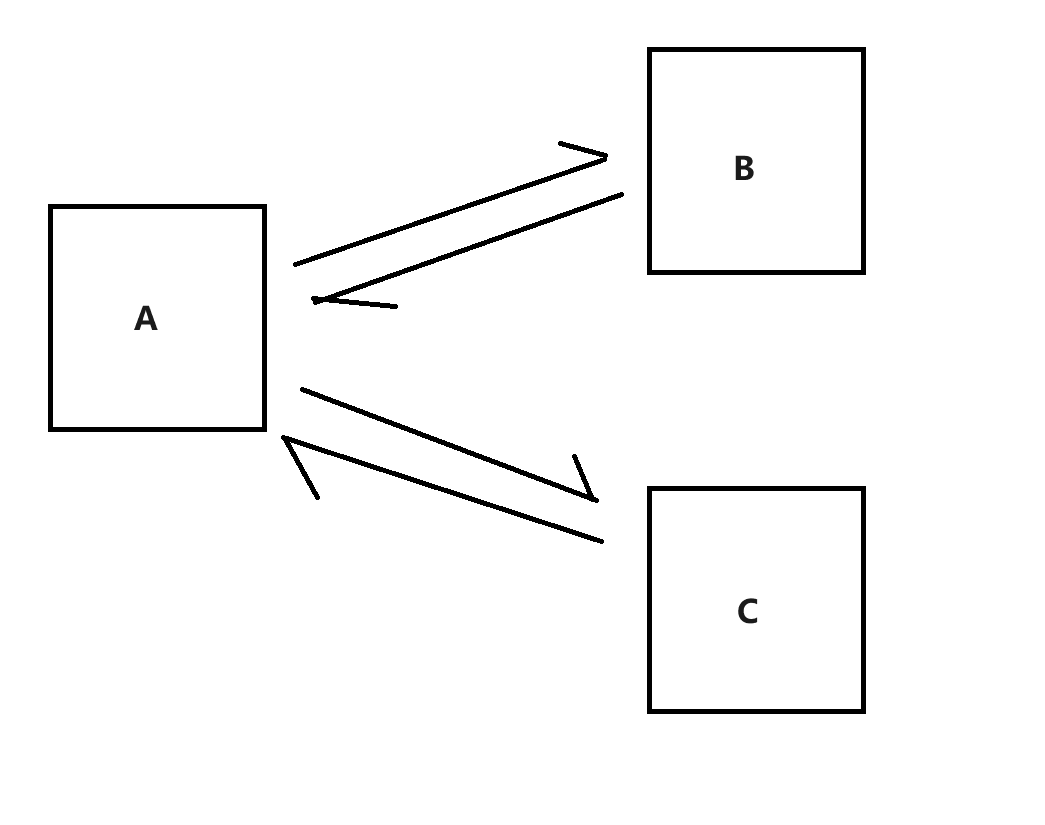
- 编写 A 和 B 代码中,会出现很多对方服务器相关的代码
- 并且,此时如果 B 服务器挂了,A 可能也会直接受到影响
- 再并且,如果后续想加入一个 C 服务器,此时对 A 的改动就很大
如果是通过阻塞队列:
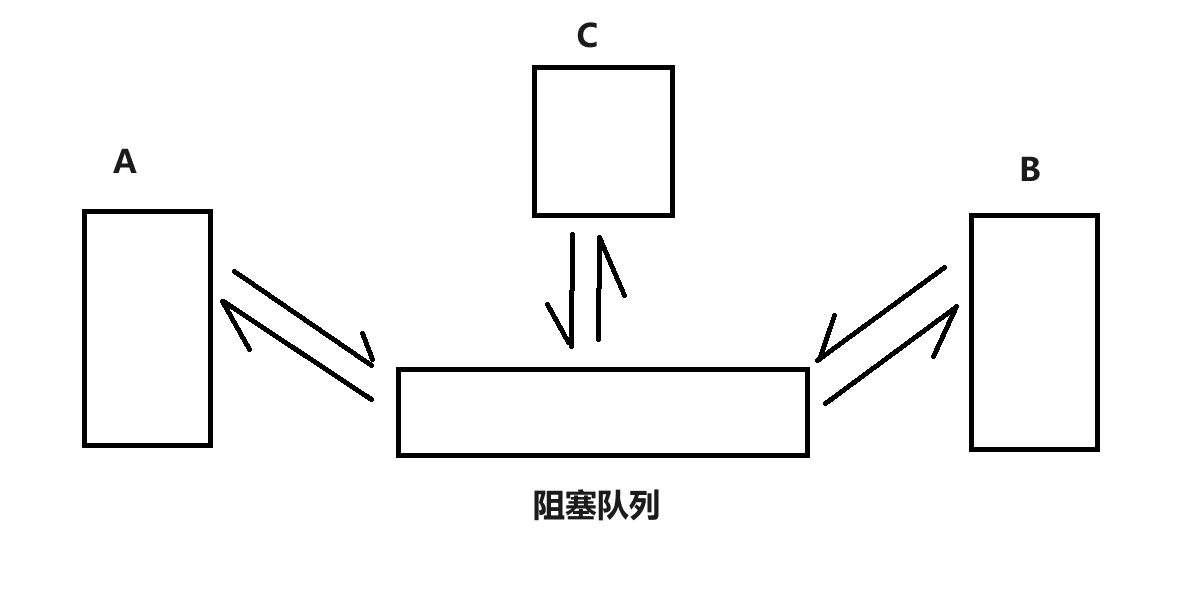
- A 之和队列通信
- B 也只和队列通信
- A 和 B 互相不知道对方的存在,代码中就更没有对方的影子
看起来,A 和 B 之间是解耦合了,但是 A 和队列,B 和队列之间,不是引入了新的耦合吗?- 耦合的代码,在后续的变更工程中,比较复杂,容易产生 bug
- 但消息队列是成熟稳定的产品,代码是稳定的,不会频繁更改。A、B 和队列之间的耦合,对我们的影响微乎其微
