【视频讲解】SMOTEBoost、RBBoost和RUSBoost不平衡数据集的集成分类酵母数据集、治癌候选药物|数据分享...
全文链接:https://tecdat.cn/?p=37502
分析师:Zilin Wu
在当今的大数据时代,科研和实际应用中常常面临着海量数据的处理挑战。在本项目中,我们拥有上万条数据,这既是宝贵的资源,也带来了诸多难题。一方面,我们渴望从这庞大的数据海洋中提取出有价值的信息,以推动科学研究和实际应用的发展;另一方面,数据量的庞大容易引发“维数灾难”现象,即随着数据维度的增加,计算复杂度呈指数增长,使得数据分析和处理变得极为困难(点击文末“阅读原文”获取完整代码数据)。
相关视频
本研究聚焦于如何在这上万条数据中找到平衡,既提取有价值的数据,又避免“维数灾难”。具体而言,我们的任务是通过对客户提供的药物信息进行分析,选择出可以成为抗乳腺癌的候选药物。通过对数据源进行预处理、建模以及选择合适的分类模型等一系列科学严谨的方法,我们致力于解决这一复杂的问题,为药物研发和医疗领域的发展贡献力量。
该项目具有上万条数据,如何从这上万条数据中既提取有价值的数据,又减少数据量避免“维数灾难”的现象成为本项目需要重点解决的问题之一。
解决方案
任务/目标
本研究希望通过提供的药物信息选择出可以成为抗乳腺癌的候选药物。
数据源预处理
客户提供了 1974 个化合物的 729 个分子描述符信息,通过对表格数据的初 步分析,我们发现其中有大量的“0”数据。若某一分子描述符对所有的化合物 的参数均为 0,我们可以认为该分子描述符对化合物的生物活性没有影响,该列 数据予以清除;若某一分子描述符的参数含 0 比率大于 80%,我们可以认为该分 子描述符对化合物的生物活性影响较小,可忽略不计,该列数据予以清除。
通过给出的数据分类,初步判断数据之间具有多重共线性,通过 SPSS 软件对样本数据源进行逐步回归法(Stepwise Regression),得到各分子描述符的 容差和 VIF 值,通过文献阅读,发现当 Tolerance(容差)小于 0.2 或 VIF(方差膨 胀因子)大于 10,可以说明自变量具有高度的共线性,可以使用 Spearman 相关系数。
建模
问题 1:根据 1974 个化合物对 ERα 的活性值以及上述 1974 个化 合物的 729 个分子描述符信息数据,对 729 个分子描述符进行变量选择,按照变 量对生物活性的影响的重要程度进行排序,最终得出对生物活性最具有显著影响 的前 20 个分子描述符。
最为常用的求解相关系数的方法有两种:Pearson 相关系数和 Spearman 等级 相关系数,我们根据数据的不同特征,选择合适的相关系数来表示变量之间的相 关性大小。
