k8s教程
1. k8s框架
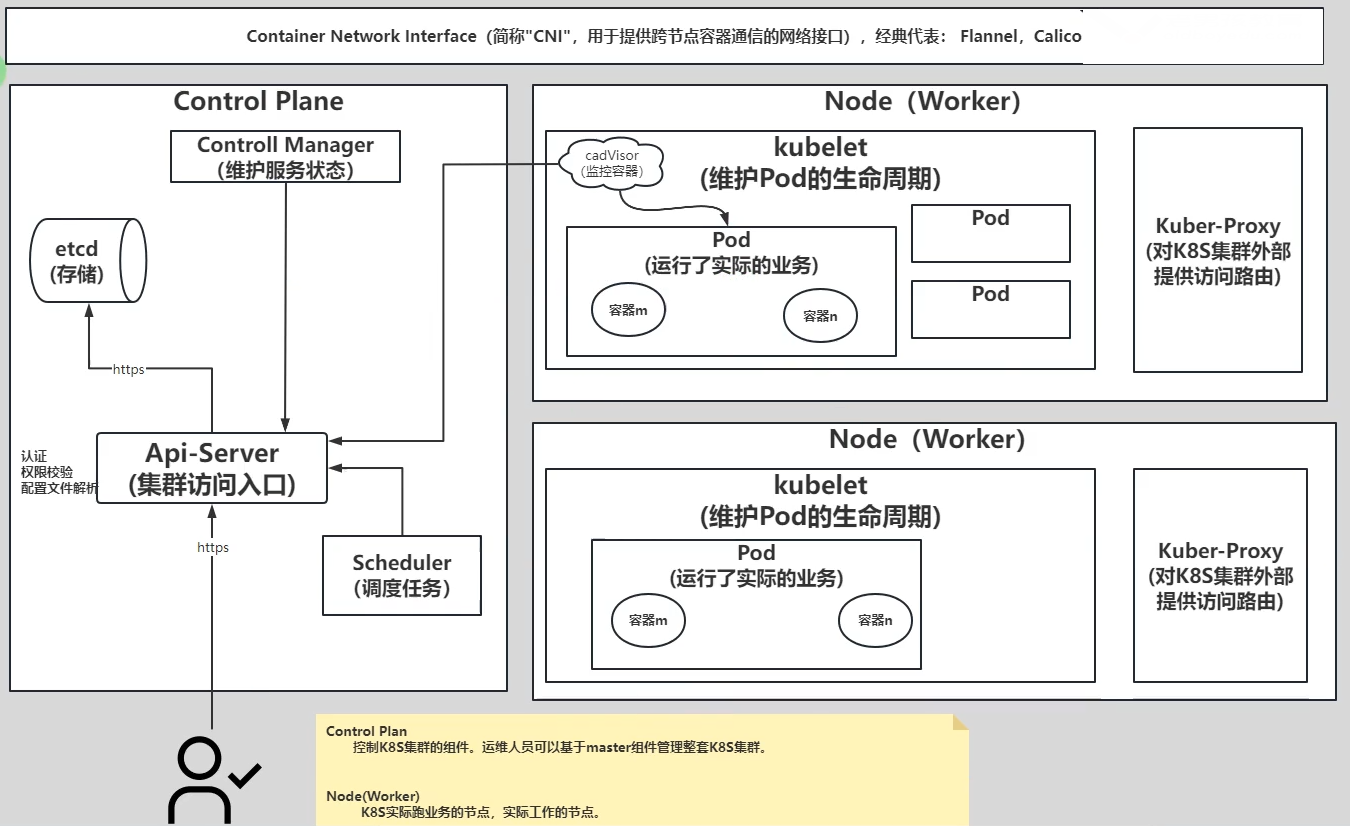
- kubernetes的架构- Control Plane: 控制K8S集群的组件。- Api Server: 集群的访问入口。- etcd: 存储集群的数据。一般情况下,只有API-SERVER会访问.- Control Manager: 维护集群的状态。- Scheduler: 负责Pod的调度功能。- Worker Node: 实际运行业务的组件。- kubelet: 管理Pod的生命周期,并上报Pod和节点的状态。- kube-proxy: 对K8S集群外部提供访问路由。底层可以基于iptables或者ipvs实现。- Kubernetes的常见术语- CNI:Container Network Interface容器网络插件,主要用于跨节点的容器进行通信的组件。- CRI: Container Runtime Interface容器运行接口,主要用于kubelet调用容器的生命周期管理相关即可。docker-shim ---> cri-dockerd,在K8S 1.24已经弃用!若更高版本想要使用docker,需要单独部署docker-shim组件即可。2. kubernetes集群部署方式介绍
kubernetes集群部署方式:
目前生产环境部署kubernetes集群主要由两种方式:- kubeadm:kubeadm是一个K8S部署工具,提供kubeadm init和kubejoin,用于快速部署kubernetes集群。你可以使用kubeadm工具来创建和管理Kubernetes集群,适合在生产环境部署。该工具能够执行必要的动作并用一种用户友好的方式启动一个可用的、安全的集群。推荐阅读:https://kubernetes.io/zh/docs/setup/production-environment/tools/kubeadm/https://kubernetes.io/zh/docs/setup/production-environment/tools/kubeadm/install-kubeadm/https://kubernetes.io/zh/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/- 二进制部署:从GitHub下载发行版的二进制包,手动部署每个组件,组成kubernetes集群。除了上述介绍的两种方式部署外,还有其他部署方式的途径:- yum: 已废弃,目前支持的最新版本为2017年发行的1.5.2版本。- kind安装:kind让你能够在本地计算机上运行Kubernetes。 kind要求你安装并配置好Docker。推荐阅读:https://kind.sigs.k8s.io/docs/user/quick-start/- minikube:适合开发环境,能够快速在Windows或者Linux构建K8S集群。参考链接:https://minikube.sigs.k8s.io/docs/- rancher:基于K8S改进发行了轻量级K8S,让K3S孕育而生。参考链接:https://www.rancher.com/- KubeSphere:青云科技基于开源KubeSphere快速部署K8S集群。参考链接:https://kubesphere.com.cn- kuboard:也是对k8s进行二次开发的产品,新增了很多独有的功能。参考链接: https://kuboard.cn/- kubeasz:使用ansible部署,扩容,缩容kubernetes集群,安装步骤官方文档已经非常详细了。参考链接: https://github.com/easzlab/kubeasz/- 第三方云厂商:比如aws,阿里云,腾讯云,京东云等云厂商均有K8S的相关SAAS产品。- 更多的第三方部署工具:参考链接:https://landscape.cncf.io/3. harbor服务器准备(方便快速拉取镜像)
--------------------harbor(81) 准备docker-ce,docker-compose----------------
#1.安装相关依赖.
yum install -y yum-utils device-mapper-persistent-data lvm2
#2.下载官方的docker yum源文件
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
#3.替换yum源地址
sed -i 's+download.docker.com+mirrors.aliyun.com/docker-ce+' /etc/yum.repos.d/docker-ce.repo
#4.安装docker-ce
yum makecache fast
yum -y install docker-ce docker-compose
systemctl enable --now docker
#检查
docker versionsystemctl disable --now firewalld
sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config #开启镜像下载加速
mkdir -p /etc/docker
cat > /etc/docker/daemon.json <<EOF
{"exec-opts": ["native.cgroupdriver=systemd"],"registry-mirrors": ["https://docker.1panel.live"]
}
EOF
systemctl daemon-reload
systemctl restart docker--------------------harbor(81) 下载harbor包,安装----------------
harbor]# mkdir -p /app/tools/
harbor]# cd /app/tools/
harbor]# wget https://github.com/goharbor/harbor/releases/download/v2.11.0/harbor-offline-installer-v2.11.0.tgz
harbor]# tar -xvf harbor-offline-installer-v2.11.0.tgz
harbor]# cd harbor
harbor]# tree .
.
├── common.sh
├── harbor.v2.11.0.tar.gz
├── harbor.yml.tmpl #临时配置文件 正式配置文件叫harbor.yml
├── install.sh #每次修改配置 需要执行下
├── LICENSE
└── prepareharbor]# cp harbor.yml.tmpl harbor.yml
harbor]# vim harbor.yml
#修改域名
hostname: harbor.tom.cn#修改登录密码
harbor_admin_password: admin--------------------harbor(81) 证书配置--------------------------------
(1)创建证书的工作目录
[root@harbor ~]# mkdir -pv /app/tools/harbor/certs/{ca,server,client}(2)生成自建CA证书#2.1 进入证书目录
[root@harbor ~]# cd /app/tools/harbor/certs/#2.2 生成CA私钥
[root@harbor certs]# openssl genrsa -out ca/ca.key 4096#2.3 生成ca的自签名证书
[root@harbor certs]# openssl req -x509 -new -nodes -sha512 -days 3650 \-subj "/C=CN/O=example/CN=tom.com" \-key ca/ca.key \-out ca/ca.crt(3)生成harbor服务器的证书及客户端证书#3.1 生成harbor主机的私钥
[root@harbor certs]# openssl genrsa -out server/harbor.key 4096#3.2 生成harbor主机的证书申请
[root@harbor certs]# openssl req -sha512 -new \-subj "/C=CN/CN=tom.com" \-key server/harbor.key \-out server/harbor.csr #3.3 生成x509 v3扩展文件
[root@harbor certs]# cat > v3.ext <<-EOF
authorityKeyIdentifier=keyid,issuer
basicConstraints=CA:FALSE
keyUsage = digitalSignature, nonRepudiation, keyEncipherment, dataEncipherment
extendedKeyUsage = serverAuth
subjectAltName = @alt_names[alt_names]
DNS.1=tom.com
DNS.2=harbor.tom.com
DNS.3=harbor.tom.com
EOF#3.4 使用"v3.ext"给harbor主机签发证书
[root@harbor certs]# openssl x509 -req -sha512 -days 3650 \-extfile v3.ext \-CA ca/ca.crt -CAkey ca/ca.key -CAcreateserial \-in server/harbor.csr \-out server/harbor.crt #3.5 将crt文件转换为cert客户端证书文件
[root@harbor certs]# openssl x509 -inform PEM -in server/harbor.crt -out server/harbor.cert#3.6 准备docker客户端证书
[root@harbor certs]# cp server/harbor.{cert,key} client/
[root@harbor certs]# cp ca/ca.crt client/
[root@harbor certs]# ll client/
-rw-r--r-- 1 root root 2033 Apr 12 10:09 ca.crt
-rw-r--r-- 1 root root 2122 Apr 12 10:09 harbor.cert
-rw-r--r-- 1 root root 3247 Apr 12 10:09 harbor.key#3.7 查看所有证书文件结果
[root@harbor certs]# tree
.
├── ca
│ ├── ca.crt
│ ├── ca.key
│ └── ca.srl
├── client
│ ├── ca.crt
│ ├── harbor.cert
│ └── harbor.key
├── server
│ ├── harbor.cert
│ ├── harbor.crt
│ ├── harbor.csr
│ └── harbor.key
└── v3.ext(4)配置harbor服务器使用证书4.1 切换工作目录
[root@harbor certs]# cd /app/tools/harbor/4.2 修改配置文件
[root@harbor harbor]# vim harbor.yml
...
hostname: harbor.tom.com
https:port: 443certificate: /app/tools/harbor/certs/server/harbor.crtprivate_key: /app/tools/harbor/certs/server/harbor.keyharbor_admin_password: Admin
...
--------------------harbor(81) 安装--------------------------------
./install.sh
#注意要检查80是否被占用
提示successfully
? ----Harbor has been installed and started
successfully.----
成功
需要安装docker和docker-compose
4. K8S服务器需求
三台服务器: k8s节点:10.0.0.231-233,3G/2C/30G
5. k8s v1.23安装(基于kubeadm)
- kubeadm: 快速构建K8S集群,需要单独安装docker,kubectl,kubeadm,kubelet。
本文介绍2个版本的k8s的安装,v1.23,v1.26
5.1. k8s所有节点环境准备
- K8S所有节点环境准备(1)虚拟机操作系统环境准备
参考链接:https://kubernetes.io/zh/docs/setup/production-environment/tools/kubeadm/install-kubeadm/(2)系统配置2.1 临时关闭
swapoff -a && sysctl -w vm.swappiness=02.2 基于配置文件关闭
sed -ri '/^[^#]*swap/s@^@#@' /etc/fstab2.3 启用IPv4转发echo "net.ipv4.ip_forward=1" >> /etc/sysctl.confsysctl -p(3)确保各个节点MAC地址或product_uuid唯一
ifconfig eth0 | grep ether | awk '{print $2}'
cat /sys/class/dmi/id/product_uuid 温馨提示:一般来讲,硬件设备会拥有唯一的地址,但是有些虚拟机的地址可能会重复。 Kubernetes使用这些值来唯一确定集群中的节点。 如果这些值在每个节点上不唯一,可能会导致安装失败。(4)检查网络节点是否互通
简而言之,就是检查你的k8s集群各节点是否互通,可以使用ping命令来测试。(5)允许iptable检查桥接流量
cat <<EOF | tee /etc/modules-load.d/k8s.conf
br_netfilter
EOFcat <<EOF | tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system(6)检查端口是否被占用
参考链接: https://kubernetes.io/zh/docs/reference/ports-and-protocols/(7)检查docker的环境
参考链接: https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/CHANGELOG-1.15.md#unchanged7.1 配置docker源
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
curl -o /etc/yum.repos.d/docker-ce.repo https://download.docker.com/linux/centos/docker-ce.repo
sed -i 's+download.docker.com+mirrors.tuna.tsinghua.edu.cn/docker-ce+' /etc/yum.repos.d/docker-ce.repo
yum list docker-ce --showduplicates7.2 安装指定的docker版本
yum -y install docker-ce-20.10.24 docker-ce-cli-20.10.24
yum -y install bash-completion
source /usr/share/bash-completion/bash_completion7.3 配置docker优化
cat > /etc/docker/daemon.json <<EOF
{"exec-opts": ["native.cgroupdriver=systemd"],"registry-mirrors": ["https://docker.1panel.live"]
}
EOF
7.4 将harbor服务器的客户端证书拷贝到k8s集群 *****7.4.1 k8s所有节点创建自建证书目录
mkdir -pv /etc/docker/certs.d/harbor.tom.com7.4.2 登录harbor服务器将自建证书拷贝到K8S集群的所有节点
[root@harbor ~]# scp /app/tools/harbor/certs/client/* root@10.0.0.231:/etc/docker/certs.d/harbor.tom.com
[root@harbor ~]# scp /app/tools/harbor/certs/client/* root@10.0.0.232:/etc/docker/certs.d/harbor.tom.com
[root@harbor ~]# scp /app/tools/harbor/certs/client/* root@10.0.0.233:/etc/docker/certs.d/harbor.tom.com7.5 配置docker开机自启动
systemctl enable --now docker
systemctl status docker(8)禁用防火墙
systemctl disable --now firewalld(9)禁用selinux
sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config
grep ^SELINUX= /etc/selinux/config(10)配置host解析
cat >> /etc/hosts <<'EOF'
10.0.0.231 k8s231.tom.com
10.0.0.232 k8s232.tom.com
10.0.0.233 k8s233.tom.com
10.0.0.81 harbor.tom.com
EOF
cat /etc/hosts(11)验证是否能够登录harbor仓库
[root@k8s231 ~]# docker login -u admin -padmin harbor.tom.com
5.2. k8s所有节点安装kubeadm,kubelet,kubectl
- 所有节点安装kubeadm,kubelet,kubectl(1)配置软件源
cat > /etc/yum.repos.d/kubernetes.repo <<EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
repo_gpgcheck=0
EOF(2)查看kubeadm的版本(将来你要安装的K8S时请所有组件版本均保持一致!)
yum -y list kubeadm --showduplicates | sort -r(3)安装kubeadm,kubelet,kubectl软件包
yum -y install kubeadm-1.23.17-0 kubelet-1.23.17-0 kubectl-1.23.17-0(4)启动kubelet服务(若服务启动失败时正常现象,其会自动重启,因为缺失配置文件,初始化集群后恢复!此步骤可跳过!)
systemctl enable --now kubelet
systemctl status kubelet(5)添加kubectl的自动补全功能
echo "source <(kubectl completion bash)" >> ~/.bashrc && source ~/.bashrc
参考链接: https://kubernetes.io/zh/docs/tasks/tools/install-kubectl-linux/5.3. master节点(k8s231)-集群初始化control plane
- 初始化control plan节点(k8s231)(1)使用kubeadm初始化master节点
[root@k8s231 ~]# kubeadm init --kubernetes-version=v1.23.17 \
--image-repository registry.aliyuncs.com/google_containers \
--service-cidr=10.100.0.0/16 \
--pod-network-cidr=10.200.0.0/16 \
--service-dns-domain=tom.com相关参数说明:--kubernetes-version:指定K8S master组件的版本号。--image-repository:指定下载k8s master组件的镜像仓库地址。--pod-network-cidr:指定Pod的网段地址。--service-cidr:指定SVC的网段--service-dns-domain:指定service的域名。若不指定,默认为"cluster.local"。使用kubeadm初始化集群时,可能会出现如下的输出信息:
[init] 使用初始化的K8S版本。[preflight] 主要是做安装K8S集群的前置工作,比如下载镜像,这个时间取决于你的网速。[certs] 生成证书文件,默认存储在"/etc/kubernetes/pki"目录哟。[kubeconfig]生成K8S集群的默认配置文件,默认存储在"/etc/kubernetes"目录哟。[kubelet-start] 启动kubelet,环境变量默认写入:"/var/lib/kubelet/kubeadm-flags.env"配置文件默认写入:"/var/lib/kubelet/config.yaml"[control-plane]使用静态的目录,默认的资源清单存放在:"/etc/kubernetes/manifests"。此过程会创建静态Pod,包括"kube-apiserver","kube-controller-manager"和"kube-scheduler"[etcd] 创建etcd的静态Pod,默认的资源清单存放在:""/etc/kubernetes/manifests"[wait-control-plane] 等待kubelet从资源清单目录"/etc/kubernetes/manifests"启动静态Pod。[apiclient]等待所有的master组件正常运行。[upload-config] 创建名为"kubeadm-config"的ConfigMap在"kube-system"名称空间中。[kubelet] 创建名为"kubelet-config-1.22"的ConfigMap在"kube-system"名称空间中,其中包含集群中kubelet的配置[upload-certs] 跳过此节点,详情请参考”--upload-certs"[mark-control-plane]标记控制面板,包括打标签和污点,目的是为了标记master节点。[bootstrap-token] 创建token口令,例如:"kbkgsa.fc97518diw8bdqid"。如下图所示,这个口令将来在加入集群节点时很有用,而且对于RBAC控制也很有用处哟。[kubelet-finalize] 更新kubelet的证书文件信息[addons] 添加附加组件,例如:"CoreDNS"和"kube-proxy”(2)拷贝授权文件,用于管理K8S集群
[root@k8s231 ~]# mkdir -p $HOME/.kube
[root@k8s231 ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@k8s231 ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config (3)查看集群节点
[root@k8s231 ~]# kubectl get componentstatuses
[root@k8s231 ~]# kubectl get cs5.4. worker节点(k8s232,k8s233)加入集群
- 配置所有worker节点加入k8s集群(1)所有节点加入K8S集群(命令来自主节点初始化结果最后一行,需要复制新生成的)
[root@k8s232 ~]# kubeadm join 10.0.0.231:6443 --token yd1dlg.yxadkryuok54wafx \
--discovery-token-ca-cert-hash sha256:0126bdf649181b08b57e12ecfb3310ba570368ac51bcf5062b9391d279059c77[root@k8s233 ~]# kubeadm join 10.0.0.231:6443 --token yd1dlg.yxadkryuok54wafx \
--discovery-token-ca-cert-hash sha256:0126bdf649181b08b57e12ecfb3310ba570368ac51bcf5062b9391d279059c77(2)查看现有的节点
[root@k8s231 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s231.tom.com NotReady control-plane,master 4m24s v1.23.17
k8s232.tom.com NotReady <none> 2m52s v1.23.17
k8s233.tom.com NotReady <none> 37s v1.23.175.5. master节点(k8s231)安装CNI网络插件flannel
- 安装网络插件并验证连通性(1)下载flannel的资源清单
[root@k8s231 ~]# wget https://github.com/flannel-io/flannel/releases/latest/download/kube-flannel.yml(2)安装flanne(podCIDR如果不是10.244.0.0/16,需要修改配置文件)
[root@k8s231 ~]# grep "\bNetwork" kube-flannel.yml"Network": "10.200.0.0/16",
[root@k8s231 ~]# kubectl apply -f kube-flannel.yml (3)检查flannel组件是否正常,均处于"Running"状态!
[root@k8s231 ~]# kubectl get pods -A -o wide| grep kube-flannel
kube-flannel kube-flannel-ds-c94t8 1/1 Running 0 16s 10.0.0.233 k8s233.tom.com <none> <none>
kube-flannel kube-flannel-ds-kzxs7 1/1 Running 0 16s 10.0.0.231 k8s231.tom.com <none> <none>
kube-flannel kube-flannel-ds-zjbhz 1/1 Running 0 16s 10.0.0.232 k8s232.tom.com <none> <none>---------------编写ds资源清单,测试跨节点Pod之间的通信------------
(4)编写ds资源清单
[root@k8s231 ~]# cat > test-ds.yaml <<EOF
kind: DaemonSet
apiVersion: apps/v1
metadata:name: test-ds
spec:selector:matchLabels:class: testtemplate:metadata:labels:class: testspec:containers:- image: alpinestdin: truename: c1
EOF(5)创建ds资源
[root@k8s231 ~]# kubectl apply -f test-ds.yaml
daemonset.apps/test-ds created[root@k8s231 ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
test-ds-6l8dc 1/1 Running 0 20s 10.200.1.2 k8s232.tom.com <none> <none>
test-ds-vlbtf 1/1 Running 0 20s 10.200.2.2 k8s233.tom.com <none> <none>(6)测试跨节点Pod之间的通信
[root@k8s231 ~]# kubectl exec test-ds-6l8dc -- ping -c 3 10.200.2.2
PING 10.200.2.2 (10.200.2.2): 56 data bytes
64 bytes from 10.200.2.2: seq=0 ttl=62 time=1.087 ms
64 bytes from 10.200.2.2: seq=1 ttl=62 time=0.762 ms
64 bytes from 10.200.2.2: seq=2 ttl=62 time=1.028 ms--- 10.200.2.2 ping statistics ---
3 packets transmitted, 3 packets received, 0% packet loss
round-trip min/avg/max = 0.762/0.959/1.087 ms(7)删除ds资源
[root@k8s231 ~]# kubectl delete -f test-ds.yaml
daemonset.apps "test-ds" deleted6. pod资源
6.1. 资源清单的创建,查看,删除,修改
K8S资源清单apiVersion:指的是Api的版本。kind:资源的类型。metadata:资源的元数据。比如资源的名称,标签,名称空间,注解等信息。spec:用户期望资源的运行状态。staus:资源实际的运行状态,由K8S集群内部维护。实战案例:
#获取pod书写用法指导
kubectl explain pod (1)创建工作目录
[root@k8s231 ~]# mkdir -pv /manifests/pods/ && cd /manifests/pods/(2)编写资源清单
[root@k8s231 pods]# cat > 01-nginx.yaml <<EOF
# 指定API的版本号
apiVersion: v1
# 指定资源的类型
kind: Pod
# 指定元数据
metadata:# 指定名称name: 01-nginx
# 用户期望的资源状态
spec:# 定义容器资源containers:# 指定的名称- name: nginx# 指定容器的镜像image: nginx:1.14.2
EOF(3)创建资源清单
[root@k8s231 pods]# kubectl create -f 01-nginx.yaml
pod/web created(4)查看资源
[root@k8s231 pods]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
01-web 1/1 Running 0 9s 10.200.1.3 k8s232.tom.com <none> <nonekubectl get pods -o wide相关字段说明:NAME 代表的是资源的名称。READY 代表资源是否就绪。比如 0/1 ,表示一个Pod内有一个容器,而且这个容器还未运行成功。STATUS 代表容器的运行状态。RESTARTS 代表Pod重启次数,即容器被创建的次数。AGE 代表Pod资源运行的时间。IP 代表Pod的IP地址。NODE 代表Pod被调度到哪个节点。其他: "NOMINATED NODE和"READINESS GATES"暂时先忽略哈。[root@k8s231 pods]# ]# curl -I 10.200.1.3
HTTP/1.1 200 OK
Server: nginx/1.14.2
Date: Sat, 03 Aug 2024 05:22:26 GMT
Content-Type: text/html
Content-Length: 612
Last-Modified: Tue, 04 Dec 2018 14:44:49 GMT
Connection: keep-alive
ETag: "5c0692e1-264"
Accept-Ranges: bytes (5)删除资源
[root@k8s231 pods]# kubectl delete -f 01-nginx.yaml
pod "web" deleted
-----------------------------------------------------------------------
K8S的Pod资源运行多个容器案例(1)编写资源清单
[root@k8s231 pods]# cat > 02-nginx-tomcat.yaml <<EOF
apiVersion: v1
kind: Pod
metadata:name: 02-nginx-tomcat
spec:containers:- name: nginximage: nginx:1.23.4-alpine- name: tomcatimage: tomcat:jre8-alpine
EOF(2)创建资源清单
[root@k8s231 pods]# kubectl create -f 02-nginx-tomcat.yaml(3)查看Pod状态
]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
02-nginx-tomcat 2/2 Running 0 65s 10.200.2.3 k8s233.tom.com <none> <none>#显示pod详细信息
[root@k8s231 pods]# kubectl describe pod 02-nginx-tomcat (4)删除Pod
[root@k8s231 pods]# kubectl delete pod 02-nginx-tomcat
pod "02-nginx-tomcat" deleted--------------------------------------------------------------------------
故障排查方法:1.加入一条命令hold住容器,然后连接容器,运行容器内服务看报错(1)资源清单
[root@k8s231 pods]# cat > 03-nginx-alpine.yaml <<EOF
apiVersion: v1
kind: Pod
metadata:name: 03-nginx-alpine
spec:# 使用宿主机网络,相当于"docker run --network host"hostNetwork: truecontainers:- name: nginximage: nginx:1.23.4-alpine- name: linuximage: alpine# 给容器分配一个标准输入,默认值为false# stdin: true# 给容器分配一个启动命令,修改Dockerfile的CMD指令# args: ["tail","-f","/etc/hosts"]# 也可以修改command字段,相当于修改Dockerfile的ENTRYPOINT指令# command: ["sleep","15"]# args也可以和command命令搭配使用,和Dockfile的ENTRYPOINT和CMD效果类似command:- "tail"args:- "-f"- "/etc/hosts"
EOF(2)创建Pod
[root@k8s231 pods]# kubectl apply -f 03-nginx-alpine.yaml
pod/nginx-alpine created----------------------------------
#把项目推送到私人harbor仓库,然后从私人仓库创建资源清单
(1)把项目推送到私人仓库
docker tag ilemonrain/h5ai:full harbor.tom.com/library/h5ai:v1
docker push harbor.tom.com/library/h5ai:v1(2)资源清单
[root@k8s231 pods]# cat > 04-h5ai.yaml <<EOF
apiVersion: v1
kind: Pod
metadata: name: 04-h5ai
spec:# 将Pod调度到指定节点,注意,该node名称必须和etcd的数据保持一致nodeName: k8s232.tom.comhostNetwork: truecontainers:- name: h5ai image: harbor.tom.com/library/h5ai:v1 volumeMounts:- name: my-volumemountPath: /h5aivolumes:- name: my-volumehostPath:path: /pantype: DirectoryOrCreate
EOF(3)创建Pod
[root@k8s231 pods]# kubectl apply -f 04-h5ai.yaml
[root@k8s231 pods]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
04-h5ai 1/1 Running 0 13s 10.0.0.232 k8s232.tom.com <none> <none>(4)访问测试windows访问10.0.0.232,可以看到文件清单6.2. 排查pod故障常用命令:
常用命令:(1)pod中容器和宿主机之间拷贝文件(cp)
[root@k8s231 pods]# kubectl get pods
NAME READY STATUS RESTARTS AGE
game-008 1/1 Running 0 4m15s
#将Pod的的文件拷贝到宿主机
[root@k8s231 pods]# kubectl cp game-008:/start.sh /tmp/1.sh
#将Pod的的目录拷贝到宿主机
[root@k8s231 pods]# kubectl cp game-008:/etc /tmp/2222#将宿主机的文件拷贝到Pod的容器中
[root@k8s231 pods]# kubectl cp 01-nginx.yaml game-008:/
#将宿主机的目录拷贝到Pod的容器中
[root@k8s231 pods]# kubectl cp /tmp/2222/ game-008:/(2)连接到Pod的容器(exec)
[root@k8s231 pods]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-tomcat 2/2 Running 0 63s#查看pod中的容器名称方式,查看清单文件中containers字段中的name字段
[root@k8s231 pods]# cat 02-nginx-tomcat.yaml
apiVersion: v1
kind: Pod
metadata:name: 02-nginx-tomcat
spec:containers:- name: nginximage: nginx:1.23.4-alpine- name: tomcatimage: tomcat:jre8-alpine[root@k8s231 pods]# kubectl exec -it 02-nginx-tomcat -- sh # 默认连接到第一个容器
[root@k8s231 pods]# kubectl exec -it 02-nginx-tomcat -c nginx -- sh # 连接nginx容器
[root@k8s231 pods]# kubectl exec -it 02-nginx-tomcat -c tomcat -- sh # 连接tomcat容器(3)查看Pod的日志(logs)
#使用"kubectl logs"查看的是容器的标准输出或错误输出日志,
#如果想要使用该方式查看,需要将日志重定向到/dev/stdout或者/dev/stderr。
#查看nginx容器的全部日志
[root@k8s231 pods]# kubectl logs 02-nginx-tomcat -c nginx
#查看nginx容器的1小时内日志
[root@k8s231 pods]# kubectl logs 02-nginx-tomcat -c nginx --since=1h
#查看nginx容器的从某个时间点之后的日志
[root@k8s231 pods]# kubectl logs 02-nginx-tomcat -c nginx --since-time="2023-12-22T02:00:00+00:00"
#查看nginx容器上一个挂掉的容器的日志 -p
[root@k8s231 pods]# kubectl logs 02-nginx-tomcat -c nginx -p6.3. 镜像下载策略,pod容器重启策略
一.镜像下载策略:
spec:containers:- name: nginximage: harbor.tom.com/web/web:v0.1 imagePullPolicy: Always|IfNotPresent|Never
# Always: 默认值,表示始终拉取最新的镜像。
# IfNotPresent: 如果本地有镜像,则不去远程仓库拉取镜像,若本地没有,才会去远程仓库拉取镜像。
# Never: 如果本地有镜像则尝试启动,若本地没有镜像,也不会去远程仓库拉取镜像。二. Pod中容器重启策略:(K8S所谓的重启指的是重新创建容器)
spec:restartPolicy: Always|OnFailure|Never
# Always: 当容器退出时,始终重启。
# OnFailure: 当容器正常退出时不会重启容器,异常退出时,会重启容器。
# Never: 当容器退出时,始终不重启。6.4. 向容器传递环境变量的方式
向容器传递环境变量的两种方式:
[root@k8s231 pods]# cat > 05-nginx-env.yaml <<EOF
apiVersion: v1
kind: Pod
metadata:name: 05-nginx-env
spec:nodeName: k8s232.tom.comcontainers:- name: nginximage: nginx:alpine# 向容器传递环境变量env:
#方式1: 使用自定义的变量值# 指定的变量名称- name: SCHOOL# 指定变量的值value: "qinghua"- name: CLASSvalue: "104"#方式2:不适用自定义的变量值,而是引用别处的值- name: PODN-AME valueFrom:# 值引用自某个字段fieldRef:# 指定字段的路径 fieldPath: "metadata.name"- name: NODE-NAMEvalueFrom:fieldRef:fieldPath: "spec.nodeName"- name: HOST-IPvalueFrom:fieldRef:fieldPath: "status.hostIP"- name: POD-IPvalueFrom:fieldRef:fieldPath: "status.podIP"
EOF
[root@k8s231 pods]# kubectl apply -f 05-nginx-env.yaml [root@k8s231 pods]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
05-nginx-env 1/1 Running 0 8s 10.200.1.6 k8s232.tom.com <none> <none>[root@k8s231 pods]# kubectl exec 05-nginx-env -- env
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
HOSTNAME=05-nginx-env
POD-IP=10.200.1.6
SCHOOL=qinghua
CLASS=104
PODN-AME=05-nginx-env
NODE-NAME=k8s232.tom.com
HOST-IP=10.0.0.2327. volume资源
存储的资源,包括volumes和persistent volume(pv)(后面的章节讲解)
Volume可以提供多种类型的资源存储(可持久或不持久),但是它定义在Pod上的,是属于"资源对象"的一部分
7.1. k8s支持的volumes类型:
使用kubectl explain pod.spec.volumes 查看k8s支持的存储类型
volume常用类型:
- emptyDir: (临时目录)Pod删除,数据也会被清除,用于数据的临时存储,只能单个pod内部容器共享数据。
- hostPath: (宿主机目录映射)
- 本地的SAN (iSCSI,FC)、NAS(nfs,cifs,http)存储
- 分布式存储(glusterfs,rbd,cephfs)
- 云存储(EBS,Azure Disk)
k8s要使用存储卷,需要2步:
1)在pod定义volume,并指明使用哪个存储设备
2)在容器使用volume mount进行挂载
7.2. emptyDir类型volume: 同pod内容器共享数据
emptyDir volumes特点:
- emptyDir volume在某个节点上刚创建时,它的初始内容为空,并且无须指定宿主机上对应的目录文件,因为这是Kubernetes自动分配的一个目录。
- 同一pod中的容器都可以读写这个目录,这个目录可以被挂在到各个容器相同或者不相同的的路径下。
- 当一个pod因为任何原因被移除的时候,这些数据会被永久删除。
- 一个容器崩溃了不会导致数据的丢失,因为容器的崩溃并不移除pod.