- 再增加 C 服务器也很方便,也不会影响到原有的 A 和 B 服务器
2. “削峰填谷”的效果
通过中间的阻塞队列,可以起到削峰填谷的效果,在遇到请求量激增突发的情况下,可以有效保护下游服务器,不会被请求冲垮
阻塞队列的作用就相当与三峡大坝在三峡的防汛作用
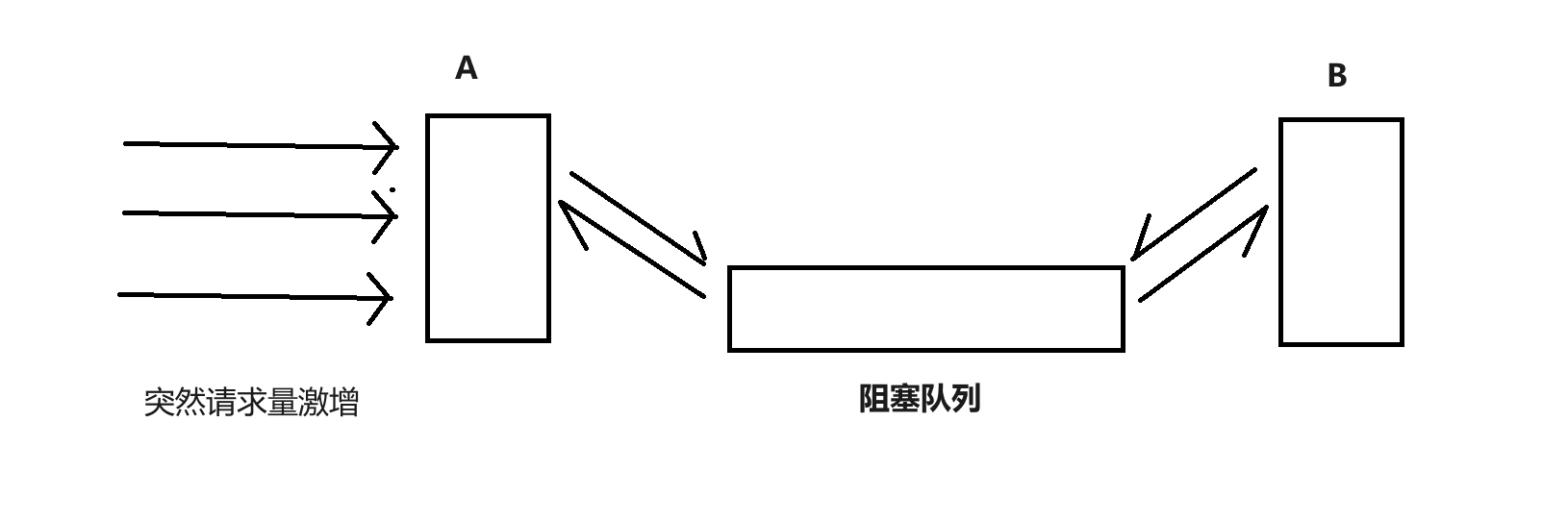
- A 向队列中写入数据变快了,但是 B 仍然可以按照原有的速度来消费数据
- 阻塞队列扛下了这样的压力,就像三峡大坝抗住上游的大量水量的压力
- 如果是直接调用,A 收到多少请求,B 也收到多少,那很可能直接就把 B 给搞挂了
- 当 A 不再写入数据的时候,但队列中还存有数据,可以继续工给 B
问题
- 为啥一个服务器,收到的请求变多,就容易挂?
