「大数据分析」Pandas图形可视化,基本绘图:折线图及实践
在使用Python语言进行的可视化的过程中,基本上是通过Matplotlib第三方图形可视化库,来实现数据的可视化过程。Pandas的图形可视化,也是基于Matplotlib的底层库来实现的,可以算是Matplotlib库的简化版本。
很多时候,我们不一定非要立马做出精美的可视化图形。在我们分析数据和处理数据的过程中,经常需要快速生成图形,以便于我们及时查看数据在图形上是个什么样子,这样才能保证我们的数据分析和处理过程,有一个直观,能看见的参考。
安装matplotlib库
我们先来看Pandas图形可视化的基本绘图部分,折线图的实现过程。
这里我们用到了matplotlib库,没有安装的话,需要先安装这个库,才能正常绘图。
在vscode的终端,输入pip install matplotlib命令,进行安装

导入所需库,并设置关闭打开图形界面窗口参数。
绘制折线图
先通过随机函数,生成模拟数据集。
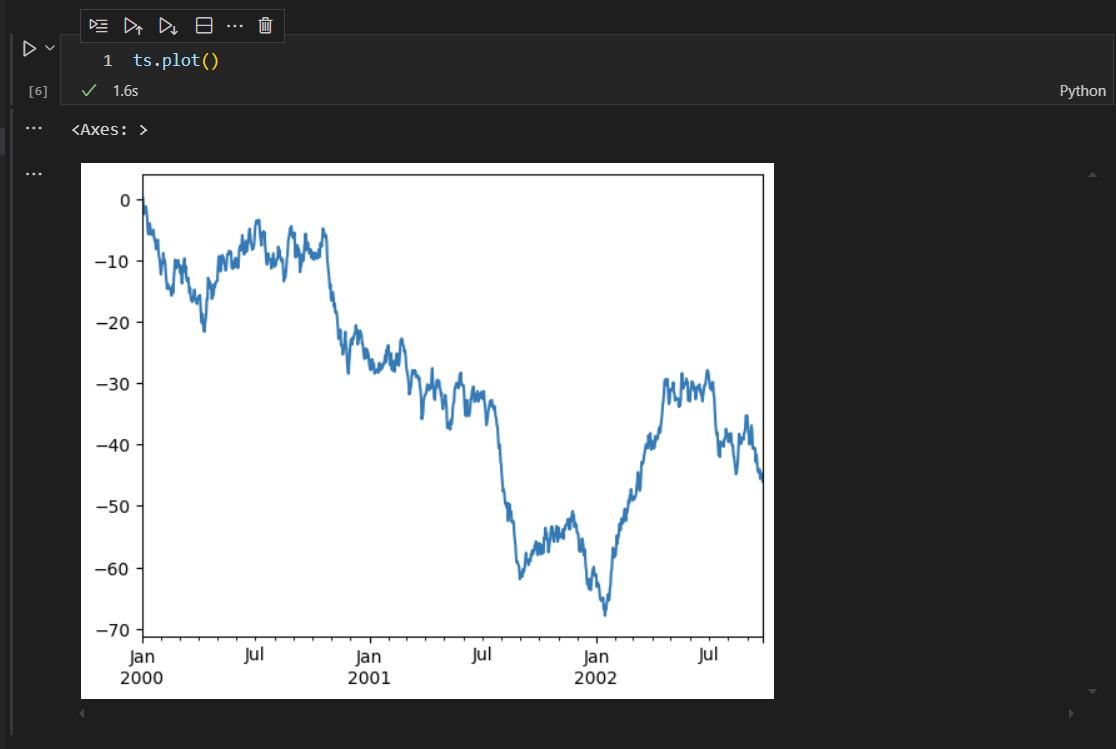
调用matplotlib的plot函数,实现绘图过程。
图形生成和绘制完毕后,可以点击图形右上方的按钮,复制和保存图片。
绘制多条折线图
我们经常需要在同一幅图中,查看多个变量之间趋势的,多条折线图。这样可以看出,多个变量间的趋势和影响的关系。
