Stable Diffusion不同部件拆分详解!
前言
看到很多文章对Stable Diffusion各种原理、详解等,但是么有看到有文章细拆里面各个子模块在做啥,怎么做的,所以就会遇到整体原理理解很透传,问到细节就卡住,这段时间细看了一下文章,对各个部分做一个拆解详解。
Stable Diffusion由多个子网络组成,包括文本编码器、UNet和VAE三大部分。组合在一起可以看做一个接收文本输入,输出图像的模型。
所有的AI设计工具,模型和插件,都已经整理好了,👇获取~ 

整体上看是一个接收文本输入,并输出图像的模型。Stable Diffusion处理的过程如下:
-
输入文本,使用CLIP模型对文本进行编码,获得文本Embedding
-
噪声输入VAE编码器,获取潜空间生成噪声Latent
-
将文本Embedding和Latent输入UNet模型,预测Latent中的噪声
-
去除Latent中的噪声,去除噪声后的结果重新赋值为Latent
-
重复步骤3、4直至噪声去除干净(step=30/50/1000等)
-
将Latent传入VAE解码器,得到最终生成图片
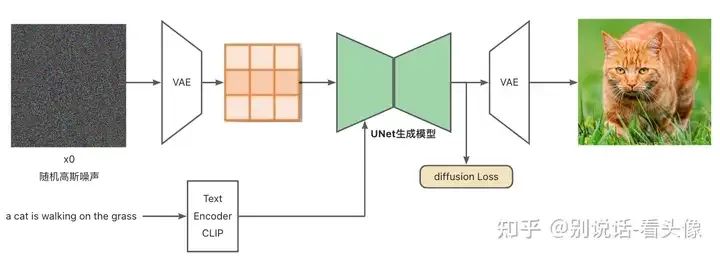
在整个网络训练过程当中,VAE编码器和解码器是在大量数据上预训练获取,CLIP Text Encoder使用大量的文本-图像对坐预训练,整个模型的核心是一个UNet噪声预测网络。不同于GAN直接从噪声中生成图片,Stable Diffusion会进行多次预测噪声并降噪,最终生成图片。
VAE
VAE模型在Diffusion Model里面并非必要的,因为Unet是可以直接接收图像输入,但是因为图像维度较高,增加计算量,训练效率降低,实际上VAE在Stable Diffusion中是作为一种提效的方法,减少了图片生成的资源需求。
VAE由Encoder和Decoder两个部分组成,首先需要输入x,经过Encoder编码后,得到(μ,σ),分别表示均值和方差,这两个变量可以确定一个分布,然后在当前分布中采样出样本z。z通常是一个比x维度更低的向量。采样出来的z输入Decoder,希望Decoder的输出x`与输入的x越接近越好。这样就达到了图像压缩的效果。
在训练Stable Diffusion时,会把图片输入VAE的Encoder,然后再拿来训练UNet,这样就可以在更低的维度空间训练图像生成模型,这样就可以减少资源的消耗。
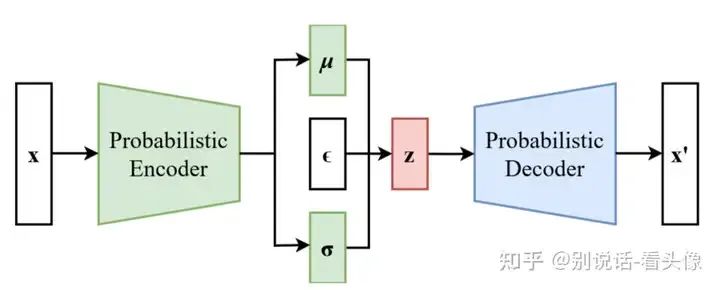
问题就来了,VAE为什么能够作为图像恢复使用?
说到VAE就不得不先说一下AutoEncoder(AE:自编码器)
-
AE的Encoder是将图片映射成“数值编码”
-
Decoder是将“数值编码”映射成图片
这样存在的问题是,在训练过程中,随着不断降低输入图片与输出图片之间的误差,模型会过拟合,泛化性能不好。也就是说对于一个训练好的AE,输入固定的一张图片,就只会将其编码为确定的code,对于Decoder输入某个确定的code就只会输出某个确定的图片,并且如果这个code来自于没见过的图片,那么生成的图片也不会好。所以AE多用于数据的压缩和恢复,用于数据生成时效果并不理想。
那么VAE的为什么可以呢?实际上VAE不是将图片映射成“数值编码”,而将其映射成“分布”。举一个例子,假设人脸的属性只有6个维度[smile,skin tone, gender, beard,glasses,hair color],使用大型人脸数据集上训练了一个自编码器模型,理想的自编码器将学习人脸的描述性属性,如肤色、是否戴眼镜等,模型试图用一些压缩的表示来描述观,我们可能更倾向于将每个潜在属性表示为可能值的范围,比如概率在0~5之间认为是【笑】,其他是【不笑】。通过这种方法,我们现在将给定输入的每个潜在属性表示为概率分布。当从潜在状态解码时,我们将从每个潜在状态分布中随机采样,生成一个向量作为解码器模型的输入来得到对应的图像。
通过构造的编码器模型来输出可能值的范围(统计分布),我们将随机采样这些值以供给我们的解码器模型,我们实质上实施了连续,平滑的潜在空间表示。对于潜在分布的所有采样,期望解码器模型能够准确重构输入。因此,在潜在空间中彼此相邻的值应该与非常类似的重构相对应。
那也可以看出来,VAE的缺点是生成的数据不一定那么“真”,存在中间值,比如二分类猫狗数据,会存在一段概率分布在猫狗之间,那么解码器生成的图像会是即像猫又像狗,这也是现在SD等生图模型的结果会存在四不像。

