Self Refine技术测评:利用Self Refine提高LLM的生成质量
1. 背景与挑战
在当今人工智能蓬勃发展的时代,大型语言模型(Large Language Models,简称 LLMs)已成为众多企业不可或缺的核心技术。从智能客服到内容创作,LLMs 在各个领域都展现出了惊人的能力。然而,随着应用范围的不断扩大,LLMs 的输出质量问题也日益凸显。许多组织发现,尽管 LLMs 能够生成看似合理的内容,但在细节、一致性和上下文理解等方面仍存在显著缺陷。 具体而言,企业面临以下挑战:
- 内容质量不稳定:LLMs 生成的内容质量波动较大,难以保证持续的高质量输出。
- 内容和上下文不一致问题:虽然有 AI 大量的知识存储,但是运营团队发现 AI 生成的文案内容不够丰富,往往达不到运营人员设置的 PE 效果。
- 后期评估耗时:客户支持团队不得不花费大量时间修改和优化 AI 生成的生成。
这些挑战凸显了一个关键问题:如何在充分利用 LLMs 强大生成能力的同时,确保输出内容的稳定,一致和丰富?为解决这一问题,研究人员提出了 Self Refine技术,这一创新方法旨在通过迭代优化提升 LLMs 的输出质量。
2. 解决方案
2.1 Self Refine 的简介
当我们创作时,很少能一次性完成最终版本。相反,我们通常会经历多轮修改和完善。Self Refine 技术的核心思想是模仿人类的思考和写作过程。它允许 LLM 迭代地细化输出,并沿多个维度合并反馈,以提高不同任务的性能。与之前的工作不同,它不需要监督训练数据或强化学习,并且使用单个 LLM 即可。
Self Refine 的核心思想类似于人类反馈强化学习(RHLF)。尽管开箱即用的 LLM 经过传统方法的训练,能够产生语法通顺的输出,但训练 LLM 产生“良好”的输出却是一个谜一样的难题。如“真实”、“有用”、“创意”这样的概念,比起单纯的词义和语言结构,更加依赖于具体语境。当我们没有足够多的数据样本去做 RHLF 这样的训练时,Self Refine 可以通过少数的例子对于具体的语境加以描述,并将人类偏好转化为数字奖励信号(i.e. 评分),从而让模型能够更好得对齐人类的偏好。
2.2 Self Refine 解决的问题
Self Refine 文章提到,人类思考的过程其实是一个逐步迭代优化的过程,先开始思考大纲、然后完善细节等等,在这个过程会逐步文本进行修改。因此这种特性其实也可以应用到 LLM 中。Self Refine 的核心思想是通过迭代反馈来改善 LLMs 初始输出。具体步骤是使用 LLM 生成一个输出,然后允许相同的模型为其自己的输出提供多方面的反馈;最后,相同的模型通过自己的反馈对其先前生成的输出进行了改进。因此、在整个过程中,都不会修改模型的参数。因此self-refine完全是基于 Prompt 设计来实现的,在其中会包含 few-shot 来激活模型强大的能力。
2.3 技术原理
|
|
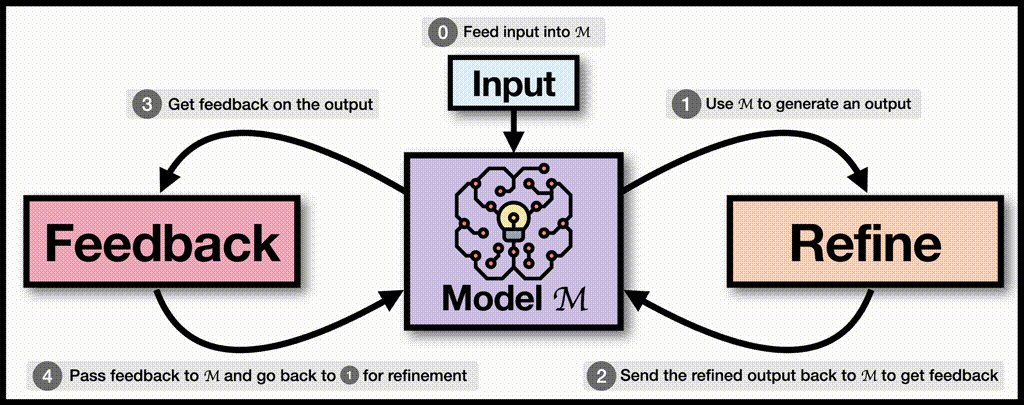
如上图 ,Self Refine 是通过迭代反馈和优化来改进其自生成的初始输出。该框架的主要思想:
- 使用一个模型 M 生成一个初始输出 y0。
- 将这个输出反馈回同一个模型 M,让它对自己的输出进行多方面的反馈。
- 将反馈结果再次传回模型 M,用于根据反馈优化之前生成的输出。
- 重复上述反馈-优化过程,进行迭代改进。
因此 Self Refine 的工作原理可以分为以下几个关键步骤:
- 初始生成:LLM 根据给定的提示词生成初始输出内容。