生成模拟数据集
这里的模拟数据集,有4列,分别代表4个变量。然后用前面的ts数据,作为df数据集的数据标签索引。
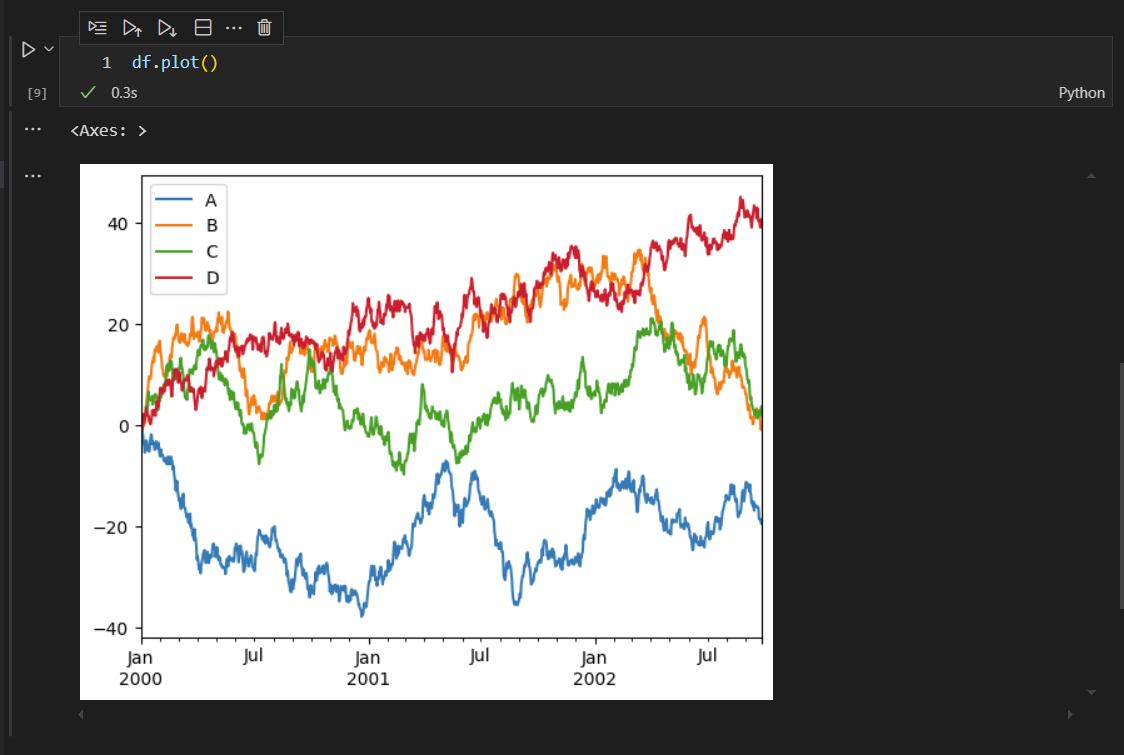
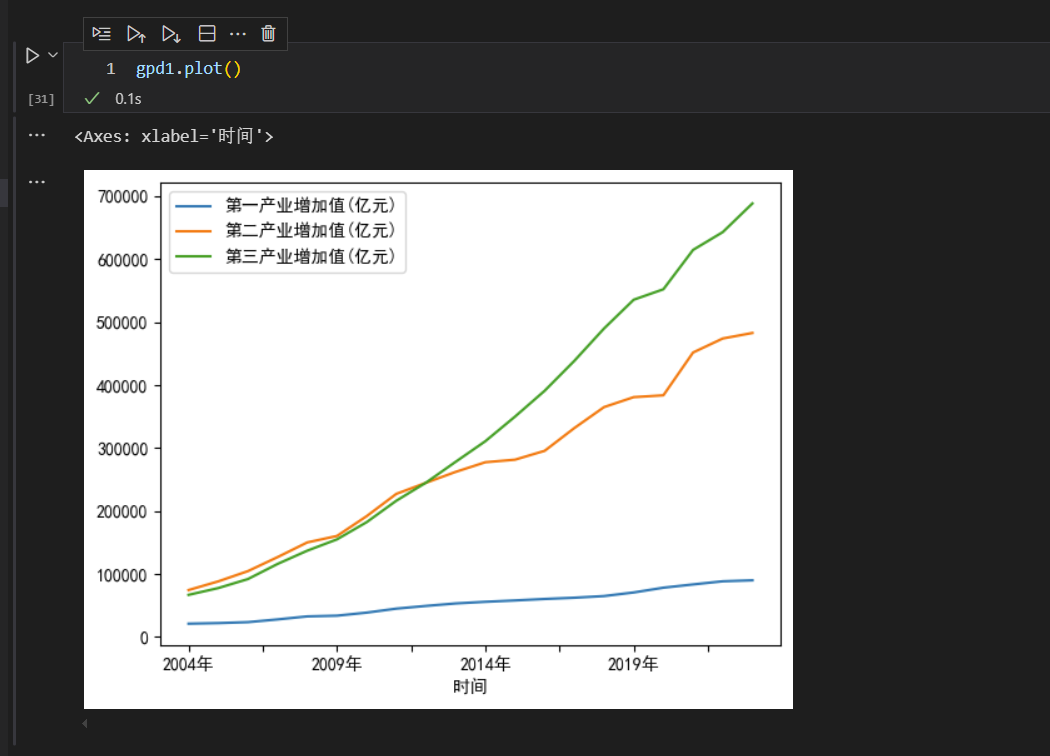
上图是可视化图形的样子,我们可以观察图形,其中,横轴X,是df数据集的索引,纵轴Y,是df数据集的列(这里是4列),形成4个变量,4条曲线的图形。
指定X轴和Y轴
有些时候,数据集变量多的话,我们可能只关注两个变量之间的关系,需要生成指定的两个变量的折线图,以此来查看两个变量数据的趋势和关系。