Pearson 相关系数的适用范围:(1)两个变量之间应该为线性关系,而且两个变量的数据都应该是连续的;(2)两个变量的总体为正态分布,或者为接近于正态分布的单峰分布;(3)两个变量的观测值是相匹配的,且每一对观测值之间应该保持独立。若以上任一条件不满足,就不能用 Pearson 相关系数来衡量它们之间的相关 性大小。
由于本项目随机变量不服从正态分布,所以选择使用 Spearman 等级相关系数。
用 MATLAB 计算得到分子描述符与 pIC50 的相关系数,进行相关系数排序, 筛选得到前 20 个对生物活性最具有显著影响的分子描述符,如表所示:
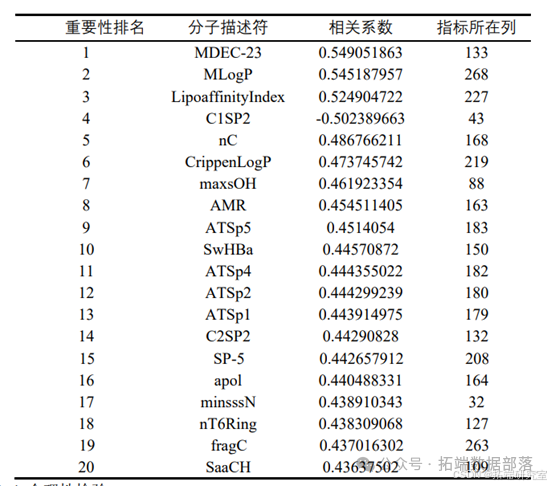
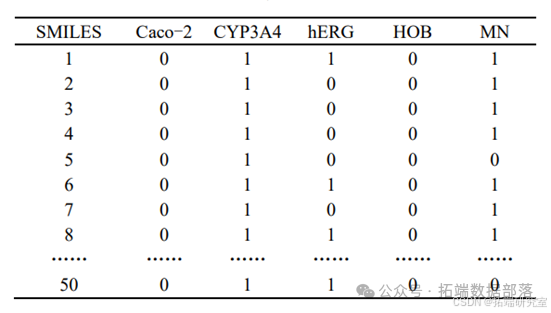
问题 2:结合问题 1 的结果,选择不超过 20 个分子描述符变量,建立化合 物对 ERα 生物活性的定量预测模型,并使用该模型预测 50 个化合物的 IC50 值 和对应的 pIC50 值,将预测结果填入相对应的表格中。
需要以化合物的 729 个分子描述符为变量,依据附件中提供的 1924 个 化合物的 ADMET 数据,分别构建化合物 ADMET 性质的 5 个分类预测模型。首先在变量选择的问题上,729 分子描述符作为变量会使模型的构建过于复杂, 应去除对化合物性质影响较小的变量,于是结合问题 1 得到的结果,最终选择对 生物活性有显著影响的前 287 个分子描述符作为变量。其次在分类模型的选择 上,我们使用 Matlab 编程,选出对模型分类准确率较高的 SVM 支持向量机模型。然后经过大量的文献阅读,发现当样本数据存在不平衡问题时不能将分类准确率 作为唯一指标,还需看少数样本分类的正确率。于是我们考虑使用 RUSBoost 算 法对样本数据不平衡的性质进行分类。最终我们用 SVM 支持向量机对 Caco-2、 hERG 进行分类预测,用 RUSBoost 算法对 CYP3A4、HOB、MN 进行分类预测。
问题分析流程图如下:

分类模型的选择
我们初步选择了 Matlab 中若干个分类模型进行预测,将模型预测分类值与 真实分类值进行对比,计算这些模型的分类准确率,筛选出分类准确率较高的前 三个模型,结果如图所示
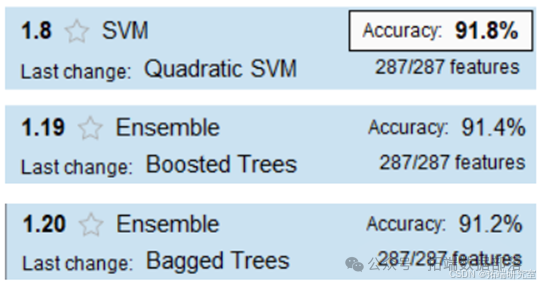
准确率大小比较:Quadratic SVM(91.8%)>Boosted Trees(91.4%)>Bagged Trees(91.2%)。接下来我们以 AUC 为指标进行进一步的模型选择。AUC 结果如 图所示:
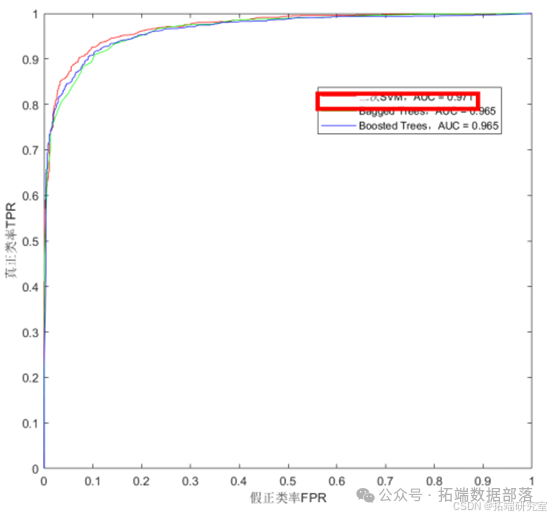