- 一台服务器,就是一台“电脑”,上面就提供了一些硬件资源(包括但不限于 CPU,内存,硬盘,网络带宽…)
- 就算你这个及其配置再好,硬件资源也是有限的
- 服务器每次收到一个请求,处理这个请求的过程,就都需要执行一系列的代码,在执行这些代码的过程中,就需要消耗一定的硬件资源(CPU,内存,硬盘,网络带宽…)
- 这些请求小号的总的硬件资源的量,超过了及其能提供的上限,那么此时机器就会出现(卡死,程序直接崩溃等…)
- 在请求激增的时候,A 为啥不会挂?队列为啥不会挂?反而是 B 更容易挂呢?
- A 的角色是一个“网关服务器”,收到客户端的请求,再把请求转发给其他的服务器
- 这样的服务器里的代码,做的工作比较简单(单纯的数据转发),消耗的硬件资源通常更少
- 处理一个请求,消耗的资源更少,同样的配置下,就能支持更多的请求处理
- 同理,队列其实也是比较简单的程序,单位请求消耗的硬件资源,也是比较少见的
- B 这个服务器,是真正干活的服务器,要真正完成一系列的业务逻辑
- 这一系列的工作,代码量非常庞大,消耗的时间很多,消耗的系统硬件资源,也是更多的
类似的,像 MySQL 这样的数据库,处理每个请求的时候,做的工作就是比较多的,消耗的硬件资源也是比较多的,因此 MySQL 也是后端系统中,容易挂的部分
对应的,像 Redis 这种内存数据库,处理请求,做的工作远远少于 MySQL,消耗的资源更少,Redis 就比 MySQL 硬朗很多,不容易挂
代价
- 需要更多的机器来部署这样的消息队列(小代价)
- A 和 B 之间的通信延迟会变长
- 对于 A 和 B 之间的调用,要求响应时间比较短就不太适合了
每个技术都有优缺点,不能无脑吹,也不能无脑黑
比如:微服务
- 本质上就是把分布式系统服务拆的更细了,每个服务都很小,只做一项功能
- 非常适合大公司,部门分的很细
- 但需要更多的机器,处理请求需要更多的响应时间,更复杂的后端结构,运维成本水涨船高
Java 自带的阻塞队列
阻塞队列在 Java 标准库中也提供了现成的封装——BlockingQueue
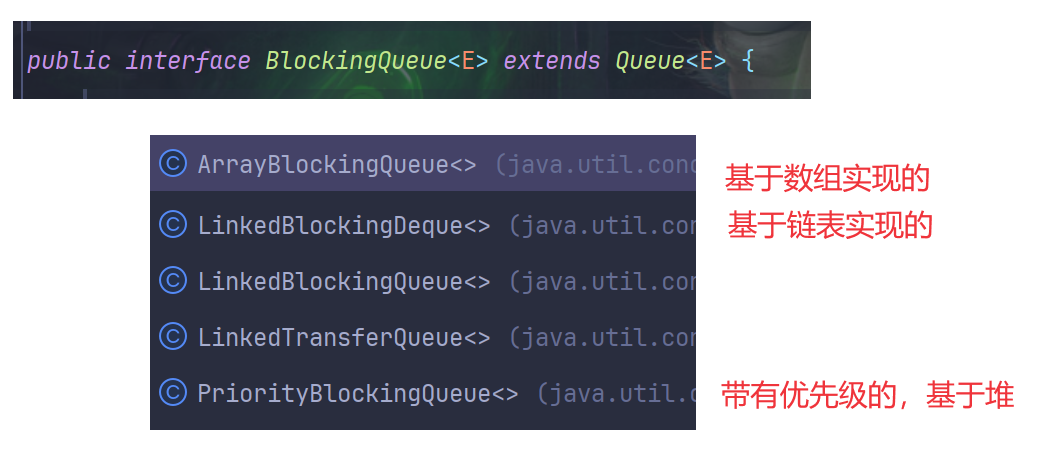
BlockingQueue本质上是一个接口,不能直接new,只能new一个类- 因为是继承与
Queue,所以Queue的一些操作,offer、poll这些,在BlockingQueue中同样可以使用(不过不建议使用,因为都不能阻塞)BlockingQueue提供了另外两个专属方法,都能阻塞
put——入列take——出队列
BlockingQueue<String> queue = new ArrayBlockingQueue<>(1000);
capacity 指的是容量,是一个需要加上的参数
public class Demo10 { public static void main(String[] args) throws InterruptedException { BlockingQueue<String> queue = new ArrayBlockingQueue<>(3); queue.put("111"); System.out.println("put成功"); queue.put("111"); System.out.println("put成功"); }
}
//运行结果
put成功
put成功
put成功
- 只打印了三个,说明第四次 put 的时候容量不够,阻塞了
public class Demo10 { public static void main(String[] args) throws InterruptedException { BlockingQueue<String> queue = new ArrayBlockingQueue<>(3); queue.put("111"); System.out.println("put 成功"); queue.put("111"); System.out.println("put 成功"); queue.take(); System.out.println("take 成功"); queue.take(); System.out.println("take 成功"); queue.take(); System.out.println("take 成功"); }
}
//运行结果
put 成功
put 成功
take 成功
take 成功
- 由于只有
put了两次,所以也只有两次take,随后阻塞住了