还是先生成模拟数据集
通过plot绘图函数,设置x和y
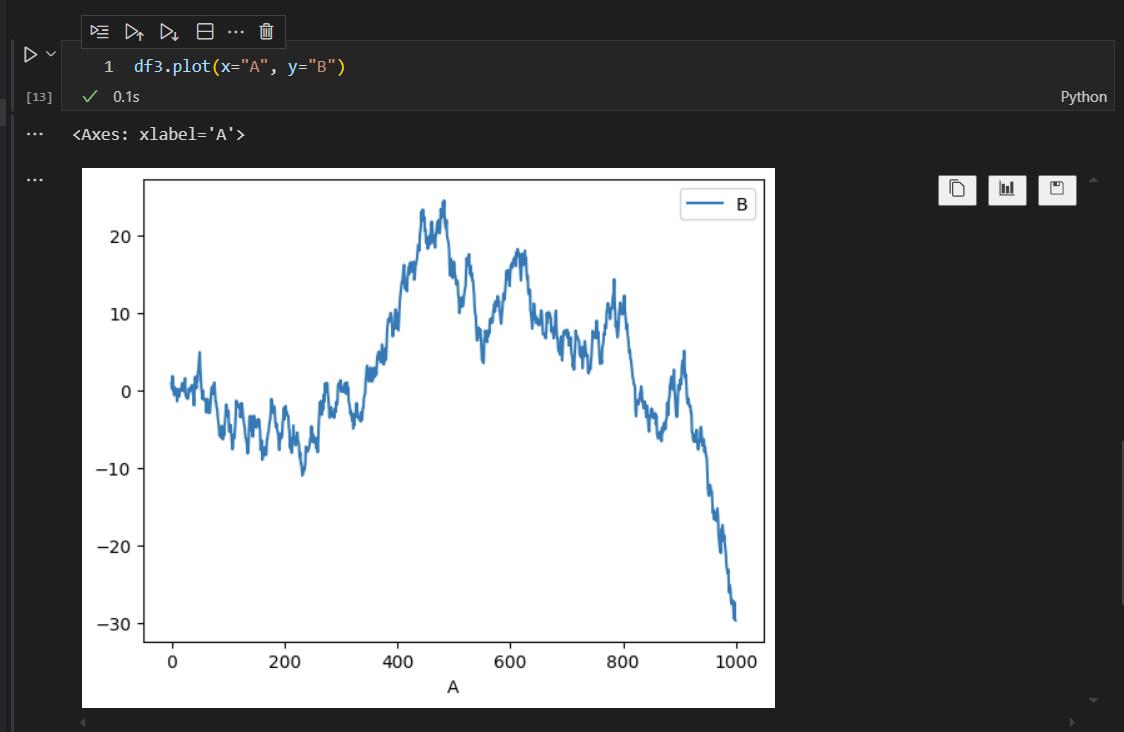
这样,我们就可以在多个变量,也就是多个列的数据集中,灵活指定绘制我们所需变量的曲线图。
折线图实践
这部分,我们来看,通过把以上知识点,运用到实际的数据可视化过程中,具体该怎么实现。
我们以国家统计局的数据为例,选取国内生产总值(GDP)数据,以及第一,第二,第三产业增加值,作为原始数据集。
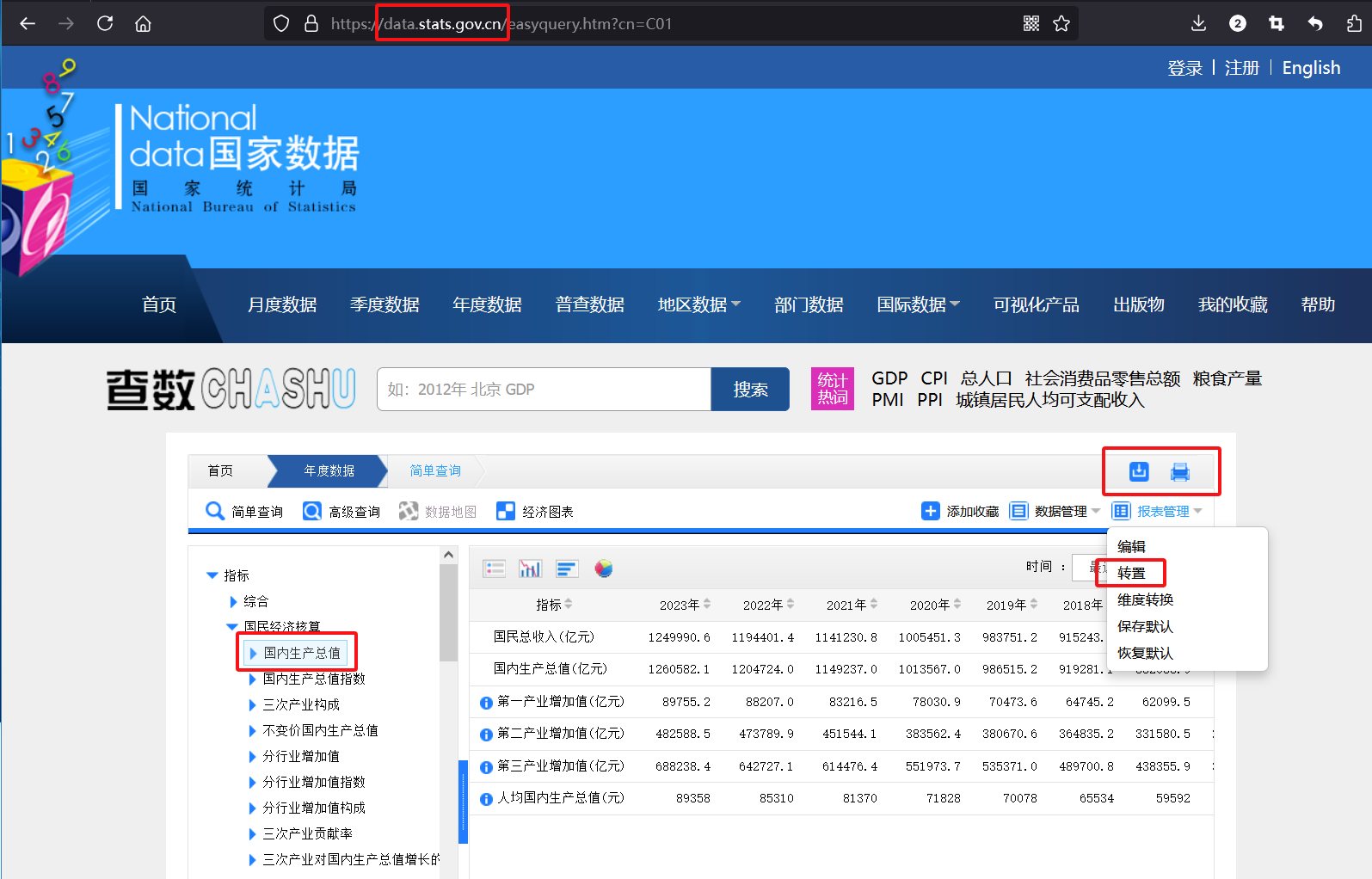
