ElasticSearch学习笔记(四)分页、高亮、RestClient查询文档
文章目录
- 前言
- 7 搜索结果处理
- 7.2 分页
- 7.2.1 基本使用
- 7.2.2 深度分页
- 7.2.3 小结
- 7.3 高亮
- 7.3.1 高亮原理
- 7.3.2 实现高亮
- 8 RestClient查询文档
- 8.1 match_all查询
- 8.2 match查询与multi_match查询
- 8.3 精确查询
- 8.4 布尔查询
- 8.5 排序、分页、高亮
- 9 项目实战
- 9.1 酒店搜索和分页
- 9.2 酒店列表过滤
前言
ElasticSearch学习笔记(一)倒排索引、ES和Kibana安装、索引操作
ElasticSearch学习笔记(二)文档操作、RestHighLevelClient的使用
ElasticSearch学习笔记(三)RestClient操作文档、DSL查询文档、搜索结果排序
7 搜索结果处理
7.2 分页
7.2.1 基本使用
ES默认情况下只返回top10的数据:
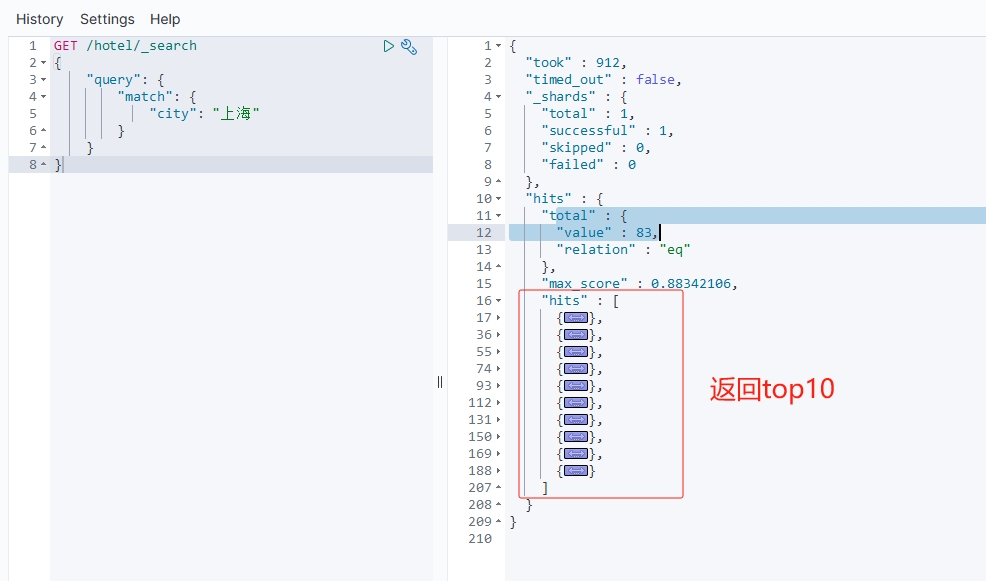
而如果要查询更多数据,就需要修改分页参数:
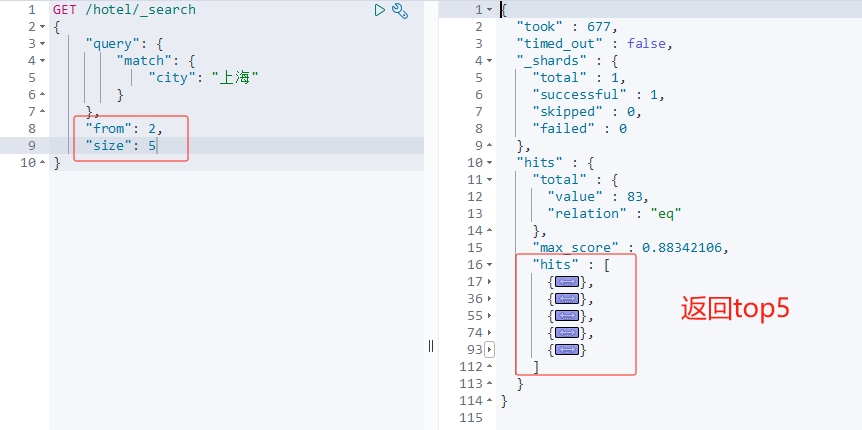
from:从第几个文档开始size:总共查询几个文档
例如:
7.2.2 深度分页
如果要查询第990-1000个文档,则查询条件应该是:
GET /hotel/_search
{"query": {"match": {"city": "上海"}},"from": 990,"size": 10
}
要注意的是,在ES内部进行分页时,不会直接定位到第990个文档,而是先把第0-1000个文档都查出来,在截取其中的第990-1000个文档:
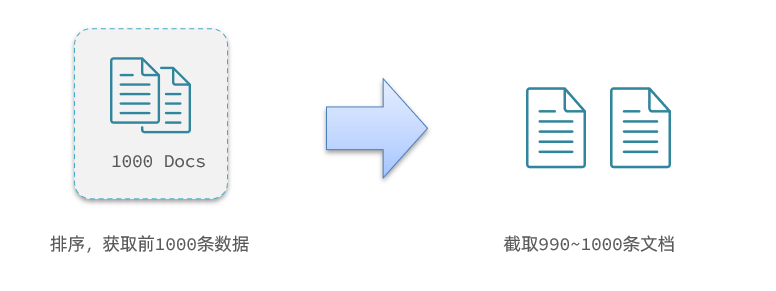
查询top1000,如果ES是单点模式,这并无太大影响,但在ES集群中的影响是很大的。
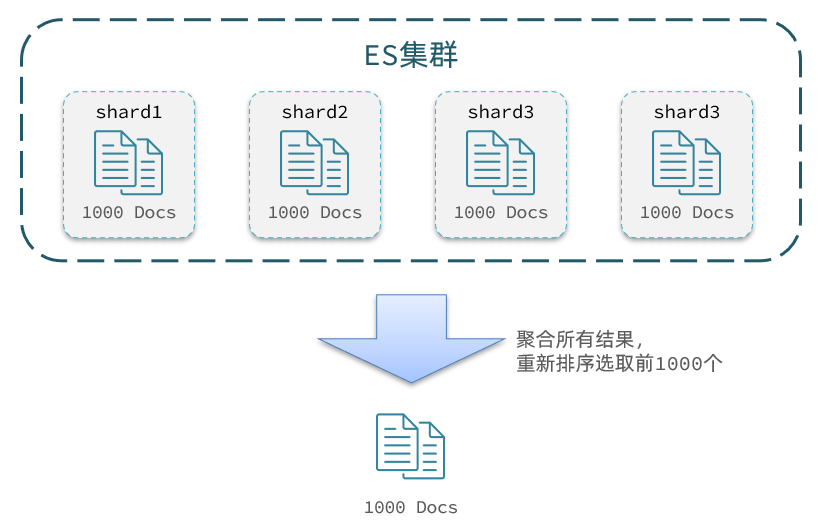
假设ES集群有5个节点,要查询top1000的数据,并不是每个节点查询出top200就可以了。这是因为节点A的top200,在另一个节点可能排到200名以外了。
因此要想获取整个集群的top1000,必须先查询出每个节点的top1000,汇总结果后重新排名,重新截取top1000。
如果查询分页深度更深,例如查询9900~10000的数据,就要先查询出每个节点的top10000,汇总后再进行截取。