emptyDir 磁盘的用途:
- 临时空间,例如用于某些应用程序运行时所需的临时目录,且无须永久保留。
- 长时间任务的中间过程CheckPoint的临时保存目录。
- 一个容器需要从另一个容器中获取数据的目录(多容器共享目录)
#数据持久化之emptyDir实战案例:
#我们在一个pod定义了2个容器,2个容器都挂载同一个emptyDir volume,2个容器挂载目录的数据是相同的
[root@k8s231 pods]# cat > pod-volumes-emptyDir.yaml <<EOF
apiVersion: v1
kind: Pod
metadata:name: volume-emptydir
spec: volumes: - name: data01emptyDir: {} containers:- name: webimage: nginx:alpine volumeMounts: - name: data01 mountPath: /usr/share/nginx/html- name: busyboximage: busybox:latest volumeMounts:- name: data01mountPath: /datacommand: ['tail','-f','/etc/hosts']
EOF[root@k8s231 pods]# kubectl apply -f pod-volumes-emptyDir.yaml
[root@k8s231 pods]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
volume-emptydir 2/2 Running 0 13s 10.200.1.64 k8s232.tom.com <none> <none>[root@k8s231 pods]# kubectl exec -it volume-emptydir -c busybox -- sh -c "echo 1 > /data/index.html"
[root@k8s231 pods]# curl 10.200.1.64
1
[root@k8s231 pods]# kubectl exec -it volume-emptydir -c busybox -- sh -c "echo 2 > /data/index.html"
[root@k8s231 pods]# curl 10.200.1.64
2[root@k8s232 ~]# docker ps|awk -F'_' '/busybox/{print $(NF-1)}'
ad63d319-3809-4468-8c5d-f5b6765594a6
[root@k8s232 ~]# tree /var/lib/kubelet/pods/ad63d319-3809-4468-8c5d-f5b6765594a6/volumes/kubernetes.io~empty-dir/
/var/lib/kubelet/pods/ee925cb5-a35a-40ad-a434-c36423549e60/volumes/kubernetes.io~empty-dir/
└── data01└── index.html7.3. hostPath类型volume:同节点的不同POD共享数据
hostPath volumes特点:
- hostPath volume只能为同一个node节点上不同pod提供数据共享服务(不同pod使用hostPath的时候需要指定相同的node节点)
- 容器被删除,或者pod被删除,数据不会丢失
- node节点故障则会导致数据丢失
数据持久化之hostPath实战案例:
[root@k8s231 pods]# cat > volumes-hostPath.yaml <<EOF
apiVersion: v1
kind: Pod
metadata:name: volume-hostpath
spec:nodeName: k8s232.tom.comvolumes:- name: data01# 指定类型为宿主机存储卷,该存储卷只要用于容器访问宿主机路径的需求。 hostPath:# 指定存储卷的路径path: /k8s/volume/hostpathcontainers:- name: webimage: nginx:alpinevolumeMounts:- name: data01mountPath: /usr/share/nginx/html
---
apiVersion: v1
kind: Pod
metadata:name: volume-hostpath-002
spec:nodeName: k8s232.tom.comvolumes:- name: data01hostPath:path: /k8s/volume/hostpathcontainers:- name: linuximage: nginx:1.20.1-alpinestdin: truevolumeMounts:- name: data01mountPath: /data-test
EOF7.4. nfs类型volume:可以在不同节点的不同POD共享数据
nfs环境准备
- 部署nfs server(1)所有节点安装nfs相关软件包
yum -y install nfs-utils(2)k8s231节点设置共享目录
mkdir -p /k8s/volume/
cat > /etc/exports <<'EOF'
/k8s/volume/ *(rw,no_root_squash)
EOF(3)k8s231节点配置nfs服务开机自启动
systemctl enable --now nfs(4)服务端检查NFS挂载信息
exportfs(5)客户端节点手动挂载测试
mount -t nfs k8s231.tom.com:/k8s/volume/ /mnt/
umount /mnt
----------------------------------------------------
- 数据持久化之nfs实战案例
[root@k8s231 pods]# cat > volumes-nfs.yaml <<EOF
apiVersion: v1
kind: Pod
metadata:name: volume-nfs-web
spec:nodeName: k8s232.tom.comvolumes:- name: data# 指定存储卷类型是nfsnfs:# 指定nfs服务器的地址server: 10.0.0.231# 指定nfs对外暴露的挂载路径path: /k8s/volume/nfscontainers:- name: webimage: nginx:1.20.1-alpinevolumeMounts:- name: datamountPath: /usr/share/nginx/html
---apiVersion: v1
kind: Pod
metadata:name: volume-nfs-linux
spec:nodeName: k8s233.tom.comvolumes:- name: datanfs:server: 10.0.0.231path: /k8s/volume/nfscontainers:- name: linuximage: alpine:lateststdin: truevolumeMounts:- name: datamountPath: /tom-data
EOF7.5. volumeMounts[*].subPath
7.5.1. 目的1:同pod内多容器挂载同一个volume,但是有每个容器自己的目录
有时候,在单个 Pod 中多个container使用同一个volume。 volumeMounts.subPath 属性可用于指定所引用的卷内的子路径,而不是其根路径。
[root@k8s231 pods]# cat > volumemounts-subpath.yaml <<EOF
apiVersion: v1
kind: Pod
metadata:name: volumemounts-subpath-pod
spec:nodeName: k8s232.tom.comvolumes:- name: data hostPath: path: /k8s/volume/hostpathcontainers:- name: webimage: nginx:alpinevolumeMounts:- name: datamountPath: /usr/share/nginx/htmlsubPath: html- name: busyboximage: busybox:lateststdin: truevolumeMounts:- name: datamountPath: /datasubPath: log
EOF
#232上创建共享目录
[root@k8s232 ~]# mkdir -p /k8s/volume/hostpath
[root@k8s231 ~]# kubectl apply -f volumemounts-subpath.yaml
[root@k8s231 pods]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
volumemounts-subpath-pod 2/2 Running 0 10s 10.200.1.76 k8s232.tom.com <none> <none>[root@k8s232 ~]# tree /k8s/volume/hostpath
/k8s/volume/hostpath
├── html
└── log7.5.2. 目的2:将 config/secret 作为文件挂载到容器中的某个目录下,而不覆盖挂载目录下的文件
[root@k8s231 pods]# cat > configmap-subpath-pod.yaml <<EOF
apiVersion: v1
kind: ConfigMap
metadata:name: configmap-subpath
data:config.ini: "hello"config.conf: "world"
---
apiVersion: v1
kind: Pod
metadata:name: pod-configmap-subpath
spec:containers:- name: testimage: busyboxcommand: ["/bin/sh","-c","sleep 3600s"]volumeMounts:- name: vm-testmountPath: /etc/config.ini # 最终在容器中的文件名subPath: config.ini #要挂载的confmap中的key的名称- name: vm-testmountPath: /etc/config.conf subPath: config.conf volumes:- name: vm-testconfigMap:name: configmap-subpath
EOF[root@k8s231 pods]# kubectl apply -f configmap-subpath-pod.yaml
configmap/configmap-subpath-pod created
pod/configmap-subpath created[root@k8s231 pods]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-configmap-subpath 1/1 Running 0 33s 10.200.1.77 k8s232.tom.com <none> <none>[root@k8s231 pods]# kubectl exec pod-configmap-subpath -- sh -c "cat -n /etc/config.ini;cat -n /etc/config.conf;"1 hello1 world8. port端口映射
prots的端口映射案例
[root@k8s231 configMap]# cat > web-port.yaml <<EOF
apiVersion: v1
kind: Pod
metadata:name: web-port
spec:nodeName: k8s232.tom.comcontainers:- name: webimage: nginx:alpine# 指定容器的端口映射相关字段ports:# 指定容器的端口号- containerPort: 80# 绑定主机的IP地址hostIP: "0.0.0.0"# 指定绑定的端口号hostPort: 88# 给该端口起一个别名,要求唯一name: game# 指定容器的协议protocol: TCP
9. 容器资源请求,资源限制
requests 表示创建pod时预留的资源,limits 表示pod 能够使用资源的最大值;
requests 值可以被超过,limits 值不能超过;
如果是内存使用超过limits 会触发oom 然后杀掉进程,如果是 cpu 超过limits 则会压缩cpu 的使用率
容器的资源限制实战案例:
[root@k8s231 pods]# cat > 12-requests.yaml <<EIF
apiVersion: v1
kind: Pod
metadata:name: pod-requests
spec:nodeName: k8s233.tom.comcontainers:- name: pod-requestsimage: nginx:alpine# 对容器进行资源限制resources:# 期望目标节点有的资源大小,若不满足,则无法调度,Pod处于Pedding状态。# 若满足调度需求,调度到节点后也不会立刻使用requests字段的定义的资源。requests:# 要求目标节点有256M内存memory: 256M# 指定CPU的核心数,固定单位: 1core=1000mcpu: 500m# 配置资源的使用上限limits:memory: 500Mcpu: 1.5
EOF10. configMap资源
k8s可以使用ConfigMap来实现对容器中应用的配置进行管理(应用的conf文件内容写到cm里)。
可以把ConfigMap看作是一个挂载到pod中的存储卷
推荐阅读:
Volumes | Kubernetes
ConfigMaps | Kubernetes
10.1. 创建configMap
创建configmap,支持的数据类型: (1)键值对; (2)多行数据;
[root@k8s231 configMap]# cat > configmap-01.yaml <<EOF
apiVersion: v1
kind: ConfigMap
metadata:name: cm-01
# 定义cm资源的数据
data:# 键值对name: tomage: "18"# 定义多行数据my.cfg: |datadir: "/var/lib/mysql"basedir: "/usr/share/mysql"socket: "/tmp/mysql.sock"
EOF[root@k8s231 pods]# kubectl apply -f configmap-01.yaml
configmap/cm-01 created
]# kubectl get cm cm-01
NAME DATA AGE
cm-01 3 2m41s
[root@k8s231 pods]# kubectl describe cm cm-01
Name: cm-01
Namespace: default
Labels: <none>
Annotations: <none>Data
====
age:
----
18
my.cfg:
----
datadir: "/var/lib/mysql"
basedir: "/usr/share/mysql"
socket: "/tmp/mysql.sock"name:
----
tomBinaryData
====Events: <none>10.2. Pod引用configmap资源的两种常见的方式
10.2.1. 方式1-pod基于env环境变量引入cm资源:
pod基于env环境变量引入cm资源:
[root@k8s231 configMap]# cat > pod-configmap-env.yaml <<EOF
apiVersion: v1
kind: Pod
metadata:name: pod-cm-env
spec:nodeName: k8s232.tom.comcontainers:- name: gameimage: nginx:alpineenv:- name: env_cm_agevalueFrom:# 指定引用的configMap资源configMapKeyRef:# 指定configMap的名称name: cm-01# 指定configMap的KEYkey: age- name: env_cm_mycfgvalueFrom:configMapKeyRef:name: cm-01key: my.cfg
EOF[root@k8s231 pods]# kubectl apply -f pod-configmap-env.yaml
pod/pod-cm-env created[root@k8s231 pods]# kubectl get pods
NAME READY STATUS RESTARTS AGE
pod-cm-env 1/1 Running 0 4s[root@k8s231 pods]# kubectl exec pod-cm-env -- env
PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
HOSTNAME=pod-cm-env
env_cm_age=18
env_cm_mycfg=datadir: "/var/lib/mysql"
basedir: "/usr/share/mysql"
socket: "/tmp/mysql.sock"10.2.2. 方式2-pod基于存储卷的方式引入cm资源
在Kubernetes中,要挂载nginx.conf配置文件到Nginx Pod中,你可以使用ConfigMap来管理配置文件,并将其作为卷挂载到Pod中。
10.2.2.1. 挂载nginx配置方式1:把nginx配置文件写在configmap的文件里,然后再用到挂载
1.创建一个名为nginx-configmap.yaml的ConfigMap文件:
cat > nginx-configmap.yaml <<EOF
apiVersion: v1
kind: ConfigMap
metadata:name: nginx-configmap
data:nginx.conf: |-user nginx;worker_processes 1;error_log /var/log/nginx/error.log warn;pid /var/run/nginx.pid;events {worker_connections 1024;}http {include /etc/nginx/mime.types;default_type application/octet-stream;server{listen 80;server_name _;root /usr/share/nginx/html; }}
EOF2.应用ConfigMap到Kubernetes集群:
kubectl apply -f nginx-configmap.yaml3.创建Pod(nginx-pod.yaml)并挂载ConfigMap作为卷:
cat > nginx-pod.yaml <<EOF
apiVersion: v1
kind: Pod
metadata:name: nginx-pod
spec:containers:- name: nginximage: nginx:latestvolumeMounts:- name: config-volumemountPath: /etc/nginx/nginx.conf#不加subPath时,默认挂载的是文件夹,#加subPath时,且subPath的值和configMap.items.path相同时,mountPath的挂载点是一个文件而非目录!subPath: nginx.confvolumes:- name: config-volume# 指定存储卷的类型为configMapconfigMap:# 指定configMap的名称name: nginx-configmap# 不加items,就是全部引入,加上是引用configMap的特定keyitems:- key: nginx.conf# 可以暂时理解为指定文件的名称path: nginx.conf
EOF4.应用Pod定义到Kubernetes集群:
kubectl apply -f nginx-pod.yaml10.2.2.2. 挂载nginx配置方式2: 把nginx配置文件加载为configmap,然后再用到挂载
| 1 | 创建Nginx配置文件 |
| 2 | 创建ConfigMap对象 |
| 3 | 创建Deployment对象 |
| 4 | 挂载ConfigMap到Deployment中 |
(1)创建Nginx配置文件
[root@k8s231 pods]# cat > server01.conf <<EOF
server {listen 80;server_name _;location / {root /usr/share/nginx/html;index index.html;}
}
EOF
(2)创建ConfigMap对象
在K8S中,可以使用ConfigMap对象来存储配置信息。
我们可以通过以下命令将Nginx配置文件创建为一个ConfigMap对象
#可以一次性储存多个文件为配置信息
#kubectl create configmap nginx-config --from-file=key1=/path/to/bar/file1.txt --from-file=key2=/path/to/bar/file2.txt
#可以把文件夹作为参数,会递归把文件夹下面的文件储存为配置信息
#kubectl create configmap nginx-config --from-file=nginx-conf.dkubectl create configmap nginx-config --from-file=server01.conf(3)创建pod资源清单
cat > nginx-pod-cm-from-file.yaml <<EOF
apiVersion: v1
kind: Pod
metadata:name: nginx-pod-cm-from-file
spec:containers:- name: nginximage: nginx:latestvolumeMounts:- name: config-volumemountPath: /etc/nginx/conf.d/volumes:- name: config-volume# 指定存储卷的类型为configMapconfigMap:# 指定configMap的名称name: nginx-config
EOF(4)创建pod
kubectl apply -f nginx-pod-cm-from-file.yaml(5)验证
]# kubectl exec nginx-pod-cm-from-file -- cat /etc/nginx/conf.d/server01.conf
server {listen 80;server_name _;location / {root /usr/share/nginx/html;index index.html;}
}11. secret资源
Kubernetes 中的 Secret 对象用来保存敏感信息,例如密码、OAuth 令牌和 ssh 密钥等。Secret 的数据可以是任何二进制数据,但最常见的是用来保存文本数据。
Kubernetes 支持以下几种数据类型 Secret:
Opaque: 默认的 Secret 类型。使用base64编码存储信息,可通过base64 --decode解码获得原始数据,因此安全性弱。kubernetes.io/service-account-token: 这种类型的 Secret 由 Kubernetes 自动创建,并且挂载到 Pod 中的 Service Account 里。kubernetes.io/dockerconfigjson: 用于保存 Docker 登录的认证信息,例如用户名和密码。kubernetes.io/ssh-auth: 用于保存 SSH 密钥。kubernetes.io/tls: 用于保存 TLS 证书和私钥。
11.1. 创建secret
11.1.1. 创建Opaque类型的secret
Opaque类型的secret资源的增删改查实战:(1)编写secret资源
#对用户名密码进行base64编码,下面编写secret清单会用到
[root@k8s231 ~]# echo tom |base64
dG9tCg==
[root@k8s231 ~]# echo 123456 |base64
MTIzNDU2Cg==[root@k8s231 secret]# cat > opaque-secret.yaml <<EOF
apiVersion: v1
kind: Secret
metadata:name: opaque-secret
data:username: dG9tCg==password: MTIzNDU2Cg==
EOF(2)创建secret资源
[root@k8s231 secret]# kubectl apply -f opaque-secret.yaml(3)查询secret资源
[root@k8s231 secret]# ]# kubectl get secrets opaque-secret
NAME TYPE DATA AGE
opaque-secret Opaque 2 13s[root@k8s231 secret]# kubectl describe secrets opaque-secret
Name: opaque-secret
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
password: 7 bytes
username: 4 bytes(4)删除secret资源
[root@k8s231 secret]# kubectl delete -f opaque-secret.yaml11.1.2. 创建 kubernetes.io/dockerconfigjson类型的secret
#得确保harbor仓库存在此用户,且项目对此用户开放
kubectl create secret docker-registry docker-secret \--docker-email=tom@qq.com \--docker-username=tom \--docker-password=Tom123456 \--docker-server=harbor.tom.com[root@k8s231 secret]# kubectl get secrets docker-secret
NAME TYPE DATA AGE
docker-secret kubernetes.io/dockerconfigjson 1 11s11.2. pod引用secret的方式
11.2.1. opaque secret引用方式
11.2.1.1. 方式1-pod基于env环境变量引入secret资源:
#使用方式可参考
kubectl explain po.spec.containers.env.valueFrom.secretKeyRefPod基于env引用opaque secret资源案例:
[root@k8s231 secret]# cat > pod-env-opaque-secret.yaml <<EOF
apiVersion: v1
kind: Pod
metadata:name: pod-env-opaque-secret
spec:nodeName: k8s232.tom.comcontainers:- name: gameimage: nginx:alpine env: - name: env-opaque-secret-usernamevalueFrom:# 指定引用的secret资源secretKeyRef:# 指定secret的名称name: opaque-secret# 指定secret的KEYkey: username - name: env-opaque-secret-passwordvalueFrom:secretKeyRef:name: opaque-secretkey: password
EOF
]# kubectl apply -f pod-env-opaque-secret.yaml
]# kubectl exec pod-env-opaque-secret -- env
...
env-opaque-secret-username=tom
env-opaque-secret-password=123456
....11.2.1.2. 方式2-pod基于存储卷的方式引入opaque secret资源
Pod基于env引用opaque secret资源案例:
[root@k8s231 secret]# cat > pod-volume-opaque-secret.yaml << EOF
apiVersion: v1
kind: Pod
metadata:name: pod-volume-opaque-secret
spec:volumes:- name: data# 指定存储卷的类型为secretsecret:# 指定secret的名称secretName: opaque-secretitems:- key: usernamepath: username.info- key: passwordpath: password.infocontainers:- name: gameimage: nginx:alpine volumeMounts:- name: data mountPath: /data/username.infosubPath: username.info- name: datamountPath: /data/password.infosubPath: password.info
EOF [root@k8s231 secret]# kubectl apply -f pod-volume-opaque-secret.yaml
[root@k8s231 secret]# kubectl exec pod-volume-opaque-secret -- cat /data/username.info /data/password.info
tom
12345611.2.2. pod引用dockercfg secret方式
#使用dockercfg secret 从harbor拉取镜像
[root@k8s231 secret]# cat > pod-dockercfg-secret.yaml << EOF
apiVersion: v1
kind: Pod
metadata:name: pod-dockercfg-secret
spec:imagePullSecrets:- name: docker-secretcontainers:- name: nginximage: harbor.tom.com/private-lib/nginx:alpine
EOF12. 标签管理
标签管理分响应式和声明式:
响应式:创建标签立即生效,但资源被重新创建时,标签可能会丢失哟~需要重新创建
声明式:需要将标签写入到资源清单,每次修改后需要重新应用资源的配置文件,否则不会生效。
12.1. 标签管理:响应式
(一)响应式进行标签管理(1)创建标签#指定给资源清单文件所对应的pod打标签
[root@k8s231 pods]# kubectl label -f web-labels.yaml version=v1#查看pod的标签
[root@k8s231 pods]# kubectl get pod 01-nginx --show-labels
NAME READY STATUS RESTARTS AGE LABELS
01-nginx 1/1 Running 0 82s version=v1#指定给pod打标签
[root@k8s231 pods]# kubectl label pod 01-nginx app=game#查看pod的标签
[root@k8s231 pods]# kubectl get pod 01-nginx --show-labels
NAME READY STATUS RESTARTS AGE LABELS
01-nginx 1/1 Running 0 82s app=game,version=v1(2)修改标签
[root@k8s231 pods]# kubectl label --overwrite pod 01-nginx version=v2
pod/01-nginx labeled#查看pod的标签
[root@k8s231 pods]# kubectl get pod 01-nginx --show-labels
NAME READY STATUS RESTARTS AGE LABELS
01-nginx 1/1 Running 0 2m57s app=game,version=v2(3)删除标签
[root@k8s231 pods]# kubectl label pod 01-nginx version-
pod/01-nginx unlabeled
[root@k8s231 pods]# kubectl get pod 01-nginx --show-labels
NAME READY STATUS RESTARTS AGE LABELS
01-nginx 1/1 Running 0 5m45s app=game
---------------------------------------------------------------------12.2. 标签管理:声明式
(二)基于声明式进行标签管理:(1)创建标签
[root@k8s231 pods]# cat 01-nginx.yaml
apiVersion: v1
kind: Pod
metadata:name: 01-nginxlabels:version: v3app: web
spec:containers:- name: nginximage: nginx:alpine
#应用配置
[root@k8s231 pods]# kubectl apply -f 01-nginx.yaml
#查看pod的标签
[root@k8s231 pods]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
01-nginx 1/1 Running 0 7s app=web,version=v3(2)修改标签
#vim 修改 labels 里面的version: v4
[root@k8s231 pods]# sed -i 's#version: v3#version: v4#g' 01-nginx.yaml
#重新应用配置
[root@k8s231 pods]# kubectl apply -f 01-nginx.yaml#查看pod的标签
[root@k8s231 pods]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
01-nginx 1/1 Running 0 5m54s app=web,version=v412.3. 基于标签删除pod
基于标签删除Pod资源案例
[root@k8s231 pods]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
02-nginx-tomcat 2/2 Running 0 77s version=v1
03-nginx-alpine 2/2 Running 0 73s version=v2
[root@k8s231 pods]# kubectl delete pods -l version=v1
pod "02-nginx-tomcat" deleted
[root@k8s231 pods]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
03-nginx-alpine 2/2 Running 0 92s version=v212.4. 基于标签查看Pod
基于标签查看Pod
[root@k8s231 pods]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
01-nginx 1/1 Running 0 41s app=web,version=v4
02-nginx-tomcat 2/2 Running 0 2s <none>
03-nginx-alpine 2/2 Running 0 4m26s version=v2
[root@k8s231 pods]# kubectl get pods --show-labels -l version
NAME READY STATUS RESTARTS AGE LABELS
01-nginx 1/1 Running 0 65s app=web,version=v4
03-nginx-alpine 2/2 Running 0 4m50s version=v212.5. 基于标签管理cm资源
创建标签的方式也可以分为响应式和声明式。和标签管理不同的是命令中pod换成cm即可
#响应式创建cm资源
#响应式创建标签
kubectl label cm cm-01 v=0.1
#响应式修改标签
kubectl label cm cm-01 v=0.3 --overwrite#声明式创建cm资源
cat > configmap-01.yaml <<EOF
apiVersion: v1
kind: ConfigMap
metadata:name: cm-01labels:v: "0.1"
data:name: tomage: "18"
EOF
kubectl apply -f configmap-01.yaml#基于标签查看cm
]# kubectl get cm -l v --show-labels
NAME DATA AGE LABELS
cm-01 3 13m v=0.3
nginx-config 2 21h v=0.2#基于标签删除cm
[root@k8s231 pods]# kubectl delete cm -l v=0.3
configmap "cm-01" deleted
[root@k8s231 pods]# kubectl get cm -l v --show-labels
NAME DATA AGE LABELS
nginx-config 2 21h v=0.212.6. 查看nodes节点的标签
查看nodes节点的标签:
[root@k8s231 pods]# kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
k8s231.tom.com Ready control-plane,master 4d6h v1.23.17 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s231.tom.com,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node-role.kubernetes.io/master=,node.kubernetes.io/exclude-from-external-load-balancers=
k8s232.tom.com Ready <none> 4d6h v1.23.17 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s232.tom.com,kubernetes.io/os=linux
k8s233.tom.com Ready <none> 4d6h v1.23.17 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=k8s233.tom.com,kubernetes.io/os=linux13. 名称空间(namespace)
在同一个名称空间下,同一种资源类型,是无法同时创建多个名称相同的资源。
名称空间是用来隔离K8S集群的资源。我们通常使用名称空间对企业业务进行逻辑上划分。
K8S集群一切皆资源,有的资源是不支持名称空间的,我们将其称为全局资源,而支持名称空间的资源我们称之为局部资源。
我们可以通过"kubectl api-resources"命令来判断一个资源是否支持名称空间。
温馨提示:(1)在同一个名称空间下,同一个资源类型是不能出现重名的;(2)在不同的名称空间下,相同的资源类型是能出现同名的;13.1. 名称空间的各种资源查看详解
#1.查看现象有的名称空间
[root@k8s231 pods]# ]# kubectl get namespaces
NAME STATUS AGE
default Active 4d9h
kube-flannel Active 4d8h
kube-node-lease Active 4d9h
kube-public Active 4d9h
kube-system Active 4d9h #2.查看默认名称空间的Pod资源
kubectl get pods -n default
kubectl get pods #3.查看指定的名称空间Pod资源
kubectl get pods -n kube-system
kubectl get pods --namespace kube-system#4.查看所有名称空间的Pod资源
kubectl get pods --all-namespaces
kubectl get pods -A#5.查看所有名称空间的cm资源
kubectl get cm -A#6.查看指定名称空间的cm资源
kubectl get cm -n kube-system13.2. 创建名称空间
- 创建名称空间1.响应式创建名称空间
kubectl create namespace ns-tom-12.声明式创建名称空间
[root@k8s231 namespaces]# cat > ns-tom-2.yaml <<EOF
apiVersion: v1
kind: Namespace
metadata:name: ns-tom-2
EOF
[root@k8s231 namespaces]# kubectl apply -f ns-tom-2.yaml
[root@k8s231 pods]# kubectl get ns
NAME STATUS AGE
default Active 4d9h
kube-flannel Active 4d9h
kube-node-lease Active 4d9h
kube-public Active 4d9h
kube-system Active 4d9h
ns-tom-1 Active 14s
ns-tom-2 Active 4s13.3. 修改名称空间(名称空间一旦创建将无法修改!)