这里,注意国家统计局的网址。我们可以把数据进行转置,选取年度数据,时间范围是20年的数据。把数据集下载成为excel,下载的时候需要注册用户才行。
下载好的excel数据,如下图所示。
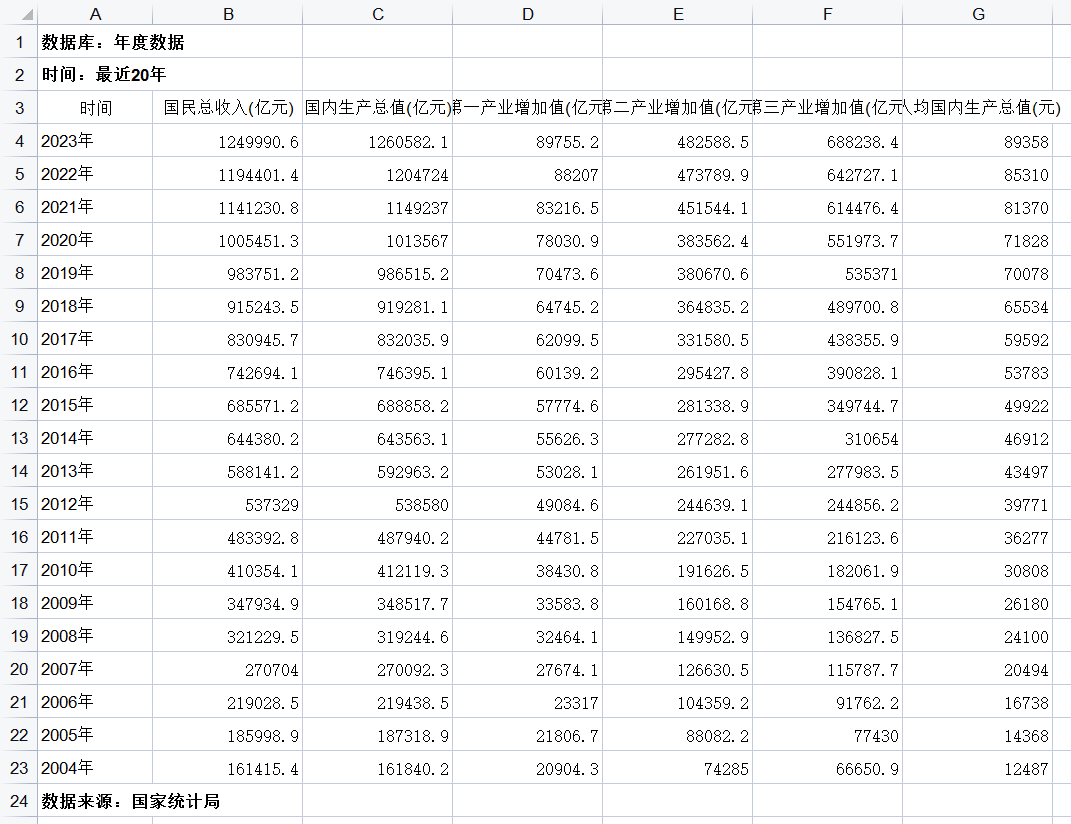
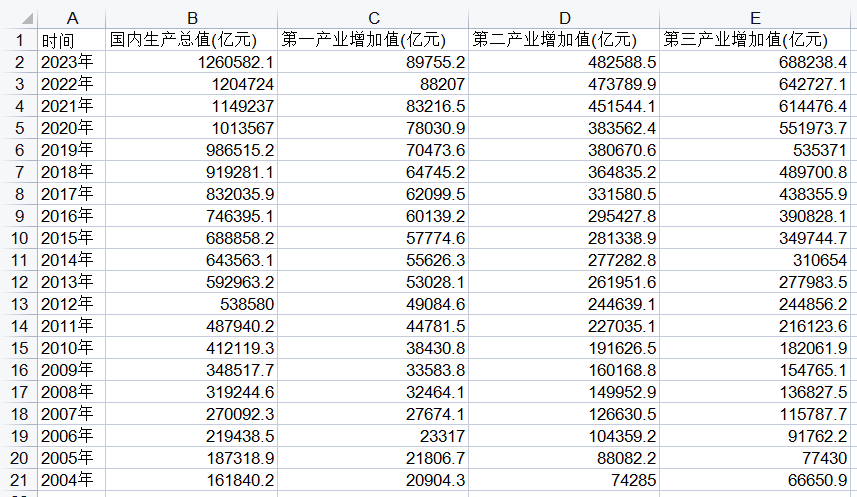
这里,我们整理一下数据,筛选出我们需要的数据集。
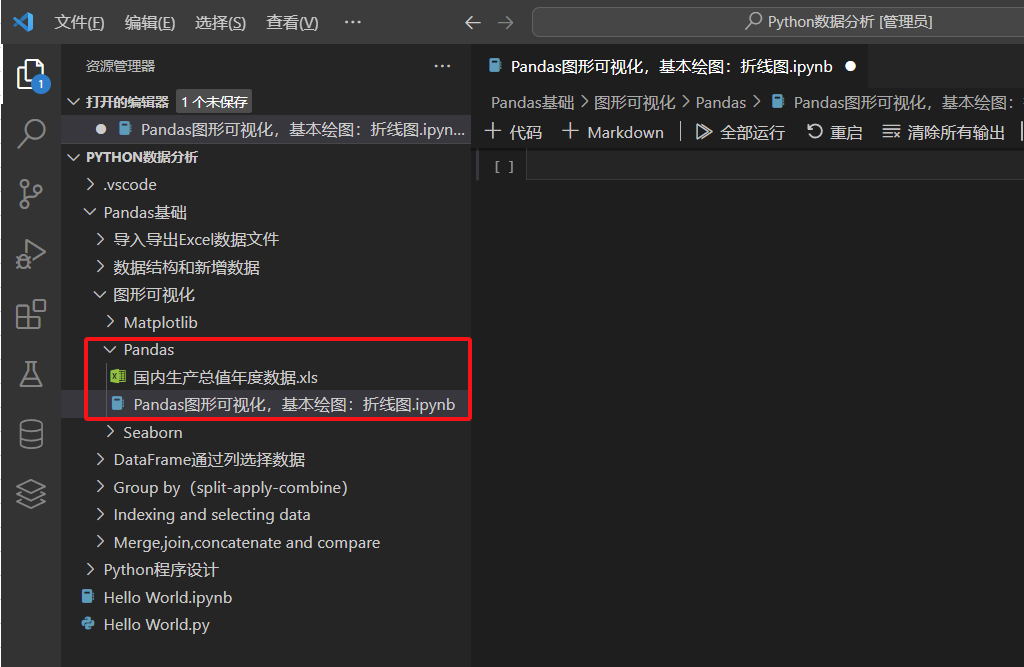
在导入数据之前,我们需要把下载好的excel数据文件,放到和python笔记本源程序文件,同一个目录下面。