从图中可以看出,SVM 支持向量机的 AUC 指标最高,为 0.971。综合准确率和 AUC 两个指标,得出 SVM 支持向量机分类预测较为准确。基于以上结果,我们选择 SVM 支持向量机进行分类预测。
模型调参
在调参中,我们通过不断调整最大分裂数和决策树个数来找到效果最好的模 型。接下来我们以对 HOB 性质进行分类的模型调参为例。通过 Matlab 计算出不 同参数组合下模型的预测准确率,并将数据进行可视化处理,结果如表所示:
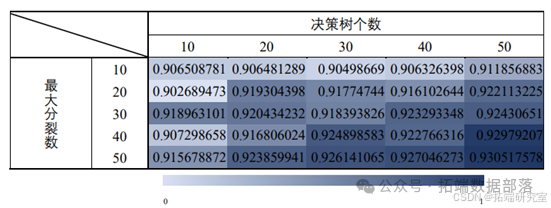
调参前,(最大分裂数,决策树)=(20,30),由以上表格可以看出,此 时模型的 AUC 值为 91.77%。当(最大分裂数,决策树)=(50,50)时,模型 的 AUC 值达到了 93.05%,提高了 1.28 个百分比。所以我们最终选择(最大分 裂数,决策树)=(50,50)的参数组合,以提高模型的分类效果。
点击标题查阅往期内容

PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯和KMEANS聚类用户画像

左右滑动查看更多
01
02
03

04
项目结果
使用支持向量机对候选药物的安全性进行分类,确保候选药物对人体无害。
Python用SMOTEBoost、RB-Boost 和 RUS-Boost不平衡数据集的集成分类器分析酵母数据集|附数据代码
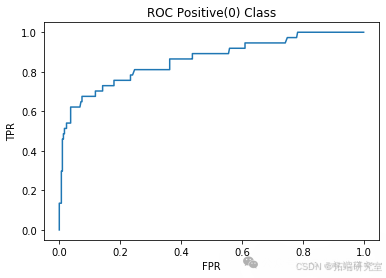
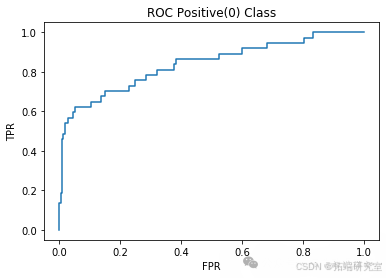
当分类类别不能近似等比例表示时,数据集是不平衡的。数据采样技术试图通过调整训练数据集的类别分布来缓解类别不平衡问题。这可以通过从多数类中移除示例(欠采样)或向少数类中添加示例(过采样)来实现。本研究在两类不平衡数据集上实现了 SMOTEBoost、RB-Boost 和 RUS-Boost 三种构建分类器集成的方法,并报告了它们在 5 折不平衡酵母数据集(查看文末了解数据免费获取方式)上的性能指标和 ROC 曲线,同时将结果与支持向量机(SVM)分类器、AdaBoost-M2 和随机森林集成进行了比较。
在现实世界的许多应用中,数据集往往存在类别不平衡的问题。这给分类任务带来了挑战,因为传统的分类算法通常假设各类别样本数量大致相等。为了解决这个问题,研究人员提出了各种方法,其中包括数据采样技术和集成学习方法。
相关技术
数据采样技术
欠采样:从多数类中移除示例,以减少多数类的样本数量,使其与少数类的样本数量更加接近。
过采样:向少数类中添加示例,以增加少数类的样本数量。其中,合成少数过采样技术(SMOTE)通过在特征空间中创建 “合成” 示例来对少数类进行过采样。具体方法是:取当前考虑的特征向量(样本)与其最近邻之间的差值,将该差值乘以一个 0 到 1 之间的随机数,然后将其添加到当前考虑的特征向量中。这样可以在两个特定特征之间的线段上选择一个随机点,有效地使少数类的决策区域变得更加通用。根据参考文献 [1],本实现使用五个最近邻。