Text Encoder CLIP
先看整体结构,是不是十分的清爽,简单明了。包括两个部分,即文本编码器(Text Encoder)和图像编码器(Image Encoder)。Text Encoder选择的是Text Transformer模型;Image Encoder选择了两种模型,一是基于CNN的ResNet(对比了不同层数的ResNet),二是基于Transformer的ViT。
CLIP在文本-图像对数据集上的对比学习训练过程如下:
-
对于一个包含N个<文本-图像>对的训练batch,使用Text Encoder和Image Encoder提取N个文本特征和N个图像特征。
-
这里共有N个正样本,即真正属于一对的文本和图像(矩阵中的对角线元素),而剩余的文本-图像对皆为负样本。
-
将N个文本特征和N个图像特征两两组合,CLIP模型会预测出 N^2个可能的文本-图像对的相似度,这里的相似度直接计算文本特征和图像特征的余弦相似性(cosine similarity),即图中所示的矩阵。
-
CLIP的训练目标就是最大化N个正样本的相似度,同时最小化N^2−N个负样本的相似度,即最大化对角线中蓝色的数值,最小化其它非对角线的数值

Image_features = image_encoder(I) #[n, d_i]
Text_features = text_encoder(T) #[n, d_t] # 对两个特征进行线性投射,得到相同维度的特征,并进行l2归一化
Image_embedding = l2_normalize(np.dot(Image_features, W_i), axis=1)
Text_embedding = l2_normalize(np.dot(Text_features, W_t), axis=1) # 计算缩放的余弦相似度:[n, n]
logits = np.dot(Image_embedding, Text_embedding.T) * np.exp(t) # 对称的对比学习损失:等价于N个类别的cross_entropy_loss
labels = np.arange(n) # 对角线元素的labels
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
思考题:CLIP的text Encoder为什么能在Stable Diffusion中用来做Unet的去噪Condition?
-
文本直接输入网络需要转换为特征,其实现在有很多预训练好的文本编码器效果都很好,为什么当时优先选择了CLIP呢,大概率是因为CLIP的text Encoder在训练过程当中和图像进行了对齐,因为本身来讲图像和文本是两个域的数据,由于跨域之后一般不可比的原因,所以优先选择了CLIP,预训练时候已经把text和image做对齐,引起拿到对应的输入信息之后,可以类比为图像信息,对去噪进行增加,提高生成图像的效果。
-