导入原始数据集
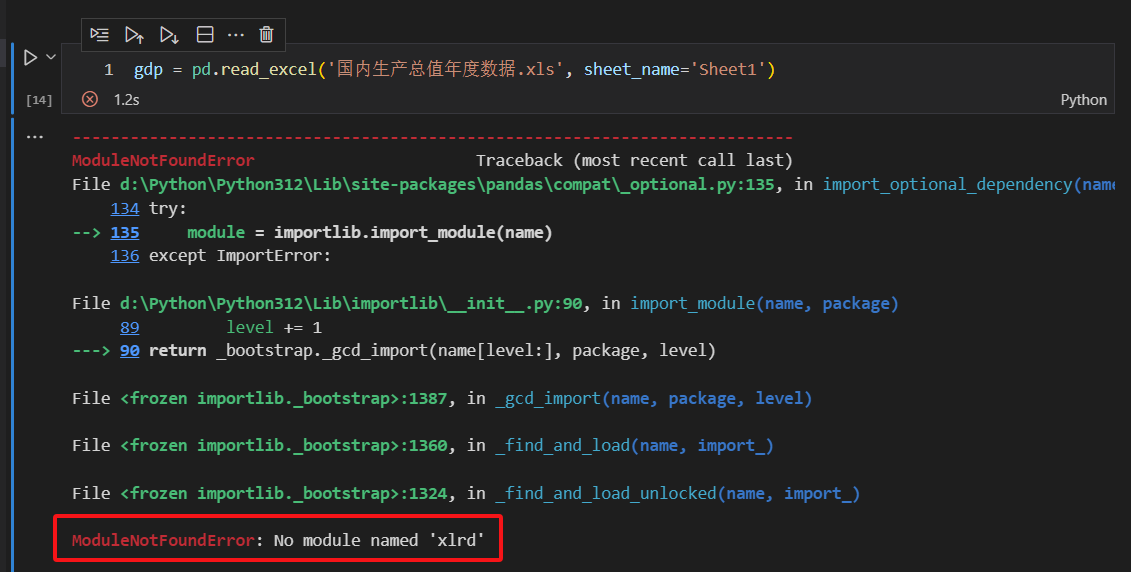
注意,这里我们导入的是xls后缀的excel文件,所以需要xlrd库。没有xlrd库,就会如上图一样的报错。我没有xlrd这个第三方库,所以要安装一下。
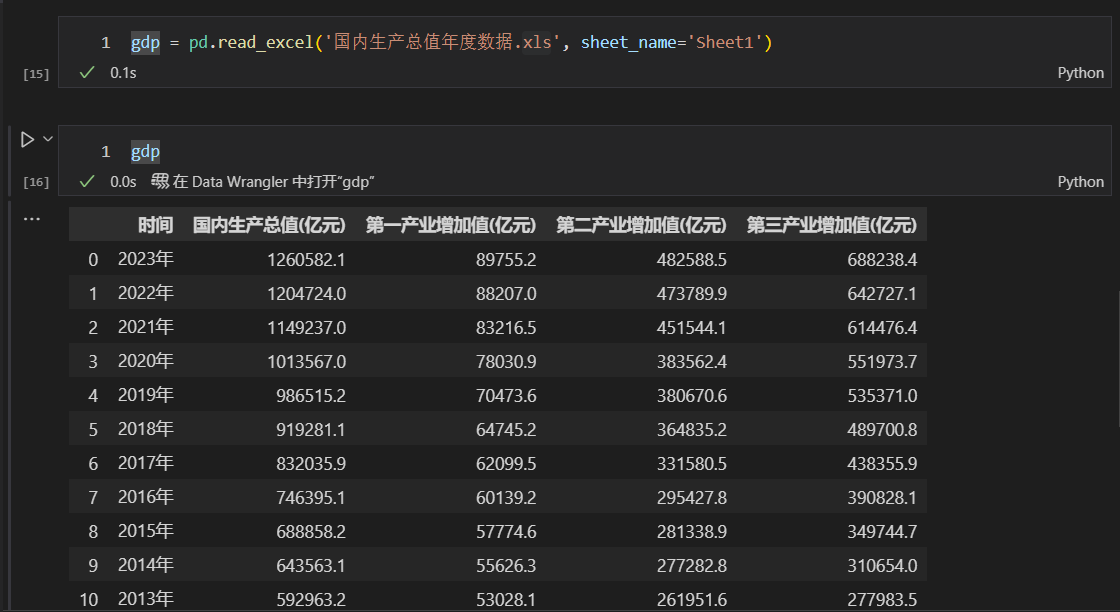
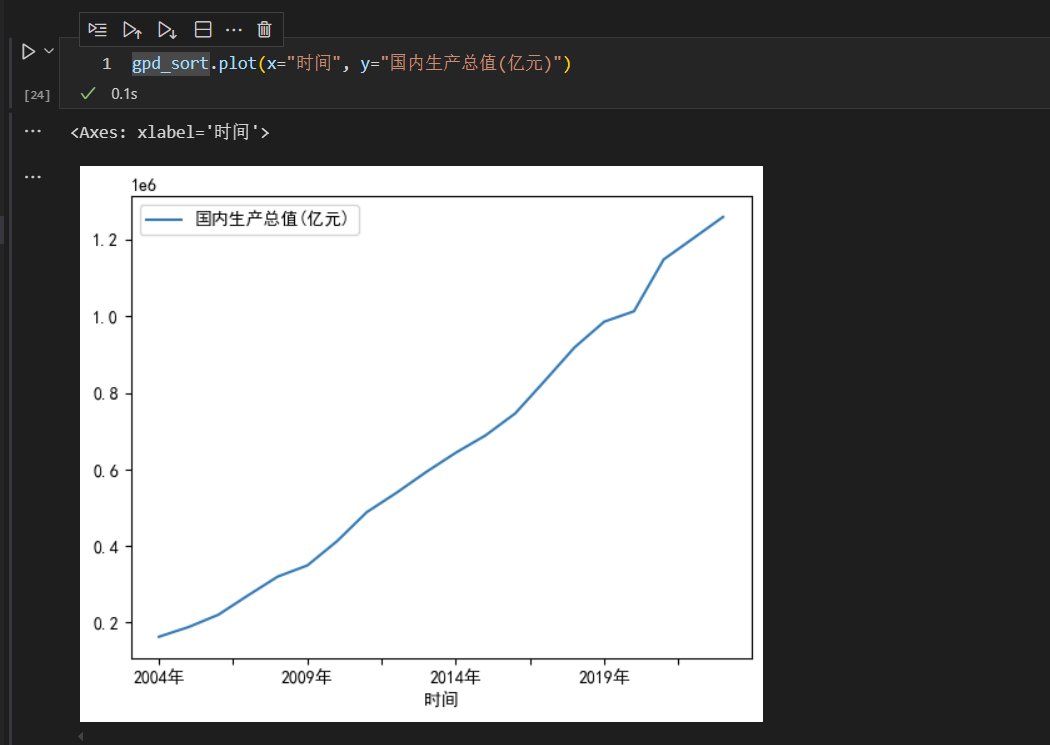
数据导入成功之后,我们先用plot函数,指定x轴和y轴,绘制单变量图形。这里,x轴设置为“时间”列,y轴设置为“国内生产总值(亿元)”列。