集成学习方法
SMOTEBoost 算法:结合了合成少数过采样技术(SMOTE)和标准提升过程。在每次迭代中,仅对分布 D 中的少数类示例进行 SMOTE,新创建的合成少数类示例在学习分类器后被丢弃,不在原始训练集中添加。
Ada-Boost M2:定义了一种更复杂的误差,称为伪损失。伪损失是相对于所有示例和错误标签对的集合上的分布计算的,而普通误差是相对于示例上的分布计算的。
Random Balancex:在集成中使用该技术可以增加多样性并处理不平衡问题。对于给定的数据集,为集成中的每个成员获得一个相同大小但不平衡比例随机选择的不同数据集。使用 SMOTE 和随机欠采样分别增加或减少类的大小以匹配所需的大小。
RB-Boost:在每次迭代中,根据 Random Balancex 函数生成数据集 S´t,更新分布 D´t,为原始数据集中的每个实例维护其关联的权重,并为合成示例分配均匀权重 1/m。然后使用 S´t 和 D´t 训练一个弱学习算法(此处为最大深度为 3 的决策树),该分类器将为每个类给出 0 到 1 之间的概率。计算弱分类器的伪损失 ϵ´t,并更新分布 D,使与错误分类相关的权重高于正确分类的权重。
RUSBoost:也是 AdaBoost-M2 的一种修改,在每次迭代中使用随机欠采样从多数类中移除实例,直到达到所需的类分布。与 SMOTE 相比,RUSBoost 具有算法复杂度低和训练时间短的优点。
使用 5 折交叉验证的不平衡酵母数据集。
加载数据集:使用glob模块加载训练集和测试集文件,并将其存储在列表中。
traFiles = sorted(glob.')) X_train = \[\]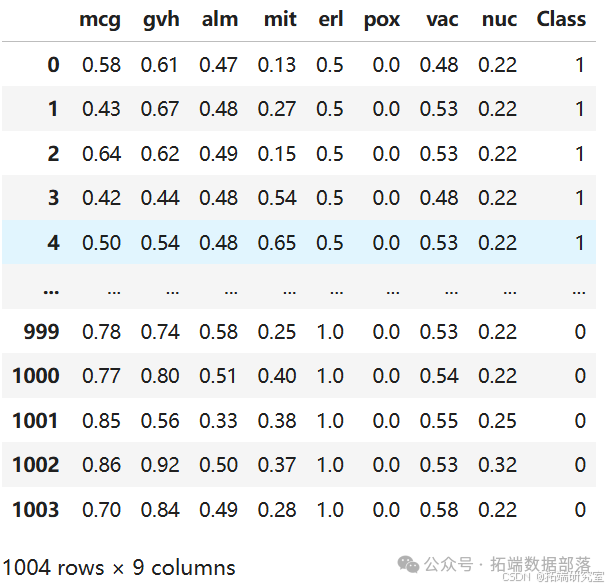
分类函数:定义一个用于训练、评估和计算指标的函数
classify,该函数接受一个模型和分类器名称作为参数,并返回准确率、精确率和召回率。
def classify(model, classifier\_name):acc = precision = recall = 0for i in range(kFold):# 训练model.fit(X\_train\[i\], Y_train\[i\])SVM
支持向量机(SVM):使用线性核函数和参数 C = 1 的 SVC 模型。
model = SVC(kernel ='linear', C = 1, probability=True)acc\_svm, precision\_svm, recall_svm = classify(model, "SVM")