13.4. pod使用名称空间
[root@k8s231 namespaces]# cat > pods-ns.yaml <<EOF
apiVersion: v1
kind: Pod
metadata:name: webnamespace: ns-tom-1
spec:containers:- name: nginximage: nginx:alpine
---
apiVersion: v1
kind: Pod
metadata:name: webnamespace: ns-tom-2
spec:containers:- name: nginximage: nginx:alpine
EOF[root@k8s231 pods]# kubectl apply -f pods-ns.yaml
pod/web created
pod/web created[root@k8s231 pods]# kubectl get pods -A|egrep "NAMESPACE|web"
NAMESPACE NAME READY STATUS RESTARTS AGE
ns-tom-1 web 1/1 Running 0 97s
ns-tom-2 web 1/1 Running 0 97s13.5. 删除名称空间中的pod
[root@k8s231 pods]# kubectl delete pod web -n ns-tom-1
pod "web" deleted13.6. 删除名称空间
慎用:一旦删除名称空间,该名称空间下的所有资源都会被随之删除
[root@k8s231 pods]# kubectl get po,cm,secret -n ns-tom-2
NAME READY STATUS RESTARTS AGE
pod/web 1/1 Running 0 4m55sNAME DATA AGE
configmap/kube-root-ca.crt 1 13mNAME TYPE DATA AGE
secret/default-token-n8wnp kubernetes.io/service-account-token 3 13m[root@k8s231 pods]# kubectl delete namespaces ns-tom-2
namespace "ns-tom-2" deleted[root@k8s231 pods]# kubectl get po,cm,secret -n ns-tom-2
No resources found in ns-tom-2 namespace.14. 控制器之RC(Replication Controller)副本控制器
Replication Controller(副本控制器),RC能够保证任意时间,pod都有指定的数量的副本在运行。(pod被删除会重新创建pod)
RC控制的pod的多个副本,每个副本都有独立的ip,并且支持pod副本数量的扩、缩容。
(1) 编写rc清单
cat > rc-web.yaml <<EOF
#api版本
apiVersion: v1
#对象资源类型 RC
kind: ReplicationController
#RC元数据
metadata:#对象资源名称name: nginx
#RC的详细描述
spec:#维持pod的共数量replicas: 3#RC选择器,指定对哪个Pod使用rcselector:#label 标签,选择有此 label 的 Podapp: webversion: v1# 定义创建 Pod 实例的模板template:metadata:name: nginx # Pod 的 label,对应上面 rc 的 selector labels:app: webversion: v1level: "3"spec:containers: # 定义 Pod 中的容器- name: nginximage: nginx:alpine
EOF(2) 创建rc清单
[root@k8s231 rc]# kubectl apply -f rc-web.yaml(3) 查看rc清单
[root@k8s231 rc]# kubectl get rc -o wide --show-labels
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR LABELS
nginx 3 3 3 5m52s nginx nginx:alpine app=web,version=v1 app=nginx(4) 查看rc清单创建的pod
[root@k8s231 rc]# kubectl get pod -o wide --show-labels
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
nginx-2t6pn 1/1 Running 0 3m15s 10.200.2.27 k8s233.tom.com <none> <none> app=web,level=3,version=v1
nginx-tdlqd 1/1 Running 0 3m15s 10.200.2.26 k8s233.tom.com <none> <none> app=web,level=3,version=v1
nginx-xdbwf 1/1 Running 0 3m15s 10.200.1.30 k8s232.tom.com <none> <none> app=web,level=3,version=v1(5) 修改rc清单的副本数
#方式1:静态修改清单,然后apply
sed -i 's#replicas:.*#replicas: 2#g' rc-web.yaml
kubectl apply -f rc-web.yaml#方式2:动态修改,修改完立马生效
kubectl edit replicationcontrollers nginx (6) 删除rc
kubectl delete rc nginx 或 kubectl delete -f rc-web.yaml 15. Service
Service 存在的意义?
引入 Service 主要是解决 Pod 的动态变化,通过创建 Service,可以为一组具有相同功能的容器应用提供一个统一的入口地址,并且将请求负载分发到后端的各个容器应用上。
若提供服务的容器应用是分布式,所以存在多个 pod 副本,而 Pod 副本数量可能在运行过程中动态改变,比如水平扩缩容,或者服务器发生故障 Pod 的 IP 地址也有可能发生变化。当 pod 的地址端口发生改变后,客户端再想连接访问应用就得人工干预,很麻烦,这时就可以通过 service 来解决问题。
概念:
Service 主要用于提供网络服务,通过 Service 的定义,能够为客户端应用提供稳定的访问地址(域名或 IP 地址)和负载均衡功能,以及屏蔽后端 Endpoint 的变化,是 K8s 实现微服务的核心资源。
svc 特点:
-
- 服务发现,防止阴滚动升级等因素导致 Pod IP 发生改变而失联,找到提供同一个服务的 Pod。
- 负载均衡,定义一组 Pod 的访问策略。
15.1. svc的分类:
- ExternalName: 可以将K8S集群外部的服务映射为一个svc服务。类似于一种CNAME技术.
- ClusterIP: 仅用于K8S集群内部使用。提供统一的VIP地址。默认值!
- NodePort: 除了分配 ClusterIP 外,还会在每一个 Node 上享有一个高端口号,即
nodeIP:nodePort暴露服务。可以从集群外部访问服务。但不经常使用,局限性较大 - LoadBalancer: 主要用于云平台的LB等产品。
15.2. serveice 之 ClusterIP案例
#(1)查看当前存在的pod
[root@k8s231 svc]# kubectl get pods -o wide --show-labels
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
nginx-65zbj 1/1 Running 0 4m9s 10.200.1.33 k8s232.tom.com <none> <none> app=web,level=3,version=v1
nginx-8w7qb 1/1 Running 0 4m9s 10.200.2.30 k8s233.tom.com <none> <none> app=web,level=3,version=v1
nginx-tvr7k 1/1 Running 0 4m9s 10.200.1.32 k8s232.tom.com <none> <none> app=web,level=3,version=v1#(2)编写svc清单
[root@k8s231 services]# cat > 01-svc-ClusterIP.yaml <<EOF
apiVersion: v1
kind: Service
metadata:name: webnamespace: defaultlabels:apps: svc
spec:# 根据标签,关联后端的Podselector:app: webtype: ClusterIP# 指定端口映射相关信息ports:# 指定svc的端口号- port: 88# 指定Pod端口号targetPort: 80# 指定协议protocol: TCP# 指定ClusterIP的地址#clusterIP: 10.100.1.0
EOF#(3)创建svc
[root@k8s231 svc]# kubectl apply -f 01-svc-ClusterIP.yaml#(4)查看创建的svc
[root@k8s231 svc]# kubectl get svc -o wide --show-labels
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR LABELS
kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 5d8h <none> component=apiserver,provider=kubernetes
web ClusterIP 10.100.194.202 <none> 88/TCP 28s app=web apps=svc#(5)Endpoints为通过select的指定的标签匹配到的pod的ip,字段IP为对外提供服务的ip
[root@k8s231 svc]# kubectl describe svc web
Name: web
Namespace: default
Labels: apps=svc
Annotations: <none>
Selector: app=web
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.100.194.202
IPs: 10.100.194.202
Port: <unset> 88/TCP
TargetPort: 80/TCP
Endpoints: 10.200.1.32:80,10.200.1.33:80,10.200.2.30:80
Session Affinity: None
Events: <none>#(6)把三个web页面修改成相应的ip
[root@k8s231 svc]# kubectl exec nginx-tvr7k -- sh -c 'echo "nginx-tvr7k 10.200.1.32" > /usr/share/nginx/html/index.html'
[root@k8s231 svc]# kubectl exec nginx-8w7qb -- sh -c 'echo "nginx-8w7qb 10.200.2.30" > /usr/share/nginx/html/index.html'
[root@k8s231 svc]# kubectl exec nginx-65zbj -- sh -c 'echo "nginx-65zbj 10.200.1.33" > /usr/share/nginx/html/index.html'#(7)访问svc的ip,查看负载均衡的效果
[root@k8s231 svc]# curl 10.100.194.202:88
nginx-tvr7k 10.200.1.32
[root@k8s231 svc]# curl 10.100.194.202:88
nginx-8w7qb 10.200.2.30
[root@k8s231 svc]# curl 10.100.194.202:88
nginx-65zbj 10.200.1.33#(8)删除svc
[root@k8s231 svc]# kubectl delete svc web15.3. serveice 之 NodePort案例
除了分配 ClusterIP 外,还会在每一个 Node 上享有一个高端口号暴露服务。客户可以从集群外部访问nodeIP:nodePort访问服务。但不经常使用,局限性较大
#(1)编写资源清单
]# cat > 02-svc-nodeport.yaml <<EOF
apiVersion: v1
kind: Pod
metadata:name: pod-nginxlabels:app: web
spec:containers:- name: nginximage: nginx:alpine
---
apiVersion: v1
kind: Service
metadata:name: svc-nginx
spec:selector:app: webtype: NodePortports:# 指定访问宿主机的端口,有效端口范围是:"30000-32767",该端口的报文会被转发后端的容器端口- nodePort: 30080#集群内部访问的端口号port: 88#容器内部服务端口号targetPort: 80# 指定协议protocol: TCP # 指定ClusterIP的地址#clusterIP: 10.100.100.200
EOF#(2)创建资源
]# kubectl apply -f 02-svc-nodeport.yaml#(3)查看资源
]# kubectl get svc,pod -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service/kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 10s <none>
service/svc-nginx NodePort 10.100.25.155 <none> 88:30080/TCP 7s app=webNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/pod-nginx 1/1 Running 0 7s 10.200.1.58 k8s232.tom.com <none> <none>#(3)集群内部访问端口号80访问
]# curl -o /dev/null -s -w %{http_code} 10.100.25.155:88
200#(4)集群外部访问端口号30080访问
]# curl -o /dev/null -s -w %{http_code} k8s233.tom.com:30080
20015.4. serveice 之 LoadBalance案例:
- LoadBalance案例:(1)前提条件
K8S集群在任意云平台环境,比如腾讯云,阿里云,京东云等。(2)创建svc
[root@k8s231 services]# cat > 03-services-LoadBalance.yaml <<EOF
kind: Service
apiVersion: v1
metadata:name: svc-loadbalancer
spec:# 指定service类型为LoadBalancer,注意,一般用于云环境type: LoadBalancerselector:apps: webports:- protocol: TCPport: 80targetPort: 80nodePort: 30080
EOF(3)配置云环境的应用负载均衡器
添加监听器规则,比如访问负载均衡器的80端口,反向代理到30080端口。
简而言之,就是访问云环境的应用服务器的哪个端口,把他反向代理到K8S集群的node端口为30080即可。(4)用户访问应用负载均衡器的端口
用户直接访问云环境应用服务器的80端口即可,请求会自动转发到云环境nodePort的30080端口哟。15.5. service 之 ExternalName案例:
[root@k8s231 ~]# cat 04-svc-ExternalName.yaml
apiVersion: v1
kind: Service
metadata:name: svc-externalname
spec:# svc类型type: ExternalName# 指定外部域名externalName: www.baidu.com温馨提示:启动容器后访问名为"svc-externalname"的svc,请求会被cname到"www.baidu.com"的A记录。这种方式使用并不多,因为对于域名解析直接配置DSNS的解析较多,因此此处了解即可。 16. 探针(probe)
参考链接: Pod 的生命周期 | Kubernetes
16.1. 探针(Probe)分类:
常用的探针(Probe):livenessProbe:存活探针健康状态检查,周期性检查服务是否存活,检查结果失败,将"重启"容器(删除源容器并重新创建新容器)。如果容器没有提供健康状态检查,则默认状态为Success。readinessProbe:就绪探针,可用性检查可用性检查,周期性检查服务是否可用,从而判断容器是否就绪。若检测Pod服务不可用,则会将Pod从svc的ep列表中移除。若检测Pod服务可用,则会将Pod重新添加到svc的ep列表中。如果容器没有提供可用性检查,则默认状态为Success。startupProbe:启动探针 (1.16+之后的版本才支持)如果提供了启动探针,则所有其他探针都会被禁用,直到此探针成功为止。如果启动探测失败,kubelet将杀死容器,而容器依其重启策略进行重启。 如果容器没有提供启动探测,则默认状态为 Success。16.2. 探针(Probe)检测Pod服务方法:
探针(Probe)检测Pod服务方法:exec:执行一段命令,根据返回值判断执行结果。返回值为0或非0,有点类似于"echo $?"。httpGet:发起HTTP请求,根据返回的状态码来判断服务是否正常。200: 返回状态码成功301: 永久跳转302: 临时跳转401: 验证失败403: 权限被拒绝404: 文件找不到413: 文件上传过大500: 服务器内部错误502: 无效的请求504: 后端应用网关响应超时...tcpSocket:测试某个TCP端口是否能够链接,类似于telnet,nc等测试工具。16.3. 检测成功和失败的相关参数
initialDelaySeconds:Pod启动后延迟多久才进行检查,单位:秒。
periodSeconds:检查的间隔时间,默认为10,单位:秒。
timeoutSeconds:探测的超时时间,默认为1,单位:秒。
successThreshold:探测失败后认为成功的最小连接成功次数,默认为1,在Liveness探针中必须为1,最小值为1。
failureThreshold:探测失败的重试次数,重试一定次数后将认为失败,在readiness探针中,Pod会被标记为未就绪,默认为3,最小值16.4. livenessProbe探针使用方法
livenessProbe健康状态检查,周期性检查服务是否存活,检查结果失败,将"重启"容器(删除源容器并重新创建新容器)。如果容器没有提供健康状态检查,则默认状态为Success。
16.4.1. livenessProbe之exec: 检测命令执行是否成功
cat > livenessprobe-exec.yaml <<EOF
kind: Pod
apiVersion: v1
metadata:name: livenessprobe-exec
spec:containers:- name: webimage: nginx:alpinecommand: - /bin/sh- -c- touch /tmp/healthy; sleep 5; rm -f /tmp/healthy; sleep 600# 健康状态检查,周期性执行命令,命令执行失败,将重启容器。livenessProbe:# 使用exec的方式去做健康检查exec:# 自定义检查的命令command:- cat- /tmp/healthy# 检测服务失败次数的累加值,默认值是3次,最小值是1。当检测服务成功后,该值会被重置!failureThreshold: 3# Pod启动后延迟多久才进行检查,即此时间段内检测服务失败并不会对failureThreshold进行计数。initialDelaySeconds: 15# 指定探针检测的频率,默认是10s,最小值为1.periodSeconds: 1# 检测服务成功次数的累加值,默认值为1次,最小值1.successThreshold: 1# 一次检测周期超时的秒数,默认值是1秒,最小值为1.timeoutSeconds: 1
EOF实验结果:15秒开始,检测到失败,18秒左右pod中容器重启16.4.2. livenessProbe之httpGet:检测页面是否能访问
livenessProbe-httpGet检测方法
cat > livenessprobe-httpget.yaml <<EOF
kind: Pod
apiVersion: v1
metadata:name: livenessprobe-httpget
spec:volumes:- name: dataemptyDir: {}containers:- name: webimage: nginx:alpine volumeMounts:- name: datamountPath: /usr/share/nginx/html# 健康状态检查,周期性检查页面是否能访问,检查结果失败,将重启容器。livenessProbe:# 使用httpGet的方式去做健康检查httpGet:# 指定访问的端口号port: 80# 检测指定的访问路径path: /index.html# 检测服务失败次数的累加值,默认值是3次,最小值是1。当检测服务成功后,该值会被重置!failureThreshold: 3# 指定多久之后进行健康状态检查,即此时间段内检测服务失败并不会对failureThreshold进行计数。initialDelaySeconds: 20# 指定探针检测的频率,默认是10s,最小值为1.periodSeconds: 1# 检测服务成功次数的累加值,默认值为1次,最小值1.successThreshold: 1# 一次检测周期超时的秒数,默认值是1秒,最小值为1.timeoutSeconds: 1
EOF实验结果:
1.刚开始启动,pod正常运行,但是web服务异常,因为缺失index.html
2.连接pod中的web,手动创建/usr/share/nginx/html/index.html(容器启动20秒内完成,否则就会触发重启)16.4.3. livenessProbe之tcpSocket:检测端口连通性
- tcpSocket检测方法
cat > livenessprobe-tcpsocket.yaml <<EOF
kind: Pod
apiVersion: v1
metadata:name: livenessprobe-tcpsocket
spec:containers:- name: webimage: nginx:alpinecommand:- /bin/sh- -c- nginx ; sleep 10; nginx -s stop ; sleep 600# 健康状态检查,周期性检查端口是否存在,检查结果失败,将重启容器。livenessProbe:# 使用tcpSocket的方式去做健康检查tcpSocket:port: 80# 检测服务失败次数的累加值,默认值是3次,最小值是1。当检测服务成功后,该值会被重置!failureThreshold: 3# 指定多久之后进行健康状态检查,即此时间段内检测服务失败并不会对failureThreshold进行计数。initialDelaySeconds: 15# 指定探针检测的频率,默认是10s,最小值为1.periodSeconds: 1# 检测服务成功次数的累加值,默认值为1次,最小值1.successThreshold: 1# 一次检测周期超时的秒数,默认值是1秒,最小值为1.timeoutSeconds: 1
EOF实验结果:
1.15秒开始检测,18秒左右报错,pod中容器重启16.5. readinessProbe探针使用方法
readinessProbe:就绪探针
- 可用性检查,周期性检查服务是否可用,从而判断容器是否就绪。
- 若检测Pod服务不可用,则会将Pod从svc的ep列表中移除。
- 若检测Pod服务可用,则会将Pod重新添加到svc的ep列表中。
- 如果容器没有提供可用性检查,则默认状态为Success。
16.5.1. readinessProbe之exec: 检测命令执行是否成功
(1)编写资源清单(包含rc,svc)
cat > readiessprobe-exec.yaml <<EOF
apiVersion: v1
kind: ReplicationController
metadata:name: rc-readinessprobe-execnamespace: defaultlabels:v1: tomv2: jack
spec:replicas: 3selector:hobby: gamebook: sanguotemplate:metadata:namespace: defaultlabels:hobby: gamebook: sanguoage: "18"spec:containers:- name: webimage: nginx:alpine# 可用性检查,周期性执行命令是否成功,从而判断容器是否就绪.readinessProbe:# 使用exec的方式去做健康检查exec:# 自定义检查的命令command:- ls- /usr/share/nginx/html/index.htmlfailureThreshold: 3initialDelaySeconds: 15periodSeconds: 1successThreshold: 1timeoutSeconds: 1
---
apiVersion: v1
kind: Service
metadata:name: svc-readinessprobe-execnamespace: defaultlabels:apps: svc-read
spec:selector:hobby: gamebook: sanguotype: ClusterIPports:- port: 80targetPort: 80protocol: TCP#clusterIP: 10.100.100.200
EOF(2)创建资源清单
[root@k8s231 probe]# kubectl apply -f readiessprobe-exec.yaml(3)查看Pod状态(三个pod里面的容器都是未就绪状态,15秒内是未就绪状态(用了readinessProbe默认就是未就绪),15秒后,命令检测成功了就变为就绪状态了)
#15秒内是未就绪状态
[root@k8s231 probe]# kubectl get pods
NAME READY STATUS RESTARTS AGE
rc-readinessprobe-exec-4z5zs 1/1 Running 0 32s
rc-readinessprobe-exec-7jfgb 1/1 Running 0 32s
rc-readinessprobe-exec-qdk75 1/1 Running 0 32s
#15秒后,命令检测成功了就变为就绪状态了
[root@k8s231 probe]# kubectl get pods
NAME READY STATUS RESTARTS AGE
rc-readinessprobe-exec-4z5zs 1/1 Running 0 5m46s
rc-readinessprobe-exec-7jfgb 1/1 Running 0 5m46s
rc-readinessprobe-exec-qdk75 1/1 Running 0 5m46s(4)查看svc的状态
[root@k8s231 probe]# kubectl get svc --show-labels
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE LABELS
kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 6d component=apiserver,provider=kubernetes
svc-readinessprobe-exec ClusterIP 10.100.141.130 <none> 80/TCP 5m16s apps=svc-read(5)查看ep(ENDPOINTS)的状态
[root@k8s231 probe]# kubectl get ep
NAME ENDPOINTS AGE
kubernetes 10.0.0.231:6443 6d1h
svc-readinessprobe-exec 10.200.1.36:80,10.200.1.37:80,10.200.2.34:80 4m30s(6)查看svc的详细信息ep(此时Endpoints为空)
[root@k8s231 probe]# kubectl describe svc svc-readinessprobe-exec|grep Endpoints
Endpoints: 10.200.1.36:80,10.200.1.37:80,10.200.2.34:80(7)查看ep详细信息中的就绪地址和未就绪地址
[root@k8s231 probe]# kubectl describe ep svc-readinessprobe-exec |grep -i addressAddresses: 10.200.1.36,10.200.1.37,10.200.2.34NotReadyAddresses: <none>(8)将任意2个Pod调整为未就绪状态
[root@k8s231 probe]# kubectl exec rc-readinessprobe-exec-4z5zs -- rm /usr/share/nginx/html/index.html
[root@k8s231 probe]# kubectl exec rc-readinessprobe-exec-7jfgb -- rm /usr/share/nginx/html/index.html(9)查看pod状态,发现有2个pod状态已经变为就绪了
[root@k8s231 probe]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
rc-readinessprobe-exec-4z5zs 0/1 Running 0 6m41s 10.200.1.36 k8s232.tom.com <none> <none>
rc-readinessprobe-exec-7jfgb 0/1 Running 0 6m41s 10.200.1.37 k8s232.tom.com <none> <none>
rc-readinessprobe-exec-qdk75 1/1 Running 0 6m41s 10.200.2.34 k8s233.tom.com <none> <none>(9)查看ep(ENDPOINTS)的状态(发现只有1个就绪的pod的ip了)
[root@k8s231 probe]# kubectl get ep
NAME ENDPOINTS AGE
kubernetes 10.0.0.231:6443 6d1h
svc-readinessprobe-exec 10.200.2.34:80 6m58s(10)查看svc的详细信息ep(此时Endpoints只有1个就绪的pod的ip了)
[root@k8s231 probe]# kubectl describe svc svc-readinessprobe-exec|grep Endpoints
Endpoints: 10.200.2.34:80(11)查看ep详细信息中的就绪地址和未就绪地址(1个就绪ip,2个未就绪ip)
[root@k8s231 probe]# kubectl describe ep svc-readinessprobe-exec |grep -i addressAddresses: 10.200.2.34NotReadyAddresses: 10.200.1.36,10.200.1.37(12)删除案例(rc和svc一起删除)
[root@k8s231 probe]# kubectl delete -f readiessprobe-exec.yaml
replicationcontroller "rc-readinessprobe-exec" deleted
service "svc-readinessprobe-exec" deleted16.5.2. readinessProbe之httpGet:检测页面是否能访问
(1)编写资源清单(包含rc,svc)
cat > readiessprobe-httpget.yaml <<EOF
apiVersion: v1
kind: ReplicationController
metadata:name: rc-readinessprobe-httpgetnamespace: defaultlabels:v1: tomv2: jack
spec:replicas: 3selector:hobby: gamebook: sanguotemplate:metadata:namespace: defaultlabels:hobby: gamebook: sanguoage: "18"spec:containers:- name: webimage: nginx:alpine# 可用性检查,周期性检查页面是否能访问,从而判断容器是否就绪.readinessProbe:# 使用httpGet的方式去做健康检查httpGet:# 指定访问的端口号port: 80# 检测指定的访问路径path: /index.htmlfailureThreshold: 3initialDelaySeconds: 15periodSeconds: 1successThreshold: 1timeoutSeconds: 1
---
apiVersion: v1
kind: Service
metadata:name: svc-readinessprobe-httpgetnamespace: defaultlabels:apps: svc-read
spec:selector:hobby: gamebook: sanguotype: ClusterIPports:- port: 80targetPort: 80protocol: TCP#clusterIP: 10.100.100.200
EOF(2)创建资源清单
kubectl apply -f readiessprobe-httpget.yaml(3)查看Pod状态
[root@k8s231 probe]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
rc-readinessprobe-httpget-hqtgd 1/1 Running 0 70s age=18,book=sanguo,hobby=game
rc-readinessprobe-httpget-kvk6q 1/1 Running 0 70s age=18,book=sanguo,hobby=game
rc-readinessprobe-httpget-w52h5 1/1 Running 0 70s age=18,book=sanguo,hobby=game(4)查看svc的状态
[root@k8s231 probe]# kubectl get svc --show-labels
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE LABELS
kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 6d1h component=apiserver,provider=kubernetes
svc-readinessprobe-httpget ClusterIP 10.100.112.29 <none> 80/TCP 6s apps=svc-read(5)查看ep(ENDPOINTS)的状态
[root@k8s231 probe]# kubectl get ep
NAME ENDPOINTS AGE
kubernetes 10.0.0.231:6443 6d1h
svc-readinessprobe-exec 10.200.1.38:80,10.200.2.35:80,10.200.2.36:80 21s(6)查看svc的详细信息ep
[root@k8s231 probe]# kubectl describe svc svc-readinessprobe-exec|grep Endpoints
Endpoints: 10.200.1.38:80,10.200.2.35:80,10.200.2.36:80(7)查看ep详细信息中的就绪地址和未就绪地址
[root@k8s231 probe]# kubectl describe ep svc-readinessprobe-exec |grep -i addressAddresses: 10.200.1.38,10.200.2.35,10.200.2.36NotReadyAddresses: <none>(8)将任意2个Pod调整为未就绪状态
[root@k8s231 probe]# kubectl exec rc-readinessprobe-httpget-hqtgd -- rm /usr/share/nginx/html/index.html
[root@k8s231 probe]# kubectl exec rc-readinessprobe-httpget-kvk6q -- rm /usr/share/nginx/html/index.html(9)查看pod状态,发现有2个pod状态已经变未就绪了
[root@k8s231 probe]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
rc-readinessprobe-httpget-hqtgd 0/1 Running 0 2m55s 10.200.2.36 k8s233.tom.com <none> <none>
rc-readinessprobe-httpget-kvk6q 0/1 Running 0 2m55s 10.200.2.35 k8s233.tom.com <none> <none>
rc-readinessprobe-httpget-w52h5 1/1 Running 0 2m55s 10.200.1.38 k8s232.tom.com <none> <none>(9)查看ep(ENDPOINTS)的状态(发现有2个就绪的pod的ip了)
[root@k8s231 probe]# kubectl get ep
NAME ENDPOINTS AGE
kubernetes 10.0.0.231:6443 6d1h
svc-readinessprobe-httpget 10.200.1.38:80 3m15s(10)查看svc的详细信息ep(此时Endpoints有2个就绪的pod的ip了)
[root@k8s231 probe]# kubectl describe svc svc-readinessprobe-httpget|grep Endpoints
Endpoints: 10.200.1.38:80(11)查看ep详细信息中的就绪地址和未就绪地址
[root@k8s231 probe]# kubectl describe ep svc-readinessprobe-httpget |grep -i addressAddresses: 10.200.1.38NotReadyAddresses: 10.200.2.35,10.200.2.36(12)删除案例(rc和svc一起删除)
[root@k8s231 probe]# kubectl delete -f readiessprobe-httpget.yaml 16.5.3. readinessProbe之tcpSocket:检测端口连通性
(1)编写资源清单(包含rc,svc)
cat > readiessprobe-tcpsocket.yaml <<EOF
apiVersion: v1
kind: ReplicationController
metadata:name: rc-readinessprobe-tcpsocketnamespace: defaultlabels:v1: tomv2: jack
spec:replicas: 3selector:hobby: gamebook: sanguotemplate:metadata:namespace: defaultlabels:hobby: gamebook: sanguoage: "18"spec:containers:- name: webimage: nginx:alpine# 可用性检查,周期性检查服务是否可用,从而判断容器是否就绪.readinessProbe:# 使用tcpSocket的方式去做健康检查tcpSocket:port: 80failureThreshold: 3initialDelaySeconds: 15periodSeconds: 1successThreshold: 1timeoutSeconds: 1
---
apiVersion: v1
kind: Service
metadata:name: svc-readinessprobe-tcpsocketnamespace: defaultlabels:apps: svc-read
spec:selector:hobby: gamebook: sanguotype: ClusterIPports:- port: 80targetPort: 80protocol: TCP#clusterIP: 10.100.100.200
EOF(2)创建资源清单
[root@k8s231 probe]# kubectl apply -f readiessprobe-tcpsocket.yaml(3)查看Pod状态(三个pod里面的容器都是未就绪状态)
[root@k8s231 probe]# kubectl get pod --show-labels
NAME READY STATUS RESTARTS AGE LABELS
rc-readinessprobe-tcpsocket-jpqv5 0/1 Running 0 10s age=18,book=sanguo,hobby=game
rc-readinessprobe-tcpsocket-p8bhk 0/1 Running 0 10s age=18,book=sanguo,hobby=game
rc-readinessprobe-tcpsocket-wnrvg 0/1 Running 0 10s age=18,book=sanguo,hobby=game(4)查看svc的状态
[root@k8s231 probe]# kubectl get svc --show-labels
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE LABELS
kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 6d1h component=apiserver,provider=kubernetes
svc-readinessprobe-tcpsocket ClusterIP 10.100.67.17 <none> 80/TCP 20s apps=svc-read(5)查看ep(ENDPOINTS)的状态
[root@k8s231 probe]# kubectl get ep --show-labels
NAME ENDPOINTS AGE LABELS
kubernetes 10.0.0.231:6443 6d1h endpointslice.kubernetes.io/skip-mirror=true
svc-readinessprobe-tcpsocket 10.200.1.42:80,10.200.1.43:80,10.200.2.40:80 30s apps=svc-read(6)查看svc的详细信息ep
[root@k8s231 probe]# kubectl describe svc svc-readinessprobe-tcpsocket|grep Endpoints
Endpoints: 10.200.1.42:80,10.200.1.43:80,10.200.2.40:80(7)查看ep详细信息中的就绪地址和未就绪地址
[root@k8s231 probe]# kubectl describe ep svc-readinessprobe-tcpsocket |grep -i addressAddresses: 10.200.1.42,10.200.1.43,10.200.2.40NotReadyAddresses: <none>(8)将任意2个Pod调整为未就绪状态(将80端口变为88端口)
[root@k8s231 probe]# kubectl exec rc-readinessprobe-tcpsocket-jpqv5 -- sh -c " sed -i 's#80#88#g' /etc/nginx/conf.d/default.conf; nginx -s reload"
[root@k8s231 probe]# kubectl exec rc-readinessprobe-tcpsocket-p8bhk -- sh -c " sed -i 's#80#88#g' /etc/nginx/conf.d/default.conf; nginx -s reload"(9)查看pod状态,发现有2个pod状态已经变未就绪了
[root@k8s231 probe]# kubectl get pods
NAME READY STATUS RESTARTS AGE
rc-readinessprobe-tcpsocket-jpqv5 0/1 Running 0 2m26s
rc-readinessprobe-tcpsocket-p8bhk 0/1 Running 0 2m26s
rc-readinessprobe-tcpsocket-wnrvg 1/1 Running 0 2m26s(9)查看ep(ENDPOINTS)的状态(发现有2个就绪的pod的ip了)
[root@k8s231 probe]# kubectl get ep
NAME ENDPOINTS AGE
kubernetes 10.0.0.231:6443 6d1h
svc-readinessprobe-tcpsocket 10.200.1.42:80 2m47s(10)查看svc的详细信息ep(此时Endpoints有2个就绪的pod的ip了)
[root@k8s231 probe]# kubectl describe svc svc-readinessprobe-tcpsocket|grep Endpoints
Endpoints: 10.200.1.42:80(11)查看ep详细信息中的就绪地址和未就绪地址
[root@k8s231 probe]# kubectl describe ep svc-readinessprobe-tcpsocket |grep -i addressAddresses: 10.200.1.42NotReadyAddresses: 10.200.1.43,10.200.2.40(12)删除案例(rc和svc一起删除)
[root@k8s231 probe]# kubectl delete -f readiessprobe-tcpsocket.yaml 16.6. startupProbe探针使用方法
startupProbe:启动探针 (1.16+之后的版本才支持)
- 如果提供了启动探针,则所有其他探针都会被禁用,直到此探针成功为止。
- 如果启动探测失败,kubelet将杀死容器,而容器依其重启策略进行重启。
- 如果容器没有提供启动探测,则默认状态为 Success。
- 优先级高于readinessprobe和livenessprobe
16.6.1. 三种探针一起使用的案例
(1)编写资源清单(包含rc,svc)
cat > probe.yaml <<EOF
apiVersion: v1
kind: ReplicationController
metadata:name: rc-probenamespace: defaultlabels:v1: tomv2: jack
spec:replicas: 3selector:hobby: gamebook: sanguotemplate:metadata:namespace: defaultlabels:hobby: gamebook: sanguoage: "18"spec:containers:- name: webimage: nginx:alpine# 可用性检查,周期性检查服务是否可用,从而判断容器是否就绪.livenessProbe:tcpSocket:port: 80failureThreshold: 3initialDelaySeconds: 15periodSeconds: 1successThreshold: 1timeoutSeconds: 1 readinessProbe:httpGet: port: 80path: /read.htmlfailureThreshold: 3initialDelaySeconds: 15periodSeconds: 3successThreshold: 1timeoutSeconds: 1startupProbe:exec:command:- ls- /usr/share/nginx/html/index.htmlfailureThreshold: 3initialDelaySeconds: 15periodSeconds: 3successThreshold: 1timeoutSeconds: 1
---
apiVersion: v1
kind: Service
metadata:name: svc-probenamespace: defaultlabels:apps: svc-probe
spec:selector:hobby: gamebook: sanguotype: ClusterIPports:- port: 80targetPort: 80protocol: TCP#clusterIP: 10.100.100.200
EOF(2)创建资源清单
[root@k8s231 probe]# kubectl apply -f probe.yaml(3)查看Pod状态(startupProbe检查成功,liveness-probe成功,readinessProbe失败)
[root@k8s231 probe]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
rc-readiess-liveness-probe-7m6zl 0/1 Running 0 92s age=18,book=sanguo,hobby=game
rc-readiess-liveness-probe-ms5wt 0/1 Running 0 93s age=18,book=sanguo,hobby=game
rc-readiess-liveness-probe-sq74z 0/1 Running 0 92s age=18,book=sanguo,hobby=game(4)startupProbe只在启动的时候检测,成功启动后,删除/usr/share/nginx/html/index.html,startupProbe就不会再次检测了
[root@k8s231 probe]# kubectl exec rc-probe-k8sgx -- rm -f /usr/share/nginx/html/index.html[root@k8s231 probe]# kubectl get pods
NAME READY STATUS RESTARTS AGE
rc-probe-k8sgx 0/1 Running 0 4m38s
rc-probe-ksjmj 0/1 Running 0 4m38s
rc-probe-swsxl 0/1 Running 0 4m38s(5)livenessProbe检测80端口,这里把80端口改为88端口,会触发容器重启
[root@k8s231 probe]# kubectl exec rc-probe-k8sgx -- sh -c " sed -i 's#80#88#g' /etc/nginx/conf.d/default.conf; nginx -s reload"
[root@k8s231 probe]# kubectl get pods
NAME READY STATUS RESTARTS AGE
rc-probe-k8sgx 0/1 Running 1 (1s ago) 9m10s
rc-probe-ksjmj 0/1 Running 0 9m10s
rc-probe-swsxl 0/1 Running 0 9m10s(6)readinessProbe检测/read.html,这里创建这个文件,pod状态就会变为就绪
[root@k8s231 probe]# kubectl exec rc-probe-k8sgx -- sh -c "echo 1 > /usr/share/nginx/html/read.html"
[root@k8s231 probe]# kubectl get pods
NAME READY STATUS RESTARTS AGE
rc-probe-k8sgx 1/1 Running 1 (3m28s ago) 12m
rc-probe-ksjmj 0/1 Running 0 12m
rc-probe-swsxl 0/1 Running 0 12m(7)删除案例(rc和svc一起删除)
[root@k8s231 probe]# kubectl delete -f probe.yaml17. 初始化容器(init container)
初始化容器用到的字段为initContainers。
Init Container 是一种特殊容器,顾名思义是用来做初始化工作的容器,可以是一个或者多个,如果有多个的话,这些容器会按定义的顺序依次执行,只有所有的Init Container执行完后,主容器才会被启动
举个例子: 下面的例子定义了一个具有 2 个 Init 容器的简单 Pod。第一个等待 myservice 启动, 第二个等待 mydb 启动。一旦这两个 Init 容器都启动完成,Pod 将启动 spec 节中的应用容器。
apiVersion: v1
kind: Pod
metadata:name: myapp-podlabels:app.kubernetes.io/name: MyApp
spec:containers:- name: myapp-containerimage: busybox:1.28command: ['sh', '-c', 'echo The app is running! && sleep 3600']initContainers:- name: init-myserviceimage: busybox:1.28command: ['sh', '-c', "until nslookup myservice.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for myservice; sleep 2; done"]- name: init-mydbimage: busybox:1.28command: ['sh', '-c', "until nslookup mydb.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for mydb; sleep 2; done"]18. Pod的安全上下文securityContext
安全上下文(Security Context)定义 Pod 或 Container 的特权与访问控制设置
kubectl explain po.spec.containers.securityContext
kubectl explain po.spec.securityContext
https://kubernetes.io/zh-cn/docs/tasks/configure-pod-container/security-context/参考案例:(1)编写dockerfile
[root@k8s231 ]# mkdir -p cd /docker/securityContext && cd /docker/securityContext
[root@k8s231 securityContext]# cat > Dockerfile <<EOF
FROM centos:7
RUN curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
RUN yum -y install iptables-services net-tools && rm -rf /var/cache/yum
RUN useradd -u 666 tom
CMD ["tail","-f","/etc/hosts"]
EOF
[root@k8s231 securityContext]# cat > build.sh <<EOF
#!/bin/bash
docker image build -t harbor.tom.com/library/centos7-iptabls:v0.1 .