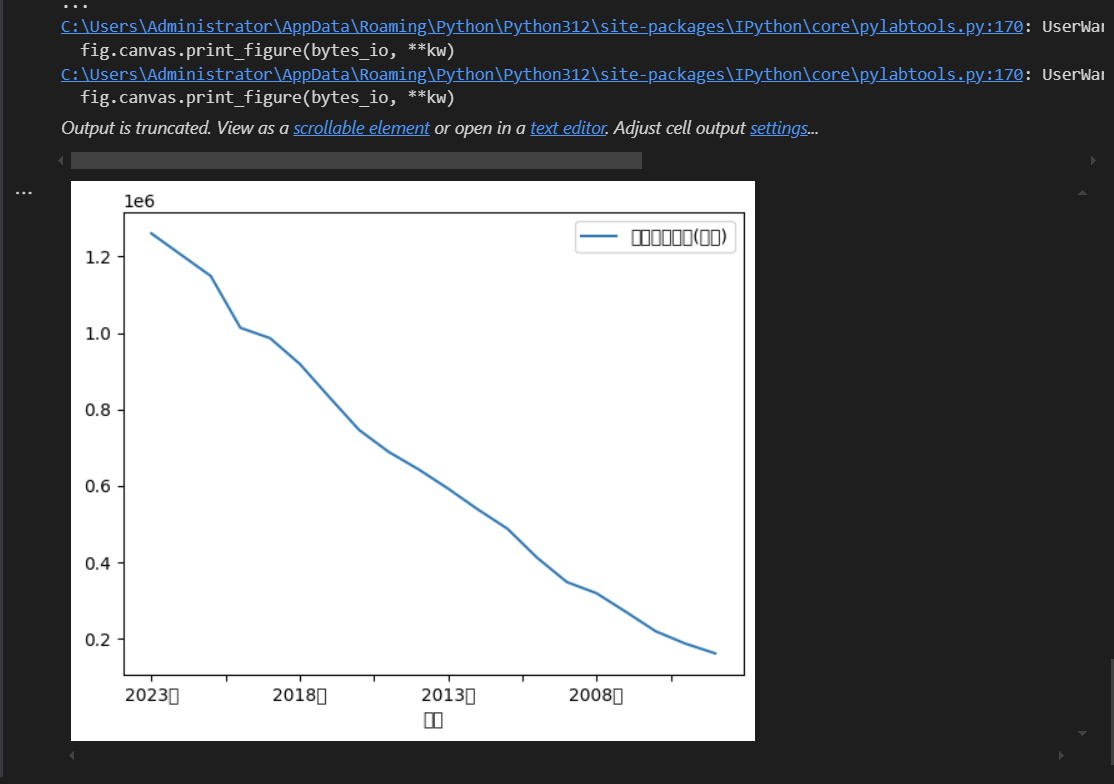
这里,输出的图形,中文会显示乱码,我们需要设置图形的中文编码形式。
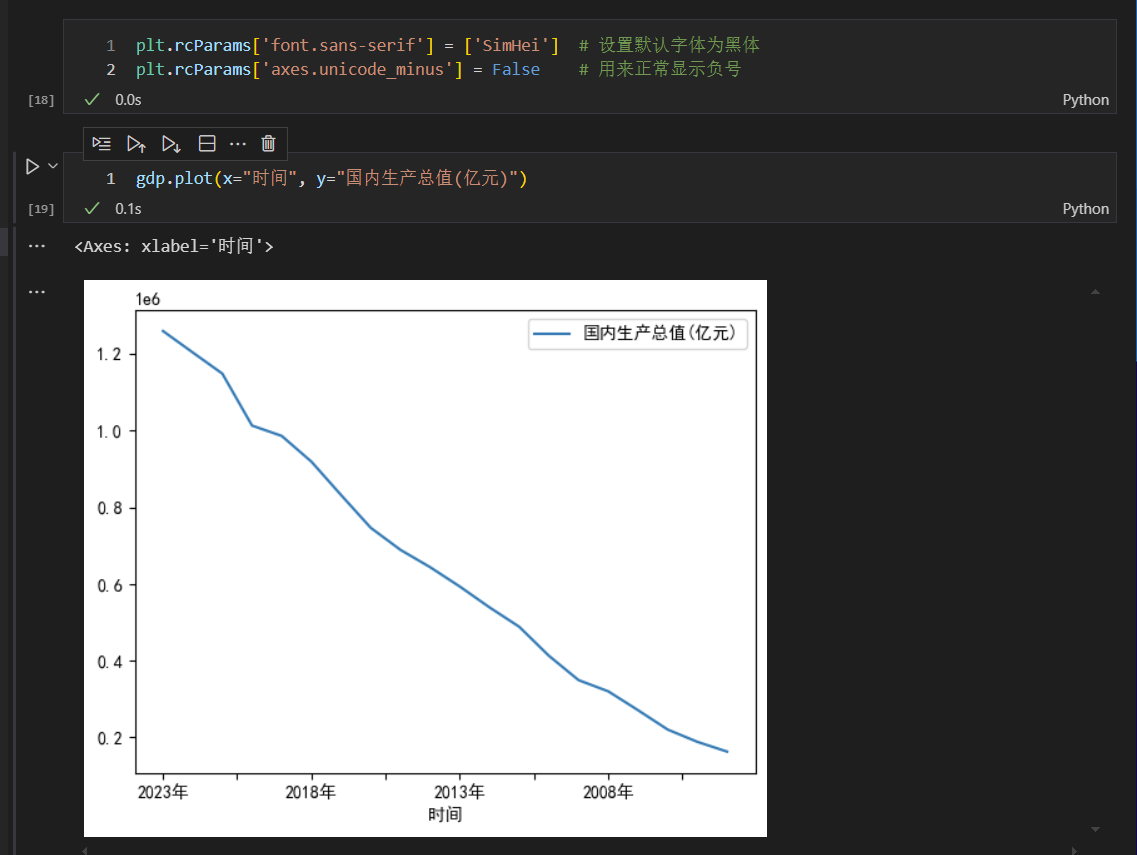
可以看出,设置默认字体为黑体之后,图形中文就显示正常了。
我们把数据进行降序排列,也就是按照时间,从小到大排列数据,查看数据的增长趋势。
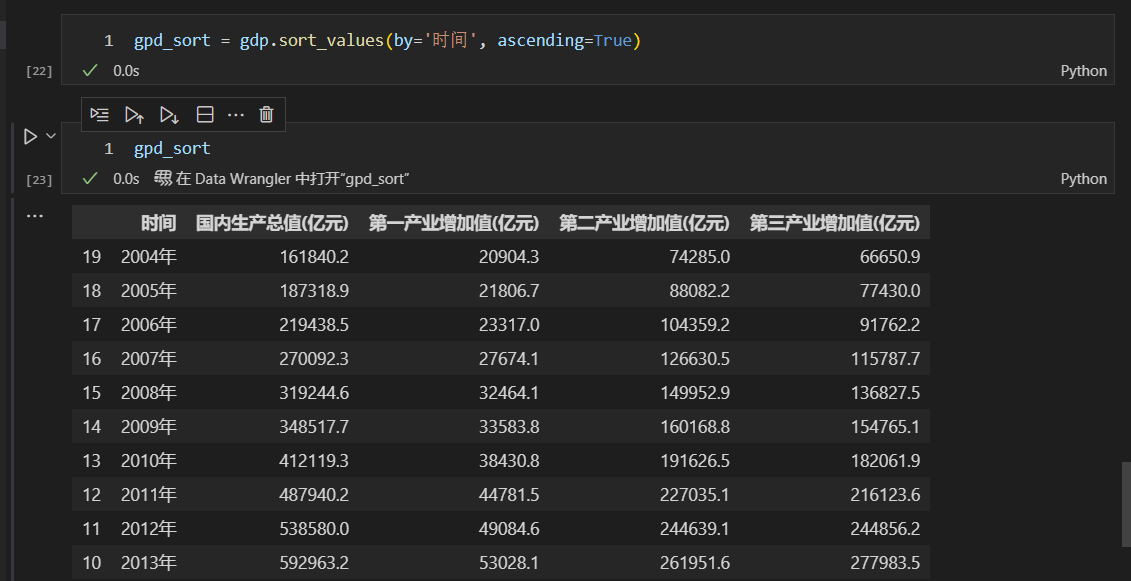
通过sort_values函数,设置by='时间',表示通过时间列进行排序。设置ascending=True,表示升序,从小到大进行排列。