``````
随机森林:分别实现了不同参数设置的随机森林分类器,包括 n\_estimators = 10、50、100,max\_depth = 2。
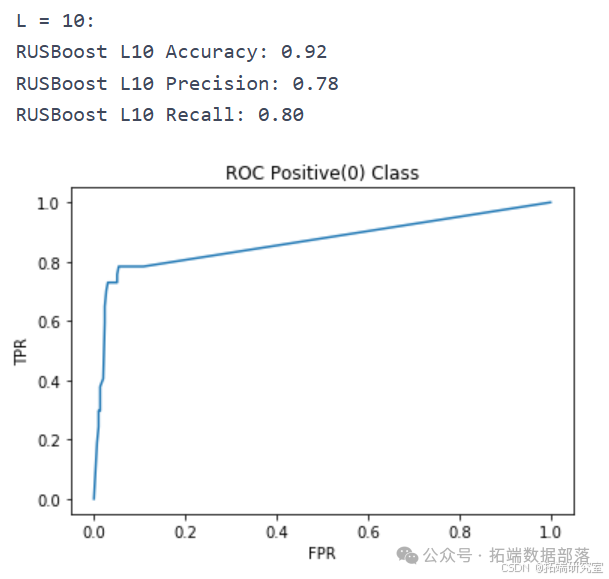
L = 10
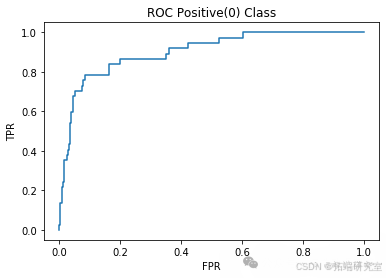
model = RandomForestClassifier(n\_estimators=10, max\_depth=2)acc\_RF\_L10, precision\_RF\_L10, recall\_RF\_L10 = classify(model, "Random Forest L10")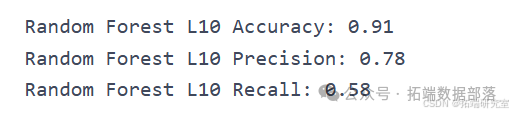
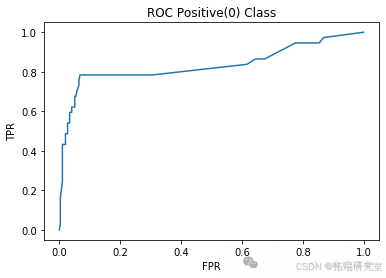
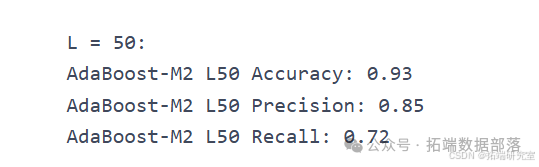
L = 50
model = RandomForestClassifier(n\_estimators=50, max\_depth=2)acc\_RF\_L50, precision\_RF\_L50, recall\_RF\_L50 = classify(model, "Random Forest L50")
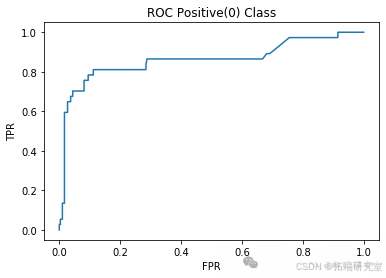
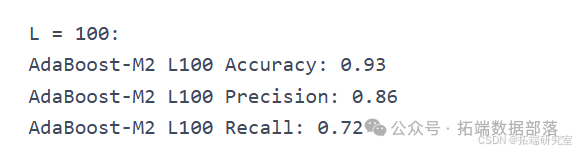
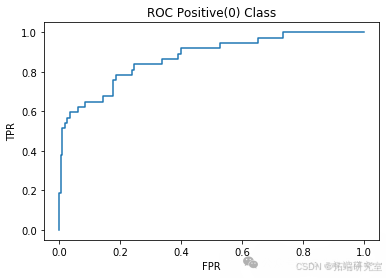
L = 100
model = RandomForestClassifier(n\_estimators=100, max\_depth=2)acc\_RF\_L100, precision\_RF\_L100, recall\_RF\_L100 = classify(model, "Random Forest L100")
``````
Random Forest L100 Accuracy: 0.91
Random Forest L100 Precision: 0.75
Random Forest L100 Recall: 0.53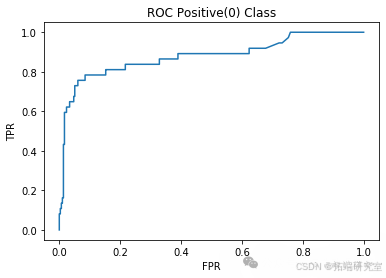
SMOTE:实现了 SMOTE 算法,用于过采样少数类。
def smote(minority\_x, N, k):T = len(minority\_x)SMOTEBoost:实现了 SMOTEBoost 算法。
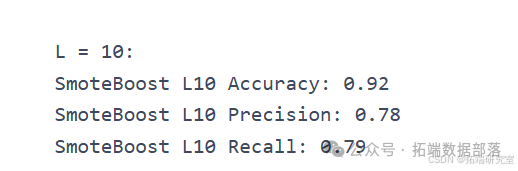