docker login -u admin -padmin harbor.tom.com
docker image push harbor.tom.com/library/centos7-iptabls:v0.1
docker logout harbor.tom.com
EOF(2)部署pod测试
[root@k8s231 pods]# cd /manifests/pods
[root@k8s231 pods]# cat > pod-securityContext.yaml <<EOF
apiVersion: v1
kind: Pod
metadata:name: pod-securitycontext
spec:containers:- name: c1image: harbor.tom.com/library/centos7-iptabls:v0.1# 配置Pod的安全相关属性securityContext:# 配置容器为特权容器,若配置了特权容器,可能对capabilities测试有影响哟!#privileged: true# 自定义LINUX内核特性# 推荐阅读:# https://man7.org/linux/man-pages/man7/capabilities.7.html# https://docs.docker.com/compose/compose-file/compose-file-v3/#cap_add-cap_dropcapabilities:# 添加所有的Linux内核功能add:- ALL# 移除指定Linux内核特性drop:# 代表禁用网络管理的配置,# - NET_ADMIN# 代表禁用UID和GID,表示你无法使用chown命令哟 - CHOWN# # 代表禁用chroot命令- SYS_CHROOT# 如果容器的进程以root身份运行,则禁止容器启动!# runAsNonRoot: true# 指定运行程序的用户UID,注意,该用户的UID必须存在!runAsUser: 666
EOF[root@k8s231 pods]# kubectl apply -f pod-securityContext.yaml [root@k8s231 pods]# kubectl exec -it pod-securitycontext -- bash
[tom@pod-securitycontext /]$ whoami
tom19. pod生命周期lifecycle
Pod的生命周期优雅的终止案例:
[root@k8s231 pods]# cat > pod-lifecycle-postStart-preStop.yaml <<EOF
apiVersion: v1
kind: Pod
metadata:name: lifecycle-001
spec:nodeName: k8s232.tom.comvolumes:- name: datahostPath:path: /tom-data# 在pod优雅终止时,定义延迟发送kill信号的时间,此时间可用于pod处理完未处理的请求等状况。# 默认单位是秒,若不设置默认值为30s。terminationGracePeriodSeconds: 60containers:- name: mywebimage: nginx:alpinestdin: truevolumeMounts:- name: datamountPath: /data/# 定义Pod的生命周期。lifecycle:# Pod启动之后做的事情postStart:exec:command: - "/bin/sh"- "-c"- "echo \"postStart at $(date +%F_%T)\" >> /data/postStart.log"# Pod停止之前做的事情preStop:exec:command: - "/bin/sh"- "-c"- "echo \"preStop at $(date +%F_%T)\" >> /data/preStop.log"
EOF[root@k8s231 pods]# kubectl apply -f pod-lifecycle-postStart-preStop.yaml#在232节点上查看日志
[root@k8s232 ~]# cat /tom-data/*.log
postStart at 2024-08-09_22:05:57[root@k8s231 pods]# kubectl delete -f pod-lifecycle-postStart-preStop.yaml#在232节点上查看日志
[root@k8s232 ~]# cat /tom-data/*.log
postStart at 2024-08-09_22:05:57
preStop at 2024-08-09_22:05:5720. pod创建流程
1.用户发起请求:
用户通过响应式或者声明式提交创建pod请求,请求信息包含容器镜像、环境变量、资源需求、卷挂载等2.格式解析,认证,权限校验(apiServer):
用户的请求首先到达apiServer,会对请求进行认证、授权和准入控制检查。3.pod信息存储(etcd):
apiServer认定请求有效后,它会将Pod的定义信息写入etcd(分布式键值存储),以确保集群内的所有组件都能获取最新的集群状态。
这标志着Pod在k8s集群中已被创建并存在,尽管此刻它还没有被调度到任何节点上运行4.controller manager管理集群
controller manager会通过API Server提供的接口实时监控资源对象的当前状态
控制器计算需要创建的Pod副本数量,并根据Pod模板创建出相应数量的Pods,维护集群状态5.调度决策(scheduler):
Scheduler监听apiserver中创建的Pod事件,基于节点的资源可用性、硬件等因素,选择最适合运行该Pod的节点,然后把信息告知apiserver6.apiserver将调度结果存入etcd:
scheduler将Pod绑定Node的结果发给API Server,由API Server写入etcd7.节点上部署pod(kubelet):
被选定Pod的节点上的kubelet监听到APIServer发送的Pod更新的事件后,开始创建pod
1.创建Pause基础网路镜像容器
2.创建initcontainers初始化容器
3.创建业务容器1.容器启动后,执行poststart操作2.容器启动后,执行startupProbe探针,判断是否继续运行3.执行readinessProbe和livenessProbe探针4.容器退出前,执行prestop21. 静态Pod(了解即可):
vim /var/lib/kubelet/config.yaml ...
staticPodPath: /etc/kubernetes/manifests
温馨提示:
(1)静态Pod是由kubelet启动时通过"staticPodPath"配置参数指定路径
(2)静态Pod创建的Pod名称会自动加上kubelet节点的主机名,比如"k8s231.tom.com"
(3)静态Pod的创建并不依赖API-Server,而是直接基于kubelet所在节点来启动Pod;
(4)静态Pod的删除只需要将其从staticPodPath指定的路径移除即可;
(5)静态Pod路径仅对Pod资源类型有效,其他类型资源将不被创建
(6)kubeadm部署方式就是基于静态Pod部署的;
22. 控制器之RS(ReplicaSet)副本控制器
replicaset作用: 控制Pod的副本数量。
和rc相比: 功能更加强大,不仅仅支持标签匹配,还支持表达式匹配。
rs的Pod控制器实战案例:
mkdir
[root@k8s231 replicasets]# cat 01-rs-matchlabels.yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:name: rs-matchlabels
spec: replicas: 5 selector: matchLabels: apps: webtemplate:metadata:labels:apps: weblevel: L1spec:containers:- name: webimage:nginx:alpine[root@k8s231 replicasets]# cat 02-rs-matchexpressions.yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:name: rs-matchexpressions
spec: replicas: 5 selector:# 基于表达式匹配matchExpressions:- key: apps# 当operator的值为In或者NotIn时,values的值不能为空。# values:# - haha# - xixi# 当operator的值为Exists或者DoesNotExist时,values的值必须为空.operator: Exists# 定义Pod资源创建的模板template:metadata:labels:apps: webspec:containers:- name: webimage: nginx:alpine23. 控制器之Deployment
- Deployment是k8s中用来管理发布的控制器
- Deployment滚动更新的实现,依赖的是Kubernetes中的ReplicaSet
- Deployment控制器实际操纵的,就是Replicas对象,而不是Pod对象。对于Deployment、ReplicaSet、Pod它们的关系如下图:

#(1)创建deploy资源清单
]# cat > 01-deployment.yaml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:name: nginx-deploymentlabels:app: nginx
spec:replicas: 2 selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:hostNetwork: truecontainers:- name: nginximage: nginx:1.12.2ports:- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:name: svc-deploy-nginx
spec:selector:app: nginxtype: ClusterIPports:- port: 80targetPort: 80clusterIP: 10.100.1.11
EOF#(2)创建deploy资源
]# kubectl apply -f 01-deployment.yaml#(3)查看deploy,rs,pods资源
]# kubectl get deploy,rs,svc,pod -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
deployment.apps/nginx-deployment 2/2 2 2 10s nginx nginx:1.12 app=nginxNAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
replicaset.apps/nginx-deployment-84fc49578f 2 2 2 10s nginx nginx:1.12 app=nginx,pod-template-hash=84fc49578fNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service/kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 12s <none>
service/svc-deploy-nginx ClusterIP 10.100.1.11 <none> 80/TCP 9s app=nginxNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/nginx-deployment-84fc49578f-64kqb 1/1 Running 0 10s 10.200.1.61 k8s232.tom.com <none> <none>
pod/nginx-deployment-84fc49578f-r4v5k 1/1 Running 0 9s 10.200.2.51 k8s233.tom.com <none> <none>#(4)验证nginx版本号
]# curl 10.100.1.11 -I|& grep Server
Server: nginx/1.12.2#(5)版本升级#响应式-非交互修改
]# kubectl set image deployment nginx-deployment nginx=nginx:1.13#响应式-交互修改
]# kubectl edit deployments.apps nginx-deployment #声明式修改
]# vim 01-deployment.yaml
]# kubectl apply -f 01-deployment.yaml#(6)查看deploy,rs,pods资源
]# kubectl get deploy,rs,svc,pod -o wide
NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
deployment.apps/nginx-deployment 2/2 2 2 71s nginx nginx:1.13 app=nginxNAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
replicaset.apps/nginx-deployment-6bc9989998 2 2 2 5s nginx nginx:1.13 app=nginx,pod-template-hash=6bc9989998
replicaset.apps/nginx-deployment-84fc49578f 0 0 0 71s nginx nginx:1.12 app=nginx,pod-template-hash=84fc49578fNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service/kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 73s <none>
service/svc-deploy-nginx ClusterIP 10.100.1.11 <none> 80/TCP 70s app=nginxNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/nginx-deployment-6bc9989998-fzhjj 1/1 Running 0 5s 10.200.2.52 k8s233.tom.com <none> <none>
pod/nginx-deployment-6bc9989998-j7lxd 1/1 Running 0 3s 10.200.1.62 k8s232.tom.com <none> <none>#(7)验证nginx版本号
]# curl 10.100.1.11 -I|& grep Server
Server: nginx/1.13.12#(8)deployment查看历史版本,共2个版本,说明进行了1次升级
]# kubectl rollout history deployment nginx-deployment
deployment.apps/nginx-deployment
REVISION CHANGE-CAUSE
1 <none>
2 <none>#(8)deployment 回滚到之前的版本,加上--to-revision= 指定到之前哪个版本
]# kubectl rollout undo deployment nginx-deployment --to-revision=1
]# curl 10.100.1.11 -I|& grep Server
Server: nginx/1.12.223.1. strategy升级策略
#strategy更新策略,分recreate和rollingUpdate(默认方式),可定制修改
apiVersion: apps/v1
kind: Deployment
metadata:name: nginx-deployment
spec:strategy:# 定义升级策略strategy:# 升级的类型,"Recreate" or "RollingUpdate"# Recreate:# 先停止所有的Pod运行,然后在批量创建更新。# 生产环节中不推荐使用这种策略,因为升级过程中用户将无法访问服务!# RollingUpdate:# 滚动更新,即先实现部分更新,逐步替换原有的pod,是默认策略。# type: Recreatetype: RollingUpdate# 自定义滚动更新的策略rollingUpdate:# 在原有Pod的副本基础上,多启动Pod的数量。# maxSurge: 2maxSurge: 3# 在升级过程中最大不可访问的Pod数量.# maxUnavailable: 1maxUnavailable: 223.2. deployment实现蓝绿发布
蓝绿部署(Blue/Green)特点:
- 1.不需要停止老版本代码(不影响上一版本访问),而是在另外一套环境部署新版本然后进行测试。
- 2.测试通过后将用户流量切换到新版本,其特点为业务无中断,升级风险相对较小。
deployment实现蓝绿发布步骤:
- 1.部署当前版本
- 2.部署service
- 3.部署新版本(使用新的deployment名称,新的label标签)
- 4.切换service标签到新的pod
蓝绿部署案例:(1) 部署蓝环境
[root@k8s231 blue-green]# cat > 01-deployment-blue.yaml <<EOF
kind: Deployment
apiVersion: apps/v1
metadata:name: blue
spec:replicas: 3selector:matchLabels:app: bluetemplate:metadata:labels:app: bluespec:containers:- name: nginximage: nginx:1.12
EOF
[root@k8s231 blue-green]# kubectl apply -f 01-deployment-blue.yaml (2) 创建svc资源
[root@k8s231 blue-green]# cat > 02-svc-deployment.yaml <<EOF
kind: Service
apiVersion: v1
metadata:name: svc-blue
spec: type: NodePortports:- port: 80targetPort: 80nodePort: 30080selector:app: blue
EOF[root@k8s231 blue-green]# kubectl apply -f 02-svc-deployment.yaml(3) 查看pod,svc资源
[root@k8s231 bluegreen]# kubectl get pod,svc -o wide --show-labels
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
pod/blue-78f5fcbcb-494k6 1/1 Running 0 5m15s 10.200.2.81 k8s233.tom.com <none> <none> app=blue,pod-template-hash=78f5fcbcb
pod/blue-78f5fcbcb-jcn6l 1/1 Running 0 5m15s 10.200.1.95 k8s232.tom.com <none> <none> app=blue,pod-template-hash=78f5fcbcb
pod/blue-78f5fcbcb-wnzx8 1/1 Running 0 5m15s 10.200.2.80 k8s233.tom.com <none> <none> app=blue,pod-template-hash=78f5fcbcbNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR LABELS
service/kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 5m11s <none> component=apiserver,provider=kubernetes
service/svc-deployment NodePort 10.100.20.177 <none> 80:30080/TCP 10s app=blue <none>(4)单独开一个窗口观察外部入口访问结果,蓝部署后结果是1.12,绿部署并切换svc后,结果就是1.13了
[root@k8s231 ~]# while true ; do sleep 0.5;curl 10.0.0.233:30080 -I |& grep Server; done(5)部署绿环境
[root@k8s231 blue-green]# cat > 03-deployment-green.yaml <<EOF
kind: Deployment
apiVersion: apps/v1
metadata:name: green
spec:replicas: 3selector:matchLabels:app: greentemplate:metadata:labels:app: greenspec:containers:- name: nginximage: nginx:1.13
EOF
[root@k8s231 blue-green]# kubectl apply -f 03-deployment-green.yaml (6)切换svc的标签,修改selector中app为green:
[root@k8s231 blue-green]# cat > 02-svc-deployment.yaml <<EOF
kind: Service
apiVersion: v1
metadata:name: svc-deployment
spec: type: NodePortports:- port: 80targetPort: 80nodePort: 30080selector:app: green
EOF[root@k8s231 blue-green]# kubectl apply -f 02-svc-deployment.yaml(7)红绿环境都存在,svc的selector已经变为green
[root@k8s231 bluegreen]# kubectl get pod,svc -o wide --show-labels
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
pod/blue-78f5fcbcb-494k6 1/1 Running 0 8m7s 10.200.2.81 k8s233.tom.com <none> <none> app=blue,pod-template-hash=78f5fcbcb
pod/blue-78f5fcbcb-jcn6l 1/1 Running 0 8m7s 10.200.1.95 k8s232.tom.com <none> <none> app=blue,pod-template-hash=78f5fcbcb
pod/blue-78f5fcbcb-wnzx8 1/1 Running 0 8m7s 10.200.2.80 k8s233.tom.com <none> <none> app=blue,pod-template-hash=78f5fcbcb
pod/green-74b6476b55-2wbrr 1/1 Running 0 5m37s 10.200.1.96 k8s232.tom.com <none> <none> app=green,pod-template-hash=74b6476b55
pod/green-74b6476b55-rnkbr 1/1 Running 0 5m37s 10.200.2.82 k8s233.tom.com <none> <none> app=green,pod-template-hash=74b6476b55
pod/green-74b6476b55-s7t4m 1/1 Running 0 5m37s 10.200.1.97 k8s232.tom.com <none> <none> app=green,pod-template-hash=74b6476b55NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR LABELS
service/kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 8m3s <none> component=apiserver,provider=kubernetes
service/svc-deployment NodePort 10.100.20.177 <none> 80:30080/TCP 3m2s app=green <none>23.3. deployment实现灰度发布
deployment实现灰度发布步骤:
1.部署当前版本,使用多副本;(最开始是3个副本)
2.部署service,匹配一个label标签;
3.部署新版本(使用deployment名称,但是label标签和之前保持一致),新版本runing之后service会自动匹配label并将pod添加service的endpoints接收客户端请求;(最开始)
4.灰度版本测试没有问题,将灰度版本的pod副本数逐渐增加为生产数量;
5.将旧版本pod逐渐调低至为0,此时数流量将全部转发至新版本;
灰度发布实战案例:(逐渐增加新版本的副本数,将旧版本副本逐渐调低到0)(1)部署旧版本
[root@k8s231 grayrelease]# cat > 01-deploy-old.yaml <<EOF
kind: Deployment
apiVersion: apps/v1
metadata:name: old
spec:replicas: 3selector:matchLabels:app: webtemplate:metadata:labels:app: webspec:containers:- name: mywebimage: nginx:1.12.2
EOF
[root@k8s231 grayrelease]# kubectl apply -f 01-deploy-old.yaml(2)创建svc
[root@k8s231 grayrelease]# cat > 02-svc-deployment.yaml <<EOF
kind: Service
apiVersion: v1
metadata:name: svc-deploy
spec:type: NodePortports:- port: 80targetPort: 80nodePort: 30080selector:app: web
EOF
[root@k8s231 grayrelease]# kubectl apply -f 02-svc-deployment.yaml(3)单独开一个窗口观察外部入口访问结果,随着新版本的副本数增多,结果中1.13就会逐渐增多,最后全是1.13
[root@k8s231 ~]# while true ; do sleep 0.5;curl 10.0.0.233:30080 -I |& grep Server; done(4)部署新版本(先将副本数设置为1,随着新版本的稳定,将副本逐渐调高到3)
[root@k8s231 grayrelease]# cat > 03-deploy-new.yaml <<EOF
kind: Deployment
apiVersion: apps/v1
metadata:name: new
spec:replicas: 1selector:matchLabels:app: webtemplate:metadata:labels:app: webspec:containers:- name: mywebimage: nginx:1.13.2
EOF
[root@k8s231 grayrelease]# kubectl apply -f 03-deploy-new.yaml(5)查看新旧副本数
[root@k8s231 grayrelease]# kubectl get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
new 1/1 1 1 14s
old 3/3 3 3 3m27s(6)渐近跳转新旧deploy中的副本数量,最后new的副本数调为3,old的副本数调为0
[root@k8s231 grayrelease] kubectl edit deploy new
[root@k8s231 grayrelease] kubectl edit deploy old[root@k8s231 grayrelease]# kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
new 3/3 3 3 6m24s
old 0/0 0 0 9m37s
24. add-on附加组件之 coreDNS
CoreDNS 作为其集群内的 DNS 服务,它负责处理集群内的 DNS 查询请求
使得我们在k8s内部访问各自服务名称能够拿到对应服务后面pod的IP地址
service域名解析是:<servicename>.<namespace>.svc.<clusterdomain>
servicename为service名称,
namespace为service所处的命名空间,
clusterdomain是k8s集群设计的域名后缀,默认为cluster.local
一般的,在生产环境中,我们可以直接简写为<servicename>.<namespace>即可,后面的部分保持默认即可。
如果pod与svc是在同一个命名空间,那么直接写svc即可,如 <servicename>。
stateful创建的pod,其pod的域名为:<podname>.<servicename>.<namespace>.svc.<clusterdomain>
[root@k8s231 ]# sed -n '/clusterDNS/,/clusterDomain/p' /var/lib/kubelet/config.yaml
clusterDNS:
- 10.100.0.10
clusterDomain: tom.com#测试coreDNS组件是否正常
#方式一:
# 直接使用alpine取ping您想测试的SVC名称即可,观察能否解析成对应的VIP即可。
[root@k8s231 ]# kubectl run pod-demo --image=alpine -- tail -f /etc/hosts
pod/pod-demo created
[root@k8s231 dashbord]# kubectl get deploy,pod -A|grep coredns
kube-system deployment.apps/coredns 2/2 2 2 14d
kube-system pod/coredns-6d8c4cb4d-jvvmw 1/1 Running 0 3d19h
kube-system pod/coredns-6d8c4cb4d-swzfg 1/1 Running 0 3d19h
[root@k8s231 ]# kubectl get svc -A
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 18s
kube-system kube-dns ClusterIP 10.100.0.10 <none> 53/UDP,53/TCP,9153/TCP 9d
[root@k8s231 ]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-demo 1/1 Running 0 19s 10.200.1.65 k8s232.tom.com <none> <none>
[root@k8s231 ]# kubectl exec pod-demo -- ping kubernetes
PING kubernetes (10.100.0.1): 56 data bytes
^C
[root@k8s231 ]# kubectl exec pod-demo -- ping kube-dns.kube-system
PING kube-dns.kube-system (10.100.0.10): 56 data bytes方式二:yum -y install bind-utils
[root@k8s231 deployment]# dig @10.100.0.10 kube-dns.kube-system.svc.tom.com +short
10.100.0.10
[root@k8s231 ~]# dig @10.100.0.10 kubernetes.default.svc.tom.com +short
10.100.0.1coredns使用举例
wordpress POD清单中使用,wordpress_db是mysql数据的pod名称
pod.spec.containers.env中定义连接数据库相关变量
..............