- 自我评估:对同一个 LLM 对生成的内容进行评估(需要自己设计评估指标和方法,可以使用 few-shot 来做为 example),识别需要改进的方面。
- 反馈生成:LLM 基于评估的指标和方法生成具体的改进反馈。
- 内容优化:将反馈结果输入给 LLM,让其对原始输出进行修改和优化。
- 迭代循环:重复步骤 2-4,直到达到预设的质量标准或迭代次数上限。
2.4 实现细节说明
为了更好地理解 Self Refine 的工作机制,让我们深入探讨其实现细节:
组件:
Init:初始时,LLM 根据提示词首次生成内容。
Feedback:接收初始输出,并返回如何增强它的反馈,反馈的形成通常涉及输入的评估指标。例如:在文案生成场景中,需要提供给 LLM 多个评价指标,以便于 LLM 能够量化输出内容并生成反馈建议。
Refine:负责接收从“反馈“组件传递的改进建议,通过改进建议,Refine 模块再次针对之前的生成的内容进行生成。
过程说明:
- 大致过程为:Init → Feedback → Refine,其中 Feedback 和 Refine 会进行多次,直到系统设定要求为止。
- Self Refine 保留了过去经历的历史。这是通过将以前的输出连续附加到提示中来实现的。这使系统能够从过去的错误中吸取教训,避免重蹈覆辙。
- Feedback 会生成可操作的反馈。给定 LLM 的初始输出,反馈会指出输出满足(或不满足)要求的原因。可操作的反馈包括两个方面:(一)问题的本地化;(二)改进的指导建议。
特点:
Self Refine 技术具有以下特点:
- 单模型架构:与需要多个模型协作的方法不同,Self Refine 仅使用一个 LLM 完成所有任务,简化了实现过程,降低了计算资源需求。
- 无需额外训练:Self Refine 可直接应用于预训练的 LLMs,无需针对特定任务进行微调或额外训练。
- 提示工程的灵活应用:通过精心设计的提示模板,引导 LLM 完成自我评估、反馈生成和内容优化等任务。
- 历史感知能力:系统会保留每次迭代的输出和反馈,使 LLM 能够学习从过往错误中吸取教训,避免重复同样的问题。
- 适应性强:Self Refine 可应用于多种任务类型,如文本生成、代码编写、问答系统等,具有广泛的适用性。
3. Self Refine 的实践案例
为了更好地理解 Self Refine 技术的实际应用,让我们深入探讨一个具体的案例。
3.1 案例背景:某公司的营销文案
某公司每天需要投入人力去做撰写攻略和旅游笔记。为了提高效率,公司决定使用 LLM 自动生成旅游笔记。然而,初期尝试发现,直接使用 LLM 生成的描述常常存在风格单一、内容不够丰富等问题。
如下是文案的需求和要求 (示例里的部分信息作了脱敏处理)
sys_prompt= """你是一个旅游攻略文案写手,你的任务是基于现有的行程规划文案参考生成一篇旅游攻略文案行程规划是{schedule} 行文格式请参考文案示例:{example}。<Rule>注意方案内容需要满足以下要求:1.xxxxxx2.xxxxxx3.xxxxxxxxx </Rule>
"""
schedule="""第1天,AAA——汉秀**——CCC第2天,BBB——**博物馆——黄鹤楼——DDDD
"""
example="""
#周末去哪儿 #笔记灵感
一提到古镇,可能很多人会想到江浙沪的水乡
但安徽黄山脚下的📍「徽州」也有❗️
如果感觉生活工作累了,就去这5个徽州小众古村落🏘️过几天神仙日子吧~
😌没有宏村西递的人挤人,想怎么玩都行!