因此,当查询分页深度较大时,汇总数据过多,对内存和CPU会产生非常大的压力,所以ES禁止from+size超过10000的请求。
针对深度分页,ES官方提供了两种解决方案:
search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。scroll:原理将排序后的文档id形成快照,保存在内存。官方已经不推荐使用。
7.2.3 小结
| 实现方案 | 优点 | 缺点 | 使用场景 |
|---|---|---|---|
| form + size | 支持随机翻页 | 会有深度分页问题,默认查询上限(from + size)是10000 | 百度、京东、谷歌、淘宝这样的随机翻页搜索 |
| search after | 没有查询上限(单次查询的size不超过10000) | 只能向后逐页查询,不支持随机翻页 | 没有随机翻页需求的搜索,例如手机向下滚动翻页 |
| scroll | 没有查询上限(单次查询的size不超过10000) | 会有额外内存消耗,并且搜索结果是非实时的 | 海量数据的获取和迁移。从ES7.1开始不推荐使用 |
7.3 高亮
7.3.1 高亮原理

由上图可知,在百度进行搜索时,关键字会变成红色,这就是一种高亮显示。而实现高亮显示的原理是:
- 1)给文档中的所有关键字都添加一个标签,例如
<em>标签; - 2)页面给
<em>标签编写CSS样式。
7.3.2 实现高亮
下面是实现高亮的一个例子:

其中一些需要注意的点是:
- 高亮是对关键字高亮,因此搜索条件必须包含关键字,而不能是范围这样的查询;
- 默认情况下,搜索字段必须与要高亮的字段一致,例如上面的例子中搜索字段和高亮字段都是name;
- 如果要对非搜索字段高亮,则需要添加一个属性:require_field_match=false。例如上例中,如果高亮字段加一个city字段,没加这个属性时不会高亮:
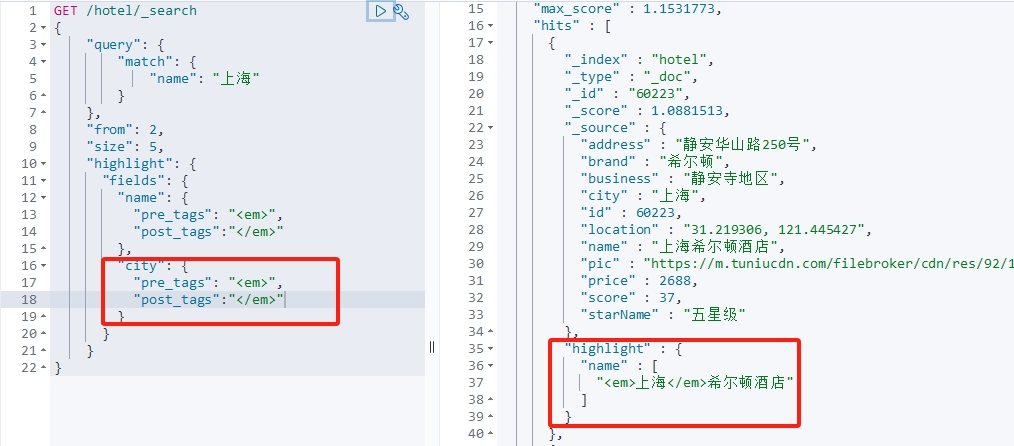
而加上该属性后,city字段也高亮:

8 RestClient查询文档
8.1 match_all查询
match_all查询是匹配所有文档的一种查询。在没有指定查询方式时,它也是ES默认的查询。
例如下面的例子,会将所有文档查询出来:

使用RestClient客户端实现match_all查询的代码如下:
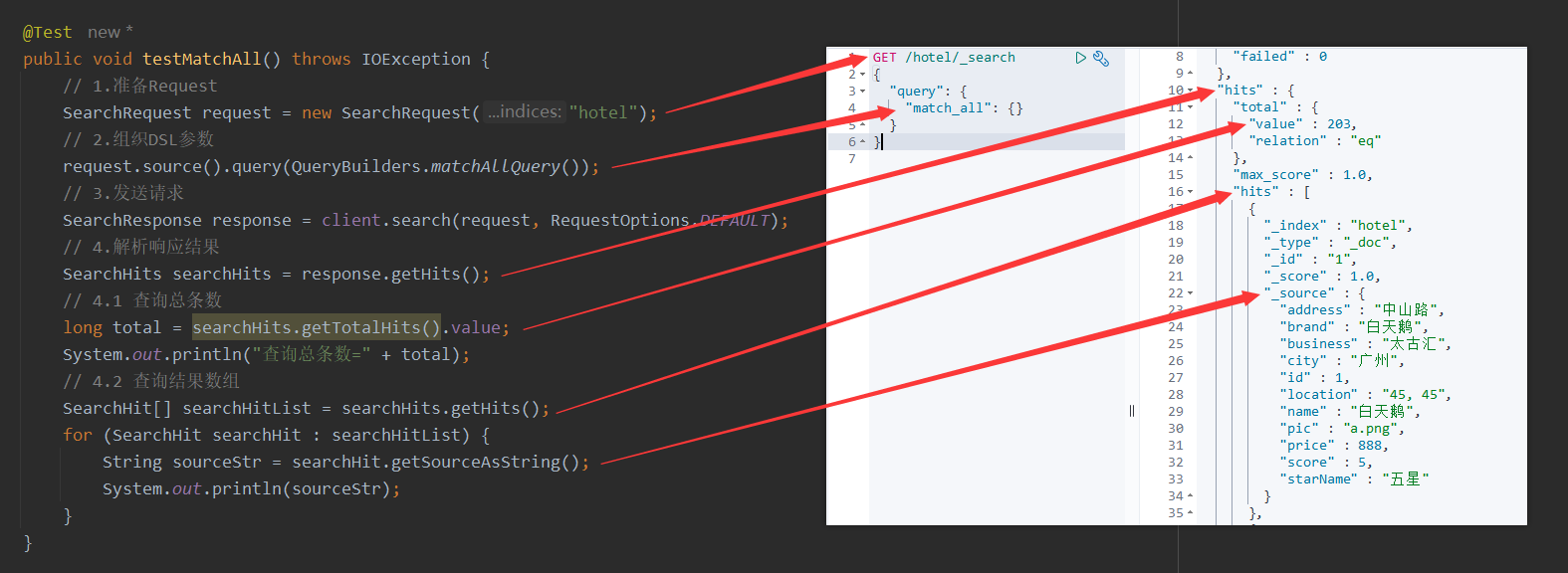
@Test