- name: WORDPRESS_DB_HOSTvalue: wordpress_db25. 控制器之Job(一次性任务)
cat > job.yaml <<'EOF'
apiVersion: batch/v1
kind: Job
metadata:name: job-01
spec:template:spec:containers:- name: helloimage: busyboxcommand: ["date"]restartPolicy: Never
EOF[root@k8s231 job]# kubectl apply -f job.yaml
job.batch/job-01 created
[root@k8s231 job]# kubectl get jobs.batch
NAME COMPLETIONS DURATION AGE
job-01 0/1 7s 7s
[root@k8s231 job]# kubectl get pod
NAME READY STATUS RESTARTS AGE
job-01-t4mzd 0/1 Completed 0 15s
[root@k8s231 job]# kubectl logs job-01-t4mzd
Mon Aug 12 15:58:48 UTC 202426. 控制器之CronJob(周期性任务)
cat > cronjob.yaml <<'EOF'
apiVersion: batch/v1
kind: CronJob
metadata:name: cronjob-01
spec:schedule: "* * * * *"jobTemplate:spec:template:spec:containers:- name: helloimage: busybox:1.28imagePullPolicy: IfNotPresentcommand: ["date"]restartPolicy: OnFailure
EOF[root@k8s231 job]# kubectl apply -f cronjob.yaml
cronjob.batch/cronjob-01 created
[root@k8s231 job]# kubectl get cronjobs.batch
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
cronjob-01 * * * * * False 0 <none> 10s
[root@k8s231 job]# kubectl get pod
NAME READY STATUS RESTARTS AGE
cronjob-01-28724640-xjmmq 0/1 Completed 0 6s
[root@k8s231 job]# kubectl logs cronjob-01-28724640-xjmmq
Mon Aug 12 16:00:01 UTC 202427. Taints(污点)
在Kubernetes中,污点(Taints)是应用在节点上的,用来表示节点应该避免调度哪些Pod。一旦节点被添加了污点,只有那些可以容忍这些污点的Pods才能被调度到这些节点上。
污点的主要目的是允许系统管理员对某些节点进行标记,以指示它们专门用于特定的任务,或者将它们排除用于一组特定的Pods
以下是如何给节点添加污点的命令:
kubectl taint nodes <node-name> key[=value]:effect
相关字段说明:
key:
字母或数字开头,可以包含字母、数字、连字符(-)、点(.)和下划线(_),最多253个字符。也可以以DNS子域前缀和单个"/"开头
value:
该值是可选的。如果给定,它必须以字母或数字开头,可以包含字母、数字、连字符、点和下划线,最多63个字符。
effect: NoExecute|NoSchedule|PreferNoSchedule
- NoExecute: 该节点不再接收新的Pod调度,与此同时,会立刻驱逐已经调度到该节点的Pod。
- NoSchedule: 该节点不再接收新的Pod调度,但不会驱赶已经调度到该节点的Pod。
- PreferNoSchedule: 该节点可以接受调度,但会尽可能将Pod调度到其他节点,换句话说,让该节点的调度优先级降低啦。
27.1. 污点案例
(1)创建deploy资源清单
[root@k8s231 taints]# cat > 01-deploy-web.yaml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:name: web
spec:replicas: 3selector:matchExpressions:- key: appsoperator: Existstemplate:metadata:labels:apps: webspec:containers:- name: webimage: nginx:1.12
EOF
[root@k8s231 taints]# kubectl apply -f 01-deploy-web.yaml (2)查看Pod调度节点
[root@k8s231 taints]# kubectl get pods -o wide | awk '{print $7}'
NODE
k8s233.tom.com
k8s232.tom.com
k8s233.tom.com
-------------------------------------------------------------------
#NoExecute污点案例(1)打污点(232打上NoExecute类型的污点,会导致232上的pod被驱逐,且不再接收新pod的调度)
[root@k8s231 taints]# kubectl taint node k8s232.tom.com level=x1:NoExecute
node/k8s232.tom.com tainted(2)打污点后
[root@k8s231 taints]# kubectl get pods -o wide | awk 'NR>1{print $7}'
k8s233.tom.com
k8s233.tom.com
k8s233.tom.com(3)查看污点
[root@k8s231 taints]# kubectl describe nodes|egrep 'Hostname|Taints'
Taints: node-role.kubernetes.io/master:NoScheduleHostname: k8s231.tom.com
Taints: level=x1:NoExecuteHostname: k8s232.tom.com
Taints: <none>Hostname: k8s233.tom.com(6)清除污点
[root@k8s231 taints]# kubectl taint node k8s232.tom.com level-
node/k8s232.tom.com untainted(7)再次修改Pod副本数量
[root@k8s231 taints]# sed -i 's#replicas:.*#replicas: 5#g' 01-deploy-web.yaml
[root@k8s231 taints]# kubectl apply -f 01-deploy-web.yaml
deployment.apps/web configured
[root@k8s231 taints]# kubectl get pods -o wide | awk 'NR>1{print $7}'
k8s233.tom.com
k8s233.tom.com
k8s233.tom.com
k8s232.tom.com
k8s232.tom.com
-------------------------------------------------------------------
#NoSchedule污点案例(1)删除pod,重新创建pod
[root@k8s231 taints]# kubectl delete -f 01-deploy-web.yaml && kubectl apply -f 01-deploy-web.yaml(2)查看pod分布的节点
[root@k8s231 taints]# kubectl get pods -o wide|awk 'NR>1{print $7}'
k8s232.tom.com
k8s233.tom.com
k8s233.tom.com(3)给node k8s233.tom.com 打上NoSchedule污点
[root@k8s231 taints]# kubectl taint node k8s233.tom.com level=x1:NoSchedule
node/k8s233.tom.com tainted(4)把pod副本数调整为5
[root@k8s231 taints]# sed -i 's#replicas:.*#replicas: 5#g' 01-deploy-web.yaml && kubectl apply -f 01-deploy-web.yaml(5)查看pod分布的节点(新增的2个pod不会分配到233)
[root@k8s231 taints]# kubectl get pods -o wide|awk 'NR>1{print $7}'
k8s232.tom.com
k8s232.tom.com
k8s233.tom.com
k8s233.tom.com
k8s232.tom.com(6)删除233上的pod
[root@k8s231 taints]# kubectl get pods -o wide|awk '/233/{print $1}'|xargs kubectl delete pod
pod "web-7fd76f585-qkfkw" deleted
pod "web-7fd76f585-t82b9" deleted(7)查看pod分布的节点(删除的2个pod不会分配到233)
[root@k8s231 taints]# kubectl get pods -o wide|awk 'NR>1{print $7}'
k8s232.tom.com
k8s232.tom.com
k8s232.tom.com
k8s232.tom.com
k8s232.tom.com(8)删除233上的污点
kubectl taint node k8s233.tom.com level--------------------------------------------------------------------
#PreferNoSchedule污点案例(1)删除pod,重新创建pod
[root@k8s231 taints]# kubectl delete -f 01-deploy-web.yaml && kubectl apply -f 01-deploy-web.yaml(2)查看pod分布的节点
[root@k8s231 taints]# kubectl get pods -o wide|awk 'NR>1{print $7}'
k8s232.tom.com
k8s232.tom.com
k8s233.tom.com
k8s233.tom.com
k8s233.tom.com(3)给node k8s233.tom.com 打上PreferNoSchedule污点
kubectl taint node k8s233.tom.com level=x1:PreferNoSchedule(4)查看污点
[root@k8s231 taints]# kubectl describe nodes|egrep 'Hostname|Taints'
Taints: node-role.kubernetes.io/master:NoScheduleHostname: k8s231.tom.com
Taints: <none>Hostname: k8s232.tom.com
Taints: level=x1:PreferNoScheduleHostname: k8s233.tom.com(5)删除233上的pod
[root@k8s231 taints]# kubectl get pods -o wide|awk '/233/{print $1}'|xargs kubectl delete pod
pod "web-7fd76f585-l7ww2" deleted
pod "web-7fd76f585-vvfwr" deleted
pod "web-7fd76f585-wc972" deleted(6)查看pod分布的节点
[root@k8s231 taints]# kubectl get pods -o wide|awk 'NR>1{print $7}'
k8s232.tom.com
k8s232.tom.com
k8s232.tom.com
k8s232.tom.com
k8s232.tom.com
(7)删除233node的污点
kubectl taint node k8s233.tom.com level-27.2. 污点容忍
使用说明
kubectl explain pod.spec.tolerations# 配置Pod的污点容忍tolerations: - key: level value: x1# 指定污点的effect,有效值为: NoSchedule, PreferNoSchedule,NoExecute# 若不指定则匹配所有的影响度。#effect: NoExecuteoperator: Equal
key: 指定污点的key, 若不指定key, 则operator的值必须为Exists,表示匹配所有的key
value: 指定污点的value,若不指定value,则operator的值必须为Exists,表示匹配指定key的所有value
effect: 指定污点的effect,有效值为: NoSchedule, PreferNoSchedule,NoExecute,若不指定则匹配所有的影响度。
operator 表示key和value的关系,有效值为Exists, Equal。Exists: 表示存在指定的key即可,若配置,则要求value字段为空。Equal:默认值,表示key=value。配置污点容忍实战案例:(1)修改污点
[root@k8s231 tolerations]# kubectl taint node k8s232.tom.com level=x1:PreferNoSchedule game=g1:NoExecute --overwrite
[root@k8s231 tolerations]# kubectl taint node k8s233.tom.com level=x1:NoExecute game=g1:NoSchedule --overwrite(2)查看污点
[root@k8s231 ipvs]# kubectl describe nodes | grep Taints -A1
Taints: node-role.kubernetes.io/master:NoSchedule
Unschedulable: false
--
Taints: game=g1:NoExecutelevel=x1:PreferNoSchedule
--
Taints: level=x1:NoExecutegame=g1:NoSchedule(3)编写资源清单(容忍三个节点上的所有污点)
[root@k8s231 tolerations]# cat 01-deploy-web.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: tolerations
spec:replicas: 5selector:matchExpressions:- key: appsvalues:- weboperator: Intemplate:metadata:labels:apps: webspec:tolerations: - key: level operator: Exists- key: gameoperator: Exists- key: node-role.kubernetes.io/masteroperator: Exists containers:- name: webimage: nginx:alpine
EOFkubectl apply -f 01-deploy-web.yaml(4)pod分布在三个有污点的节点上
[root@k8s231 tolerations]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
tolerations-6fc7bdb7b5-6blzb 1/1 Running 0 30s 10.200.0.58 k8s231.tom.com <none> <none>
tolerations-6fc7bdb7b5-b87tp 1/1 Running 0 30s 10.200.1.51 k8s232.tom.com <none> <none>
tolerations-6fc7bdb7b5-kvjc4 1/1 Running 0 30s 10.200.1.52 k8s232.tom.com <none> <none>
tolerations-6fc7bdb7b5-sz6z6 1/1 Running 0 30s 10.200.3.13 k8s233.tom.com <none> <none>
tolerations-6fc7bdb7b5-vqb9q 1/1 Running 0 30s 10.200.3.14 k8s233.tom.com <none> <none>
28. 调度器之nodeSelector(节点选择器)
NodeSelector是Kubernetes调度器的一部分,它允许开发者根据node的标签,精确地控制Pod在集群中的调度位置。通过在Pod的定义中设置NodeSelector,可以确保Pod只会被调度到具有特定标签的节点上。(nodeselector中定义的标签与node标签匹配)
NodeSelector的主要用途包括:
资源隔离: 将不同类型的应用程序或服务调度到专门标记的节点上,以便更好地隔离资源。
硬件约束: 根据节点的硬件特性(如GPU、CPU架构)将Pod调度到特定的节点上。
地理位置: 在多地域集群中,通过NodeSelector将Pod调度到特定地理位置的节点上,以降低网络延迟。
版本控制: 将Pod调度到具有特定软件版本或配置的节点上,以便更好地控制应用程序的版本。
假设我们有一个具有不同硬件配置的Kubernetes集群,其中包含既有SSD又有HDD的节点。我们有两类应用程序,一类需要高性能的SSD,另一类则对存储容量更为敏感,需要调度到HDD上。通过NodeSelector,我们可以轻松实现这一资源分配策略。
28.1. NodeSelector使用案例:
演示了如何在一个具有不同硬件配置的集群中使用:
#NodeSelector使用案例:演示了如何在一个具有不同硬件配置的集群中使用:
#232打上disktype为ssd标签
#233打上disktype为hdd标签
#ssd-deployment部署nginx1.12.2,selector选择ssd,也就是232上安装的是1.12.2
#hdd-deployment部署nginx1.13.2,selector选择hdd,也就是233上安装的是1.12.2(1)创建资源
[root@k8s231 nodeselector]# cat > nodeselector.yaml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:name: ssd-deployment
spec:replicas: 2selector:matchLabels:app: ssd-apptemplate:metadata:labels:app: ssd-appspec:containers:- name: ssd-containerimage: nginx:1.12.2nodeSelector:disktype: ssd
---
apiVersion: apps/v1
kind: Deployment
metadata:name: hdd-deployment
spec:replicas: 2selector:matchLabels:app: hdd-apptemplate:metadata:labels:app: hdd-appspec:containers:- name: hdd-containerimage: nginx:1.13.2nodeSelector:disktype: hdd
EOF
[root@k8s231 nodeselector]# kubectl label nodes k8s232.tom.com disktype=ssd
[root@k8s231 nodeselector]# kubectl label nodes k8s233.tom.com disktype=hdd
[root@k8s231 nodeselector]# kubectl apply -f nodeselector.yaml(2)查看hdd-deployment是否部署到233,ssd-deploylment是否部署到232
[root@k8s231 nodeselector]# kubectl get pod -o wide --show-labels
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
hdd-deployment-79b9bbc4d7-4hgqf 1/1 Running 0 66s 10.200.2.113 k8s233.tom.com <none> <none> app=hdd-app,pod-template-hash=79b9bbc4d7
hdd-deployment-79b9bbc4d7-pmk99 1/1 Running 0 66s 10.200.2.114 k8s233.tom.com <none> <none> app=hdd-app,pod-template-hash=79b9bbc4d7
ssd-deployment-75b677ff46-xdfjk 1/1 Running 0 66s 10.200.1.155 k8s232.tom.com <none> <none> app=ssd-app,pod-template-hash=75b677ff46
ssd-deployment-75b677ff46-xpkk9 1/1 Running 0 66s 10.200.1.154 k8s232.tom.com <none> <none> app=ssd-app,pod-template-hash=75b677ff46(3) hdd-deployment部署的是nginx:1.13.2,ssd-deployment部署的是nginx:1.12.2
[root@k8s231 nodeselector]# curl 10.200.2.113 -I|& grep Server
Server: nginx/1.13.2
[root@k8s231 nodeselector]# curl 10.200.2.114 -I|& grep Server
Server: nginx/1.13.2
[root@k8s231 nodeselector]# curl 10.200.1.155 -I|& grep Server
Server: nginx/1.12.2
[root@k8s231 nodeselector]# curl 10.200.1.154 -I|& grep Server
Server: nginx/1.12.228.2. 修改nodeport的端口范围
Kubernetes 集群中,NodePort 默认范围是 30000-32767,某些情况下,因为您所在公司的网络策略限制,您可能需要修改 NodePort 的端口范围
vim /etc/kubernetes/manifests/kube-apiserver.yaml
找到 --service-cluster-ip-range 这一行,在这一行的下一行增加 如下内容
- --service-node-port-range=1-65535#重启apiserver
kubectl delete pod kube-apiserver-k8s231.tom.com -n kube-system#验证修改是否成功
[root@k8s231 tolerations]# kubectl describe pod -n kube-system kube-apiserver-k8s231.tom.com|grep 'port-range'--service-node-port-range=1-6553529. 调度器之Affinity(亲和性)
运行时调度策略,包括nodeAffinity(主机亲和性),podAffinity(POD亲和性)以及podAntiAffinity(POD反亲和性)。
- nodeAffinity 主要解决POD要部署在哪些主机,以及POD不能部署在哪些主机上的问题,处理的是POD和主机之间的关系。
- podAffinity 主要解决哪些POD部署在同一个拓扑域中的问题(拓扑域用主机标签实现,可以是单个主机,也可以是多个主机)
- podAntiAffinity主要解决POD不能和哪些POD部署在同一个拓扑域中的问题。它们处理的是Kubernetes集群内部POD和POD之间的关系。
三种亲和性和反亲和性策略的比较如下表所示:
| 策略名称 | 匹配目标 | 支持的操作符 | 支持拓扑域 | 设计目标 |
| nodeAffinity | node标签 | In,NotIn,Exists,DoesNotExist,Gt,Lt | 不支持 | 决定Pod可以部署在哪些主机上 |
| podAffinity | Pod标签 | In,NotIn,Exists,DoesNotExist | 支持 | 决定Pod可以和哪些Pod部署在同一拓扑域 |
| PodAntiAffinity | Pod标签 | In,NotIn,Exists,DoesNotExist | 支持 | 决定Pod不可以和哪些Pod部署在同一拓扑域 |
亲和性:应用A与应用B两个应用频繁交互,所以有必要利用亲和性让两个应用的尽可能的靠近,甚至在一个node上,以减少因网络通信而带来的性能损耗。
反亲和性:当应用的采用多副本部署时,有必要采用反亲和性让各个应用实例打散分布在各个node上,以提高HA。
nodeAffinity规则有2种:硬亲和性(require)和软亲和性(preferred)
硬亲和性:requiredDuringSchedulingIgnoredDuringExecution
实现的是强制性规则,是Pod调度时必须满足的规则,否则Pod对象的状态会一直是Pending
软亲和性:preferredDuringSchedulingIgnoredDuringExecution
实现的是一种柔性调度限制,在Pod调度时可以尽量满足其规则,在无法满足规则时,可以调度到一个不匹配规则的节点之上。
注:本节实验因为节点数不多,所以把master上面的污点去除了,kubectl taint node k8s231.tom.com node-role.kubernetes.io/master-
29.1. nodeAffinity(节点亲和性)
#硬亲和性
kubectl explain pods.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution(1) 创建资源
kubectl label nodes k8s231.tom.com hdd_disk=t1
kubectl label nodes k8s232.tom.com ssd_disk=t1
kubectl label nodes k8s233.tom.com ssd_disk=t2cat > 01-node-affinity-required.yaml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:name: node-affinity-required-deployment
spec:replicas: 4selector:matchLabels:app: affinity-required-apptemplate:metadata:labels:app: affinity-required-appspec:containers:- name: myappimage: nginx:alpineaffinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: ssd_diskoperator: Invalues:- t1- t2
EOFkubectl apply -f 01-node-affinity-required.yaml(2) 查看pod分布在哪个节点(232,233上打了ssd_disk的标签,且值在nodeAffnity指定的值范围之内)
[root@k8s231 affinity]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-affinity-required-deployment-5d997c4fd6-9qh2p 1/1 Running 0 20s 10.200.1.13 k8s232.tom.com <none> <none>
node-affinity-required-deployment-5d997c4fd6-bgn9h 1/1 Running 0 20s 10.200.1.14 k8s232.tom.com <none> <none>
node-affinity-required-deployment-5d997c4fd6-gdx6v 1/1 Running 0 20s 10.200.2.40 k8s233.tom.com <none> <none>
node-affinity-required-deployment-5d997c4fd6-wcbx2 1/1 Running 0 20s 10.200.2.39 k8s233.tom.com <none> <none>(4)删除node标签
kubectl label nodes k8s231.tom.com hdd_disk-
kubectl label nodes k8s232.tom.com ssd_disk-
kubectl label nodes k8s233.tom.com ssd_disk-(5)删除资源
kubectl delete -f 01-node-affinity-required.yaml29.2. podAffinity(Pod的亲和性)
在出于高效通信的需求,有时需要将一些Pod调度到相近甚至是同一区域位置(比如同一节点、机房、区域)等等,比如业务的前端Pod和后端Pod,
此时这些Pod对象之间的关系可以叫做亲和性。同时出于安全性的考虑,也会把一些Pod之间进行隔离,此时这些Pod对象之间的关系叫做反亲和性
主要解决哪些POD部署在同一个拓扑域中的问题(拓扑域用主机标签实现,可以是单个主机,也可以是多个主机)
- topologyKey: 定义了用于匹配节点的拓扑域的标签键。
- labelSelector: 用于匹配其他Pod的标签选择器
亲和性,即全部被调度到topologyKey的其中一个value值的所有节点上
kubectl label nodes k8s231.tom.com hdd_disk=t1
kubectl label nodes k8s232.tom.com ssd_disk=t1
kubectl label nodes k8s233.tom.com ssd_disk=t2
topologyKey: ssd_disk ,要么全部调度ssd_disk=t1的232节点上,要么全部调度到ssd_disk=t2的233节点上
kubectl label nodes k8s231.tom.com hdd_disk=t1
kubectl label nodes k8s232.tom.com ssd_disk=t1
kubectl label nodes k8s233.tom.com ssd_disk=t1
topologyKey: ssd_disk ,全部调度ssd_disk=t1的232和233节点上
(1)给node打标签
kubectl label nodes k8s231.tom.com hdd_disk=t1
kubectl label nodes k8s232.tom.com ssd_disk=t1
kubectl label nodes k8s233.tom.com ssd_disk=t2(2)编写资源清单
cat > 02-pod-affinity.yaml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:name: deploy-pod-affinity
spec:replicas: 5selector:matchExpressions:- key: appsoperator: Existstemplate:metadata:labels:apps: webspec:# 定义亲和性affinity:# 定义Pod的亲和性podAffinity:requiredDuringSchedulingIgnoredDuringExecution:# 指定拓扑域的key - topologyKey: ssd_disk# 基于标签匹配labelSelector:matchExpressions:# 指的是Pod标签的key- key: apps# 指的是Pod标签的valuesvalues:- weboperator: Incontainers:- name: webimage: nginx:alpine
EOF(3)创建资源
[root@k8s231 affinity]# kubectl apply -f 02-pod-affinity.yaml(4)查看pod亲和性分布的节点#(232,233的topologyKey相同,都是ssd_disk,但是值不同,亲和性会导致所有pod都选择相同value值的node)#从实验结果可以看到第一次是选择232节点,删除pod,重新创建后,都选择了233
[root@k8s231 affinity]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deploy-pod-affinity-6f94686c6c-dppng 1/1 Running 0 4s 10.200.1.16 k8s232.tom.com <none> <none>
deploy-pod-affinity-6f94686c6c-fwrkl 1/1 Running 0 4s 10.200.1.19 k8s232.tom.com <none> <none>
deploy-pod-affinity-6f94686c6c-gprjc 1/1 Running 0 4s 10.200.1.15 k8s232.tom.com <none> <none>
deploy-pod-affinity-6f94686c6c-j6bvg 1/1 Running 0 4s 10.200.1.17 k8s232.tom.com <none> <none>
deploy-pod-affinity-6f94686c6c-r8mrv 1/1 Running 0 4s 10.200.1.18 k8s232.tom.com <none> <none>[root@k8s231 affinity]# kubectl delete -f 02-pod-affinity.yaml
[root@k8s231 affinity]# kubectl apply -f 02-pod-affinity.yaml[root@k8s231 affinity]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deploy-pod-affinity-6f94686c6c-7b67r 1/1 Running 0 5s 10.200.2.44 k8s233.tom.com <none> <none>
deploy-pod-affinity-6f94686c6c-hhslb 1/1 Running 0 5s 10.200.2.45 k8s233.tom.com <none> <none>
deploy-pod-affinity-6f94686c6c-m7lst 1/1 Running 0 5s 10.200.2.41 k8s233.tom.com <none> <none>
deploy-pod-affinity-6f94686c6c-mcxhz 1/1 Running 0 5s 10.200.2.42 k8s233.tom.com <none> <none>
deploy-pod-affinity-6f94686c6c-z7fc4 1/1 Running 0 5s 10.200.2.43 k8s233.tom.com <none> <none> <none>(6)把233打的标签和232打的一样ssd_disk=t1,再重新创建pod,就会发现pod选择节点就是在232和233两个节点上,因为具有相同的拓扑域值
kubectl label nodes k8s233.tom.com ssd_disk=t1 --overwrite[root@k8s231 affinity]# kubectl delete -f 02-pod-affinity.yaml
[root@k8s231 affinity]# kubectl apply -f 02-pod-affinity.yaml
[root@k8s231 affinity]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deploy-pod-affinity-6f94686c6c-6zjts 1/1 Running 0 3s 10.200.1.20 k8s232.tom.com <none> <none>
deploy-pod-affinity-6f94686c6c-7r4vw 1/1 Running 0 3s 10.200.1.21 k8s232.tom.com <none> <none>
deploy-pod-affinity-6f94686c6c-9zr2z 1/1 Running 0 3s 10.200.2.46 k8s233.tom.com <none> <none>
deploy-pod-affinity-6f94686c6c-fc9lp 1/1 Running 0 3s 10.200.2.47 k8s233.tom.com <none> <none>
deploy-pod-affinity-6f94686c6c-j5k49 1/1 Running 0 3s 10.200.1.22 k8s232.tom.com <none> <none>(7)删除node标签
kubectl label nodes k8s231.tom.com hdd_disk-
kubectl label nodes k8s232.tom.com ssd_disk-
kubectl label nodes k8s233.tom.com ssd_disk-(8)删除资源
kubectl delete -f 02-pod-affinity.yaml29.3. PodAntiAffinity(pod反亲和性)
借助反硬特性我们可以部署3个redis实例,并且为了提升HA,部署在不同的节点
当要部署的pod副本数小于指定拓扑域的节点数时,会在指定拓扑域的节点上部署,且每个节点上只部署一个此pod
当要部署的pod副本数大于指定拓扑域的节点数时,会先在指定拓扑域的节点上部署,且每个节点上只部署一个此pod,然后在别的拓扑域的节点上部署(不限制副本)
(1)给node打标签
kubectl label nodes k8s231.tom.com hdd_disk=t1
kubectl label nodes k8s232.tom.com ssd_disk=t1
kubectl label nodes k8s233.tom.com ssd_disk=t2(2)创建资源
cat > 03-pod-anti-affinity.yaml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:name: redis-cache
spec:selector:matchLabels:app: storereplicas: 2template:metadata:labels:app: storespec:affinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- storetopologyKey: ssd_diskcontainers:- name: redis-serverimage: redis:3.2-alpine
EOF
[root@k8s231 affinity]# kubectl apply -f 03-pod-anti-affinity.yaml(2)查看pod分布,k8s233和k8s232含有指定的拓扑域ssd_disk,但是值不同,所以每个节点部署一个
[root@k8s231 affinity]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
redis-cache-6b7b79d589-lxvcn 1/1 Running 0 2m11s 10.200.2.38 k8s233.tom.com <none> <none>
redis-cache-6b7b79d589-zbdqn 1/1 Running 0 2m11s 10.200.1.12 k8s232.tom.com <none> <none>(4)调整副本数为4个,除了原先的2个,新增的2个pod都在k8s231
[root@k8s231 affinity]# kubectl edit -f 03-pod-anti-affinity.yaml
deployment.apps/redis-cache edited
[root@k8s231 affinity]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
redis-cache-676856dc77-6nhz7 1/1 Running 0 2s 10.200.0.38 k8s231.tom.com <none> <none>
redis-cache-676856dc77-fddpf 1/1 Running 0 8m6s 10.200.2.52 k8s233.tom.com <none> <none>
redis-cache-676856dc77-kgvlp 1/1 Running 0 2s 10.200.0.39 k8s231.tom.com <none> <none>
redis-cache-676856dc77-r74bt 1/1 Running 0 8m6s 10.200.1.26 k8s232.tom.com <none> <none>(5)删除node标签
kubectl label nodes k8s231.tom.com hdd_disk-
kubectl label nodes k8s232.tom.com ssd_disk-
kubectl label nodes k8s233.tom.com ssd_disk-(6)删除资源
kubectl delete -f 03-pod-anti-affinity.yaml 29.4. (PodAntiAffinity和PodAffinity综合案例)
部署2个web实例,为了提升HA,都不在一个node;并且为了方便与redis交互,尽量与redis在同一个node
(1)给node打标签
kubectl label nodes k8s231.tom.com hdd_disk=t1
kubectl label nodes k8s232.tom.com ssd_disk=t1
kubectl label nodes k8s233.tom.com ssd_disk=t2(2)创建redis,2个副本,创建web,2个副本
kubectl apply -f 03-pod-anti-affinity.yaml
cat > 04-affinity-pod-and-anti.yaml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:name: web-server
spec:selector:matchLabels:app: webreplicas: 2template:metadata:labels:app: webspec:affinity:podAntiAffinity: #反亲和性requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- webtopologyKey: ssd_diskpodAffinity: #亲和性requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- storetopologyKey: ssd_diskcontainers:- name: web-appimage: nginx:1.12-alpine
EOFkubectl apply -f 04-affinity-pod-and-anti.yaml(3)查看web,和redis分布节点
[root@k8s231 affinity]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
redis-cache-676856dc77-5wszs 1/1 Running 0 7s 10.200.1.34 k8s232.tom.com <none> <none>
redis-cache-676856dc77-zrqdx 1/1 Running 0 7s 10.200.2.60 k8s233.tom.com <none> <none>
web-server-9658b4b75-756lj 1/1 Running 0 7s 10.200.2.59 k8s233.tom.com <none> <none>
web-server-9658b4b75-pw6b6 1/1 Running 0 7s 10.200.1.33 k8s232.tom.com <none> <none>
30. 控制器之DaemonSet
DaemonSet被创建时,系统会自动调度Pod到所有符合条件的节点上,确保每个节点上都有且仅有一个该Pod的实例。
DaemonSet的一些典型用法:
(1)在每个节点上运行集群守护进程(flannel等)
(2)在每个节点上运行日志收集守护进程(flume,filebeat,fluentd等)
(3)在每个节点上运行监控守护进程(zabbix agent,node_exportor等)
温馨提示:
(1)当有新节点加入集群时,也会为新节点新增一个Pod;
(2)当有节点从集群移除时,这些Pod也会被回收;
(3)删除DaemonSet将会删除它创建的所有Pod;
(4)如果节点被打了污点的话,且DaemonSet中未定义污点容忍,则Pod并不会被调度到该节点上;("flannel案例")
(1)创建daemonset资源
cat > 01-ds-busybox.yaml <<EOF
apiVersion: apps/v1
kind: DaemonSet
metadata:name: ds
spec:selector:matchExpressions:- key: appsoperator: Existstemplate:metadata:labels:apps: busyboxspec:containers:- name: busyboximage: nginx:alpine
EOF[root@k8s231 daemonset]# kubectl apply -f 01-ds-busybox.yaml(2)查看pod,发现231上没有,因为231上有污点,可以给ds加上污点容忍让污点节点也可以部署
[root@k8s231 daemonset]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
ds-25r48 1/1 Running 0 7s 10.200.1.36 k8s232.tom.com <none> <none>
ds-dh8bf 1/1 Running 0 7s 10.200.2.62 k8s233.tom.com <none> <none>
[root@k8s231 daemonset]# kubectl describe node|grep Taints
Taints: node-role.kubernetes.io/master:NoSchedule
Taints: <none>
Taints: <none>31. 集群的扩缩容
31.1. 缩容:drain(Pod驱逐)及K8S节点下线
驱逐简介:
kubelet监控当前node节点的CPU,内存,磁盘空间和文件系统的inode等资源。
当这些资源中的一个或者多个达到特定的消耗水平,kubelet就会主动地将节点上一个或者多个Pod强制驱逐。
以防止当前node节点资源无法正常分配而引发的OOM。
参考链接:
节点压力驱逐 | Kubernetes
- 手动驱逐Pod,模拟下线节点
- 应用场景:node因为硬件故障或者其他原因要下线。
- 参考步骤:(1)编写资源清单并创建
[root@k8s231 drain]# cat > 01-drain.yaml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:name: drain-dp
spec:replicas: 3selector:matchExpressions:- key: appsoperator: Existstemplate:metadata:labels:apps: dp-webspec:containers:- name: webimage: nginx:alpine
---
apiVersion: apps/v1
kind: DaemonSet
metadata:name: drain-ds
spec:selector:matchExpressions:- key: appsoperator: Existstemplate:metadata:labels:apps: ds-webspec:containers:- name: webimage: nginx:alpine
EOF[root@k8s231 drain]# kubectl apply -f 01-drain.yaml[root@k8s231 drain]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
drain-dp-6849c8b47c-862qk 1/1 Running 0 90s 10.200.1.39 k8s232.tom.com <none> <none>
drain-dp-6849c8b47c-jkn5z 1/1 Running 0 90s 10.200.2.63 k8s233.tom.com <none> <none>
drain-dp-6849c8b47c-ptftv 1/1 Running 0 90s 10.200.2.64 k8s233.tom.com <none> <none>
drain-dp-6849c8b47c-sckd8 1/1 Running 0 90s 10.200.1.37 k8s232.tom.com <none> <none>
drain-dp-6849c8b47c-zxvcg 1/1 Running 0 90s 10.200.2.66 k8s233.tom.com <none> <none>
drain-ds-p5hjl 1/1 Running 0 90s 10.200.2.65 k8s233.tom.com <none> <none>
drain-ds-rclq5 1/1 Running 0 90s 10.200.1.38 k8s232.tom.com <none> <none>(2)驱逐无法驱逐Ds调度的pod(drain-ds-p5hjl),驱逐节点的pod后,节点233会被打上SchedulingDisable标签。
[root@k8s231 drain]# kubectl drain k8s233.tom.com --ignore-daemonsets
[root@k8s231 drain]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s231.tom.com Ready <none> 15h v1.23.17
k8s232.tom.com Ready <none> 15h v1.23.17
k8s233.tom.com Ready,SchedulingDisabled <none> 15h v1.23.17
[root@k8s231 drain]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
drain-dp-6849c8b47c-862qk 1/1 Running 0 106s 10.200.1.39 k8s232.tom.com <none> <none>
drain-dp-6849c8b47c-mhczj 1/1 Running 0 4s 10.200.1.40 k8s232.tom.com <none> <none>
drain-dp-6849c8b47c-nkxkz 1/1 Running 0 4s 10.200.1.42 k8s232.tom.com <none> <none>
drain-dp-6849c8b47c-sckd8 1/1 Running 0 106s 10.200.1.37 k8s232.tom.com <none> <none>
drain-dp-6849c8b47c-zvvk4 1/1 Running 0 4s 10.200.1.41 k8s232.tom.com <none> <none>
drain-ds-p5hjl 1/1 Running 0 106s 10.200.2.65 k8s233.tom.com <none> <none>
drain-ds-rclq5 1/1 Running 0 106s 10.200.1.38 k8s232.tom.com <none> <none>(3)drain无法驱逐ds资源的pod,但是可以通过给节点配置NoExecute污点,将ds资源Pod(drain-ds-p5hjl)从233节点驱逐。
[root@k8s231 drain]# kubectl taint nodes k8s233.tom.com test=1:NoExecute
[root@k8s231 drain]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
drain-dp-6849c8b47c-862qk 1/1 Running 0 9m42s 10.200.1.39 k8s232.tom.com <none> <none>
drain-dp-6849c8b47c-mhczj 1/1 Running 0 8m 10.200.1.40 k8s232.tom.com <none> <none>
drain-dp-6849c8b47c-nkxkz 1/1 Running 0 8m 10.200.1.42 k8s232.tom.com <none> <none>
drain-dp-6849c8b47c-sckd8 1/1 Running 0 9m42s 10.200.1.37 k8s232.tom.com <none> <none>
drain-dp-6849c8b47c-zvvk4 1/1 Running 0 8m 10.200.1.41 k8s232.tom.com <none> <none>
drain-ds-rclq5 1/1 Running 0 9m42s 10.200.1.38 k8s232.tom.com <none> <none>(4)登录要下线的节点并重置kubeadm集群环境
[root@k8s233 ~]# kubeadm reset -f
[root@k8s233 ~]# rm -rf /etc/cni/net.d && iptables -F && iptables-save
[root@k8s233 ~]# systemctl disable kubelet (5)master上删除要下线的节点。
[root@k8s231 drain]# kubectl delete nodes k8s233.tom.com(6)下线的节点关机并重新安装操作系统
[root@k8s233 ~]# reboot 31.2. 扩容:kubeadm快速将节点加入集群:
kubeadm快速将节点加入集群:1.安装必要组件1.1 配置软件源
cat > /etc/yum.repos.d/kubernetes.repo <<EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
repo_gpgcheck=0
EOF1.2 安装kubeadm,kubelet,kubectl软件包
yum -y install kubeadm-1.23.17-0 kubelet-1.23.17-0 kubectl-1.23.17-0 1.3 启动kubelet服务(若服务启动失败时正常现象,其会自动重启,因为缺失配置文件,初始化集群后恢复!此步骤可跳过!)