去古镇里发发呆,躲在阴凉里快乐过夏天!
💚#呈坎
充满人间烟火气的千年古村!🏠一条溪水把古镇分为八卦布局,🪷夏日满塘荷花盛开,更是被朱熹称为“江南第一村”。村口有一个平安坎,流传:“到过呈坎,此生无坎”,♥️光是这福气就值得你来一趟啦!
✅推荐:八卦村、晒秋广场、古村群落、罗东舒祠
🎫门票:102💰
💚#西溪南
🌳古村被掩映在枫杨林之中,🍃夏天来着眼里尽是满眼葱翠。🪵石桥、汀步、木桥横穿于湿地溪流之上。清流绿树,石阶古村绿野仙踪也不过如此了
✅推荐:枫杨林湿地、古村木桥
🎫门票:0💰
💚#南屏
南屏古镇是安徽的影视村📷,是一座非常典型的皖南古村落,可以看到马头墙层层叠叠创造出来的极致美学。村里最有名的是祠堂,电影《菊豆》、《卧虎藏龙》多部作品的取景地都在这。🎬
✅推荐:叶氏宗祠、明清古建筑群
🎫门票:43💰
💚#查济古镇
查济(zhā jǐ)是皖南一个小众到连名字都容易读错的地方,但它所在的桃花潭镇,🌸你一定很熟悉,就是李白《赠汪伦》曾提到的桃花潭。🏠这里有现存规模最大的明清古村落,依山造屋,傍水结村🌊
✅推荐:画家村、青砖徽派建筑群、许溪
🎫门票:60💰
趁着周末的时间,去古镇感受慢时光吧!只需要一点时间就能满血复活~
#日常不想上班 #古镇 #夏日荷花 #小众 #黄山旅行 #我的小众旅行攻略 #假期去哪玩 #夏天 #避暑 #避暑好地方 #夏日避暑好去处 #小众旅行地
"""
user_input_prompt = "请按照要求并参照格式示例完成目的地攻略营销文案生成,最终生成的营销文案请放在<result>里"
3.2 设计实现
以下代码样例均用 Amazon Bedrock + Claude3 来进行试验。
Init
#初始化先通过LLM生成一次文案内容,如下是代码实现.
class TaskInit():def __init__(self, model_id: str) -> None:self.model_id = model_id #自行选择使用任意一种LLMself.bedrock_client = boto3.client(service_name='bedrock-runtime',config=bedrockcoCfig)def __call__(self) -> str:messages = [//加上result标签,便于从response中提出LLM生成的内容{"role": "user", "content": messages},{"role": "assistant", "content": "<result>"}]body=json.dumps({ "anthropic_version": "bedrock-2023-05-31", "max_tokens": model_config['max_tokens'], "temperature": model_config['temperature'], "top_p": .model_config['top_p'], "top_k": model_config['top_k'],"system": sys_prompt, "messages": messages"stop_sequences" : '</result>'} )response = bedrock_client.invoke_model(body = body,modelId = model_id,accept = 'application/json',contentType = 'application/json',)response_body = json.loads(response.get('body').read())for response_content in response_body['content']:if response_content['type'] == 'text':generated_response = response_content['text']usage = response_body['usage']#返回response,token使用量,文案生成内容return response_body, usage, generated_response
初始生成的效果如下:
#清明踏青去哪儿 #武汉赏樱花
🌸樱花季来临,是时候去武汉赏樱花啦!