public void testMatchAll() throws IOException {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.组织DSL参数request.source().query(QueryBuilders.matchAllQuery());// 3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 4.解析响应结果SearchHits searchHits = response.getHits();// 4.1 查询总条数long total = searchHits.getTotalHits().value;System.out.println("查询总条数=" + total);// 4.2 查询结果数组SearchHit[] searchHitList = searchHits.getHits();for (SearchHit searchHit : searchHitList) {String sourceStr = searchHit.getSourceAsString();System.out.println(sourceStr);}
}
以上代码中关键的API有两个:
request.source():该方法返回一个SearchSourceBuilder对象,该对象中包含了查询、排序、分页、高亮等所有功能
QueryBuilders:其中包含match、term、function_score、bool等各种查询
执行以上单元测试,输出结果如下:
查询总条数=203
{"address":"中山路","brand":"白天鹅","business":"太古汇","city":"广州","id":1,"location":"45, 45","name":"白天鹅","pic":"a.png","price":888,"score":5,"starName":"五星"}
{"address":"静安交通路40号","brand":"7天酒店","business":"四川北路商业区","city":"上海","id":36934,"location":"31.251433, 121.47522","name":"7天连锁酒店(上海宝山路地铁站店)","pic":"https://m.tuniucdn.com/fb2/t1/G1/M00/3E/40/Cii9EVkyLrKIXo1vAAHgrxo_pUcAALcKQLD688AAeDH564_w200_h200_c1_t0.jpg","price":336,"score":37,"starName":"二钻"}
......