systemctl enable --now kubelet
systemctl status kubelet2.在master组件创建token2.1 创建一个永不过期的token,并打印加入集群的命令
[root@k8s231 ]# kubeadm token create --print-join-command tom123.qwertyuiopasdfgh --ttl 0
kubeadm join 10.0.0.231:6443 --token tom123.qwertyuiopasdfgh --discovery-token-ca-cert-hash sha256:211d5700f7443ccb7f8a32e908cbb292699d678605bd0fb735926a97c1fa43452.2 查看现有的token
[root@k8s231 ]# kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
tom123.qwertyuiopasdfgh <forever> <never> authentication,signing <none> system:bootstrappers:kubeadm:default-node-token3.新worker节点执行刚才master节点生成的加入集群的命令
[root@k8s233 ~]# kubeadm join 10.0.0.231:6443 --token tom123.qwertyuiopasdfgh --discovery-token-ca-cert-hash sha256:211d5700f7443ccb7f8a32e908cbb292699d678605bd0fb735926a97c1fa43454.查看节点
[root@k8s231 ]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s231.tom.com Ready <none> 15h v1.23.17
k8s232.tom.com Ready <none> 15h v1.23.17
k8s233.tom.com Ready <none> 62s v1.23.175.查看bootstrap阶段的token信息
[root@k8s231 ]# kubectl get secrets -A | grep tom
kube-system bootstrap-token-tom123 bootstrap.kubernetes.io/token 5 4m29s31.3. bootstrap过程
当集群开启了 TLS 认证后,每个节点的 kubelet 组件都要使用由 apiserver 使用的 CA 签发的有效证书才能与 apiserver 通讯;此时如果节点多起来,为每个节点单独签署证书将是一件非常繁琐的事情;TLS bootstrapping 功能就是让 kubelet 先使用一个预定的低权限用户连接到 apiserver,然后向 apiserver 申请证书,kubelet 的证书由 apiserver 动态签署
32. Endpoint资源
Service是Kubernetes中的一种资源对象,用来定义一组Pod的访问规则,实现对Pod的负载均衡、服务发现等功能。
Endpoint是Service的另一个关联资源对象,用来存储一个Service对应的后端Pod的网络信息
k8s使用ep资源映射外部服务实战案例:
| 步骤1 | k8s集群外部的一个nginx服务
| 步骤2 | 创建svc,查看Endpoint信息,endpoint ip地址为空
| 步骤3 | 通过Endpoint资源清单的方式,修改Endpoint中的地址为步骤1中的nginx的ip地址,查看endpoint地址就不为空了(1)k8s集群外10.0.0.81节点上部署nginx
docker run -d --name nginx -p 8080:80 nginx:alpine[root@k8s231 endpoint]# cat > 01-svc.yaml <<EOF
apiVersion: v1
kind: Service
metadata:name: svc
spec:type: ClusterIPports:- port: 80targetPort: 8080
EOF
[root@k8s231 endpoint]# kubectl apply -f 01-svc.yaml
[root@k8s231 endpoint]# kubectl get svc,ep -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service/kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 7s <none>
service/svc ClusterIP 10.100.49.25 <none> 80/TCP 10s <none>NAME ENDPOINTS AGE
endpoints/kubernetes 10.0.0.231:6443 7s
endpoints/svc <none> 9s[root@k8s231 endpoint]# curl 10.100.49.25:80 -I
curl: (7) Failed connect to 10.100.49.25:80; Connection refused(2)编写ep资源清单修改svc的endpoint
cat > 02-ep.yaml <<EOF
apiVersion: v1
kind: Endpoints
metadata:name: svc
subsets:
- addresses:- ip: 10.0.0.81ports:- port: 8080
EOF[root@k8s231 endpoint]# kubectl apply -f 02-ep.yaml
[root@k8s231 endpoint]# kubectl get svc,ep -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service/kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 3m14s <none>
service/svc ClusterIP 10.100.49.25 <none> 80/TCP 3m17s <none>NAME ENDPOINTS AGE
endpoints/kubernetes 10.0.0.231:6443 3m14s
endpoints/svc 10.0.0.81:8080 3m16s[root@k8s231 endpoint]# curl 10.100.49.25:80 -I
HTTP/1.1 200 OK
Server: nginx/1.27.0
Date: Wed, 14 Aug 2024 07:38:52 GMT33. kube-proxy的工作模式:
对于kube-proxy组件的作用就是为k8s集群外部用户提供访问服务的路由。
kube-proxy监听K8S APIServer,一旦service资源发生变化,kube-proxy就会生成对应的负载调度的调整,这样就保证service的最新状态。
kube-proxy有三种调度模型:
- userspace: k8s 1.1之前。
- iptables: k8s 1.2 ~ k8s 1.11之前。
- ipvs: K8S 1.11之后,如果没有开启ipvs,则自动降级为iptables。
修改ipvs工作模式(1)所有master,worker节点启用ipvs(1)所有节点安装ipvs相关组件
yum -y install conntrack-tools ipvsadm.x86_64 (2)所有节点编写加载ipvs的配置文件
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF(3)所有节点加载ipvs相关模块并查看
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4(4)master节点上,修改kube-proxy的工作模式为ipvs4.1仅需修改工作模式("mode")为ipvs即可。切记,一定要保存退出!
[root@k8s231 ~]# kubectl -n kube-system edit cm kube-proxy4.2 验证是否修改成功
[root@k8s231 ~]# kubectl -n kube-system describe cm kube-proxy | grep mode
mode: "ipvs"(5)master节点上,删除旧的kube-proxy
kubectl get pods -A | grep kube-proxy | awk '{print $2}' | xargs kubectl -n kube-system delete pods (6)master节点上验证kube-proxy组件工作模式是否生效6.1 查看日志
[root@k8s231 endpoint]# kubectl get pods -A | grep kube-proxy
kube-system kube-proxy-c5mvl 1/1 Running 0 88s
kube-system kube-proxy-hptsr 1/1 Running 0 89s
kube-system kube-proxy-ljhgc 1/1 Running 0 89s[root@k8s231 ~]# kubectl logs kube-proxy-c5mvl -n kube-system |grep Using
I0814 07:49:40.985153 1 server_others.go:269] "Using ipvs Proxier"(7)创建pod,svc,验证ipvs的工作模式
]# cat > 01-dp-svc.yaml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:name: dp-nginxlabels:app: nginx
spec:replicas: 2 selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec: containers:- name: nginximage: nginx:1.12.2ports:- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:name: svc-nginx
spec:selector:app: nginxtype: ClusterIPports:- port: 80targetPort: 80clusterIP: 10.100.1.11
EOFkubectl apply -f 01-dp-svc.yaml
[root@k8s231 ipvs]# kubectl get po,svc,ep -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/dp-nginx-5d94f77b4f-n8c46 1/1 Running 0 68s 10.200.1.50 k8s232.tom.com <none> <none>
pod/dp-nginx-5d94f77b4f-zjzpn 1/1 Running 0 68s 10.200.3.11 k8s233.tom.com <none> <none>NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service/kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 77s <none>
service/svc-nginx ClusterIP 10.100.1.11 <none> 80/TCP 68s app=nginxNAME ENDPOINTS AGE
endpoints/kubernetes 10.0.0.231:6443 77s
endpoints/svc-nginx 10.200.1.50:80,10.200.3.11:80 68s[root@k8s231 ipvs]# ipvsadm -ln | grep 10.100.1.11 -A 3
TCP 10.100.1.11:80 rr-> 10.200.1.50:80 Masq 1 0 0 -> 10.200.3.11:80 Masq 1 0 0 温馨提示:在实际工作中,如果修改了kube-proxy服务时,若删除Pod,请逐个删除,不要批量删除哟!34. 影响Pod调度的因素
- nodeName
- resources
- hostNetwork
- 污点
- 污点容忍
- 节点选择器
- 亲和性
-Pod亲和性
-Pod反亲和性
-节点亲和性
-控制器
-ds
-rs
-rc
-deploy
-job
-cronjob
35. k8s安全框架
35.1. k8s安全控制框架概述
k8s安全控制框架主要由下面三个阶段进行控制,每一个阶段都支持插件方式,通过api server配置来启用插件。
1、认证:Authentication
2、授权:Authorization
3、准入控制:Admission Control
35.2. 认证、授权、准入控制
35.2.1. 认证:Authentication
35.2.2. 授权:Authorization

35.2.3. 准入控制:Admission Control
实际上是一个准入控制插件列表,发送到API Server的请求都需要经过这个列表中的每个准入控制器插件的检查,检查不通过,则拒绝请求。准入控制插件列表:https://kubernetes.io/zh-cn/docs/reference/command-line-tools-reference/kube-apiserver/
35.3. 案例:为单用户授权访问单个命名空间的资源权限
示例:为用户tom授权访问default命名空间资源权限
35.3.1. 用户认证
用k8s CA签发为用户签发证书,CA指的是k8s的根证书。kubeadmin部署,目录是:/etc/kubernetes/pki/ca.crt 和 ca.key
二进制部署,一般会放到一个单独的目录:TLS/kubernetes/ca.pem或者其他后缀 和 ca-key.pem
35.3.1.1. 需要单独安装cfssl、 cfssl-certinfo、cfssljson等 命令
https://github.com/cloudflare/cfssl/releases/
wget https://pkg.cfssl.org/1.6.5/cfssl_linux-amd64
wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64
[root@k8s231 user]# mv cfssl_linux-amd64 /usr/bin/cfssl
[root@k8s231 user]# mv cfssljson_linux-amd64 /usr/bin/cfssl-certinfo
[root@k8s231 user]# mv cfssl-certinfo_linux-amd64 /usr/bin/cfssljson35.3.1.2. 为指定用户生成证书
mkdir -p /manifests/rbac && cd /manifests/rbac
[root@k8s231 rbac]# vim cert.sh
#!/bin/bash
[ $# -ne 2 ] && {
echo "usage: $0 用户名 用户组" && exit 1
}
user=$1
group=$2
#1 配置证书生成策略,需要什么功能的证书及有效期
cat > ca-config.json << EOF
{"signing": {"default": {"expiry": "876000h"},"profiles": {"kubernetes": {"usages": ["signing","key encipherment","server auth","client auth"],"expiry": "876000h"}}}
}
EOF#default默认策略,指定了证书的默认有效期是一年(876000h 100年)
#kubernetes:表示该配置(profile)的用途是为kubernetes生成证书及相关的校验工作
#signing:表示该证书可用于签名其它证书;生成的 ca.pem 证书中 CA=TRUE
#server auth:表示可以该CA 对 server 提供的证书进行验证
#client auth:表示可以用该 CA 对 client 提供的证书进行验证
#expiry:也表示过期时间,如果不写以default中的为准#2 配置证书信息
cat > csr-${user}.json << EOF
{"CN": "${user}","hosts": [],"key": {"algo": "rsa","size": 2048},"names": [{"C": "CN","ST": "GUANGDONG","L": "shenzhen","O": "${group}","OU": "System"}]
}
EOF#CN: Common Name,浏览器使用该字段验证网站是否合法,一般写的是域名。非常重要。浏览器使用该字段验证网站是否合法
#key:生成证书的算法
#hosts:表示哪些主机名(域名)或者IP可以使用此csr申请的证书,为空或者""表示所有的都可以使用
#names:一些其它的属性
#C: Country, 国家
#ST: State,州或者是省份
#L: Locality Name,地区,城市
#O: Organization Name,组织名称,公司名称(在k8s中常用于指定Group,进行RBAC绑定)
#OU: Organization Unit Name,组织单位名称,公司部门#3 生成证书,使用k8s ca签发客户端证书
/usr/bin/cfssl gencert \
-ca=/etc/kubernetes/pki/ca.crt \
-ca-key=/etc/kubernetes/pki/ca.key \
-config=ca-config.json \
-profile=kubernetes \
csr-${user}.json | cfssljson -bare ${user}#gencert: 生成新的key(密钥)和签名证书
#-ca:指明ca的证书
#-ca-key:指明ca的私钥文件
#-config: 指明请求证书的json文件
#-profile:与-config中的profile对应,是指根据config中的profile字段来生成证书的相关信息#4 查看cert(证书信息):
echo "---------查看${user}.pem--------------"
/usr/bin/cfssl-certinfo --cert ${user}.pem[root@k8s231 rbac]# bash cert.sh tom k8s35.3.1.3. 生成kubeconfig文件

kubeconfig是一个包含连接到Kubernetes集群所需信息的配置文件
kubeconfig中主要由如下部分组成:
- clusters (集群)
- users(用户)
- context(上下文) 将集群、命名空间、用户进行分组
#kubeconfig常用命令
kubectl config view #打印kubeconfig文件内容
kubectl config set-cluster #设置kubeconfig的cluster端
kubectl config set-credentials #设置kubeconfig的user端
kubectl config set-context #设置kubeconfig的context上下文,绑定user和cluster
kubectl config use-context #把某个上下文设置为当前上下文,就是使用他的上下文信息中的user去访问cluster#生成kubeconfig文件
#1 编写生成kubeconfig文件的脚本
cat > kubeconfig.sh <<'EOF'
[ $# -ne 1 ] && {
echo "usage: $0 用户名" && exit 1
}
user=$1#(1) 设置要连接的集群的参数
kubectl config set-cluster kubernetes \
--server=https://10.0.0.231:6443 \
--certificate-authority=/etc/kubernetes/pki/ca.crt \
--embed-certs=true \
--kubeconfig=${user}.kubeconfig#set-cluster kubernetes #设定要连接的集群的名字
#--server #指定APIServer的地址。
#--certificate-authority #指定K8s的ca根证书文件路径
#--embed-certs# #true表示将根证书文件的内容写入到配置文件中,false只是引用配置文件
#--kubeconfig=${user}.kubeconfig #参数被写入的文件名称。如果不指定,配置文件写到~/.kube/config这个文件中。#(2) 认证用户
#把指定用户的证书和客户端密钥嵌入到配置文件中
kubectl config set-credentials ${user} \
--client-key=${user}-key.pem \
--client-certificate=${user}.pem \
--embed-certs=true \
--kubeconfig=${user}.kubeconfig#set-credentials ${user} #用户名
#--client-certificate=${user}.pem #用户的证书
#--client-key=${user}-key.pem #用户的私钥
#--embed-certs=true #把client端的证书和私钥写入kubeconfig文件
#--kubeconfig=${user}.kubeconfig #参数被写入的文件名称。如果不指定,配置文件写到~/.kube/config这个文件中。#(3) 增加上下文信息context
#设置context将集群、命名空间、用户进行分组。即在context-${user}这个context的以${user}用户的信息访问kubernetes集群的default命名空间
kubectl config set-context context-${user} \
--cluster=kubernetes \
--user=${user} \
--kubeconfig=${user}.kubeconfig#set-context context-${user} #context名字
#--cluster=kubernetes #集群名字
#--user=${user} #访问集群的用户名字
#--kubeconfig=${user}.kubeconfig #参数被写入的文件名称。如果不指定,配置文件写到~/.kube/config这个文件中。#(4) 把刚创建的context设置为正在使用的context
kubectl config use-context context-${user} --kubeconfig=${user}.kubeconfig
EOF#2 生成kubeconfig文件
[root@k8s231 rbac]# bash kubeconfig.sh tom
Cluster "kubernetes" set.
User "tom" set.
Context "context-tom" modified.
Switched to context "context-tom".#3 查看kubeconfig中的信息
[root@k8s231 rbac]# kubectl config --kubeconfig=tom.kubeconfig view --minify
apiVersion: v1
clusters:
- cluster:certificate-authority-data: DATA+OMITTEDserver: https://10.0.0.231:6443name: kubernetes
contexts:
- context:cluster: kubernetesuser: tomname: context-tom
current-context: context-tom
kind: Config
preferences: {}
users:
- name: tomuser:client-certificate-data: REDACTEDclient-key-data: REDACTED[root@k8s231 rbac]# kubectl config get-contexts --kubeconfig=tom.kubeconfig
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* context-tom kubernetes tom[root@k8s231 rbac]# kubectl config --kubeconfig=tom.kubeconfig current-context
context-tom35.3.2. RBAC授权
RBAC(Role-BasedAccess Control,基于角色的访问控制),负责完成授权(Authorization)工作。
RBAC根据API请求属性,决定允许还是拒绝
角色:1、Role:角色,用于授权特定命名空间的访问权限2、ClusterRole:集群角色,用于授权所有命名空间的访问权限
角色绑定:1、RoleBinding:用于将角色绑定到主体(即subject)2、ClusterRoleBinding:用于将集群角色绑定到主体
subject(主题):1、User: 用户2、Group: 用户组3、ServiceAccount:服务账户,用途是为Pod提供身份验证和授权,确保Pod能够正确地与Kubernetes API Server交互,并获取所需的权限
-----------------------------------------------------------------------------------
role 和 rolebinding,clusterrole和clusterrolebinding
role 仅是一组许可权限的集合,其描述了对那些资源可执行哪种操作,资源配置清单中使用rules资源嵌套授权规则。
rolebinding 用于将role中定义的权限赋予一个或一组用户,rolebinding仅能够引用同一名称空间中的role对象完成授权。
clusterrole 除了能够管理与role资源相同的许可权限外,还可以用于集群级组件的授权,配置方式及其在rules字段中可内嵌的字段和Role类似。
clusterrolebinding 整个集群级别和所有namespaces将特定的subject与ClusterRole绑定,授予权限role(权限角色)
role.rules.verbs: 定义对资源可执行的操作列表,包括 create/apply/delete/update/patch/edit/list/get/proxy/redirect等
role.rules.apiGroups: 包含可资源的API组名称,空串标识核心组
role.rules.resourceNames: 规则应用的目标资源名称组成的列表,如POD资源中的那些资源的操作等
role.rules.resources: 规则应用的目标资源类型组成的列表,如pods,deployment等
role.rules.nonResourceURLs: 用于定义用户应该投权限访问的网址列表,其不是名称空间级别的资源,其只能应用于clusterrole 和 clusterrolebinding。
-----------------------------------------------------------------------------------rolebinding(在特定的名称空间内,绑定用户和权限role)
subjects 字段,主体信息绑定字段
rolebinding.subjects.kind: 要应用的主体类型。有User,Group和ServiceAccount三种选择,必选字段。
rolebinding.subjects.apiGroup: 要引用的主体所属的API群组,serviceaccount类的主体来说默认是"",而User和Group类主体的默认值为"rbac.authorization.k8s.io"
rolebinding.subjects.name: 指定要绑定的主体账户的账户名称,必选字段
rolebinding.subjects.namespace: 指定引用的主体的名称空间,对于非名称空间类的主体,如"User"和"Group",其值必须为空,否则授权插件将返回错误信息。
-----------------------------------------------------------------------------------
roleRef 字段 角色绑定字段
rolebinding.roleRef.kind: 引用的资源所属的类别,可用值为Role或ClusterRole,必选字段 。
rolebinding.roleRef.apiGroup: 引用的资源(Role或ClusterRole)所属的API群组,必选字段 。
rolebinding.roleRef.name: 引用的角色资源的名称。 #(1) 创建role资源
[root@k8s231 rbac]# cat > rbac-role-read.yaml <<EOF
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:namespace: defaultname: role-read
rules:
- apiGroups: ["","apps/v1"] resources: ["pods","deployments","services"] verbs: ["get", "list"]
- apiGroups: [""]resources: ["secrets"]verbs: ["list"]
EOF#(2) 创建rolebind资源绑定用户tom和role-read
cat > rolebinding-user-tom.yaml <<EOF
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: rb-tom namespace: default
subjects:
- kind: User name: tom apiGroup: rbac.authorization.k8s.io
roleRef:kind: Role name: role-tomapiGroup: rbac.authorization.k8s.io
EOF[root@k8s231 rbac]# kubectl apply -f rbac-role-read.yaml -f rolebinding-user-tom.yaml[root@k8s231 rbac]# kubectl get rolebindings.rbac.authorization.k8s.io rb-tom -o wide
NAME ROLE AGE USERS GROUPS SERVICEACCOUNTS
rb-tom Role/role-tom 27s tom35.3.3. 测试验证
#拷贝授权文件到232,232使用授权文件访问k8s集群
[root@k8s231 rbac]# scp tom.kubeconfig root@10.0.0.232:/tmp/
[root@k8s232 ~]# kubectl get pod --kubeconfig=/tmp/tom.kubeconfig
NAME READY STATUS RESTARTS AGE
tolerations-6fc7bdb7b5-6blzb 1/1 Running 0 28h
tolerations-6fc7bdb7b5-b87tp 1/1 Running 0 28h35.4. 案例:为用户组授权访问单个命名空间的资源权限
#(1) 创建一个具有超级权限的role
[root@k8s231 rbac]# cat > rbac-role-super.yaml <<EOF
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:namespace: defaultname: role-super
rules:
- apiGroups: ["*"] resources: ["*"] verbs: ["*"]
EOF#(2) 为"group-super"组绑定刚才的超级权限角色
cat > rolebinding-group-super.yaml <<EOF
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: rb-group-supernamespace: default
subjects:
- kind: Group name: group-superapiGroup: rbac.authorization.k8s.io
roleRef:kind: Role name: role-superapiGroup: rbac.authorization.k8s.io
EOF[root@k8s231 rbac]# kubectl apply -f rbac-role-super.yaml -f rolebinding-group-super.yaml
[root@k8s231 rbac]# kubectl get rolebindings.rbac.authorization.k8s.io -o wide
NAME ROLE AGE USERS GROUPS SERVICEACCOUNTS
rb-group-super Role/role-super 20s group-super
rb-tom Role/role-tom 23m tom#(3) 为一个组为group-server的用户jack创建证书和鉴权文件
[root@k8s231 rbac]# bash cert.sh jack group-super#(4) 为jack生成鉴权文件
[root@k8s231 rbac]# bash kubeconfig.sh jack
Cluster "kubernetes" set.
User "jack" set.
Context "context-jack" created.
Switched to context "context-jack".#(4) 测试验证
#拷贝授权文件到233,233使用授权文件访问k8s集群
[root@k8s231 rbac]# scp jack.kubeconfig root@10.0.0.233:/tmp/
[root@k8s233 ~]# kubectl get pod --kubeconfig=/tmp/jack.kubeconfig
NAME READY STATUS RESTARTS AGE
tolerations-6fc7bdb7b5-6blzb 1/1 Running 0 29h
tolerations-6fc7bdb7b5-b87tp 1/1 Running 0 29h35.4.1. 在worker节点使用kubeconfig文件方法
默认方法:kubectl get pod --kubeconfig=/tmp/jack.kubeconfig
便捷做法1:在/etc/profile里面加上别名,直接输入kubectl行了
[root@k8s233 ~]# tail -1 /etc/profile
alias kubectl='kubectl --kubeconfig=/tmp/jack.kubeconfig'
便捷做法2:把kubeconfig文件复制到/root/.kube/目录下并命名为config,因为kubectl 默认就是使用/root/.kube/config文件作为kubeconfig文件
[root@k8s233 ~]# cp /tmp/jack.kubeconfig /root/.kube/config
35.5. 案例:为ServiceAccount授权访问单个命名空间的资源权限
ServiceAccount的主要用途是为Pod提供身份验证和授权,确保Pod能够正确地与Kubernetes API Server交互,并获取所需的权限
ServiceAccount是一种特殊的Resource,用于Pod内的进程访问Kubernetes API或与其他集群内服务交互。ServiceAccount会自动创建一个Secret,该Secret包含访问API所需的信息。
当当你创建ServiceAccount时,Kubernetes会自动创建一个Secret,并将其以Volume的形式挂载到Pod的/run/secrets/kubernetes.io/serviceaccount目录下,
# 查看token方式:cat /var/run/secrets/kubernetes.io/serviceaccount/token
(1)创建sa- 响应式创建serviceAccounts
[root@k8s231 rbac]# kubectl create serviceaccount sa1
serviceaccount/sa1 created- 声明式创建serviceaccount
[root@k8s231 serviceaccounts]# cat > sa-tom.yaml <<
apiVersion: v1
kind: ServiceAccount
metadata:name: sa1
EOF
[root@k8s231 rbac]# kubectl apply -f sa-tom.yaml(2)绑定sa和role
cat > rolebinding-sa.yaml <<EOF
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:name: rb-sanamespace: default
subjects:
- kind: ServiceAccountname: sa1apiGroup: ""
roleRef:kind: Role name: role-superapiGroup: rbac.authorization.k8s.io
EOF
[root@k8s231 rbac]# kubectl apply -f rolebinding-sa.yaml[root@k8s231 rbac]# kubectl get rolebindings.rbac.authorization.k8s.io -o wide
NAME ROLE AGE USERS GROUPS SERVICEACCOUNTS
rb-group-super Role/role-super 52m group-super
rb-sa Role/role-super 2m3s /sa1
rb-tom Role/role-tom 75m tom(3)创建pod,引用sa
[root@k8s231 rbac]# cat > deploy-python-sa.yaml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:name: web
spec:replicas: 1selector:matchExpressions:- key: appsoperator: Existstemplate:metadata:labels:apps: webspec:serviceAccountName: sa1containers:- image: python:latestname: webcommand: ["tail","-f","/etc/hosts"]
EOF
[root@k8s231 rbac]# kubectl apply -f deploy-python-sa.yaml
[root@k8s231 rbac]# cat > python-k8s.py <<'EOF'
# -*- coding: UTF-8 -*-
from kubernetes import client, config
with open('/var/run/secrets/kubernetes.io/serviceaccount/token') as f:token = f.read()# print(token)
configuration = client.Configuration()
configuration.host = "https://kubernetes" # APISERVER地址
configuration.ssl_ca_cert="/var/run/secrets/kubernetes.io/serviceaccount/ca.crt" # CA证书
configuration.verify_ssl = True # 启用证书验证
configuration.api_key = {"authorization": "Bearer " + token} # 指定Token字符串
client.Configuration.set_default(configuration)
apps_api = client.AppsV1Api()
core_api = client.CoreV1Api()
try:print("###### Deployment列表 ######")#列出default命名空间所有deployment名称for dp in apps_api.list_namespaced_deployment("default").items:print(dp.metadata.name)
except:print("没有权限访问Deployment资源!")try:#列出default命名空间所有pod名称print("###### Pod列表 ######")for po in core_api.list_namespaced_pod("default").items:print(po.metadata.name)
except:print("没有权限访问Pod资源!")