武汉不仅有长江美景,更有满城樱花绽放的浪漫景致~
跟着我的行程,一起去武汉感受春日里最美的樱花吧!
🌸****
这是一艘复古的游船,沿着长江缓缓前行,两岸风光尽收眼底。船上还有歌舞表演,让你在赏景的同时也能欣赏到武汉的地方文化。
💡必打卡点:船头拍照留念,江景尽收眼底
🌍地址:武汉市武昌区东湖路知音门游船码头
⏱️游玩时长:2小时
#复古游船 #长江美景 #地方文化
🌸****
这是一座融合了古典与现代元素的大剧场,每晚都有精彩的歌舞表演。剧场内部装潢华丽,充满了浓郁的楚文化气息。
💡必打卡点:剧场大堂,拍照留念
🌍地址:武汉市武昌区东湖路汉秀剧场
⏱️游玩时长:2小时
#楚文化 #歌舞表演 #古典与现代
🌸****
乘船游览长江和汉江的交汇处,领略”两江交汇”的壮丽景象。沿途还能欣赏到武汉的城市风光和樱花盛开的美景。
💡必打卡点:长江大桥,拍照留念
🌍地址:武汉市江岸区长江大桥
⏱️游玩时长:1小时
#两江交汇 #城市风光 #樱花盛开
🌸*
这是武汉市区内的一座城中湖,四周环湖而建有公园、步行道等,是武汉人民休闲娱乐的好去处。樱花季节,湖边的樱花小径更是不可错过。
💡必打卡点:樱花小径,拍照留念
🌍地址:武汉市武昌区东湖风景区
⏱️游玩时长:2-3小时
#城中湖 #樱花小径 #休闲娱乐
🌸*
这里收藏了大量珍贵的文物,全面展示了湖北的历史文化。馆内设有楚文化陈列、古代钱币陈列等多个专题展区。
💡必打卡点:楚文化陈列区,感受楚文化魅力
🌍地址:武汉市武昌区东湖路6号
⏱️游玩时长:2-3小时
#文物珍品 #楚文化 #历史文化
🌸**
这是武汉市的地标性建筑,坐落在蛇山之巅,是观赏长江风光的绝佳去处。登上黄鹤楼,可将长江两岸的美景尽收眼底。
💡必打卡点:黄鹤楼顶层,远眺长江美景
🌍地址:武汉市武昌区黄鹤楼路1号
⏱️游玩时长:1-2小时
#地标建筑 #长江美景 #登高望远
#武汉旅游攻略 #武汉赏樱花 #清明踏青好去处
跟着我的行程,一定能在武汉过一个浪漫又充实的樱花季哦~快快行动起来,武汉的樱花正等着你呢!
Feedback
#Feedback的主要目的接受到输入的Response后,通过LLM对Response分析,然后输出改进建议。
#所以Feedback代码主要实现2个地方: 1.设定评估指标是什么 2.让大模型根据评估指标对Init产生的Response
#或者是迭代产生的Response生成改进建议。
class Feedback():def __init__(self, model_id: str, prompt_examples: str) -> None:self.model_id = model_idself.inter_example_sep = '\n'self.setup_prompt_from_examples_file(prompt_examples)#example文件提供了好的文案所对应的评价以及评价建议和得分(示例会在后面提供),需要人工预先设计,作为few_shot。#组装成Feedback的prompt.即上面说的第1点的实现def setup_prompt_from_examples_file(self, examples_path: str) -> str:with open(examples_path, 'r') as f:examples_json = json.load(f)#需要自己来设计和Feedback相关的评价指标,如下是此case的6个指标## Relevant: {Relevant} 相关性# Engaging : {Engaging} 吸引力# Vivid: {Vivid} 生动性# Consistent: {Consistent} 一致性# Informative: {Informative} 信息量# Formatting: {Formatting}。 排版TEMPLATE = """Response: {response}Scores:* Relevant: {Relevant}* Engaging : {Engaging}* Vivid: {Vivid}* Consistent: {Consistent}* Informative: {Informative}* Formatting: {Formatting}* Total score: {total_score} //综合得分"""feedback = []for row in examples_json:feedback.append(TEMPLATE.format(response=row["response"],Relevant=row["Relevant"],Informative=row["Informative"],Consistent=row["Consistent"],Engaging=row["Engaging"],Vivid=row["Vivid"],Formatting=row['Formatting'],total_score=row["total_score"],))feedback_prompt = """我们期望通过不同迭代提高文案的质量。为了帮助提高质量,我们提供了一些样例,并针对这些样例在一些与文案质量相关的维度上进行了打分。下面是这些样例以及它们的分数:"""self.system_prompt = feedback_prompt + self.inter_example_sep.join(feedback)#第(2)步:将(1)里组装好的system prompt + init / iterate 产生的response 输入给LLM,返回反馈建议def __call__(self,response: str):feedback_user_prompt = """请按照样例对文案在每个维度上进行打分和评估,并将分数和打分的理由放在<score></score>里。