8.2 match查询与multi_match查询
match查询是根据某个字段进行查询。 例如:
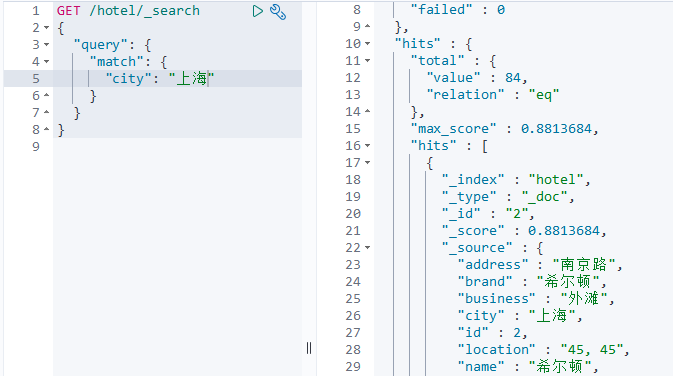
使用RestClient客户端实现match查询的代码和上面的match_all查询基本一致,在组织DSL参数是略有查差异:
// 其余代码和match_all查询的代码一致// 2.组织DSL参数
request.source().query(QueryBuilders.matchQuery("city", "上海"));

multi_match查询则是可以在多个字段上执行相同的match查询。 例如:

8.3 精确查询
精确查询主要包括:
term:词条精确匹配,这些精确值可以是数字、时间、布尔或者字符串等。range:数字或时间的范围查询,包括gt大于、gte大于等于、lt小于、lte小于等于。
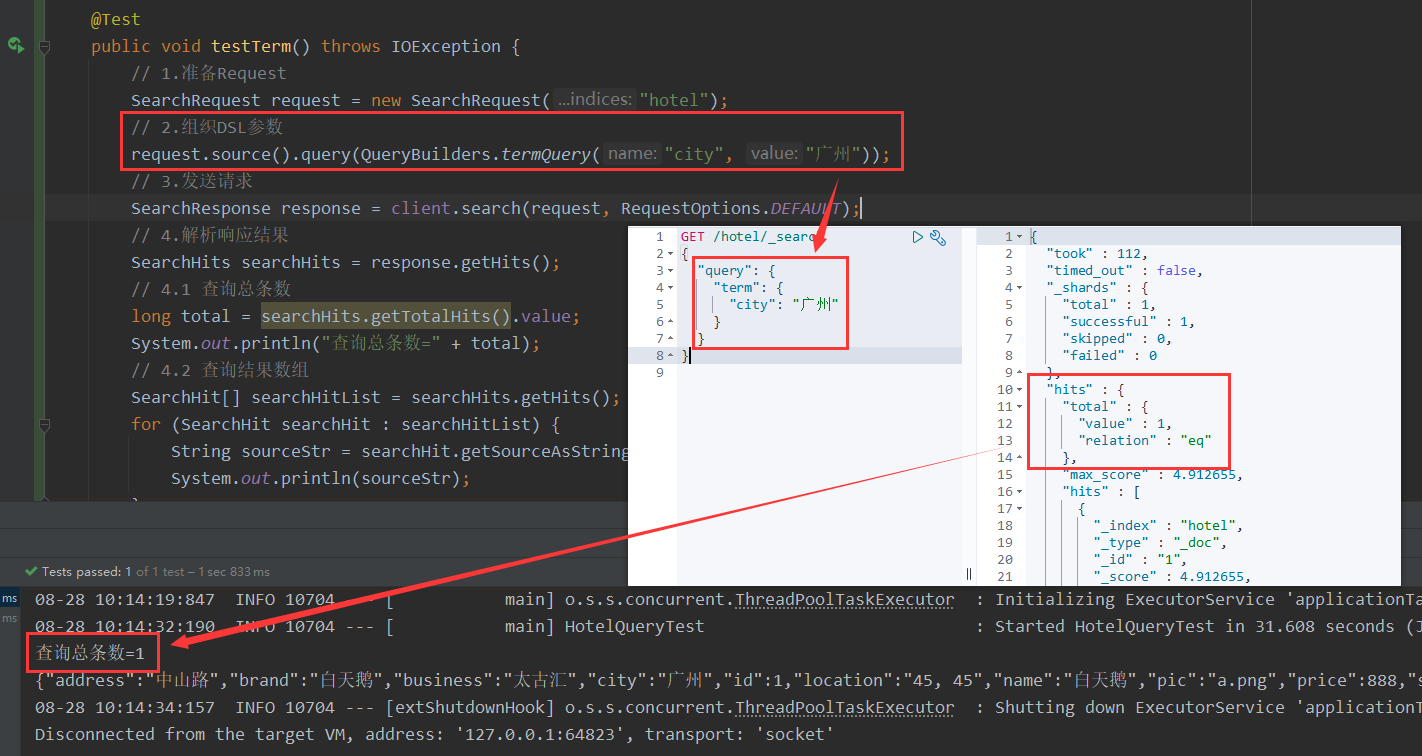

8.4 布尔查询
布尔查询就是用must、must_not、filter等方式组合其他的match、term、range等查询。

8.5 排序、分页、高亮
前面提到过,request.source()方法返回一个SearchSourceBuilder对象,该对象中包含了排序、分页、高亮等所有功能。
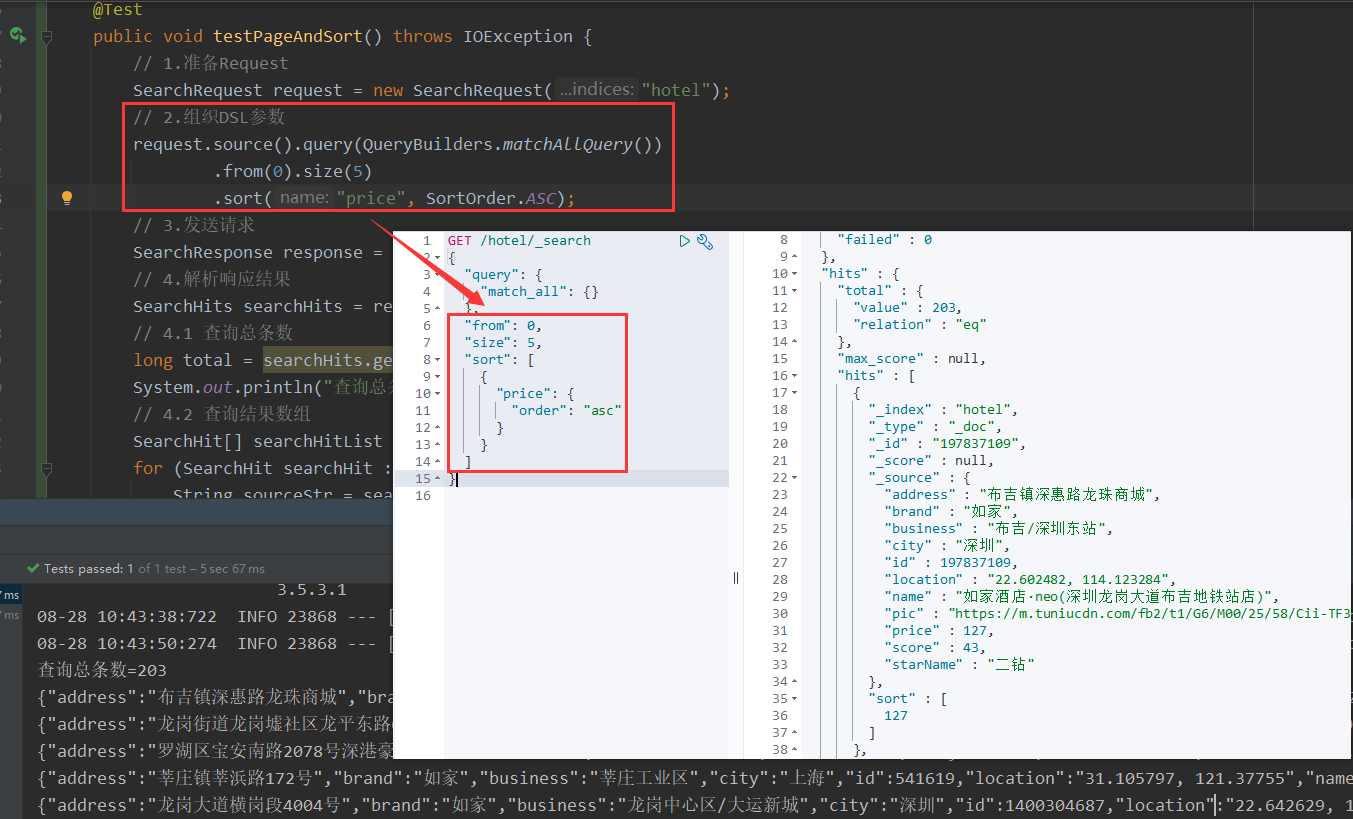
高亮的代码相比前面会差异大一点。在组织DSL语句时,除了查询条件,还需要添加高亮条件,同样是与query同级;在结果解析时,除了要解析_source文档数据,还要解析高亮结果。

9 项目实战
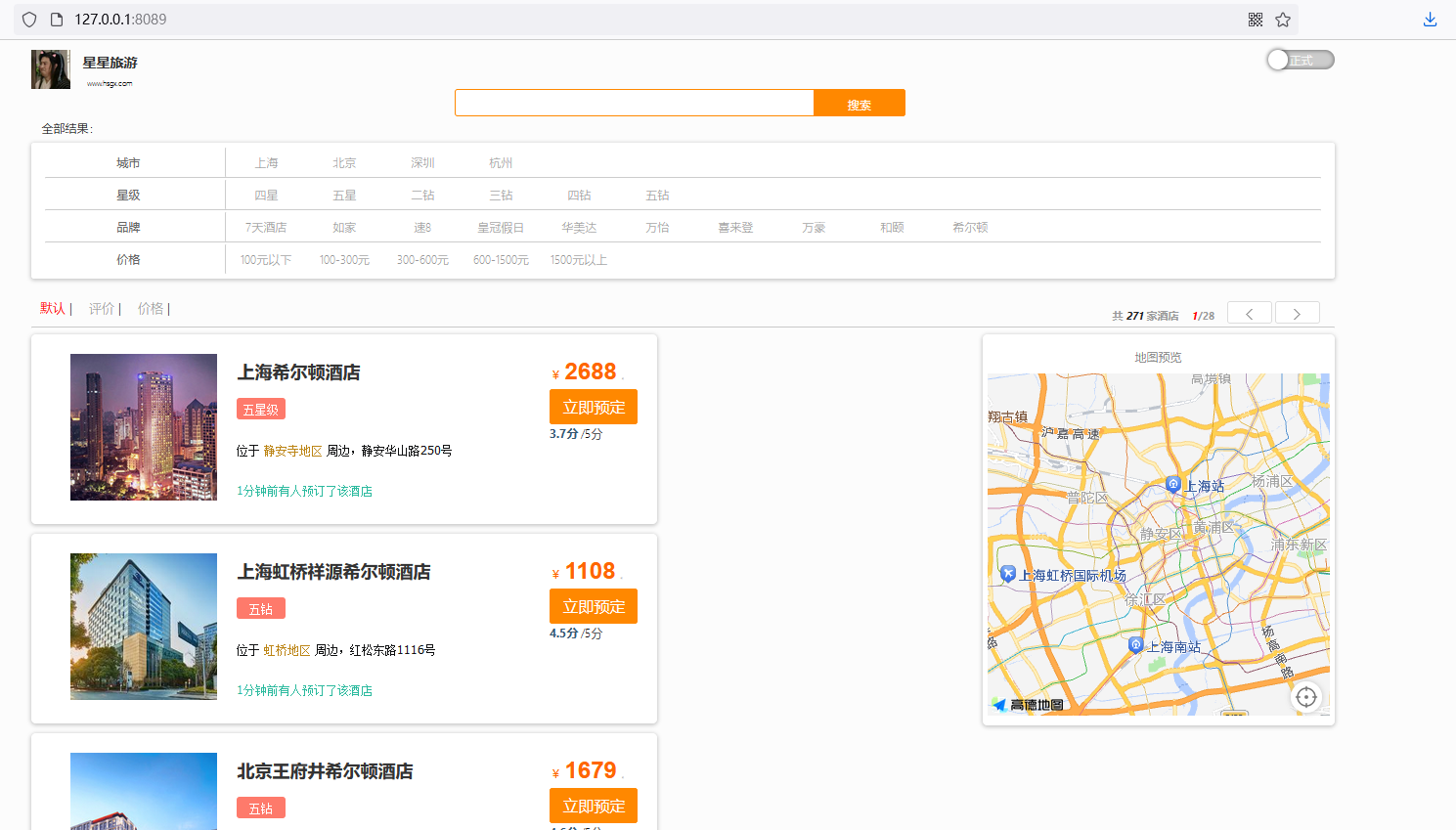
下面通过一个项目来实战演练ES的知识,主要实现四个功能:
- 酒店搜索和分页
- 酒店结果过滤
- 我周边的酒店
- 酒店竞价排名
本实战的重点在于Service层的逻辑实现,即根据需求组织DSL语句去查询ES获得想要的数据,因此对于SpringBoot项目的搭建过程、以及对应的HotelController类-IHotelService接口-HotelServiceImpl实现类-HotelMapper接口的实现就省略了。最终搭建的项目框架如下:

但有一个地方需要注意,就是要把RestHighLevelClient注册到Spring中作为一个Bean。在启动类cn.hsgx.hotel.HotelDemoApplication中声明这个Bean:
// cn.hsgx.hotel.HotelDemoApplication@MapperScan("cn.hsgx.hotel.mapper")
