使用 ELK Stack 进行云原生日志记录和监控:AWS 中的开发运营方法
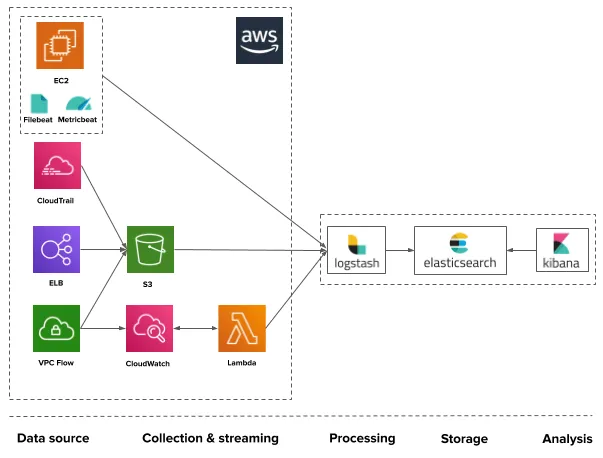
欢迎来到雲闪世界。在当今的云原生世界中,日志记录和监控是强大的 DevOps 策略的重要组成部分。监控应用程序性能、跟踪错误和分析日志对于确保无缝操作和主动识别潜在问题至关重要。在本文中,我们将指导您使用 AWS 上的 ELK Stack(Elasticsearch、Logstash 和 Kibana)设置云原生日志记录和监控,从而实现以 DevOps 为中心的方法来管理基于云的应用程序。
1.什么是ELK堆栈?
ELK Stack 是一种流行的开源解决方案,用于集中、搜索和可视化日志和指标。它由三个核心组件组成:
- Elasticsearch:分布式、可扩展的搜索引擎,用于存储日志和指标并为其建立索引。 - Logstash:一种数据处理管道,可在将日志发送到 Elasticsearch 之前从各种来源获取并转换日志。 - Kibana:一个强大的数据可视化和探索工具,可以实时洞察 Elasticsearch 中存储的数据。
2. 在 AWS 上设置 Elasticsearch
我们将使用 AWS CLI 在 Amazon Elasticsearch Service 中创建 Elasticsearch 集群。确保您已安装 AWS CLI 并使用适当的凭证进行配置。
# Use AWS CLI to create an Elasticsearch clustercreate an Elasticsearch cluster
aws es create-elasticsearch-domain --domain-name my-elasticsearch-domain \--elasticsearch-version "7.13" \--elasticsearch-cluster-config InstanceType=t2.small.elasticsearch,InstanceCount=2 \--ebs-options EBSEnabled=true,VolumeType=gp2,VolumeSize=10注意:将“my-elasticsearch-domain”替换为您的域的唯一名称。
3. 在 AWS 上设置 Logstash
为了设置 Logstash,我们将使用 Amazon Linux 2 AMI 启动安装了 Logstash 的 EC2 实例。使用 SSH 连接到实例。
# Launch an EC2 instance with Logstash
aws ec2 run-instances --image-id ami-0c3fd0f5d33134a76 --instance-type t2.micro \--image-id ami-0c3fd0f5d33134a76 --instance-type t2.micro \--key-name your-key-pair-name --security-group-ids sg-xxxxxxx --subnet-id subnet-xxxxxxx注意:将 `ami-0c3fd0f5d33134a76` 替换为适合您所在区域的 Amazon Linux 2 AMI ID。另外,将 `your-key-pair-name` 替换为您的 SSH 密钥对的名称,将 `sg-xxxxxxx` 替换为您的安全组的 ID,将 `subnet-xxxxxxx` 替换为您的子网的 ID。
接下来,通过 SSH 进入实例:
ssh -i /path/to/your-key-pair.pem ec2-user@public-ip-of-instancei /path/to/your-key-pair.pem ec2-user@public-ip-of-instance现在,安装 Logstash 并将其配置为将日志转发到 Elasticsearch。
# Install Logstash
sudo yum install -y logstash
# Create a Logstash configuration file
sudo vi /etc/logstash/conf.d/my-logstash-config.conf在 my-logstash-config.conf 文件中,添加以下配置以从 Filebeat 接收日志:
input {beats {port => 50445044}
}output {elasticsearch {hosts => ["https://your-elasticsearch-endpoint"]index => "my-application-logs-%{+YYYY.MM.dd}"}
}启动 Logstash:
sudo systemctl start logstash
sudo systemctl enable logstashenable logstash4. 在 AWS 上设置 Kibana