public class Demo11 { public static void main(String[] args) { BlockingQueue<Integer> queue = new ArrayBlockingQueue<>(1000); Thread t1 = new Thread(() -> { int i = 1; while(true){ try { queue.put(i); System.out.println("生产者元素"+i); i++; Thread.sleep(1000); } catch (InterruptedException e) { throw new RuntimeException(e); } } }); Thread t2 = new Thread(() -> { while(true) { try { Integer i = queue.take(); System.out.println("消费者元素"+i); } catch (InterruptedException e) { throw new RuntimeException(e); } } }); t1.start(); t2.start(); }
}
- 上述程序中,一个线程生产,一个线程消费
- 实际开发中,通常可能是多个线程生产,多个线程消费
自己实现一个阻塞队列
普通队列
基于数组的队列
实现一个基础的队列
//此处不考虑泛型参数,只是基于 String 进行存储
class MyBlockingQueue { private String[] data = null; private int head = 0; private int tail = 0; private int size = 0; public MyBlockingQueue(int capacity) { data = new String[capacity]; } public void put(String s) { if(size == data.length) { //队列满了 return; } data[tail] = s; tail++; if(tail >= data.length){ tail = 0; } size++; } public String take() { if(size == 0) { //队列为空 return null; } String ret = data[head]; head++; if(head >= data.length){ head = 0; } size--; return ret; }
}
阻塞队列
- 队列为空,
take就要阻塞,在其他线程put的时候唤醒 - 队列未满,
put就要阻塞,在其他线程take的时候唤醒
//此处不考虑泛型参数,只是基于 String 进行存储
class MyBlockingQueue { private String[] data = null; private int head = 0; private int tail = 0; private int size = 0; private Object locker = new Object(); public MyBlockingQueue(int capacity) { data = new String[capacity]; } public void put(String s) throws InterruptedException { //加锁的对象,可以单独定义一个,也可以直接就地使用this synchronized (locker) { if (size == data.length) { //队列满了,需要阻塞 //return; locker.wait(); } data[tail] = s; tail++; if (tail >= data.length) { tail = 0; } size++; //唤醒 take 的阻塞 locker.notify(); } } public String take() throws InterruptedException { String ret = ""; synchronized (locker) { if (size == 0) { //队列为空,需要阻塞 //return null; locker.wait(); } ret = data[head]; head++; if (head >= data.length) { head = 0; } size--; //唤醒 put 的阻塞 locker.notify(); } return ret; }
}