EOF[root@k8s231 rbac]# kubectl cp python-k8s.py web-6697f44f5f-tb7m9:/
[root@k8s231 rbac]# kubectl exec -it web-6697f44f5f-tb7m9 -- sh -c "pip install kubernetes -i https://pypi.tuna.tsinghua.edu.cn/simple/;python3 python-k8s.py"
###### Deployment列表 ######
web
###### Pod列表 ######
web-6697f44f5f-tb7m936. persistent volume(pv 持久化存储)
36.1. PersistentVolume与Volume区别
Volume是定义在Pod上的,是属于"资源对象"的一部分
PersistentVolume不属于Node、Pod等资源,但可以被他们访问
PersistentVolume(PV):
PV 是集群中的一块持久化存储,它是集群管理员预先配置好的存储资源。
PV 可以是网络存储(如 NFS、GlusterFS、Ceph)、云存储(如 AWS EBS、Azure Disk)、本地存储(HostPath)等。
PV 与存储后端进行绑定,表示集群中的可用存储资源,支持的后端存储类型详情请查看K8S官方文档
PersistentVolumeClaim(PVC):
PVC 是 Pod 中的容器对 PV 的申请。PVC 定义了对存储资源的需求,包括存储容量、访问模式和其他属性。
Kubernetes 会根据 PVC 的需求匹配可用的 PV,并将其动态绑定到 Pod 中。
PV的创建方式:静态或者动态
静态创建:
直接固定存储空间: 集群管理员创建一些 PV。它们携带可供集群用户使用的真实存储的详细信息。 它们存在于Kubernetes API中,可用于消费。
动态创建:
通过存储类(StorageClasses)动态创建存储空间: PVC 必须请求存储类,并且管理员必须已创建并配置该类才能进行动态配置。
关键词解释
kubectl explain pv.spec
pv.spec.capacity.storage: 1Gi:定义了 PV 的存储容量为 1Gi。
pv.spec.volumeMode: Filesystem:指定了 PV 的卷模式为文件系统。
pv.spec.accessModes: # ReadWriteOnce(RWO) 只允许单个worker节点读写存储卷,但是该节点的多个Pod是可以同时访问该存储卷的# ReadOnlyMany(ROX) 允许多个worker节点进行只读存储卷。# ReadWriteMany(RWX) 允许多个worker节点进行读写存储卷。# ReadWriteOncePod(RWOP) 整个集群中只有一个pod可以读取或写入存储卷
pv.spec.persistentVolumeReclaimPolicy: # 指定存储卷的回收策略,常用的有"Retain"和"Delete"#Retain:# 当绑定的pvc被删除时,pv不会被删,该卷状态变为"Released"。数据的删除需要人工干预# 生产环境中,如果对数据安全性要求极高,或者需要执行特定的数据备份或审计流程后再清理存储资源,通常会选择Retain策略。# 管理员可以手动决定何时以及如何安全地释放和清理PV,在管理员手动回收资源之前,使用该策略其他Pod将无法直接使用。#Delete:# PV会随着绑定的PVC的删除而一同被删除#Recycle:# 在这种策略下,PV被释放后,底层存储资源会被清空,以便下次使用。然而,这种方式存在安全性和隐私问题,因此已经不推荐使用。PV的状态值及解释状态 解析Availabled 空闲状态,表示pv没有被其他对象使用Bound 绑定状态,表示pv已经被其他对象使用Released 未回收状态,表示pvc已经被删除了,但是资源没有被回收Faild 资源回收失败36.1.1. 静态创建PV案例(pod调用pvc)
(1)准备nfs共享路径
[root@k8s231 ~]# mkdir -p /k8s/volume/pv00{1,2,3}
-------------------------------------------------------------------(2)手动创建3个pv
[root@k8s231 ~]# cat > 01-manual-pv.yaml <<'EOF'
apiVersion: v1
kind: PersistentVolume
metadata:name: pv01
spec: accessModes:- ReadWriteMany nfs:path: /k8s/volume/pv001server: 10.0.0.231 persistentVolumeReclaimPolicy: Retain capacity:storage: 2Gi
---
apiVersion: v1
kind: PersistentVolume
metadata:name: pv02
spec:accessModes:- ReadWriteManynfs:path: /k8s/volume/pv002server: 10.0.0.231persistentVolumeReclaimPolicy: Retaincapacity:storage: 5Gi
---
apiVersion: v1
kind: PersistentVolume
metadata:name: pv03
spec:accessModes:- ReadWriteManynfs:path: /k8s/volume/pv003server: 10.0.0.231persistentVolumeReclaimPolicy: Retaincapacity:storage: 10Gi
EOF[root@k8s231 pv]# kubectl apply -f 01-manual-pv.yaml
[root@k8s231 pv]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pv01 2Gi RWX Retain Available 23s
pv02 5Gi RWX Retain Available 23s
pv03 10Gi RWX Retain Available 23sNAME : pv的名称CAPACITY : pv的容量ACCESS MODES: pv的访问模式RECLAIM POLICY: pv的回收策略。STATUS : pv的状态。CLAIM: pv被哪个pvc使用。STORAGECLASS: sc的名称。REASON: pv出错时的原因。AGE: 创建的时间
------------------------------------------------------------------- (3)创建pvc
[root@k8s231 pv]# cat > 01-manual-pvc.yaml <<EOF
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: pvc
spec:accessModes:- ReadWriteManyresources:limits:storage: 4Girequests:storage: 3Gi
EOF
[root@k8s231 pv]# kubectl apply -f 01-manual-pvc.yaml
[root@k8s231 pv]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
pvc Bound pv03 10Gi RWX 2s
------------------------------------------------------------------- (4)创建pod关联pvc
[root@k8s231 pv]# cat > 01-deploy-nginx-pvc.yaml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:name: deploy
spec:replicas: 2selector:matchExpressions:- key: appsoperator: Existstemplate:metadata:labels:apps: nginxspec:volumes:- name: pv-nginx persistentVolumeClaim: claimName: pvccontainers:- name: webimage: nginx:alpinevolumeMounts:- name: pv-nginxmountPath: /usr/share/nginx/html
---
apiVersion: v1
kind: Service
metadata:name: svc-nginx
spec:type: NodePortselector:apps: nginxports:- port: 80targetPort: 80nodePort: 30080
EOF#下面可以看到pvc和pv02绑定了
[root@k8s231 pv]# kubectl get pod,pv,pvc -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/deploy-7999ff9f68-f88jl 1/1 Running 0 8s 10.200.1.80 k8s232.tom.com <none> <none>
pod/deploy-7999ff9f68-rjb8b 1/1 Running 0 8s 10.200.1.79 k8s232.tom.com <none> <none>NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE VOLUMEMODE
persistentvolume/pv01 2Gi RWX Retain Available 8s Filesystem
persistentvolume/pv02 5Gi RWX Retain Bound default/pvc 8s Filesystem
persistentvolume/pv03 10Gi RWX Retain Available 8s FilesystemNAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE VOLUMEMODE
persistentvolumeclaim/pvc Bound pv02 5Gi RWX 8s Filesystem36.1.2. 动态创建pv案例(pod调用sc)
动态存储配置允许Kubernetes动态地创建PV以满足PVC的存储需求
每个 StorageClass 都包含 provisioner、parameters 和 reclaimPolicy 字段
Provisioner:每个 StorageClass 都有一个制备器(Provisioner),用来决定使用哪个卷插件制备 PV,该字段必须指定
有内置制备器和外部制备器,nfs就是外置制备器

(1)nfs server准备好
10.0.0.231
/k8s/volume/ *(rw,no_root_squash)(2)下载外部nfs Provisioner
[root@k8s231 sts]# wget https://github.com/kubernetes-sigs/nfs-subdir-external-provisioner/archive/refs/tags/nfs-subdir-external-provisioner-4.0.2.zip
[root@k8s231 sts]# unzip nfs-subdir-external-provisioner-4.0.2.zip
[root@k8s231 sc]# cd nfs-subdir-external-provisioner-nfs-subdir-external-provisioner-4.0.2/deploy(3)rbac为nfs制备器授权访问k8s集群 创建了ServiceAccount并授权,后面provisioner的pod会使用这个serviceAccount来访问集群
[root@k8s231 deploy]# kubectl apply -f rbac.yaml (4)创建nfs制备器(pod),需要修改文件中的nfs信息,制备器的镜像地址(地址在国内访问被墙)
# image: registry.k8s.io/sig-storage/nfs-subdir-external-provisioner:v4.0.2 国内拉取不到,换成下面这个
#image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/nfs-subdir-external-provisioner:v4.0.2
[root@k8s231 deploy]# vim deployment.yaml.......
#修改 image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/nfs-subdir-external-provisioner:v4.0.2volumeMounts:- name: nfs-client-rootmountPath: /persistentvolumesenv:- name: PROVISIONER_NAME
#修改 value: nfs-provisioner- name: NFS_SERVER
#修改 value: 10.0.0.231- name: NFS_PATH
#修改 value: /k8s/volumevolumes:- name: nfs-client-rootnfs:
#修改 server: 10.0.0.231
#修改 path: /k8s/volume
[root@k8s231 deploy]# kubectl apply -f deployment.yaml(5) 部署storage class(动态存储类),class.yaml中使用了NFS外部制备器
vim class.yaml
#修改 provisioner: nfs-provisioner
[root@k8s231 deploy]# kubectl apply -f class.yaml(6)查看nfs制备器是否制作成功
[root@k8s231 deploy]# kubectl get pods,sc
NAME READY STATUS RESTARTS AGE
pod/nfs-client-provisioner-6474d57566-vr9dw 1/1 Running 0 29sNAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
storageclass.storage.k8s.io/nfs-client k8s-sigs.io/nfs-subdir-external-provisioner Delete Immediate false 28m(7)验证制备器是否能成功创建pv,#test-claim.yaml中创建了一个pvc,且指定使用了storageClassName: managed-nfs-storage#test-pod.yaml中容器挂载了上面这个pvc, persistentVolumeClaim: claimName: test-claim
[root@k8s231 sc]# kubectl apply -f test-claim.yaml -f test-pod.yaml(8)查看pv,pvc绑定,且pv是使用nfs-client存储类创建的
[root@k8s231 deploy]# kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc-522b3a0b-891d-4210-81e4-87795486fe56 1Mi RWX Delete Bound default/test-claim nfs-client 24sNAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/test-claim Bound pvc-522b3a0b-891d-4210-81e4-87795486fe56 1Mi RWX nfs-client 24s37. add-on附加组件之Dashboard

Dashboard,它是一个k8s附加组件,可以以图形化的方式管理k8s资源,需要单独部署。
GitHub地址: Releases · kubernetes/dashboard · GitHub
37.1. 部署dashbord
由于我们部署的k8s是1.23版本,所以选择完全支持的dashboard版本为2.5.1
(1)下载dashbord
[root@k8s231 dashabord]# wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.5.1/aio/deploy/recommended.yaml -O k8s_1_23-dashabord.yaml (2)修改資源清单,把svc修改为NodePort,添加端口8443,用于浏览器访问
[root@k8s231 dashabord]# vim k8s_1_23-dashabord.yaml
...
kind: Service
spec:#添加类型 type: NodePortports:- port: 443targetPort: 8443# 添加端口映射nodePort: 8443(3)创建dashbord
[root@k8s231 dashabord]# kubectl apply -f k8s_1_23-dashabord.yaml (4)访问dashboard页面
https://10.0.0.231:8443/37.2. 登录dashbord

37.2.1. token方式登录dashbord
#创建用于访问集群的sa并授权
[root@k8s231 dashbord]# cat > dashboard-rbac.yaml <<EOF
apiVersion: v1
kind: ServiceAccount
metadata:labels:k8s-app: kubernetes-dashboardname: sa-dashbordnamespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:labels:k8s-app: kubernetes-dashboardname: dashboardnamespace: kube-system
roleRef:apiGroup: rbac.authorization.k8s.io kind: ClusterRole# 关于集群角色可以使用"kubectl get clusterrole | grep admin"进行过滤哟~name: cluster-admin
subjects:- kind: ServiceAccount name: sa-dashbordnamespace: kube-system
EOF
[root@k8s231 dashbord]# kubectl apply -f dashboard-rbac.yaml#获取为sa自动创建的secret名称
[root@k8s231 dashbord]# kubectl -n kube-system describe sa sa-dashbord|awk '/^Tokens/{print $2}'
sa-dashbord-token-qb2wc
#获取secret信息内的token信息
[root@k8s231 dashbord]# kubectl -n kube-system describe secrets sa-dashbord-token-qb2wc|awk '/^token/{print $2}'
eyJhbGciOiJSUzI1NiIsImtpZCI6IjZuYnp4QWxFODJVc3BvOXVZNEh1TkdNMzZrTVpCbUkwMC1hTktRaE4tOEEifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJzYS1kYXNoYm9yZC10b2tlbi1xYjJ3YyIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50Lm5hbWUiOiJzYS1kYXNoYm9yZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VydmljZS1hY2NvdW50LnVpZCI6IjRiOGI2NzQxLTk0NzktNDcyMi1iNWJiLWFkODY5ODM2N2FhNyIsInN1YiI6InN5c3RlbTpzZXJ2aWNlYWNjb3VudDprdWJlLXN5c3RlbTpzYS1kYXNoYm9yZCJ9.R0qYF8a0F_OHJDCkE_MhYmoOjkHdCppsdp3-9b0uoExCTs3roEd0x95YUvAAGnid2k-VRC8W6rgjyQS-Ah37BPE35KC7hD4XvnczhlzyqYar6T3-f09CErVUnppfUhcg_7K7Ah-hy1UmTYECEpxkHPdwCxSONQ8x2PNcFMvwOuJU4yTmnhiceJQr6dOrY71rgg5SwEwitj6magp-O0bpGhhffWDiOo5wfN_O7OAUrrym99JjDnlaM8NsB3i5-mUnuqi271Elh1zLnp_MRoLnZRVX3ohGbIO0D00yfs8fekxMuE4mNaII37PhrjCf6oD6F0R2ZWYUVvhsY7w6V9alGA#可以把上面两条命令合并成一条命令获取token
kubectl -n kube-system describe secrets `kubectl -n kube-system describe sa sa-dashbord|awk '/^Tokens/{print $2}'`|awk '/^token/{print $2}'#用上面获取的token就可以在浏览器上登录dashbord37.2.2. kubeconfig方式登录dashbord
#创建用于连接k8s的kubeconfig
[root@k8s231 dashbord]# cat > generate-kubeconfig.sh <<'EOF'
#!/bin/bash
[ $# -ne 1 ] && {echo "usage $0 sa的名字"exit 1
}
#从参数中获取sa的名称,此sa需为已创建
SA_NAME=$1# 指定API SERVER的地址
API_SERVER=k8s231.tom.com:6443# 指定kubeconfig配置文件的路径名称
KUBECONFIG_NAME="`pwd`/dashbord.kubeconfig"
#KUBECONFIG_NAME="/root/dashbord.kubeconfig"# 获取tocken
TOCKEN=$(kubectl -n kube-system describe secrets `kubectl -n kube-system describe sa ${SA_NAME}|awk '/^Tokens/{print $2}'`|awk '/^token/{print $2}')# 在kubeconfig配置文件中设置群集项
kubectl config set-cluster dashboard-cluster --server=$API_SERVER --kubeconfig=${KUBECONFIG_NAME}# 在kubeconfig中设置用户项
kubectl config set-credentials dashbord-user --token=${TOCKEN} --kubeconfig=${KUBECONFIG_NAME}# 配置上下文,即绑定用户和集群的上下文关系,可以将多个集群和用户进行绑定
kubectl config set-context dashbord-context --cluster=dashboard-cluster --user=dashbord-user --kubeconfig=${KUBECONFIG_NAME}# 配置当前使用的上下文
kubectl config use-context dashbord-context --kubeconfig=${KUBECONFIG_NAME}echo -e "输出: serviceaccount: $SA_NAME \t 生成的kubeconfig路径为:\t ${KUBECONFIG_NAME}"
EOF[root@k8s231 dashbord]# bash generate-kubeconfig.sh sa-dashbord
Cluster "dashboard-cluster" set.
User "dashbord-user" set.
Context "dashbord-context" modified.
Switched to context "dashbord-context".
输出: serviceaccount: sa-dashbord 生成的kubeconfig路径为: /manifests/dashbord/dashbord.kubeconfig#把生成的kubeconfig文件上传到windows桌面
[root@k8s231 dashbord]# sz /manifests/dashbord/dashbord.kubeconfig#浏览器选择kubeconfig,选择windows桌面的kubeconfig文件上传,即可登录38. 控制器之StatefulSet
StatefulSet概述:
RC、Deployment、DaemonSet都是面向无状态的服务,它们所管理的Pod的IP、名字,启停顺序等都是随机的,
StatefulSet管理所有有状态的服务,比如MySQL、MongoDB集群等。
StatefulSet具有以下特点。
(1)稳定唯一的网络标识符。 (内置coreDns实现)
(2)稳定独立持久的存储。 (volumeClaimTemplates实现)
(4)有序的部署和缩放,有序自动的滚动更新
mkdir -p /manifests/sts && cd /manifests/sts
------------------------------------------------------------------------------------------------------(1)准备好stroage class的nfs provisioner用于创建PV(1)nfs server准备好
10.0.0.231
/k8s/volume/ *(rw,no_root_squash)(2)下载外部nfs Provisioner
[root@k8s231 sts]# wget https://github.com/kubernetes-sigs/nfs-subdir-external-provisioner/archive/refs/tags/nfs-subdir-external-provisioner-4.0.2.zip
[root@k8s231 sts]# unzip nfs-subdir-external-provisioner-4.0.2.zip
[root@k8s231 sc]# cd nfs-subdir-external-provisioner-nfs-subdir-external-provisioner-4.0.2/deploy(3)rbac为nfs制备器授权访问k8s集群 创建了ServiceAccount并授权,后面provisioner的pod会使用这个serviceAccount来访问集群
[root@k8s231 sc]# kubectl apply -f rbac.yaml (4)创建nfs制备器(pod),需要修改文件中的nfs信息,制备器的镜像地址(地址在国内访问被墙)
# image: registry.k8s.io/sig-storage/nfs-subdir-external-provisioner:v4.0.2 国内拉取不到,换成下面这个
#image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/nfs-subdir-external-provisioner:v4.0.2
[root@k8s231 sc]# vim deployment.yaml.......
#修改 image: registry.cn-hangzhou.aliyuncs.com/lfy_k8s_images/nfs-subdir-external-provisioner:v4.0.2volumeMounts:- name: nfs-client-rootmountPath: /persistentvolumesenv:- name: PROVISIONER_NAME
#修改 value: nfs-provisioner- name: NFS_SERVER
#修改 value: 10.0.0.231- name: NFS_PATH
#修改 value: /k8s/volumevolumes:- name: nfs-client-rootnfs:
#修改 server: 10.0.0.231
#修改 path: /k8s/volume
[root@k8s231 sc]# kubectl apply -f deployment.yaml
------------------------------------------------------------------------------------------------------(2)创建storage class调用nfs provisioner
cat > nginx-sc.yaml << EOF
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:name: nginx-nfs-storage
provisioner: nfs-provisioner
parameters:archiveOnDelete: "false" # # When set to "false" your PVs will not be archived# by the provisioner upon deletion of the PVC.
EOF
[root@k8s231 sc]# kubectl apply -f nginx-sc.yaml
------------------------------------------------------------------------------------------------------(3)创建headless service,给statefulset用
创建headless service
cat > nginx-headless-svc.yaml << EOF
apiVersion: v1
kind: Service
metadata:name: nginx-headless-svc
spec:ports:- port: 80name: webclusterIP: Noneselector:app: nginx
EOF
[root@k8s231 sc]# kubectl apply -f nginx-headless-svc.yaml
------------------------------------------------------------------------------------------------------(4)创建statefulset,观察pod的创建,会发现是有序创建
cat > nginx-sts.yaml << EOF
apiVersion: apps/v1
kind: StatefulSet
metadata:name: nginx-sts
spec:selector:matchLabels:app: nginxserviceName: "nginx-headless-svc" replicas: 3 template:metadata:labels:app: nginx spec:terminationGracePeriodSeconds: 10containers:- name: nginximage: nginx:alpineports:- containerPort: 80name: webvolumeMounts:- name: nginx-pvcmountPath: /usr/share/nginx/htmlvolumeClaimTemplates:- metadata:name: nginx-pvcspec:accessModes: [ "ReadWriteOnce" ]storageClassName: "nginx-nfs-storage"resources:requests:storage: 1Gi
EOF
[root@k8s231 sc]# kubectl apply -f nginx-sts.yaml
#观察pod的创建,会发现是有序创建
[root@k8s231 sc]# kubectl describe stsNormal SuccessfulCreate 35s statefulset-controller create Claim nginx-pvc-nginx-sts-0 Pod nginx-sts-0 in StatefulSet nginx-sts successNormal SuccessfulCreate 35s statefulset-controller create Pod nginx-sts-0 in StatefulSet nginx-sts successfulNormal SuccessfulCreate 32s statefulset-controller create Claim nginx-pvc-nginx-sts-1 Pod nginx-sts-1 in StatefulSet nginx-sts successNormal SuccessfulCreate 32s statefulset-controller create Pod nginx-sts-1 in StatefulSet nginx-sts successfulNormal SuccessfulCreate 29s statefulset-controller create Claim nginx-pvc-nginx-sts-2 Pod nginx-sts-2 in StatefulSet nginx-sts successNormal SuccessfulCreate 29s statefulset-controller create Pod nginx-sts-2 in StatefulSet nginx-sts successful[root@k8s231 sts]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nfs-client-provisioner-bcdf6bfbb-gq5gs 1/1 Running 0 41m 10.200.1.89 k8s232.tom.com <none> <none>
nginx-sts-0 1/1 Running 0 28m 10.200.1.90 k8s232.tom.com <none> <none>
nginx-sts-1 1/1 Running 0 27m 10.200.1.91 k8s232.tom.com <none> <none>
nginx-sts-2 1/1 Running 0 27m 10.200.1.92 k8s232.tom.com <none> <none>#pod使用的pvc
[root@k8s231 sts]# kubectl describe pod|grep ClaimNameClaimName: nginx-pvc-nginx-sts-0ClaimName: nginx-pvc-nginx-sts-1ClaimName: nginx-pvc-nginx-sts-2#观察pvc对sc调用,然后sc生成了pv与pvc绑定
[root@k8s231 sts]# kubectl get pvc,sc,pv
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/nginx-pvc-nginx-sts-0 Bound pvc-063a16a5-24a9-46f2-84dd-5905234f761e 1Gi RWO nginx-nfs-storage 10m
persistentvolumeclaim/nginx-pvc-nginx-sts-1 Bound pvc-3e6c9d1e-8528-4093-a5ad-2195053988b5 1Gi RWO nginx-nfs-storage 10m
persistentvolumeclaim/nginx-pvc-nginx-sts-2 Bound pvc-ac54e9ce-6d68-4fe9-a0bc-4f90a2656d9b 1Gi RWO nginx-nfs-storage 10mNAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
storageclass.storage.k8s.io/nginx-nfs-storage nfs-provisioner Delete Immediate false 23mNAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc-063a16a5-24a9-46f2-84dd-5905234f761e 1Gi RWO Delete Bound default/nginx-pvc-nginx-sts-0 nginx-nfs-storage 10m
persistentvolume/pvc-3e6c9d1e-8528-4093-a5ad-2195053988b5 1Gi RWO Delete Bound default/nginx-pvc-nginx-sts-1 nginx-nfs-storage 10m
persistentvolume/pvc-ac54e9ce-6d68-4fe9-a0bc-4f90a2656d9b 1Gi RWO Delete Bound default/nginx-pvc-nginx-sts-2 nginx-nfs-storage 10m
------------------------------------------------------------------------------------------------------(5)验证稳定唯一的网络标识符(通过名称可动态获取ip,就算pod删除重建也没事)
[root@k8s231 sts]# dig @10.100.0.10 nginx-sts-0.nginx-headless-svc.default.svc.tom.com +short
10.200.1.90
[root@k8s231 sts]# dig @10.100.0.10 nginx-sts-1.nginx-headless-svc.default.svc.tom.com +short
10.200.1.91
[root@k8s231 sts]# dig @10.100.0.10 nginx-sts-2.nginx-headless-svc.default.svc.tom.com +short
10.200.1.92
------------------------------------------------------------------------------------------------------(6)稳定独立持久的存储(每个pod拥有自己的pv)
#每个容器内写入内容,发现各容器内容不同,相互对立,删除pod后重建,内容未丢失
[root@k8s231 sts]# for i in `seq 0 2`;do kubectl exec nginx-sts-${i} -- sh -c "echo web${i} > /usr/share/nginx/html/index.html";done
[root@k8s231 sts]# for i in `seq 0 2`;do curl `dig @10.100.0.10 nginx-sts-${i}.nginx-headless-svc.default.svc.tom.com +short`;done
web0
web1
web2
[root@k8s231 sts]# for i in `seq 0 2`;do kubectl delete pod nginx-sts-${i};done
pod "nginx-sts-0" deleted
pod "nginx-sts-1" deleted
pod "nginx-sts-2" deleted
[root@k8s231 sts]# for i in `seq 0 2`;do curl `dig @10.100.0.10 nginx-sts-${i}.nginx-headless-svc.default.svc.tom.com +short`;done
web0
web1
web239. metric-server:
Metrics Service 是一种用于提供集群内 Pod 和节点资源使用情况(如 CPU、内存等)的标准接口
Metrics Server 并不是 kube-apiserver 的一部分,而是通过 Aggregator 这种插件机制,在独立部署的情况下同 kube-apiserver 一起统一对外服务的。
部署metric-server:(1)下载资源清单
[root@k8s231]# mkdir -p /manifests/metric-server && cd /manifests/metric-server
[root@k8s231 metrics-server]# wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/high-availability-1.21+.yaml(2)修改资源清单,修改deploy资源两处
[root@k8s231 metrics-server]# vim high-availability-1.21+.yaml
...
apiVersion: apps/v1
kind: Deployment
...
spec:...template:...spec:# 在args后添加"--kubelet-insecure-tls",和"image"字段。- args:- --kubelet-insecure-tls# image: registry.k8s.io/metrics-server/metrics-server:v0.6.3image: registry.aliyuncs.com/google_containers/metrics-server:v0.6.3(3)创建应用
[root@k8s231 metrics-server]# kubectl apply -f high-availability-1.21+.yaml (4)检查状态
[root@k8s231 metric-server]# kubectl -n kube-system get pods | grep metrics-server
metrics-server-6f9dcd57c7-dzp5b 1/1 Running 0 77s
metrics-server-6f9dcd57c7-k9x2n 1/1 Running 0 3m17s(5)验证 metrics-server是否正常
[root@k8s231 metric-server]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s231.tom.com 137m 6% 1429Mi 52%
k8s232.tom.com 53m 2% 919Mi 33%
k8s233.tom.com 35m 1% 570Mi 20%
[root@k8s231 metric-server]# kubectl top pod
NAME CPU(cores) MEMORY(bytes)
nfs-client-provisioner-bcdf6bfbb-gq5gs 2m 7Mi
nginx-sts-0 0m 2Mi
nginx-sts-1 0m 2Mi
nginx-sts-2 0m 2Mi 40. HPA(Pod 水平自动伸缩)
HPA全称是 Horizontal Pod Autoscaler,也就是对k8s的workload的副本数进行自动水平扩缩容(scale)机制,也是k8s里使用需求最广泛的一种Autoscaler机制
使用HPA,metrics-server 也需要部署到集群中, 它通过 resource metrics API 对外提供度量数据
40.1. 工作原理
- 指标收集:
HPA监控Pod的资源使用情况,只有部署了Metrics Server,这些指标可以通过Kubernetes的Metrics API获取,或者使用自定义的指标提供者(如Prometheus)。
- 计算扩缩容:
HPA根据当前的资源使用情况和预设的目标值(如CPU的目标利用率)计算出所需的Pod副本数量。如果当前的资源使用超过了目标值,HPA会增加Pod副本数量;如果资源使用 低于目标值,HPA会减少Pod副本数量。
- 执行扩缩容:
HPA通过更新相关的Deployment或ReplicaSet来改变Pod副本的数量。增加副本时,Kubernetes会创建新的Pod;减少副本时,会删除多余的Pod。
同时,为了避免过于频繁的扩缩容,默认再5分钟内没有重新扩缩容的情况下,才会触发扩缩容
40.2. HPA的配置关键参数
ScaleTargetRef:指定 HPA 将要作用的资源对象,如 Deployment、Replica Set 或 RC 的名称。
MinReplicas:最小副本数,即使在负载很低时也不会低于这个数量。
MaxReplicas:最大副本数,即使在负载很高时也不会超过这个数量。
Metrics:定义用于触发伸缩的度量标准和目标值。例如,设置 CPU 的利用率目标,当实际利用率超过这个值时,HPA 会增加副本数量;反之则会减少副本量
40.3. 声明式创建HPA
#声明式创建HPA
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:name: web
spec:minReplicas: 1maxReplicas: 1000metrics:- pods:metric:name: k8s_pod_rate_cpu_core_used_limittarget:averageValue: "80"type: AverageValuetype: PodsscaleTargetRef:apiVersion: apps/v1kind: Deploymentname: web
#-----------------------下面这段可不写,是默认的,也可以修改为自己想要的效果behavior: # 这里是重点scaleDown:stabilizationWindowSeconds: 300 # 需要缩容时,先观察 5 分钟,如果一直持续需要缩容才执行缩容policies:- type: Percentvalue: 100 # 允许全部缩掉periodSeconds: 15scaleUp:stabilizationWindowSeconds: 0 # 需要扩容时,立即扩容policies:- type: Percentvalue: 100periodSeconds: 15 # 每 15s 最大允许扩容当前 1 倍数量的 Pod- type: Podsvalue: 4periodSeconds: 15 # 每 15s 最大允许扩容 4 个 PodselectPolicy: Max # 使用以上两种扩容策略中算出来扩容 Pod 数量最大的40.4. 响应式创建HPA
- 响应式创建规则:
[root@k8s231 horizontalpodautoscalers]# kubectl autoscale deployment web --min=2 --max=5 --cpu-percent=8040.5. 查看HPA
使用 kubectl get hpa 命令查看 HPA 的状态,包括当前的 CPU 负载百分比、最小和最大 Pod 数量以及当前的 Pod 副本数
[root@k8s231 horizontalpodautoscalers]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
web Deployment/web 138%/80% 2 5 5 18m41. Helm
41.1. helm相关概念
41.1.1. 什么是Helm
在没使用 helm 之前,向 kubernetes 部署应用,我们要依次部署 deployment、svc 等,步骤较繁琐。 况且随着很多项目微服务化,复杂的应用在容器中部署以及管理显得较为复杂,
Helm 通过动态生成 K8s 资源清单文件(deployment.yaml、service.yaml)。然后调用 Kubectl 自动执行 K8s 资源部署。很大程度上简化了 Kubernetes 应用的部署和管理
41.1.2. Helm 有三个重要的概念
Helm 有三个重要的概念:Chart 、Repository 和 Release
1.2.1 Chart
Chart:Helm 的软件包,采用 TAR 格式。类似于 APT 的 DEB 包或者 YUM 的 RPM 包,其包含了一组定义 Kubernetes 资源相关的 YAML 文件。
1.2.2 Repository(仓库)
Helm 的软件仓库,Repository 本质上是一个 Web 服务器,该服务器保存了一系列的 Chart 软件包以供用户下载,并且提供了一个该 Repository 的 Chart 包的清单文件以供查询。Helm 可以同时管理多个不同的 Repository
1.2.3 Release
使用 helm install 命令在 Kubernetes 集群中部署的 Chart 称为 Release。可以理解为 Helm 使用 Chart 包部署的一个应用实例。一个 chart 通常可以在同一个集群中安装多次。每一次安装都会创建一个新的 release
以 MySQL chart 为例,如果你想在你的集群中运行两个数据库,你可以安装该 chart 两次。每一个数据库都会拥有它自己的 release 和 release name。可以将 release 想象成应用程序发布的版本号。
总结:Helm 安装 charts 到 Kubernetes 集群中,每次安装都会创建一个新的 release。你可以在 Helm 的 chart repositories 中寻找新的 chart
41.1.3. Helm3 与 Helm2 的区别
Helm2 是 C/S 架构,主要分为客户端 helm 和服务端 Tiller。在 Helm 2 中,Tiller 是作为一个 Deployment 部署在 kube-system 命名空间中,很多情况下,我们会为 Tiller 准备一个 ServiceAccount ,这个 ServiceAccount 通常拥有集群的所有权限。
用户可以使用本地 Helm 命令,自由地连接到 Tiller 中并通过 Tiller 创建、修改、删除任意命名空间下的任意资源。
在 Helm 3 中,Tiller 被移除了。新的 Helm 客户端会像 kubectl 命令一样,读取本地的 kubeconfig 文件,使用我们在 kubeconfig 中预先定义好的权限来进行一系列操作。
heml3的兼容性更好,一般使用heml3
41.2. Helm部署
Helm 的官方网站 Helm
Helm部署-(1)下载helm
[root@k8s231 ]# mkdir -p /manifests/helm && cd /manifests/helm
[root@k8s231 helm]# wget https://get.helm.sh/helm-v3.9.0-linux-amd64.tar.gz-(2)解压helm程序到指定目录
[root@k8s231 helm]# tar -xvf helm-v3.9.0-linux-amd64.tar.gz
[root@k8s231 helm]# mv linux-amd64/helm /usr/bin/-(3)验证helm安装成功
[root@k8s231 helm]# helm version
version.BuildInfo{Version:"v3.9.0", GitCommit:"7ceeda6c585217a19a1131663d8cd1f7d641b2a7", GitTreeState:"clean", GoVersion:"go1.17.5"}-(4)配置helm命令的自动补全-新手必备
[root@k8s231 helm]# helm completion bash > /etc/bash_completion.d/helm
[root@k8s231 helm]# source /etc/bash_completion.d/helm
[root@k8s231 helm]# helm # 连续按2次tab键,出现如下内容则成功
completion (generate autocompletion scripts for the specified shell)
create (create a new chart with the given name)
dependency (manage a chart's dependencies)-(5)添加常用的 chart 仓库
[root@k8s231 helm]# helm repo add bitnami https://charts.bitnami.com/bitnami
[root@k8s231 helm]# helm repo add stable http://mirror.azure.cn/kubernetes/charts
[root@k8s231 helm]# helm repo add aliyun https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
[root@k8s231 helm]# helm repo add incubator https://charts.helm.sh/incubator
[root@k8s231 helm]# helm repo update
[root@k8s231 helm]# helm repo list
NAME URL
bitnami https://charts.bitnami.com/bitnami
stable http://mirror.azure.cn/kubernetes/charts
aliyun https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts
incubator https://charts.helm.sh/incubator -(5)helm repo使用
#搜索BitnamiHelm仓库中关于Nginx的chart
[root@k8s231 helm]# helm search repo bitnami/nginx
NAME CHART VERSION APP VERSION DESCRIPTION
bitnami/nginx 18.1.9 1.27.1 NGINX Open Source is a web server that can be a...
bitnami/nginx-ingress-controller 11.3.20 1.11.2 NGINX Ingress Controller is an Ingress controll...
bitnami/nginx-intel 2.1.15 0.4.9 DEPRECATED NGINX Open Source for Intel is a lig...