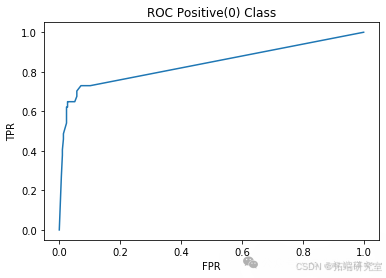
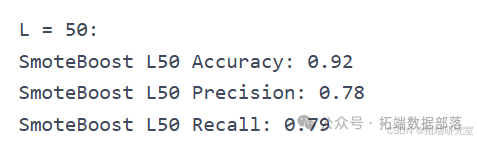
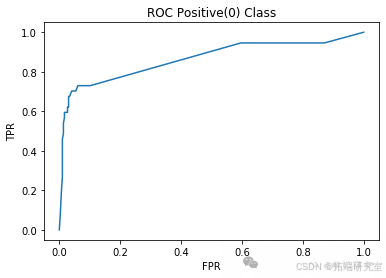
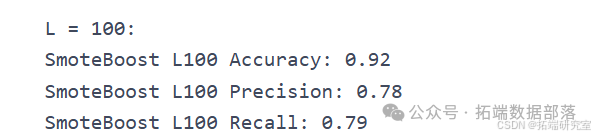
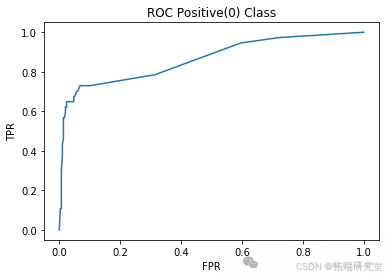
AdaBoostM2:实现了 AdaBoost-M2 算法。
def AdaBoostM2(X, Y, n\_estimators):classifier\_list = \[\]beta_list = \[\]D = np.ones(len(X), dtype=np.float64)D\[:\] = 1. / len(X)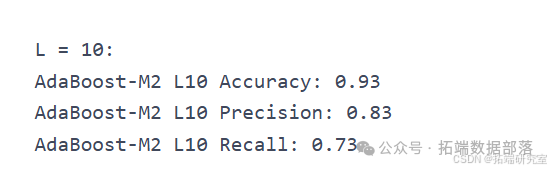
Random Balancex:实现了 Random Balancex 技术。
def Random\_Balancex(X, Y, minority\_class):minority\_x = \[X\[i\] for i in range(len(X)) if Y\[i\] == minority\_class\]majority\_x = \[X\[i\] for i in range(len(X)) if Y\[i\] != minority\_class\]total\_size = len(X)minority\_size = len(minority\_x)majority\_size = len(majority_x)RB-Boost:实现了 RB-Boost 算法。
def RBBoost(X, Y, minority\_class, n\_estimators):classifier_list = \[\]RUSBoost:实现了 RUSBoost 算法。
结果与分析
(一)准确率
将不同分类器在不同参数设置下的准确率进行比较,结果显示随机森林 L100 的准确率为 0.91。
groups = 3data = \[\[acc\_smoteBoost\_L10, acc\_smoteBoost\_L50, acc\_smoteBoost\_L100\],\[acc\_adaBoostM2\_L10, acc\_adaBoostM2\_L50, acc\_adaBoostM2\_L100\],\[acc\_rbBoost\_L10, acc\_rbBoost\_L50, acc\_rbBoost\_L100\],\[acc\_rusBoost\_L10, acc\_rusBoost\_L50, acc\_rusBoost\_L100\],\[acc\_RF\_L10, acc\_RF\_L50, acc\_RF\_L100\],\]X = np.arange(1, groups*2, step=2)fig = plt.figure()ax = fig.add_axes(\[0,0,1,1\])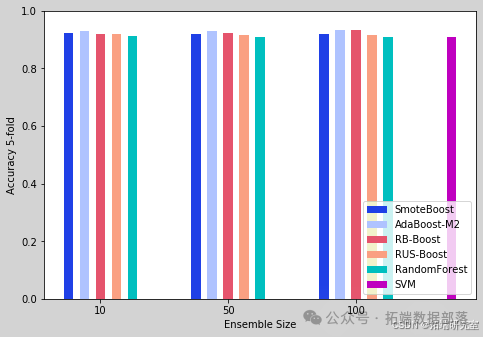
(二)精确率
比较不同分类器的精确率。
groups = 3data = \[\[precision\_smoteBoost\_L10, precision\_smoteBoost\_L50, precision\_smoteBoost\_L100\],\[precision\_adaBoostM2\_L10, precision\_adaBoostM2\_L50, precision\_adaBoostM2\_L100\],\[precision\_rbBoost\_L10, precision\_rbBoost\_L50, precision\_rbBoost\_L100\],\[precision\_rusBoost\_L10, precision\_rusBoost\_L50, precision\_rusBoost\_L100\],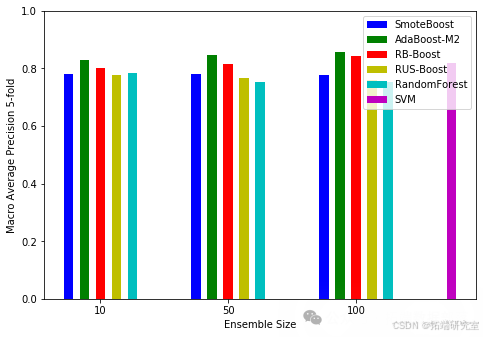
(三)召回率
比较不同分类器的召回率。
groups = 3data = \[\[recall\_smoteBoost\_L10, recall\_smoteBoost\_L50, recall\_smoteBoost\_L100\],\[recall\_adaBoostM2\_L10, recall\_adaBoostM2\_L50, recall\_adaBoostM2\_L100\],\[recall\_rbBoost\_L10, recall\_rbBoost\_L50, recall\_rbBoost\_L100\],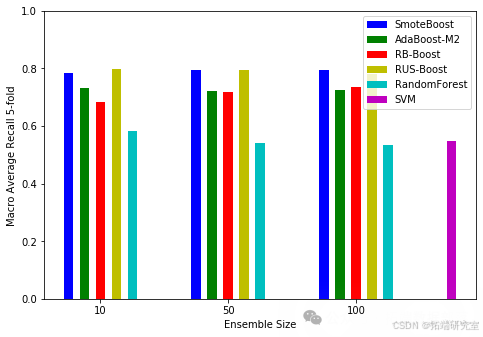
结论
本研究实现了多种用于不平衡数据集的分类器集成方法,并在不平衡酵母数据集上进行了实验。通过比较不同分类器的性能指标和可视化结果,可以得出不同方法在处理不平衡数据集上的优缺点。未来的研究可以进一步探索更有效的不平衡数据集处理方法,以及在不同应用场景下的性能表现。
参考文献
[1] Chawla, Nitesh V., et al. "SMOTE: synthetic minority over-sampling technique." Journal of artificial intelligence research 16 (2002): 321-357.