@SpringBootApplication
public class HotelDemoApplication {public static void main(String[] args) {SpringApplication.run(HotelDemoApplication.class, args);}@Beanpublic RestHighLevelClient restHighLevelClient(){return new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.245.130:9200")));}
}
9.1 酒店搜索和分页
需求:根据关键字搜索酒店列表,并可以进行分页。
- 1)创建两个实体类
请求参数实体
// cn.hsgx.hotel.pojo.RequestParams@Data
public class RequestParams {// 搜索关键字private String key;// 页码private Integer page;// 每页大小private Integer size;// 排序private String sortBy;
}
返回参数实体
// cn.hsgx.hotel.pojo.PageResult@Data
public class PageResult {// 总条数private Long total;// 当前页的数据private List<HotelDoc> hotels;public PageResult() {}public PageResult(Long total, List<HotelDoc> hotels) {this.total = total;this.hotels = hotels;}
}
- 2)在
HotelServiceImpl实现类中,创建listHotels()方法实现该功能
// cn.hsgx.hotel.service.impl.HotelServiceImpl@Override
public PageResult listHotels(RequestParams params) {try {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备请求参数// 2.1.关键字String key = params.getKey();if (StringUtils.isNotBlank(key)) {// 不为空,根据关键字查询request.source().query(QueryBuilders.matchQuery("all", key));} else {// 为空,查询所有request.source().query(QueryBuilders.matchAllQuery());}// 2.2.