CLIP的text Encoder较小,训练效率高
Unet
UNet模型在结构与VAE非常相似,也是Encoder-Decoder架构。在Stable Diffusion中,UNet作为一个噪声预测网络,在生图过程中需要进行多次推理,逐步预测当前step的噪声进行去噪,得到最终结果。首先不考虑VAE的介入,来看看UNet在Stable Diffusion中的作用。
实际上UNet在Stable Diffusion中充当噪声预测的功能。UNet接收一张带有噪声的图片,输出图片中的噪声,根据带噪声的图片和噪声我们可以得到加噪前的图片。这个降噪的过程通常会重复N遍。
知道UNet的作用后,就需要创建数据集了。输入只需要图片即可,拿到图片对该图片进行n次加噪,直到原图变成完全噪声。而加噪前的图片可以作为输入,加噪后的数据可以作为输出。如图所示:
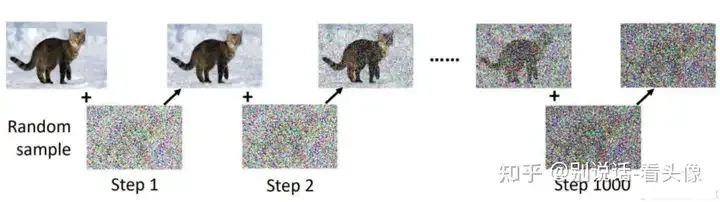
在加噪的过程中,噪声逐步增大。因此在去噪的过程中,需要有噪声图片,以及当前加噪的step,然后预测对应的噪声进行去噪。下图是噪声预测部分的结构:
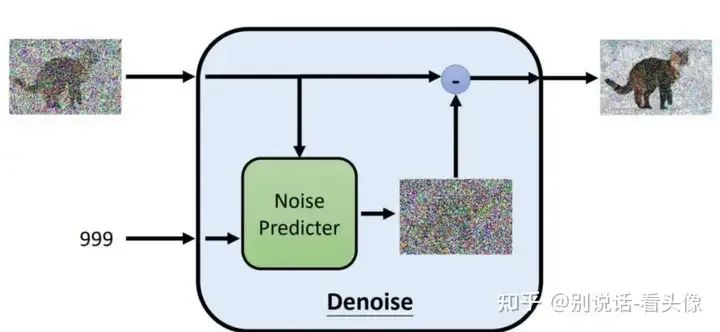
最后图像生成的步骤就是不停降噪的步骤:
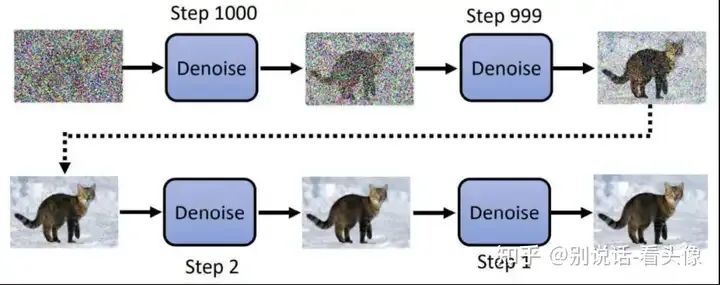
最后,再加入VAE。加噪和预测噪声的步骤不再是作用在原图上,而是作用在VAE Encoder的输出上面,这样我们就可以在较小的图像(latents)上完成UNet的训练,极大减少资源的消耗。
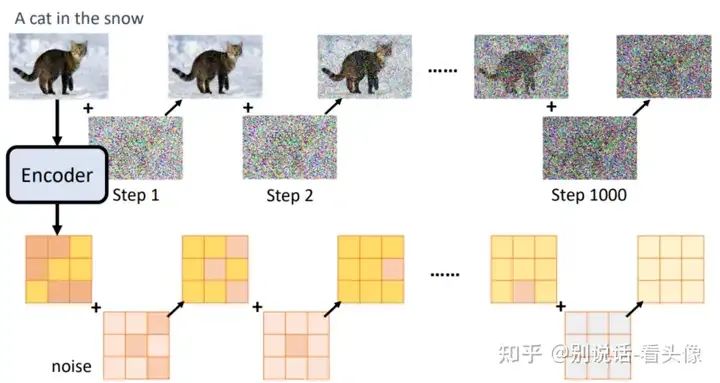
loss是如何计算的:降噪过程中Unet是在学习噪声分布,loss是约束每次添加的噪声和网络输出的噪声之间的距离,即前向加噪过程可以得到样本和噪声标签,反向过程进行计算可以得到对应的loss。

这里分享给大家一份Adobe大神整理的《AIGC全家桶学习笔记》,相信大家会对AIGC有着更深入、更系统的理解。
有需要的朋友,可以点击下方免费领取!

AIGC所有方向的学习路线思维导图
这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。如果下面这个学习路线能帮助大家将AI利用到自身工作上去,那么我的使命也就完成了:
AIGC工具库
AIGC工具库是一个利用人工智能技术来生成应用程序的代码和内容的工具集合,通过使用AIGC工具库,能更加快速,准确的辅助我们学习AIGC

有需要的朋友,可以点击下方卡片免费领取!

精品AIGC学习书籍手册
书籍阅读永不过时,阅读AIGC经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验,结合自身案例融会贯通。
AI绘画视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,科学有趣才能更方便的学习下去。