[2] Chawla, Nitesh V., et al. "SMOTEBoost: Improving prediction of the minority class in boosting." European conference on principles of data mining and knowledge discovery. Springer, Berlin, Heidelberg, 2003.
[3] Freund, Yoav, and Robert E. Schapire. "Experiments with a new boosting algorithm." icml. Vol. 96. 1996.
[4] Díez-Pastor, José F., et al. "Random balance: ensembles of variable priors classifiers for imbalanced data." Knowledge-Based Systems 85 (2015): 96-111.
[5] Seiffert, Chris, et al. "RUSBoost: A hybrid approach to alleviating class imbalance." IEEE Transactions on Systems, Man, and Cybernetics-Part A: Systems and Humans 40.1 (2009): 185-197.
关于分析师

在此对Zilin Wu对本文所作的贡献表示诚挚感谢,他完成了管理科学与工程专业的硕士学位,专注机器学习、数据采集等领域。擅长 Matlab、Sql、Python、Spss 等。
数据获取
在公众号后台回复“酵母数据”,可免费获取完整数据。
资料获取
在公众号后台回复“领资料”,可免费获取数据分析、机器学习、深度学习等学习资料。

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《SMOTEBoost、RBBoost 和 RUSBoost不平衡数据集的集成分类分析酵母数据集、治癌候选药物筛选》。
点击标题查阅往期内容
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
PYTHON集成机器学习:用ADABOOST、决策树、逻辑回归集成模型分类和回归和网格搜索超参数优化
R语言集成模型:提升树boosting、随机森林、约束最小二乘法加权平均模型融合分析时间序列数据
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
R语言基于树的方法:决策树,随机森林,Bagging,增强树
R语言用逻辑回归、决策树和随机森林对信贷数据集进行分类预测
spss modeler用决策树神经网络预测ST的股票
R语言中使用线性模型、回归决策树自动组合特征因子水平
R语言中自编基尼系数的CART回归决策树的实现
R语言用rle,svm和rpart决策树进行时间序列预测
python在Scikit-learn中用决策树和随机森林预测NBA获胜者
python中使用scikit-learn和pandas决策树进行iris鸢尾花数据分类建模和交叉验证
R语言里的非线性模型:多项式回归、局部样条、平滑样条、 广义相加模型GAM分析
R语言用标准最小二乘OLS,广义相加模型GAM ,样条函数进行逻辑回归LOGISTIC分类
R语言ISLR工资数据进行多项式回归和样条回归分析
R语言中的多项式回归、局部回归、核平滑和平滑样条回归模型
R语言用泊松Poisson回归、GAM样条曲线模型预测骑自行车者的数量
R语言分位数回归、GAM样条曲线、指数平滑和SARIMA对电力负荷时间序列预测
R语言样条曲线、决策树、Adaboost、梯度提升(GBM)算法进行回归、分类和动态可视化
如何用R语言在机器学习中建立集成模型?
R语言ARMA-EGARCH模型、集成预测算法对SPX实际波动率进行预测
在python 深度学习Keras中计算神经网络集成模型
R语言ARIMA集成模型预测时间序列分析
R语言基于Bagging分类的逻辑回归(Logistic Regression)、决策树、森林分析心脏病患者
R语言基于树的方法:决策树,随机森林,Bagging,增强树
R语言基于Bootstrap的线性回归预测置信区间估计方法
R语言使用bootstrap和增量法计算广义线性模型(GLM)预测置信区间
R语言样条曲线、决策树、Adaboost、梯度提升(GBM)算法进行回归、分类和动态可视化
Python对商店数据进行lstm和xgboost销售量时间序列建模预测分析
R语言随机森林RandomForest、逻辑回归Logisitc预测心脏病数据和可视化分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
Matlab建立SVM,KNN和朴素贝叶斯模型分类绘制ROC曲线
matlab使用分位数随机森林(QRF)回归树检测异常值



![]()