分页int page = params.getPage();int size = params.getSize();request.source().from((page - 1) * size).size(size);// 3.发送请求SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);// 4.解析响应return handleResponse(response);} catch (IOException e) {throw new RuntimeException("搜索数据失败", e);}
}private PageResult handleResponse(SearchResponse response) {SearchHits searchHits = response.getHits();// 4.1.总条数long total = searchHits.getTotalHits().value;// 4.2.获取文档数组SearchHit[] hits = searchHits.getHits();// 4.3.遍历List<HotelDoc> hotels = new ArrayList<>(hits.length);for (SearchHit hit : hits) {// 4.4.获取sourceString json = hit.getSourceAsString();// 4.5.反序列化,非高亮的HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);// 4.6.放入集合hotels.add(hotelDoc);}return new PageResult(total, hotels);
}
- 3)功能测试


9.2 酒店列表过滤
需求:根据城市、星级、品牌、价格等对就酒店查询结果进行过滤。

- 1)修改请求参数
RequestParams类,新增相关查询参数
// cn.hsgx.hotel.pojo.RequestParams@Data
public class RequestParams {// 搜索关键字private String key;// 页码private Integer page;// 每页大小private Integer size;// 排序private String sortBy;// 城市private String city;// 星级private String starName;// 品牌private String brand;// 价格private Integer minPrice;private Integer maxPrice;