请不要忘记输出总分。"""score_messages = f"""{feedback_user_prompt}{response}\n\n"""body=json.dumps({ "anthropic_version": "bedrock-2023-05-31", "max_tokens": model_config['max_tokens'], "temperature": model_config['temperature'], "top_p": .model_config['top_p'], "top_k": model_config['top_k'],"system": sys_prompt, "messages": score_messages"stop_sequences" : '</score>'} )response = bedrock_client.invoke_model(body = body,modelId = model_id,accept = 'application/json',contentType = 'application/json',)response_body = json.loads(response.get('body').read())for response_content in response_body['content']:if response_content['type'] == 'text':generated_response = response_content['text']usage = response_body['usage']return response_body, generated_response
example 文件内容如下,主要定义了好的文案的范例,以及评分的指标逻辑,供 LLM 学习。
|
|

此步骤回产生关于原文改写的建议和评分,如下所示例:
Relevant: 4/5 - 文案内容与主题"是时候去武汉赏樱花了"高度相关,提到了武汉多个适合赏樱的景点。Engaging: 4/5 - 文案采用了亲和友好的语气,并给出了实用的旅游信息和建议,能够吸引读者的兴趣。Vivid: 4/5 - 对每个景点都进行了生动形象的描述,让读者能够脑补出赏樱的场景。Consistent: 5/5 - 文案内容完全符合给出的行程安排,覆盖了所有景点。Informative: 5/5 - 为每个景点提供了详细的地址、游玩时长等实用信息,非常具有指导性。Formatting: 4/5 - 排版整洁有序,结构分明,使用了适量的表情符号和注释,格式规范。总分: 26/30
Refine
# Refine同样也做2件事情
# (1)和Feedback的(1)一样,把example的评估指标组装成system prompt。让LLM预置feedback的评估条件知识
# (2) 将Feedback返回的response,feedback连同system prompt 一起输入给LLM,让LLM进行改写。class TaskRefine():def __init__(self, model_id: str, prompt_examples: str) -> None:self.model_id = model_idself.inter_example_sep = "\n\n###\n\n"self.question_prefix = '\n\n'self.system_prompt = self.setup_prompt_from_examples_file(prompt_examples=prompt_examples)#任务(1):挑选出example文件里的得分最高的文案,然后组装成system prompt,作为LLM改写的标准def setup_prompt_from_examples_file(self, prompt_examples: str) -> str:with open(prompt_examples, 'r') as f:examples_json = json.load(f)examples_df = pd.DataFrame(examples_json)# group on examplegrouped = examples_df.groupby("example")prompt = []# sort each group by scorefor _, group in grouped:group["numerical_score"] = group["total_score"].apply(lambda x: int(x.split("/")[0].strip()))group = group.sort_values("numerical_score")prompt.append(self.make_one_iterate_example(group.to_dict("records")))return self.inter_example_sep.join(prompt) + self.inter_example_sep##任务(1)组装成system prompt,作为LLM改写的标准 def make_one_iterate_example(self, incrementally_improving_examples: List[Dict]):"""Given a list of examples that are incrementally improving, return a new example."""feedback_prompt = """我们期望通过不同迭代提高文案的质量。