#搜索已添加的几个仓库中关于Nginx的chart
[root@k8s231 helm]# helm search repo nginx
NAME CHART VERSION APP VERSION DESCRIPTION
aliyun/nginx-ingress 0.9.5 0.10.2 An nginx Ingress controller that uses ConfigMap...
aliyun/nginx-lego 0.3.1 Chart for nginx-ingress-controller and kube-lego
bitnami/nginx 18.1.9 1.27.1 NGINX Open Source is a web server that can be a...
bitnami/nginx-ingress-controller 11.3.20 1.11.2 NGINX Ingress Controller is an Ingress controll...
bitnami/nginx-intel 2.1.15 0.4.9 DEPRECATED NGINX Open Source for Intel is a lig...
stable/nginx-ingress 1.41.3 v0.34.1 DEPRECATED! An nginx Ingress controller that us...
stable/nginx-ldapauth-proxy 0.1.6 1.13.5 DEPRECATED - nginx proxy with ldapauth
stable/nginx-lego 0.3.1 Chart for nginx-ingress-controller and kube-lego
aliyun/gcloud-endpoints 0.1.0 Develop, deploy, protect and monitor your APIs ...
stable/gcloud-endpoints 0.1.2 1 DEPRECATED Develop, deploy, protect and monitor...#查看指定 chart 的基本信息
helm show chart bitnami/nginx 获取指定 chart 的所有信息
helm show all bitnami/nginx 41.3. helm部署服务:
Chart 是 Helm 用来部署 Kubernetes 应用的包。一个 Chart 包含一系列的 Kubernetes 资源定义文件(YAML 格式),以及一个描述 Chart 的 Chart.yaml 文件和一个用于配置变量的 values.yaml 文件,配置不同的vules.yaml可以使得同一Chart可以根据不同的环境或需求进行参数化部署, charts 除了可以在 repo 中下载,还可以自己自定义,创建完成后通过 helm 部署到 k8s
helm create 可以创建一个 chart 包,目录结构说明如下:
helm-test:是 chart 包的名称charts目录: 保存依赖文件的目录,如果依赖其他的 chart,则会保存在这里Chart.yaml文件:用于描述 chart 信息的 yaml 文件,如版本信息等values.yaml文件:其他文件引用的变量参数可以在这里定义。在chart安装时,可以通过--set key1=value1方式把定义在values.yaml中的变量覆盖templates目录:各类 Kubernetes 资源的配置模板都放置在这里。Helm 会将 values.yaml 中的参数值注入到模板中生成标准的 YAML 配置文件
41.3.1. 自定义chart
自定义chart(1)创建chart
[root@k8s231 helm]# helm create chart01(2)可自定义修改内容后,检查依赖和模版配置是否正确
[root@k8s231 helm]# helm lint chart01
==> Linting chart01
[INFO] Chart.yaml: icon is recommended
1 chart(s) linted, 0 chart(s) failed(3)安装release,可根据不同的配置来 install,默认是 values.yaml
[root@k8s231 helm]# helm install web01 chart01 -n default -f ./chart01/values.yaml
NAME: web01
LAST DEPLOYED: Mon Aug 19 18:02:59 2024
NAMESPACE: default
STATUS: deployed
REVISION: 1
NOTES:
1. Get the application URL by running these commands:export POD_NAME=$(kubectl get pods --namespace default -l "app.kubernetes.io/name=chart01,app.kubernetes.io/instance=web01" -o jsonpath="{.items[0].metadata.name}")export CONTAINER_PORT=$(kubectl get pod --namespace default $POD_NAME -o jsonpath="{.spec.containers[0].ports[0].containerPort}")echo "Visit http://127.0.0.1:8080 to use your application"kubectl --namespace default port-forward $POD_NAME 8080:$CONTAINER_PORT(4)查看所有 release
helm ls或list
[root@k8s231 helm]# helm ls -n default
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
web01 default 1 2024-08-19 18:02:59.113323444 +0800 CST deployed chart01-0.1.0 1.16.0 (5)查看指定的 release 状态
[root@k8s231 helm]# helm status web01 -n default
NAME: web01
LAST DEPLOYED: Mon Aug 19 18:02:59 2024
NAMESPACE: default
STATUS: deployed
REVISION: 1
NOTES:
1. Get the application URL by running these commands:export POD_NAME=$(kubectl get pods --namespace default -l "app.kubernetes.io/name=chart01,app.kubernetes.io/instance=web01" -o jsonpath="{.items[0].metadata.name}")export CONTAINER_PORT=$(kubectl get pod --namespace default $POD_NAME -o jsonpath="{.spec.containers[0].ports[0].containerPort}")echo "Visit http://127.0.0.1:8080 to use your application"kubectl --namespace default port-forward $POD_NAME 8080:$CONTAINER_PORT#port-forward 仅供开发和调试。在生产环境中,考虑使用 Service、Ingress 或其他方法来暴露应用。虽然 port-forward 可以让你访问内部服务,但它不提供任何安全性保障。
#确保只在受信任的网络中使用。当你完成转发操作后,记得关闭 kubectl port-forward 命令以释放端口。
#你可以一次转发多个端口。例如,如果你的 Pod 有两个服务在 80 和 443 端口上,你可以这样做
#kubectl port-forward pod/$POD_NAME 5000:80 5001:443(5)删除指定的 release
[root@k8s231 helm]# helm uninstall web01 -n default
release "web01" uninstalled
-------------------------------------------------------41.4. 拉取chart
[root@k8s231 helm]# helm pull stable/mysql --untar
[root@k8s231 helm]# tree mysql
mysql
├── Chart.yaml #包含 chart 的元数据,必须有name和version(chart版本)的定义
├── README.md #提供关于 chart 的信息和使用说明
├── templates #包含 chart 的模板文件
│ ├── configurationFiles-configmap.yaml #配置文件的 ConfigMap 模板
│ ├── deployment.yaml #Deployment 资源的模板
│ ├── _helpers.tpl #这个文件包含可重用的模板助手函数,可以在 chart 的其他模板中调用
│ ├── initializationFiles-configmap.yaml #初始化文件的 ConfigMap 模板
│ ├── NOTES.txt #安装后的说明和注意事项,在用户运行 helm install 时显示给用户
│ ├── pvc.yaml #PersistentVolumeClaim 资源的模板
│ ├── secrets.yaml #Secret 资源的模板
│ ├── serviceaccount.yaml #ServiceAccount 资源的模板
│ ├── servicemonitor.yaml #ServiceMonitor 资源的模板
│ ├── service.yaml #Service 资源的模板
│ ├── ingress.yaml #Ingress 资源的模板,用于管理外部访问到 Service 的路由
│ └── tests #包含测试相关的模板文件
│ ├── test-configmap.yaml
│ └── test.yaml
└── values.yaml #包含 chart 的默认配置值41.5. helm的升级与回滚
#(1)创建chart,修改初始版本号,安装chart
helm create chart02
sed -i 's#^appVersion.*#appVersion: "V1.0"#g' chart02/Chart.yaml
sed -i 's#^version:.*#version: "0.0.1"#g' chart02/Chart.yaml
helm install web02 chart02 -n default -f ./chart02/values.yaml#(2)chart第一次升级(升级方式1:声明式修改,修改配置文件)
sed -i 's#^appVersion.*#appVersion: "V2.0"#g' chart02/Chart.yaml
sed -i 's#^version:.*#version: "0.0.2"#g' chart02/Chart.yaml
helm upgrade web02 chart02 -n default -f ./chart02/values.yaml#(3)chart第二次升级(方式2:传参方式升级)
# values.yaml 中的值可以被部署 release 时用到的参数 --values YAML_FILE_PATH 或 --set key1=value1, key2=value2 覆盖掉
#[root@k8s231 helm]# helm upgrade web02 chart02 -n default -f ./chart02/values.yaml --set replicaCount=2,service.port=88
sed -i 's#^appVersion.*#appVersion: "V3.0"#g' chart02/Chart.yaml
sed -i 's#^version:.*#version: "0.0.3"#g' chart02/Chart.yaml
helm upgrade web02 chart02 -n default -f ./chart02/values.yaml#(4)查看当前release版本
[root@k8s231 helm]# helm ls -n default
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
web02 default 3 2024-08-19 19:17:02.989958737 +0800 CST deployed chart02-0.0.3 V3.0#(5)查看release版本历史
[root@k8s231 helm]# helm history web02 -n default
REVISION UPDATED STATUS CHART APP VERSION DESCRIPTION
1 Mon Aug 19 19:16:53 2024 superseded chart02-0.0.1 V1.0 Install complete
2 Mon Aug 19 19:16:58 2024 superseded chart02-0.0.2 V2.0 Upgrade complete
3 Mon Aug 19 19:17:02 2024 deployed chart02-0.0.3 V3.0 Upgrade complete
---------------------------------------------------------------------------------------------------------
- helm的回滚:#(6)回滚到上一个版本
[root@k8s231 helm]# helm rollback web02 -n default
[root@k8s231 helm]# helm ls -n default
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
web02 default 4 2024-08-19 19:55:29.036365229 +0800 CST deployed chart02-0.0.2 V2.0
[root@k8s231 helm]# helm history web02 -n default
REVISION UPDATED STATUS CHART APP VERSION DESCRIPTION
1 Mon Aug 19 19:52:23 2024 superseded chart02-0.0.1 V1.0 Install complete
2 Mon Aug 19 19:52:31 2024 superseded chart02-0.0.2 V2.0 Upgrade complete
3 Mon Aug 19 19:52:36 2024 superseded chart02-0.0.3 V3.0 Upgrade complete
4 Mon Aug 19 19:55:29 2024 deployed chart02-0.0.2 V2.0 Rollback to 2#(7)回滚到指定版本
[root@k8s231 helm]# helm rollback web02 1 -n default
[root@k8s231 helm]# helm ls -n default
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
web02 default 5 2024-08-19 19:59:35.453758575 +0800 CST deployed chart02-0.0.1 V1.0
[root@k8s231 helm]# helm history web02 -n default
REVISION UPDATED STATUS CHART APP VERSION DESCRIPTION
1 Mon Aug 19 19:52:23 2024 superseded chart02-0.0.1 V1.0 Install complete
2 Mon Aug 19 19:52:31 2024 superseded chart02-0.0.2 V2.0 Upgrade complete
3 Mon Aug 19 19:52:36 2024 superseded chart02-0.0.3 V3.0 Upgrade complete
4 Mon Aug 19 19:55:29 2024 superseded chart02-0.0.2 V2.0 Rollback to 2
5 Mon Aug 19 19:59:35 2024 deployed chart02-0.0.1 V1.0 Rollback to 1#(8)卸载Release
[root@k8s231 helm]# helm uninstall web02 -n default
release "web02" uninstalled42. Ingress
42.1. 为什么需要Ingress
在Kubernetes中,为了使外部的应用能够访问集群内的service,最为常用的是使用NodePort和LoadBalancer两种类型的service。
但这两种类型的服务各有缺点:NodePort方式会占用很多集群机器的端口;
而LoadBanlancer类型要求k8s必须跑在支持的云上,当同时存在多个LoadBanlancer类型的Service时,就会占用大量公网ip地址
而Ingress正式为了解决以上两种问题而生的
42.2. 什么是Ingress
Ingress则相当于一个服务网关,控制着从集群外部到集群内部的HTTP/HTTPS的访问路由。下面是一个简单的ingress对流量的路由示意图:

可以给Ingress配置提供外部可访问的URL、负载均衡、SSL和基于名称的虚拟主机等。
42.3. ingress组成
通常我们说Ingress,是指ingress和ingress controller(Ingress控制器)
Ingress控制器类似于nginx,Ingress类似于nginx的配置文件。如果只安装nginx,而没有nginx的配置文件,则此nginx将毫无意义;反过来,若只有nginx的配置文件,但没安装nginx,则配置文件无运行载体,下面是一个流量路由示意图:
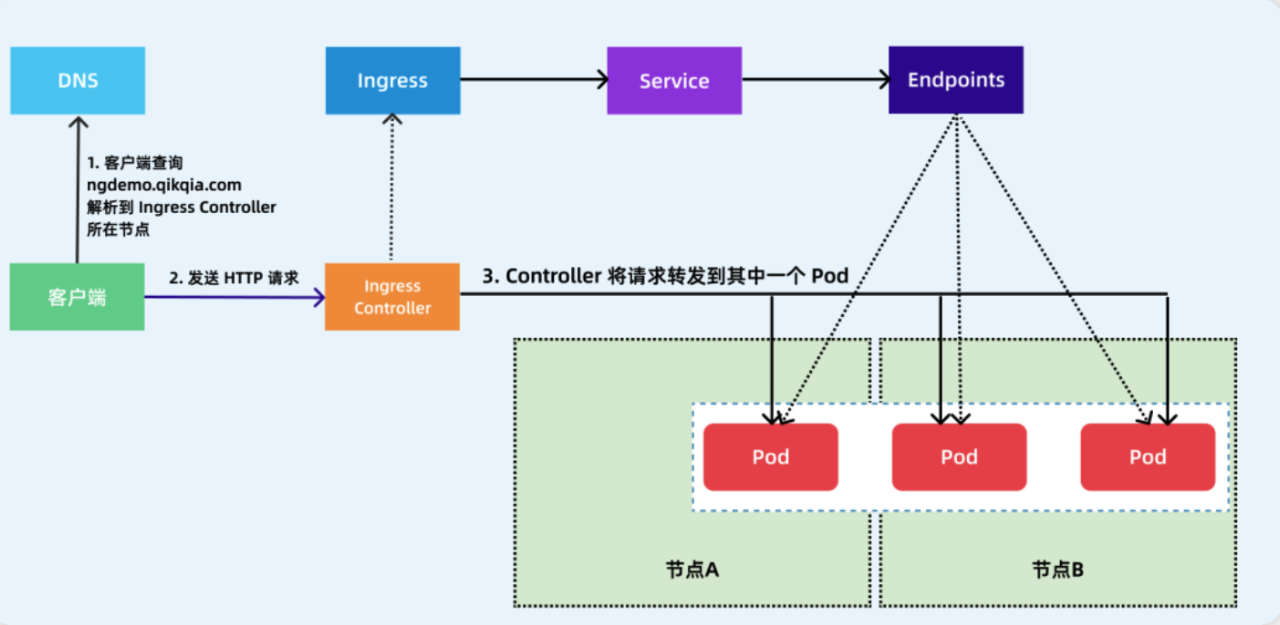
从中可以看出,
- 客户端首先对 ngdemo.qikqiak.com 执行 DNS 解析,得到 Ingress 控制器所在节点的 IP,
- 客户端向 Ingress 控制器发送 HTTP 请求,
- Ingress 控制器根据 Ingress 对象里面的描述匹配域名,找到对应的 Service 对象,并获取关联的 Endpoints 列表,将客户端的请求转发给其中一个 Pod。
理想情况下,所有的Ingress控制器都应该符合参考规范,但实际上不同的Ingress控制器操作略有不同
42.4. ingress controller 之 ingress-nginx
Ingress控制器有很多种,有官方维护的如ingress-nginx,AWS和GCE,也有第三方的。
42.4.1. 安装ingress-nginx
#(1)下载ingress-nginx的部署文件
mkdir -p /manifests/ingress/ingress-nginx && cd /manifests/ingress/ingress-nginx
[root@k8s231 ingress-nginx]# wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.8.2/deploy/static/provider/cloud/deploy.yaml -O ingress-nginx.yaml#(2)修改部署文件
#由于国内无法访问registry.k8s.io,这里把镜像地址改为阿里云的地址
[root@k8s231 ingress-nginx]# grep image: ingress-nginx.yaml image: registry.cn-hangzhou.aliyuncs.com/google_containers/nginx-ingress-controller:v1.8.1image: registry.cn-hangzhou.aliyuncs.com/google_containers/kube-webhook-certgen:v20230407image: registry.cn-hangzhou.aliyuncs.com/google_containers/kube-webhook-certgen:v20230407
#固定nodePort的端口http端口为8080,https端口为8443
kind: Service
metadata:name: ingress-nginx-controller
spec:ports:- appProtocol: http...nodePort: 8080- appProtocol: https...nodePort: 8443#(3)创建资源
[root@k8s231 ingress-nginx]# kubectl apply -f ingress-nginx.yaml#(4)检查资源,主要看ingress-nginx-controller是否启动成功,ingress-nginx-admission-create和ingress-nginx-admission-patch为Completed,已经运行完成了
[root@k8s231 ingress-nginx]# kubectl get all -n ingress-nginx
NAME READY STATUS RESTARTS AGE
pod/ingress-nginx-admission-create-4mgsj 0/1 Completed 0 12m
pod/ingress-nginx-admission-patch-tbjgh 0/1 Completed 1 12m
pod/ingress-nginx-controller-f8fb9d7c6-p4mrl 1/1 Running 0 12mNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/ingress-nginx-controller LoadBalancer 10.100.204.162 <pending> 80:8080/TCP,443:8443/TCP 12m
service/ingress-nginx-controller-admission ClusterIP 10.100.35.186 <none> 443/TCP 12mNAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/ingress-nginx-controller 1/1 1 1 12mNAME DESIRED CURRENT READY AGE
replicaset.apps/ingress-nginx-controller-f8fb9d7c6 1 1 1 12mNAME COMPLETIONS DURATION AGE
job.batch/ingress-nginx-admission-create 1/1 4s 12m
job.batch/ingress-nginx-admission-patch 1/1 5s 12m#通过刚才的创建也生成了一个ingressclass, 下面要创建ingress的时候需要指定ingressClassName: nginx ,即可使用ingress-nginx控制器。当然,也要创建Ingress路由的service和pod
[root@k8s231 ingress-nginx]# kubectl get ingressclasses.networking.k8s.io
NAME CONTROLLER PARAMETERS AGE
nginx k8s.io/ingress-nginx <none> 54m42.4.2. 创建一个ingress,关联ingress-nginx
#(1)创建pod,svc,创建ingress绑定svc(这里创建的pod,svc应该和ingress属于同一个namespace)
[root@k8s231 ingress-nginx]# cat > test.yaml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:name: deploy-tom-nginxnamespace: ingress-nginx
spec: selector:matchLabels:app: tom-nginxtemplate:metadata:labels:app: tom-nginxspec:containers:- name: tom-nginximage: nginx:alpineports:- containerPort: 80
---
# my-nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: deploy-jack-nginxnamespace: ingress-nginx
spec: selector:matchLabels:app: jack-nginxtemplate:metadata:labels:app: jack-nginxspec:containers:- name: jack-nginximage: nginx:alpineports:- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:name: svc-tom-nginxnamespace: ingress-nginxlabels:app: my-nginx
spec:ports:- port: 80protocol: TCPname: httpselector:app: tom-nginx
---
apiVersion: v1
kind: Service
metadata:name: svc-jack-nginxnamespace: ingress-nginxlabels:app: jack-nginx
spec:ports:- port: 80protocol: TCPname: httpselector:app: jack-nginx
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:name: ing-nginxnamespace: ingress-nginx
spec:ingressClassName: nginx # 关联ingress-nginx控制器的ingressclassrules:- host: tom.nginx.com # 将域名映射到svc-tom-nginx服务http:paths:- path: /pathType: Prefixbackend:service: # 将所有请求发送到svc-tom-nginx服务的 80 端口name: svc-tom-nginxport:number: 80- host: jack.nginx.com # 将域名映射到svc-jack-nginx 服务http:paths:- path: /pathType: Prefixbackend:service: # 将所有请求发送到svc-jack-nginx服务的 80 端口name: svc-jack-nginxport:number: 80
# 不过需要注意大部分Ingress控制器都不是直接转发到Service
# 而是只是通过Service来获取后端的Endpoints列表,直接转发到Pod,这样可以减少网络跳转,提高性能
EOF
[root@k8s231 ingress-nginx]# kubectl apply -f test.yaml#(2)检查ingress是否创建成功
[root@k8s231 ingress-nginx]# kubectl -n ingress-nginx get ingress ing-nginx
NAME CLASS HOSTS ADDRESS PORTS AGE
ing-nginx nginx tom.nginx.com,jack.nginx.com 80 11m[root@k8s231 ingress-nginx]# kubectl -n ingress-nginx describe ingress ing-nginx
Name: ing-nginx
Labels: <none>
Namespace: ingress-nginx
Address:
Default backend: default-http-backend:80 (<error: endpoints "default-http-backend" not found>)
Rules:Host Path Backends---- ---- --------tom.nginx.com / svc-tom-nginx:80 (10.200.3.59:80)jack.nginx.com / svc-jack-nginx:80 (10.200.1.138:80)
Annotations: <none>
Events:Type Reason Age From Message---- ------ ---- ---- -------Normal Sync 10m nginx-ingress-controller Scheduled for sync#(3)把相应容器的web页面改为对应标志,测试ingress是否生效
[root@k8s231 ingress-nginx] kubectl -n ingress-nginx get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller LoadBalancer 10.100.204.162 <pending> 80:8080/TCP,443:8443/TCP 3h20m
ingress-nginx-controller-admission ClusterIP 10.100.35.186 <none> 443/TCP 3h20m
svc-jack-nginx ClusterIP 10.100.185.25 <none> 80/TCP 3h19m
svc-tom-nginx ClusterIP 10.100.99.96 <none> 80/TCP 3h19m[root@k8s231 ingress-nginx]# kubectl -n ingress-nginx get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deploy-jack-nginx-79c4748f8-r6p74 1/1 Running 0 27m 10.200.1.138 k8s232.tom.com <none> <none>
deploy-tom-nginx-6974c49976-ww5xc 1/1 Running 0 27m 10.200.3.59 k8s233.tom.com <none> <none>
ingress-nginx-admission-create-4mgsj 0/1 Completed 0 27m 10.200.3.57 k8s233.tom.com <none> <none>
ingress-nginx-admission-patch-tbjgh 0/1 Completed 1 27m 10.200.1.137 k8s232.tom.com <none> <none>
ingress-nginx-controller-f8fb9d7c6-p4mrl 1/1 Running 0 27m 10.200.3.58 k8s233.tom.com <none> <none>[root@k8s231 ingress-nginx]# kubectl -n ingress-nginx exec deploy-jack-nginx-79c4748f8-r6p74 -- sh -c 'echo "jack web" > /usr/share/nginx/html/index.html '
[root@k8s231 ingress-nginx]# kubectl -n ingress-nginx exec deploy-tom-nginx-6974c49976-ww5xc -- sh -c 'echo "tom web" > /usr/share/nginx/html/index.html '#内网验证,访问ingress-nginx-controller 的svc的CLUSTER-IP的80端口
[root@k8s231 ingress-nginx]# curl -H 'Host:tom.nginx.com' 10.100.204.162
tom web
[root@k8s231 ingress-nginx]# curl -H 'Host:jack.nginx.com' 10.100.204.162
jack web#外网验证 windwos hosts文件修改解析,把域名指向ingress-nginx-controller所在的node的ip 10.0.0.233,访问端口8080
10.0.0.233 tom.nginx.com jack.nginx.com
#浏览器访问 http://jack.nginx.com:8080/ http://tom.nginx.com:8080/ 42.5. ingress controller 之 traefik
42.5.1. helm安装traefik
Traefik是一个功能强大的负载均衡工具,它支持4层和7层的基本负载均衡操作,通过IngressRoute、IngressRouteTCP、IngressRouteUDP资源即可轻松实现
mkdir -p /manifests/ingress/traefik && cd /manifests/ingress/traefik
# 添加repo
helm repo add traefik https://helm.traefik.io/traefik
# 更新repo仓库资源
helm repo update
# 查看repo仓库traefik
helm search repo traefik
# 创建traefik名称空间
kubectl create ns traefik
# 下载traefik
helm pull traefik/traefik
tar -xvf traefik-30.1.0.tgz
helm install --namespace=traefik traefik traefik
# 查看helm列表
[root@k8s-master traefik]# helm list -n traefik
# 查看pod资源信息
[root@k8s-master traefik]# kubectl get pod -n traefik[root@k8s231 helm]# kubectl get ingressclasses.networking.k8s.io
NAME CONTROLLER PARAMETERS AGE
traefik traefik.io/ingress-controller <none> 2m10s[root@k8s231 traefik]# kubectl -n traefik get all -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod/traefik-5698f576f8-grzsp 1/1 Running 0 10m 10.200.1.139 k8s232.tom.com <none> <none>NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
service/traefik LoadBalancer 10.100.147.82 <pending> 80:28616/TCP,443:25601/TCP 10m app.kubernetes.io/instance=traefik-traefik,app.kubernetes.io/name=traefikNAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR
deployment.apps/traefik 1/1 1 1 10m traefik docker.io/traefik:v3.1.2 app.kubernetes.io/instance=traefik-traefik,app.kubernetes.io/name=traefikNAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
replicaset.apps/traefik-5698f576f8 1 1 1 10m traefik docker.io/traefik:v3.1.2 app.kubernetes.io/instance=traefik-traefik,app.kubernetes.io/name=traefik,pod-template-hash=5698f576f842.5.2. 创建一个ingress并关联traefik
#(1)创建pod,svc,创建ingress绑定svc(这里创建的pod,svc应该和ingress属于同一个namespace)
[root@k8s231 traefik]# cat > test.yaml <<EOF
apiVersion: apps/v1
kind: Deployment
metadata:name: deploy-jerry-nginxnamespace: default
spec:#replicas: 2selector:matchLabels:app: jerry-nginxtemplate:metadata:labels:app: jerry-nginxspec:containers:- name: jerry-nginximage: nginx:alpineports:- containerPort: 80
---
# my-nginx.yaml
apiVersion: apps/v1
kind: Deployment
metadata:name: deploy-lucy-nginxnamespace: default
spec:#replicas: 2selector:matchLabels:app: lucy-nginxtemplate:metadata:labels:app: lucy-nginxspec:containers:- name: lucy-nginximage: nginx:alpineports:- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:name: svc-jerry-nginxnamespace: defaultlabels:app: my-nginx
spec:ports:- port: 80protocol: TCPname: httpselector:app: jerry-nginx
---
apiVersion: v1
kind: Service
metadata:name: svc-lucy-nginxnamespace: defaultlabels:app: lucy-nginx
spec:ports:- port: 80protocol: TCPname: httpselector:app: lucy-nginx
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:name: ing-treafiknamespace: default
spec:ingressClassName: traefik #关联treafik控制器的ingressclass rules:- host: jerry.nginx.com # 将域名映射到svc-jerry-nginx服务http:paths:- path: /pathType: Prefixbackend:service: # 将所有请求发送到svc-jerry-nginx服务的 80 端口name: svc-jerry-nginxport:number: 80- host: lucy.nginx.com # 将域名映射到svc-lucy-nginx 服务http:paths:- path: /pathType: Prefixbackend:service: # 将所有请求发送到svc-lucy-nginx服务的 80 端口name: svc-lucy-nginxport:number: 80
EOF
kubectl apply -f test.yaml#(2)检查ingress是否创建成功
[root@k8s231 traefik]# kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
ing-treafik traefik jerry.nginx.com,lucy.nginx.com 80 22m#(3)把相应容器的web页面改为对应标志,测试ingress是否生效
[root@k8s231 traefik]# kubectl -n traefik get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc-jerry-nginx ClusterIP 10.100.244.240 <none> 80/TCP 14m
svc-lucy-nginx ClusterIP 10.100.195.87 <none> 80/TCP 14m
traefik LoadBalancer 10.100.147.82 <pending> 80:28616/TCP,443:25601/TCP 45m[root@k8s231 traefik]# kubectl -n traefik get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
deploy-jerry-nginx-655bdff58d-mchcl 1/1 Running 0 14m 10.200.3.60 k8s233.tom.com <none> <none>
deploy-lucy-nginx-54c76f544b-s4rhj 1/1 Running 0 14m 10.200.1.140 k8s232.tom.com <none> <none>
traefik-5698f576f8-grzsp 1/1 Running 0 45m 10.200.1.139 k8s232.tom.com <none> <none>[root@k8s231 traefik]# kubectl -n traefik exec deploy-jerry-nginx-655bdff58d-mchcl -- sh -c 'echo "jerry web" > /usr/share/nginx/html/index.html '
[root@k8s231 traefik]# kubectl -n traefik exec deploy-lucy-nginx-54c76f544b-s4rhj -- sh -c 'echo "lucy web" > /usr/share/nginx/html/index.html '#内网验证,访问traefik controller 的svc的CLUSTER-IP的80端口
[root@k8s231 traefik]# curl -H 'Host:jerry.nginx.com' 10.100.147.82
jerry web
[root@k8s231 traefik]# curl -H 'Host:lucy.nginx.com' 10.100.147.82
lucy web#外网验证 windwos hosts文件修改解析,把域名指向traefik controller所在的node的ip 10.0.0.232,访问端口28616
10.0.0.232 jerry.nginx.com lucy.nginx.com
#浏览器访问 http://jerry.nginx.com:28616/ http://lucy.nginx.com:28616/