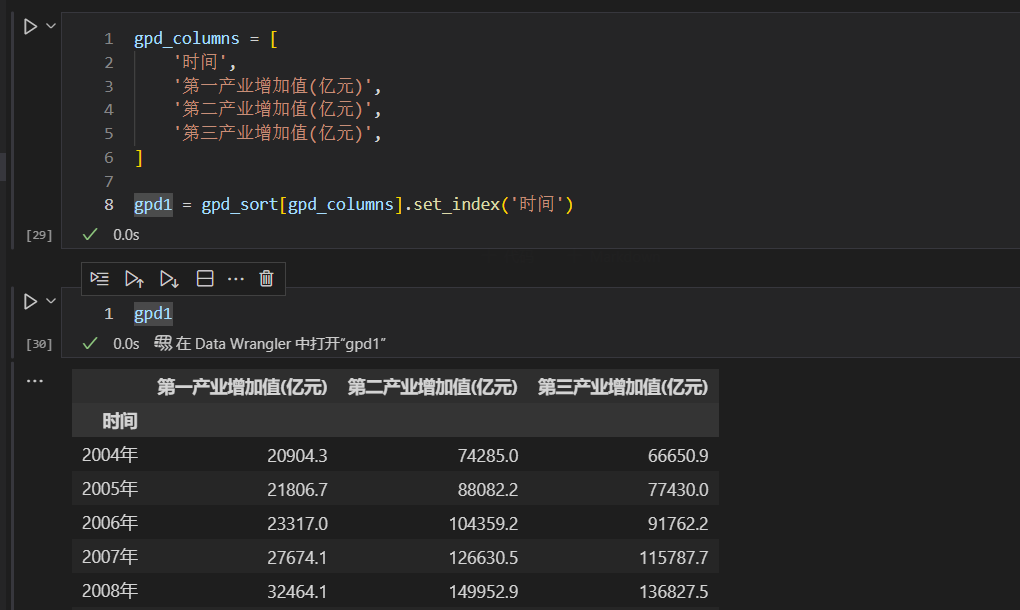
我们最后再来看看,多变量的折线图绘制。这里,我们使用第一,第二,第三产业增加值,来绘制图形。
我们gpd_sort数据集,进行清理。选择时间,第一产业增加值(亿元),第二产业增加值(亿元),第三产业增加值(亿元),4列,并且设置时间为索引列。
通过plot函数绘制图形
以上就是本篇文章的全部内容。
友情提示:
1.以上内容均为本人原创,且无偿分享。
2.如果觉得有用,请关注、点赞、收藏、转发。
3.如果有数据分析方面的难点和问题,请私信,或评论区留言。
4.我会答疑解惑,并选取部分案例,在后续作品中呈现。