为了帮助提高质量,我们提供了一些样例,并针对这些样例在一些与文案质量相关的维度上进行了打分。下面是这些样例以及它们的分数:"""self.system_prompt = feedback_prompt + self.inter_example_sep.join(feedback)TEMPLATE = """Response: {response}Scores:* Relevant: {Relevant}* Engaging : {Engaging}* Vivid: {Vivid}* Consistent: {Consistent}* Informative: {Informative}* Formatting: {Formatting}* Total score: {total_score}"""prompt = []for row in incrementally_improving_examples:prompt.append(TEMPLATE.format(response=row["response"],Relevant=row["Relevant"],Informative=row["Informative"],Consistent=row["Consistent"],Engaging=row["Engaging"],Vivid=row["Vivid"],Formatting=row['Formatting'],total_score=row["total_score"],))prompt = "".join(prompt)prompt = feedback_prompt + promptreturn prompt.strip()#任务(2):将Feedback模块生成的反馈建议和对应的文案response, 组装成用户的prompt def __call__(self,feedback:str,schedule:str,response:str) -> str:input_txt = f"""<Schedule> {schedule}</Schedule> <Response>{response}</Response><Feedback>{feedback}</Feedback>Okay, let's use this feedback to improve the response."""transfer_query = """请按照<Feedback></Feedback>里的打分和评估对<Response></Response>里的现有文案进行修改,注意请特别针对低分维度按照样例里的高分例子进行修改。将修改后的文案放在<updated_result></updated_result>里{input_txt}"""self.count += 1with open(f"responses_iterate_{self.count}.txt", "w") as f:f.write(transfer_query + "\n")body=json.dumps({ "anthropic_version": "bedrock-2023-05-31", "max_tokens": model_config['max_tokens'], "temperature": model_config['temperature'], "top_p": .model_config['top_p'], "top_k": model_config['top_k'],"system": system_prompt, "messages": transfer_query"stop_sequences" : '</updated_result>'} )response = bedrock_client.invoke_model(body = body,modelId = model_id,accept = 'application/json',contentType = 'application/json',)response_body = json.loads(response.get('body').read())for response_content in response_body['content']:if response_content['type'] == 'text':generated_response = response_content['text']usage = response_body['usage']return response_body, generated_response
3.3 实施结果
经过一轮的 Feedback+Refine 后,最终结果如下:
标题:🌸清明踏青,武汉樱花浪漫之旅,一网打尽知音号、汉秀剧场、两江夜游、东湖等经典赏樱地!🌸
亲爱的小伙伴们,樱花季来临,武汉的春色无疑是最迷人的!这座英雄城市不仅有浪漫的樱花小径,更有独具特色的文化体验。趁着清明小长假,不如就来武汉感受一番春日的活力与浪漫吧!
🌺【aaaa】:复古游船,江上赏樱正当时
📍地址:武汉市武昌区东湖路知音门游船码头
⏱️建议游玩时长:2小时
乘坐这艘复古的游船,沿着波光粼粼的长江徐徐前行,两岸的樱花美景尽收眼底。船上更有地道的楚文化歌舞表演,让你在欣赏春日美景的同时,也能领略武汉独有的文化魅力。别忘了在船头合影留念,定格这份江上赏樱的浪漫时刻!