}
- 2)修改
HotelServiceImpl类的listHotels()方法的业务逻辑
在之前的业务逻辑中,只有一个根据关键字搜索的match查询,现在要添加条件过滤,包括:
- 城市过滤:
keyword类型,用term查询 - 星级过滤:
keyword类型,用term查询 - 品牌过滤:
keyword类型,用term查询 - 价格过滤:数值类型,用
range查询
而多个查询条件组合,则需要是boolean查询来组合:
- 关键字搜索放到
must中,参与算分 - 其它过滤条件放到
filter中,不参与算分
为了代码逻辑更加清晰,可以将查询条件的处理单独封装成一个方法handleQueryParams():
// cn.hsgx.hotel.service.impl.HotelServiceImpl@Override
public PageResult listHotels(RequestParams params) {try {// 1.准备RequestSearchRequest request = new SearchRequest("hotel");// 2.准备请求参数// 2.1.处理查询条件handleQueryParams(params, request);// 2.2.分页int page = params.getPage();int size = params.getSize();request.source().from((page - 1) * size).size(size);// 3.发送请求SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);// 4.解析响应return handleResponse(response);} catch (IOException e) {throw new RuntimeException("搜索数据失败", e);}
}private void handleQueryParams(RequestParams params, SearchRequest request) {// 1.准备boolean查询BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();// 1.1.