与 Logstash 类似,我们将使用 Amazon Linux 2 AMI 启动另一个安装了 Kibana 的 EC2 实例。
# Launch an EC2 instance with Kibana
aws ec2 run-instances --image-id ami-0c3fd0f5d33134a76 --instance-type t2.micro \--image-id ami-0c3fd0f5d33134a76 --instance-type t2.micro \--key-name your-key-pair-name --security-group-ids sg-xxxxxxx --subnet-id subnet-xxxxxxx通过 SSH 登录 Kibana 实例:
ssh -i /path/to/your-key-pair.pem ec2-user@public-ip-of-instancei /path/to/your-key-pair.pem ec2-user@public-ip-of-instance现在,安装 Kibana:
# Install Kibana
sudo yum install -y kibana
# Configure Kibana to connect to Elasticsearch
sudo vi /etc/kibana/kibana.yml在 `kibana.yml` 文件中,添加以下配置以指定 Elasticsearch 端点:
elasticsearch.hosts: ["https://your-elasticsearch-endpoint"]将 `your-elasticsearch-endpoint` 替换为您的 Elasticsearch 集群的端点。
sudo systemctl start kibana
sudo systemctl enable kibanaenable kibana5. 将日志流式传输到 ELK Stack
选择以下日志传送程序之一将日志从您的应用程序流式传输到 Logstash:
使用 Filebeat(用于文本日志):
在应用程序服务器上安装并配置 Filebeat:
# Install Filebeat
sudo yum install -y filebeat
# Configure Filebeat to send logs to Logstash
sudo vi /etc/filebeat/filebeat.yml在 filebeat.yml 文件中添加以下配置:
output.logstash:hosts: ["logstash-private-ip:5044"]将 `logstash-private-ip` 替换为 Logstash 实例的私有 IP 地址。
启动并启用 Filebeat:
sudo systemctl start filebeat
sudo systemctl enable filebeatenable filebeat使用 Fluentd(用于 JSON 日志):
在应用程序服务器上安装并配置 Fluentd:
# Install Fluentd
curl -L https://toolbelt.treasuredata.com/sh/install-amazon2-td-agent4.sh | sh
# Configure Fluentd to send logs to Logstash
sudo vi /etc/td-agent/td-agent.conf在`td-agent.conf`文件中,添加以下配置:
<match my_application.**>@type forward<server>host logstash-private-ipport 5044</server>
</match>启动并启用 Fluentd:
sudo systemctl start td-agenttd-agent
sudo systemctl enable td-agent6. 在 Kibana 中监控和可视化日志
从您的 Web 浏览器访问 Kibana:
http://public-ip-of-kibana-instance在 Kibana 中创建索引模式来定义日志数据结构。在 Kibana 中探索、可视化和创建仪表板,以深入了解应用程序的性能和运行状况。
结论 通过执行这些步骤并使用提供的 AWS CLI 命令和配置文件,我们可以使用 AWS 上的 ELK Stack 设置云原生日志记录和监控。这种以 DevOps 为中心的方法使我们的团队能够高效地排除故障、调试和优化云原生应用程序,从而在云原生时代增强客户体验并取得业务成功。通过集中的日志和指标,我们可以深入了解您的应用程序的性能和运行状况,从而更好地制定决策并主动管理您的基于云的应用程序。
感谢关注雲闪世界。(Aws解决方案架构师vs开发人员&GCP解决方案架构师vs开发人员)