🌺【bbbb】:楚文化盛宴,古韵现代共舞
📍地址:武汉市武昌区东湖路汉秀剧场
⏱️建议游玩时长:2小时
这座融合了古典与现代元素的大剧场,每晚都会上演精彩绝伦的楚文化歌舞盛宴。剧场内部装潢华丽大气,处处彰显着楚文化的独特魅力。建议提前购票,在大堂留影,定格这份剧场的非凡气派。
🌺【cccc】:夜赏长江,领略”两江交汇”
📍地址:武汉市江岸区长江大桥
⏱️建议游玩时长:1小时
乘船游览被誉为”天下绝景”的长江与汉江交汇处,领略那”两江交汇”的磅礴气势。夜幕降临,城市的万家灯火与江面上盛开的樱花交相辉映,构成一幅迷人的城市夜色。别忘了在长江大桥合影留念,定格这份动人心魄的美景。
🌺【dddd】:城中湖赏樱,樱花小径徐徐
📍地址:武汉市武昌区东湖风景区
⏱️建议游玩时长:2-3小时
东湖是武汉市区内一座秀美的城中湖,四周环湖而建有公园、步行道等,是武汉人民休闲娱乐的好去处。樱花季节,湖边的樱花小径更是赏花的绝佳地点。漫步在粉色的花海中,闻着淡淡的花香,感受春日的温馨与活力。
🌺【湖北省cccc】:领略楚文化魅力
📍地址:武汉市武昌区东湖路6号
⏱️建议游玩时长:2-3小时
这里收藏了大量珍贵的文物,全面展示了湖北的悠久历史文化。馆内设有楚文化陈列、古代钱币陈列等多个专题展区,让你能够深入了解源远流长的楚文化。建议先在楚文化陈列区感受楚文化的独特魅力,再逐一欣赏其他展区的精彩展品。
🌺【黄hhhh】:登高望远,长江美景尽收眼底
📍地址:武汉市武昌区黄鹤楼路1号
⏱️建议游玩时长:1-2小时
黄鹤楼是武汉市的地标性建筑,坐落在蛇山之巅,是观赏长江风光的绝佳去处。登上黄鹤楼,你就能将长江两岸的迷人春色尽收眼底。樱花与江景交相辉映,构成一幅动人心魄的美景,让你在高处尽情感受武汉的春日魅力。
🌸【旅行小贴士】🌸
1.樱花花期短暂,出行前务必关注实时花况,把握最佳赏樱时机。
2.清明期间,武汉早晚温差较大,记得带上轻便的外套哦。
3.景点游览时,请保持环境卫生,不要在樱花树下野餐,以免破坏花树。
4.武汉还有很多其他赏樱好去处,如东湖樱花园、大学城樱花道等,可根据个人兴趣自行规划。
最终 LLM 也给出更高的评分:
Relevant: 5/5 - 文案内容与主题"是时候去武汉赏樱花了"高度相关,详细介绍了武汉多个赏樱好去处。Engaging: 4/5 - 文案采用生动有趣的语言,结合实用信息和小贴士,能够吸引读者继续阅读。Vivid: 4/5 - 对每个景点的描述都很生动形象,让读者能够脑补现场的美景。Consistent: 5/5 - 文案内容完全符合给定的行程安排,没有遗漏。Informative: 5/5 - 为每个景点提供了详细的地址、建议游玩时长等实用信息。Formatting: 4/5 - 排版整洁有序,使用了恰当的表情符号和标题,能够吸引读者的注意力。总分: 27/30
4. Self Refine 技术总结
最后我们再来总结下 Self Refine 的优劣势。
4.1 优势
- 输出质量提升:通过迭代优化,Self Refine 能够显著提高 LLM 输出的质量,使内容更加精炼、准确和上下文适当。
- 效率提高:减少了人工干预的需求,大大提高了内容生产的效率。
- 灵活性:可应用于多种任务类型,从文本生成到代码优化,适应性强。
- 无需额外训练:可直接使用现有的预训练 LLMs,降低了实施门槛。
- 自适应能力:能够根据特定任务和领域的要求进行调整,提高输出的相关性。
- 一致性保证:通过定义明确的质量标准和评估机制,确保输出的一致性。
- 持续学习:通过保留历史迭代信息,模型能够从过往经验中学习,逐步提高性能。
4.2 局限性
- 计算开销:多次迭代可能增加处理时间和计算成本,特别是对于大规模应用。
- 潜在的循环推理:在某些情况下,模型可能会陷入自我强化的循环,反复修改同一问题而无法取得实质性进展。
- 依赖初始提示质量:Self Refine 的效果在很大程度上取决于初始提示的质量和明确性。
- 停止条件的确定:设置合适的停止条件以平衡质量和效率可能具有挑战性,需要仔细调优。