关键字搜索,match查询,放到must中String key = params.getKey();if (StringUtils.isNotBlank(key)) {// 不为空,根据关键字查询boolQuery.must(QueryBuilders.matchQuery("all", key));} else {// 为空,查询所有boolQuery.must(QueryBuilders.matchAllQuery());}// 1.2.城市String city = params.getCity();if (StringUtils.isNotBlank(city)) {boolQuery.filter(QueryBuilders.termQuery("city", city));}// 1.3.星级String starName = params.getStarName();if (StringUtils.isNotBlank(starName)) {boolQuery.filter(QueryBuilders.termQuery("starName", starName));}// 1.4.品牌String brand = params.getBrand();if (StringUtils.isNotBlank(brand)) {boolQuery.filter(QueryBuilders.termQuery("brand", brand));}// 1.5.价格范围Integer minPrice = params.getMinPrice();Integer maxPrice = params.getMaxPrice();if (minPrice != null && maxPrice != null) {maxPrice = maxPrice == 0 ? Integer.MAX_VALUE : maxPrice;boolQuery.filter(QueryBuilders.rangeQuery("price").gte(minPrice).lte(maxPrice));}// 2.设置查询条件request.source().query(boolQuery);
}
- 3)功能测试
筛选出北京的酒店:
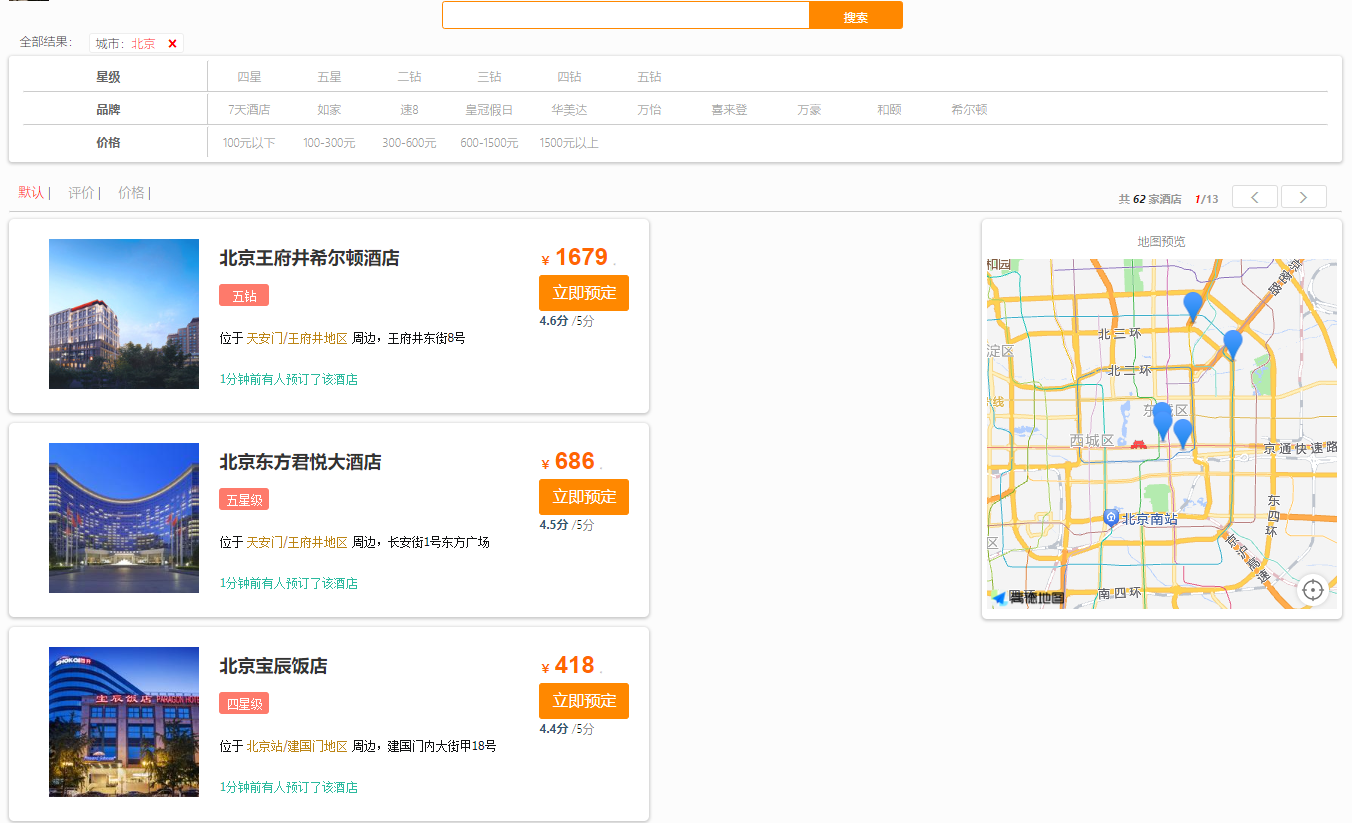
筛选出北京、五钻的酒店:
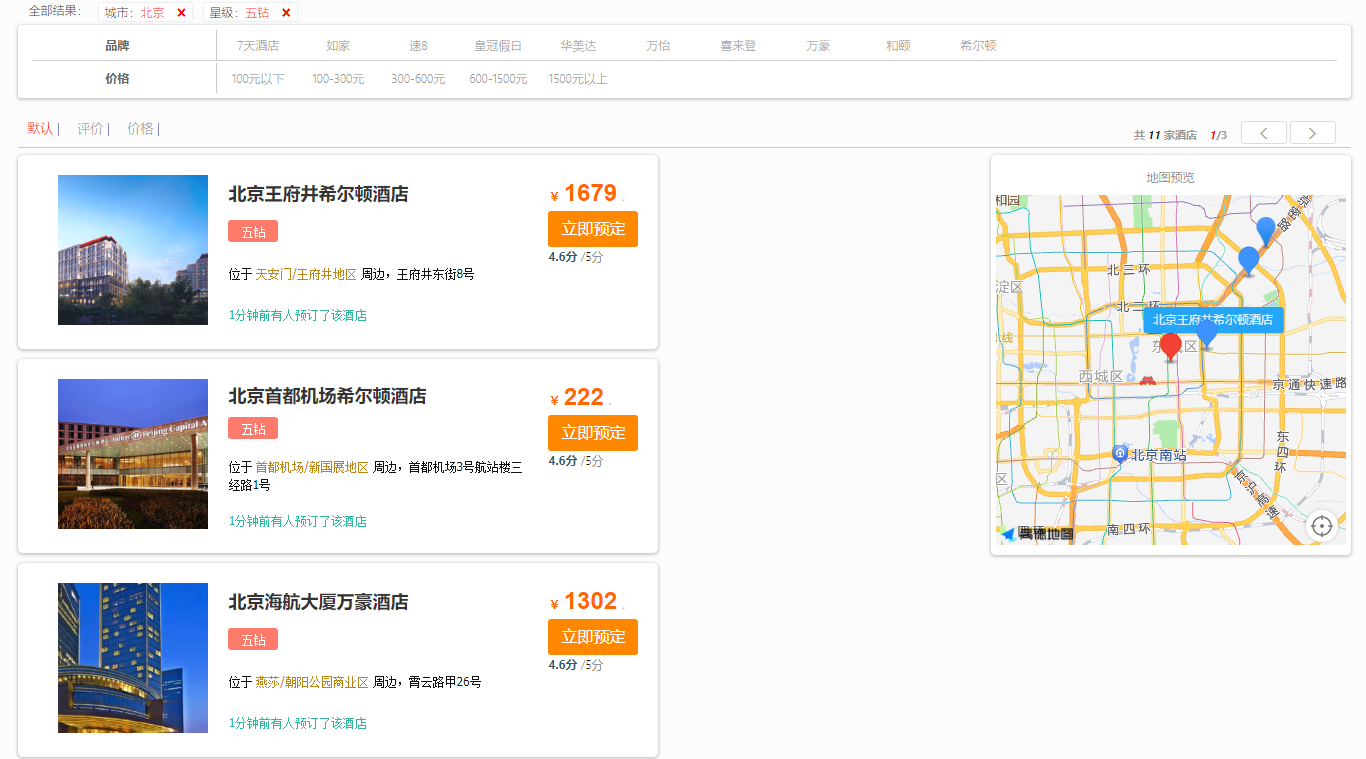
筛选出北京、五钻的万豪酒店:

筛选出北京、五钻的、且价格在100-300的万豪酒店:

…
本节完,更多内容请查阅分类专栏:微服务学习笔记
感兴趣的读者还可以查阅我的另外几个专栏:
- SpringBoot源码解读与原理分析
- MyBatis3源码深度解析
- Redis从入门到精通
- MyBatisPlus详解
- SpringCloud学习笔记